Kafka架构详解之分区Partition
目录
- 一、简介
- 二、架构
- 三、分区Partition
- 1.分区概念
- 2.Offsets(偏移量)和消息的顺序
- 3.分区如何为Kafka提供扩展能力
- 4.producer写入策略
- 5.consumer消费机制
一、简介
Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义:一个分布式发布 - 订阅消息传递系统。
Kafka 最初由 LinkedIn 公司开发,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
Kafka 的主要应用场景有:日志收集系统和消息系统。
Kafka的原理、基础架构、以及使用场景-mikechen的互联网架构
二、架构
Kafka 的架构包括以下组件:
Kafka的原理、基础架构、以及使用场景-mikechen的互联网架构
- 1、话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名;
- 2、生产者(Producer):是能够发布消息到话题的任何对象
- 3、服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或 Kafka 集群;
- 4、消费者(Consumer):可以订阅一个或多个话题,并从 Broker 拉数据,从而消费这些已发布的消息;
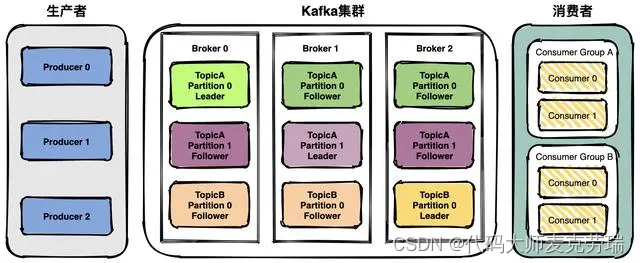
上图中可以看出,生产者将数据发送到 Broker 代理,Broker 代理有多个话题 topic ,消费者从 Broker 获取数据。
三、分区Partition
用过消息队列的同学对Kafka都不陌生,但是Kafka的topic中存在一个分区的概念,这是他和其他消息队列组件性能上一分高下的其中一个技术点,当然也是用好Kafka需要咱们开发人员理解透彻的一个技术点,接下来咱们就来掰扯一下分区Partition。
1.分区概念
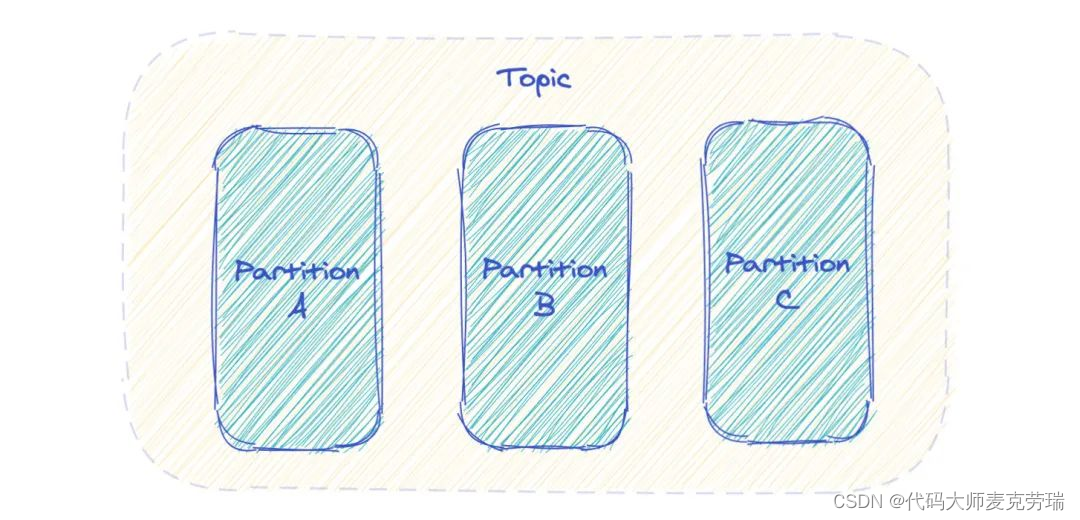
Kafka 中 Topic 被分成多个 Partition 分区。
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。
每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
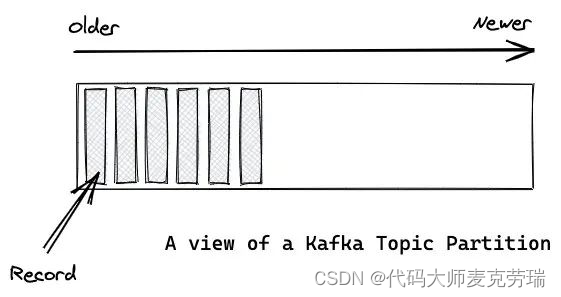
Record(记录) 和 Message(消息)是一个概念。
2.Offsets(偏移量)和消息的顺序
Partition 中的每条记录都会被分配一个唯一的序号,称为 Offset(偏移量)。
Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。
当一条记录写入 Partition 的时候,它就被追加到 log 文件的末尾,并被分配一个序号,作为 Offset。
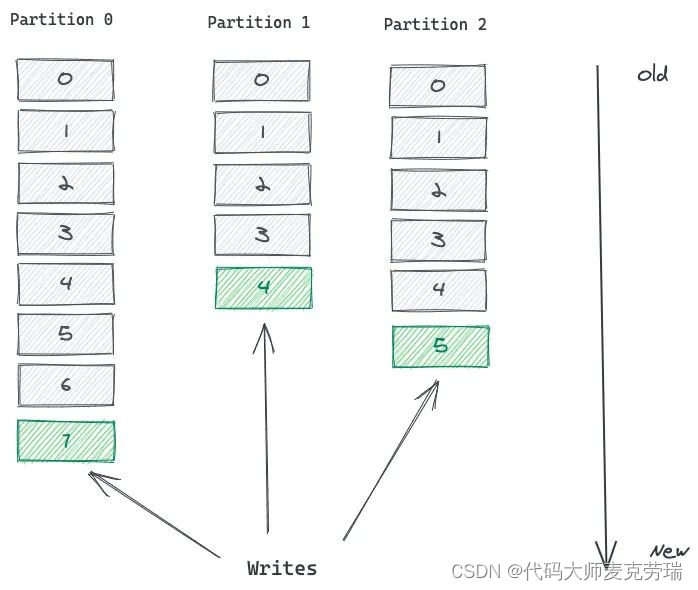
如上图,这个 Topic 有 3 个 Partition 分区,向 Topic 发送消息的时候,实际上是被写入某一个 Partition,并赋予 Offset。
消息的顺序性需要注意,一个 Topic 如果有多个 Partition 的话,那么从 Topic 这个层面来看,消息是无序的。
但单独看 Partition 的话,Partition 内部消息是有序的。
所以,一个 Partition 内部消息有序,一个 Topic 跨 Partition 是无序的。
如果强制要求 Topic 整体有序,就只能让 Topic 只有一个 Partition。
3.分区如何为Kafka提供扩展能力
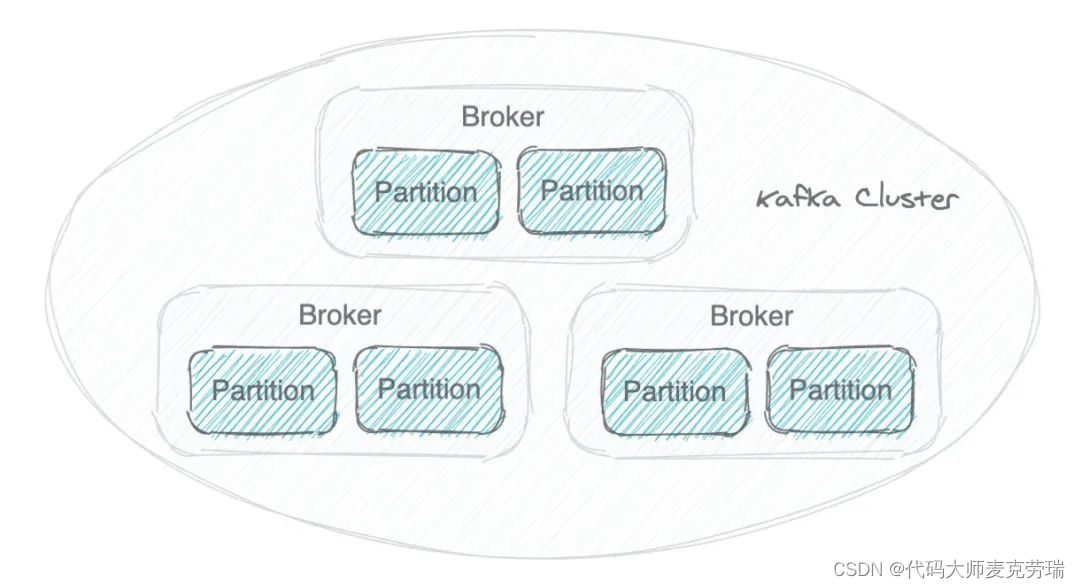
一个 Kafka 集群由多个 Broker(就是 Server) 构成,每个 Broker 中含有集群的部分数据。
Kafka 把 Topic 的多个 Partition 分布在多个 Broker 中。
这样会有多种好处:
- 如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
- 一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
- 一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
Kafka 为一个 Partition 生成多个副本,并且把它们分散在不同的 Broker。
如果一个 Broker 故障了,Consumer 可以在其他 Broker 上找到 Partition 的副本,继续获取消息。Partition 为 Kafka 提供了数据冗余。
4.producer写入策略
生产者写入分区的策略主要有以下几种:
1.轮询分区策略:生产者可以使用轮询策略将消息依次写入每个分区,实现负载均衡。在每次发送消息时,生产者会按照轮询的方式选择下一个可用的分区,并将消息写入该分区。这样可以确保消息均匀地分布在各个分区中。
2.随机分区策略:Kafka生产者随机的将消息写入分区,有可能会造成消息的分布不均,所以这个策略基本上也很少用。
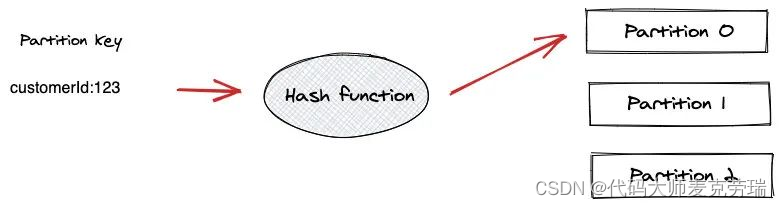
3.按 key 分区策略:Kafka生产者基于消息的键(key)进行哈希计算,然后将消息写入对应的分区。这种策略可以保证具有相同键的消息被写入到相同的分区,从而保证消息的顺序性。
这种方式需要注意 Partition 热点问题。
例如使用 User ID 作为 Partition Key,如果某一个 User 产生的消息特别多,是一个头部活跃用户,那么此用户的消息都进入同一个 Partition 就会产生热点问题,导致某个 Partition 极其繁忙。
4.自定义分区策略:Kafka生产者可以使用自定义分区策略来决定将消息写入哪个分区。
5.consumer消费机制
Kafka 不像普通消息队列具有发布/订阅功能,Kafka 不会向 Consumer 推送消息。当年因为不想换消息队列,用Kafka强行实现了发布订阅功能也正是利用了他的消费机制,具体可以看我之前的一篇帖子SpringBoot Kafka动态指定消费组。
Consumer 必须自己从 Topic 的 Partition 拉取消息。
一个 Consumer 连接到一个 Broker 的 Partition,从中依次读取消息。
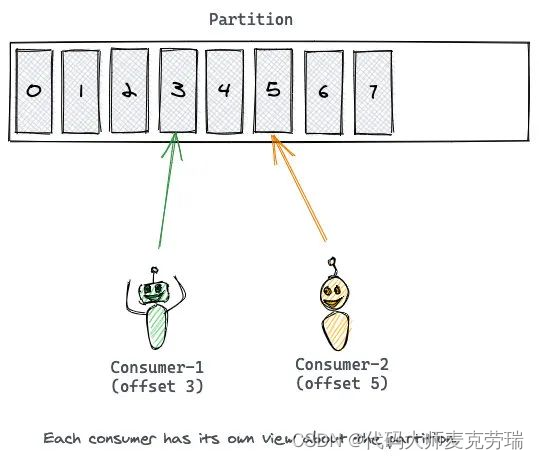
消息的 Offset 就是 Consumer 的游标,根据 Offset 来记录消息的消费情况。
读完一条消息之后,Consumer 会推进到 Partition 中的下一个 Offset,继续读取消息。
Offset 的推进和记录都是 Consumer 的责任,Kafka 是不管的。
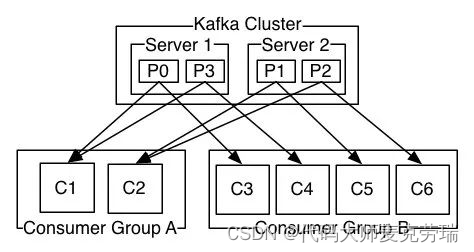
Kafka 中有一个 Consumer Group(消费组)的概念,多个 Consumer 组团去消费一个 Topic。
同组的 Consumer 有相同的 Group ID。
Consumer Group 机制会保障一条消息只被组内唯一一个 Consumer 消费,不会重复消费。
消费组这种方式可以让多个 Partition 并行消费,大大提高了消息的消费能力,最大并行度为 Topic 的 Partition 数量。
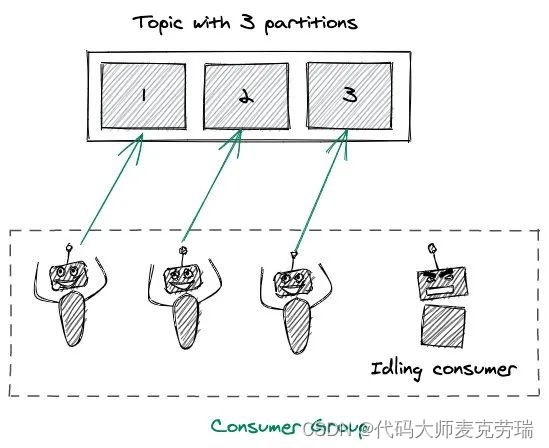
当你consumer数量大于partition数量的时候,其余空闲的consumer就是一种容错机制,当有consumer因其他原因无法正常工作时,空闲的节点就会补充上来。
相关文章:
Kafka架构详解之分区Partition
目录 一、简介二、架构三、分区Partition1.分区概念2.Offsets(偏移量)和消息的顺序3.分区如何为Kafka提供扩展能力4.producer写入策略5.consumer消费机制 一、简介 Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义…...

SSM之Mybatis
SSM之Mybatis 一、MyBatis简介1、MyBatis特性2、MyBatis的下载3、MyBatis和其他持久化层技术对比 二、MyBatis框架搭建三、MyBatis基础功能1、MyBatis核心配置文件2、MyBatis映射文件3、MyBatis实现增删改查4、MyBatis获取参数值的两种方式5、MyBatis查询功能6、MyBatis自定义映…...

Python list comprehension (列表推导式 - 列表解析式 - 列表生成式)
Python list comprehension {列表推导式 - 列表解析式 - 列表生成式} 1. Python list comprehension (列表推导式 - 列表解析式 - 列表生成式)2. Example3. ExampleReferences Python 中的列表解析式并不是用来解决全新的问题,只是为解决已有问题提供新的语法。 列…...

2024年7月12日理发记录
上周五天气还算好,不太热,晚上下班打车回家后,将目的地设置成日常去的那个理发店。 下车走到门口,熟悉的托尼帅哥正在抽烟,他一眼看到了我,马上掐灭烟头,从怀里拿出口香糖,咀嚼起来&…...

几种常用排序算法
1 基本概念 排序是处理数据的一种最常见的操作,所谓排序就是将数据按某字段规律排列,所谓的字段就是数据节点的其中一个属性。比如一个班级的学生,其字段就有学号、姓名、班级、分数等等,我们既可以针对学号排序,也可…...

Spring3(代理模式 Spring1案例补充 Aop 面试题)
一、代理模式 在代理模式(Proxy Pattern)中,一个类代表另一个类的功能,这种类型的设计模式属于结构型模式。 代理模式通过引入一个代理对象来控制对原对象的访问。代理对象在客户端和目标对象之间充当中介,负责将客户端…...

Github报错:Kex_exchange_identification: Connection closed by remote host
文章目录 1. 背景介绍2. 排查和解决方案 1. 背景介绍 Github提交或者拉取代码时,报错如下: Kex_exchange_identification: Connection closed by remote host fatal: Could not read from remote repository.Please make sure you have the correct ac…...
LabVIEW在CRIO中串口通讯数据异常问题
排查与解决步骤 检查硬件连接: 确保CRIO的串口模块正确连接,并且电缆无损坏。 确认串口模块在CRIO中被正确识别和配置。 验证串口配置: 在LabVIEW项目中,检查CRIO目标下的串口配置,确保波特率、数据位、停止位和校验…...

ALTERA芯片解密FPGA、CPLD、PLD芯片解密解密
Altera是世界一流的FPGA、CPLD和ASIC半导体生产商,所提供的解决方案与传统DSP、ASSP和ASIC解决方案相比,缩短了产品面市时间,提高了性能和效能,降低了系统成本。针对Altera芯片解密,益臻芯片解密中心经过多年的芯片解…...

[RK3588-Android12] 关于如何取消usb-typec的pd充电功能
问题描述 RK3588取消usb-typec的pd充电功能 解决方案: 在dts中fusb302节点下usb_con: connector子节点下添加如下熟悉: 打上如下2个补丁 diff --git a/drivers/usb/typec/tcpm/tcpm.c b/drivers/usb/typec/tcpm/tcpm.c index c8a4e57c9f9b..173f8cb7…...

分布式 I/O 系统 BL200 Modbus TCP 耦合器
BL200 耦合器是一个数据采集和控制系统,基于强大的 32 位微处理器设计,采用 Linux 操作系统,支持 Modbus 协议,可以快速接入现场 PLC、SCADA 以及 ERP 系统, 内置逻辑控制、边缘计算应用,适用于 IIoT 和工业…...

Java面试题--JVM大厂篇之Serial GC在JVM中有哪些优点和局限性
目录 引言: 正文: 一、Serial GC概述 二、Serial GC的优点 三、Serial GC的局限性 结束语: 引言: 在Java虚拟机(JVM)中,垃圾收集器(Garbage Collector, GC)是关键组件之一,负责自动管理内…...

【人工智能】机器学习 -- 贝叶斯分类器
目录 一、使用Python开发工具,运行对iris数据进行分类的例子程序NaiveBayes.py,熟悉sklearn机器实习开源库。 1. NaiveBayes.py 2. 运行结果 二、登录https://archive-beta.ics.uci.edu/ 三、使用sklearn机器学习开源库,使用贝叶斯分类器…...

深入理解 React 的 useSyncExternalStore Hook
深入理解 React 的 useSyncExternalStore Hook 大家好,今天我们来聊聊 React 18 引入的一个新 Hook:useSyncExternalStore。这个 Hook 主要用于与外部存储同步状态,特别是在需要确保状态一致性的场景下非常有用。本文将深入探讨这个 Hook 的…...
场:河南农业大学)
河南萌新联赛2024第(一)场:河南农业大学
C-有大家喜欢的零食吗_河南萌新联赛2024第(一)场:河南农业大学 (nowcoder.com) 思路:匈牙利算法的板子题. 二部图 int n; vector<int> vct[505]; int match[505],vis[505]; bool dfs(int s){for(auto v:vct[s]){if(vis[v]) continue;…...

K8S 上部署 Emqx
文章目录 安装方式一:1. 快速部署一个简单的 EMQX 集群:2. 部署一个持久化的 EMQX 集群:3. 部署 EMQX Edge 集群和 EMQX 企业版集群: 安装方式二:定制化部署1. 使用 Pod 直接部署 EMQX Broker2. 使用 Deoloyment 部署 …...

[React]利用Webcomponent封装React组件
[React]利用Webcomponent封装React组件 为什么这么做 我个人认为,最重要的点是可以很方便地跨框架挂载和卸载wc元素(至少我在项目里是这么玩的),此外,基于wc的css沙箱以及它的shadowRoot机制,可以提供一套…...

Linux C服务需要在A服务和B服务都启动成功后才能启动
需求 C服务需要在A服务和B服务都启动成功后才能启动 服务编号服务名服务Anginx.service服务Bmashang.service服务Credis.service 实验 如果您想要 redis.service 在 nginx.service 和 mashang.service 都成功启动后才能启动,那么需要在 redis.service 的服务单元…...

VSCODE 下 openocd Jlink 的配置笔记
title: VSCODE 下 openocd Jlink 的配置笔记 tags: STM32HalCubemax 文章目录 内容VSCODE 下 openocd Jlink 的配置笔记安装完成后修改jlink的配置文件然后修改你的下载器为jlink烧录你的项目绝对会出现下面的问题那么打开下载的第一个软件 (点到这个jlink右键&…...

JVM--HostSpot算法细节实现
1.根节点枚举 定义: 我们以可达性分析算法中从GC Roots 集合找引用链这个操作作为介绍虚拟机高效实现的第一个例 子。固定可作为GC Roots 的节点主要在全局性的引用(例如常量或类静态属性)与执行上下文(例如 栈帧中的本地变量表&a…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...