Mamba-yolo|结合Mamba注意力机制的视觉检测
一、本文介绍
PDF地址:https://arxiv.org/pdf/2405.16605v1
代码地址:GitHub - LeapLabTHU/MLLA: Official repository of MLLA
Demystify Mamba in Vision: A Linear AttentionPerspective一文中引入Baseline Mamba,指明Mamba在处理各种高分辨率图像的视觉任务有着很好的效率。发现了强大的Mamba和线性注意力Transformer( linear attention Transformer)非常相似,然后就分析了两者之间的异同。将Mamba模型重述为linear attention Transformer的变体,并且主要有六大差异,分别是:input gate, forget gate,shortcut, no attention normalization, single-head, and modified block design。作者对每个设计都细致的分析了优缺点,评估了性能,最终发现forget gate和block design是Mamba这么给力的主要贡献点。基于以上发现,作者提出了一个类似mamba的线性注意力模型,Mamba-Like Linear Attention (MLLA) ,相当于取其精华,去其糟粕,把mamba两个最为关键的优点设计结合到线性注意力模型当中,具有可并行计算和快速推理的特点。本文将结合YOlOV8检测模型通过添加MLLA模块提升检测精度。
二、宏观架构设计

线性注意 Transformer 模型通常采用图 (a) 中的设计,它由线性注意力模块和 MLP 模块组成。相比之下,Mamba 通过结合 H3和 Gated Attention这两个设计来改进,得到如图 (b) 所示的架构。改进的 Mamba Block 集成了多种操作,例如选择性 SSM、深度卷积、线性映射、激活函数、门控机制等,并且往往比传统的 Transformer 设计更有效。
MLLA (Mamba-Like Linear Attention)的则是通过将Mamba模型的一些核心设计融入线性注意力机制,从而提升模型的性能。具体来说,MLLA主要整合了Mamba中的"忘记门”(forget gate9)和模块设计(block design)这两个关键因素,这些因素被认为是Mamba成功的主要原因。
以下是对MLLA原理的详细分析:
1.忘记门(Forget Gate)
1.忘记门提供了局部偏差和位置信息。所有的忘记门元素严格限制在0到1之间,这意味着模型在接收到当前输入后会持续衰减失前的隐藏状态。这种特性确保了模型对输入序列的顺序敏感。
2.忘记门的局部偏差和位置信息对于图像处理任务来说非常重要,尽管引入忘记门会导致计算需要采用递归的形式,从而降低并行计算的效率。
2.模块设计(Block Design)
1.Mamba的模块设计在保持相似的浮点运算次数(FLOPS)的同时,通过替换注意力子模块为线性注意力来提升性能。结果表明,采用这种模块设计能够显著提高模型的表现。
3.线性注意力的改进:
1.线性注意力被重新设计以整合忘记门和模块设计,这种改进后的模型被称为MLLA。实验结果显示,MLLA在图像分类和高分辨率密集预测任务中均优于各种视觉Mamba模型
4.并行计算和快速推理速度:
1.MLLA通过使用位置编码(ROPE)来替代忘记门,从而在保持并行计算和快速推理速度的同时,提供必要的位置信息。这使得MLLA在处理非自回归的视觉任务时更加有效
结合yolov8改进
核心代码
import torch
import torch.nn as nn__all__ = ['MLLAttention']class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass ConvLayer(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=0, dilation=1, groups=1,bias=True, dropout=0, norm=nn.BatchNorm2d, act_func=nn.ReLU):super(ConvLayer, self).__init__()self.dropout = nn.Dropout2d(dropout, inplace=False) if dropout > 0 else Noneself.conv = nn.Conv2d(in_channels,out_channels,kernel_size=(kernel_size, kernel_size),stride=(stride, stride),padding=(padding, padding),dilation=(dilation, dilation),groups=groups,bias=bias,)self.norm = norm(num_features=out_channels) if norm else Noneself.act = act_func() if act_func else Nonedef forward(self, x: torch.Tensor) -> torch.Tensor:if self.dropout is not None:x = self.dropout(x)x = self.conv(x)if self.norm:x = self.norm(x)if self.act:x = self.act(x)return xclass RoPE(torch.nn.Module):r"""Rotary Positional Embedding."""def __init__(self, base=10000):super(RoPE, self).__init__()self.base = basedef generate_rotations(self, x):# 获取输入张量的形状*channel_dims, feature_dim = x.shape[1:-1][0], x.shape[-1]k_max = feature_dim // (2 * len(channel_dims))assert feature_dim % k_max == 0, "Feature dimension must be divisible by 2 * k_max"# 生成角度theta_ks = 1 / (self.base ** (torch.arange(k_max, dtype=x.dtype, device=x.device) / k_max))angles = torch.cat([t.unsqueeze(-1) * theta_ks for t intorch.meshgrid([torch.arange(d, dtype=x.dtype, device=x.device) for d in channel_dims],indexing='ij')], dim=-1)# 计算旋转矩阵的实部和虚部rotations_re = torch.cos(angles).unsqueeze(dim=-1)rotations_im = torch.sin(angles).unsqueeze(dim=-1)rotations = torch.cat([rotations_re, rotations_im], dim=-1)return rotationsdef forward(self, x):# 生成旋转矩阵rotations = self.generate_rotations(x)# 将 x 转换为复数形式x_complex = torch.view_as_complex(x.reshape(*x.shape[:-1], -1, 2))# 应用旋转矩阵pe_x = torch.view_as_complex(rotations) * x_complex# 将结果转换回实数形式并展平最后两个维度return torch.view_as_real(pe_x).flatten(-2)class MLLAttention(nn.Module):r""" Linear Attention with LePE and RoPE.Args:dim (int): Number of input channels.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True"""def __init__(self, dim=3, input_resolution=[160, 160], num_heads=4, qkv_bias=True, **kwargs):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.num_heads = num_headsself.qk = nn.Linear(dim, dim * 2, bias=qkv_bias)self.elu = nn.ELU()self.lepe = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)self.rope = RoPE()def forward(self, x):"""Args:x: input features with shape of (B, N, C)"""x = x.reshape((x.size(0), x.size(2) * x.size(3), x.size(1)))b, n, c = x.shapeh = int(n ** 0.5)w = int(n ** 0.5)# self.rope = RoPE(shape=(h, w, self.dim))num_heads = self.num_headshead_dim = c // num_headsqk = self.qk(x).reshape(b, n, 2, c).permute(2, 0, 1, 3)q, k, v = qk[0], qk[1], x# q, k, v: b, n, cq = self.elu(q) + 1.0k = self.elu(k) + 1.0q_rope = self.rope(q.reshape(b, h, w, c)).reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)k_rope = self.rope(k.reshape(b, h, w, c)).reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)q = q.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)k = k.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)v = v.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)z = 1 / (q @ k.mean(dim=-2, keepdim=True).transpose(-2, -1) + 1e-6)kv = (k_rope.transpose(-2, -1) * (n ** -0.5)) @ (v * (n ** -0.5))x = q_rope @ kv * zx = x.transpose(1, 2).reshape(b, n, c)v = v.transpose(1, 2).reshape(b, h, w, c).permute(0, 3, 1, 2)x = x + self.lepe(v).permute(0, 2, 3, 1).reshape(b, n, c)x = x.transpose(2, 1).reshape((b, c, h, w))return xdef extra_repr(self) -> str:return f'dim={self.dim}, num_heads={self.num_heads}'if __name__ == "__main__":# Generating Sample imageimage_size = (1, 64, 160, 160)image = torch.rand(*image_size)# Modelmodel = MLLAttention(64)out = model(image)print(out.size())修改一
第一还是建立文件,我们找到如下ultralvtics/n文件夹下建立一个目录名字呢就是'Addmodules文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

修改二
第二步我们在该目录下创建一个新的py文件名字为' __init__ .py,然后在其内部导入我们的检测头如
下图所示。
 修改三
修改三
第三步我门中到如下文件uitralytics/nn/tasks.py进行导入和注册我们的模块

修改四
按照我的添加在parse model里添加即可。

修改5

修改6 配置yolov8-MLLA.yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 1, MLLAttention, []] # 22 (P5/32-large) # 添加在大目标检测层后!
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
7. 训练代码
import warnings warnings.filterwarnings('ignore') from ultralytics import YOLOif __name__ == '__main__':model = YOLO('yolov8-MLLA.yaml')# 如何切换模型版本, 上面的ymal文件可以改为 yolov8s.yaml就是使用的v8s,# 类似某个改进的yaml文件名称为yolov8-XXX.yaml那么如果想使用其它版本就把上面的名称改为yolov8l-XXX.yaml即可(改的是上面YOLO中间的名字不是配置文件的)!# model.load('yolov8n.pt') # 是否加载预训练权重,科研不建议大家加载否则很难提升精度model.train(data=r"C:\Users\Administrator\PycharmProjects\yolov5-master\yolov5-master\Construction Site Safety.v30-raw-images_latestversion.yolov8\data.yaml",# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, posecache=False,imgsz=640,epochs=150,single_cls=False, # 是否是单类别检测batch=16,close_mosaic=0,workers=0,device='0',optimizer='SGD', # using SGD# resume='runs/train/exp21/weights/last.pt', # 如过想续训就设置last.pt的地址amp=True, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',)8.开启训练
专栏推荐
专栏将持续收集整理市场上深度学习的相关项目,旨在为准备从事深度学习工作或相关科研活动的伙伴,储备、提升更多的实际开发经验,每个项目实例都可作为实际开发项目写入简历,且都附带完整的代码与数据集。可通过百度云盘进行获取,实现开箱即用
正在跟新中~
深度学习落地实战_机 _ 长的博客-CSDN博客
相关文章:

Mamba-yolo|结合Mamba注意力机制的视觉检测
一、本文介绍 PDF地址:https://arxiv.org/pdf/2405.16605v1 代码地址:GitHub - LeapLabTHU/MLLA: Official repository of MLLA Demystify Mamba in Vision: A Linear AttentionPerspective一文中引入Baseline Mamba,指明Mamba在处理各种高…...
:自动标识中文多音字)
语音识别标记语言(SSML):自动标识中文多音字
好的,以下是完整的实现代码,包括导入库、分词、获取拼音和生成 SSML 标记的全过程: import thulac from pypinyin import pinyin, Style# 初始化 THULAC thu1 thulac.thulac(seg_onlyTrue)# 测试文本 text "银行行长正在走行。"…...
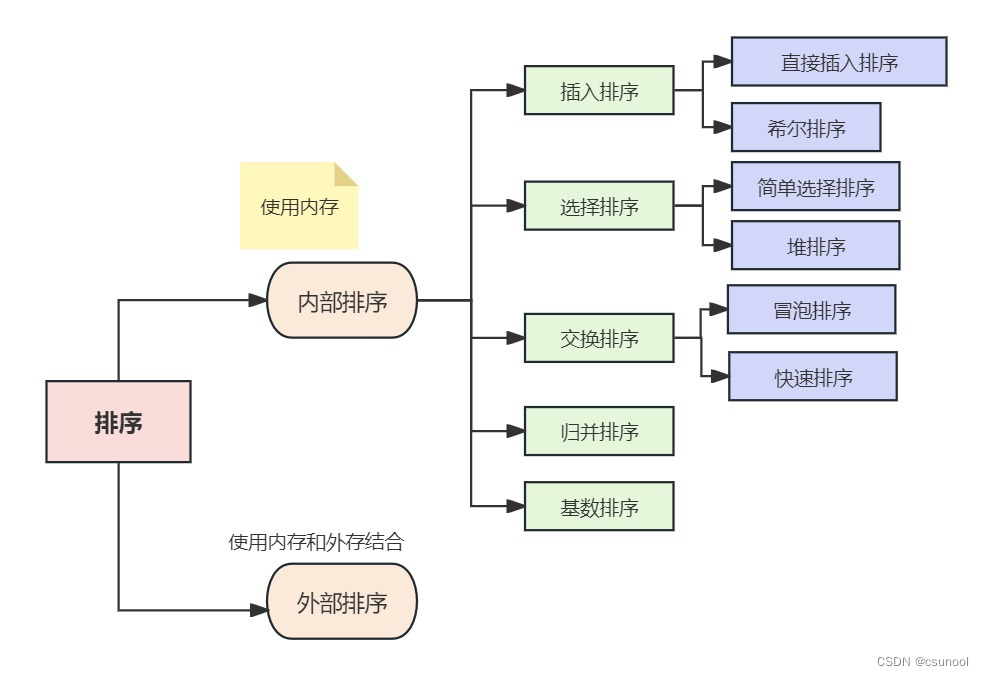
排序算法与复杂度介绍
1. 排序算法 1.1 排序算法介绍 排序也成排序算法(Sort Algorithm),排序是将一组数据,依照指定的顺序进行排序的过程 1.2 排序的分类 1、内部排序: 指将需要处理的所有数据都加载到**内部存储器(内存&am…...
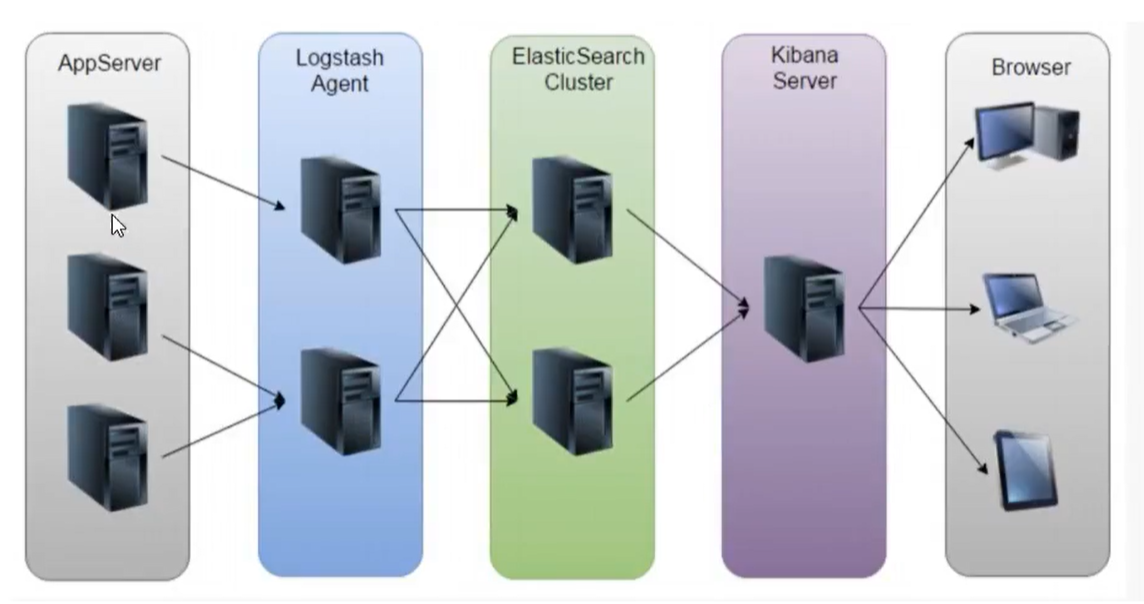
Kafka介绍及Go操作kafka详解
文章目录 Kafka介绍及Go操作kafka详解项目背景解决方案面临的问题业界方案ELKELK方案的问题日志收集系统架构设计架构设计组件介绍将学到的技能消息队列的通信模型点对点模式 queue发布/订阅 topicKafka介绍Kafka的架构图工作流程选择partition的原则ACK应答机制Topic和数据日志…...

DAY05 CSS
文章目录 1 CSS选择器(Selectors)8. 后代(包含)选择器9. 直接子代选择器10. 兄弟选择器11. 相邻兄弟选择器12. 属性选择器 2 伪元素3 CSS样式优先级1. 相同选择器不同样式2. 相同选择器相同样式3. 继承现象4. 选择器不同权值的计算 4 CSS中的值和单位1. 颜色表示法2. 尺寸表示法…...

HTTPS 的加密过程 详解
HTTP 由于是明文传输,所以安全上存在以下三个风险: 窃听风险,比如通信链路上可以获取通信内容。篡改风险,比如通信内容被篡改。冒充风险,比如冒充网站。 HTTPS 在 HTTP 与 TCP 层之间加入了 SSL/TLS 协议,…...

spring整合mybatis,junit纯注解开发(包括连接druid报错的所有解决方法)
目录 Spring整合mybatis开发步骤 第一步:创建我们的数据表 第二步:编写对应的实体类 第三步:在pom.xml中导入我们所需要的坐标 spring所依赖的坐标 mybatis所依赖的坐标 druid数据源坐标 数据库驱动依赖 第四步:编写SpringC…...

ClusterIP、NodePort、LoadBalancer 和 ExternalName
Service 定义 在 Kubernetes 中,由于Pod 是有生命周期的,如果 Pod 重启它的 IP 可能会发生变化以及升级的时候会重建 Pod,我们需要 Service 服务去动态的关联这些 Pod 的 IP 和端口,从而使我们前端用户访问不受后端变更的干扰。 …...

【Day1415】Bean管理、SpringBoot 原理、总结、Maven 高级
0 SpringBoot 配置优先级 从上到下 虽然 springboot 支持多种格式配置文件,但是在项目开发时,推荐统一使用一种格式的配置 (yml是主流) 1 Bean管理 1.1 从 IOC 容器中获取 Bean 1.2 Bean 作品域 可以通过注解 Scope("proto…...

Git之repo sync -c与repo sync -dc用法区别(四十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

vite + vue3 + uniapp 项目从零搭建
vite + vue3 + uniapp 项目从零搭建 1、创建项目1.1、创建Vue3/vite版Uniapp项目1.2、安装依赖1.3、运行项目2、弹出 用户隐私保护提示 方法2.1、更新用户隐私保护指引 和 修改配置文件2.2、授权结果处理方法3、修改`App.vue`文件内容4、处理报`[plugin:uni:mp-using-component…...

在CentOS中配置三个节点之间相互SSH免密登陆
在CentOS中配置三个节点(假设分别为node1、node2、node3)两两之间相互SSH免密登陆,可以按照以下步骤进行: 一、生成密钥对 在所有节点上生成密钥对: 在每个节点(node1、node2、node3)上执行以…...

arm 内联汇编基础
一、 Arm架构寄存器体系熟悉 基于arm neon 实现的代码有 intrinsic 和inline assembly 两种实现。 1.1 通用寄存器 arm v7 有 16 个 32-bit 通用寄存器,用 r0-r15 表示。 arm v8 有 31 个 64-bit 通用寄存器,用 x0-x30 表示,和 v7 不一样…...

Java语言程序设计——篇五(1)
数组 概述数组定义实例展示实战演练 二维数组定义数组元素的使用数组初始化器实战演练:矩阵计算 💫不规则二维数组实战演练:杨辉三角形 概述 ⚡️数组是相同数据类型的元素集合。各元素是有先后顺序的,它们在内存中按照这个先后顺…...

【香橙派开发板测试】:在黑科技Orange Pi AIpro部署YOLOv8深度学习纤维分割检测模型
文章目录 🚀🚀🚀前言一、1️⃣ Orange Pi AIpro开发板相关介绍1.1 🎓 核心配置1.2 ✨开发板接口详情图1.3 ⭐️开箱展示 二、2️⃣配置开发板详细教程2.1 🎓 烧录镜像系统2.2 ✨配置网络2.3 ⭐️使用SSH连接主板 三、…...

集成学习在数学建模中的应用
集成学习在数学建模中的应用 一、集成学习概述(一)基知(二)相关术语(三)集成学习为何能提高性能?(四)集成学习方法 二、Bagging方法(一)装袋&…...

WebKit 的 Web SQL 数据库:现代浏览器的本地存储解决方案
WebKit 的 Web SQL 数据库:现代浏览器的本地存储解决方案 随着Web应用的不断发展,对本地存储的需求也日益增加。WebKit作为许多现代浏览器的核心引擎,提供了一种强大的本地存储解决方案:Web SQL 数据库。本文将详细探讨Web SQL 数…...

Yolo-World网络模型结构及原理分析(三)——RepVL-PAN
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1. 网络结构2. 特征融合3. 文本引导(Text-guided)4. 图像池化注意力(Image-Pooling Attention)5. 区域文本匹配&…...

代码随想录——一和零(Leetcode474)
题目链接 0-1背包 class Solution {public int findMaxForm(String[] strs, int m, int n) {// 本题m,n为背包两个维度// dp[i][j]:最多右i个0和j个1的strs的最大子集大小int[][] dp new int[m 1][n 1];// 遍历strs中字符串for(String str : strs){int num0 …...
)
力扣题解(组合总和IV)
377. 组合总和 Ⅳ 给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。 题目数据保证答案符合 32 位整数范围。 思路: 本题实质上是给一些数字,让他们在满足和是targ…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

Sklearn 机器学习 缺失值处理 获取填充失值的统计值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 使用 Scikit-learn 处理缺失值并提取填充统计信息的完整指南 在机器学习项目中,数据清…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...

P10909 [蓝桥杯 2024 国 B] 立定跳远
# P10909 [蓝桥杯 2024 国 B] 立定跳远 ## 题目描述 在运动会上,小明从数轴的原点开始向正方向立定跳远。项目设置了 $n$ 个检查点 $a_1, a_2, \cdots , a_n$ 且 $a_i \ge a_{i−1} > 0$。小明必须先后跳跃到每个检查点上且只能跳跃到检查点上。同时࿰…...