Redis 深度历险:核心原理与应用实践 - 读书笔记
目录
- 第一章 基础应用篇
- Zset
- 并发问题 - 分布式锁
- 再谈分布式锁
- 客户端在请求时加锁失败策略
- redis异步队列
- 位图
- Hyperloglog
- 布隆过滤器
- GeoHash
- scan 命令
- 字典结构
- rehash扩容
- 大 key 扫描
- 第二章 原理篇
- 线程IO模型
- RESP 序列化协议
- 持久化
- 管道
- 事务
- PubSub
- 内存管理
- 第三章 集群篇
- CAP
- 主从同步
- 快照同步
- 哨兵
- Cluster
- 拓展篇
- Stream
- 过期策略
- 从节点过期策略
- 淘汰策略
- 近似LRU
- 异步线程
- redis安全通信 - spiped
第一章 基础应用篇
Zset
zset 内部的排序功能是通过 “跳表” 数据结构来实现的
list 、set 、hash 、zset 这四种数据结构是容器型数据结构,它们共享下面两条通用规则。
1.create if not exists:如果容器不存在,那就创建一个,再进行操作。比如 rpush 操作刚开始是没有列表的, Redis 就会自动创建一个,然后再 rpush 进去新元素。
2.drop if no elements:如果容器里的元素没有了,那么立即删除容器,释放内存。这意昧着 lpop 操作到最后一个元素,列表就消失了。
如果一个字符串已经设置了过期时间,然后又调用 set 方法修改了它,它的过期时间会消失。
并发问题 - 分布式锁
分布式锁本质上要实现的目标就是在 Redis 里面占一个"坑",当别的进程也要来占坑时,发现那里已经有一根"大萝卡"了,就只好放弃或者稍后再试。setnx来占,用完了调用 del 指令释放"坑"。
> setnx lock:xxx true
OK
do something critical
> del lock:xxx
(Integer) 1
问题1:如果逻辑执行到中间出现异常了,可能会导致 del指令没有被调用,这样就会陷入死锁,锁永远得不到释放。
解决1:拿到锁之后,再给锁加上一个过期时间,比如5s,这样即使中间出现异常也可以保证 5s 之后锁会自动释放。
> setnx lock : xxx true
OK
> expire lock:xxx 5
do something critical
> del lock : xxx
(integer) 1
问题2:如果在 setnx 和 expire 之间服务器进程突然挂掉了,就会导致 expire 得不到执行,也会造成死锁。
解决2:这种问题的根源就在于 setnx和 expire 是两条指令而不是原子指令。如果这两条
指令可以一起执行就不会出现问题。在 Redis 2.8 版本中,引了 set 指令的扩展参数,使
得 setnx 和 expire 指令可以一起执行,这也是分布式锁的奥义所在 。
> set lock:xxxtrue ex 5 nx
OK
do something critical
> del lock:xxx
问题3:Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行得太长,以至于超出了锁的超时限制,就会出现问题 。 因为这时候第一个线程持有的锁过期了,临界区的逻辑还没有执行完,而同时第二个线程就提前重新持有了这把锁,导致临界区代码不能得到严格串行执行 。
解决3:将 set 指令的 value 参数设置为一个随机数,释放锁时先匹配随机数是否一致,然后再删除 key,确保当前线程占有的锁不会被其他线程释放。
问题4:匹配 value 和删除 key 不是一个原子操作,
解决4:使用 Lua 脚本来处理了,因为 Lua 脚本可以保证连续多个指令的原子性执行。
问题5:但是这也不是一个完美的方案 , 它只是相对安全一点 , 因为如果真的超时了,当前线程的逻辑没有执行完,其他线程也会乘虚而入。
可重入性是指线程在持有锁的情况下再次请求加锁,如果一个锁支持同一个线程的多次加锁 , 那么这个锁就是可重入的。 比如 Java 语言里有个 ReentrantLock 就是可重入锁。
再谈分布式锁
问题:在 Sentinel 集群中,当主节点挂掉时,从节点会取而代之,此时这种set nx方式是有缺陷的。
如果第一个客户端在主节点中申请成功了一把锁,但是这把锁还没有来得及同步到从节点,主节点突然挂掉了,然后从节点变成了主节点,这个新的主节点内部没有这个锁,所以当另一个客户端过来请求加锁时,就会批准。这样就会导致系统中同样一把锁被两个客户端同时持有,不安全性由此产生。
不过这种不安全也仅在主从发生 failover 的情况下才会产生,而且持续时间极短,业务系统多数情况下可以容忍。
解决:Redlock。使用 Redlock需要提供多个 Redis 实例,这些实例之前相互独立,没有主从关系。加锁时,它会向过半节点发送 set(key, value, nx=True, ex=xx)指令,只要过半节点 set 成功,就认为加锁成功。释放锁时,需要向所有节点发送 de!指令。不过Redlock 算法还需要考虑出错重试、时钟漂移等很多细节问题,同时因为 Redlock 需要向多个节点进行读写,意昧着其相比单实例 Redis 的性能会下降一些。
客户端在请求时加锁失败策略
1.直接抛出异常,通知用户稍后重试。
直接抛出特定类型的异常
这种方式比较适合由用户直接发起的请求。用户看到错误对话框后,会先阅读对话框的内容,再点击重试,这样就可以起到人工延时的效果。如果考虑到用户体验,可以由前端的代码替代用户来进行延时重试控制。它本质上是对当前请求的放弃,由用户决定是否重新发起新的请求。
2.sleep 会儿,然后再重试。
sleep 会阻塞当前的消息处理线程,会导致队列的后续消息处理出现延迟 。如果碰撞得比较频繁或者队列里消息比较多, sleep 可能并不合适。如果因为个别死锁的key 导致加锁不成功,线程会彻底堵死,导致后续消息永远得不到及时处理 。
3.将请求转移至延时队列,过一会儿再试 。
这种方式比较适合异步消息处理,将当前冲突的请求扔到另一个队列延后处理以避开冲突。
延时队列的实现:
延时队列可以通过 Redis 的 zset (有序列表)来实现。我们将消息序列化成一个字符串作为 zset 的 value,这个消息的到期处理时间作为 score,然后用多个线程轮询zset 获取到期的任务进行处理 。多个结程是为了保障可用性,万一挂了一个线程还有其他线程可以继续处理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不会被多次执行。
retry_ts =time.time() + 5 # 5s 后重试
redis . zadd (” delay- queue ”, retry_ts, value)
values = redis. zrangebyscore (” delay-queue ”, 0 , time.time() , start=0 , num=1)
# 检查 "delay-queue" 集合中是否有元素的分数小于或等于当前时间戳,拿出第一个,0-time.time分数范围# 从消息队列中移除该消息
success = redis. zrem (” delay-queue”, value)
if success:
# 因为有多进程并发的可能 , 最终只会有一个进程可以抢到消息msg = json . loads(value)
Redis 的 zrem 方法是多线程多进程争抢任务的关键,它的返回值决定了当前实例有没有抢到任务,因为方法可能会被多个线程、多个进程调用,同一个任务可能会被多个进程、多个线程抢到,要通过 zrem 来决定唯一的属主。
redis异步队列
Redis 的 list列表数据结构常用来作为异步消息队列使用 , 用 rpush 和 lpush操作入队列,用 lpop 和 rpop 操作出队列
问题1:客户端通过队列的 pop 操作来获取消息,然后进行处理。处理完了再接着获取消息,再进行处理。如此循环,这便是作为队列消费者的客户端的生命周期。可是如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop,没有数据,接着再 pop,还没有数据。这就是浪费生命的空轮询。空轮询不但拉高了客户端的CPU 消耗, Redis 的 QPS 也会被拉高,如果这样空轮询的客户端有几十个, Redis 的慢查询可能会显著增多。
解决1:通常我们使用 sleep 来解决这个问题,让线程睡一会,睡个 1s 就可以了。不但客户端的 CPU 消耗能降下来, Redis 的 QPS 也降下来了 。
问题2:但是又有个问题,那就是睡眠会导致消息的延迟增大。如果只有 1 个消费者,那么这个延迟就是 ls。如果有多个消费者,这个延迟会有所下降,因为每个消费者的睡眠时间是岔开的。
有什么办法能显著降低延迟呢?
解决2:睡眠的时间缩短点。这种方法当然可以,不过有没有更好的解决方案呢?当然也有,那就是 blpop/brpop 。这两个指令的前缀字符 b 代表的是 blocking,也就是阻塞读。阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。用blpop/brpop 替代前面的 lpop/rpop,就完美解决了上面的问题。
位图
在我们平时的开发过程中,会有一些 bool 型数据需要存取,比如用户 年的签到记录,签了是 1 ,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户数上亿的时候,需要的存储空间是惊人的。为了解决这个问题, Redis 提供了位图数据结构,这样每天的签到记录只占据一个位, 365 天就是 365 个位, 46 个字节(一个稍长一点的字符串)就可以完全容纳下,这就大大节约了存储空间。位图的最小单位是比特( bit ),每个 bit 的取值只能是 0 或 1,位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。
> bin(ord ('h'))
'0b1101000'
127.0.0.1:6379> setbit s 1 1
(integer) 0
127.0.0.1:6379> setbit s 2 1
(integer) 0
127.0.0.1:6379> setbit s 4 1
(integer) 0
127.0.0.1:6379> get s
"h"
通过 bitcount 统计用户一共签到了多少天,通过 bitpos 指令查找用户从哪天开始第一次签到 。如果指定了范围参数 [start, end] ,就可以统计在某个时间范围内用户签到了多少天,用户自某天以后的哪天开始签到。
遗憾的是, start 和 end 参数是字节索引,也就是说指定的位范围必须是 8 的倍
数,而不能任意指定。这很奇怪,老钱不能理解 Antirez 为什么要这样设计。因为
这个设计 , 我们无法直接计算某个月内用户签到了多少天,而必须将这个月所覆盖
的字节内容全部取出来( getrange 可以取出字符串的子串),然后在内存里进行统计,
这非常烦琐。
127.0.0.1 : 6379> set w hello
OK
127.0.0.1 : 6379> bitcount w
(integer) 21
127.0.0.1 : 6379> bitcount w 0 0 #第一个字符 中 1 的位数
(integer ) 3
127.0.0.1 : 6379> bitcount w 0 1 #前两个字符 中 l 的位数
(integer ) 7
Hyperloglog
UV 是 “Unique Visitors” 的缩写,中文意思是 “独立访客”。在网站分析中,UV 指的是在一定时间范围内(通常是一天)访问网站的不重复的访客数量。如果一个人在同一天内多次访问同一个网站,他仍然只被计算为一个 UV,也就是同一个用户一天之内的多次访问请求只能计数一次。
一个简单的方案就是为每一个页面设置一个独立的 set 集合来存储所有当天访问过此页面的用户ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。但是,如果页面访问量非常大,比如一个爆款页面可能有几千万个 UV,就需要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。
r.sadd(page1_set, user_id)
HyperLogLog 提供不精确的去重计数方案,虽然不精确,但是也不是非常离谱,标准误差是 0 . 81%,
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字面意思很好理解,一个是增加计数,一个是获取计数。 pfadd 和 set 集合的 sadd 的用法是一样的,来一个用户 ID,就将用户 ID 塞进去就是。pfcount 和 scard 的用法是一样的,直接获取计数值。
127.0.0.1 : 6379> pfadd codehole user1
(integer) 1
127.0.0.1 : 6379> pfcount codehole
(integer) 1
127.0.0.1 :6379> pfadd codehole user2
(integer) 1
127.0.0.1 :6379> pfcount codehole
(integer) 2
pfmerge,用于将多个 pf 计数值累加在一起形成一个新的 pf 值。
注意事项
HyperLogLog 这个数据结构不是免费的 。这倒不是说使用这个数据结构要花钱 ,而是因为它需要占据 12KB的存储空间,所以不适合统计单个用户相关的数据。如果用户有上亿个,可以算算,这个空间成本是非常惊人的。但是相比 set 存储方案,HyperLogLog 所使用的空间那就只能算九牛之一毛了 。不过你也不必过于担心,因为 Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大、稀疏矩阵占用空间渐渐超过了阎值时,才会一次性转变成稠密矩阵,才会占用 12KB的空间。
一句话收尾:HyperLogLog 能解决很多精确度要求不高的统计问题。
布隆过滤器
HyperLogLog 数据结构来进行估数。但是如果我们想知道某一个值是不是已经在 HyperLogLog 结构里面了,它就无能为力了。
讲个使用场景,比如我们在看抖音时,它会给我们不停地推荐新的内容,而它每次推荐时都要去重,以去掉那些我们已经看过的内容。那么问题来了,抖音推荐系统是如何实现推送去重的?你可能会想到:服务器已经记录了用户看过的所有历史记录,当推荐系统推送短视频时可以从每个用户的历史记录里进行筛选,以过滤掉那些已经存在的记录。问题是,当用户量很大、每个用户看过的短视频又很多的情况下,使用这种方式,推荐系统的去重工作在性能上能跟得上吗?
实际上,如果历史记录存储在关系数据库里,去重就需要频繁地对数据库进行exists 查询,当系统并发量很高时,数据库是很难扛住压力的。你可能又想到了缓存,但是将如此多的历史记录全部缓存起来,那得浪费多大存储空间啊?而且这个存储空间是随着时间线性增长的,就算你撑得住一个月,你
能撑得住几年吗?但是不缓存的话,性能又跟不上,这该怎么办?
高级数据结构布隆过滤器闪亮登场了,它就是专门用来解决这种去重问题的。它在起到去重作用的同时,在空间上还能节省 90%以上,只是会有一定的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在:当它说某个值不存在时,那就肯定不存在。打个比方,当它说不认识你时,肯定就是真的不认识;而当它说认识你时,却有可能根本没见过你,只是因为你的脸跟它认识的某人的脸比较相似(某些熟脸的系数组合),所以误判以前认识你。布隆过滤器对于已经见过的元素肯定不会误判,它只会误判那些没见过的元素
套在上面的使用场景中,布隆过滤器能准确过滤掉那些用户已经看过的内容,那些用户没有看过的新内容,它也会过滤掉极小一部分(误判) ,但是绝大多数新内容它都能准确识别。这样就可以保证推荐给用户的内容都是无重复的。
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布
隆过)洁、器作为一个插件加载到 Redis Server 中
布隆过)洁、器有两个基本指令, bf.add 和 bf.exists 。 bf.add 添加元素, bf.exists 查询
元素是否存在
127 . 0.0.1:6379> bf.add codehole userl
(integer) 1
127 . 0 . 0.1:6379> bf.add codehole user2
(integer) 1
127.0.0.1:6379> bf.exists codehole userl
(integer) 1
127.0.0.1:6379> bf.exists codehole user2
(工 nteger) 1
127.0.0.1:6379> bf.exists codehole user3
(integer) 0
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash,算得一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置 ,再把位数组的这几个位置都置为 1 ,就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1 , 只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果这几个位置都是 1 ,并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其他的 key 存在所致。如果这个位数组比较稀疏,判断正确的概率就会很大,如果这个位数组比较拥挤,判断正确的概率就会降低。
布隆过滤器器可以显著降低数据库的 IO 请求数量 。 当用户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后再去磁盘进行查询 。
免费的在线布隆空间占用计算器,地址是 htφs:收risives . github.io/bloomcalculator 。
GeoHash
我们可以使用 Redis 来实现类似单车的“附近的单车”、美团“附近的餐馆 ” 这样的功能了。
地图元素的位置数据使用二维的经纬度表示。
在使用 Redis 进行 Geo 查询时,我们要时刻想到它的内部结构实际上只是一个zset (skiplist)。通过 zset 的 score 排序就可以得到坐标附近的其他元素(实际情况要复杂一些,不过这样理解足够了),通过将 score 还原成坐标值就可以得到元素的原始坐标。
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
geodist 指令可以用来计算两个元素之间的距离,携带集合名称、两个名称和距离单位。
127.0.0.1 : 6379> geodist company juejin ireader km # km是千米
"10.5501"
georadiusbymember 指令是最为关键的指令之一 , 它可以用来查询指定元素附近
的其他元素, 它的参数非常复杂
# 范围 20 公里以内最多 3 个元素按距离正排,它不会排除自身
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 asc
1)”ireader”
2)”juejin”
3)”meituan"
根据坐标值来查询附近的元素的指令 georadius,这个指令更加有用,它可以根据用户的定位来计算“附近的车”“附近的餐馆”等。它的参数和 georadiusbyrnernber 基本一致,唯一的差别是将目标元素改成经纬度坐标值。
127.0.0.1:6379> georadius company 116.514202 39.905409 20 km withdist count 3 asc
1) 1)”ireader"2)” 0.000”
2) 1)” juejin”2) ” 10.5501 ”
3) 1) ” meituan ”2) “ 11.5748”
scan 命令
在平时线上 Redis 维护工作中,有时候需要从 Redis 实例的成千上万个 key 中找出特定前缀的 key 列表来手动处理数据,可能是修改它的值,也可能是删除 key 。这里就有 个问题 , 如何从海量的 key 中找出满足特定前缀的 key 列表?
Redis 提供了 一个简单粗暴的指令 keys 用来列出所有满足特定正则字符串规则的 key 。
127.0 . 0 . 1:6379> set codeholel a
OK
127.0 . 0 . 1:6379> set codehole2 b
OK
127.0 . 0 . 1:6379> set codehole3 c
OK
127.0.0.1:6379> keys *
1) ” codeholel ”
2 ) ” code3hole "
3 ) ” codehole3 ”
缺点:
1.没有 offset 、limit 参数,一次性吐出所有满足条件的 key ,万一实例中有几百万个 key 满足条件,满屏的字符串,刷屏没有尽头时,你就知道难受了。
2.keys 算法是遍历算法,复杂度是 O(n). 因为 Redis 是单线程程序,顺序执行所有指令,其他指令必须等到当前的 keys指令执行完了才可以继续。
scan提供 limit 参数,可以控制每次返回结果的最大条数(控制查询的槽数量)。复杂度虽然也是O(n),但它是通过游标分步进行的,不会阻塞线程 。
# scan 0 游标从0开始, limit 1000 表示限定服务器单次遍历的字典槽位数量。
127.0.0.1:6379> scan 0 match key99* count 1000
1 ) ” 13976” # 下次scan就从13976开始,直到返回的是0. 游标值不为零,意昧着遍历还没结束。
2) 1)” key9911 ”2)” key9974 ”3) ” key9994 ”4)” key991 。 ”5) ” key9907 ”6) ” key9989 ”7) ” key9971 ”8) ” key99 ”9) ” key9966 ”10)” key992 ”11)” key9903 ”12) ” key9905 ”
字典结构
在 Redis 中所有的 key 都存储在一个大字典中,这个字典的结构和 Java 中的HashMap 一样,它是一维数组,数组里每个元素下挂着链表结构。
scan 指令返回的游标就是第一维数组的位置索引,我们将这个位置索引称为槽( slot )。如果不考虑字典的扩容缩容,直接按数组下标按个遍历就行了。 limit 参数就表示需要遍历的槽位数,之所以返回的结果可多可少,是因为每个槽位上挂的链表元素不同, 有些槽位可能是空的。每一次遍历都会将 limit 数量的槽位上挂接的所有链表元素进行模式匹配过滤后,一次性返回给客户端.
scan 的遍历顺序非常特别。它不是从第一维数组的第 0 位 直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
rehash扩容
Java 的 HashMap 在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面 。如果 HashMap 中元素特别多,线程就会出现卡顿现象 。 Redis 为了解决这个问题,采用" 渐进式 rehash "。
它会同时保留旧数组和新数组,然后在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂的元素迁移到新数组上。这意昧着要操作处于 rehash 中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面寻找。
大 key 扫描
redis - cli - h 127.0.0.1 - p 7001 -bigkeys
第二章 原理篇
线程IO模型
Redis、Node.js、Nginx 都是单线程程序 !
Redis 会将每个客户端套接字都关联一个指令队列,客户端发出的指令通过指令队列来顺序处理,先到先服务。
Redis 同样也会为每个客户端套接字关联一个响应队列,Redis 服务器通过响应队列来将指令的返回结果回复给客户端。
Redis 的定时任务会记录在一个被称为"最小堆"的数据结构中。在这个堆中,最快要执行的任务排在堆的最上方。
RESP 序列化协议
Redis 协议将传输的结构数据分为 5 种最小单元类型,单元结束时统一加上回车换行符号 \r\n。
1.单行字符串以“+”符号开头。
2.多行字符串以“$”符号开头,后跟字符串长度 。
3.整数值以“:”符号开头,后跟整数的字符串形式 。
4.错误消息以“-”符号开头。
5.数组以“*”号开头,后跟数组的长度 。
客户端向服务器发送的指令只有一种格式,多行字符串数组。比如一个简单的set 指令 set author codehole 会被序列化成下面的字符串 。
*3\r\n$3\r\nset\r\n$6\r\nauthor\r\n$8\r\ncodehole\r\n
控制台输出:
*3
$3
set
$6
author
$8
Codehole
服务器向客户端回复的响应要支持多种数据结构,所以消息响应在结构上要复杂不少,不过再复杂的响应消息也是以上 5 种基本类型的组合。
持久化
Redis 的持久化机制有两种,第一种是快照,第二种是 AOF 日志。
快照是一次全量备份, AOF 日志是连续的增量备份。
快照是内存数据的二进制序列化形式,在存储上非常紧凑。AOF 日志记录的是内存数据修改的指令记录文本。
单个 Redis 的内存不宜过大,内存太大会导致 rdb 文件过大,进一步导致主从同步时全量同步时间过长,在实例重启恢复时也会消耗很长的数据加载时间
为了不阻塞线上的业务, Redis 需要一边持久化,一边响应客户端的请求。持久化的同时,内存数据结构还在改变,比如一个大型的 hash 字典正在持久化,结果一个请求过来把它给删掉了,可是还没持久化完呢,这该怎么办呢?
Redis 使用操作系统的多进程Copy On Write 机制来实现快照持久化。
Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这是 Linux 操作系统的机制,为了节约内存资源,所以尽可能让它们共享。在进程分离的瞬间,内存的增长几乎没有明显变化。
fork 函数会在父子进程同时返回,在父进程里返回子进程的 pid,在子进程里返回零。
子进程做数据持久化,不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到碰盘中。但是父进程不一样,它必须持续服务客户端请求,然后对内存数据结构进行不间断的修改。
父进程不一样,持续服务客户端请求然后对内存数据结构进行修改。这个时候就会使用操作系统的 cow 机制来进行数据段页面的分离。数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复制一份分离出来,然后对这个复制的页面进行修改,每个页面的大小只有 4KB。子进程因为数据没有变化,它能看到的内存里的数据在进程产生的一瞬间就凝固不会变化,这也是为什么 Redis 的持久化叫“快照”的原因。接下来子进程就可以非常安心地遍历数据,进行序列化写磁盘了。
redis AOF先执行指令才将曰志存盘。 而leveldb 、hbase 等存储引擎,它们都是先存储曰志再做逻辑处理。
问题:当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回磁盘的。这就意昧着如果机器突然宕机, AOF 日志内容可能还没有来得及完全刷到磁盘中,这个时候就会出现日志丢失。
解决:Linux 的 glibc 提供了 fsync(int 但)函数可以将指定文件的内容强制从内核缓存刷到磁盘。只要 Redis 进程实时调用 fsync 函数就可以保证 AOF 日志不丢失。但是fsync 是一个磁盘 IO 操作,它很慢!
所以在生产环境的服务器中, Redis 通常是每隔 1s 左右执行一次 fsync 操作
Redis 的主节点不会进行持久化操作,持久化操作主要在从节点进行。从节点是备份节点,没有来自客户端请求的压力。
管道
管道技术本质上是由客户端提供的,跟服务器没有什么直接的关系。
客户端:请求–得到响应 --请求 – 得到响应(其实就是写-读-写-读)
调整读写顺序,改成写-写-读-读,两个连续的写操作和两个连续的读操作总共只会花费一次网络来田,这就是管道操作的本质。客户端通过对管道中的指令列表改变读写顺序就可以大幅节省 IO 时间。管道中指令越多,效果越好。
服务器根本没有任何区别对待,还是收到一条消息、执行一条消息、回复一条消息的正常流程。
我们以为:write 操作是要等到对方收到消息后才会返回。
实际上:write 操作只负责将数据写到本地操作系统内核的发送缓冲区中,然后就返回了。剩下的事交给操作系统内核异步将数据送到目标机器。(但是如果发送缓冲满了,那么就需要等待缓冲空出空闲空间来,这个就是写操作 IO 操作的真正耗时。)
我们以为:read 操作是从目标机器拉取数据,
实际上:read 操作只负责将数据从本地操作系统内核的接收缓冲区中取出。(但是如果缓冲是空的,那么就需要等待数据到来,这个就是 read 操作 IO 操作的真正耗时。)
所以对于 value = redis.get(key)这样一个简单的请求来说, write 操作几乎没有耗时,直接写到发送缓冲中就返回,而 read 就比较耗时了,因为它要等待消息经过网络路由到目标机器处理后的响应消息,再回送到当前的内核读缓冲才可以返回,这才是一个网络来回的真正开销。
而对于管道来说,连续的 write 操作根本就没有耗时,之后第一个 read 操作会等待一个网络的来回开销,然后所有的响应消息就都已经送回到内核的读缓冲了,后续的 read 操作直接就可以从缓冲中拿到结果,瞬间就返回了。
事务
每个事务的操作指令都有 begin 、commit 、rollback, 对应到redis里就是 multi 、exec 、discard。
> multi
OK
> incr books
QUEUED
> incr books
QUEUED
> exec
(integer) 1
(integer) 2
所有的指令在 exec 之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到exec 指令,才开始执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。
事务在遇到指令执行失败后,后面的指令还会继续执行。所以 Redis 的事务不具备"原子性",仅仅是满足了事务的"隔离性"中的串行化–当前执行的事务有着不被其他事务打断的权利。
Redis 事务在发送每个指令到事务缓存队列时都要经过一次网络读写,当一个事务内部的指令较多时,需要的网络 IO 时间也会线性增长,所以通常 Redis的客户端在执行事务时都会结合 pipeline 一起使用,这样可以将多次 IO 操作压缩为单次 IO 操作。比如我们在使用 Python 的 Redis 客户端执行事务时是要强制使用pipeline 的 。
pipe = redis.pipeline(transaction=true)
pipe.multi ()
pipe.incr (”books ” )
pipe.incr (” books ” )
values = pipe.execute()
分布式锁是一种悲观锁,watch机制是一种乐观锁
PubSub
消息多播允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由相应的消费组进行消费。redis单独使用了个模块来支持消息多播,这个模块的名字叫作 PubSub。
内存管理
Redis 如果使用 32bit 进行编译,内部所有数据结构所使用的指针空间占用会少一半,如果你的 Redis 使用内存不超过 4GB,可以考虑使用 32bit 进行编译,能够节约大量内存。
如果 Redis 内部管理的集合数据结构很小,它会使用紧凑存储形式压缩存储。
如果当前 Redis 内存有 10GB ,当删除了 1GB 的 key 后再去观察内存,会发现内存变化不会太大。原因是操作系统是以页为单位来回收内存的, Redis 虽然删除了 1GB 的 key,但是这些 key 分散到了很多页面中,这个页上只要还有一个 key 在使用,那么它就不能立即被回收。如果执行 flushdb ,内存会立刻被回收了,原因是所有的 key 都被干掉了。
Redis 虽然无法保证立即回收已经删除的 key 的内存,但是它会重新使用那些尚未回收的空闲内存。
Redis 为 了保持自身结构的简单性,在内存分配方面直接做了甩手掌柜,将内存分配的细节丢给了第三方内存分配库去实现(默认使用facebook的 jemalloc)。
第三章 集群篇
CAP
C : Consistent , 一致性
A : Availability , 可用性
P : Partition tolerance ,分区容忍性
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的, 这意味着必然会有网络断开的风险, 这个网络断开的场景的专业词汇叫作网络分区 。
在网络分区发生时,两个分布式节点之间无法进行通信,我们对一个节点进行的修改操作将无法同步到另外一个节点,所以数据的一致性将无法满足 。
如果我们在在网络分区发生时暂停节点服务,不再提供修改数据的功能,那可用性将无法满足。
用一句话概括 CAP 原理就是 : 当网络分区发生时 , 一致性和可用性两难全 。
当客户端在 Redis 的主节点修改了数据后,立即返回, 即使在主从网络断开的情况下,主节点依旧可以正常对外提供修改服务, 所以 Redis 满足可用性 。
Redis 保证最终一致性, Redis 的主从数据是异步同步的,从节点会努力追赶主节点, 最终从节点的状态会和主节点的状态保持一致。
主从同步
Redis 同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一样的状态,一边向主节点反馈自己同步到哪里了(偏移量〉 。因为内存的 buffer 是有限的,所以 Redis 主节点不能将所有的指令都记录在内存 buffer中 。 Redis 的复制内存 buffer是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容 。
如果因为网络状况不好,从节点在短时间内无法和主节点进行同步,那么当网络状况恢复肘, Redis 的主节点中那些没有同步的指令在buffer 中有可能已经被后续的指令覆盖掉了,从节点将无法直接通过指令流来进行同步,这个时候就需要用到更加复杂的同步机制一一快照同步。
快照同步
快照同步是个非常耗费资源的操作,它首先需要在主节点上进行一次 bgsave,将当前内存的数据全部快照到磁盘文件中,然后再将快照文件的内容全部传送到从节点 。
从节点将快照文件接受完毕后,立即执行一次全量加载,加载之前先要将当前内存的数据清空,加载完毕后通知主节点继续进行增量同步 。
在整个快照同步进行的过程中,主节点的复制 buffer 还在不停地往前移动,如果快照同步的时间过长或者复制 buffer 太小,都会导致同步期间的增量指令在复制buffer 中被覆盖,这样就会导致快照同步完成后无法进行增量复制,然后会再次发起快照同步,如此极有可能会陷入快照同步的死循环。
当从节点刚刚加入到集群时,它必须先进行一次快照同步,同步完成后再继续进行增量同步。
Redis 支持无盘复制。所谓无盘复制是指主服务器直接通过套接字将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内存,一边将序列化的内容发送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中,再进行一次性加载。
wait 指令可以让Redis的异步复制变成同步复制,确保系统的强一致性。
wait 1 0
# 等待 wait 指令之前的所有写操作同步到 N 个从节点
# 最多等待时间 t。 如果时间 t=O , 表示无限等待直到 N 个从节点同步完成 。
哨兵
客户端来连接集群时,会首先连接 Sentinel , 通过 Sentinel来查询主节点的地址,然后再连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 Sentinel 要地址, Sentinel 会将最新的主节点地址告诉客户端,这样应用程序将无须重启即可自动完成节点切换 。
Redis 主从采用异步复制,意昧着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息就丢失了。Sentinel 无法保证消息完全不丢失,但是也能尽量保证消息少丢失。
它有两个选项可以限制主从延迟过大。
# 主节点必须至少有一个从节点在进行正常复制,否则就停止对外写服务,丧失可用性。
min-slaves-to-write 1
# 怎么定义正常复制和异常复制?第二个参数控制,单位是秒。如果在 10s 内没有收到从节点反馈,就意味着从节点同步不正常
min-slaves-max- lag 10
Sentinel 的默认端口是 26379
从地址有多个,Redis 客户端默认采用轮询方案
问题:当 Sentinel 进行主从切换时,客户端如何知道地址变更了?
解决:redis-py 在建立连接的时候进行了主节点地址变更判断。连接池建立新连接肘,会去查询主节点地址,然后跟内存中的主节点地址进行比对,如果变更了,就断开所有连接,重新使用新地址建立新连接。如果是旧的主节点挂掉了,那么所有正在使用的连接都会被关闭,然后在重连时就会用上新地址。
问题2:如果是 Sentinel 主动进行主从切换的,但主节点并没有挂掉,而之前的主节点连接已经建立了且在使用中,没有新连接需要建立,那么这个连接是不是一直切换不了?
解决2:在处理命令的时候捕获了一个特殊的异常 ReadOnlyError,在这个异常里将所有的旧连接
全部关闭了,后续指令就会进行重连。主从切换后,之前的主节点被降级为从节点,所有的修改性的指令都会抛出ReadonlyError。如果没有修改性指令,虽然连接不会得到切换,但是数据不会被破坏,
所以即使不切换也没关系。
Cluster
Redis Cluster是去中心化的,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样,它们之间通过一种特殊的二进制协议交互集群信息。
Redis Cluster 将所有数据划分为 16384 个槽位,每个节点负责其中一 部分槽位。槽位的信息存储于每个节点中,当 Redis Cluster 的客户端来连接集群时,也会得到并缓存一份集群的槽位配置信息 。这样当客户端要查找某个 key 时,可以直接定位到目标节点。
另外, Redis Cluster 的每个节点会将集群的配置信息持久化到配置文件中,所以必须确保配置文件是可写的 , 而且尽量不要依靠人工修改配置文件。
Redis Cluster 默认会对 key 值使用哈希算法进行 hash,得到一个整数值,然后用这个整数值对 16 384 进行取模来得到具体槽位。
Redis Cluster 允许用户强制把某个 key 挂在特定槽位上。
如果客户端向一个错误的节点发出了指令后,该节点会发现指令的 key 所在的槽位并不归自己管理, 这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连接这个节点以获取数据。客户端在收到指令后, 要纠正本地的槽位映射表,后续所有 key将使用新的槽位映射表。
拓展篇
Stream
支持多播的可持久化消息队列,借鉴了 Kafka 的设计。
它有一个消息链表,将所有加入的消息都串起来,
每个消息都有个唯一的 ID 和对应的内容,消息 ID 可以由服务器自动生成也可以客户端自己指定,但是形式必须是 “整数 ,
整数” ,而且后面加入的消息的 ID 必须要大于前面的消息 ID 。。 消息是持久化的, Redis 重启后,内容还在。每个 Stream 都可以挂多个消费组( Consumer Group ) , 每个消费组会有个游标
last_delivered_id 在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息
了。每个消费组的状态都是独立的,相互不受影响。
增删改查等指令说明如下。
- xadd : 向 S仕earn 追加消息。
- xdel :从 Stream 中删除消息,这里的删除仅仅是设置标志位,不影响消息总长度。
3 . xrange:获取 S位earn 中的消息列表,会自动过滤已经删除的消息。 - xlen : 获取 Stream 消息长度。
- de!: 删除整个 Stream 消息列表中的所有消息。
# *号表示服务器自动生成ID,后面顺序跟着 key、value
# 名字叫 laoqian ,年龄 30 岁
127.0.0.1:6379> xadd codehole * name laoqian age 30
1527849609889-0 # 生成的消息 ID
127.0.0.1:6379> xadd codehole *name xiaoyu age 29
1527849629172-0
过期策略
Redis 会将每个设置了过期时间的 key 放入一个独立的字典中。
1、定时策略遍历这个字典来删除到期的 key。
2、使用惰性策略来删除过期的key。所谓惰性策略就是在客户端访问这个 key 的时候, Redis 对 key 的过期时间进行检查,如果过期了就立即删除。
定时策略:Redis 默认每秒进行 10 次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略,从过期字典中随机选出 20 个 key。删除这 20 个 key 中已经过期的 key 。
如果过期的 key 的比例超过 1/4 ,那就重复从随机选20个key步骤开始。同时,为了保证过期扫描不会出现循环过度,导致结程卡死的现象,算法还增加了扫描时间的上限,默认不会超过 25ms 。
问题1:当客户端请求到来时,服务器如果正好进入过期扫描状态,客户端的请求将会等待至少25ms 后才会进行处理,如果客户端将超时时间设置得比较短,比如10ms ,那么就会出现大量的链接因为超时而关闭 ,业务端就会出现很多异常,而且这时还无法从 Redis 的 slowlog 中看到慢查询记录,因为慢查询指的是逻辑处理过程慢,不包含等待时间。
解决1:所以业务开发人员一定要注意过期时间,如果有大批量的 key 过期,要给过期时间设置一个随机范围,而不能全部在同一时间过期。
从节点过期策略
从节点不会进行过期扫描,从节点对过期的处理是被动的。主节点在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从节点,从节点通过执行这条 del 指令来删除过期的 key 。
因为指令同步是异步进行的,所以如果主节点过期的 key 的 del 指令没有及时同步到从节点的话,就会出现主从数据的不一致,主节点没有的数据在从节点里还存在,比如上一节的集群环境分布式锁的算法漏洞就是因为这个同步延迟产生的。
淘汰策略
1.noeviction :不会继续服务写请求(del 请求可以继续服务),读请求可以继续进行。这是默认的淘汰策略。
2.volatile-lru : 从设置了过期时间的 key中,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
3.volatile-ttl:跟上面几乎一样,不过淘汰的策略不是 LRU,而是比较 key 的剩余寿命时的值,ttl 越小越优先被淘汰。
4.volatile-random:跟上面几乎一样,不过淘汰的 key 是过期 key 集合中随机的key 。
5.allkeys-lru :区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。
6.allkeys-random:跟上面几乎一样,不过淘汰的 key 是随机的 key 。
volatile-xxx 策略只会针对带过期时间的 key 进行淘汰, allkeys - xxx 策略会对所有的 key 进行淘汰。如果你只是拿 Redis 做缓存,那么应该使用 allkeys-xxx 策略,客户端写缓存时不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用volatile-xxx 策略,这样可以保留没有设置过期时间的 key ,它们是永久的 key ,不会被 LRU 算法淘汰。
近似LRU
Redis 使用的是近似 LRU 算法,它跟 LRU 算法还不太一样。之所以不使用LRU 算法,是因为其需要消耗大量的额外内存,需要对现有的数据结构进行较大的改造。
近似 LRU 算法很简单,在现有数据结构的基础上使用随机采样法来淘汰元素,能达到和 LRU 算法非常近似的效果。 Redis 为实现近似 LRU 算法,给每个 key 增加了一个额外的小字段,这个字段的长度是 24 个 bit,也就是最后一次被访问的时间截。
LRU 淘汰只有懒惰处理。当 Redis 执行写操作时,发现内存超出 rnaxmemory,就会执行一次 LRU 淘汰算法。这个算法也很简单,就是随机采样出 5 (该数量可以设置)个key,然后淘汰掉最旧的key,如果淘汰后内存还是超出 maxmemory,那就继续随机采样淘汰,直到内存低于 maxmemory为止。
异步线程
一直以来我们都知道 Redis 是单线程的,单线程为 Redis 带来了代码的简洁性和丰富多样的数据结构。不过 Redis 内部实际上并不是只有一个主线程,它还有几个异步线程专门用来处理一些耗时的操作。
问题:删除指令 del 会直接释放对象的内存,大部分情况下,这个指令非常快,没有明显延迟。不过如果被删除的 key 是一个非常大的对象,比如一个包含了上千万个元素的 hash,那么删除操作就会导致单线程卡顿。
解决:Redis 为了解决这个卡顿问题,在 4.0 版本里引入了 unlink 指令,它能对删除操作进行懒处理,丢给后台线程来异步回收内存。会将这个 key 的内存回收操作包装成一个任务,塞进异步任务队列,后台线程会从这个异步队列中取任务。
> unlink key
OK
会不会出现多个线程同时并发修改数据结构的情况存在?
关于这一点,打个比方。可以将整个 Redis 内存里面所有有效的数据想象成一棵大树。当 unlink 指令发出时,它只是把大树中的一个树枝剪断了,然后扔到旁边的火堆(异步线程池)里焚烧。在树枝离开大树的瞬间,它就再也无法被主线程中的其他指令访问到了,因为主线程只会沿着这棵大树来访问。
Redis 提供了 flushdb 和 flushall 指令,用来清空数据库,这也是极其缓慢的操作。
Redis 4.0 同样给这两个指令带来了异步化,在指令后面增加 async 参数就可以将整棵大树连根拔起,扔给后台线程慢慢焚烧
> flushall async
OK
Redis 需要每秒 1(该数量可设置〉次同步 AOF 曰志到磁盘,确保消息尽量不丢失,需要调用 sync 函数,这个操作比较耗时,会导致主线程的效率下降,所以 Redis也将这个操作移到异步线程来完成。执行 AOF Sync 操作的线程是一个独立的异步线程,和前面的懒惰删除线程不是一个线程,同样它也有一个属于自己的任务队列,队列里只用来存放 AOF Sync 任务 。
redis安全通信 - spiped
想象这样一个应用场景,公司有两个机房。因为一个紧急需求,需要跨机房读取 Redis 数据。应用部署在 A 机房,存储部署在 B 机房。如果使用普通 tcp 直接访问,因为跨机房所以传输数据会暴露在公网上,客户端服务器交互的数据存在被窃昕的风险。
Redis 本身并不支持 SSL 安全链接 ,不过有了 SSL 代理软件,我们可以让通信数据得到加密,就好像 Redis 穿上了一层隐身外套一样, spiped 就是这样的一款 SSL 代理软件,它是 Redis 官方推荐的代理软件。
spiped 会在客户端和服务器各启动一个 spiped 进程,左边的 spiped 进程负责接受来自 Redis Client 发送过来的请求数据 , 加密后传送到右边的 spiped 进程 。 右边的 spiped 进程将接收到的数据解密后传递到 Redis Server。然后 Redis Server 再走一个反向的流程将响应回复给 Redis Client 。
spiped 进程需要成对出现,相互之间需要使用相同的共享密钥来加密消息。每一个 spiped 进程都会有个监听端口 (server socket)用来接收数据,同时还会作为一个客户端(socket client)将数据转发到目标地址。
相关文章:

Redis 深度历险:核心原理与应用实践 - 读书笔记
目录 第一章 基础应用篇Zset并发问题 - 分布式锁再谈分布式锁客户端在请求时加锁失败策略redis异步队列位图Hyperloglog布隆过滤器GeoHashscan 命令字典结构rehash扩容大 key 扫描 第二章 原理篇线程IO模型RESP 序列化协议持久化管道事务PubSub内存管理 第三章 集群篇CAP主从同…...

微服务重启优化kafka+EurekaNotificationServerListUpdater
由于遇到服务重启导致的业务中断等异常,所以计划通过kafkaeureka实现服务下线通知,来尽可能规避这类问题。 如果可以升级spring,则可以考虑nacos等更为方便的方案; 程序优化: 1.默认启用的为 PollingServerListUpdater…...

removeIf 方法设计理念及泛型界限限定
ArrayList 中的 removeIf 方法是 Java 8 中引入的集合操作方法之一。它使用了 Predicate 接口作为参数,以便根据指定的条件移除集合中的元素。以下是对 removeIf 方法入参设计的详细解释: Predicate 接口 Predicate 是一个函数式接口,定义了…...

kubernetes集群部署elasticsearch集群,包含无认证和有认证模式
1、背景: 因公司业务需要,需要在测试、生产kubernetes集群中部署elasticsearch集群,因不同环境要求,需要部署不同模式的elasticsearch集群, 1、测试环境因安全性要求不高,是部署一套默认配置; 2…...

Java 随笔记: 集合与泛型
文章目录 1. 集合框架概述2. 集合接口2.1 Collection 接口2.2 List 接口2.3 Set 接口2.4 Map 接口 3. 集合的常用操作3.1 添加元素3.2 删除元素3.3 遍历元素3.4 判断大小3.5 判断是否为空 4. 迭代器4.1 迭代器的作用4.2 迭代器的使用4.3 迭代器与增强 for 循环4.4 迭代器的注意…...
SurrealDB:高效构建实时Web应用的数据库
SurrealDB:数据驱动,实时协同。用SurrealDB简化你的开发流程- 精选真开源,释放新价值。 概览 SurrealDB,一款专为现代Web应用设计的云原生数据库,以其创新的架构和功能,为开发者提供了一个强大的工具。它整…...

SQL Server查询计划阅读及分析
6.4.5. 查询计划阅读及分析 SQL Server中,SQL语句的查询计划可能会包含多个节点,每个节点除了包含和对应一个操作符外,还包含节点及操作符相关的其他信息,其细节与具体的操作符相关。SQL Server查询计划与Oracle执行计划中,虽然每个节点所包含内容的具体称谓…...

SAP Fiori 实战课程(二):新建页面
课程回顾 上一课中,利用Visual studio Code 新建、并运行了一个Demo工程。可以实现对项目的启动,启动后进入一个List清单。 那么本次课程的目前就是在上一节Demo的基础上,从零开始新建一个完整的页面。实现从首页清单,选择行后,鼠标点击,进入下一个页面。 准备工作 在开…...

【Rust光年纪】超越ORM:探索Rust语言多款数据库客户端库的核心功能和使用场景
数据库操作新选择:从异步操作到连接管理,掌握Rust语言数据库客户端库的全貌 前言 在现代软件开发中,与数据库进行交互是一个常见的任务。Rust语言作为一种高性能、内存安全的编程语言,拥有丰富的生态系统来支持各种数据库操作。…...

解决:事件监听器 addEventListener 被多次调用
背景: 给一个元素添加了事件监听,click 会触发 然而在实际场景中,点击一次,事件会被触发两次 阻止冒泡也没有用 解决: 使用API:event.stopImmediatePropagation() stopImmediatePropagation() 方法可防止…...

配置RIPv2的认证
目录 一、配置IP地址、默认网关、启用端口 1. 路由器R1 2. 路由器R2 3. 路由器R3 4. Server1 5. Server2 二、搭建RIPv2网络 1. R1配置RIPv2 2. R2配置RIPv2 3. Server1 ping Server2 4. Server2 ping Server1 三、模拟网络攻击,为R3配置RIPv2 四、在R…...

前端调试技巧:动态高亮渲染区域
效果: 前端界面的渲染过程、次数,会通过高亮变化来显示,通过这种效果排除一些BUG 高亮 打开方式 F12进入后点击ESC,进入rendering,选择前三个即可(如果没有rendering,点击橘色部分勾选上&…...

深克隆与浅克隆的区别与实现
在软件开发中,克隆对象是一个常见需求。克隆的方式主要有两种:深克隆(Deep Clone)和浅克隆(Shallow Clone)。了解它们的区别及其实现方法,对于编写高效、安全的代码非常重要。 深克隆与浅克隆的…...

【学习笔记】无人机系统(UAS)的连接、识别和跟踪(六)-无人机直接C2通信
目录 引言 5.4 直接C2通信 5.4.1 概述 5.4.2 A2X直接C2通信服务的授权策略 5.4.3 USS使用A2X直接C2通信服务的C2授权程序 5.4.4 直接C2通信建立程序 引言 3GPP TS 23.256 技术规范,主要定义了3GPP系统对无人机(UAV)的连接性、身份识别…...

认识和安装R的扩展包,什么是模糊搜索安装,工作目录和空间的区别与设置
R语言以其强大的功能和灵活的扩展性,成为了无数数据分析师和研究者的首选工具。R的丰富功能和海量扩展包直接相关,但如何高效管理这些扩展包,进而充分发挥R的强大潜力?本文将为您揭示这些问题的答案。 一、R的扩展包 R的包(packages)是由R函数、数据和预编译代码组成的一…...

解决STM32开启定时器时立即进入一次中断程序问题
转自 解决STM32开启定时器时立即进入一次中断程序问题_stm32f407定时器初始化自动进入一次-CSDN博客 配置STM32定时器时,定时器中断使能、定时器使能、清除更新中断标志位,三者不同顺序程序执行时有不同效果,具体如下: TIM_Clea…...

Unity UGUI 之EventSystem
本文仅作学习笔记与交流,不作任何商业用途 本文包括但不限于unity官方手册,唐老狮,麦扣教程知识,引用会标记,如有不足还请斧正 1.EventSystem是什么? 有需要请查看手册:Unity - 手册࿱…...
USB转多路UART - USB 基础
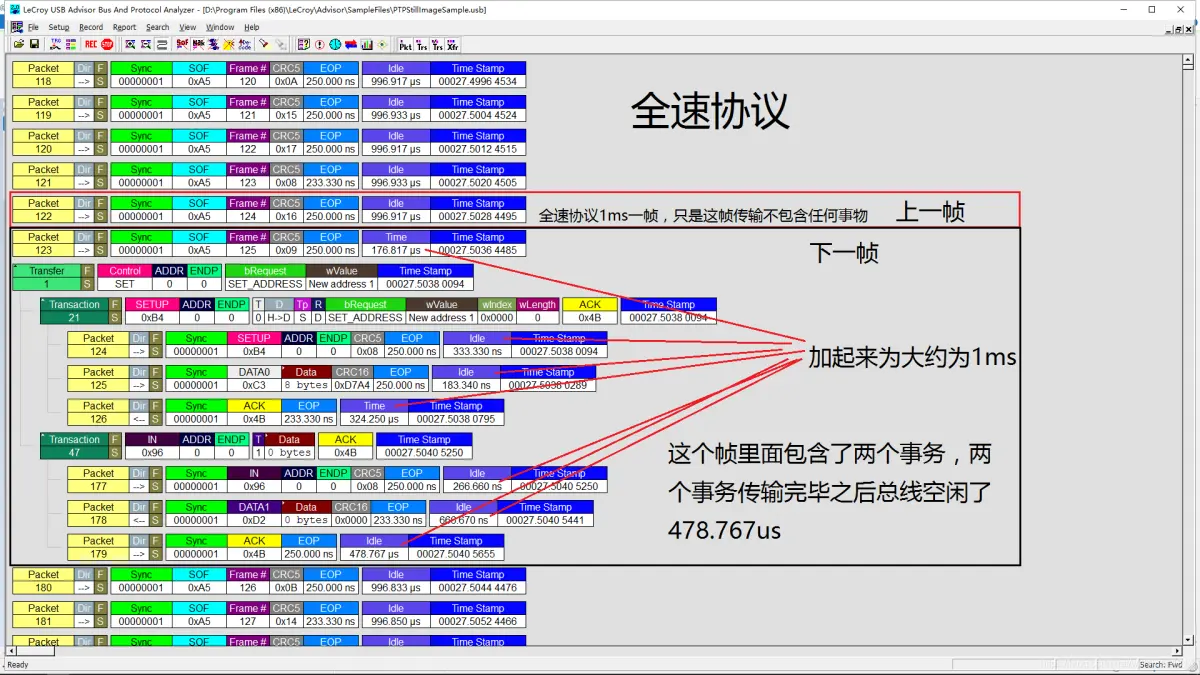
一、 前言 断断续续做了不少USB相关开发,但是没有系统去了解过,遇到问题就很被动了。做这个USB转UART的项目就是,于是专门花了一天的时间学习USB及CDC相关,到写这文章时估计也忘得差不多了,趁项目收尾阶段记录一下&am…...

接近50个实用编程相关学习资源网站
Date: 2024.07.17 09:45:10 author: lijianzhan 编程语言以及编程相关工具等实用性官方文档网站 C语言文档:https://learn.microsoft.com/zh-cn/cpp/c-languageMicrosoft C、C和汇编程序文档:https://learn.microsoft.com/zh-cn/cppJAVA官方文档&#…...

在数据操作中使用SELECT子句
目录 一、INSERT 语句中使用 SELECT子句 二、UPDATE 语句中使用 SELECT子句 三、DELETE 语句中使用 SELECT子句 一、INSERT 语句中使用 SELECT子句 在 INSERT 语句中使用 SELECT子句,可以将一个或多个表或视图中的数据添加到另外一个表中。使用 SELECT 子句还可以…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...