Open-TeleVision复现及机器人迁移
相关信息
- 标题 Open-TeleVision: Teleoperation with
Immersive Active Visual Feedback - 作者 Xuxin Cheng1 Jialong Li1 Shiqi Yang1 Ge Yang2 Xiaolong Wang1
UC San Diego1 MIT2 - 主页 https://robot-tv.github.io/
- 链接 https://robot-tv.github.io/resources/television.pdf
- 代码 https://github.com/OpenTeleVision/TeleVision
简要介绍
远程操作是收集机器人学习演示所需数据的有力方法。
远程操作系统的直观性和易用性对于确保高质量、多样性和可扩展性的数据至关重要。
为实现这一目标,我们提出了一种沉浸式远程操作系统OpenTeleVision,使操作员能够以立体方式主动感知机器人的周围环境。
此外,该系统将操作员的手臂和手部动作映射到机器人上,创造出一种仿佛操作员的意识被传送到机器人化身的沉浸体验。
我们通过收集数据并在四项长期精度任务(罐头分类、罐头插入、折叠和卸货)上训练模仿学习策略,验证了系统的有效性,并在两种不同的人形机器人上进行实际部署。
该系统是开源的,网址为:https://robot-tv.github.io/
测试复现
下载
- 下载并安装tv
conda create -n tv python=3.8
conda activate tv
cd TeleVision
pip install -r requirements.txt
cd act/detr && pip install -e .
- 下载并安装Isaac Gym
tv的仿真是在Isaac Gym中搭建的,如果需要运行它的遥操作仿真,请下载Isaac Gym,或遵循以下命令行进行安装配置:
# Download isaac gym
wget https://developer.nvidia.com/isaac-gym-preview-4
# Unpack
# tar -xzf filename.tar.gz -C /path/to/directory
cd isaacgym
# Activate tv
conda activate tv
# Install
cd isaacgym/python
pip install -e .
# Test
cd isaacgym/python/examples
python joint_monkey.py
配置ZED相机
前往ZED SDK下载对应的SDK。
对于Ubuntu20.04,CUDA11.x,此处以CU118为例:
wget https://download.stereolabs.com/zedsdk/4.1/cu118/ubuntu20
chmod +x ZED_SDK_Ubuntu20_cuda11.8_v4.1.3.zstd.run
./ZED_SDK_Ubuntu20_cuda11.8_v4.1.3.zstd.run
- 在conda中安装ZED的Python API
conda activate tv
cd /usr/local/zed/ && python get_python_api.py
# If numpy incompatible
pip install dex-retargeting
配置网络环境
- Apple Vision Pro
Apple 不允许在非 https 连接上使用 WebXR。要在本地测试应用程序,我们需要创建一个自签名证书并将其安装在客户端上。你需要一台 Ubuntu 机器和一台路由器。将 VisionPro 和 Ubuntu 机器连接到同一个路由器。 - mkcert
mkcert 是一个简单的工具,用于生成本地信任的开发证书,且无需任何配置。它的主要用途是在本地环境中创建和安装自签名证书,以避免在使用自签名证书时常见的信任错误。
# Install certutil
sudo apt install libnss3-tools
# Install homebrew
sudo apt-get install build-essential procps curl file git
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> ~/.bashrc
source ~/.bashrc
brew update
brew upgrade
# Install mkcert
brew install mkcert
- 生成证书
# Save cert.pem and key.pem files to /teleop
cd TeleVision/teleop
# Check local ip
local_ip=$(hostname -I | awk '{print $1}')
# Run mkcert
mkcert -install && mkcert -cert-file cert.pem -key-file key.pem $local_ip localhost 127.0.0.1

- 关闭防火墙
可以直接关闭防火墙,也可以参考官方给对应的8012端口开允许。
sudo ufw disable
sudo ufw status
# Or
sudo ufw allow 8012
配置Apple Vsion Pro
- 安装证书
运行 mkcert -CAROOT 命令后,你会看到 mkcert 使用的 CA 根目录路径。
# Get CA root path
mkcert -CAROOT

将rootCA.pem以Airdrop的形式发送到VisionPro,并在Setting/General/VPN&Device Management中对接收到的证书进行安装。

-
启用WebXR特性
在Apple Vision Pro的Setting > Apps > Safari > Advanced > Feature Flags路径下,启用和WebXR有关的特性。 -
在VisionPro中打开Safari中并进入以下命令行获取的指定网址
# Check local ip
local_ip=$(hostname -I | awk '{print $1}')
echo $local_ip
# Get address for Safari in Vsion Pro
echo https://$local_ip:8012?ws=wss://$local_ip:8012
例如https://192.168.50.168:8012?ws=wss://192.168.50.168:8012,将网址分享到VisionPro并打开它。
运行Demo
首先,在Ubuntu端启用demo。
cd TeleVision
conda activate tv
cd teleop && python teleop_hand.py

随后,在VisionPro中访问指定网址,例如https://192.168.50.168:8012?ws=wss://192.168.50.168:8012,这个网址在之前的步骤中获取,点击Enter VR 以及Allow开启VR会话。

你将看到你的手出现在WebXR界面中。

训练复现
- 前往谷歌盘下载数据集。
- 将
recordings数据集放置在data/目录下。
cd TeleVision
mkdir data
cd data
- 使用
scripts/post_process.py对数据集进行处理。
这部分的主要作用是匹配视频与机器人的状态帧。
cd TeleVision
conda activate tv
# Go to scripts directory
cd scripts
python post_process.py
注意: 截止2024年7月22日,作者的数据集中并未提供机器人状态的HDF5文件及获取机器人状态的HDF5录制代码,此步骤跳过。
- 使用
scripts/replay_demo.py测试数据集中的特定部分。
cd TeleVision
conda activate tv
# Go to scripts directory
cd scripts
python replay_demo.py
注意: 截止2024年7月22日,作者的数据集中并未提供机器人状态的HDF5文件及获取机器人状态的HDF5录制代码,此步骤跳过。
- 使用ACT策略进行训练。
cd TeleVision
conda activate tv
# Go to act directory
cd act
python imitate_episodes.py --policy_class ACT --kl_weight 10 --chunk_size 60 --hidden_dim 512 --batch_size 45 --dim_feedforward 3200 --num_epochs 50000 --lr 5e-5 --seed 0 --taskid 00 --exptid 01-sample-expt
- 保存指定checkpoint的即时编译版本(JIT)。
cd TeleVision
conda activate tv
# Go to act directory
cd act
python imitate_episodes.py --policy_class ACT --kl_weight 10 --chunk_size 60 --hidden_dim 512 --batch_size 45 --dim_feedforward 3200 --num_epochs 50000 --lr 5e-5 --seed 0 --taskid 00 --exptid 01-sample-expt\--save_jit --resume_ckpt 25000
- 使用数据集中的数据可视化已训练的模型。
cd TeleVision
conda activate tv
# Go to scripts directory
cd scripts
python deploy_sim.py --taskid 00 --exptid 01 --resume_ckpt 25000
机器人迁移
注意:将OpenTelevision的工作迁移到其他机器人上需要等待作者开放机器人端代码,截止2024年7月22日机器人端代码尚未release,将在后续更新。
论文翻译
注意:以下论文翻译可能存在事实性错误,请谨慎甄别。
图1:使用我们的设置进行自主和远程操作的会话。a-e:机器人自主执行长期精度敏感任务。f-j:机器人使用我们的沉浸式远程操作系统执行细致任务。a:卸货、手中传递;b:H1分类罐头;c:GR-1分类罐头;d:罐头插入;e:折叠毛巾;f:包装耳塞;g:钻孔;h:移液;i:两名操作员互动操作两台机器人。H1机器人的操作员在波士顿,而两台机器人和GR-1的操作员在圣地亚哥(相距约3000英里)。j:与人类互动。

摘要 (Abstract)
远程操作是收集机器人学习演示所需数据的有力方法。
远程操作系统的直观性和易用性对于确保高质量、多样性和可扩展性的数据至关重要。
为实现这一目标,我们提出了一种沉浸式远程操作系统OpenTeleVision,使操作员能够以立体方式主动感知机器人的周围环境。
此外,该系统将操作员的手臂和手部动作映射到机器人上,创造出一种仿佛操作员的意识被传送到机器人化身的沉浸体验。
我们通过收集数据并在四项长期精度任务(罐头分类、罐头插入、折叠和卸货)上训练模仿学习策略,验证了系统的有效性,并在两种不同的人形机器人上进行实际部署。
该系统是开源的,网址为:https://robot-tv.github.io/
图2:远程操作数据收集和学习设置。左图:我们的远程操作系统。虚拟现实设备将手、头和手腕的姿态传输到服务器。服务器将人类的姿态重定向到机器人,并向机器人发送关节位置目标。右图:我们使用动作分块变换器为每个任务训练一个模仿策略。变换器编码器捕捉图像和本体感受标记之间的关系,变换器解码器输出一定块大小的动作序列。

1. 引言 (Introduction)
在过去的几年中,基于学习的机器人操作取得了新的进展,这要归功于大规模的真实机器人数据[1, 2]。远程操作在模仿学习的数据收集中发挥了重要作用,不仅提供了准确和精确的操作演示,还提供了自然流畅的轨迹,使学习到的策略能够推广到新的环境配置和任务中。各种远程操作方法已经通过虚拟现实设备[3, 2]、RGB相机[4, 5, 6]、可穿戴手套[7, 8, 9]和定制硬件[10, 11]进行了研究。
大多数远程操作系统有两个主要组成部分:驱动 (actuation) 和感知(perception)。在驱动方面,使用关节复制技术来操纵机器人提供了高控制带宽和精度[10, 12, 13]。然而,这要求操作员和机器人必须在物理上位于同一地点,不允许远程控制。每个机器人硬件需要与一个特定的远程操作硬件配对。重要的是,这些系统尚无法操作多指灵巧手(multi-finger dexterous hands)。
在感知方面,最直接的方法是操作员用自己的眼睛以第三人称视角[5, 4, 3]或第一人称视角[14, 15]观察机器人任务空间。这不可避免地会在远程操作期间导致操作员视线被遮挡(例如,被机器人手臂或躯干遮挡),操作员无法确保所收集的演示捕捉到了策略学习所需的视觉观察。重要的是,对于细致的操作任务,远程操作员很难在操作期间近距离和直观地观察物体。在VR头显中显示第三人称静态相机视角或使用透视功能[3, 2, 16]也会遇到类似的挑战。
在本文中,我们提出使用虚拟现实设备重新审视远程操作系统。我们介绍了OpenTeleVision,这是一个通用框架,可以在不同的机器人和机械手上使用不同的VR设备进行高精度的远程操作。我们对两种人形机器人进行了实验,包括具有多指手的Unitree H1 [17]人形机器人和具有夹持器的Fourier GR1 [18]人形机器人,进行双手操作任务(如图1所示)。通过捕捉人类操作员的手部姿态,我们进行重定向以控制多指机器人手或平行夹持器。我们依靠逆运动学将操作员的手部根部位置转换为机器人手臂末端执行器的位置。
我们在感知方面的主要贡献在于允许精细操作(fine-grained manipulations),这结合了带有主动视觉反馈的VR系统。我们在机器人头部使用一个单一的主动立体RGB相机,该相机配备2或3个自由度的驱动,模仿人类头部运动来观察大工作空间。在远程操作期间,相机会随着操作员的头部移动,向VR设备实时传输(real-time)和自我中心(egocentric)的3D观测数据。人类操作员看到的就是机器人看到的。这种第一人称的主动感知为远程操作和策略学习带来了好处。对于远程操作,它提供了一种更直观的机制,使用户在移动机器人的头部时可以探索更广阔的视野,并关注重要区域以进行详细交互。对于模仿学习,我们的策略将模仿如何主动移动机器人头部与操作一起进行。
与其将远距离和静态捕捉视图作为输入,主动相机提供了一种自然的注意机制,专注于与下一步操作相关的区域并减少要处理的像素,允许平滑、实时和精确的闭环控制。感知方面的另一个重要创新是从机器人视角向人眼传输立体视频。操作员可以获得更好的空间理解,这在我们的实验中被证明对于完成任务至关重要。我们还展示了使用立体图像帧进行训练可以提高策略的性能。
图3:OpenTeleVision实现了对头部安装的主动相机和上半身运动的高自由度控制。左图:机器人的头部跟随操作员的运动,提供直观的空间感知。右图:机器人的手臂和手部运动通过逆运动学和运动重定向从操作员那里映射。

2. 遥操系统 (TeleVision System)
我们的系统概述如图2所示。我们基于Vuer [19]开发了一个网络服务器。VR设备将操作员的手、头和手腕的姿态以SE(3)格式流传输到服务器,服务器处理人类到机器人的运动重定向。图3展示了机器人的头部、手臂和手部如何跟随人类操作员的运动。反过来,机器人以每只眼480x640的分辨率流传输立体视频。整个循环以60 Hz的频率进行。虽然我们的系统对VR设备型号不敏感,但本文中我们选择了Apple VisionPro作为我们的VR设备平台。
- 硬件
对于机器人,我们选择了两个如图4所示的人形机器人:Unitree H1 [17]和Fourier GR-1 [18]。我们只考虑它们的主动感知颈部、两个7自由度的手臂和末端执行器,而其他自由度未使用。H1的每只手有6个自由度[20],而GR-1有一个1自由度的颚式夹持器。对于主动感知,我们设计了一个安装在H1躯干顶部的具有两个旋转自由度(偏航和俯仰)的万向节。万向节由3D打印部件组装,并由DYNAMIXEL XL330-M288-T电机[21]驱动。对于GR-1,我们使用了制造商提供的具有偏航、滚动和俯仰3个自由度的颈部。
我们在两个机器人上都使用了ZED Mini [22]立体相机,以提供立体RGB流媒体。我们主要在设置中使用人形机器人,因为当前系统的遮挡和缺乏直观性的问题最为突出。虽然我们的系统专门为人形机器人量身定制,以最大限度地提供沉浸式远程操作体验,但它足够通用,可以应用于任何具有两条手臂和一个相机的设置。
图4:OpenTeleVision在两种硬件上的参考设计。左图:Unitree H1 [17] 配备具有6自由度的Inspire [20] 手。头部包含偏航和俯仰电机。右图:Fourier GR-1 [18] 配备颚式夹持器。主动颈部来自制造商,具有偏航、滚动和俯仰电机。

-
机械臂控制
首先将人类手腕的姿态转换到机器人的坐标系中。具体来说,机器人末端执行器与机器人头部之间的相对位置应与人类手腕和头部之间的位置相匹配。 机器人的手腕方向与人类手腕的绝对方向对齐,这在Apple VisionPro手部追踪后端初始化期间进行估算。
这种对末端执行器位置和方向的差异化处理确保了当机器人的头部随人类头部移动时机器人末端执行器的稳定性。我们使用基于Pinocchio [23, 24, 25]的闭环逆运动学(CLIK)算法来计算机器人手臂的关节角。输入的末端执行器姿态使用SE(3)群过滤器进行平滑处理,该过滤器通过Pinocchio的SE(3)插值实现,增强了逆运动学算法的稳定性。为了进一步降低逆运动学失败的风险,我们的实现引入了一个关节角度偏移,当手臂的可操作性接近其极限时进行校正。这个校正过程对末端执行器跟踪性能的影响最小,因为偏移被投影到机器人手臂雅可比矩阵的零空间,从而在解决约束的同时保持跟踪精度。 -
手部控制
人类手部关键点通过dex-retargeting(一种高度通用且快速计算的运动重定向库[4] Anyteleop:
A general vision-based dexterous robot arm-hand teleoperation system. In Robotics: Science
and Systems, 2023.)被转换为机器人关节角度命令。我们的方法在灵巧手和夹持器形态上使用向量优化器。向量优化器将重定向问题公式化为一个优化问题[4, 26],而优化是基于用户选择的向量定义的:
m i n q t ∑ i = 0 N ∣ ∣ α v i t − f i ( q t ) ∣ ∣ 2 + β ∣ ∣ q t − q t − 1 ∣ ∣ 2 min_{q_t} \sum_{i=0}^{N} ||\alpha v_{i t} - f_i(q_t)||^2 + \beta||q_t - q_{t-1}||^2 minqti=0∑N∣∣αvit−fi(qt)∣∣2+β∣∣qt−qt−1∣∣2
在上述公式中, q t q_t qt 表示时间 t t t 时的机器人关节角度, v i t v_{i t} vit 是人类手上的第 i i i 个关键点向量。函数 f i ( q t ) f_i(q_t) fi(qt) 使用正向运动学从关节角度 q t q_t qt 计算机器人手上的第 i i i 个关键点向量。参数 α \alpha α 是一个缩放因子,用于考虑人手和机器人手之间的手部尺寸差异(我们将其设置为1.1用于Inspire手)。参数 β \beta β 权衡了惩罚项,以确保连续步骤之间的时间一致性。优化使用NLopt库[28]中实现的顺序最小二乘二次规划(SLSQP)算法[27]实时进行。前向运动学及其导数的计算在Pinocchio[24]中进行。
对于灵巧手,我们使用七个向量来同步人类和机器人手
五个向量表示手腕和每个指尖关键点之间的相对位置;两个额外的向量,从拇指指尖到主要指尖(食指和中指)之间,用于在精细任务期间增强运动精度。
对于夹爪,优化使用一个向量,该向量在人的拇指和食指指尖之间定义。
这个向量与夹持器上下端之间的相对位置对齐,使得通过简单地捏住操作员的食指和拇指,能够直观地控制夹持器的开闭动作。
图5:使用H1进行四个任务的数据收集。每行代表一个任务。在每个任务结束时,操作员做出相同的结束手势,以表示一次演示的成功完成。然后我们的系统会停止记录数据。我们不会从数据集中裁剪掉结束手势。学到的策略可以成功地对结束条件做出反应。
(a) 机器人捡起随机放置的罐头(#1),将红色罐头放入左边的盒子中(#2),捡起下一个罐头(#3),将绿色罐头放入右边的盒子中(#4)。当桌边的分类盒为空(如图 #1, #3 所示),且桌上没有更多的罐头时,机器人做出结束手势(End)。
(b) GR-1 机器人执行与图 5a 相同的罐头分类任务。
© 机器人捡起罐头(#1),将罐头插入插槽(#2),用另一只手重复捡起和插入(#3, #4)。当六个插槽都被填满时,机器人做出结束手势(End)。
(d) 机器人捡起毛巾的两个角(#1),折叠毛巾(#2),将毛巾轻轻移动到桌边(#3),折叠毛巾两次(#4)。当毛巾被折叠成满意的形状时,机器人做出结束手势(End)。
(e) 机器人从随机插槽中取出管子(#1, #4),从右手传递到左手(#2),将管子放置在指定位置(#3)。当没有管子时,机器人做出结束手势(End)。

3. 实验 (Experiments)
在本节中,我们旨在回答以下问题:
- 我们系统的关键设计选择如何影响模仿学习结果的性能?
- 我们的远程操作系统在收集数据方面有多有效?
我们选择了ACT[10]作为我们的模仿学习算法,并进行了两个关键修改。首先,我们用一个更强大的视觉骨干网络DinoV2[29, 30](一种通过自监督学习预训练的视觉变压器ViT)取代了ResNet。其次,我们使用两个立体图像代替了四个独立布置的RGB摄像机图像作为变压器编码器的输入。DinoV2骨干网络为每张图像生成16×22个标记。状态标记由机器人的当前关节位置投影而来。我们使用绝对关节位置作为动作空间。对于H1,动作维度是28(每只手臂7个,每只手6个,主动脖子2个)。对于GR-1,动作维度是19(每只手臂7个,每个夹爪1个,主动脖子3个)。本体感知标记由相应的关节位置读数投影而来。
我们选择了四个任务,重点是精度、泛化和长时间执行,以展示我们提出的远程操作系统在图5中的有效性。这些任务需要使用一个主动摄像机主动观察工作区的左侧或右侧,否则需要在桌上设置多摄像机。这些任务还涉及显著的物体位置随机化和不同的操作策略。我们通过对所有四个任务进行用户研究并与人类完成相同任务进行比较,进一步展示了数据收集的直观性和速度。任务包括:
罐子分类:如图5a所示的任务涉及在桌子上分类随机放置的可乐罐(红色)和雪碧罐(绿色)。罐子一个一个地放在桌子上,但位置和类型(可乐或雪碧)是随机的。目标是捡起桌子上的每个罐子并将其扔进指定的箱子:左边是可乐,右边是雪碧。解决这个任务需要机器人在每个罐子的放置和方向上进行自适应泛化,以实现精确抓取。这也要求策略能根据当前拿着的罐子的颜色调整计划的动作。每个回合包含连续分类10个罐子(随机5个雪碧和5个可乐)。
罐子插入:如图5c所示的任务涉及从桌子上捡起饮料罐并按预定顺序小心地将其插入容器中的槽中。虽然这两个任务都涉及饮料罐的操作,但这个任务需要比前一个任务更精确和细致的动作,因为成功的插入需要高精度。此外,在这个任务中采用了不同的抓取策略。在前一个罐子分类任务中,机器人只需要将罐子扔进指定区域,因此我们形成了一个涉及手掌和所有五根手指的抓取策略,这是一种宽容但不精确的抓取策略。在这个任务中,为了将罐子插入仅比罐子稍大的槽中(饮料罐的直径大约为5.6厘米,槽的直径大约为7.6厘米),我们采用了更像捏的策略,只使用拇指和食指,从而在放置罐子时能够进行更细致的调整。这两种不同的抓取策略展示了我们的系统能够完成具有复杂手势要求的任务。这个任务的每个回合包括将所有六个罐子放入正确的槽中。
折叠:如图5d所示的任务涉及将毛巾折叠两次。任务的区别在于它展示了系统操作像毛巾这样柔软和顺应性材料的能力。这个任务的动作序列如下展开:捏住毛巾的两个角;提起并折叠;轻轻地将毛巾移动到桌子边缘以准备第二次折叠;再次捏住、提起和折叠。这个任务的每个回合包括一次完整的毛巾折叠。
卸载:如图5e所示的任务是一项复合操作,包括提取管子和在手中传递。在这个任务中,芯片管随机放置在分类盒中的四个槽中的一个。目标是识别包含管子的槽,用右手提取管子,传递给左手,并将管子放在预定位置。为了成功执行这个任务,机器人需要进行视觉推理以辨别管子的位置,并进行精确的动作协调以进行提取和在手中传递。这个任务的每个回合包括从四个随机槽中提取4个管子,传递给另一只手,最后将它们放在桌上。
Table 1: 自主策略成功率。我们为每个任务记录了5个真实世界的实验集。每个实验集包含在第3节定义的完整任务周期。在GR-1上,每次罐头分类执行包括6次拾取和6次放置,累计每个子任务30次试验。

- 3.1 模仿学习结果
我们对系统的关键设计选择进行了消融实验,并通过实际实验展示了其有效性。两个基准分别是使用原始ACT视觉骨干网ResNet18[31]的“w. ResNet18”和只使用左图像视觉标记而非双眼图像的“w/o Stereo Input”。所有模型均使用AdamW优化器[32, 33]进行训练,学习率为5e-5,批量大小为45,迭代次数为25k次,使用一块RTX 4090 GPU。我们在H1和GR-1机器人上进行了罐子分类任务,所有其他任务仅在H1机器人上进行。
从我们在表1中展示的实验结果来看,我们注意到原始的ResNet骨干网无法充分完成所有四项任务。
在原始的ACT实现中,使用了四个摄像头(两个固定,两个安装在手腕上)以缓解使用RGB图像时缺乏显式空间信息的问题。然而,我们的设置仅涉及两个立体RGB摄像头,这可能使得ResNet骨干网更难以获取空间信息。
罐子分类:我们分别评估了捡起罐子的成功率和将其放入指定箱子的准确率。根据表1中H1的结果,我们的模型在两个评估指标中都具有最高的成功率。使用ResNet18的模型在捡拾和分类上明显逊色,可能是由于其骨干网的局限性。由于缺乏立体输入的隐式深度信息,“w/o Stereo Input”无法正确捡起罐子(23/50成功率)。其低分类准确率(26/50成功率)与其在前一阶段的糟糕表现高度相关,因为实验人员必须经常帮助它抓住罐子,这一动作干扰了视觉推理。
表1中还报告了GR-1进行罐子分类的结果。在捡拾子任务中,我们的模型始终优于其他两个基准。然而,在放置子任务中,没有一个模型达到满意的准确率。这种现象可以归因于灵巧手和夹爪之间的不同形态:当机器人手抓住罐子时,摄像头能够看到罐子的颜色并根据所见进行动作;相反,当夹爪抓住罐子时,由于显著的遮挡,摄像头几乎无法辨认颜色(图5b),使视觉推理变得复杂。另一个限制是ACT进行长时间推理的能力依赖于其块大小。在我们的设置中,使用60的块大小和60 Hz的推理频率有效地为机器人提供了一秒钟的记忆:当机器人应在没有直接视觉确认的情况下放下罐子时,它可能已经忘记了在捡起时可见的罐子颜色。
罐子插入:我们分别评估了捡起和插入的成功率。结果(表1)表明,我们的模型在两个指标上都优于基准模型。仅用两根手指捏起汽水罐并调整其姿势以适应插槽需要精确的控制,这需要以空间推理为基础的能力,而这种能力在“w/o Stereo Input”中显著缺失。
折叠任务
我们根据策略在不掉落毛巾的情况下执行连续两次折叠的能力来评估成功率。结果见表1。我们和使用ResNet18的模型都在执行折叠任务时达到了100%的成功率。我们推测,这个任务在所有模型中都具有高成功率是因为其动作的高度重复性。另一方面,“w/o Stereo Input”模型在第三阶段偶尔失败(5次中有2次失败),在这一阶段中,机器人应轻轻将毛巾移到桌子的边缘以便进行第二次折叠。我们观察到,“w/o Stereo Input”倾向于将手压得太重,阻止毛巾成功移动。这个动作可能是由于使用单个RGB图像缺乏深度信息,因为这一步需要机器人根据与桌面的距离调整手的力度。
卸载任务
我们分别评估了连续三个阶段的成功率:抽取管子、手内传递和放置。正如表1所示,我们的模型在所有三个阶段都达到了100%的成功率。使用ResNet18和“w/o Stereo Input”模型在从某些插槽中抽取管子时失败(分别为20次中的3次和6次)。对于“w/o Stereo Input”来说,抽取特别困难,部分原因是它无法正确估计管子和手之间的相对方向。手内传递和放置相对简单,因为这两个阶段在数据收集中没有涉及太多随机化。尽管如此,使用ResNet18和“w/o Stereo Input”的模型在这两个阶段仍偶尔失败(均为20次中的1次),而我们的模型在这两个阶段均未出错。
Figure 7: 宽角镜头和裁剪视图之间的比较。左图:H1罐头分类。右图:卸货。宽角图像分辨率为1280x720,视场为102°(水平) x 57°(垂直)。裁剪图像从原始宽角图像的底部中间裁剪,分辨率为640x480。红色标记为任务的兴趣点(PoIs)。对于罐头分类任务,PoIs包括罐头待分类的箱子、拾取位置、可乐箱和雪碧箱。对于卸货任务,PoIs包括管道插槽、手中传递和放置位置。

- 3.2 泛化能力
我们在随机条件下评估模型的泛化能力。在使用H1进行的罐子分类任务中,我们评估了模型在4x4网格中每个单元格尺寸为3厘米的情况下的拾取成功率,如图6左所示。结果详见图6右侧,显示我们的策略在数据集中覆盖的大区域内表现出良好的泛化能力,保持100%的成功率。即使在演示中很少或没有出现的外围区域,我们的模型有时仍能适应完成抓取任务。
Figure 6: 罐头放置分布。左图:罐头放置在一个4×4的网格中。右图:每个位置进行了5次试验后成功拾取次数的热力图。

为什么使用主动感知?
我们比较了广角摄像头的视角和我们主动摄像头设置的裁剪视角,如图7所示。单个静态广角摄像头仍然难以捕捉到所有感兴趣点(PoI)。需要安装多个摄像头[10, 12]或为每个任务调整摄像头位置。静态广角摄像头还捕捉到不相关的信息,增加了训练和部署的计算成本,如表2所示。我们的TeleVision系统在相同批量大小的情况下,训练速度是其两倍,并且在4090 GPU上可以在一个批次中容纳4倍的数据。在推理过程中,我们的系统也快了两倍,为IK和重定向计算留出了足够的时间,以实现60Hz的部署控制频率。使用广角图像作为输入时,推理速度较低,约为42帧每秒。
此外,使用静态摄像头时,操作员需要注视图像边缘的PoI,这带来了额外的不适感和不直观性,因为人类使用中央(中央凹)视力来集中注意力[34, 35]。
Table 2: 主动视觉与非主动视觉设置的计算成本比较。我们对训练进行了100个批次的采样,并对100个部署步骤的计算时间进行了平均。基线名称中的数字表示批次大小。裁剪的主动视觉图像从640x480下采样到308x224,每个摄像头产生352个图像令牌。宽角视角图像以相同比例从588x336下采样,每个摄像头产生1008个图像令牌。由于RTX 4090 GPU的内存限制,我们在宽角视角设置下使用批次大小为10。
- 远程操控性能
在图8中,我们展示了更多我们的系统能够执行的远程操控任务。木板钻孔任务表明,由于系统与灵巧手的兼容性,我们的系统可以操作为人类设计的重达1公斤的工具,并能够对木板施加足够的力量进行钻孔。
这样的任务对夹爪来说几乎是不可能完成的。耳塞包装任务展示了我们的系统在进行敏捷的双手臂协调操作时的灵巧性和响应速度。移液器任务展示了我们的系统也能执行精确的操作。由于使用移液器是专为类人手设计的,这也是一个对夹爪来说极难甚至不可能完成的任务。即使H1人形机器人的电机是带有行星减速器的准直接驱动电机,众所周知其具有齿隙且精度和刚性远低于其他类型电机,但在人的操作下,我们的系统仍然能够实现高精度。我们的系统还实现了远程操控,如图9所示。请参见我们的视频以进行可视化。
- 用户研究
我们通过用户研究验证了在VR头显中流式传输和显示立体图像的设计选择。用户研究在四名具有不同VR设备使用经验的参与者中进行。参与者是年龄在20-25岁的研究生。每个参与者在指导下完成所有四项任务,并有大约五分钟的时间来熟悉系统和任务。他们在立体和单眼(Mono)设置下的表现详见表3。两项指标(任务完成时间和成功率)都表明立体图像大大优于单眼图像。此外,基于用户反馈的定性结果,使用立体图像显著优于使用单个RGB图像。通常情况下,人眼足够适应从单个RGB图像中推断深度和空间关系。然而,在远程操控的情况下,操作员必须主动与不同的物体互动,这种直觉往往是不足的。利用立体图像中的空间信息可以显著减轻仅通过图像进行机器人远程操控时的不适感。
4.相关工作(Related Work)
-
数据采集
基于学习的方法在使用大量模拟数据和Sim2Real转换进行运动控制方面取得了巨大成功[36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]。另一方面,收集真实机器人演示以进行模仿学习已被证明是机器人操作更有效的方法[49, 50, 1, 51, 52]。这主要是由于操纵器与物体及周围环境之间复杂接触的Sim2Real差距较大。为了收集现实世界的数据,远程操作已成为使用RGB摄像头[4, 5, 6]、动捕手套[7, 8, 9]和VR设备[3, 2]的主流方法。也有一些更传统的框架利用外骨骼设备[11]或镜像手臂进行关节复制[10, 12, 13]。例如,最近的ALOHA框架[10]在细粒度操作任务上提供了精确的控制和准确的关节映射。在本文中,我们发现基于VR的远程操作系统通过手部重定向也可以实现对细粒度操作任务的精确控制,而不是采用关节复制。表4总结了我们的系统与之前的远程操作系统之间的差异。 -
双手远程操作
访问一个直观且响应迅速的远程操作系统对于收集高保真演示至关重要。大多数现有的远程操作系统限制于使用夹爪[11, 53, 13, 14]或单手设置[54, 55, 56],这往往非直观或功能有限。我们认为,允许在三维空间中使用多指手进行操作,可以在各种任务上进行更稳健的操作,相较于现有的远程操作系统具有显著优势。例如,对于平行夹爪来说,稳定抓取薯片筒将是非常具有挑战性的。对于少数双手设置的系统[3, 2],它们需要操作员在任务执行期间直接观察机器人的手或从固定摄像头看到的RGB图像。相比之下,我们的系统结合了第一人称立体显示和主动头部旋转,提供了一个直观的界面,就像机器人是操作员自己的化身。我们的系统允许操作员远程控制机器人(例如,从东海岸控制西海岸的机器人)。这也是区别于其他人形远程操作系统工作的主要创新点[57, 58]。我们的系统允许在细粒度任务上进行顺畅的远程操作,并实现长时间执行的精确控制策略。 -
模仿学习
模仿学习的主题涵盖了广泛的文献。如果我们根据演示的来源区分现有的工作,可以将它们分为从真实机器人专家数据中学习[14, 10, 12, 59, 60, 61, 62, 50, 63, 1, 64, 51, 65]、从游戏数据中学习[66, 67, 68]以及从人类演示中学习[67, 69, 70, 71, 72, 73, 74, 56]。除了用于操作的学习外,物理角色和真实机器人运动模仿也在[75, 76, 40, 77, 78, 79, 80, 81, 82, 80, 83, 84, 85, 86, 87, 88]中被广泛研究。本文属于使用由人类远程操作收集的真实机器人数据进行操作任务的模仿学习。
5.结论与局限(Conclusion and Limitations)
在本文中,我们提出了一种带有立体视频流和主动感知的沉浸式远程操作系统,配备可动颈部。我们展示了该系统能够实现精确和长时间的操作任务,并且使用该系统收集的数据可以被模仿学习算法直接利用。我们还进行了用户研究,证明了立体感知对人类操作员空间理解的重要性。虽然立体感知对操作员的空间理解至关重要,但仍然缺乏其他形式的反馈,如触觉反馈,通常在第一人称视觉遮挡和触觉密集任务中占主导地位。能够重新标注专家数据的系统对于提高成功率非常有帮助,而这也是我们系统目前所缺乏的。未来的工作可以扩展到利用机器人所有自由度的移动版本。
A 与现有远程操作系统的比较讨论
我们从远程操作的两个关键方面进行讨论:驱动和感知。
-
驱动
各种方法已经被用于通过人类指令进行机器人远程操作,包括视觉跟踪、动作捕捉设备和通过定制硬件进行的关节复制。虽然使用动作捕捉手套进行远程操作似乎是最直观的,但市面上可供购买的手套不仅价格昂贵,而且无法提供手腕姿态估计。关节复制方法最近受到了极大关注,得益于ALOHA的成功[10]。这种方法提供了精确和灵巧的控制。历史上,这种方法被认为成本高昂,因为需要使用另一对相同的机械臂进行远程操作;不过,通过采用低成本的外骨骼设备来传输指令,这个问题已经有所缓解[11]。尽管其简单,关节复制系统目前仅限于使用夹持器,还没有扩展到操作多指手。相反,视觉跟踪使用现成的手姿态提取器来跟踪手指运动,但仅依靠RGB或RGBD图像可能会导致数据噪声和不精确。近年来,VR技术的兴起推动了利用VR跟踪的远程操作系统的发展。VR头戴设备制造商通常集成内置的手部跟踪算法,融合来自多种传感器的数据,包括多台摄像机、深度传感器和IMU。通过VR设备收集的手部跟踪数据通常被认为比自开发的视觉跟踪系统更稳定和准确,而后者仅利用了所述传感器的一部分(RGB+RGBD[4]、深度+IMU[6]等)。 -
感知
作为远程操作的另一关键组成部分,感知在该领域的研究相对较少。大多数现有的远程操作系统要求操作员用自己的眼睛直接观察机器人的手。虽然直接观看为操作员提供了深度感知,利用了人类固有的立体视觉能力,但这限制了系统不能进行远程操作,要求操作员必须在物理上接近机器人。一些远程操作系统通过流式传输RGB图像来绕过这一限制,使得远程控制成为可能[4, 5]。然而,如果操作员选择通过观看RGB流进行远程控制,人体眼睛提供的深度感知优势将丧失。尽管这些系统能够同时提供远程控制和深度感知,但这两个功能在这些系统中是互斥的。OPEN TEACH[2]以混合现实的方式融合了这两者,但仍要求操作员接近机器人,否则无法提供深度感知。在Open-TeleVision之前,没有系统能够同时提供远程控制和深度感知:操作员不得不在直接观看(要求物理存在)和RGB流(放弃深度信息)之间做出选择。通过利用立体流,我们的系统是第一个在单一设置中同时提供这两种功能的系统。
B 视觉遮挡讨论
为了支持我们提出的假设,即在GR-1罐头分类任务中观察到的不理想表现源于GR-1夹持器末端效应器引起的视觉遮挡,我们进行了一项控制实验。在新实验中,我们为罐子添加了彩色标签以减轻遮挡因素,如图10左所示。其他设置与文章中描述的GR-1罐头分类任务相同。实验结果记录在表格5中。
结果显示,在使用标记罐子的情况下,所有三个基线在放置任务的成功率上都有显著提高。与之前的0.60相比,我们的模型在放置任务中达到了100%的准确率;其他基线也观察到了显著的增益,w. ResNet18从0.50提高到0.97,而没有立体输入的模型则从0.63提高到0.93。
另一方面,虽然我们的模型和w. ResNet18在捡取成功率上也有所提高,但没有立体输入的模型并未展现类似的改进。这种差异进一步验证了我们的观点,即成功捡取罐子需要来自立体图像的空间信息。
与第3.2节中的H1进行实验类似,我们进行了一项实验,评估带有标记罐子的GR-1在罐头分类任务中的泛化能力。实验结果同样从一个4x4网格收集(与图5左侧相同),每个单元格尺寸为3厘米。泛化结果显示在图10右侧的热图中。结果表明,我们的模型可以轻松适应我们实验中涵盖的大多数随机位置,几乎在网格上所有位置都达到了100%的抓取准确率。
在GR-1罐头分类的这些结果显示中,与H1罐头分类的结果相比,显著改善。这种差异也可能归因于末端效应器形态的不同。夹持苏打罐这种需要较少灵巧和更多容忍度的任务,对夹持器而言更加合适,而不适合机器人手。
C 灵巧手
对于H1机器人的设置,我们使用的人形手由Inspire Robots [20] 提供。图11展示了Inspire Hand的一个特写。每只手有五根手指和12个自由度(DoFs),其中6个是执行自由度(actuated DoFs):两个执行自由度在拇指上,其余手指每个有一个执行自由度。每个非拇指手指在掌指关节(MCP joint)处有一个单独的执行旋转关节,作为整个手指的执行自由度。这四根手指的近侧指间关节(PIP joints)通过连杆机构由掌指关节(MCP joints)驱动,增加了四个被执行自由度(underactuated DoFs)。拇指在第一掌骨间关节(CMC joint)处有两个执行自由度。拇指的掌指关节(MCP)和指间关节(IP joints)也通过连杆机构驱动,增加了额外的两个被执行自由度。
D 远程操作界面
图12展示了我们的基于Web的跨平台界面,不仅可以从VR设备访问,还可以从笔记本电脑、平板电脑和手机访问。
E 实验细节和超参数
E.1 实验细节
更多实验细节列在表6中。除了罐头分类(包括H1罐头分类和GR-1罐头分类)外,所有任务都使用20次人类演示进行训练。相比之下,罐头分类仅使用10次演示。这个选择主要是因为它的重复性质:每一集包括10次(对于GR-1罐头分类是6次)单独的罐头分类。因此,10次演示包括100次单独的分类执行,为训练提供了充分的数据。
E.2 超参数
用于训练ACT [10]模型的超参数详见表7。虽然大多数超参数在所有基线和所有任务中保持一致,但也有一些例外,包括块大小和时间加权。具体解释如下。
在动作分块操作中,块大小的定义在原ACT论文[10]中概述。对于所有任务,我们使用块大小为60,唯独在罐装插入任务中使用块大小为100。在我们的设置中使用块大小为60有效地为机器人提供了约一秒钟的记忆,与我们的推断和动作频率60Hz相关。然而,我们注意到在罐装插入任务中,使用更大的块大小,即包含更多历史动作,对模型执行正确的动作序列是有利的。
在时间聚合操作中,时间加权的定义在原ACT论文[10]中概述,其中使用指数加权方案wi = exp(−m ∗ i)为不同时间步的动作分配权重。w0是最老动作的权重,符合ACT的设定。m是表7中提到的时间加权超参数。随着m的减小,更多的重视放在最近的动作上,使模型更具反应性但不太稳定。我们发现使用时间权重m为0.01在大多数任务中达到了响应和稳定性的满意平衡。然而,对于卸货和罐头分类任务,我们调整这个参数以满足它们特定的需求。对于卸货任务,m设为0.05,确保在手中传递时更稳定;对于罐头分类任务,m设为0.005,提供更快的动作。
文章作者: Herman Ye @Auromix
测试环境: Ubuntu20.04 AnaConda
更新日期: 2024/07/22
注1: Auromix 是一个机器人方向的爱好者组织。
注2: 本文中的硬件设备由Galbot提供。
注3: 由于笔者水平有限,本篇内容可能存在事实性错误。
注4: 本篇直接引用的其他来源图片/文字素材,版权为原作者所有。
相关文章:

Open-TeleVision复现及机器人迁移
相关信息 标题 Open-TeleVision: Teleoperation with Immersive Active Visual Feedback作者 Xuxin Cheng1 Jialong Li1 Shiqi Yang1 Ge Yang2 Xiaolong Wang1 UC San Diego1 MIT2主页 https://robot-tv.github.io/链接 https://robot-tv.github.io/resources/television.pdf代…...

Notepad++换安装路径之后,右键打开方式报错:Windows无法访问指定设备、路径或文件。你可能没有适当的权限访问该项目。的处理方法
把Notepad添加到右键打开方式,可以参考下面的3篇文章添加: https://blog.csdn.net/xiaoerbuyu1233/article/details/88287747 https://blog.csdn.net/qq_44000337/article/details/120277317 https://www.cnblogs.com/zhrngM/p/12899026.html 这里主要是…...

【Flutter 面试题】 使用成熟状态管理库的弊端有哪些?
【Flutter 面试题】 使用成熟状态管理库的弊端有哪些? 文章目录 写在前面口述回答补充说明写在前面 🙋 关于我 ,小雨青年 👉 CSDN博客专家,GitChat专栏作者,阿里云社区专家博主,51CTO专家博主。2023博客之星TOP153。 👏🏻 正在学 Flutter 的同学,你好! 😊 …...

Apache Commons技术详解
文章目录 简介官网链接原理基础使用Commons LangCommons Collections 高级使用Commons IOCommons Math 优缺点优点缺点 总结 简介 Apache Commons 是 Apache 软件基金会下的一个项目,旨在提供可重用的Java组件。这些组件覆盖了广泛的编程任务,从字符串处…...

怎样使用 Juicer tools 的 dump 命令将.hic文件转换为交互矩阵matrix计数文件 (Windows)
创作日志: 万恶的生信…一个scHiC数据集没有提供处理好的计数文件,需要从.hic转换。Github一个个好长的文档看了好久才定位到 juicer tools 的dump命令,使用起来比想象中简单。 一、下载Juicer tools 注意:使用Juicer tools的前提…...
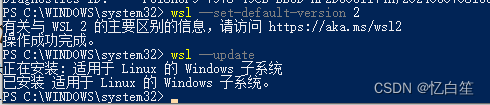
【Docker】Docker Desktop - WSL update failed
问题描述 Windows上安装完成docker desktop之后,第一次启动失败,提示:WSL update failed 解决方案 打开Windows PowerShell 手动执行: wsl --set-default-version 2 wsl --update...

基于rsync\unlink 等一套本机备份跨机备份历史备份清理shell 脚本
一 摘要 本文主要介绍一套本地备份、跨机器备份、历史备份清理脚本,使用场景如数据库备份等 二 环境 linux 系列系统 基本都支持,个别命令可能需要微调。 2.1 实验环境 [rootlocalhost rsync]# cat /etc/centos-release CentOS Linux release 7.9.2…...

使用nginx实现一个端口和ip访问多个vue前端
前言:由于安全组要求,前端页面只开放一个端口,但是项目有多个前端,此前一直使用的是一个前端使用单独一个端口进行访问,现在需要调整。 需要实现:这里以80端口为例,两个前端分别是:p…...

Linux云计算 |【第一阶段】SERVICES-DAY5
主要内容: 源码编译安装、rsync同步操作、inotify实时同步、数据库服务基础 实操前骤:(所需tools.tar.gz与users.sql) 1.两台主机设置SELinnx和关闭防火墙 setenforce 0 systemctl stop firewalld.service //停止防火墙 sy…...

IP第一次综合实验
一、实验拓扑 二、实验要求 1、R6为ISP,接口IP地址均为公有地址,该设备只能配置地址之后不能冉对其进行任何配置 2、R1-R5为局域网,私有Ip地址192.168.1.0/24,请合理分配 3、R1、82、R4,各有两个环回IP地址;R5,R6各…...

Could not load dynamic library ‘cudart64_100.dll‘
python代码报错 Could not load dynamic library cudart64_100.dll; dlerror: cudart64_100.dll not found 2024-07-22 14:19:21.931639: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine…...

四大引用——强软弱虚
目录 一、强引用 二、软引用 三、弱引用 四、虚引用 一、强引用 强引用是在程序代码之中普遍存在的,类似于“Object obj new Object()”,obj变量引用Object这个对象,就叫做强引用。当内存空间不足,Java虚拟机宁愿抛出OutOfMe…...

MySQL--索引(2)
InnoDB 1.索引类型 主键索引(Primary Key) 数据表的主键列使用的就是主键索引。 一张数据表有只能有一个主键,并且主键不能为 null,不能重复。 在 mysql 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是…...

JVM类加载机制详解
Java在运行期才对类进行加载到内存、连接、初始化过程。这使得Java应用具有极高的灵活性和拓展性,可以依赖运行期进行动态加载和动态连接。 主要加载哪些?Java中的数据类型分为基本数据类型和引用数据类型,基本数据类型由虚拟机预先定义&…...

【MATLAB实战】基于UNet的肺结节的检测
数据: 训练过程图 算法简介: UNet网络是分割任务中的一个经典模型,因其整体形状与"U"相似而得名,"U"形结构有助于捕获多尺度信息,并促进了特征的精确重建,该网络整体由编码器,解码器以及跳跃连接三部分组成。 编码器由…...

Elasticsearch基础(五):使用Kibana Discover探索数据
文章目录 使用Kibana Discover探索数据 一、添加样例数据 二、数据筛选 三、保存搜索 使用Kibana Discover探索数据 一、添加样例数据 登录Kibana。在Kibana主页的通过添加集成开始使用区域,单击试用样例数据。 在更多添加数据的方式页面下方,单击…...

爬取百度图片,想爬谁就爬谁
前言 既然是做爬虫,那么肯定就会有一些小心思,比如去获取一些自己喜欢的资料等。 去百度图片去抓取图片吧 打开百度图片网站,点击搜索xxx,打开后,滚动滚动条,发现滚动条越来越小,说明图片加载…...

HTTP 缓存
缓存 web缓存是可以自动保存常见的文档副本的HTTP设备,当web请求抵达缓存时,如果本地有已经缓存的副本,就可以从本地存储设备而不是从原始服务器中提取这个文档。使用缓存有如下的优先。 缓存减少了冗余的数据传输缓存环节了网络瓶颈的问题…...

设计模式实战:图形编辑器的设计与实现
简介 本篇文章将介绍如何设计一个图形编辑器系统,系统包括图形对象的创建、组合、操作及撤销等功能。我们将通过这一项目,应用命令模式、组合模式和备忘录模式来解决具体的设计问题。 问题描述 设计一个图形编辑器系统,用户可以创建并操作图形对象,将多个图形对象组合成…...

.NET 情报 | 分析某云系统添加管理员漏洞
01阅读须知 此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失…...

22 华夏之光永存:指挥AI修复自身代码bug,无需人工逐行查找
指挥AI修复自身代码bug,无需人工逐行查找 摘要 本文为《30天掌控AI编程:从指令到落地,手把手教你指挥AI写代码》系列第二十二篇,属于第四阶段「AI代码校验与优化」核心内容。承接上篇AI代码校验成果,本篇聚焦AI代码bug自动化修复,针对零基础开发者“不会改bug、改完又出…...

文墨共鸣功能全解析:StructBERT双塔/单塔架构怎么选?
文墨共鸣功能全解析:StructBERT双塔/单塔架构怎么选? 1. 理解文墨共鸣的核心功能 文墨共鸣是一个融合深度学习技术与传统美学的语义相似度分析系统。它能够判断两段中文文本在语义层面的相似程度,并以独特的水墨风格界面呈现结果。这个系统…...

MinimalUltrasonic:超声波ToF测距库的极简主义实践
1. 项目概述MinimalUltrasonic 是一款专为嵌入式微控制器设计的极简主义超声波测距库,面向 Arduino 生态系统深度优化。其核心设计哲学是“以最小资源开销实现最大功能覆盖”,在保持接口简洁性的同时,提供工业级的鲁棒性、多单位支持与多传感…...

DeepSeek-OCR-2高级配置:多GPU并行处理优化
DeepSeek-OCR-2高级配置:多GPU并行处理优化 1. 引言 如果你正在处理海量文档,可能会发现单张GPU运行DeepSeek-OCR-2时速度不够理想。一张A100处理复杂文档可能需要几秒钟,当成千上万的文档排队等待时,这个时间就会累积成小时甚至…...

YOLO目标检测完全指南:从入门到实践
YOLO目标检测完全指南:从入门到实践YOLO概述 YOLO(You Only Look Once)是目标检测领域的开创性算法,其核心思想非常直接——对图像只看一次,同时输出所有物体的位置和类别。 两阶段 vs 单阶段 传统R-CNN系列是"两…...

外贸 SEO 中如何进行跨境关键词研究
外贸 SEO 中如何进行跨境关键词研究 在当今全球化的商业环境中,外贸 SEO(搜索引擎优化)已成为跨境电商企业提升品牌知名度和销售额的重要手段。而在外贸 SEO 中,跨境关键词研究是关键步骤。如何进行有效的跨境关键词研究呢&#…...

OpenClaw技能推荐:百川2-13B-4bits最适合的5个办公自动化技能
OpenClaw技能推荐:百川2-13B-4bits最适合的5个办公自动化技能 1. 为什么选择百川2-13B-4bits作为办公自动化引擎 去年冬天,当我第一次尝试用OpenClaw对接各种开源模型时,发现大多数13B参数级别的模型都需要至少24GB显存。直到遇到百川2-13B…...
对网站排名有什么影响)
搜索引擎优化(SEO)对网站排名有什么影响
搜索引擎优化(SEO)对网站排名有什么影响 在当今互联网时代,拥有一个成功的网站不仅仅是建立一个美观的网页,更重要的是让这个网站在搜索引擎中获得高排名。搜索引擎优化(SEO)正是为了解决这个问题,让你的网站能够在大…...

OpenClaw对接Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF实战:3步完成本地模型调用
OpenClaw对接Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF实战:3步完成本地模型调用 1. 为什么选择本地模型对接? 去年冬天,当我第一次尝试用OpenClaw自动化处理周报时,发现调用云端API不仅响应慢,还频繁遇到限…...
:当缓存行竞争超阈值时自动切换为lock-free队列——工业级源码级实现)
C++27原子智能降级策略(Auto-Degrade Atomic Pattern):当缓存行竞争超阈值时自动切换为lock-free队列——工业级源码级实现
第一章:C27原子智能降级策略的演进动因与设计哲学C27将首次引入原子智能降级(Atomic Intelligent Fallback)机制,其核心动因源于现代异构计算环境中硬件原子指令集碎片化加剧、内存模型语义边界模糊化,以及开发者在可移…...