爬取百度图片,想爬谁就爬谁
前言
既然是做爬虫,那么肯定就会有一些小心思,比如去获取一些自己喜欢的资料等。
去百度图片去抓取图片吧
打开百度图片网站,点击搜索xxx,打开后,滚动滚动条,发现滚动条越来越小,说明图片加载是动态的,应该是通过ajax获取数据的,网站地址栏根本不是真正的图片地址。按F12打开开发者模式,我们边滚动边分析,发现下面的url才是真正获取图片地址的。
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=xxxxxxx&ipn=rj&ct=201326592&is=&fp=result&fr=&word=你搜索的内容&queryWord=你搜索的内容&cl=&lm=&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=120&rn=30&gsm=78&1721292699879=
盲目分析分析,其中pn=120,这有可能就是page number,这里的pn rn 很有可能就是page_size row_num,然后再去试着修改pn值为0,30,60去试试,发现果然数据不同,得。实锤了…
下面是pn=30的数据

(太严格了,只能发图片了,不知道能不能通过)
通过分析可知,data中就是真正的图片数据,好了我们可以拿到url,拿到各种数据了。
用python去爬取数据
这要分几个步骤:
- 我们是循环爬取数据的
- 爬取数据后还得保存到文件夹中
- 所以要引入os 以及 requests库
上代码
创建文件夹
# 需要用来创建文件夹
import os
# 在当前目录创建文件夹,咱就简单的弄吧,别搞复杂的
def mkdir_dir_at_curr_path(dir_name):try:os.mkdir(dir_name)print('文件夹:',dir_name,'创建成功')except FileExistsError:print('文件夹:',dir_name,'已经存在')def get_headers():return {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36","Access-Control-Allow-Credentials": "true","Access-Control-Allow-Origin": "https://m.baidu.com, https://www.baidu.com, http://m.baidu.com,http://www.baidu.com","Connection":"keep-alive","Content-Encoding": "br","Content-Type":"application/json"}
定义url以及headers
因为是循环爬取,所以url肯定是动态的,也就是改一下pn的值,查询的人物的名称,保证通用性。而且发现单纯的请求返回的数据不正常,这个时候我们就得加上headers了,这个没办法,百度肯定会有一些防御性的措施来防止爬虫捣乱。
# 需要发送请求
import requestsdef get_headers():return {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36","Access-Control-Allow-Credentials": "true","Access-Control-Allow-Origin": "https://m.baidu.com, https://www.baidu.com, http://m.baidu.com,http://www.baidu.com","Connection":"keep-alive","Content-Encoding": "br","Content-Type":"application/json"}
def get_url(search_name,page_size):url='https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8332766429333445053&ipn=rj&ct=201326592&is=&fp=result&fr=&word='+search_name+'&queryWord='+search_name+'&cl=2&lm=&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn='+str(page_size)+'&rn=30&gsm=3c&1721294093333='return url下载的主体逻辑
# 定义函数去下载图片
def down_load_pics(search_name):# 创建文件夹mkdir_dir_at_curr_path(search_name)#是否继续循环去下载flag=True# 确定是第几次下载request_count=0while(flag):print('第',request_count+1,'次下载中')# 获取urldownload_num=request_count*30url= get_url(search_name,download_num)# 获取请求头headers=get_headers()#发送请求获得响应数据resp=requests.get(url,headers=headers)# 确定是json数据了jsonData=resp.json()if 'data' not in jsonData or jsonData['data']==[] or jsonData['data']==[{}]:print('已经全部下载完成')# 下载完了就要跳出循环flag=Falsereturn# 有数据就去下载for item in jsonData['data']:if 'thumbURL' in item and 'fromPageTitleEnc' in item and search_name in item['fromPageTitleEnc']:# 图片的真正地址sub_url=item['thumbURL']if sub_url.startswith('http'):response=requests.get(sub_url)# 文件夹中文件数量,用来计算下载图片名称file_size= len(os.listdir(search_name))# 下载后图片名称下标pic_index=file_size+1#图片名称curr_file_name=search_name+'_'+str(pic_index)# 将下载好的图片数据保存到文件夹中with open(str(search_name+'/'+curr_file_name)+'.jpg','wb') as f:f.write(response.content)print('第',pic_index,'张图片下载完成')# 准备下一次循环request_count = request_count + 1
最后可以去测试一下了
测试
if __name__ == '__main__':down_load_pics('你搜索的内容')
真的是perfect!完全达到预期!
现在是不是感觉自己很帅啊哈哈
下面附上完整的代码,朋友们记得点个赞哦~~
# 需要发送请求
import requests
# 需要用来创建文件夹
import os# 定义函数去下载图片
def down_load_pics(search_name):# 创建文件夹mkdir_dir_at_curr_path(search_name)#是否继续循环去下载flag=True# 确定是第几次下载request_count=0while(flag):print('第',request_count+1,'次下载中')# 获取urldownload_num=request_count*30url= get_url(search_name,download_num)# 获取请求头headers=get_headers()#发送请求获得响应数据resp=requests.get(url,headers=headers)# 确定是json数据了jsonData=resp.json()if 'data' not in jsonData or jsonData['data']==[] or jsonData['data']==[{}]:print('已经全部下载完成')# 下载完了就要跳出循环flag=Falsereturn# 有数据就去下载for item in jsonData['data']:if 'thumbURL' in item and 'fromPageTitleEnc' in item and search_name in item['fromPageTitleEnc']:# 图片的真正地址sub_url=item['thumbURL']if sub_url.startswith('http'):response=requests.get(sub_url)# 文件夹中文件数量,用来计算下载图片名称file_size= len(os.listdir(search_name))# 下载后图片名称下标pic_index=file_size+1#图片名称curr_file_name=search_name+'_'+str(pic_index)# 将下载好的图片数据保存到文件夹中with open(str(search_name+'/'+curr_file_name)+'.jpg','wb') as f:f.write(response.content)print('第',pic_index,'张图片下载完成')# 准备下一次循环request_count = request_count + 1
def get_headers():return {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36","Access-Control-Allow-Credentials": "true","Access-Control-Allow-Origin": "https://m.baidu.com, https://www.baidu.com, http://m.baidu.com,http://www.baidu.com","Connection":"keep-alive","Content-Encoding": "br","Content-Type":"application/json"}
def get_url(search_name,page_size):url='https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8332766429333445053&ipn=rj&ct=201326592&is=&fp=result&fr=&word='+search_name+'&queryWord='+search_name+'&cl=2&lm=&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn='+str(page_size)+'&rn=30&gsm=3c&1721294093333='return url
# 在当前目录创建文件夹,咱就简单的弄吧,别搞复杂的
def mkdir_dir_at_curr_path(dir_name):try:os.mkdir(dir_name)print('文件夹:',dir_name,'创建成功')except FileExistsError:print('文件夹:',dir_name,'已经存在')if __name__ == '__main__':down_load_pics('xxx任何你喜欢的内容')
相关文章:
爬取百度图片,想爬谁就爬谁
前言 既然是做爬虫,那么肯定就会有一些小心思,比如去获取一些自己喜欢的资料等。 去百度图片去抓取图片吧 打开百度图片网站,点击搜索xxx,打开后,滚动滚动条,发现滚动条越来越小,说明图片加载…...

HTTP 缓存
缓存 web缓存是可以自动保存常见的文档副本的HTTP设备,当web请求抵达缓存时,如果本地有已经缓存的副本,就可以从本地存储设备而不是从原始服务器中提取这个文档。使用缓存有如下的优先。 缓存减少了冗余的数据传输缓存环节了网络瓶颈的问题…...

设计模式实战:图形编辑器的设计与实现
简介 本篇文章将介绍如何设计一个图形编辑器系统,系统包括图形对象的创建、组合、操作及撤销等功能。我们将通过这一项目,应用命令模式、组合模式和备忘录模式来解决具体的设计问题。 问题描述 设计一个图形编辑器系统,用户可以创建并操作图形对象,将多个图形对象组合成…...

.NET 情报 | 分析某云系统添加管理员漏洞
01阅读须知 此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失…...

vue检测页面手指滑动距离,执行回调函数,使用混入的语法,多个组件都可以使用
mixin.ts 定义滑动距离的变量和检测触摸开始的方法,滑动方法,并导出两个方法 sendTranslateX.value > 250 && sendTranslateY.value < -100是向上滑动,满足距离后执行回调函数func,并在一秒内不再触发,一…...

opencv 优势
OpenCV(开源计算机视觉库)是一个广泛使用的计算机视觉和机器学习软件框架。它最初由Intel开发,后来由Itseez公司维护,最终于2015年成为非营利组织OpenCV.org的一部分。OpenCV的目的是实现一个易于使用且高效的计算机视觉框架,支持实时视觉应用。 以下是关于OpenCV的一些关…...

1-如何挑选Android编译服务器
前几天,我在我的星球发了一条动态:入手洋垃圾、重操老本行。没错,利用业余时间,我又重新捣鼓捣鼓代码了。在接下来一段时间,我会分享我从服务器的搭建到完成Android产品开发的整个过程。这些东西之前都是折腾过的&…...

【JS逆向课件:第十六课:Scrapy基础2】
ImagePipeLines的请求传参 环境安装:pip install Pillow USER_AGENT Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36需求:将图片的名称和详情页中图片的数据进行爬取&a…...

使用 PowerShell 自动化图像识别与鼠标操作
目录 前言功能概述代码实现1. 引入必要的程序集2. 定义读取文件行的函数3. 定义加载图片的函数4. 定义查找小图像在大图像中的位置的函数5. 定义截取全屏的函数6. 定义模拟鼠标点击的函数7. 定义主函数 配置文件示例运行脚本结语全部代码提示打包exe 下载地址 前言 在日常工作…...

组队学习——支持向量机
本次学习支持向量机部分数据如下所示 IDmasswidthheightcolor_scorefruit_namekind 其中ID:1-59是对应训练集和验证集的数据,60-67是对应测试集的数据,其中水果类别一共有四类包括apple、lemon、orange、mandarin。要求根据1-59的数据集的自…...

【数据中心】数据中心的IP封堵防护:构建网络防火墙的基石
数据中心的IP封堵防护:构建网络防火墙的基石 引言一、理解IP封堵二、IP封堵的功能模块及其核心技术三、实施IP封堵的关键策略四、结论 引言 在当今高度互联的世界里,数据中心成为信息流动和存储的神经中枢,承载着企业和组织的大量关键业务。…...
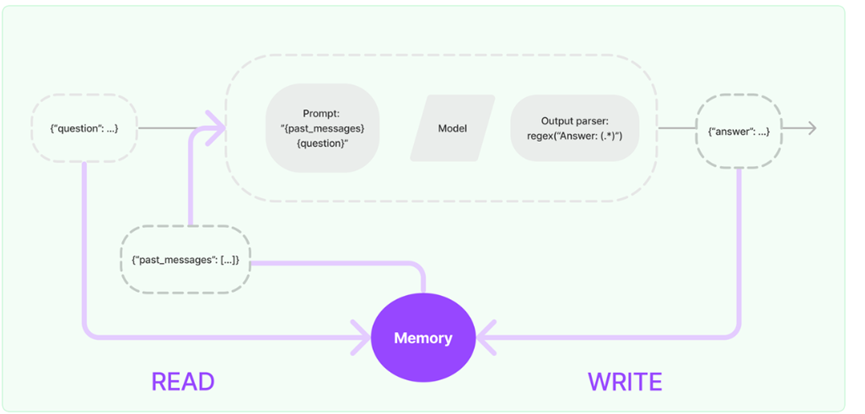
LangChain的使用详解
一、 概念介绍 1.1 Langchain 是什么? 官方定义是:LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序,它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供…...
Modbus转BACnet/IP网关快速对接Modbus协议设备与BA系统
摘要 在智能建筑和工业自动化领域,Modbus和BACnet/IP协议的集成应用越来越普遍。BA(Building Automation,楼宇自动化)系统作为现代建筑的核心,需要高效地处理来自不同协议的设备数据,负责监控和管理建筑内…...

万字长文之分库分表里无分库分表键如何查询【后端面试题 | 中间件 | 数据库 | MySQL | 分库分表 | 其他查询】
在很多业务里,分库分表键都是根据主要查询筛选出来的,那么不怎么重要的查询怎么解决呢? 比如电商场景下,订单都是按照买家ID来分库分表的,那么商家该怎么查找订单呢?或是买家找客服,客服要找到对…...

如何查看jvm资源占用情况
如何设置jar的内存 java -XX:MetaspaceSize256M -XX:MaxMetaspaceSize256M -XX:AlwaysPreTouch -XX:ReservedCodeCacheSize128m -XX:InitialCodeCacheSize128m -Xss512k -Xmx2g -Xms2g -XX:UseG1GC -XX:G1HeapRegionSize4M -jar your-application.jar以上配置为堆内存4G jar项…...

科研绘图系列:R语言TCGA分组饼图(multiple pie charts)
介绍 在诸如癌症基因组图谱(TCGA)等群体研究项目中,为了有效地表征和比较不同群体的属性分布,科研人员广泛采用饼图作为数据可视化的工具。饼图通过将一个完整的圆形划分为若干个扇形区域,每个扇形区域的面积大小直接对应其代表的属性在整体中的占比。这种图形化的展示方…...

ReadAgent,一款具有要点记忆的人工智能阅读代理
人工智能咨询培训老师叶梓 转载标明出处 现有的大模型(LLMs)在处理长文本时受限于固定的最大上下文长度,并且当输入文本越来越长时,性能往往会下降,即使在没有超出明确上下文窗口的情况下,LLMs 的性能也会随…...

构建智能:利用Gradle项目属性控制构建行为
构建智能:利用Gradle项目属性控制构建行为 Gradle作为一款强大的构建工具,提供了丰富的项目属性管理功能。通过项目属性,开发者可以灵活地控制构建行为,实现条件编译、动态配置和多环境构建等高级功能。本文将详细解释如何在Grad…...

如何通过smtp设置使ONLYOFFICE协作空间服务器可以发送注册邀请邮件
什么是ONLYOFFICE协作空间 ONLYOFFICE协作空间,是Ascensio System SIA公司出品的,基于Web的,开源的,跨平台的,在线文档编辑和协作的解决方案。在线Office包含了最基本的办公三件套:文档编辑器、幻灯片编辑…...

SQL labs靶场-SQL注入入门
靶场及环境配置参考 一,工具准备。 推荐下载火狐浏览器,并下载harkbar插件(v2)版本。hackbar使用教程在此不做过多描述。 补充:url栏内部信息会进行url编码。 二,SQL注入-less1。 1,判断传参…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...