Yolo-World网络模型结构及原理分析(一)——YOLO检测器
文章目录
- 概要
- 一、整体架构分析
- 二、详细结构分析
- YOLO检测器
- 1. Backbone
- 2. Head
- 3.各模块的过程和作用
- Conv卷积模块
- C2F模块
- BottleNeck模块
- SPPF模块
- Upsampling模块
- Concat模块
概要
尽管YOLO(You Only Look Once)系列的对象检测器在效率和实用性方面表现出色,但它们通常只能检测预定义的对象类别,这限制了它们在更开放场景中的应用。
为了克服这一限制,作者提出了YOLO-World,这是一种新的方法,它通过视觉-语言建模和在大规模数据集上的预训练,增强了YOLO的开放词汇(open-vocabulary)检测能力。开放词汇检测指的是能够检测并识别在训练阶段未见过的对象类别。
下面我们通过系列文章对Yolo-World模型的网络结构及其原理进行详细分析。
一、整体架构分析
-
YOLO检测器:
(1)Darknet Backbone:YOLO-World基于YOLOv8,使用Darknet作为其图像编码器。Darknet是一个深度卷积神经网络,能够提取图像的多尺度特征。
(2)特征金字塔网络(FPN):通过路径聚合网络(PAN),YOLO-World构建了一个特征金字塔,将不同尺度的特征图进行融合,增强了模型对不同大小目标的检测能力。 -
文本编码器:
-CLIP Text Encoder:YOLO-World利用预训练的CLIP文本编码器将输入文本(如类别名称、名词短语或对象描述)编码为文本嵌入。CLIP是一个视觉-语言预训练模型,能够将文本和图像特征映射到同一语义空间。 -
RepVL-PAN(Re-parameterizable Vision-Language Path Aggregation Network):
(1)Text-guided CSPLayer:在特征金字塔的每个阶段,YOLO-World通过Text-guided CSPLayer将文本特征注入到图像特征中。具体来说,它使用文本嵌入和图像特征的点积,并通过sigmoid函数进行归一化,然后将结果与图像特征相乘,实现文本对图像特征的引导。
(2)Image-Pooling Attention:为了增强文本嵌入的图像意识,YOLO-World通过Image-Pooling Attention聚合图像特征。它使用最大池化操作从多尺度特征中提取关键区域,并将这些区域的特征通过多头注意力机制映射回文本嵌入。 -
区域-文本对比损失(Region-Text Contrastive Loss):
在训练过程中,YOLO-World通过区域-文本对比损失来优化模型。这种损失函数通过计算预测的边界框和文本嵌入之间的相似度,以及预测和真实标注之间的一致性,来训练模型识别和定位目标。 -
推理策略:
(1)在线词汇表训练:在训练阶段,YOLO-World构建在线词汇表,包含正面和负面名词,以增强模型对大型词汇表对象的识别能力。
(2)离线词汇表推理:在推理阶段,YOLO-World采用“提示-检测”范式。用户可以定义自定义提示,然后通过文本编码器编码这些提示以获得离线词汇表嵌入。这些嵌入可以重参数化为RepVL-PAN中的权重,从而提高推理效率。
二、详细结构分析
YOLO检测器
结合网络模型结构图以及代码分析一下yoloV8的网络结构

# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 第0层:使用64个3x3的卷积核,步幅为2进行卷积,得到P1/2特征图。- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 第1层:使用128个3x3的卷积核,步幅为2进行卷积,得到P2/4特征图,- [-1, 3, C2f, [128, True]] # 第2层:进行3次C2f操作,每次操作使用128个通道,最后一次操作使用降维(True)。- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 第3层:使用256个3x3的卷积核,步幅为2进行卷积,得到P3/8特征图。- [-1, 6, C2f, [256, True]] #第4层:进行6次C2f操作,每次操作使用256个通道,最后一次操作使用降维(True)。- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 第5层:使用512个3x3的卷积核,步幅为2进行卷积,得到P4/16特征图。- [-1, 6, C2f, [512, True]] #第6层:进行6次C2f操作,每次操作使用512个通道,最后一次操作使用降维(True)- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 第7层:使用1024个3x3的卷积核,步幅为2进行卷积,得到P5/32特征图。- [-1, 3, C2f, [1024, True]] #第8层:进行3次C2f操作,每次操作使用1024个通道,最后一次操作使用降维(True),- [-1, 1, SPPF, [1024, 5]] # 9 第9层:使用1024个通道的SPPF(空间金字塔池化)层,使用5个不同大小的池化核进行池化操作。
1. Backbone
(1)第0层:输入640×640×3大小的图像,使用3×3的卷积核,步幅为2,padding为1进行卷积,得到P1特征图。这里卷积的过程可以看到图示1:首先进行一次普通卷积,然后是batchNormalization归一化,最后进行的是SiLU激活函数引入非线性关系,得到320×320×64大小的图像;
(2)第1层:重复上一步过程使用128个3x3的卷积核,步幅为2进行卷积,得到P2特征图,得到160×160×128大小的图像,尺寸减半通道数加倍,通道数等于卷积核数;
(3)第2层:进行3次C2f操作图示2,每次操作使用128个通道,最后一次操作使用降维(True)。这里C2f模块接收来自上一步卷积得到的160×160×128大小的图像,首先进行一次Conv卷积,然后把输出的图像进行split切分为两份,其中一份通道数减半传到最后进行Concat操作,另一份通道数减半进入BottleNeck部分(图示3),这里需要接收参数shortcut=True or False,如果参数是True,那么就在BottleNeck中进行一次shortcut操作,也就是残差连接(这个概念可以参考resnet论文),每次BottleNeck之后都将一半的数据直接传入网络最后,另一半数据再进行一次BottleNeck,BottleNeck进行多少次取决于C2f进行多少次,也就是最开始的参数n,最后将前边处理得到的图像数据进行concat连接,这时的通道数为0.5×(n+2),在进行一次Conv卷积,将通道数变为split分割之前的通道数,也就是经过C2f模块尺寸和通道数并不会产生改变,此时输出图像尺寸为160×160×128;
(4)第3层:使用256个3x3的卷积核,padding为1,步幅为2进行卷积,得到P3特征图,此时输出图片尺寸为80×80×256。
(5)第4层:进行6次C2f操作,每次操作使用256个通道,最后一次操作使用降维(True)。此时输出图片尺寸为80×80×256。
(6)第5层:使用512个3x3的卷积核,padding为1,步幅为2进行卷积,得到P4/特征图。此时图片尺寸为40×40×512。
(7)第6层:进行6次C2f操作,每次操作使用512个通道,最后一次操作使用降维(True),此时输出图片尺寸为40×40×512。
(8)第7层:使用1024个3x3的卷积核,padding为1,,步幅为2进行卷积,得到P5特征图。此时图片尺寸为20×20×1024。
(9)第8层:进行3次C2f操作,每次操作使用1024个通道,最后一次操作使用降维(True),此时图片尺寸为20×20×1024。
(10)第9层:使用1024个通道的SPPF(空间金字塔池化)层,使用5个(代码中是5个,图片中是3个)不同大小的池化核进行池化操作。池化金字塔中先接收来自上一层的图像输入,首先进行一次卷积调整输入特征的通道数,为后续的池化操作做准备;然后进行三次最大池化,不同池化窗口如1x1、3x3、5x5等,用于捕获不同尺度的上下文信息;最后进行特征图拼接,拼接后的特征图再次通过一个1x1卷积层,以整合不同尺度的特征,得到最终的输出,此时图片尺寸为20×20×1024。
至此backbone部分结束,下边接收head部分。
2. Head
Head部分主要进行不同尺寸图像信息的融合,以便更好的获得图像特征并且进行目标检测。
(1)第10层:这里接收的图像为第9层的输出尺寸为20×20×1024,使用最近邻上采样(nn.Upsample)将特征图尺寸放大两倍,以便进行更细粒度的特征提取或与不同分辨率的特征图进行融合。其核心思想是将每个像素点复制到其周围的像素点,从而实现尺寸的放大,此时输出尺寸为40×40×1024。
(2)第11层:将backbone第6层提取的特征图与Upsample放大后的特征图进行拼接(Concat),生成新的特征图,此时输出尺寸为40×40×1024。
(3)第12层:进行3次C2f操作,在BottleNeck中不进行残差链接,此时输出尺寸为40×40×1024。
(4)第13层:同第10层操作一样,使用最近邻上采样将特征图尺寸放大两倍。此时输出尺寸为80×80×1024。
(5)第14层:将backbone第4层提取的特征图,与第13层放大后的特征图进行拼接,生成新的特征图,此时输出尺寸为80×80×1536
(6)第15层:进行3次C2f操作,不进行残差链接;
(7)后续的第16,17,18,19,20,21层进行10~15层的倒序操作,也就是通过conv操作缩小尺寸,将80×80的特征图变成20×20的特征图,并且在过程中进行C2f模块操作,concat操作拼接前边层的特征图,更好的进行特征融合,获取图片的上下文信息,最终获取到三个尺寸特征图输出,也就是80×80×1024,40×40×1024,20×20×1024,这样三个尺寸的特征图便可以检测不同大小的目标,并且含有丰富的语义特征,获取到这三个尺寸的特征图便完成了yolo-world网络模型结构中的yolo获取特征图的部分,后续还有进行边界框回归的部分,留在后边进行说明;
----------------------------------分割线-------------------------------------
此部分如果有写的不对的地方请各位在评论中指出,我会认真修改,感谢各位大佬!
3.各模块的过程和作用
图示1 卷积模块过程

Conv卷积模块
如图是一个典型的卷积神经网络(CNN)层的卷积过程,其中包括卷积层(Conv)、批量归一化层(BatchNorm2d)和激活函数(SiLU)
(1)卷积层(Conv):
- 核大小(k):卷积核的尺寸,通常用 ( k \times k ) 表示。
- 步长(s):卷积时滑动的步长,步长为1意味着每次滑动一个像素。
- 填充(p):卷积核边缘的填充大小,填充为0通常意味着没有额外的填充。
- 输出通道数(c):卷积层输出特征图的通道数。
(2)卷积操作(Conv2d): - 卷积操作是深度学习中的基本操作之一,用于提取图像的局部特征。
- 在二维卷积(Conv2d)中,卷积核在输入特征图的每个位置滑动,并计算卷积核与输入特征图对应部分的点积,生成新的输出特征图。
(3)批量归一化层(BatchNorm2d): - 批量归一化是一种技术,用于加速训练过程并提高模型的稳定性。
- 它通过规范化(归一化)层的输入来减少内部协变量偏移(即不同训练样本的尺度和分布差异)。
- BatchNorm2d通常在卷积层之后应用,对每个特征通道的输出进行归一化处理。
(4)激活函数(SiLU): - SiLU(Sigmoid线性单元)是一种非线性激活函数;
- 它将输入特征图的每个元素通过SiLU函数进行非线性变换,增加网络的非线性表达能力。
(5)整体流程: - 输入特征图首先通过卷积层,卷积核在特征图上滑动,提取局部特征。
- 卷积后的输出特征图通过批量归一化层进行归一化处理,减少不同批次数据的分布差异。
- 最后,归一化后的特征图通过SiLU激活函数进行非线性变换,生成最终的输出特征图。
图示2 C2F结构展示

C2F模块
(1)输入特征:模块接收尺寸为 h×w、通道数为 c_in 的特征图。
(2)1x1卷积:
特征图通过一个核大小为1(k=1)、步长为1(s=1)、填充为0(p=0)的卷积层,输出通道数为 c_out。
(3)通道分割:
输出特征图被分割成两个子特征图,每个子特征图的通道数为 c_out/2。
(4)瓶颈层(Bottleneck):
每个子特征图通过瓶颈层进行处理,瓶颈层通常包含深度可分离卷积或其他轻量化的卷积操作,以减少计算量并提取特征。
(5)跨阶段连接(Cross-stage Connections):
在瓶颈层之后,特征图的尺寸减半,但通道数保持不变。图片中的 “shortcut=?” 表示这里存在某种形式的残差连接或跳跃连接,具体细节见下边BottleNeck解释。
(6)特征拼接(Concatenation):
处理后的两个子特征图被拼接回一起,得到尺寸为 h×w、通道数为c_out/2×(n + 2)的特征图,其中n是一个与模块设计相关的参数。
(7)最终1x1卷积:
最后,拼接后的特征图再次通过一个1x1卷积层,输出最终的特征图,尺寸保持不变,通道数为c_out。
(8)C2F输出:
C2F模块的输出是经过这些处理步骤后的特征图,这些特征图具有增强的特征表示能力,可以用于后续的目标检测任务。
C2F模块的设计意图是通过轻量化的卷积操作和特征融合,提高网络的计算效率和特征提取能力。这种模块可能在YOLOv8的多个地方使用,以确保在不同尺度的特征图中都能有效地提取有用的信息。 “shortcut” 指的是残差连接,用于帮助网络学习输入和输出之间的残差,从而提高网络的学习能力和稳定性。
图示3 BottleNeck模块

BottleNeck模块
Bottleneck模块是一种常见的网络结构,用于减少参数数量和计算量,同时保持或提升特征表达能力。以下是Bottleneck模块的两种变体的过程介绍:
(1)输入特征:模块接收尺寸为 h×w、通道数为 c的特征图。
(2)第一个3x3卷积:
特征图首先通过一个核大小为3( k=3)、步长为1( s=1)、填充为1( p=1)的卷积层。
(3)第二个3x3卷积:
紧接着,输出特征图再次通过一个相同配置的3x3卷积层。
(4)Shortcut连接:
由于shortcut=True,原始输入特征图与经过两个卷积层的输出特征图进行相加。这允许梯度直接从输出传递回输入,有助于解决深层网络中的梯度消失问题。
(5)输出特征:
最终输出的特征图尺寸仍为 h×w,通道数保持不变为c。
对于不带Shortcut的Bottleneck模块:只进行两次卷积过程后输出特征,不进行shortcut连接
注:shortcut通用特点:
- 深度和参数效率:Bottleneck模块通过先压缩后扩展的卷积操作,减少了参数数量和计算量。
- 特征不变性:带Shortcut的Bottleneck模块通过残差连接保持了输入和输出的尺寸和通道数不变。
- 计算效率:使用3x3卷积可以在减少特征图尺寸的同时,捕获足够的局部空间信息。
- 适用性:Bottleneck模块常用于深度学习网络中,尤其是在需要处理高分辨率输入时,如图像分类和目标检测任务。
图示4 SPPF过程
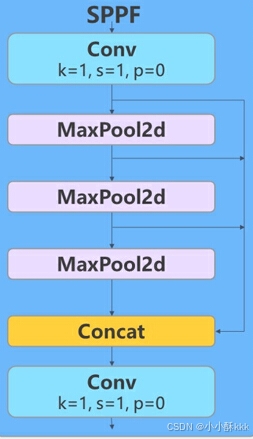
SPPF模块
一种改进的空间金字塔池化模块。
(1)输入特征:
模块接收尺寸为 h×w、通道数为 c的特征图。
(2)1x1卷积:
首先,特征图通过一个1x1卷积层,核大小为1( k=1)、步长为1( s=1 )、填充为0(p=0)。这个卷积层可以调整输入特征的通道数,为后续的池化操作做准备。
(3)空间金字塔池化(Spatial Pyramid Pooling):
接着,特征图经过三次不同的最大池化操作(MaxPool2d)。这些池化操作通常具有不同的窗口大小,例如1x1、3x3、5x5等,用于捕获不同尺度的上下文信息。
每个最大池化层都会在特征图上应用一个固定大小的窗口,并输出该窗口内的最大值,这有助于提取多尺度的特征。
(4)特征图拼接(Concatenation):
池化操作后,得到的多个不同尺度的特征图被拼接在一起。这样,网络就可以在后续层中同时考虑到局部特征和全局上下文信息。
(5)最终1x1卷积:
最后,拼接后的特征图再次通过一个1x1卷积层,以整合不同尺度的特征,并输出最终的特征图。
(6)SPPF输出:
SPPF模块的输出是一个综合了多尺度信息的特征图,这个特征图可以提供更丰富的上下文信息,有助于提高目标检测的准确性。
SPPF模块是通过多尺度的池化操作捕获图像中的全局和局部特征,然后将这些特征有效地融合在一起。这种模块在目标检测网络中非常有用,因为它可以帮助模型更好地理解不同尺寸的物体,从而提高检测性能。
Upsampling模块
在深度学习中,上采样(Upsampling)是一种常用的技术,用于将特征图的尺寸放大,以便进行更细粒度的特征提取或与不同分辨率的特征图进行融合。最近邻上采样(Nearest Neighbor Upsampling)是一种简单的上采样方法,其核心思想是将每个像素点复制到其周围的像素点,从而实现尺寸的放大。
以下是使用最近邻上采样将特征图尺寸放大两倍的基本步骤:
(1)确定上采样的尺寸:
- 假设原始特征图的尺寸为 h×w×c
- 目标是将特征图的尺寸放大两倍,因此新的尺寸将是2h×2w
(2)应用最近邻上采样: - 对于每个像素点 (x,y) 在原始特征图中,复制其值到新特征图中的(2x,2y)位置。
- 这样,每个像素点在水平和垂直方向上都会被复制一次,从而实现尺寸的放大。
(3)填充边缘: - 在新特征图的边缘,可能没有足够的像素点可以复制。在这种情况下,可以选择复制最近的像素点,或者简单地复制最后一个像素点。
(4)实现代码: - 在PyTorch中,可以使用
nn.Upsample模块来实现最近邻上采样。以下是一个示例代码:
import torch
import torch.nn as nn# 定义原始特征图
original_feature_map = torch.randn(1, 3, 10, 10) # 假设有3个通道,10x10的尺寸# 创建上采样模块,模式为最近邻
upsample = nn.Upsample(scale_factor=2, mode='nearest')# 应用上采样
upscaled_feature_map = upsample(original_feature_map)# 打印结果
print("Original Feature Map Shape:", original_feature_map.shape)
print("Upsampled Feature Map Shape:", upscaled_feature_map.shape)
Concat模块
在深度卷积神经网络中,concat模块用于将来自不同层或不同尺度的特征图在通道维度上进行拼接。这种操作有助于融合多层次、多尺度的信息,从而增强模型的特征表达能力和检测性能。
(1)特征提取:从不同的网络层提取特征图,这些特征图可能来自不同的卷积层或不同的检测头。
(2)尺寸匹配:对特征图进行尺寸调整,使它们在空间维度上具有相同的宽度和高度。
(3)拼接操作:在通道维度上将这些特征图拼接在一起,形成一个新的特征图。
concat模块主要用于以下几个方面:
(1)特征融合:将来自不同尺度的特征图拼接在一起,以提高模型对不同大小目标的检测能力。
(2)跨层连接:将低层的细节特征与高层的语义特征结合起来,增强模型的特征表达能力。
(3)多任务学习:在多任务学习场景中,concat模块可以将来自不同任务的特征图拼接在一起,进行联合训练。
相关文章:
Yolo-World网络模型结构及原理分析(一)——YOLO检测器
文章目录 概要一、整体架构分析二、详细结构分析YOLO检测器1. Backbone2. Head3.各模块的过程和作用Conv卷积模块C2F模块BottleNeck模块SPPF模块Upsampling模块Concat模块 概要 尽管YOLO(You Only Look Once)系列的对象检测器在效率和实用性方面表现出色…...
WEB前端06-BOM对象
BOM浏览器对象模型 浏览器对象模型:将浏览器的各个组成部分封装成对象。是用于描述浏览器中对象与对象之间层次关系的模型,提供了独立于页面内容、并能够与浏览器窗口进行交互的对象结构。 组成部分 Window:浏览器窗口对象 Navigator&…...

Android11 framework 禁止三方应用开机自启动
Android11应用自启动限制 大纲 Android11应用自启动限制分析验证猜想:Android11 AOSP是否自带禁止三方应用监听BOOT_COMPLETED方案禁止执行非系统应用监听到BOOT_COMPLETED后的代码逻辑在执行启动时判断其启动的广播接收器一棍子打死方案(慎用&#…...

Java | Leetcode Java题解之第263题丑数
题目: 题解: class Solution {public boolean isUgly(int n) {if (n < 0) {return false;}int[] factors {2, 3, 5};for (int factor : factors) {while (n % factor 0) {n / factor;}}return n 1;} }...

将AWS RDS MySQL实例从存储未加密改为加密的方案
问题描述: 因为AWS RDS官方文档【1】中已经明确说明,MySQL RDS的存储为EBS卷,用KMS进行RDS加密有如下限制: 您只能在创建RDS的时候,选择加密。对于已经创建的RDS实例,您无法将为加密的实例,直…...

nginx的配置:TLSv1 TLSv1.1 被暴露不安全
要在 Nginx 配置中禁用不安全的 SSL 协议(如 TLSv1 和 TLSv1.1),并仅启用更安全的协议(如 TLSv1.2 和 TLSv1.3),您可以更新您的 Nginx 配置文件。下面是一个示例配置: # 位于 Nginx 配置文件 (…...

揭开黑箱:目标检测中可解释性的重要性与实现
揭开黑箱:目标检测中可解释性的重要性与实现 在深度学习的目标检测任务中,模型的准确性虽然重要,但模型的决策过程是否透明也同样关键。可解释性(Explainability)是指模型能够为其预测结果提供清晰、可理解的解释。本…...
Mysql高价语句
一.高级语法的查询语句 1.排序语法(默认的排序方式就是升序)。 升序ASC:select * from test01 order by name; 降序DESC:select * from test01 order by name desc; 多个列排序:以多个列作为排序,只有第一…...
几何 6 包络)
ArcGIS Pro SDK (九)几何 6 包络
ArcGIS Pro SDK (九)几何 6 包络 文章目录 ArcGIS Pro SDK (九)几何 6 包络1 构造包络2 构造包络 - 从 JSON 字符串3 合并两个包络4 与两个包络相交5 展开包络6 更新包络的坐标 环境:Visual Studio 2022 .NET6 ArcGI…...
单链表<数据结构 C版>
目录 概念 链表的单个结点 链表的打印操作 新结点的申请 尾部插入 头部插入 尾部删除 头部删除 查找 在指定位置之前插入数据 在任意位置之后插入数据 测试运行一下: 删除pos结点 删除pos之后结点 销毁链表 概念 单链表是一种在物理存储结构上非连续、非顺序…...
监控电脑进程,避免程序在打开前就已经在运行
文章目录 一、文章的目的(适用于windows)二、处理方式三、进程查看的内容在窗口端的演示四、附上代码例子四、通过os.kill的方式,再回到原来的表格时,会出现如下错误提示: 一、文章的目的(适用于windows&am…...

【MySQL进阶篇】存储对象:视图、存储过程及触发器
一、视图 1、介绍 视图(view)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来定义视图的查询中使用的表(基表),并且是在使用视图时动态生成的。 通俗的讲,视图只保存了…...
算法day05 master公式估算递归时间复杂度 归并排序 小和问题 堆排序
2.认识O(NlogN)的排序_哔哩哔哩_bilibili master公式 有这样一个数组:【0,4,2,3,3,1,2】;假设实现了这样一个sort()排序方法, 将数组二分成左右两等分,使用so…...
基于jeecgboot-vue3的Flowable流程仿钉钉流程设计器-支持VForm3表单的选择与支持
因为这个项目license问题无法开源,更多技术支持与服务请加入我的知识星球。 1、初始化的时候加载表单 /** 查询表单列表 */ const getFormList () > {listForm().then(res > formOptions.value res.result.records) } 2、开始节点的修改,增加表…...
【刷题汇总 -- 压缩字符串(一)、chika和蜜柑、 01背包】
C日常刷题积累 今日刷题汇总 - day0181、压缩字符串(一)1.1、题目1.2、思路1.3、程序实现 2、chika和蜜柑2.1、题目2.2、思路2.3、程序实现 3、 01背包3.1、题目3.2、思路3.3、程序实现 -- dp 4、题目链接 今日刷题汇总 - day018 1、压缩字符串(一) 1.1、题目 1.2、思路 读完…...

《Exploring Aligned Complementary Image Pair for Blind Motion Deblurring》
这篇论文的标题《Exploring Aligned Complementary Image Pair for Blind Motion Deblurring》可以翻译为《探索对齐的互补图像对用于盲运动去模糊》。从标题可以推断,论文的焦点在于开发一种算法或技术,利用成对的图像来解决运动模糊问题,特别是在不知道模糊核(即造成模糊…...
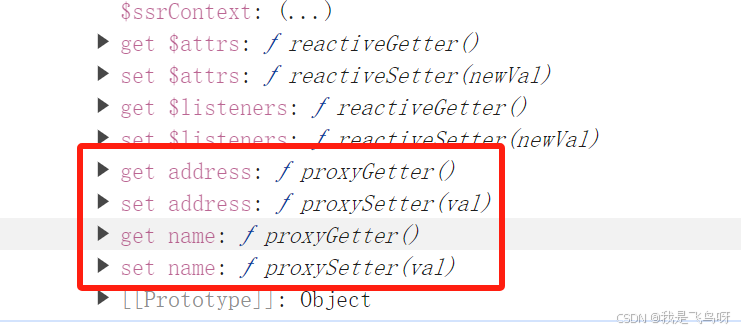
vue2学习笔记9 - 通过观察vue实例中的data,理解Vue中的数据代理
接着上一节,学一学vue中的数据代理。学vue这几天,最大的感受就是,名词众多,听得发懵。。不过,深入理解之后,其实说得都是一回事。 在Vue中,数据代理是指在实例化Vue对象时,将data对…...
04 Git与远程仓库
第4章:Git与远程仓库 一、Gitee介绍及创建仓库 一)获取远程仓库 使用在线的代码托管平台,如Gitee(码云)、GitHub等 自行搭建Git代码托管平台,如GitLab 二)Gitee创建仓库 gitee官…...
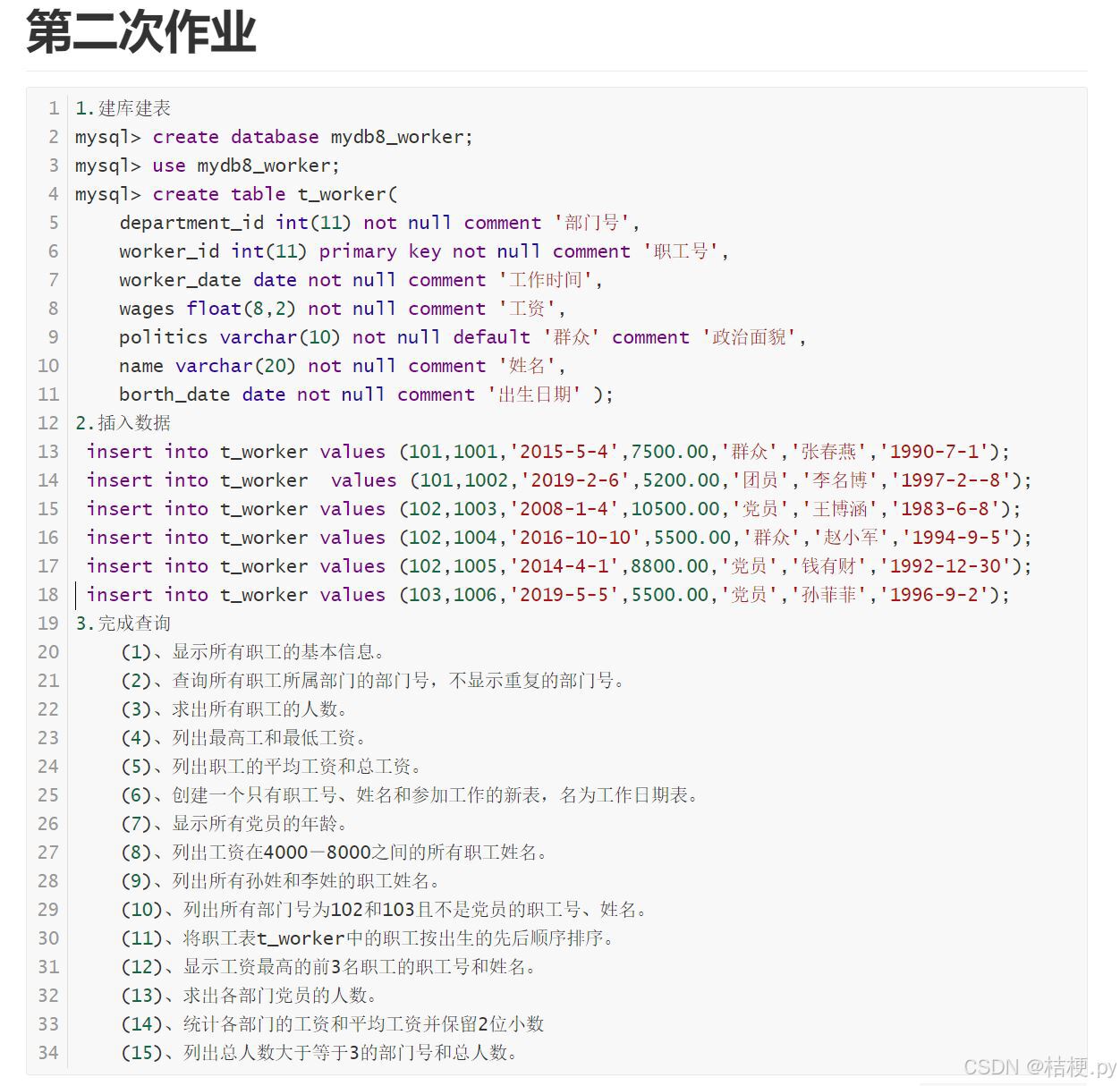
数据库之表的查询
一.新建表: mysql> create table t_worker(-> department_id int(11) not null comment部门号,-> worker_id int(11) primary key not null comment职工号,-> worker_date date not null comment工作时间,-> wages float(8,2) not null comment工资,…...
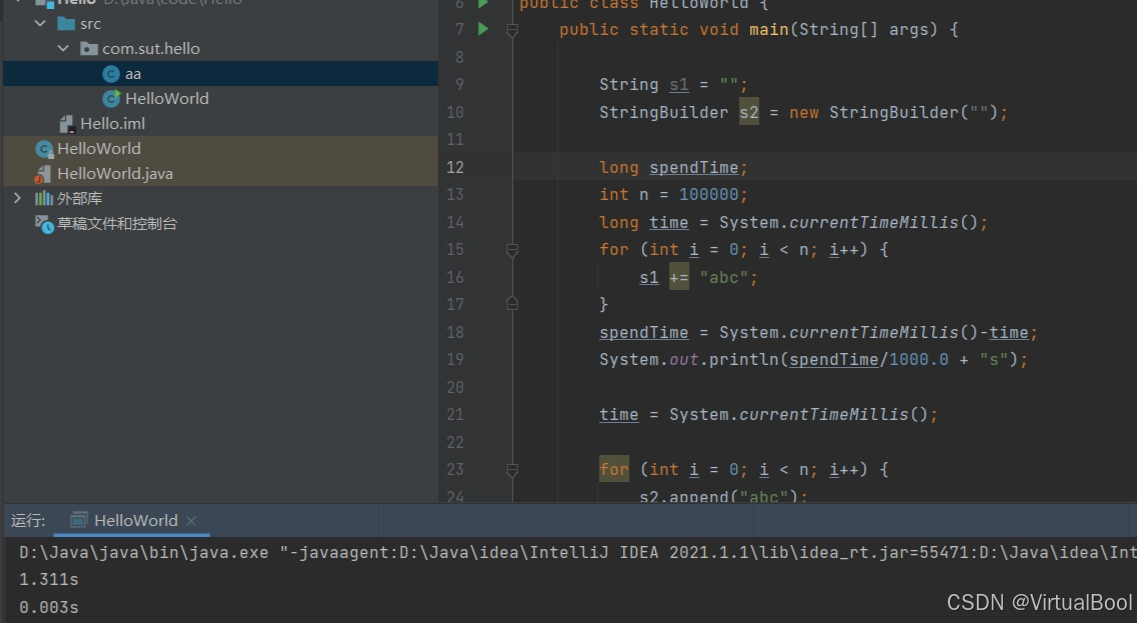
String 和StringBuilder字符串操作快慢的举例比较
System.currentTimeMillis(); //当前时间与1970年1月1日午夜UTC之间的毫秒差。public class HelloWorld {public static void main(String[] args) {String s1 "";StringBuilder s2 new StringBuilder("");long time System.currentTimeMillis();long s…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...