flink多流操作(connect cogroup union broadcast)
flink多流操作
- 1 分流操作
- 2 connect连接操作
- 2.1 connect 连接(DataStream,DataStream→ConnectedStreams)
- 2.2 coMap(ConnectedStreams → DataStream)
- 2.3 coFlatMap(ConnectedStreams → DataStream)
- 3 union操作
- 3.1 union 合并(DataStream * → DataStream)
- 4 coGroup 协同分组
- 4.1 coGroup 实现 left join操作
- 5 join
- 6 broadcast 广播
- 6.1 API 介绍 , 核心要点
1 分流操作
SingleOutputStreamOperator<Student> mainStream = students.process(new ProcessFunction<Student, Student>() {@Overridepublic void processElement(Student student, ProcessFunction<Student, Student>.Context ctx, Collector<Student> collector) throws Exception {if (student.getGender().equals("m")) {// 输出到测流ctx.output(maleOutputTag, student);} else if (student.getGender().equals("f")) {// 输出到测流ctx.output(femaleOutputTag, student.toString());} else {// 在主流中输出collector.collect(student);}}
});SingleOutputStreamOperator<Student> side1 = mainStream.getSideOutput(maleOutputTag);
SingleOutputStreamOperator<String> side2 = mainStream.getSideOutput(femaleOutputTag);2 connect连接操作
2.1 connect 连接(DataStream,DataStream→ConnectedStreams)
connect 翻译成中文意为连接,可以将两个数据类型一样也可以类型不一样 DataStream 连接成一个新 的 ConnectedStreams。需要注意的是,connect 方法与 union 方法不同,虽然调用 connect 方法将两个 流连接成一个新的 ConnectedStreams,但是里面的两个流依然是相互独立的,这个方法最大的好处是 可以让两个流共享 State 状态。
// 使用 fromElements 创建两个 DataStream
DataStreamSource<String> word = env.fromElements("a", "b", "c", "d");
DataStreamSource<Integer> num = env.fromElements(1, 3, 5, 7, 9);// 将两个 DataStream 连接到一起
ConnectedStreams<String, Integer> connected = word.connect(num);2.2 coMap(ConnectedStreams → DataStream)
对 ConnectedStreams 调用 map 方法时需要传入 CoMapFunction 函数;
该接口需要指定 3 个泛型:
- 第一个输入 DataStream 的数据类型
- 第二个输入 DataStream 的数据类型
- 返回结果的数据类型。
该接口需要重写两个方法: - map1 方法,是对第 1 个流进行 map 的处理逻辑。
- 2 map2 方法,是对 2 个流进行 map 的处理逻辑
这两个方法必须是相同的返回值类型。
//将两个 DataStream 连接到一起ConnectedStreams<String, Integer> wordAndNum = word.connect(num);// 对 ConnectedStreams 中两个流分别调用个不同逻辑的 map 方法
DataStream<String> result = wordAndNum.map(new CoMapFunction<String, Integer, String>() {@Overridepublic String map1(String value) throws Exception {// 第一个 map 方法是将第一个流的字符变大写return value.toUpperCase();}@Overridepublic String map2(Integer value) throws Exception {// 第二个 map 方法将是第二个流的数字乘以 10 并转成 Stringreturn String.valueOf(value * 10);}
});2.3 coFlatMap(ConnectedStreams → DataStream)
对 ConnectedStreams 调用 flatMap 方法。调用 flatMap 方法,传入的 Function 是 CoFlatMapFunction;
这个接口要重写两个方法:
- flatMap1 方法,是对第 1 个流进行 flatMap 的处理逻辑;
- flatMap2 方法,是对 2 个流进行 flatMap 的处理逻辑;
这两个方法都必须返回是相同的类型。
// 使用 fromElements 创建两个 DataStream
DataStreamSource<String> word = env.fromElements("a b c", "d e f");
DataStreamSource<String> num = env.fromElements("1,2,3", "4,5,6");// 将两个 DataStream 连接到一起
ConnectedStreams<String, String> connected = word.connect(num);// 对 ConnectedStreams 中两个流分别调用个不同逻辑的 flatMap 方法
DataStream<String> result = connected.flatMap(new CoFlatMapFunction<String, String, String>() {@Overridepublic void flatMap1(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String w : words) {out.collect(w);}}@Overridepublic void flatMap2(String value, Collector<String> out) throws Exception {String[] nums = value.split(",");for (String n : nums) {out.collect(n);}}
});3 union操作
3.1 union 合并(DataStream * → DataStream)
该方法可以将两个或者多个数据类型一致的 DataStream 合并成一个 DataStream。DataStream union(DataStream… streams)可以看出 DataStream 的 union 方法的参数为可变参数,即可以合并两 个或多个数据类型一致的 DataStream,connect 不要求两个流的类型一致,但union必须一致。
下面的例子是使用 fromElements 生成两个 DataStream,一个是基数的,一个是偶数的,然后将两个 DataStream 合并成一个 DataStream。
// 使用 fromElements 创建两个 DataStream
DataStreamSource<Integer> odd = env.fromElements(1, 3, 5, 7, 9);
DataStreamSource<Integer> even = env.fromElements(2, 4, 6, 8, 10);// 将两个 DataStream 合并到一起
DataStream<Integer> result = odd.union(even);4 coGroup 协同分组
coGroup 本质上是join 算子的底层算子;功能类似;可以用cogroup来实现join left join full join的功能。 代码结构如下:
DataStreamSource<String> stream1 = env.fromElements("1,aa,m,18", "2,bb,m,28", "3,cc,f,38");
DataStreamSource<String> stream2 = env.fromElements("1:aa:m:18", "2:bb:m:28", "3:cc:f:38");DataStream<String> res = stream1.coGroup(stream2).where(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value;}}).equalTo(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value;}}).window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(new CoGroupFunction<String, String, String>() {@Overridepublic void coGroup(Iterable<String> first, Iterable<String> second, Collector<String> out) throws Exception {// 这里添加具体的 coGroup 处理逻辑// 这两个迭代器,是这5s的数据中的某一组,id = 1}});
4.1 coGroup 实现 left join操作
package batch;import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;public class coGrouptest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// id nameDataStreamSource<String> stream1 = env.socketTextStream("localhost", 9998);
// id ageDataStreamSource<String> stream2 = env.socketTextStream("localhost", 9999);
// nc -lp 9999
// nc -lp 9998SingleOutputStreamOperator<Tuple2<String, String>> s1 = stream1.map(s -> {String[] arr = s.split(",");return Tuple2.of(arr[0], arr[1]);}).returns(new TypeHint<Tuple2<String, String>>() {});SingleOutputStreamOperator<Tuple2<String, String>> s2 = stream2.map(s -> {String[] arr = s.split(",");return Tuple2.of(arr[0], arr[1]);}).returns(new TypeHint<Tuple2<String, String>>() {});DataStream<Tuple3<String, String, String>> out = s1.coGroup(s2).where(tp -> tp.f0) //左的f0 id 字段.equalTo(tp -> tp.f0) //又的f0 id 字段.window(TumblingProcessingTimeWindows.of(Time.seconds(2))).apply(new CoGroupFunction<Tuple2<String, String>, Tuple2<String, String>, Tuple3<String, String, String>>() {@Overridepublic void coGroup(Iterable<Tuple2<String, String>> iterable, Iterable<Tuple2<String, String>> iterable1, Collector<Tuple3<String, String, String>> out) throws Exception {for (Tuple2<String, String> t1 : iterable) {boolean t2isnull = false;for (Tuple2<String, String> t2 : iterable1) {out.collect(new Tuple3<String, String, String>(t1.f0,t1.f1,t2.f1));t2isnull = true;}if(!t2isnull){out.collect(new Tuple3<String, String, String>(t1.f0,t1.f1,null));}}}});out.print();env.execute();}
}5 join
用于关联两个流(类似于 sql 中 join),需要指定 join,需要在窗口中进行关联后的逻辑计算。
只能支持inner join 不支持 左右和全连接
stream.join(otherStream).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>);实例:
SingleOutputStreamOperator<Student> s1;
SingleOutputStreamOperator<StuInfo> s2;// join 两个流,此时并没有具体的计算逻辑
JoinedStreams<Student, StuInfo> joined = s1.join(s2);// 对 join 流进行计算处理
DataStream<String> stream = joined// where 流 1 的某字段 equalTo 流 2 的某字段.where(s -> s.getId()).equalTo(s -> s.getId())// join 实质上只能在窗口中进行.window(TumblingProcessingTimeWindows.of(Time.seconds(20)))// 对窗口中满足关联条件的数据进行计算.apply(new JoinFunction<Student, StuInfo, String>() {// 这边传入的两个流的两条数据,是能够满足关联条件的@Overridepublic String join(Student first, StuInfo second) throws Exception {// first: 左流数据 ; second: 右流数据// 计算逻辑// 返回结果return null;}});// 对 join 流进行计算处理
joined.where(s -> s.getId()).equalTo(s -> s.getId()).window(TumblingProcessingTimeWindows.of(Time.seconds(20))).apply(new FlatJoinFunction<Student, StuInfo, String>() {@Overridepublic void join(Student first, StuInfo second, Collector<String> out) throws Exception {out.collect();}});6 broadcast 广播
Broadcast State 是 Flink 1.5 引入的新特性。 在开发过程中,如果遇到需要下发/广播配置、规则等低吞吐事件流到下游所有 task 时,就可以使用Broadcast State 特性。下游的 task 接收这些配置、规则并保存为 BroadcastState, 将这些配置应用到 另一个数据流的计算中 。
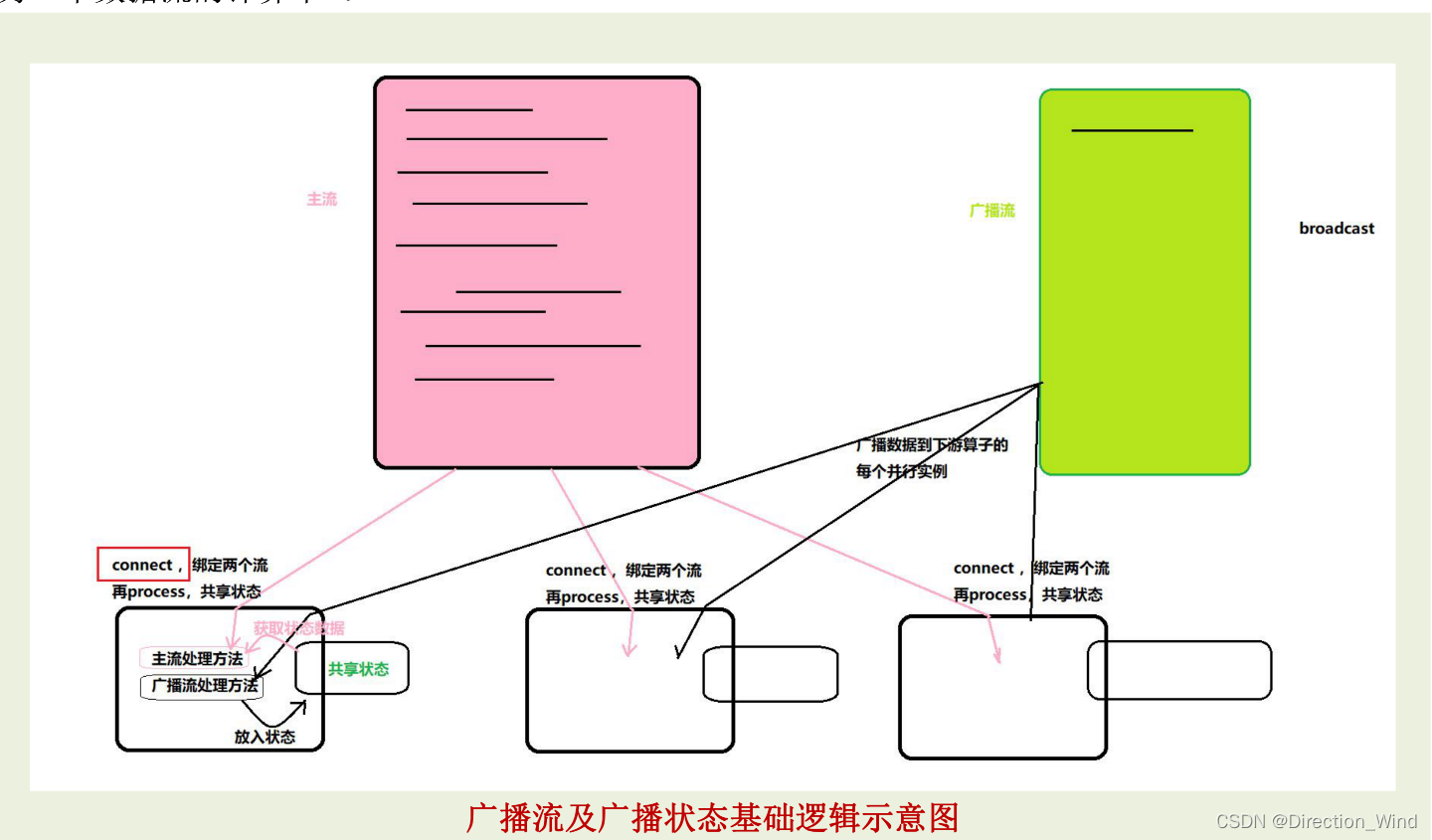
6.1 API 介绍 , 核心要点
- 将需要广播出去的流,调用 broadcast 方法进行广播转换,得到广播流 BroadCastStream
- 然后在主流上调用 connect 算子,来连接广播流(以实现广播状态的共享处理)
- 在连接流上调用 process 算子,就会在同一个 ProcessFunciton 中提供两个方法分别对两个流进行 处理,并在这个 ProcessFunction 内实现“广播状态”的共享
public class _16_BroadCast_Demo {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();configuration.setInteger("rest.port", 8822);StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);env.setParallelism(1);// id,eventIdDataStreamSource<String> stream1 = env.socketTextStream("localhost", 9998);SingleOutputStreamOperator<Tuple2<String, String>> s1 = stream1.map(s -> {String[] arr = s.split(",");return Tuple2.of(arr[0], arr[1]);}).returns(new TypeHint<Tuple2<String, String>>() { });// id,age,cityDataStreamSource<String> stream2 = env.socketTextStream("localhost", 9999);SingleOutputStreamOperator<Tuple3<String, String, String>> s2 = stream2.map(s -> {String[] arr = s.split(",");return Tuple3.of(arr[0], arr[1], arr[2]);}).returns(new TypeHint<Tuple3<String, String, String>>() { });/*** 案例背景:* 流 1: 用户行为事件流(持续不断,同一个人也会反复出现,出现次数不定* 流 2: 用户维度信息(年龄,城市),同一个人的数据只会来一次,来的时间也不定 (作为广播流)* 需要加工流 1,把用户的维度信息填充好,利用广播流来实现*/// 将字典数据所在流: s2 , 转成 广播流MapStateDescriptor<String, Tuple2<String, String>> userInfoStateDesc =new MapStateDescriptor<>("userInfoStateDesc", TypeInformation.of(String.class),TypeInformation.of(new TypeHint<Tuple2<String, String>>() {}));BroadcastStream<Tuple3<String, String, String>> s2BroadcastStream = s2.broadcast(userInfoStateDesc);// 哪个流处理中需要用到广播状态数据,就要 去 连接 connect 这个广播流SingleOutputStreamOperator<String> connected = s1.connect(s2BroadcastStream).process(new BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {/**BroadcastState<String, Tuple2<String, String>> broadcastState;*//*** 本方法,是用来处理 主流中的数据(每来一条,调用一次)* @param element 左流(主流)中的一条数据* @param ctx 上下文* @param out 输出器* @throws Exception*/@Overridepublic void processElement(Tuple2<String, String> element,BroadcastProcessFunction<Tuple2<String, String>,Tuple3<String, String, String>, String>.ReadOnlyContext ctx,Collector<String> out) throws Exception {// 通过 ReadOnlyContext ctx 取到的广播状态对象,是一个 “只读 ” 的对象;ReadOnlyBroadcastState<String, Tuple2<String, String>> broadcastState = ctx.getBroadcastState(userInfoStateDesc);if (broadcastState != null) {Tuple2<String, String> userInfo = broadcastState.get(element.f0);out.collect(element.f0 + "," + element.f1 + "," + (userInfo == null ? null : userInfo.f0) + "," + (userInfo == null ? null : userInfo.f1));} else { out.collect(element.f0 + "," + element.f1 + "," + null + "," + null);}}/**** * @param element 广播流中的一条数据 * @param ctx 上下文 * @param out 输出器 * @throws Exception */ @Override public void processBroadcastElement(Tuple3<String, String, String> element, BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>.Context ctx, Collector<String> out) throws Exception { // 从上下文中,获取广播状态对象(可读可写的状态对象) BroadcastState<String, Tuple2<String, String>> broadcastState = ctx.getBroadcastState(userInfoStateDesc); // 然后将获得的这条广播流数据,拆分后,装入广播状态 broadcastState.put(element.f0, Tuple2.of(element.f1, element.f2)); }resultStream.print(); env.execute(); }}相关文章:
flink多流操作(connect cogroup union broadcast)
flink多流操作1 分流操作2 connect连接操作2.1 connect 连接(DataStream,DataStream→ConnectedStreams)2.2 coMap(ConnectedStreams → DataStream)2.3 coFlatMap(ConnectedStreams → DataStream)3 union操作3.1 uni…...

漫画:什么是快速排序算法?
这篇文章,以对话的方式,详细着讲解了快速排序以及排序排序的一些优化。 一禅:归并排序是一种基于分治思想的排序,处理的时候可以采取递归的方式来处理子问题。我弄个例子吧,好理解点。例如对于这个数组arr[] { 4&…...

vue 3.0组件(下)
文章目录前言:一,透传属性和事件1. 如何“透传属性和事件”2.如何禁止“透传属性和事件”3.多根元素的“透传属性和事件”4. 访问“透传属性和事件”二,插槽1. 什么是插槽2. 具名插槽3. 作用域插槽三,单文件组件CSS功能1. 组件作用…...
双指针 -876. 链表的中间结点-leetcode
开始一个专栏,写自己的博客 双指针,也算是作为自己的笔记吧! 双指针从广义上来说,是指用两个变量在线性结构上遍历而解决的问题。狭义上说, 对于数组,指两个变量在数组上相向移动解决的问题;对…...

Linux之运行级别
文章目录一、指定运行级别基本介绍CentOS7后运行级别说明一、指定运行级别 基本介绍 运行级别说明: 0:关机 1:单用户【找回丢失密码】 2:多用户状态没有网络服务 3:多用户状态有网络服务 4:系统未使用保留给用户 5:图形界面 6:系统重启 常用运行级别是3和5,也可以…...

python搭建web服务器
前言:相信看到这篇文章的小伙伴都或多或少有一些编程基础,懂得一些linux的基本命令了吧,本篇文章将带领大家服务器如何部署一个使用django框架开发的一个网站进行云服务器端的部署。 文章使用到的的工具 Python:一种编程语言&…...
【SpringCloud】SpringCloud Feign详解
目录前言SpringCloud Feign远程服务调用一.远程调用逻辑图二.两个服务的yml配置和访问路径三.使用RestTemplate远程调用四.构建Feign五.自定义Feign配置六.Feign配置日志七.Feign调优八.抽离Feign前言 微服务分解成多个不同的服务,那么多个服务之间怎么调用呢&…...

更改Hive元数据发生的生产事故
今天同事想在hive里用中文做为分区字段。如果用中文做分区字段的话,就需要更改Hive元 数据库。结果发生了生产事故。导致无法删除表和删除分区。记一下。 修改hive元数据库的编码方式为utf后可以支持中文,执行以下语句: alter table PARTITI…...
《Netty》从零开始学netty源码(八)之NioEventLoop.selector
目录java原生的WEPollSelectorImplnetty的SelectionKey容器SelectedSelectionKeySetnetty的SelectedSelectionKeySetSelectorSelectorTupleopenSelector每一个NioEventLoop配一个选择器Selector,在创建NioEventLoop的构造函数中会调用其自身方法openSelector获取sel…...
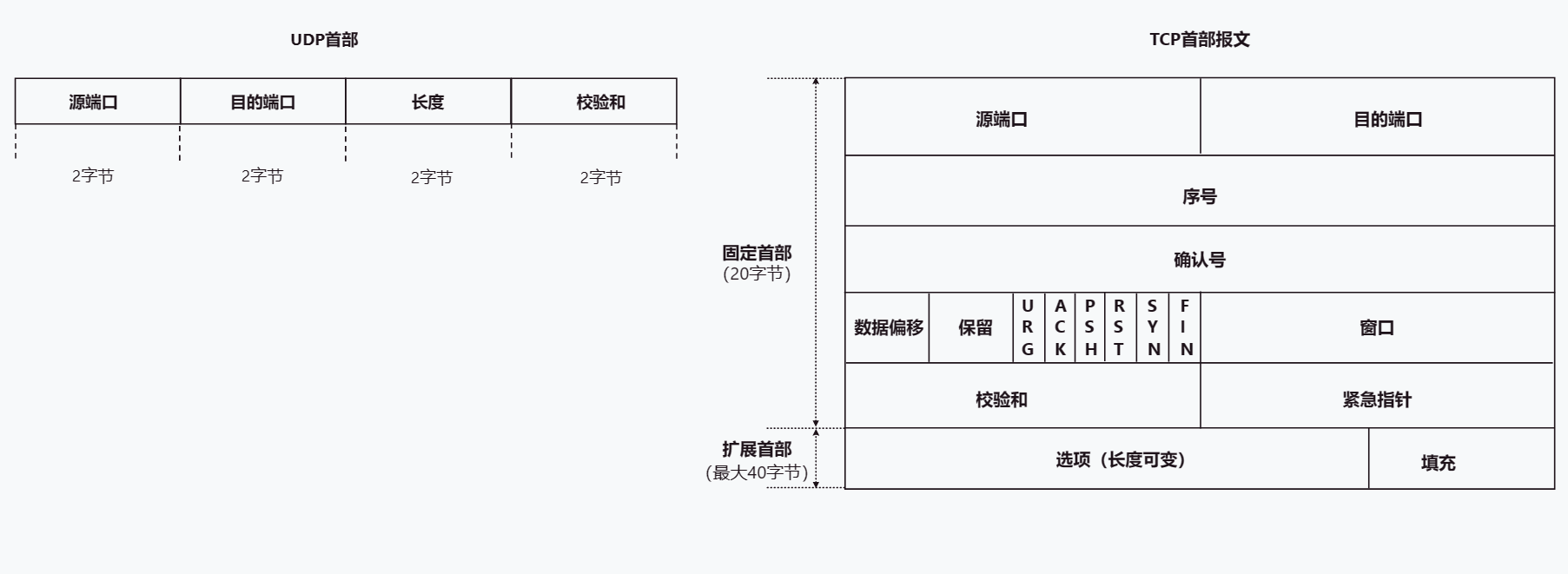
TCP UDP详解
文章目录TCP UDP协议1. 概述2. 端口号 复用 分用3. TCP3.1 TCP首部格式3.2 建立连接-三次握手3.3 释放连接-四次挥手3.4 TCP流量控制3.5 TCP拥塞控制3.6 TCP可靠传输的实现3.7 TCP超时重传4. UDP5.TCP与UDP的区别TCP UDP协议 1. 概述 TCP、UDP协议是TCP/IP体系结构传输层中的…...
超详细淘宝小程序的接入开发步骤
本文是向大家介绍的关于工作中遇到的如何对接淘宝小程序开发的步骤,它能够帮助大家省略在和淘宝侧对接沟通过程中的一些繁琐问题,便捷大家直接快速开展工作~~一、步骤演示1、首先我们打开淘宝开放平台,进入控制台2、进入控制台后,…...

【Python】正则表达式re库
文章目录函数re.match函数re.search函数re.findall函数re.compile函数re.sub函数re.split函数修饰符正则表达式模式正则表达式实例函数 re.match函数 re.match()函数用于尝试从字符串的 起始位置 匹配一个模式,匹配成功返回一个匹配对象,否则返回None。…...

JDK8使用Visual VM根据Dump文件排查OutOfMemoryError生产问题思路
文章目录1. 前言2. 堆内存溢出3. GC执行异常4. 元空间内存溢出5. 创建线程异常6. 内存交换问题7. 数组长度过大8. 系统误杀异常1. 前言 当系统异常产生了dump文件需要我们对其进行排查时,其本质上考验的是我们对于Java运行时内存结构的知识掌握是否牢固以及对业务代…...
2023年网络安全比赛--网络安全事件响应中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.找出黑客植入到系统中的二进制木马程序,并将木马程序的名称作为Flag值(若存在多个提交时使用英文逗号隔开,例如bin,sbin,…)提交; 2.找出被黑客修改的系统默认指令,并将被修改的指令里最后一个单词作为Flag值提交; 3.找出…...

【半监督学习】3、PseCo | FPN 错位对齐的高效半监督目标检测器
文章目录一、背景二、方法2.1 基础框架结构2.2 带噪声的伪边界框学习2.3 多视图尺度不变性学习三、实验论文:PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection 代码:https://github.com/ligang-cs/PseCo 出处&a…...
Tomcat+Servlet初识
文章目录Tomcat什么是TomcatTomcat的安装启动tomcat静态页面的访问动态页面的访问一个Servlet程序的部署流程Tomcat 什么是Tomcat Tomcat是一个HTTP服务器,在开发或调试Servlet代码时应用广泛;使用Tomcat,实际就是将用户浏览器输入的http请…...
ChatGPT-4 终于来了(文末附免费体验地址)
大家好,我是小钱学长。 ChatGPT4.0 重磅来袭,今天一打开plus页面出现的就是这个GPT-4的体验界面!现在就带大家一起看看GPT4.0。 进入之后是这样的 看到最下面有一行话,目前应该是4个小时限制100条消息。 GPT-4有什么优势&…...

【C++学习】类和对象(中)一招带你彻底了解六大默认成员函数
前言:在之前,我们对类和对象的上篇进行了讲解,今天我们我将给大家带来的是类和对象中篇的学习,继续深入探讨【C】中类和对象的相关知识!!! 目录 1. 类的6个默认成员函数 2. 构造函数 2.1概念介…...

面试——Java基础
说一说你对Java访问权限的了解 在修饰成员变量/成员方法时,该成员的四种访问权限的含义如下: private:该成员可以被该类内部成员访问; default:该成员可以被该类内部成员访问,也可以被同一包下其他的类访…...

JavaWeb——Request(请求)和Response(响应)介绍
在写servlet时需要实现5个方法,在一个service方法里面有两个参数request和response。 浏览器向服务器发送请求会发送HTTP的请求数据——字符串,这些字符串会被Tomcat所解析,然后这些请求数据会被放到一个对象(request)里面保存。 相应的Tom…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...

2.2.2 ASPICE的需求分析
ASPICE的需求分析是汽车软件开发过程中至关重要的一环,它涉及到对需求进行详细分析、验证和确认,以确保软件产品能够满足客户和用户的需求。在ASPICE中,需求分析的关键步骤包括: 需求细化:将从需求收集阶段获得的高层需…...

Easy Excel
Easy Excel 一、依赖引入二、基本使用1. 定义实体类(导入/导出共用)2. 写 Excel3. 读 Excel 三、常用注解说明(完整列表)四、进阶:自定义转换器(Converter) 其它自定义转换器没生效 Easy Excel在…...

英国云服务器上安装宝塔面板(BT Panel)
在英国云服务器上安装宝塔面板(BT Panel) 是完全可行的,尤其适合需要远程管理Linux服务器、快速部署网站、数据库、FTP、SSL证书等服务的用户。宝塔面板以其可视化操作界面和强大的功能广受国内用户欢迎,虽然官方主要面向中国大陆…...

Spring事务传播机制有哪些?
导语: Spring事务传播机制是后端面试中的必考知识点,特别容易出现在“项目细节挖掘”阶段。面试官通过它来判断你是否真正理解事务控制的本质与异常传播机制。本文将从实战与源码角度出发,全面剖析Spring事务传播机制,帮助你答得有…...
react-pdf(pdfjs-dist)如何兼容老浏览器(chrome 49)
之前都是使用react-pdf来渲染pdf文件,这次有个需求是要兼容xp环境,xp上chrome最高支持到49,虽然说iframe或者embed都可以实现预览pdf,但为了后续的定制化需求,还是需要使用js库来渲染。 chrome 49测试环境 能用的测试…...