《DRL》P10-P15-损失函数-优化(梯度下降和误差的反向传播)
文章目录
- 损失函数
- 交叉熵损失
- 多类别分类任务概述
- 真实标签的独热编码
- 交叉熵损失函数
- L p 范式 \mathcal{L}_{p}\text{ 范式} Lp 范式
- 均方误差
- 平均绝对误差
- 优化
- 梯度下降和误差的反向传播
简介
本文介绍了神经网络中的损失函数及其优化方法。损失函数用于衡量模型预测值与真实值之间的差异,其中交叉熵损失函数在分类问题中尤为重要。文章详细解释了交叉熵的概念,并通过二分类任务示例,阐述了如何使用sigmoid函数和交叉熵损失函数进行模型训练。在多类别分类任务中,softmax函数与交叉熵损失函数的结合提供了一个强大的训练框架。此外,文章还介绍了均方误差、平均绝对误差等其他损失函数,以及梯度下降和反向传播算法在神经网络优化中的应用。最后,讨论了激活函数的选择对模型训练效果的影响。
损失函数
神经网络的参数是自动学习的,那么它是如何自动学习的呢?
这需要损失函数(Loss Function)来引导。
损失函数通常被定义为一种计算误差的量化方式,也就是计算网络输出的预测值和目标值之间的损失值或者代价大小
损失值被用来作为优化神经网络参数的目标,我们优化的参数包括权重和偏差。
交叉熵损失
首先介绍KL(Kullback-Leibler)散度 起作用是衡量两个分布 P ( x ) P(x) P(x)和 Q ( x ) Q(x) Q(x) 的相似度:
D K L ( P ∥ Q ) = E x ∼ P [ log P ( x ) Q ( x ) ] = E x ∼ P [ log P ( x ) − log Q ( x ) ] D_{\mathrm{KL}}(P\|Q)=\mathbb{E}_{x\sim P}\bigg[\log\frac{P(x)}{Q(x)}\bigg]=\mathbb{E}_{x\sim P}[\log P(x)-\log Q(x)] DKL(P∥Q)=Ex∼P[logQ(x)P(x)]=Ex∼P[logP(x)−logQ(x)]
KL散度是一个非负的指标,并且只有P和Q两个分布一样时才取值0。当我们讨论KL散度 D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL(P∥Q)时,我们假设分布P是已知的并且固定的。这意味着P是一个确定性的概率分布,它的概率密度函数(或概率质量函数)是固定的,不随时间或样本的变化而变化。
因此,KL散度中的第一部分 E x ∼ P [ log P ( x ) ] \mathbb{E}_{x\sim P}[\log P(x)] Ex∼P[logP(x)]实际上是分布P的熵 H ( P ) H(P) H(P)。熵是分布P的一个性质,它衡量了P的不确定性或信息量。由于P是固定的,它的熵也是一个固定的数值,不依赖于我们选择的另一个分布Q。
因为KL散度的第一个项和Q没有关系,我们引入交叉熵的概念并把公式的第一项移除。
以下是交叉熵的定义:
H ( P , Q ) = − E x ∼ P log Q ( x ) H(P,Q)=-\mathbb{E}_{x\sim P}\log Q(x) H(P,Q)=−Ex∼PlogQ(x)
当我们说通过Q来最小化交叉熵,我们实际上是在尝试找到一个Q,使得 − E x ∼ P [ log Q ( x ) ] -\mathbb{E}_{x\sim P}[\log Q(x)] −Ex∼P[logQ(x)]尽可能小。由于KL散度的第一部分(即P的熵)是一个常数,不依赖于Q,所以当我们最小化交叉熵时,我们实际上是在最小化KL散度的第二部分。
因此,最小化交叉熵的效果等同于最小化KL散度,因为交叉熵是KL散度中唯一依赖于Q的部分。当交叉熵最小时,KL散度的第二部分也最小,而第一部分是固定的,所以整个KL散度也就最小了。
总结来说,最小化交叉熵H(P,Q)就是在最小化KL散度 D K L ( P ∥ Q ) D_{\mathrm{KL}}(P\|Q) DKL(P∥Q)中与Q有关的部分,而KL散度的另一部分(P的熵)是固定的,所以最小化交叉熵就等同于最小化KL散度。
在多类别分类任务中,深度神经网络通过softmax函数输出的是不同类别概率的分布,而不是直接输出一个样本属于的类别。softmax和交叉熵的结合为多类别分类任务提供了一个强大的框架,其中softmax提供了一种将网络输出转换为概率分布的方法,而交叉熵则提供了一个衡量这些概率分布与真实分布之间差异的度量,从而可以有效地训练网络。
例子:
在二分类任务中如何使用sigmoid函数和交叉熵损失函数来进行模型训练和损失计算。
-
二分类任务:在二分类任务中,每个数据样本 x i x_i xi都有一个对应的标签 y i y_i yi,这个标签是0或1。例如,如果我们是在做垃圾邮件分类,标签1可能代表垃圾邮件,而标签0代表非垃圾邮件。
在二分类问题中,每个样本 x i x_i xi 都有一个对应的真实标签 y i y_i yi,这个标签通常是二进制的,即 y i ∈ { 0 , 1 } y_i \in \{0, 1\} yi∈{0,1}。为了将这个标签转化为概率分布,我们可以使用 one-hot 编码:
- 如果 y i = 1 y_i = 1 yi=1,则真实标签对应的概率分布是 [ 0 , 1 ] [0, 1] [0,1],表示样本属于类别 1 的概率是 1,属于类别 0 的概率是 0。
- 如果 y i = 0 y_i = 0 yi=0,则真实标签对应的概率分布是 [ 1 , 0 ] [1, 0] [1,0],表示样本属于类别 0 的概率是 1,属于类别 1 的概率是 0。
-
模型预测:模型的任务是预测每个样本属于类别1的概率,记为 y ^ i , 1 \hat{y}_{i,1} y^i,1。由于在二分类问题中,样本只属于两个类别中的一个,所以样本属于类别0的概率就是 1 − y ^ i , 1 1 - \hat{y}_{i,1} 1−y^i,1,记为 y ^ i , 2 \hat{y}_{i,2} y^i,2。
-
使用sigmoid函数:在二分类神经网络中,最后一层通常使用sigmoid激活函数,它的输出是一个介于0和1之间的值,可以解释为样本属于类别1的概率。sigmoid函数定义为:
sigmoid ( x ) = 1 1 + e − x \text{sigmoid}(x) = \frac{1}{1 + e^{-x}} sigmoid(x)=1+e−x1
其中, x x x是神经网络的原始输出(logit)。在这个例子中,我们可以令 y ^ i = sigmoid ( x i ) \hat{y}_i = \text{sigmoid}(x_i) y^i=sigmoid(xi)。 -
交叉熵损失:现在我们有了真实标签的概率分布 [ y i , 1 − y i ] [y_i, 1 - y_i] [yi,1−yi] 和模型预测的概率分布 [ y ^ i , 1 − y ^ i ] [\hat{y}_i, 1 - \hat{y}_i] [y^i,1−y^i],我们可以计算交叉熵损失:
对于每个样本 i i i,交叉熵损失是:
L i = − ( y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ) L_i = - \left( y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right) Li=−(yilog(y^i)+(1−yi)log(1−y^i))
交叉熵损失函数用于衡量模型预测的概率分布与真实标签之间的差异。在二分类任务中,交叉熵损失函数可以写为:
L = − 1 N ∑ i = 1 N ( y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ) L = -\frac{1}{N} \sum_{i=1}^{N} \left( y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right) L=−N1i=1∑N(yilog(y^i)+(1−yi)log(1−y^i))
其中, N N N是总数据样本的大小。 -
损失函数的解释:在损失函数的表达式中,对于每个样本 i i i, y i y_i yi是真实标签, y ^ i \hat{y}_i y^i是模型预测的概率。由于 y i y_i yi是0或1,所以在 y i log ( y ^ i ) y_i \log(\hat{y}_i) yilog(y^i)和 ( 1 − y i ) log ( 1 − y ^ i ) (1 - y_i) \log(1 - \hat{y}_i) (1−yi)log(1−y^i)中,只有一个项会为非零值。具体来说:
- 如果 y i = 1 y_i = 1 yi=1,那么 1 − y i = 0 1 - y_i = 0 1−yi=0,所以只有 y i log ( y ^ i ) y_i \log(\hat{y}_i) yilog(y^i)这一项会被计算。
- 如果 y i = 0 y_i = 0 yi=0,那么 y i = 0 y_i = 0 yi=0,所以只有 ( 1 − y i ) log ( 1 − y ^ i ) (1 - y_i) \log(1 - \hat{y}_i) (1−yi)log(1−y^i)这一项会被计算。
-
最优情况:如果对于所有的样本 i i i,模型预测 y ^ i \hat{y}_i y^i都完全等于真实标签 y i y_i yi,那么交叉熵损失 L L L将会是0。这是因为当预测概率等于真实标签时,相应的对数项将会是0(因为 log ( 1 ) = 0 \log(1) = 0 log(1)=0),从而整个损失函数的值为0。
总结来说,这个例子说明了在二分类任务中,如何使用sigmoid函数来输出一个样本属于类别1的概率,以及如何使用交叉熵损失函数来衡量模型预测与真实标签之间的差异,并通过最小化这个损失来训练模型。
在多类别分类任务中,理解交叉熵损失函数的关键在于认识到每个样本都有一个确切的类别,并且模型需要预测每个类别的概率。
多类别分类任务概述
- 样本和类别:在多类别分类任务中,每个样本 x i x_i xi 被分到 M M M 个类别中的一个,其中 M ≥ 3 M \geq 3 M≥3。
- 模型预测:模型需要预测每个样本属于每个类别的概率,记为 y ^ i , 1 , y ^ i , 2 , … , y ^ i , M \hat{y}_{i,1}, \hat{y}_{i,2}, \ldots, \hat{y}_{i,M} y^i,1,y^i,2,…,y^i,M。这些预测概率必须满足条件 ∑ j = 1 M y ^ i , j = 1 \sum_{j=1}^{M} \hat{y}_{i,j} = 1 ∑j=1My^i,j=1,即每个样本的概率总和为 1。
真实标签的独热编码
- 类别标签:每个样本的目标类别 c i c_i ci 是一个整数,取值范围是 [ 1 , M ] [1, M] [1,M]。
- 独热编码:类别标签 c i c_i ci 可以被转换成一个独热编码向量 y i = [ y i , 1 , y i , 2 , … , y i , M ] y_i = [y_{i,1}, y_{i,2}, \ldots, y_{i,M}] yi=[yi,1,yi,2,…,yi,M],其中只有 y i , c i = 1 y_{i,c_i} = 1 yi,ci=1,表示样本属于第 c i c_i ci 个类别,其余元素都是 0。
交叉熵损失函数
-
交叉熵损失:多类别分类的交叉熵损失函数可以写成以下形式:
L = − 1 N ∑ i = 1 N ∑ j = 1 M y i , j log y ^ i , j L = -\frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{M} y_{i,j} \log \hat{y}_{i,j} L=−N1i=1∑Nj=1∑Myi,jlogy^i,j
其中, N N N 是样本总数。 -
简化损失函数:由于独热编码中只有一个元素为 1(即 y i , c i = 1 y_{i,c_i} = 1 yi,ci=1),其他元素都是 0,所以上述损失函数可以进一步简化。对于每个样本 i i i,只有 y i , c i log y ^ i , c i y_{i,c_i} \log \hat{y}_{i,c_i} yi,cilogy^i,ci 这一项是非零的,因此损失函数可以简化为:
L = − 1 N ∑ i = 1 N log y ^ i , c i L = -\frac{1}{N} \sum_{i=1}^{N} \log \hat{y}_{i,c_i} L=−N1i=1∑Nlogy^i,ci
这里, log y ^ i , c i \log \hat{y}_{i,c_i} logy^i,ci 是模型预测样本 i i i 属于其真实类别 c i c_i ci 的概率的对数。
由于独热编码的特性,我们只需要关注每个样本的真实类别对应的预测概率,这就是为什么最终的损失函数只涉及每个样本的真实类别 c i c_i ci 的预测概率 y ^ i , c i \hat{y}_{i,c_i} y^i,ci。
L p 范式 \mathcal{L}_{p}\text{ 范式} Lp 范式
向量 x \boldsymbol{x} x的 p p p-范式用来测量其数值幅度大小:如果一个向量的值更大,它的 p p p-范式也会有一个更大的值。p是一个大于或等于1的值, p p p-范式定义如下:
∥ x ∥ p = ( ∑ i = 1 N ∣ x i ∣ p ) 1 / p i . e . , ∥ x ∥ p p = ∑ i = 1 N ∣ x i ∣ p \begin{aligned}\|\boldsymbol{x}\|_p&=\left(\sum_{i=1}^N|x_i|^p\right)^{1/p}\\\mathrm{i.e.,~}\|\boldsymbol{x}\|_p^p&=\sum_{i=1}^N|x_i|^p\end{aligned} ∥x∥pi.e., ∥x∥pp=(i=1∑N∣xi∣p)1/p=i=1∑N∣xi∣p
p p p-范式在深度学习中往往用来测量两个向量的差别大小,写作 L p 范式 \mathcal{L}_{p}\text{ 范式} Lp 范式
L p = ∥ y − y ^ ∥ p p = ∑ i = 1 N ∣ y i − y ^ i ∣ p \mathcal{L}_p=\|\boldsymbol{y}-\hat{\boldsymbol{y}}\|_p^p=\sum_{i=1}^N|y_i-\hat{y}_i|^p Lp=∥y−y^∥pp=i=1∑N∣yi−y^i∣p
y \boldsymbol{y} y 是目标值向量 y ^ \hat{\boldsymbol{y}} y^ 是预测值向量
均方误差
均方误差(Mean Squared Error,MSE)是 L 2 范式 \mathcal{L}_{2}\text{ 范式} L2 范式的平均值。
MSE在网络输出时连续值的回归问题中使用。例如,两个不同的图像在像素上的区别可以用MSE来测量
L = 1 N ∥ y − y ^ ∥ 2 2 = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 \mathcal{L}=\frac1N\|\boldsymbol{y}-\hat{\boldsymbol{y}}\|_2^2=\frac1N\sum_{i=1}^N(y_i-\hat{y}_i)^2 L=N1∥y−y^∥22=N1i=1∑N(yi−y^i)2
平均绝对误差
类似于MSE,平均绝对误差(Mean Absolute Error,MAE) 也可用来做回归任务。
定义为 L 1 范式 \mathcal{L}_{1}\text{ 范式} L1 范式 的平均。
L = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ \mathcal{L}=\frac1N\sum_{i=1}^N|y_i-\hat{y}_i| L=N1i=1∑N∣yi−y^i∣
MAE和MSE都可用来衡量 y i y_i yi和 y ^ i \hat{y}_i y^i 的误差,用以优化网络模型。
- 均方误差提供了更好的数学性质:
- 均方误差是观测值与真实值之差的平方的平均值。由于平方操作是连续和可导的,因此在实现梯度下降算法时,均方误差的梯度(偏导数)可以很容易地计算出来。这一点对于优化算法来说非常重要,因为梯度下降算法需要通过计算损失函数的梯度来更新模型参数。
- 平均绝对误差中,当yi = ˆyi时,绝对值项无法求导:
- 平均绝对误差是观测值与真实值之差的绝对值的平均值。绝对值函数在值为零的地方不可导,这意味着当预测值(ˆyi)正好等于真实值(yi)时,MAE的导数为零或不定义。这会给优化过程带来困难,因为梯度下降依赖于损失函数的梯度来调整参数。
- 当yi和ˆyi的绝对差大于1时,均方误差相对平均绝对误差来说误差值更大:
- 这句话解释了均方误差和平均绝对误差在数值上的一个重要差异。当预测值与真实值的差距较大时,平方操作会放大这种差异。因此,如果(yi−ˆyi)的绝对值大于1,那么(yi−ˆyi)²将会比|yi−ˆyi|大。
- 显然地,当(yi−ˆyi)>1时,(yi−ˆyi)² >|yi−ˆyi|:
- 这是一个数学上的事实,说明了为什么均方误差对于较大的预测误差给予更高的惩罚。对于任何大于1的实数a,a²总是大于a。
综合以上几点,我们可以得出以下理解:
- 这是一个数学上的事实,说明了为什么均方误差对于较大的预测误差给予更高的惩罚。对于任何大于1的实数a,a²总是大于a。
- 均方误差在数学上更易于处理,特别是在使用梯度下降算法进行模型训练时。
- 平均绝对误差在预测值恰好等于真实值时存在导数不可求的问题,这可能会对优化过程产生不利影响。
- 均方误差对较大的预测误差给予更高的权重,这可能导致模型在处理异常值或大误差时更为敏感。
在实际应用中,选择哪种损失函数取决于具体问题的需求以及我们对模型误差的容忍度。均方误差在回归问题中更为常见,尤其是在解决连续值预测问题时,而平均绝对误差则可能在某些情况下更为稳健。
优化
梯度下降和误差的反向传播
如果有了神经网络和损失函数,那么训练神经网络的意义就是学习它的 θ \boldsymbol{\theta} θ使损失值 L \mathcal{L} L最小化。最暴力的方法是寻找一组 θ \boldsymbol{\theta} θ 使 ▽ θ L = 0 \bigtriangledown_{\boldsymbol{\theta}}\mathcal{L}=0 ▽θL=0 找到损失值的最小值,但这种方法很难实现,因为深度神经网络的参数很多、非常复杂。所以一般采用 梯度下降(Gradient Descent) 它是通过逐步优化来一步一步找更好的参数来降低损失值的。
梯度下降的学习过程是从一组随机指定的参数开始,参数通过 ∂ L ∂ θ \frac{\partial\mathcal{L}}{\partial\boldsymbol{\theta}} ∂θ∂L 被逐步优化。优化过程为:
θ : = θ − α ∂ L ∂ θ \boldsymbol{\theta}:=\boldsymbol{\theta}-\alpha\frac{\partial\mathcal{L}}{\partial\boldsymbol{\theta}} θ:=θ−α∂θ∂L
α \alpha α 为学习率,用以控制步长幅度。关键就是计算$\frac{\partial\mathcal{L}}{\partial\boldsymbol{\theta}} $ 。
反向传播(back-propagation) 是一种计算神经网络偏导数 ∂ L ∂ θ \frac{\partial\mathcal{L}}{\partial\boldsymbol{\theta}} ∂θ∂L 的方法,
反向传播算法(Back-Propagation)是一种用于计算神经网络参数梯度的高效方法,旨在优化网络的损失函数。该算法通过引入中间变量 δ l \delta_l δl,即损失函数 L L L 对网络层输出 z l z_l zl 的偏导数( δ l = ∂ L ∂ z l \delta_l = \frac{\partial L}{\partial z_l} δl=∂zl∂L),来简化梯度计算的过程。
在网络结构中,各层以序号 l l l 标识,其中 l ∈ { 1 , 2 , … , L } l \in \{1, 2, \ldots, L\} l∈{1,2,…,L}, L L L 代表输出层的序号。对于每个网络层,定义输出 z l z_l zl、中间变量 δ l = ∂ L ∂ z l \delta_l = \frac{\partial L}{\partial z_l} δl=∂zl∂L 以及激活输出 a l = f ( z l ) a_l = f(z_l) al=f(zl),其中 f f f 表示激活函数。
以下是反向传播算法的详细步骤:
- 输出层梯度计算:
- 对于输出层 L L L,首先计算中间变量 δ L \delta_L δL:
δ L = ∂ L ∂ a L ⋅ ∂ a L ∂ z L = ( a L − y ) ⊙ f ′ ( z L ) = ( a L − y ) ⊙ a L ( 1 − a L ) \delta_L = \frac{\partial L}{\partial a_L} \cdot \frac{\partial a_L}{\partial z_L} = (a_L - y) \odot f'(z_L) = (a_L - y) \odot a_L(1 - a_L) δL=∂aL∂L⋅∂zL∂aL=(aL−y)⊙f′(zL)=(aL−y)⊙aL(1−aL)
其中, ⊙ \odot ⊙ 表示元素逐乘。
- 对于输出层 L L L,首先计算中间变量 δ L \delta_L δL:
- 隐藏层梯度传播:
- 对于隐藏层( l = L − 1 , L − 2 , … , 1 l = L-1, L-2, \ldots, 1 l=L−1,L−2,…,1),利用链式法则和前一层传播回来的 δ \delta δ 值计算当前层的 δ l \delta_l δl:
δ l = ∂ L ∂ z l = ( ∂ z l + 1 ∂ a l ) T δ l + 1 ⊙ f ′ ( z l ) = ( W l + 1 ) T δ l + 1 ⊙ a l ( 1 − a l ) \delta_l = \frac{\partial L}{\partial z_l} = \left(\frac{\partial z_{l+1}}{\partial a_l}\right)^T \delta_{l+1} \odot f'(z_l) = (W_{l+1})^T \delta_{l+1} \odot a_l(1 - a_l) δl=∂zl∂L=(∂al∂zl+1)Tδl+1⊙f′(zl)=(Wl+1)Tδl+1⊙al(1−al)
- 对于隐藏层( l = L − 1 , L − 2 , … , 1 l = L-1, L-2, \ldots, 1 l=L−1,L−2,…,1),利用链式法则和前一层传播回来的 δ \delta δ 值计算当前层的 δ l \delta_l δl:
- 参数梯度计算:
- 在获得每层的 δ l \delta_l δl 后,计算损失函数对权重 ∂ L ∂ W l \frac{\partial L}{\partial W_l} ∂Wl∂L 和偏置 ∂ L ∂ b l \frac{\partial L}{\partial b_l} ∂bl∂L 的偏导数:
∂ L ∂ W l = δ l ⋅ ( a l − 1 ) T , ∂ L ∂ b l = δ l \frac{\partial L}{\partial W_l} = \delta_l \cdot (a_{l-1})^T, \quad \frac{\partial L}{\partial b_l} = \delta_l ∂Wl∂L=δl⋅(al−1)T,∂bl∂L=δl
- 在获得每层的 δ l \delta_l δl 后,计算损失函数对权重 ∂ L ∂ W l \frac{\partial L}{\partial W_l} ∂Wl∂L 和偏置 ∂ L ∂ b l \frac{\partial L}{\partial b_l} ∂bl∂L 的偏导数:
- 参数更新:
- 使用梯度下降法更新网络参数。权重和偏置的更新公式分别为:
W l : = W l − α ∂ L ∂ W l , b l : = b l − α ∂ L ∂ b l W_l := W_l - \alpha \frac{\partial L}{\partial W_l}, \quad b_l := b_l - \alpha \frac{\partial L}{\partial b_l} Wl:=Wl−α∂Wl∂L,bl:=bl−α∂bl∂L
其中, α \alpha α 是学习率。
- 使用梯度下降法更新网络参数。权重和偏置的更新公式分别为:
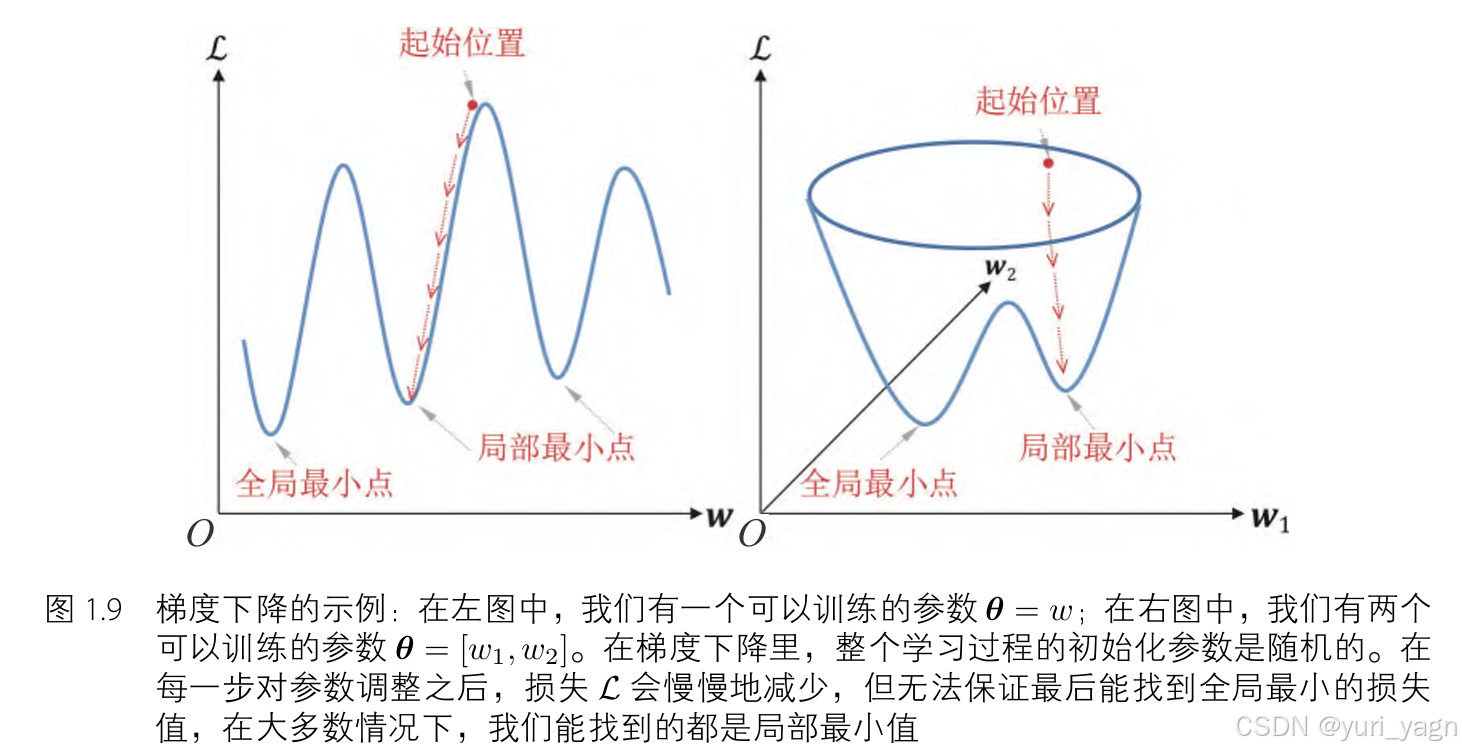
- 局部最小值问题:
- 在实际应用中,梯度下降可能不会收敛到全局最小值,而是局部最小值。然而,由于深度神经网络强大的表示能力,这些局部最小值通常足够接近全局最小值,从而使得损失函数的值降至可接受的水平。
在深度学习中,激活函数的选择对模型的训练效果有着重要的影响。以下是关于sigmoid激活函数和ReLU激活函数的一些讨论:
- Sigmoid激活函数的问题:
- 当使用sigmoid激活函数时,其导数为 ∂ a l ∂ z l = a l ( 1 − a l ) \frac{\partial a_l}{\partial z_l} = a_l(1 - a_l) ∂zl∂al=al(1−al)。当 a l a_l al 接近于0或1时, ∂ a l ∂ z l \frac{\partial a_l}{\partial z_l} ∂zl∂al 会变得非常小。这导致在深层网络中,反向传播时中间变量 δ l \delta_l δl 也会变得非常小,从而出现梯度消失(Vanishing Gradient)问题。梯度消失问题会使靠近输入层的网络参数难以更新,导致模型难以训练。
- 数学上,这可以表示为:
∂ a l ∂ z l = a l ( 1 − a l ) 当 a l ≈ 0 或 a l ≈ 1 , ∂ a l ∂ z l 非常小 \frac{\partial a_l}{\partial z_l} = a_l(1 - a_l) \quad \text{当} \quad a_l \approx 0 \quad \text{或} \quad a_l \approx 1, \quad \frac{\partial a_l}{\partial z_l} \quad \text{非常小} ∂zl∂al=al(1−al)当al≈0或al≈1,∂zl∂al非常小
- ReLU激活函数的优势:
- 相比之下,ReLU激活函数的导数 ∂ a l ∂ z l \frac{\partial a_l}{\partial z_l} ∂zl∂al 在 a l > 0 a_l > 0 al>0 时恒为1,从而避免了梯度消失问题。这也是当前深度学习模型在隐藏层中普遍使用ReLU而不是sigmoid的原因。
- 数学上,ReLU的导数可以表示为:
∂ a l ∂ z l = { 1 if a l > 0 0 otherwise \frac{\partial a_l}{\partial z_l} = \begin{cases} 1 & \text{if } a_l > 0 \\ 0 & \text{otherwise} \end{cases} ∂zl∂al={10if al>0otherwise
- 随机梯度下降法(SGD):
- 在梯度下降中,如果数据集的大小 N N N 很大,计算损失函数 L L L 的开销可能会很高。以均方误差为例,损失函数可以展开为:
L = 1 2 ∥ y − a L ∥ 2 = 1 2 ∑ i = 1 N ( y i − a L , i ) 2 L = \frac{1}{2} \left\| y - a_L \right\|^2 = \frac{1}{2} \sum_{i=1}^{N} \left( y_i - a_{L,i} \right)^2 L=21∥y−aL∥2=21∑i=1N(yi−aL,i)2 - 实践中,数据集往往很大,这使得梯度下降因为需要计算整个数据集上的 L L L 而变得低效。为了解决这个问题,随机梯度下降(SGD)被提出,它只使用少量的数据样本来近似计算损失函数的梯度。
- SGD的计算可以表示为:
∇ θ L ≈ ∇ θ L ^ ( B ) = 1 ∣ B ∣ ∑ i ∈ B ∇ θ L i ( θ ) \nabla_{\theta} L \approx \nabla_{\theta} \hat{L}(B) = \frac{1}{|B|} \sum_{i \in B} \nabla_{\theta} L_i(\theta) ∇θL≈∇θL^(B)=∣B∣1∑i∈B∇θLi(θ)
其中, B B B 是从数据集中随机抽取的一个小批量样本, ∣ B ∣ |B| ∣B∣ 是批量大小, L i L_i Li 是单个样本的损失函数。
- 在梯度下降中,如果数据集的大小 N N N 很大,计算损失函数 L L L 的开销可能会很高。以均方误差为例,损失函数可以展开为:
相关文章:
《DRL》P10-P15-损失函数-优化(梯度下降和误差的反向传播)
文章目录 损失函数交叉熵损失多类别分类任务概述真实标签的独热编码交叉熵损失函数 L p 范式 \mathcal{L}_{p}\text{ 范式} Lp 范式均方误差平均绝对误差 优化梯度下降和误差的反向传播 简介 本文介绍了神经网络中的损失函数及其优化方法。损失函数用于衡量模型预测值与真实值…...

Spring Boot项目的404是如何发生的
问题 在日常开发中,假如我们访问一个Sping容器中并不存在的路径,通常会返回404的报错,具体原因是什么呢? 结论 错误的访问会调用两次DispatcherServlet:第一次调用无法找到对应路径时,会给Response设置一个…...

<数据集>手势识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:2400张 标注数量(xml文件个数):2400 标注数量(txt文件个数):2400 标注类别数:5 标注类别名称:[fist, no_gesture, like, ok, palm] 序号类别名称图片数框数1fist597…...

【Vue3】选项式 API
【Vue3】选项式 API 背景简介开发环境开发步骤及源码总结 背景 随着年龄的增长,很多曾经烂熟于心的技术原理已被岁月摩擦得愈发模糊起来,技术出身的人总是很难放下一些执念,遂将这些知识整理成文,以纪念曾经努力学习奋斗的日子。…...

2、如何发行自己的数字代币(truffle智能合约项目实战)
2、如何发行自己的数字代币(truffle智能合约项目实战) 1-Atom IDE插件安装2-truffle tutorialtoken3-tutorialtoken源码框架分析4-安装openzeppelin代币框架(代币发布成功) 1-Atom IDE插件安装 正式介绍基于web的智能合约开发 推…...

百日筑基第二十三天-23种设计模式-创建型总汇
百日筑基第二十三天-23种设计模式-创建型总汇 前言 设计模式可以说是对于七大设计原则的实现。 总体来说设计模式分为三大类: 创建型模式,共五种:单例模式、简单工厂模式、抽象工厂模式、建造者模式、原型模式。结构型模式,共…...

张量的基本使用
目录 1.张量的定义 2.张量的分类 3.张量的创建 3.1 根据已有数据创建张量 3.2 根据形状创建张量 3.3 创建指定类型的张量 1.张量的定义 张量(Tensor)是机器学习的基本构建模块,是以数字方式表示数据的形式。PyTorch就是将数据封装成张量…...
什么是唯一键(Unique Key)?)
Oracle(14)什么是唯一键(Unique Key)?
唯一键(Unique Key)是数据库表中的一个或多个列,它们的值必须在整个表中唯一,但允许包含NULL值。唯一键的主要目的是确保表中每一行的数据在指定的列(或列组合)中是唯一的,以防止重复数据的出现…...

PostgreSQL的引号、数据类型转换和数据类型
一、单引号和双引号(重要): 1、在mysql没啥区别 2、在pgsql中,实际字符串用单引号,双引号相当于mysql的,用来包含关键字; -- 单引号,表示user_name的字符串实际值 insert into t_user(user_nam…...
)
Mad MAD Sum-Codeforces Round 960 (Div. 2)
题目在这里 大意: MAD函数返回出现次数 ≥ 2 \geq2 ≥2的最大整数 b i b_i bi M A D ( a [ 1 , 2 , . . . i ] ) MAD(a[1,2,...i]) MAD(a[1,2,...i]) 每次操作把 a i a_i ai进行上述操作,直到全变为0为止,对每次操作的数组进行求和,记…...

Flutter 插件之 package_info_plus
当使用Flutter开发应用时,通常需要获取应用程序的基本信息,例如包名、版本号和构建号。Flutter提供了一个名为 package_info_plus 的插件,它能方便地帮助我们获取这些信息。 1. 添加依赖 首先,需要在项目的 pubspec.yaml 文件中添加 package_info_plus 的依赖。打开 pubs…...
如何实现布隆过滤器?
1.布隆过滤器的场景 在Redis 缓存击穿(失效)、缓存穿透、缓存雪崩怎么解决?中我们说到可以使用布隆过滤器避免「缓存穿透」。 你会说我们只要记录了每个用户看过的历史记录,每次推荐的时候去查询数据库过滤存在的数据实现去重。 …...

运维团队如何高效监控容器化环境中的PID及其他关键指标
随着云计算和容器化技术的快速发展,越来越多的企业开始采用容器化技术来部署和管理应用程序。然而,容器化环境的复杂性和动态性给运维团队带来了前所未有的挑战。本文将从PID(进程标识符)监控入手,探讨运维团队如何高效…...

通过vue3 + TypeScript + uniapp + uni-ui 实现下拉刷新和加载更多的功能
效果图: 核心代码: <script lang="ts" setup>import { ref, reactive } from vue;import api from @/request/api.jsimport empty from @/component/empty.vueimport { onLoad,onShow, onPullDownRefresh, onReachBottom } from @dcloudio/uni-applet form …...

Pointnet++改进即插即用系列:全网首发WTConv2d大接受域的小波卷积|即插即用,提升特征提取模块性能
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入WTConv2d,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3 步骤三 1.理…...
4核16G服务器支持多少人?4C16G服务器性能测评
租赁4核16G服务器费用,目前4核16G服务器10M带宽配置70元1个月、210元3个月,那么能如何呢?配置为ECS经济型e实例4核16G、按固定带宽10Mbs、100GB ESSD Entry系统盘。 那么问题来了,4C16G10M带宽的云服务器可以支持多少人同时在线&…...

塔子哥的平均数-美团2023笔试(codefun2000)
题目链接 塔子哥的平均数-美团2023笔试(codefun2000) 题目内容 给定一个正整数数组a1 ,a2 ,…,an,求平均数正好等于k的最长连续子数组的长度 输入描述 输出描述 输出一个整数,表示最长满足题目条件的长度。 样例1 输入 5 2 1 3 2 4 1 输出 3 样例1解释…...

故障诊断 | 基于小波包能量谱对滚动轴承的故障诊断Matlab代码
故障诊断 | 基于小波包能量谱对滚动轴承的故障诊断Matlab代码 目录 故障诊断 | 基于小波包能量谱对滚动轴承的故障诊断Matlab代码效果一览基本介绍程序设计参考资料 效果一览 基本介绍 基于小波包能量谱对滚动轴承的故障诊断 matlab代码 数据采用的是凯斯西储大学数据 首先利用…...

E14.【C语言】练习:有关短路运算
#include <stdio.h> int main() {int i 0,a0,b2,c 3,d4;i a && b && d;printf("a %d\nb %d\nc %d\nd %d\n", a, b, c, d);return 0; } 求输出结果 分析: a:先使用后 ,a(见第15篇http://…...

python BeautifulSoup库安装与使用(anaconda、pip)
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。Beautiful Soup 已成为和 lxml、html5lib 一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。 Requests 获取html BeautifulSoup 解析html、xml,BeautifulSoup4库也称bs4库 安装B…...

打造清爽高效的Android优化工具:Universal Android Debloater样式系统全解析
打造清爽高效的Android优化工具:Universal Android Debloater样式系统全解析 【免费下载链接】universal-android-debloater Cross-platform GUI written in Rust using ADB to debloat non-rooted android devices. Improve your privacy, the security and batter…...

Phi-4-reasoning-vision-15B多场景落地:从办公文档处理到工业质检界面分析
Phi-4-reasoning-vision-15B多场景落地:从办公文档处理到工业质检界面分析 1. 引言:当AI学会“看图说话”与“看图思考” 想象一下,你手头有一份复杂的财务报表PDF,里面全是密密麻麻的数字和图表,你需要快速提取关键…...

双向DC/DC变换器 buck-boost变换器仿真 输入侧为直流电压源,输出侧接蓄电池
双向DC/DC变换器 buck-boost变换器仿真 输入侧为直流电压源,输出侧接蓄电池 模型采用电压外环电流内环的双闭环控制方式 正向运行时电压源给电池恒流恒压充电,反向运行时电池放电维持直流侧电压稳定 matlab/simulink双向Buck-Boost变换器是一种经典的DC/…...

Legion 9笔记本风扇控制功能异常问题深度解析与解决
Legion 9笔记本风扇控制功能异常问题深度解析与解决 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 如何定位Legion 9风扇控…...

RexUniNLU效果展示:同一段政府公告文本的11种NLP任务结构化输出
RexUniNLU效果展示:同一段政府公告文本的11种NLP任务结构化输出 1. 系统概览:一站式中文NLP分析利器 RexUniNLU是一个基于ModelScope DeBERTa Rex-UniNLU模型的全功能中文自然语言处理系统。这个系统的最大特点是能够用同一个模型处理十多种不同的NLP任…...

Yakit渗透工具实战:Windows环境下的5个高效插件组合与使用技巧
Yakit渗透工具实战:Windows环境下的5个高效插件组合与使用技巧 在渗透测试的实战场景中,工具的高效组合往往能带来事半功倍的效果。Yakit作为一款新兴的单兵渗透工具,凭借其轻量化和插件化设计,正在成为安全从业者的新宠。本文将聚…...

MouseTester:量化鼠标性能的专业检测方案
MouseTester:量化鼠标性能的专业检测方案 【免费下载链接】MouseTester 项目地址: https://gitcode.com/gh_mirrors/mo/MouseTester 一、核心价值:从用户痛点到专业解决方案 1.1 三大核心用户的真实痛点 电竞选手面临的关键挑战:在…...

ChatGPT出现Unable to Load Site错误的排查与修复指南
上周,我们团队的一个内部工具突然“罢工”了。这个工具的核心功能是调用一个类似ChatGPT的AI对话接口,为客服系统生成智能回复。那天下午,前端页面突然弹出了刺眼的“Unable to Load Site”错误,整个智能回复功能瞬间瘫痪。客服团…...
)
Datagrip连接人大金仓避坑指南:解决‘column t does not exist‘报错(附驱动jar下载)
Datagrip连接人大金仓实战指南:从驱动配置到SQL优化全解析 最近在协助团队迁移数据库系统时,发现不少开发者在使用Datagrip连接人大金仓(Kingbase)数据库时遇到了各种"水土不服"的问题。特别是那个神秘的"column t does not exist"报…...
)
第7章:Docker network网络管理(网络模式和创建docker网络)
第7章:Docker network网络管理(网络模式和创建docker网络) 7.2、Docker网络模式 Docker 服务安装完成之后,默认在每个宿主机会生成一个名称为 docker0 的网卡其 IP 地址都是 172.17.0.1/16。 每次新建一个容器后,宿主机就会多了个虚拟网卡,与容器的网卡组合成一个网卡,例…...