架构以及架构中的组件
架构以及架构中的组件
- Transform
Transform
以下的代码包含:
- 标准化的示例
- 残差化的示例
# huggingface
# transformers# https://www.bilibili.com/video/BV1At4y1W75x?spm_id_from=333.999.0.0import copy
import math
from collections import namedtupleimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import VariableHypothesis = namedtuple('Hypothesis', ['value', 'score'])def clones(module, n):return nn.ModuleList([copy.deepcopy(module) for _ in range(n)])"""
实现x 的标准化处理(标准化的作用:使x符合正太分布)
"""
class LayerNorm(nn.Module):def __init__(self, feature, eps=1e-6):""":param feature: self-attention 的 x 的大小:param eps:"""super(LayerNorm, self).__init__()self.a_2 = nn.Parameter(torch.ones(feature))self.b_2 = nn.Parameter(torch.zeros(feature))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a_2 * (x - mean) / (std + self.eps) + self.b_2"""
残差化的示例
"""
class SublayerConnection(nn.Module):"""这不仅仅做了残差,这是把残差和 layernorm 一起给做了"""def __init__(self, size, dropout=0.1):super(SublayerConnection, self).__init__()# 第一步做 layernorm 这是类的实例化的一种方法self.layer_norm = LayerNorm(size)# 第二步做 dropoutself.dropout = nn.Dropout(p=dropout)def forward(self, x, sublayer):""":param x: 就是self-attention的输入:param sublayer: self-attention层:return:"""return self.dropout(self.layer_norm(x + sublayer(x)))class FeatEmbedding(nn.Module):def __init__(self, d_feat, d_model, dropout):super(FeatEmbedding, self).__init__()self.video_embeddings = nn.Sequential(LayerNorm(d_feat),nn.Dropout(dropout),nn.Linear(d_feat, d_model))def forward(self, x):return self.video_embeddings(x)class TextEmbedding(nn.Module):def __init__(self, vocab_size, d_model):super(TextEmbedding, self).__init__()self.d_model = d_modelself.embed = nn.Embedding(vocab_size, d_model)def forward(self, x):return self.embed(x) * math.sqrt(self.d_model)"""
给一个词向量添加位置编码的示例
"""
class PositionalEncoding(nn.Module):def __init__(self, dim, dropout, max_len=5000):if dim % 2 != 0:raise ValueError("Cannot use sin/cos positional encoding with ""odd dim (got dim={:d})".format(dim))pe = torch.zeros(max_len, dim)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *-(math.log(10000.0) / dim)))pe[:, 0::2] = torch.sin(position.float() * div_term)pe[:, 1::2] = torch.cos(position.float() * div_term)pe = pe.unsqueeze(1)super(PositionalEncoding, self).__init__()self.register_buffer('pe', pe)self.drop_out = nn.Dropout(p=dropout)self.dim = dimdef forward(self, emb, step=None):emb = emb * math.sqrt(self.dim)if step is None:emb = emb + self.pe[:emb.size(0)]else:emb = emb + self.pe[step]emb = self.drop_out(emb)return emb"""
自注意力机制的实现示例
"""
def self_attention(query, key, value, dropout=None, mask=None):d_k = query.size(-1)scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)# mask的操作在QK之后,softmax之前if mask is not None:mask.cuda()scores = scores.masked_fill(mask == 0, -1e9)self_attn = F.softmax(scores, dim=-1)if dropout is not None:self_attn = dropout(self_attn)return torch.matmul(self_attn, value), self_attn"""
多头--注意力机制的实现示例
"""
class MultiHeadAttention(nn.Module):def __init__(self, head, d_model, dropout=0.1):super(MultiHeadAttention, self).__init__()assert (d_model % head == 0)self.d_k = d_model // headself.head = headself.d_model = d_modelself.linear_query = nn.Linear(d_model, d_model)self.linear_key = nn.Linear(d_model, d_model)self.linear_value = nn.Linear(d_model, d_model)self.linear_out = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(p=dropout)self.attn = Nonedef forward(self, query, key, value, mask=None):if mask is not None:# 多头注意力机制的线性变换层是4维,是把query[batch, frame_num, d_model]变成[batch, -1, head, d_k]# 再1,2维交换变成[batch, head, -1, d_k], 所以mask要在第一维添加一维,与后面的self attention计算维度一样mask = mask.unsqueeze(1)n_batch = query.size(0)# if self.head == 1:# x, self.attn = self_attention(query, key, value, dropout=self.dropout, mask=mask)# else:# query = self.linear_query(query).view(n_batch, -1, self.head, self.d_k).transpose(1, 2) # [b, 8, 32, 64]# key = self.linear_key(key).view(n_batch, -1, self.head, self.d_k).transpose(1, 2) # [b, 8, 28, 64]# value = self.linear_value(value).view(n_batch, -1, self.head, self.d_k).transpose(1, 2) # [b, 8, 28, 64]## x, self.attn = self_attention(query, key, value, dropout=self.dropout, mask=mask)# # 变为三维, 或者说是concat head# x = x.transpose(1, 2).contiguous().view(n_batch, -1, self.head * self.d_k)query = self.linear_query(query).view(n_batch, -1, self.head, self.d_k).transpose(1, 2) # [b, 8, 32, 64]key = self.linear_key(key).view(n_batch, -1, self.head, self.d_k).transpose(1, 2) # [b, 8, 28, 64]value = self.linear_value(value).view(n_batch, -1, self.head, self.d_k).transpose(1, 2) # [b, 8, 28, 64]x, self.attn = self_attention(query, key, value, dropout=self.dropout, mask=mask)# 变为三维, 或者说是concat headx = x.transpose(1, 2).contiguous().view(n_batch, -1, self.head * self.d_k)return self.linear_out(x)class PositionWiseFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):super(PositionWiseFeedForward, self).__init__()self.w_1 = nn.Linear(d_model, d_ff)self.w_2 = nn.Linear(d_ff, d_model)self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)self.dropout_1 = nn.Dropout(dropout)self.relu = nn.ReLU()self.dropout_2 = nn.Dropout(dropout)def forward(self, x):inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x))))output = self.dropout_2(self.w_2(inter))return outputclass EncoderLayer(nn.Module):def __init__(self, size, attn, feed_forward, dropout=0.1):super(EncoderLayer, self).__init__()self.attn = attnself.feed_forward = feed_forwardself.sublayer_connection = clones(SublayerConnection(size, dropout), 2)def forward(self, x, mask):x = self.sublayer_connection[0](x, lambda x: self.attn(x, x, x, mask))return self.sublayer_connection[1](x, self.feed_forward)class EncoderLayerNoAttention(nn.Module):def __init__(self, size, attn, feed_forward, dropout=0.1):super(EncoderLayerNoAttention, self).__init__()self.attn = attnself.feed_forward = feed_forwardself.sublayer_connection = clones(SublayerConnection(size, dropout), 2)def forward(self, x, mask):return self.sublayer_connection[1](x, self.feed_forward)class DecoderLayer(nn.Module):def __init__(self, size, attn, feed_forward, sublayer_num, dropout=0.1):super(DecoderLayer, self).__init__()self.attn = attnself.feed_forward = feed_forwardself.sublayer_connection = clones(SublayerConnection(size, dropout), sublayer_num)def forward(self, x, memory, src_mask, trg_mask, r2l_memory=None, r2l_trg_mask=None):x = self.sublayer_connection[0](x, lambda x: self.attn(x, x, x, trg_mask))x = self.sublayer_connection[1](x, lambda x: self.attn(x, memory, memory, src_mask))if r2l_memory is not None:x = self.sublayer_connection[-2](x, lambda x: self.attn(x, r2l_memory, r2l_memory, r2l_trg_mask))return self.sublayer_connection[-1](x, self.feed_forward)class Encoder(nn.Module):def __init__(self, n, encoder_layer):super(Encoder, self).__init__()self.encoder_layer = clones(encoder_layer, n)def forward(self, x, src_mask):for layer in self.encoder_layer:x = layer(x, src_mask)return xclass R2L_Decoder(nn.Module):def __init__(self, n, decoder_layer):super(R2L_Decoder, self).__init__()self.decoder_layer = clones(decoder_layer, n)def forward(self, x, memory, src_mask, r2l_trg_mask):for layer in self.decoder_layer:x = layer(x, memory, src_mask, r2l_trg_mask)return xclass L2R_Decoder(nn.Module):def __init__(self, n, decoder_layer):super(L2R_Decoder, self).__init__()self.decoder_layer = clones(decoder_layer, n)def forward(self, x, memory, src_mask, trg_mask, r2l_memory, r2l_trg_mask):for layer in self.decoder_layer:x = layer(x, memory, src_mask, trg_mask, r2l_memory, r2l_trg_mask)return xdef pad_mask(src, r2l_trg, trg, pad_idx):if isinstance(src, tuple):if len(src) == 4:src_image_mask = (src[0][:, :, 0] != pad_idx).unsqueeze(1)src_motion_mask = (src[1][:, :, 0] != pad_idx).unsqueeze(1)src_object_mask = (src[2][:, :, 0] != pad_idx).unsqueeze(1)src_rel_mask = (src[3][:, :, 0] != pad_idx).unsqueeze(1)enc_src_mask = (src_image_mask, src_motion_mask, src_object_mask, src_rel_mask)dec_src_mask_1 = src_image_mask & src_motion_maskdec_src_mask_2 = src_image_mask & src_motion_mask & src_object_mask & src_rel_maskdec_src_mask = (dec_src_mask_1, dec_src_mask_2)src_mask = (enc_src_mask, dec_src_mask)if len(src) == 3:src_image_mask = (src[0][:, :, 0] != pad_idx).unsqueeze(1)src_motion_mask = (src[1][:, :, 0] != pad_idx).unsqueeze(1)src_object_mask = (src[2][:, :, 0] != pad_idx).unsqueeze(1)enc_src_mask = (src_image_mask, src_motion_mask, src_object_mask)dec_src_mask = src_image_mask & src_motion_masksrc_mask = (enc_src_mask, dec_src_mask)if len(src) == 2:src_image_mask = (src[0][:, :, 0] != pad_idx).unsqueeze(1)src_motion_mask = (src[1][:, :, 0] != pad_idx).unsqueeze(1)enc_src_mask = (src_image_mask, src_motion_mask)dec_src_mask = src_image_mask & src_motion_masksrc_mask = (enc_src_mask, dec_src_mask)else:src_mask = (src[:, :, 0] != pad_idx).unsqueeze(1)if trg is not None:if isinstance(src_mask, tuple):trg_mask = (trg != pad_idx).unsqueeze(1) & subsequent_mask(trg.size(1)).type_as(src_image_mask.data)r2l_pad_mask = (r2l_trg != pad_idx).unsqueeze(1).type_as(src_image_mask.data)r2l_trg_mask = r2l_pad_mask & subsequent_mask(r2l_trg.size(1)).type_as(src_image_mask.data)return src_mask, r2l_pad_mask, r2l_trg_mask, trg_maskelse:trg_mask = (trg != pad_idx).unsqueeze(1) & subsequent_mask(trg.size(1)).type_as(src_mask.data)r2l_pad_mask = (r2l_trg != pad_idx).unsqueeze(1).type_as(src_mask.data)r2l_trg_mask = r2l_pad_mask & subsequent_mask(r2l_trg.size(1)).type_as(src_mask.data)return src_mask, r2l_pad_mask, r2l_trg_mask, trg_mask # src_mask[batch, 1, lens] trg_mask[batch, 1, lens]else:return src_maskdef subsequent_mask(size):"""Mask out subsequent positions."""attn_shape = (1, size, size)mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')return (torch.from_numpy(mask) == 0).cuda()class Generator(nn.Module):def __init__(self, d_model, vocab_size):super(Generator, self).__init__()self.linear = nn.Linear(d_model, vocab_size)def forward(self, x):return F.log_softmax(self.linear(x), dim=-1)class ABDTransformer(nn.Module):def __init__(self, vocab, d_feat, d_model, d_ff, n_heads, n_layers, dropout, feature_mode,device='cuda', n_heads_big=128):super(ABDTransformer, self).__init__()self.vocab = vocabself.device = deviceself.feature_mode = feature_modec = copy.deepcopy# attn_no_heads = MultiHeadAttention(1, d_model, dropout)attn = MultiHeadAttention(n_heads, d_model, dropout)attn_big = MultiHeadAttention(n_heads_big, d_model, dropout)# attn_big2 = MultiHeadAttention(10, d_model, dropout)feed_forward = PositionWiseFeedForward(d_model, d_ff)if feature_mode == 'one':self.src_embed = FeatEmbedding(d_feat, d_model, dropout)elif feature_mode == 'two':self.image_src_embed = FeatEmbedding(d_feat[0], d_model, dropout)self.motion_src_embed = FeatEmbedding(d_feat[1], d_model, dropout)elif feature_mode == 'three':self.image_src_embed = FeatEmbedding(d_feat[0], d_model, dropout)self.motion_src_embed = FeatEmbedding(d_feat[1], d_model, dropout)self.object_src_embed = FeatEmbedding(d_feat[2], d_model, dropout)elif feature_mode == 'four':self.image_src_embed = FeatEmbedding(d_feat[0], d_model, dropout)self.motion_src_embed = FeatEmbedding(d_feat[1], d_model, dropout)self.object_src_embed = FeatEmbedding(d_feat[2], d_model, dropout)self.rel_src_embed = FeatEmbedding(d_feat[3], d_model, dropout)self.trg_embed = TextEmbedding(vocab.n_vocabs, d_model)self.pos_embed = PositionalEncoding(d_model, dropout)# self.encoder_no_heads = Encoder(n_layers, EncoderLayer(d_model, c(attn_no_heads), c(feed_forward), dropout))self.encoder = Encoder(n_layers, EncoderLayer(d_model, c(attn), c(feed_forward), dropout))self.encoder_big = Encoder(n_layers, EncoderLayer(d_model, c(attn_big), c(feed_forward), dropout))# self.encoder_big2 = Encoder(n_layers, EncoderLayer(d_model, c(attn_big2), c(feed_forward), dropout))self.encoder_no_attention = Encoder(n_layers,EncoderLayerNoAttention(d_model, c(attn), c(feed_forward), dropout))self.r2l_decoder = R2L_Decoder(n_layers, DecoderLayer(d_model, c(attn), c(feed_forward),sublayer_num=3, dropout=dropout))self.l2r_decoder = L2R_Decoder(n_layers, DecoderLayer(d_model, c(attn), c(feed_forward),sublayer_num=4, dropout=dropout))self.generator = Generator(d_model, vocab.n_vocabs)def encode(self, src, src_mask, feature_mode_two=False):if self.feature_mode == 'two':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder_big(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder_big(x2, src_mask[1])return x1 + x2if feature_mode_two:x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder_big(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder_big(x2, src_mask[1])return x1 + x2if self.feature_mode == 'one':x = self.src_embed(src)x = self.pos_embed(x)return self.encoder(x, src_mask)elif self.feature_mode == 'two':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder_big(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder_big(x2, src_mask[1])return x1 + x2elif self.feature_mode == 'three':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder(x2, src_mask[1])x3 = self.object_src_embed(src[2])x3 = self.pos_embed(x3)x3 = self.encoder(x3, src_mask[2])return x1 + x2 + x3elif self.feature_mode == 'four':x1 = self.image_src_embed(src[0])x1 = self.pos_embed(x1)x1 = self.encoder(x1, src_mask[0])x2 = self.motion_src_embed(src[1])x2 = self.pos_embed(x2)x2 = self.encoder(x2, src_mask[1])x3 = self.object_src_embed(src[2])# x3 = self.pos_embed(x3)x3 = self.encoder(x3, src_mask[2])# x3 = self.encoder_no_attention(x3, src_mask[2])x4 = self.rel_src_embed(src[3])# x4 = self.pos_embed(x4)# x4 = self.encoder_no_# heads(x4, src_mask[3])x4 = self.encoder_no_attention(x4, src_mask[3])# x4 = self.encoder(x4, src_mask[3])return x1 + x2 + x3 + x4def r2l_decode(self, r2l_trg, memory, src_mask, r2l_trg_mask):x = self.trg_embed(r2l_trg)x = self.pos_embed(x)return self.r2l_decoder(x, memory, src_mask, r2l_trg_mask)def l2r_decode(self, trg, memory, src_mask, trg_mask, r2l_memory, r2l_trg_mask):x = self.trg_embed(trg)x = self.pos_embed(x)return self.l2r_decoder(x, memory, src_mask, trg_mask, r2l_memory, r2l_trg_mask)def forward(self, src, r2l_trg, trg, mask):src_mask, r2l_pad_mask, r2l_trg_mask, trg_mask = maskif self.feature_mode == 'one':encoding_outputs = self.encode(src, src_mask)r2l_outputs = self.r2l_decode(r2l_trg, encoding_outputs, src_mask, r2l_trg_mask)l2r_outputs = self.l2r_decode(trg, encoding_outputs, src_mask, trg_mask, r2l_outputs, r2l_pad_mask)elif self.feature_mode == 'two' or 'three' or 'four':enc_src_mask, dec_src_mask = src_maskr2l_encoding_outputs = self.encode(src, enc_src_mask, feature_mode_two=True)encoding_outputs = self.encode(src, enc_src_mask)r2l_outputs = self.r2l_decode(r2l_trg, r2l_encoding_outputs, dec_src_mask[0], r2l_trg_mask)l2r_outputs = self.l2r_decode(trg, encoding_outputs, dec_src_mask[1], trg_mask, r2l_outputs, r2l_pad_mask)# r2l_outputs = self.r2l_decode(r2l_trg, encoding_outputs, dec_src_mask, r2l_trg_mask)# l2r_outputs = self.l2r_decode(trg, encoding_outputs, dec_src_mask, trg_mask, None, None)else:raise "没有输出"r2l_pred = self.generator(r2l_outputs)l2r_pred = self.generator(l2r_outputs)return r2l_pred, l2r_preddef greedy_decode(self, batch_size, src_mask, memory, max_len):eos_idx = self.vocab.word2idx['<S>']r2l_hidden = Nonewith torch.no_grad():output = torch.ones(batch_size, 1).fill_(eos_idx).long().cuda()for i in range(max_len + 2 - 1):trg_mask = subsequent_mask(output.size(1))dec_out = self.r2l_decode(output, memory, src_mask, trg_mask) # batch, len, d_modelr2l_hidden = dec_outpred = self.generator(dec_out) # batch, len, n_vocabsnext_word = pred[:, -1].max(dim=-1)[1].unsqueeze(1) # pred[:, -1]([batch, n_vocabs])output = torch.cat([output, next_word], dim=-1)return r2l_hidden, output# beam search 必用的def r2l_beam_search_decode(self, batch_size, src, src_mask, model_encodings, beam_size, max_len):end_symbol = self.vocab.word2idx['<S>']start_symbol = self.vocab.word2idx['<S>']r2l_outputs = None# 1.1 Setup Src"src has shape (batch_size, sent_len)""src_mask has shape (batch_size, 1, sent_len)"# src_mask = (src[:, :, 0] != self.vocab.word2idx['<PAD>']).unsqueeze(-2) # TODO Untested"model_encodings has shape (batch_size, sentence_len, d_model)"# model_encodings = self.encode(src, src_mask)# 1.2 Setup Tgt Hypothesis Tracking"hypothesis is List(4 bt)[(cur beam_sz, dec_sent_len)], init: List(4 bt)[(1 init_beam_sz, dec_sent_len)]""hypotheses[i] is shape (cur beam_sz, dec_sent_len)"hypotheses = [copy.deepcopy(torch.full((1, 1), start_symbol, dtype=torch.long,device=self.device)) for _ in range(batch_size)]"List after init: List 4 bt of List of len max_len_completed, init: List of len 4 bt of []"completed_hypotheses = [copy.deepcopy([]) for _ in range(batch_size)]"List len batch_sz of shape (cur beam_sz), init: List(4 bt)[(1 init_beam_sz)]""hyp_scores[i] is shape (cur beam_sz)"hyp_scores = [copy.deepcopy(torch.full((1,), 0, dtype=torch.float, device=self.device))for _ in range(batch_size)] # probs are log_probs must be init at 0.# 2. Iterate: Generate one char at a time until maxlenfor iter in range(max_len + 1):if all([len(completed_hypotheses[i]) == beam_size for i in range(batch_size)]):break# 2.1 Setup the batch. Since we use beam search, each batch has a variable number (called cur_beam_size)# between 0 and beam_size of hypotheses live at any moment. We decode all hypotheses for all batches at# the same time, so we must copy the src_encodings, src_mask, etc the appropriate number fo times for# the number of hypotheses for each example. We keep track of the number of live hypotheses for each example.# We run all hypotheses for all examples together through the decoder and log-softmax,# and then use `torch.split` to get the appropriate number of hypotheses for each example in the end.cur_beam_sizes, last_tokens, model_encodings_l, src_mask_l = [], [], [], []for i in range(batch_size):if hypotheses[i] is None:cur_beam_sizes += [0]continuecur_beam_size, decoded_len = hypotheses[i].shapecur_beam_sizes += [cur_beam_size]last_tokens += [hypotheses[i]]model_encodings_l += [model_encodings[i:i + 1]] * cur_beam_sizesrc_mask_l += [src_mask[i:i + 1]] * cur_beam_size"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 128 d_model)"model_encodings_cur = torch.cat(model_encodings_l, dim=0)src_mask_cur = torch.cat(src_mask_l, dim=0)y_tm1 = torch.cat(last_tokens, dim=0)"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 128 d_model)"if self.feature_mode == 'one':out = self.r2l_decode(Variable(y_tm1).to(self.device), model_encodings_cur, src_mask_cur,Variable(subsequent_mask(y_tm1.size(-1)).type_as(src.data)).to(self.device))elif self.feature_mode == 'two' or 'three' or 'four':out = self.r2l_decode(Variable(y_tm1).to(self.device), model_encodings_cur, src_mask_cur,Variable(subsequent_mask(y_tm1.size(-1)).type_as(src[0].data)).to(self.device))r2l_outputs = out"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 50002 vocab_sz)"log_prob = self.generator(out[:, -1, :]).unsqueeze(1)"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 50002 vocab_sz)"_, decoded_len, vocab_sz = log_prob.shape# log_prob = log_prob.reshape(batch_size, cur_beam_size, decoded_len, vocab_sz)"shape List(4 bt)[(cur_beam_sz_i, dec_sent_len, 50002 vocab_sz)]""log_prob[i] is (cur_beam_sz_i, dec_sent_len, 50002 vocab_sz)"log_prob = torch.split(log_prob, cur_beam_sizes, dim=0)# 2.2 Now we process each example in the batch. Note that the example may have already finished processing before# other examples (no more hypotheses to try), in which case we continuenew_hypotheses, new_hyp_scores = [], []for i in range(batch_size):if hypotheses[i] is None or len(completed_hypotheses[i]) >= beam_size:new_hypotheses += [None]new_hyp_scores += [None]continue# 2.2.1 We compute the cumulative scores for each live hypotheses for the example# hyp_scores is the old scores for the previous stage, and `log_prob` are the new probs for# this stage. Since they are log probs, we sum them instaed of multiplying them.# The .view(-1) forces all the hypotheses into one dimension. The shape of this dimension is# cur_beam_sz * vocab_sz (ex: 5 * 50002). So after getting the topk from it, we can recover the# generating sentence and the next word using: ix // vocab_sz, ix % vocab_sz.cur_beam_sz_i, dec_sent_len, vocab_sz = log_prob[i].shape"shape (vocab_sz,)"cumulative_hyp_scores_i = (hyp_scores[i].unsqueeze(-1).unsqueeze(-1).expand((cur_beam_sz_i, 1, vocab_sz)) + log_prob[i]).view(-1)# 2.2.2 We get the topk values in cumulative_hyp_scores_i and compute the current (generating) sentence# and the next word using: ix // vocab_sz, ix % vocab_sz."shape (cur_beam_sz,)"live_hyp_num_i = beam_size - len(completed_hypotheses[i])"shape (cur_beam_sz,). Vals are between 0 and 50002 vocab_sz"top_cand_hyp_scores, top_cand_hyp_pos = torch.topk(cumulative_hyp_scores_i, k=live_hyp_num_i)"shape (cur_beam_sz,). prev_hyp_ids vals are 0 <= val < cur_beam_sz. hyp_word_ids vals are 0 <= val < vocab_len"prev_hyp_ids, hyp_word_ids = top_cand_hyp_pos // self.vocab.n_vocabs, \top_cand_hyp_pos % self.vocab.n_vocabs# 2.2.3 For each of the topk words, we append the new word to the current (generating) sentence# We add this to new_hypotheses_i and add its corresponding total score to new_hyp_scores_inew_hypotheses_i, new_hyp_scores_i = [], [] # Removed live_hyp_ids_i, which is used in the LSTM decoder to track live hypothesis idsfor prev_hyp_id, hyp_word_id, cand_new_hyp_score in zip(prev_hyp_ids, hyp_word_ids,top_cand_hyp_scores):prev_hyp_id, hyp_word_id, cand_new_hyp_score = \prev_hyp_id.item(), hyp_word_id.item(), cand_new_hyp_score.item()new_hyp_sent = torch.cat((hypotheses[i][prev_hyp_id], torch.tensor([hyp_word_id], device=self.device)))if hyp_word_id == end_symbol:completed_hypotheses[i].append(Hypothesis(value=[self.vocab.idx2word[a.item()] for a in new_hyp_sent[1:-1]],score=cand_new_hyp_score))else:new_hypotheses_i.append(new_hyp_sent.unsqueeze(-1))new_hyp_scores_i.append(cand_new_hyp_score)# 2.2.4 We may find that the hypotheses_i for some example in the batch# is empty - we have fully processed that example. We use None as a sentinel in this case.# Above, the loops gracefully handle None examples.if len(new_hypotheses_i) > 0:hypotheses_i = torch.cat(new_hypotheses_i, dim=-1).transpose(0, -1).to(self.device)hyp_scores_i = torch.tensor(new_hyp_scores_i, dtype=torch.float, device=self.device)else:hypotheses_i, hyp_scores_i = None, Nonenew_hypotheses += [hypotheses_i]new_hyp_scores += [hyp_scores_i]# print(new_hypotheses, new_hyp_scores)hypotheses, hyp_scores = new_hypotheses, new_hyp_scores# 2.3 Finally, we do some postprocessing to get our final generated candidate sentences.# Sometimes, we may get to max_len of a sentence and still not generate the </s> end token.# In this case, the partial sentence we have generated will not be added to the completed_hypotheses# automatically, and we have to manually add it in. We add in as many as necessary so that there are# `beam_size` completed hypotheses for each example.# Finally, we sort each completed hypothesis by score.for i in range(batch_size):hyps_to_add = beam_size - len(completed_hypotheses[i])if hyps_to_add > 0:scores, ix = torch.topk(hyp_scores[i], k=hyps_to_add)for score, id in zip(scores, ix):completed_hypotheses[i].append(Hypothesis(value=[self.vocab.idx2word[a.item()] for a in hypotheses[i][id][1:]],score=score))completed_hypotheses[i].sort(key=lambda hyp: hyp.score, reverse=True)return r2l_outputs, completed_hypothesesdef beam_search_decode(self, src, beam_size, max_len):"""An Implementation of Beam Search for the Transformer Model.Beam search is performed in a batched manner. Each example in a batch generates `beam_size` hypotheses.We return a list (len: batch_size) of list (len: beam_size) of Hypothesis, which contain our output decoded sentencesand their scores.:param src: shape (sent_len, batch_size). Each val is 0 < val < len(vocab_dec). The input tokens to the decoder.:param max_len: the maximum length to decode:param beam_size: the beam size to use:return completed_hypotheses: A List of length batch_size, each containing a List of beam_size Hypothesis objects.Hypothesis is a named Tuple, its first entry is "value" and is a List of strings which contains the translated word(one string is one word token). The second entry is "score" and it is the log-prob score for this translated sentence.Note: Below I note "4 bt", "5 beam_size" as the shapes of objects. 4, 5 are default values. Actual values may differ."""# 1. Setupstart_symbol = self.vocab.word2idx['<S>']end_symbol = self.vocab.word2idx['<S>']# 1.1 Setup Src"src has shape (batch_size, sent_len)""src_mask has shape (batch_size, 1, sent_len)"# src_mask = (src[:, :, 0] != self.vocab.word2idx['<PAD>']).unsqueeze(-2) # TODO Untestedsrc_mask = pad_mask(src, r2l_trg=None, trg=None, pad_idx=self.vocab.word2idx['<PAD>'])"model_encodings has shape (batch_size, sentence_len, d_model)"if self.feature_mode == 'one':batch_size = src.shape[0]model_encodings = self.encode(src, src_mask)r2l_memory, r2l_completed_hypotheses = self.r2l_beam_search_decode(batch_size, src, src_mask,model_encodings=model_encodings,beam_size=beam_size, max_len=max_len)elif self.feature_mode == 'two' or 'three' or 'four':batch_size = src[0].shape[0]enc_src_mask = src_mask[0]dec_src_mask = src_mask[1]r2l_model_encodings = self.encode(src, enc_src_mask, feature_mode_two=True)# model_encodings = r2l_model_encodingsmodel_encodings = self.encode(src, enc_src_mask)r2l_memory, r2l_completed_hypotheses = self.r2l_beam_search_decode(batch_size, src, dec_src_mask[0],model_encodings=r2l_model_encodings,beam_size=beam_size, max_len=max_len)# 1.2 Setup r2l target output# r2l_memory, r2l_completed_hypotheses = self.r2l_beam_search_decode(batch_size, src, src_mask,# model_encodings=model_encodings,# beam_size=1, max_len=max_len)# r2l_memory, r2l_completed_hypotheses = self.greedy_decode(batch_size, src_mask, model_encodings, max_len)# beam_r2l_memory = [copy.deepcopy(r2l_memory) for _ in range(beam_size)]# 1.3 Setup Tgt Hypothesis Tracking"hypothesis is List(4 bt)[(cur beam_sz, dec_sent_len)], init: List(4 bt)[(1 init_beam_sz, dec_sent_len)]""hypotheses[i] is shape (cur beam_sz, dec_sent_len)"hypotheses = [copy.deepcopy(torch.full((1, 1), start_symbol, dtype=torch.long,device=self.device)) for _ in range(batch_size)]"List after init: List 4 bt of List of len max_len_completed, init: List of len 4 bt of []"completed_hypotheses = [copy.deepcopy([]) for _ in range(batch_size)]"List len batch_sz of shape (cur beam_sz), init: List(4 bt)[(1 init_beam_sz)]""hyp_scores[i] is shape (cur beam_sz)"hyp_scores = [copy.deepcopy(torch.full((1,), 0, dtype=torch.float, device=self.device))for _ in range(batch_size)] # probs are log_probs must be init at 0.# 2. Iterate: Generate one char at a time until maxlenfor iter in range(max_len + 1):if all([len(completed_hypotheses[i]) == beam_size for i in range(batch_size)]):break# 2.1 Setup the batch. Since we use beam search, each batch has a variable number (called cur_beam_size)# between 0 and beam_size of hypotheses live at any moment. We decode all hypotheses for all batches at# the same time, so we must copy the src_encodings, src_mask, etc the appropriate number fo times for# the number of hypotheses for each example. We keep track of the number of live hypotheses for each example.# We run all hypotheses for all examples together through the decoder and log-softmax,# and then use `torch.split` to get the appropriate number of hypotheses for each example in the end.cur_beam_sizes, last_tokens, model_encodings_l, src_mask_l, r2l_memory_l = [], [], [], [], []for i in range(batch_size):if hypotheses[i] is None:cur_beam_sizes += [0]continuecur_beam_size, decoded_len = hypotheses[i].shapecur_beam_sizes += [cur_beam_size]last_tokens += [hypotheses[i]]model_encodings_l += [model_encodings[i:i + 1]] * cur_beam_sizeif self.feature_mode == 'one':src_mask_l += [src_mask[i:i + 1]] * cur_beam_sizeelif self.feature_mode == 'two' or 'three' or 'four':src_mask_l += [dec_src_mask[1][i:i + 1]] * cur_beam_sizer2l_memory_l += [r2l_memory[i: i + 1]] * cur_beam_size"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 128 d_model)"model_encodings_cur = torch.cat(model_encodings_l, dim=0)src_mask_cur = torch.cat(src_mask_l, dim=0)y_tm1 = torch.cat(last_tokens, dim=0)r2l_memory_cur = torch.cat(r2l_memory_l, dim=0)"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 128 d_model)"if self.feature_mode == 'one':out = self.l2r_decode(Variable(y_tm1).to(self.device), model_encodings_cur, src_mask_cur,Variable(subsequent_mask(y_tm1.size(-1)).type_as(src.data)).to(self.device),r2l_memory_cur, r2l_trg_mask=None)elif self.feature_mode == 'two' or 'three' or 'four':out = self.l2r_decode(Variable(y_tm1).to(self.device), model_encodings_cur, src_mask_cur,Variable(subsequent_mask(y_tm1.size(-1)).type_as(src[0].data)).to(self.device),r2l_memory_cur, r2l_trg_mask=None)"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 50002 vocab_sz)"log_prob = self.generator(out[:, -1, :]).unsqueeze(1)"shape (sum(4 bt * cur_beam_sz_i), 1 dec_sent_len, 50002 vocab_sz)"_, decoded_len, vocab_sz = log_prob.shape# log_prob = log_prob.reshape(batch_size, cur_beam_size, decoded_len, vocab_sz)"shape List(4 bt)[(cur_beam_sz_i, dec_sent_len, 50002 vocab_sz)]""log_prob[i] is (cur_beam_sz_i, dec_sent_len, 50002 vocab_sz)"log_prob = torch.split(log_prob, cur_beam_sizes, dim=0)# 2.2 Now we process each example in the batch. Note that the example may have already finished processing before# other examples (no more hypotheses to try), in which case we continuenew_hypotheses, new_hyp_scores = [], []for i in range(batch_size):if hypotheses[i] is None or len(completed_hypotheses[i]) >= beam_size:new_hypotheses += [None]new_hyp_scores += [None]continue# 2.2.1 We compute the cumulative scores for each live hypotheses for the example# hyp_scores is the old scores for the previous stage, and `log_prob` are the new probs for# this stage. Since they are log probs, we sum them instaed of multiplying them.# The .view(-1) forces all the hypotheses into one dimension. The shape of this dimension is# cur_beam_sz * vocab_sz (ex: 5 * 50002). So after getting the topk from it, we can recover the# generating sentence and the next word using: ix // vocab_sz, ix % vocab_sz.cur_beam_sz_i, dec_sent_len, vocab_sz = log_prob[i].shape"shape (vocab_sz,)"cumulative_hyp_scores_i = (hyp_scores[i].unsqueeze(-1).unsqueeze(-1).expand((cur_beam_sz_i, 1, vocab_sz)) + log_prob[i]).view(-1)# 2.2.2 We get the topk values in cumulative_hyp_scores_i and compute the current (generating) sentence# and the next word using: ix // vocab_sz, ix % vocab_sz."shape (cur_beam_sz,)"live_hyp_num_i = beam_size - len(completed_hypotheses[i])"shape (cur_beam_sz,). Vals are between 0 and 50002 vocab_sz"top_cand_hyp_scores, top_cand_hyp_pos = torch.topk(cumulative_hyp_scores_i, k=live_hyp_num_i)"shape (cur_beam_sz,). prev_hyp_ids vals are 0 <= val < cur_beam_sz. hyp_word_ids vals are 0 <= val < vocab_len"prev_hyp_ids, hyp_word_ids = top_cand_hyp_pos // self.vocab.n_vocabs, \top_cand_hyp_pos % self.vocab.n_vocabs# 2.2.3 For each of the topk words, we append the new word to the current (generating) sentence# We add this to new_hypotheses_i and add its corresponding total score to new_hyp_scores_inew_hypotheses_i, new_hyp_scores_i = [], [] # Removed live_hyp_ids_i, which is used in the LSTM decoder to track live hypothesis idsfor prev_hyp_id, hyp_word_id, cand_new_hyp_score in zip(prev_hyp_ids, hyp_word_ids,top_cand_hyp_scores):prev_hyp_id, hyp_word_id, cand_new_hyp_score = \prev_hyp_id.item(), hyp_word_id.item(), cand_new_hyp_score.item()new_hyp_sent = torch.cat((hypotheses[i][prev_hyp_id], torch.tensor([hyp_word_id], device=self.device)))if hyp_word_id == end_symbol:completed_hypotheses[i].append(Hypothesis(value=[self.vocab.idx2word[a.item()] for a in new_hyp_sent[1:-1]],score=cand_new_hyp_score))else:new_hypotheses_i.append(new_hyp_sent.unsqueeze(-1))new_hyp_scores_i.append(cand_new_hyp_score)# 2.2.4 We may find that the hypotheses_i for some example in the batch# is empty - we have fully processed that example. We use None as a sentinel in this case.# Above, the loops gracefully handle None examples.if len(new_hypotheses_i) > 0:hypotheses_i = torch.cat(new_hypotheses_i, dim=-1).transpose(0, -1).to(self.device)hyp_scores_i = torch.tensor(new_hyp_scores_i, dtype=torch.float, device=self.device)else:hypotheses_i, hyp_scores_i = None, Nonenew_hypotheses += [hypotheses_i]new_hyp_scores += [hyp_scores_i]# print(new_hypotheses, new_hyp_scores)hypotheses, hyp_scores = new_hypotheses, new_hyp_scores# 2.3 Finally, we do some postprocessing to get our final generated candidate sentences.# Sometimes, we may get to max_len of a sentence and still not generate the </s> end token.# In this case, the partial sentence we have generated will not be added to the completed_hypotheses# automatically, and we have to manually add it in. We add in as many as necessary so that there are# `beam_size` completed hypotheses for each example.# Finally, we sort each completed hypothesis by score.for i in range(batch_size):hyps_to_add = beam_size - len(completed_hypotheses[i])if hyps_to_add > 0:scores, ix = torch.topk(hyp_scores[i], k=hyps_to_add)for score, id in zip(scores, ix):completed_hypotheses[i].append(Hypothesis(value=[self.vocab.idx2word[a.item()] for a in hypotheses[i][id][1:]],score=score))completed_hypotheses[i].sort(key=lambda hyp: hyp.score, reverse=True)# print('completed_hypotheses', completed_hypotheses)return r2l_completed_hypotheses, completed_hypotheses
相关文章:

架构以及架构中的组件
架构以及架构中的组件 Transform Transform 以下的代码包含: 标准化的示例残差化的示例 # huggingface # transformers# https://www.bilibili.com/video/BV1At4y1W75x?spm_id_from333.999.0.0import copy import math from collections import namedtupleimport …...

Docker启动PostgreSql并设置时间与主机同步
在 Docker 中启动 PostgreSql 时,需要配置容器的时间与主机同步。可以通过在 Dockerfile 或者 Docker Compose 文件中设置容器的时区,或者使用宿主机的时间来同步容器的时间。这样可以确保容器中的 PostgreSql 与主机的时间保持一致,避免在使…...
提升无线网络安全:用Python脚本发现并修复WiFi安全问题
文章目录 概要环境准备技术细节3.1 实现原理3.2 创建python文件3.3 插入内容3.4 运行python脚本 加固建议4.1 选择强密码4.2 定期更换密码4.3 启用网络加密4.4 关闭WPS4.5 隐藏SSID4.6 限制连接设备 小结 概要 在本文中,我们将介绍并展示如何使用Python脚本来测试本…...
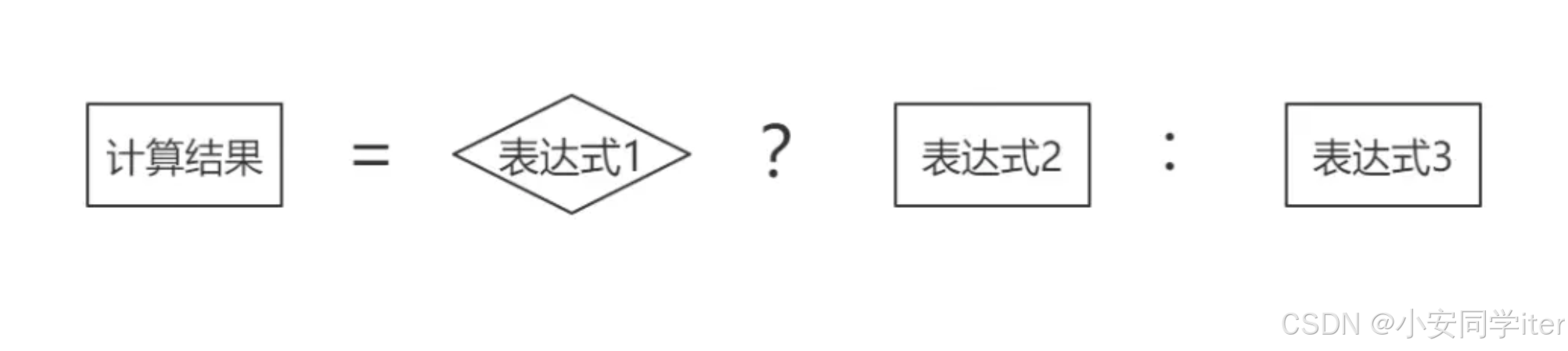
#三元运算符(python/java/c)
引入:什么是三元运算符呢?无疑其操作元有三个,一个是条件表达式,剩余两个为值,条件表达式为真时运算取第一个值,为假时取第二个值。 一 Python true_expression if condition else false_expressi…...

探索Python自然语言处理的新篇章:jionlp库介绍
探索Python自然语言处理的新篇章:jionlp库介绍 1. 背景:为什么选择jionlp? 在Python的生态中,自然语言处理(NLP)是一个活跃且不断发展的领域。jionlp是一个专注于中文自然语言处理的库,它提供了…...
Deepin系统,中盛科技温湿度模块读温度纯c程序(备份)
#include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <termios.h>int main() {int fd;struct termios options;// 打开串口设备fd open("/dev/ttyMP0", O_RDWR | O_NOCTTY|O_NDELAY); //O_NDELAY:打开设备不阻塞//O_NOCTT…...

文件包含漏洞: 函数,实例[pikachu_file_inclusion_local]
文件包含 文件包含是一种较为常见技术,允许程序员在不同的脚本或程序中重用代码或调用文件 主要作用和用途: 代码重用:通过将通用函数或代码段放入单独的文件中,可以在多个脚本中包含这些文件,避免重复编写相同代码。…...

学习计划2024下半年
基础: 学习《算法第4版》,学习leetcode上的面试经典150题,使用C完成;再看一般《深入理解计算机系统》语言: 学习go语言,并且用它写一个小软件(还没想好什么),写一个pingtool程序编程思想: 阅读经…...

RabbitMQ的学习和模拟实现|sqlite轻量级数据库的介绍和简单使用
SQLite3 项目仓库:https://github.com/ffengc/HareMQ SQLite3 什么是SQLite为什么需要用SQLite官方文档封装Helper进行一些实验 什么是SQLite SQLite是一个进程内的轻量级数据库,它实现了自给自足的、无服务器的、零配置的、事务性的 SQL数据库引擎…...
AI批量剪辑,批量发布大模型矩阵系统搭建开发
目录 前言 一、AI矩阵系统功能 二、AI批量剪辑可以解决什么问题? 总结: 前言 基于ai生成或剪辑视频的原理,利用ai将原视频进行混剪,生成新的视频素材。ai会将剪辑好的视频加上标题,批量发布到各个自媒体账号上。这…...
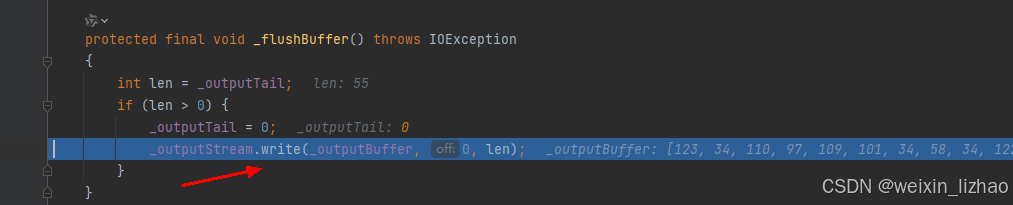
SpringMVC源码深度解析(中)
接上一遍博客《SpringMVC源码深度解析(上)》继续聊。最后聊到了SpringMVC的九大组建的初始化,以 HandlerMapping为例,SpringMVC提供了三个实现了,分别是:BeanNameUrlHandlerMapping、RequestMappingHandlerMapping、RouterFunctio…...

Mojo模型动态批处理:智能预测的终极武器
标题:Mojo模型动态批处理:智能预测的终极武器 在机器学习领域,模型的灵活性和可扩展性是至关重要的。Mojo模型(Model-as-a-Service)提供了一种将机器学习模型部署为服务的方式,允许开发者和数据科学家轻松…...

人、智能、机器人……
在遥远的未来之城,智能时代如同晨曦般照亮了每一个角落,万物互联,机器智能与人类智慧交织成一幅前所未有的图景。这座城市,既是科技的盛宴,也是人性与情感深刻反思的舞台。 寓言:《智光与心影》 在智能之…...
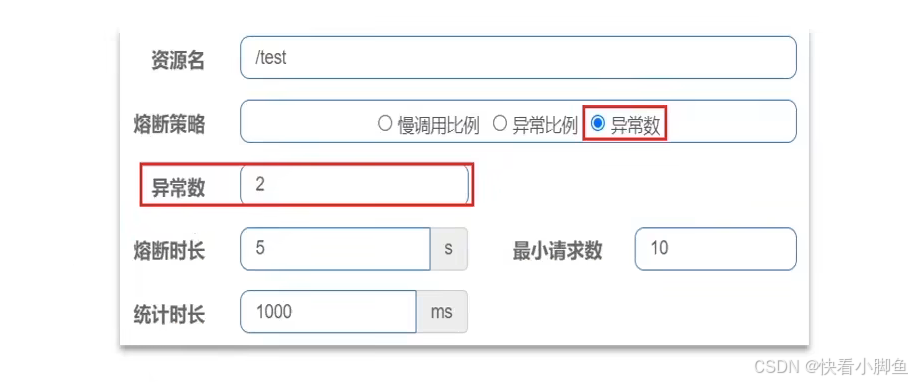
SpringCloud------Sentinel(微服务保护)
目录 雪崩问题 处理方式!!!技术选型 Sentinel 启动命令使用步骤引入依赖配置控制台地址 访问微服务触发监控 限流规则------故障预防流控模式流控效果 FeignClient整合Sentinel线程隔离-------故障处理线程池隔离和信号量隔离编辑 两种方式优缺点设置方式 熔断降级-----…...

【无标题】Elasticsearch for windows
一、windows安装Elasticsearch 1、Elasticsearch:用于存储数据、计算和搜索; 2、Logstash/Beats:用于数据搜集 3、Kibana:用于数据可视化 以上三个被称为ELK,常用语日志搜集、系统监控和状态分析 Elasticsearch安…...
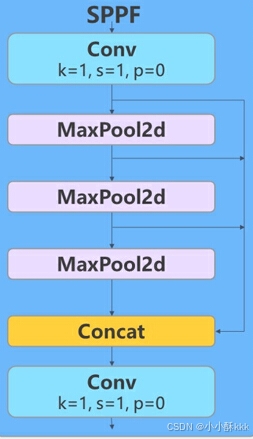
Yolo-World网络模型结构及原理分析(一)——YOLO检测器
文章目录 概要一、整体架构分析二、详细结构分析YOLO检测器1. Backbone2. Head3.各模块的过程和作用Conv卷积模块C2F模块BottleNeck模块SPPF模块Upsampling模块Concat模块 概要 尽管YOLO(You Only Look Once)系列的对象检测器在效率和实用性方面表现出色…...
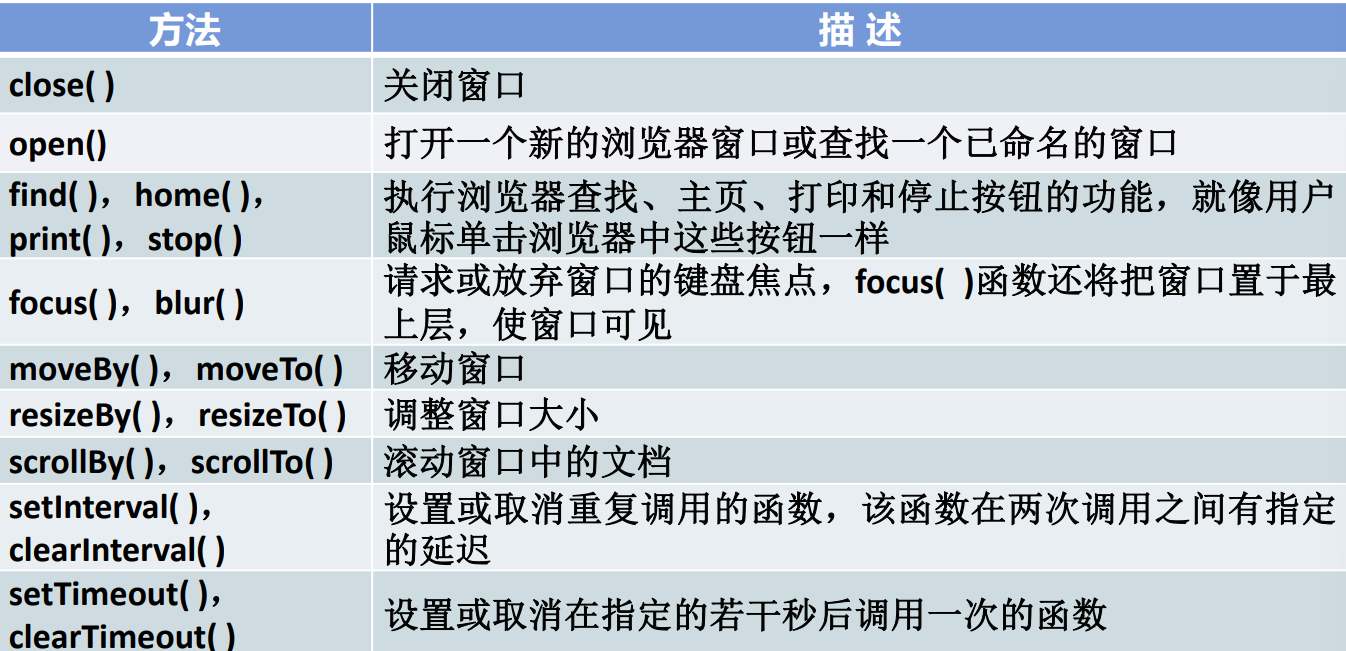
WEB前端06-BOM对象
BOM浏览器对象模型 浏览器对象模型:将浏览器的各个组成部分封装成对象。是用于描述浏览器中对象与对象之间层次关系的模型,提供了独立于页面内容、并能够与浏览器窗口进行交互的对象结构。 组成部分 Window:浏览器窗口对象 Navigator&…...

Android11 framework 禁止三方应用开机自启动
Android11应用自启动限制 大纲 Android11应用自启动限制分析验证猜想:Android11 AOSP是否自带禁止三方应用监听BOOT_COMPLETED方案禁止执行非系统应用监听到BOOT_COMPLETED后的代码逻辑在执行启动时判断其启动的广播接收器一棍子打死方案(慎用&#…...

Java | Leetcode Java题解之第263题丑数
题目: 题解: class Solution {public boolean isUgly(int n) {if (n < 0) {return false;}int[] factors {2, 3, 5};for (int factor : factors) {while (n % factor 0) {n / factor;}}return n 1;} }...

将AWS RDS MySQL实例从存储未加密改为加密的方案
问题描述: 因为AWS RDS官方文档【1】中已经明确说明,MySQL RDS的存储为EBS卷,用KMS进行RDS加密有如下限制: 您只能在创建RDS的时候,选择加密。对于已经创建的RDS实例,您无法将为加密的实例,直…...

华为云配置docker记录
浅浅记录一下配置华为云docker的步骤(内含踩雷和我使用的解决方法)作为之后万一有用的记录 略去购买华为云步骤(安全组是本身就有的,根据实际情况添加)根据华为云操作指引进行(我这里是通过Xshell远程连接了…...

影墨·今颜小红书模型计算机组成原理教学案例:用AI讲解CPU工作原理
影墨今颜小红书模型计算机组成原理教学案例:用AI讲解CPU工作原理 作为一名在计算机体系结构领域摸爬滚打了多年的工程师,我深知《计算机组成原理》这门课对很多学生来说有多“劝退”。那些抽象的寄存器、复杂的流水线、绕来绕去的寻址方式,光…...

EmbeddingGemma-300m部署教程:Ollama+Docker组合实现多实例并发嵌入服务
EmbeddingGemma-300m部署教程:OllamaDocker组合实现多实例并发嵌入服务 1. 为什么你需要一个轻量又靠谱的嵌入模型 你是不是也遇到过这些情况: 想给自己的知识库加个语义搜索,但主流大模型动辄几GB显存,笔记本直接卡死…...
)
产业链供应链论文“从0到1”写作指南:我用这套AI指令三天跑完框架(附可直接复制的Prompt)
带过四届经济学、物流管理专业毕业设计,每年3月都会被同一个问题轰炸:“老师,产业链供应链这个题太大了,我拆不动。”学生交上来的初稿,十有八九长一个样:第一章写“双循环背景”,第二章抄“波特…...

ssm+java2026年毕设求知书友屋网站【源码+论文】
本系统(程序源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容一、选题背景关于图书管理系统的研究,现有研究主要以传统单机版管理系统或简单的Web应用为主,专门针对基于SSM框架&…...

Blender4.3雕刻笔刷实战指南:从基础到进阶
1. Blender4.3雕刻笔刷入门指南 刚接触Blender雕刻功能的新手可能会被琳琅满目的笔刷搞得眼花缭乱。其实这些笔刷就像雕塑家的各种工具,每种都有独特的用途。Blender4.3版本对雕刻笔刷做了不少优化,操作响应更快,效果也更自然。 我刚开始学习…...

Z-Image-Turbo-rinaiqiao-huiyewunv镜像部署:NVIDIA NGC容器镜像同步与私有Registry托管
Z-Image-Turbo-rinaiqiao-huiyewunv镜像部署:NVIDIA NGC容器镜像同步与私有Registry托管 1. 项目概述 Z-Image Turbo (辉夜大小姐-日奈娇)是基于Tongyi-MAI Z-Image底座模型开发的专属二次元人物绘图工具。该工具通过注入辉夜大小姐(日奈娇)微调safetensors权重&a…...

从NASA Earthdata获取ASTER L2地表温度数据的完整实战指南
1. 从零开始:NASA Earthdata账号注册与准备 第一次接触遥感数据下载的朋友可能会觉得有点懵,但别担心,我刚开始也是这样。NASA Earthdata这个平台其实对科研人员非常友好,只是需要掌握几个关键步骤。先说账号注册,这就…...

从零实现Unity高级UI交互:手把手教你打造可扩展的点击管理系统
Unity高级UI交互架构:构建可扩展的点击管理系统 在游戏开发中,UI交互系统往往是项目后期最容易被技术债务拖累的模块之一。当新手开发者简单地为每个按钮添加OnClick监听时,可能不会想到随着UI复杂度增加,这种分散式管理将导致难以…...

信创CMS推荐:PageAdmin性价比高!2026国产化网站建设选型指南
在众多信创CMS选项中,PageAdmin CMS 以其高度灵活性、强大的扩展能力和持续的信创适配能力,成为中小企业、教育机构及政府事业单位的热门选择。它不仅在功能上媲美主流商业CMS,更在信创国产化进程中展现出独特的优势。 核心优势与信创亮点 1、…...