AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理
AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理
目录
AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理
一、简单介绍
二、Transformer
1、模型架构
2、应用场景
3、Hugging Face 工具和库
三、从零训练一个模型
1、预训练模型
2、初始化模型
3、实现Dataloader
4、定义训练回路
5、开启训练任务
四、结果与分析
附录
一、当前案例环境 package 的 版本如下
一、简单介绍
AGI,即通用人工智能(Artificial General Intelligence),是一种具备人类智能水平的人工智能系统。它不仅能够执行特定的任务,而且能够理解、学习和应用知识于广泛的问题解决中,具有较高的自主性和适应性。AGI的能力包括但不限于自我学习、自我改进、自我调整,并能在没有人为干预的情况下解决各种复杂问题。
- AGI能做的事情非常广泛:
跨领域任务执行:AGI能够处理多领域的任务,不受限于特定应用场景。
自主学习与适应:AGI能够从经验中学习,并适应新环境和新情境。
创造性思考:AGI能够进行创新思维,提出新的解决方案。
社会交互:AGI能够与人类进行复杂的社会交互,理解情感和社会信号。
- 关于AGI的未来发展前景,它被认为是人工智能研究的最终目标之一,具有巨大的变革潜力:
技术创新:随着机器学习、神经网络等技术的进步,AGI的实现可能会越来越接近。
跨学科整合:实现AGI需要整合计算机科学、神经科学、心理学等多个学科的知识。
伦理和社会考量:AGI的发展需要考虑隐私、安全和就业等伦理和社会问题。
增强学习和自适应能力:未来的AGI系统可能利用先进的算法,从环境中学习并优化行为。
多模态交互:AGI将具备多种感知和交互方式,与人类和其他系统交互。
Hugging Face作为当前全球最受欢迎的开源机器学习社区和平台之一,在AGI时代扮演着重要角色。它提供了丰富的预训练模型和数据集资源,推动了机器学习领域的发展。Hugging Face的特点在于易用性和开放性,通过其Transformers库,为用户提供了方便的模型处理文本的方式。随着AI技术的发展,Hugging Face社区将继续发挥重要作用,推动AI技术的发展和应用,尤其是在多模态AI技术发展方面,Hugging Face社区将扩展其模型和数据集的多样性,包括图像、音频和视频等多模态数据。
- 在AGI时代,Hugging Face可能会通过以下方式发挥作用:
模型共享:作为模型共享的平台,Hugging Face将继续促进先进的AGI模型的共享和协作。
开源生态:Hugging Face的开源生态将有助于加速AGI技术的发展和创新。
工具和服务:提供丰富的工具和服务,支持开发者和研究者在AGI领域的研究和应用。
伦理和社会责任:Hugging Face注重AI伦理,将推动负责任的AGI模型开发和应用,确保技术进步同时符合伦理标准。
AGI作为未来人工智能的高级形态,具有广泛的应用前景,而Hugging Face作为开源社区,将在推动AGI的发展和应用中扮演关键角色。
(注意:以下代码运行,可能需要科学上网)
二、Transformer
Transformer 模型是由 Vaswani 等人于 2017 年提出的,是一种用于序列到序列任务(如机器翻译)的神经网络架构。其核心是自注意力机制,能够高效地捕捉序列中各个位置之间的依赖关系。与传统的 RNN 和 LSTM 模型相比,Transformer 具有更好的并行计算能力和处理长距离依赖关系的能力。
1、模型架构
编码器(Encoder):由多个相同的编码器层堆叠而成,每一层包括一个自注意力机制和一个前馈神经网络。
解码器(Decoder):由多个相同的解码器层堆叠而成,每一层包括一个自注意力机制、一个编码器-解码器注意力机制和一个前馈神经网络。
自注意力机制(Self-Attention):通过计算输入序列中每个位置与其他位置的关系来捕捉全局信息。
位置编码(Positional Encoding):由于 Transformer 不具有顺序信息,因此通过位置编码将位置信息引入模型。
2、应用场景
文本分类:将文本分为预定义的类别,如垃圾邮件检测、情感分析。
命名实体识别(NER):识别文本中具有特定意义的实体,如人名、地名、组织名等。
机器翻译:将一种语言的文本翻译成另一种语言。
文本生成:生成自然语言文本,如对话系统、文章生成等。
3、Hugging Face 工具和库
Hugging Face 提供了多种工具和库,帮助开发者简化 NLP 模型的开发和使用:
Transformers:用于加载、训练和使用预训练的 Transformer 模型。
Datasets:用于加载和处理各种标准和自定义数据集。
Tokenizers:用于高效的文本分词和预处理。
三、从零训练一个模型
模型训练。我们将为此项任务设计最合适的架构,初始化一个没有预训练权重的模型,编写一个自定义数据加载类,最后构建训练循环。在本节的最后,我们将分别使用1.11亿和15亿个参数来训练小型与大型的GPT-2模型。在此之前,我们先来确定一个最适合用在代码自动补全场景的架构。
在这里,我们会编写一段很长的代码,基于分布式基础设施训练出一个模型。所以不要单独运行该代码的某一个片段,而应该下载Hugging Face Transformers库(https://oreil.ly/ZyPPR)中提供的脚本,并使用Hugging Face Accelerate库来执行。
1、预训练模型
现在我们拥有了一个大规模的预训练语料库和一个高效的词元分析器,可以考虑用其预训练一个Transformer模型。有了如下图所示的由大量代码片段组成的语料库,就可以拉起好几个训练任务,最后我们根据预训练的目的来选择一个任务。


下面介绍一下三种常见的训练任务。
- 因果语言建模
一种非常容易想到的任务类型是向模型提供一段代码作为开头,并让模型补全剩余可能的代码。这是一种自监督类型的训练任务,并且要确保使用不包含标注的数据集,在第5章中我们讲到过类似的因果语言模型任务。一种最容易想到的下游应用场景就是代码自动填充,所以这种模型在我们的考虑范围。像GPT这样的只有解码器的架构通常比较适合这类任务,如下图所示。


通常像GPT这样的纯解码器模型能用在这个场景
- 掩码语言建模
一种与此相关但稍显不同的方法是给模型提供一段有噪声的代码,比如使用一个随机的或被掩码的词来代替一个代码指令,再用相关模型预测出原来的代码段,如下图所示。这也是一个自监督的训练任务,通常被称为掩码语言建模。要想出一个与去噪直接相关的下游任务是比较困难的,但是去噪通常是一种很好的预训练任务,可为以后的下游任务学习表示方式。我们在前几章中使用的许多模型(如BERT和XLM-RoBERTa)都是以这种方式来预训练的。因此,在一个大型语料库上训练一个掩码语言模型,可以与下游任务(标注数据有限)中做微调的模型相结合。


这一般是Transformer模型编码器分支的基础架构
- Seq2Seq训练
另一种方式是使用像正则表达式这样的启发式方法,将注释和文档与代码分开,构建一个大规模的“代码-注释”对的数据集。然后,训练任务是监督的训练目标,假设我们将代码当作模型的输入,注释就会被当成标注。这样就成为标准的具备“输入-标注”对的监督学习任务,如下图所示。有了一个大型的、纯粹的、多样化的数据集,以及一个具备足够能力的模型,就可以尝试训练出一个能够学习代码及其注释的模型。与这个监督训练任务直接相关的下游任务将根据代码生成注释或根据注释生成代码,这取决于我们如何设置输入与输出。在这种设定下,一个序列被翻译为另一种序列,这就是诸如T5、BART、PEGASUS这些具备编码器-解码器架构的模型的魅力所在。


因为我们想构建一个能完成代码自动补全的模型,所以这里选用第一种任务搭配GPT架构。下面我们来初始化一个新的GPT-2模型。
2、初始化模型
这里将是本书中第一次不使用from_pretrained()方法来加载模型,而是初始化新模型。但我们会加载gpt2-xl的配置,因此将会使用相同的超参数,且会为新的词元分析器调整词表大小。随后通过from_config()方法使用加载的配置信息初始化一个新的模型:
# 从 transformers 库导入 AutoConfig, AutoModelForCausalLM, AutoTokenizer 类
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer# 使用 AutoTokenizer 类创建一个与预训练模型 org/model_ckpt 配套的 tokenizer 实例
# org 和 model_ckpt 应该是定义好的变量,表示模型的组织名和模型检查点名
# from_pretrained 方法自动下载(如果需要)并加载与该模型检查点配套的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(org + "/" + model_ckpt)# 使用 AutoConfig 类创建一个与 "gpt2-xl" 模型配套的配置对象
# vocab_size=len(tokenizer) 指定了配置对象的词汇表大小,这里使用 tokenizer 的词汇表大小
config = AutoConfig.from_pretrained("gpt2-xl", vocab_size=len(tokenizer))# 使用 AutoModelForCausalLM 类创建一个因果语言模型(Causal Language Model),用于生成文本
# from_config 方法根据给定的配置对象初始化模型
# 这里创建的模型将使用与 "gpt2-xl" 配套的预训练权重,但具有自定义的词汇表大小
model = AutoModelForCausalLM.from_config(config)我们来看看这个模型的最终大小:
# 假设 model_size 函数已经被定义,用于计算模型的参数数量
# 假设 model 是一个已经创建的模型实例,比如 GPT-2 (xl)# 打印 GPT-2 (xl) 模型的大小,以百万(M)为单位
# model_size(model) 调用 model_size 函数计算模型的参数总数
# 除以 1000**2 (等于 1,000,000) 将参数总数从单位转换为百万
# .1f 格式化输出,保留一位小数
print(f'GPT-2 (xl) size: {model_size(model)/1000**2:.1f}M parameters')运行结果:
GPT-2 (xl) size: 1529.6M parameters
这居然是一个拥有超过15亿个参数的模型!这个模型的容量很大,但其实数据集也很大。一般来说,只要数据集的规模大得合理,用作大型语言模型的训练就会更有效率。我们把初始化完成的模型保存在models/目录中,并将它推送到Hub上:
# 假设 model 是一个已经创建和训练好的模型实例,比如 GPT-2 (xl)# 调用 model 的 save_pretrained 方法来保存模型
# 这个方法会将模型的权重、配置和tokenizer(如果存在)保存到指定的目录
model.save_pretrained("models/" + model_ckpt, # 指定保存模型的目录路径和模型检查点名push_to_hub=True, # 如果设置为 True,则会尝试将模型推送到 Hugging Face Huborganization=org # 指定推送到 Hugging Face Hub 时使用的组织名
)由于checkpoint大于5GB,因此将模型推送到Hub可能需要花费几分钟的时间。另外,我们将为这个大模型创建一个能正常运行的小版本,使用GPT-2为基础:
# 从 transformers 库导入 AutoTokenizer 类
from transformers import AutoTokenizer# 使用 AutoTokenizer 类创建一个与预训练模型 model_ckpt 配套的 tokenizer 实例
# model_ckpt 应该是一个包含模型名称或路径的字符串
# from_pretrained 方法会自动下载(如果需要)并加载与该模型检查点配套的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)# 从 transformers 库导入 AutoConfig 类
from transformers import AutoConfig# 使用 AutoConfig 类创建一个与 "gpt2" 模型配套的配置对象
# vocab_size=len(tokenizer) 指定了配置对象的词汇表大小,这里使用 tokenizer 的词汇表大小
# from_pretrained 方法加载 "gpt2" 模型的预训练配置,并根据 tokenizer 的词汇表大小进行调整
config_small = AutoConfig.from_pretrained("gpt2", vocab_size=len(tokenizer))# 从 transformers 库导入 AutoModelForCausalLM 类
from transformers import AutoModelForCausalLM# 使用 AutoModelForCausalLM 类创建一个因果语言模型(Causal Language Model)实例
# from_config 方法根据给定的配置对象初始化模型
# model_small 将是一个使用 "gpt2" 配置的模型实例,具有与 tokenizer 匹配的词汇表大小
model_small = AutoModelForCausalLM.from_config(config_small)# 假设 model_size 函数已经被定义,用于计算模型的参数数量
# 假设 model_small 是一个已经创建的模型实例,比如 GPT-2# 打印 GPT-2 模型的大小,以百万(M)为单位
# model_size(model_small) 调用 model_size 函数计算 model_small 模型的参数总数
# 除以 1000**2 (等于 1,000,000) 将参数总数从单位转换为百万
# .1f 格式化输出,保留一位小数点后一位数字
print(f'GPT-2 size: {model_size(model_small)/1000**2:.1f}M parameters')运行结果:
GPT-2 size: 111.0M parameters
将此小型模型保存到Hub,便于分享和复用:
# 假设 model_small 是已经训练好并准备保存的模型实例
# 假设 model_ckpt 是模型检查点的名称或标识符,org 是组织名# 使用模型实例的 save_pretrained 方法保存模型的配置、权重和tokenizer(如果有)
# "models/" + model_ckpt + "-small" 指定了保存模型的路径和文件名,添加 "-small" 后缀区分原始模型
model_small.save_pretrained("models/" + model_ckpt + "-small", # 保存模型的路径和检查点名,包含 "-small" 后缀push_to_hub=True, # 设置为 True 以尝试将模型自动上传到 Hugging Face Huborganization=org # 如果提供,指定上传到 Hugging Face Hub 的目标组织名
)现在我们有了两个可供训练的模型,需要确保在训练期间的数据供应。
3、实现Dataloader
为了使训练效率最大化,我们将为模型提供序列以填充到上下文。例如,如果模型上下文包含1024个词元,就需要1024个词元的序列。但实际上一些代码段很少能精准地获得1024个词元,为了给模型提供具备sequence_length的序列,就应该放弃最后一个不完整的序列,或是填充序列。然而,这样会造成训练效率略微降低,并且还必须花精力关注如何放弃与填充序列,这样在计算方面比在数据本身上面的限制更多,所以我们可以采取一些方法来解决这个问题。我们使用一个小技巧可以确保不会丢失过多的尾部片段:对几个例子进行词元化后再连接起来,用特殊的代表序列结束的词元将它们分隔开,就可以得到一个很长的序列。最后再将它们拆分成同等大小的块,如图所示。采用这种方法,我们最多只会损失最后那一小部分数据。


我们可以指定输入字符串的字符长度,来确保词元实例中有100个完整的序列:

这里的参数解释如下:
- input_characters:输入到词元分析器的字符串所包含的字符数量。
- number_of_sequences:希望从词元分析器中得到的(拆分的)序列数量(比如,100个)。
- sequence_length:词元分析器返回的每个序列的词元数量(比如,1024个)。
- characters_per_token:估算值,每个输出词元的平均字符数量。
假如我们输入一个带有“input_characters”字符的字符串,还有number_of_sequences的平均值,就可以很容易算出最后一个序列会丢弃多少输入数据。如果让number_of_sequences=100,表示大概连接了100个序列,则最多可以丢弃1%的数据。这种方法可以确保不会因丢弃了大多数文件尾而引入偏差。
我们来估算一个数据集中每个字符串的平均字符长度:
# 设置示例数量以及用于计数的总字符数和总token数的初始值
examples, total_characters, total_tokens = 500, 0, 0# 从 Hugging Face datasets 库导入 load_dataset 函数
from datasets import load_dataset# 加载名为 'transformersbook/codeparrot-train' 的数据集的 'train' 分割部分
# streaming=True 参数表示以流式传输方式加载数据集,适用于大型数据集
dataset = load_dataset('transformersbook/codeparrot-train', split='train', streaming=True)# 使用 tqdm 库来显示进度条,zip 函数将范围对象与数据集迭代器组合
# tqdm 的 total 参数设置为 examples,表示迭代的总次数
for _, example in tqdm(zip(range(examples), iter(dataset)), total=examples):# 累加每个样本 'content' 字段的字符数到总字符数total_characters += len(example['content'])# 使用 tokenizer 对样本 'content' 字段进行编码,累加编码后的 token 数量到总 token 数total_tokens += len(tokenizer(example['content']).tokens())# 计算每个 token 平均对应的字符数
characters_per_token = total_characters / total_tokens运行结果:

# 打印每个 token 平均对应的字符数
# 这个指标可以帮助我们了解 tokenizer 是如何将字符转换为 token 的
# 一个较低的值可能意味着 tokenizer 产生了更多的 token,用于捕捉更多的细节
# 一个较高的值可能意味着 tokenizer 将更多的字符合并为一个 token,可能丢失一些细节
print(characters_per_token)运行结果:
3.6231516195736053
按照上面这样操作就创建好了IterableDataset(它是PyTorch提供的一个辅助类)需要的所有内容,以便为模型准备定长的输入数据。只需继承IterableDataset,并编写__iter()__函数逻辑,用刚介绍的这套逻辑产生下一个元素:
import torch
from torch.utils.data import IterableDatasetclass ConstantLengthDataset(IterableDataset):# ConstantLengthDataset 类继承自 IterableDataset,用于创建一个可迭代的数据集def __init__(self, tokenizer, dataset, seq_length=1024,num_of_sequences=1024, chars_per_token=3.6):# 初始化函数,设置数据集的主要参数self.tokenizer = tokenizer # 分词器实例self.concat_token_id = tokenizer.eos_token_id # 用于连接序列的结束token的IDself.dataset = dataset # 原始数据集self.seq_length = seq_length # 每个序列的长度self.input_characters = seq_length * chars_per_token * num_of_sequences # 总字符数限制def __iter__(self):# 迭代器函数,用于生成数据集的批次iterator = iter(self.dataset)more_examples = Truewhile more_examples:buffer, buffer_len = [], 0# 循环直到达到所需的总字符数或数据集结束while True:if buffer_len >= self.input_characters:# 如果已达到总字符数限制,打印消息并退出循环m=f"Buffer full: {buffer_len}>={self.input_characters:.0f}"print(m)breaktry:# 尝试从数据集中获取下一个样本并添加到缓冲区m=f"Fill buffer: {buffer_len}<{self.input_characters:.0f}"print(m)buffer.append(next(iterator)["content"])buffer_len += len(buffer[-1])except StopIteration:# 如果迭代器耗尽,重置迭代器iterator = iter(self.dataset)# 对缓冲区中的所有文本进行分词all_token_ids = []tokenized_inputs = self.tokenizer(buffer, truncation=False)for tokenized_input in tokenized_inputs['input_ids']:# 将分词结果添加到all_token_ids,并在每个序列后添加结束tokenall_token_ids.extend(tokenized_input + [self.concat_token_id])# 按指定的序列长度生成批次for i in range(0, len(all_token_ids), self.seq_length):input_ids = all_token_ids[i : i + self.seq_length]if len(input_ids) == self.seq_length:# 如果生成的序列长度符合要求,则将其作为tensor返回yield torch.tensor(input_ids)__Iter()__函数中建立了一个字符串缓冲区,可以容纳足够多的字符。缓冲区中所有元素都被词元化,且与EOS词元相连接,然后将all_token ids中的长序列拆分为具有seq_length大小的片段。通常情况下,需要使用掩码来堆叠不同长度的扩充序列,并确保在训练过程中忽略它。可以通过只提供最大长度的序列来解决这个问题,所以这里没有使用掩码,而是只返回input ids。下面我们看看创建的可迭代数据集:
# 假设 dataset 是已经加载的数据集,tokenizer 是已经初始化的分词器实例# 使用 shuffle 方法对数据集进行随机打乱
# buffer_size 参数指定了用于打乱操作的缓冲区大小
shuffled_dataset = dataset.shuffle(buffer_size=100)# 创建 ConstantLengthDataset 的实例
# tokenizer 是用于分词的 tokenizer 实例
# shuffled_dataset 是经过随机打乱的数据集
# num_of_sequences=10 指定了生成的序列数量为 10
constant_length_dataset = ConstantLengthDataset(tokenizer, shuffled_dataset, num_of_sequences=10)# 创建 ConstantLengthDataset 实例的迭代器
dataset_iterator = iter(constant_length_dataset)# 使用列表推导式和迭代器获取前 5 个批次的序列,并计算每个批次序列的长度
# zip(range(5), dataset_iterator) 用于从迭代器中获取前 5 个元素
# len(b) 计算每个序列的长度
lengths = [len(b) for _, b in zip(range(5), dataset_iterator)]# 打印序列长度的列表
print(f"Lengths of the sequences: {lengths}")运行结果:
Fill buffer: 0<36864 Fill buffer: 2416<36864 Fill buffer: 27957<36864 Fill buffer: 29090<36864 Fill buffer: 31567<36864 Buffer full: 59795>=36864 Lengths of the sequences: [1024, 1024, 1024, 1024, 1024]
结果符合预期!我们为模型提供了定长的输入。现在我们有了一个供模型使用的可靠数据源,可以创建训练回路了。
注意,在创建ConstantLengthDataset之前,我们将原始数据进行了洗牌操作。因为这是一个可迭代的数据集,所以不能一开始就进行洗牌操作。我们设置了一个大小为buffer_size的缓冲区,在从数据集中获取元素之前,对缓冲区中的元素做洗牌操作。
4、定义训练回路
到目前,所有的准备工作已经就绪,我们可以开始编写训练回路了。我们自己在本地训练语言模型的一个问题是单个GPU提供的内存是有限的。即使在最新的GPU上面,也很难保证在规定时间能将一个GPT-2规模的模型训练完成。所以这里我们将实现数据并行化,利用几个GPU进行分布式训练任务。幸运的是,我们可以使用Hugging Face Accelerate库来使训练代码具备可扩展性。Hugging Face Accelerate库的推出,使模型训练突破硬件的限制,让分布式并行训练变得简单。此外,我们也可以使用Trainer进行分布式训练,但使用Hugging Face Accelerate库能够完全掌控训练回路,这也是本节需要探讨的。
Hugging Face Accelerate库提供了一套简单的API,能让训练脚本以混合精度和任何类型的分布式设置(单GPU、多GPU和TPU)来运行。同样的一套代码能够在本地轻松运行,用于调试,也能在资源富集的训练集群上做模型训练,而这只需要对本地的PyTorch训练回路代码做少量修改:

主要的修改点是在调用prepare()函数的地方,需要确保模型、优化器和数据加载器都已在基础设施之上准备完成。在PyTorch代码上完成这些改动可以让我们的模型在不同的硬件环境中进行训练。下面我们开始编写训练脚本和辅助函数,首先设置的是训练使用的超参数,将它们封装在一个Namespace中,便于访问:
from argparse import Namespace# 定义配置字典,包含用于训练和验证的参数设置
# 注释中的参数是针对较小模型的设置,当前设置可能针对不同情况有所调整
config = {"train_batch_size": 2, # 训练时每个批次的样本数量,之前设置为 12"valid_batch_size": 2, # 验证时每个批次的样本数量,之前设置为 12"weight_decay": 0.1, # 权重衰减,用于正则化以防止过拟合"shuffle_buffer": 1000, # 用于打乱数据的缓冲区大小"learning_rate": 2e-4, # 学习率,之前设置为 5e-4"lr_scheduler_type": "cosine", # 学习率调度器类型,使用余弦退火策略"num_warmup_steps": 750, # 预热步数,之前设置为 2000"gradient_accumulation_steps": 16, # 梯度累积步数,之前设置为 1"max_train_steps": 50000, # 最大训练步数,之前设置为 150000"max_eval_steps": -1, # 最大评估步数,-1 表示使用数据集中的所有样本"seq_length": 1024, # 输入序列的长度"seed": 1, # 随机种子,用于确保结果的可重复性"save_checkpoint_steps": 50000 # 保存检查点的步数,之前设置为 15000
}# 使用 argparse 的 Namespace 将配置字典转换为对象
# 这允许我们将配置选项作为属性访问
args = Namespace(**config)接下来,设置训练日志打印逻辑。由于我们是从头开始训练一个模型,时间不定,并且基础设施资源也比较昂贵,因此,我们需要确保所有的相关信息都被记录下来,方便后期查看。编写setup_logging()函数,设置三种日志记录方式:标准Python日志(https://oreil.ly/P9Xrm),TensorBoard日志(https://oreil.ly/kY5ri),Weights&Biases日志(https://oreil.ly/BCC3k),可以根据需要,添加或删除日志记录框架:
from torch.utils.tensorboard import SummaryWriter
import logging
import wandb
from accelerate import Accelerator# setup_logging 函数用于设置日志记录和集成 Wandb (Weights & Biases) 以及 TensorBoard
def setup_logging(project_name):# 获取当前模块的 loggerlogger = logging.getLogger(__name__)# 配置基本的日志格式和处理器logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", # 日志格式datefmt="%m/%d/%Y %H:%M:%S", # 时间格式level=logging.INFO, # 设置日志级别为 INFOhandlers=[ # 日志处理器列表logging.FileHandler(f"log/debug_{accelerator.process_index}.log"), # 文件日志处理器logging.StreamHandler() # 流日志处理器,通常输出到控制台])# accelerator.is_main_process 检查是否是主进程,以避免多进程中的重复设置if accelerator.is_main_process:# 初始化 Wandb 项目并配置wandb.init(project=project_name, config=args)# 获取 Wandb 运行的名称run_name = wandb.run.name# 初始化 TensorBoard 的 SummaryWritertb_writer = SummaryWriter()# 向 TensorBoard 添加超参数tb_writer.add_hparams(vars(args), {'0': 0})# 设置 logger 的日志级别为 INFOlogger.setLevel(logging.INFO)# 设置 datasets 库的日志详细程度为 DEBUGdatasets.utils.logging.set_verbosity_debug()# 设置 transformers 库的日志详细程度为 INFOtransformers.utils.logging.set_verbosity_info()else:# 如果不是主进程,则不设置 TensorBoard 和运行名称tb_writer = Nonerun_name = ''# 设置 logger 的日志级别为 ERRORlogger.setLevel(logging.ERROR)# 设置 datasets 库的日志详细程度为 ERRORdatasets.utils.logging.set_verbosity_error()# 设置 transformers 库的日志详细程度为 ERRORtransformers.utils.logging.set_verbosity_error()# 返回配置好的 logger, TensorBoard 的 writer 和 Wandb 运行的名称return logger, tb_writer, run_name(如果没有安装 tensorboard ,在 Jupyter Notebook 中使用 !pip install tensorboard 安装)
(如果没有安装 wandb ,在 Jupyter Notebook 中使用 !pip install wandb 安装)
(如果没有安装 accelerate,在 Jupyter Notebook 中使用 !pip install accelerate 安装)
每个worker都有一个全局唯一的accelerator.process index,这里将其与FileHandler一起使用,将每个worker的日志分别写入单独的文件中。我们还使用了accelerator. is_main_process属性,该属性仅对主worker有效。这里我们还避免了TensorBoard日志和Weights & Biases日志的多次初始化,并降低了其他worker的日志级别。函数返回值是自动生成且唯一的wandb.run.name,后面我们使用它来命名在Hub上的实验分支。
此外,我们还定义了一个函数,使用TensorBoard和Weights & Biases记录指标数据,并再次使用了accelerator.is_main_process属性来确保只记录一次,而不是为每个worker都记录:
# 假设 logger, accelerator, wandb 和 tb_writer 已经被正确定义和初始化def log_metrics(step, metrics):"""记录训练或评估步骤的指标函数。参数:- step: 当前的训练或评估步骤。- metrics: 一个字典,包含要记录的指标名称和值。"""# 使用 logger 的 info 级别记录指标信息logger.info(f"Step {step}: {metrics}")# 检查当前进程是否是主进程,确保只有主进程记录到 Wandb 和 TensorBoardif accelerator.is_main_process:# 使用 Wandb 的 log 方法记录指标wandb.log(metrics)# 使用列表推导式遍历 metrics 字典中的每个项# 对于每个项,使用 tb_writer 的 add_scalar 方法向 TensorBoard 添加一个标量指标# k 是指标名称,v 是指标值,step 是记录的步骤[tb_writer.add_scalar(k, v, step) for k, v in metrics.items()]接下来我们编写数据加载器的创建函数,使用全新的ConstantLengthDataset类来为训练集和验证集创建数据加载器:
from torch.utils.data.dataloader import DataLoader
from datasets import load_dataset# 假设 tokenizer 和 args 已经被正确定义和初始化def create_dataloaders(dataset_name):"""创建数据加载器函数,用于加载训练和验证数据集。参数:- dataset_name: 数据集的名称,将用于加载训练和验证数据集。返回:- train_dataloader: 训练数据的 DataLoader 对象。- eval_dataloader: 验证数据的 DataLoader 对象。"""# 加载训练数据集,使用 dataset_name 添加 '-train' 后缀,并指定分割为 'train'train_data = load_dataset(dataset_name+'-train', split="train", streaming=True)# 对训练数据集进行随机打乱,使用配置中的 shuffle_buffer 作为缓冲区大小,并设置随机种子train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)# 加载验证数据集,使用 dataset_name 添加 '-valid' 后缀,并指定分割为 'validation'valid_data = load_dataset(dataset_name+'-valid', split="validation", streaming=True)# 创建训练数据集的 ConstantLengthDataset 实例,使用 tokenizer 和训练数据集train_dataset = ConstantLengthDataset(tokenizer, train_data, seq_length=args.seq_length)# 创建验证数据集的 ConstantLengthDataset 实例,使用 tokenizer 和验证数据集valid_dataset = ConstantLengthDataset(tokenizer, valid_data, seq_length=args.seq_length)# 创建训练数据的 DataLoader,使用 train_dataset 并设置批大小为 args.train_batch_sizetrain_dataloader = DataLoader(train_dataset, batch_size=args.train_batch_size)# 创建验证数据的 DataLoader,使用 valid_dataset 并设置批大小为 args.valid_batch_sizeeval_dataloader = DataLoader(valid_dataset, batch_size=args.valid_batch_size)# 返回创建的训练和验证数据的 DataLoader 对象return train_dataloader, eval_dataloader最后,我们将数据集设置到DataLoader,也能进行批处理,Hugging Face Accelerate库会将批处理结果分配给每个worker。
另一个需要实现的是优化部分逻辑,我将在主流程中设置优化器和学习率策略,但这里定义了一个辅助函数来分辨权重衰减参数。一般来说,偏差和LayerNorm权重不受权重衰减的影响:
# 假设 args 已经被正确定义和初始化,包含权重衰减的配置def get_grouped_params(model, no_decay=["bias", "LayerNorm.weight"]):"""将模型参数分组,以便于应用不同的权重衰减策略。参数:- model: 要训练的模型。- no_decay: 不应用权重衰减的参数列表,默认包括 "bias" 和 "LayerNorm.weight"。返回:- 包含两个字典的列表,第一个字典包含应用权重衰减的参数,第二个字典包含不应用权重衰减的参数。"""params_with_wd, params_without_wd = [], [] # 初始化两个空列表,用于存储不同组的参数for n, p in model.named_parameters(): # 遍历模型的所有命名参数if any(nd in n for nd in no_decay): # 检查参数名是否包含不衰减的项params_without_wd.append(p) # 不应用权重衰减的参数添加到列表else:params_with_wd.append(p) # 应用权重衰减的参数添加到列表# 返回两个配置字典,分别对应不同的参数组和权重衰减设置# 第一个字典应用权重衰减(从 args 中获取值),第二个字典不应用权重衰减(权重衰减为 0.0)return [{'params': params_with_wd, 'weight_decay': args.weight_decay},{'params': params_without_wd, 'weight_decay': 0.0}]# 请注意,这段代码假设模型的参数可以通过 named_parameters() 方法遍历,
# 并且 args 是包含权重衰减配置的对象。最后,我们希望随时能在验证集上评估模型,下面编写一个评估函数,用于计算验证集上的损失与困惑度:
import torch
from accelerate import Accelerator# 假设 model, eval_dataloader, 和 args 已经被正确定义和初始化def evaluate():"""评估模型性能的函数。返回:- loss.item(): 评估过程中的平均损失。- perplexity.item(): 评估过程中的平均困惑度。"""# 将模型设置为评估模式,这会关闭 Dropout 等随机层model.eval()# 初始化损失列表,用于存储每个批次的损失losses = []# 遍历验证数据加载器中的批次for step, batch in enumerate(eval_dataloader):# 禁用梯度计算,因为在评估过程中不需要更新模型权重with torch.no_grad():# 通过模型传递批次数据,并获取输出# 假设模型的输出是一个包含 'loss' 的字典outputs = model(batch, labels=batch)# 重复损失值以匹配验证批次大小,以便于后续处理loss = outputs.loss.repeat(args.valid_batch_size)# 收集所有进程的损失,以便于在主进程中计算平均损失losses.append(accelerator.gather(loss))# 如果设置了最大评估步数,并且在当前步骤已经达到,则跳出循环if args.max_eval_steps > 0 and step >= args.max_eval_steps:break# 计算所有批次损失的平均值loss = torch.mean(torch.cat(losses))# 计算困惑度,即损失的指数try:perplexity = torch.exp(loss)except OverflowError:# 如果损失过大导致溢出,将困惑度设置为无穷大perplexity = torch.tensor(float("inf"))# 返回评估过程中的平均损失和困惑度return loss.item(), perplexity.item()困惑度这个指标度量的是模型的输出概率分布对目标词元的预测程度,所以,困惑度越低,代表语言模型的性能越好。需要注意的是,可以通过对模型输出的交叉熵损失进行指数化来计算困惑度。特别是在训练刚开始的时候,那时的损失还很高,在计算困惑度的时候可能会出现溢出的情况。因此在这种情况下,我们一般将困惑度设置为无穷大。
在我们将这些函数写到训练脚本中之前,还需要使用一些与Hugging Face有关的函数。我们知道,Hugging Face Hub依靠Git指令来存储模型与数据集,通过huggingface_hub仓库中的Repository类,可以直接在代码中访问仓库并拉取代码、建立分支、提交变更或推送产物。我们会在训练脚本中使用这些函数,保证在训练过程中能持续不断地将checkpoint推送到Hub。
下面我们来编写训练脚本代码:
这段代码虽然很长,但它是基于分布式基础设施训练大型语言模型的标准写法,下面我们来剖析一下这段代码,特别介绍重要部分。
- 模型保存
我们在模型仓库中运行这段代码,在开始的时候,设置一个新分支,并从Weights& Biases获取run name来命名新分支。之后,我们会在每个checkpoint提交模型,并推送到Hub。通过这种设置,会让每个实验都有一个单独的分支,每次提交也对应于一个模型checkpoint。不过需要注意的是,务必调用wait_for_everyone()和unwrap_model()方法,因为我们需要确保模型在存储时已经与版本同步。
- 优化
T. Brown et al., “Language Models Are Few-Shot Learners”(https://arxiv.org/abs/2005.14165),(2020).
对于模型的优化,我们使用AdamW,并在一个线性预热周期后,使用余弦学习率调整策略。对于超参数,我们需要严格遵循GPT-3论文中提到的类似规模模型的设置方式 。
- 评估
当每次保存的时候我们在验证集上评估模型,也就是save_checkpoint_steps步骤和之后的训练。与验证集的损失一起,我们还记录了验证集的困惑度。
- 梯度累加与梯度checkpoint
你可以在OpenAI的发布帖子上关于梯度checkpoint的信息(https://oreil.ly/94oj1)。
即便在最新一代的GPU上运行,需要的数据批量大小也很难刚好就等于内存大小。因此,我们应用梯度累加方法,即在几个后向通道上收集梯度,一旦梯度累加到一定量就开始优化。在第6章中,我们介绍了使用Trainer来完成这个操作。对于大型模型来说,即使是单批量数据也不适合使用单个GPU来训练。使用一种叫作梯度checkpoint的方法,允许空间换时间(使用一些内存来换取20%的训练速度提升),这样甚至能打破使用单个GPU的限制。
有一个地方可能还有点令人疑惑,那就是在多GPU上训练模型究竟意味着什么。其实有好几种方法可以完成分布式训练,但是需要考虑模型的大小和数据量。Hugging Face Accelerate库所使用的方法叫作DataDistributedParallelism(简称DDP)(https://oreil.ly/m4iNm),这种方法的主要优点是允许使用大批量数据来更快地训练模型(这种批量数据不能在任何单GPU上被处理)。这个过程如下图所示。

下面分步骤介绍这个pipeline:
- 1.每个worker由一个GPU组成,在Hugging Face Accelerate库中,有一个运行在主进程上的数据加载器,它准备数据批量,并发送给所有的worker。
- 2.每个GPU接收一个批量的数据,并通过模型的本地副本计算前向和后向的损失和各自的累积梯度。
- 3.每个节点的梯度用reduce模式进行平均,将平均后的梯度返还给每个worker。
- 4.在每个节点上使用优化器单独应用梯度。虽然看起来这是多余的,但它避免了在节点之间传输大型模型的副本。我们至少需要更新一次模型,如果没有这种方法,则其他节点在收到更新的版本之前都将会处于等待状态。
- 5.一旦所有模型都更新了,就由主worker准备新的数据批量。
使用这种简单的方式,就可以增加GPU规模来加速大型模型的训练过程,且无须其他额外的开销。然而,在有些情况下,这还不足以获得理想的性能。例如,如果模型并不适用于单个GPU,就需要更复杂的并行化策略(https://oreil.ly/3uhfq)。
5、开启训练任务
这里我们将训练源代码保存在codeparrot_training.py文件中,并将它和包含所有Python依赖关系的requirements.txt文件一起上传到Hub上的模型仓库(https://oreil.ly/ndqSB)。由于Hub仓库的本质是Git仓库,因此我们可以使用Git的方式来操作它。在训练服务器上,可以通过下列命令来开启训练任务:

$ git clone https://huggingface.co/transformersbook/codeparrot
$ cd codeparrot$ pip install -r requirements.txt
$ wandb login
$ accelerate config
$ accelerate launch codeparrot_training.py执行完上述命令,模型就开始训练了。请注意,输入wandb login后,会有Weights & Biases日志提示你进行认证。accelerate config命令会帮助你完成基础设施的设置;可以在下图中查看本实验使用的设置参数。使用一个a2-megagpu-16g实例运行所有的实验,这是个拥有16个A100(40GB内存)的工作站。

在这样的基础设施上训练小型模型需要24h左右,大型模型则需要7天左右。如果是训练自定义模型,则要确保其能在小规模基础设施上能稳定运行,保障长期训练的结果。在整个训练过程完毕后,可以用下面的命令将Hub上的实验分支合并到主分支:

$ git checkout main
$ git merge <RUN_NAME>
$ git push上面的RUN NAME是你想设置的分支名称。现在我们已经训练完成了一个模型,下面来看看如何评估它的性能。
四、结果与分析
在持续监控一周的训练过程之后,可能会得到如图10-7所示的损失和困惑度曲线。从图中可以明显看出,训练损失和困惑度持续下降,并且损失曲线在对数坐标系几乎是线性的;还可以看出,大模型在处理词元方面收敛很快,尽管它的训练需要更多的时间。

下面我们来趁热打铁,用刚出炉的模型来完成一些代码。在评估结果方面,可以采用两种分析方法:定性分析和定量分析。定性分析需要根据具体的案例,确定模型输出在哪些情况下符合预期,以及哪些情况下不符合预期。定量分析则需要在一大批案例上评估模型的性能,本节将就这两个问题展开讨论。下面会介绍几个例子,以便介绍如何系统性地、稳健地评估模型性能。首先,把小模型设置到pipeline中,来续写代码:
# 从 transformers 库导入 pipeline 和 set_seed 函数
from transformers import pipeline, set_seed# 指定模型检查点的名称或路径,这里使用的是 'transformersbook/codeparrot-small'
model_ckpt = 'transformersbook/codeparrot-small'# 使用 pipeline 函数创建一个文本生成的 pipeline
# 'text-generation' 指定了 pipeline 的任务类型为文本生成
# model 参数指定了使用的预训练模型,这里使用 model_ckpt 变量
# device 参数指定了模型运行的设备,0 通常表示 CPU,如果是 GPU 可以是 0, 1, 2 等
# pipeline 函数返回一个可以直接调用的对象,用于生成文本
generation = pipeline('text-generation', model=model_ckpt, device=0)运行结果:

设置好之后就可以使用pipeline根据给定的提示来续写代码。在默认情况下,这个pipeline将生成预定义长度的代码,输出内容还可能包含多个函数和类。为了保证输出代码的简洁性,这里将实现一个first_block()函数,该函数使用正则表达式来提取一个函数或类的首段代码,后面的complete_code()函数运用此逻辑来输出CodeParrot模型自动生成的代码补全内容:
import re
from transformers import set_seeddef first_block(string):"""提取字符串中的第一个代码块。参数:- string: 输入的字符串,通常包含多行代码。返回:- 返回字符串中的第一个代码块,去除尾部的空白字符。"""# 使用正则表达式分割字符串,分割点包括 '\nclass', '\ndef', '\n#', '\n@', '\nprint', '\nif'# 这些分割点通常表示 Python 代码块的开始# [0] 选择第一个分割结果,即原始字符串中的第一个代码块# rstrip() 去除结果字符串尾部的空白字符(包括换行符)return re.split('\nclass|\ndef|\n#|\n@|\nprint|\nif', string)[0].rstrip()def complete_code(pipe, prompt, max_length=64, num_completions=4, seed=1):"""生成代码补全。参数:- pipe: 预训练的文本生成模型的 pipeline。- prompt: 代码提示,即用户输入的部分代码。- max_length: 生成代码的最大长度。- num_completions: 要生成的代码补全数量。- seed: 随机种子,用于确保结果的可重复性。返回:- 打印生成的代码补全。"""# 设置随机种子set_seed(seed)# 定义生成文本时使用的参数gen_kwargs = {"temperature": 0.4, # 温度参数,控制随机性"top_p": 0.95, # 核采样参数,控制生成的多样性"top_k": 0, # 选择顶部k个概率的token进行采样"num_beams": 1, # 束搜索的束数"do_sample": True, # 是否使用采样}# 使用 pipeline 生成代码补全# num_return_sequences 参数指定生成的序列数量# max_length 参数指定生成序列的最大长度# **gen_kwargs 将生成参数传递给 pipelinecode_gens = pipe(prompt, num_return_sequences=num_completions, max_length=max_length, **gen_kwargs)code_strings = []# 遍历生成的每个代码补全for code_gen in code_gens:# 使用 first_block 函数提取第一个代码块generated_code = first_block(code_gen['generated_text'][len(prompt):])# 将提取的代码块添加到列表中code_strings.append(generated_code)# 打印生成的代码补全,每个代码块之间用 '\n' 和 '='*80 分隔print(('\n'+'='*80 + '\n').join(code_strings))下面让模型输出一个计算矩形面积的函数:
# 定义一个代码提示字符串,这里是一个函数注解的开始部分
prompt = '''
def area_of_rectangle(a: float, b: float):"""Return the area of the rectangle."""'''# 调用 complete_code 函数来补全给定的代码提示
# 这里使用 generation pipeline 进行代码补全,传入提示字符串 prompt
# 由于函数的其他参数使用了默认值,所以没有在函数调用中显示指定
complete_code(generation, prompt)运行结果:
return math.sqrt(a * b) ================================================================================return math.sqrt(a * b) ================================================================================return a * b ================================================================================return a * b / 2.0
从结果看起来,效果非常棒!虽然并不是所有结果都对,但正确的结果就在其中。下面来尝试另一个场景,这个模型能从HTML字符串中提取出URL吗?来看看:
# 定义一个代码提示字符串,这里是一个函数的文档字符串部分
# 该函数名为 get_urls_from_html,预期接收一个 HTML 字符串参数,并返回其中的所有嵌入 URL
prompt = '''
def get_urls_from_html(html):"""Get all embedded URLs in a HTML string."""'''# 调用 complete_code 函数来补全给定的代码提示
# 这里使用 generation pipeline 进行代码补全,传入提示字符串 prompt
# 函数调用使用默认参数,没有显示指定 max_length、num_completions、seed 等
# 假设 complete_code 函数会处理 pipeline 的调用,生成代码补全,并打印结果
complete_code(generation, prompt)运行结果:
if not html:return []return [url for url in re.findall(r'<a href="(/[^/]+/[^"]+?)">', html)] ================================================================================return [url for url in re.findall(r'<a href="(.*?)"', html)if url] ================================================================================return [url for url in re.findall(r'<a href="(/.*)",\s*href="(/.*)"\s*>', html)] ================================================================================return [url for url in re.findall(r'<a href="(.*?)"', html)]
结果表明,虽然模型的第二次输出是错误的,但其他三次都是正确的。在Hugging Face主页上测试这个函数:


结果表明,所有https开头的URL都是外站链接,而其他则是Hugging Face的子页面路径。结果完全符合预期。最后,我们尝试使用这个大模型来尝试将一个Python函数转换为NumPy库函数写法:
# 指定模型检查点的名称或路径,这里使用的是 'transformersbook/codeparrot'
model_ckpt = 'transformersbook/codeparrot'# 使用 pipeline 函数创建一个文本生成的 pipeline
# 'text-generation' 指定了 pipeline 的任务类型为文本生成
# model 参数指定了使用的预训练模型,这里使用 model_ckpt 变量
# device 参数指定了模型运行的设备,0 表示 CPU;如果是 GPU,可以是 0, 1, 2 等
# pipeline 函数返回一个可以直接调用的对象,用于生成文本
generation = pipeline('text-generation', model=model_ckpt, device=0)# 定义一个代码提示字符串,这里提供了一个 Python 函数的开始部分
# 该提示包括一个原生 Python 函数 mean 的实现,以及使用 numpy 库的 mean 函数的开始
prompt = '''
# a function in native python:
def mean(a):return sum(a)/len(a)# the same function using numpy:
import numpy as np
def mean(a)
'''# 调用 complete_code 函数来补全给定的代码提示
# 这里使用 generation pipeline 进行代码补全,传入提示字符串 prompt
# max_length 参数指定了生成文本的最大长度
# 由于函数的其他参数使用了默认值,所以没有在函数调用中显示指定
# 假设 complete_code 函数会处理 pipeline 的调用,生成代码补全,并打印结果
complete_code(generation, prompt, max_length=64)运行结果:

return np.mean(a) ================================================================================return np.mean(a) ================================================================================return np.mean(a) ================================================================================return np.mean(a)
这非常有效!那么,是否能用CodeParrot模型来辅助我们建立一个Scikit-Learn模型呢?
# 定义一个代码提示字符串,这里提供了一个 Python 代码片段的开始部分
# 该代码片段生成了两个 NumPy 数组:X 是一个 100x100 的正态分布随机矩阵,y 是一个长度为 100 的包含 0 和 1 的随机整数数组
# 接着提供了一个注释,提示接下来要拟合一个包含 20 个估计器的随机森林分类器
prompt = '''
X = np.random.randn(100, 100)
y = np.random.randint(0, 1, 100)# fit random forest classifier with 20 estimators'''# 这里假设 generation 是之前创建的 pipeline 对象,用于文本生成任务,特别是代码补全
# 调用 complete_code 函数来补全给定的代码提示
# prompt 是代码补全的起点,提供了部分代码实现和注释
# max_length=96 参数指定了生成文本的最大长度,限制生成代码的长度
# complete_code 函数会处理 pipeline 的调用,生成代码补全,并打印结果
complete_code(generation, prompt, max_length=96)运行结果:
clf = RandomForestClassifier(n_estimators=20) clf.fit(X, y) ================================================================================clf = ExtraTreesClassifier(n_estimators=100,random_state=1, max_features=1,random_state=1) clf.fit(X, y) ================================================================================clf = ExtraTreesClassifier(n_estimators=20, n_jobs=n_jobs, random_state=1) clf.fit(X, y) ================================================================================clf = RandomForestClassifier(n_estimators=20, random_state=1) clf.fit(X, y)
尽管在第二次尝试中,它试图训练一个extra-trees分类器(https://oreil.ly/40Uy7),但最后它生成了我们在其他案例中期望的结果。
在之前介绍了一些用于度量生成文本质量的指标,其中的BLEU分数被广泛使用。然而这个指标在总体上存在一些局限性,非常不适用于我们的案例。BLEU分数通常度量的是参考文本和生成文本之间的n-grams重叠程度。在实际编写代码时,变量名、类名和方法名都有很大的自由度,只要它们是符合要求的,就不会有问题。因此,这类信息几乎是不可预测的(对人来说也一样)。
M. Chen et al., “Evaluating Large Language Models Trained on Code”(https://arxiv.org/abs/2107.03374),(2021).
在软件开发中,存在更好、更可靠的方法来度量代码的质量,比如常见的单元测试。然而这就是所有OpenAI Codex模型的评估方式:通过一组单元测试来运行几代编码任务的模型代码,并计算出通过测试的百分比。为了将性能评估做得更完善,我们可以使用这种方案,但这超出了本章的讨论范围,不做展开。如果感兴趣,你可以在该相关博客(https://oreil.ly/hKOP8)中找到CodeParrot在HumanEval基准测试上的细节。
附录
一、当前案例环境 package 的 版本如下
Package Version
------------------------- --------------
absl-py 2.1.0
accelerate 0.32.1
aiohttp 3.9.5
aiosignal 1.3.1
alembic 1.13.2
anyio 4.4.0
argon2-cffi 23.1.0
argon2-cffi-bindings 21.2.0
arrow 1.3.0
asttokens 2.4.1
async-lru 2.0.4
attrs 23.2.0
Babel 2.15.0
beautifulsoup4 4.12.3
bleach 6.1.0
certifi 2024.7.4
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
colorama 0.4.6
coloredlogs 15.0.1
colorlog 6.8.2
comm 0.2.2
contourpy 1.2.1
cycler 0.12.1
datasets 2.20.0
debugpy 1.8.2
decorator 5.1.1
defusedxml 0.7.1
dill 0.3.8
docker-pycreds 0.4.0
executing 2.0.1
faiss-cpu 1.8.0.post1
fastjsonschema 2.20.0
filelock 3.15.4
flatbuffers 24.3.25
fonttools 4.53.1
fqdn 1.5.1
frozenlist 1.4.1
fsspec 2024.5.0
gdown 5.2.0
gitdb 4.0.11
GitPython 3.1.43
greenlet 3.0.3
grpcio 1.65.1
h11 0.14.0
httpcore 1.0.5
httpx 0.27.0
huggingface-hub 0.23.4
humanfriendly 10.0
idna 3.7
intel-openmp 2021.4.0
ipykernel 6.29.5
ipython 8.26.0
ipywidgets 8.1.3
isoduration 20.11.0
jedi 0.19.1
Jinja2 3.1.4
joblib 1.4.2
json5 0.9.25
jsonpointer 3.0.0
jsonschema 4.23.0
jsonschema-specifications 2023.12.1
jupyter 1.0.0
jupyter_client 8.6.2
jupyter-console 6.6.3
jupyter_core 5.7.2
jupyter-events 0.10.0
jupyter-lsp 2.2.5
jupyter_server 2.14.2
jupyter_server_terminals 0.5.3
jupyterlab 4.2.3
jupyterlab_pygments 0.3.0
jupyterlab_server 2.27.2
jupyterlab_widgets 3.0.11
kiwisolver 1.4.5
Mako 1.3.5
Markdown 3.6
MarkupSafe 2.1.5
matplotlib 3.9.1
matplotlib-inline 0.1.7
mistune 3.0.2
mkl 2021.4.0
mpmath 1.3.0
multidict 6.0.5
multiprocess 0.70.16
nbclient 0.10.0
nbconvert 7.16.4
nbformat 5.10.4
nest-asyncio 1.6.0
networkx 3.3
nlpaug 1.1.11
notebook 7.2.1
notebook_shim 0.2.4
numpy 1.26.4
onnx 1.16.1
onnxruntime 1.18.1
optuna 3.6.1
overrides 7.7.0
packaging 24.1
pandas 2.2.2
pandocfilters 1.5.1
parso 0.8.4
pillow 10.4.0
pip 24.1.2
platformdirs 4.2.2
prometheus_client 0.20.0
prompt_toolkit 3.0.47
protobuf 4.25.3
psutil 6.0.0
pure-eval 0.2.2
pyarrow 16.1.0
pyarrow-hotfix 0.6
pycparser 2.22
Pygments 2.18.0
pyparsing 3.1.2
pyreadline3 3.4.1
PySocks 1.7.1
python-dateutil 2.9.0.post0
python-json-logger 2.0.7
pytz 2024.1
pywin32 306
pywinpty 2.0.13
PyYAML 6.0.1
pyzmq 26.0.3
qtconsole 5.5.2
QtPy 2.4.1
referencing 0.35.1
regex 2024.5.15
requests 2.32.3
rfc3339-validator 0.1.4
rfc3986-validator 0.1.1
rpds-py 0.19.0
safetensors 0.4.3
scikit-learn 1.5.1
scikit-multilearn 0.2.0
scipy 1.14.0
Send2Trash 1.8.3
sentencepiece 0.2.0
sentry-sdk 2.10.0
setproctitle 1.3.3
setuptools 70.0.0
six 1.16.0
smmap 5.0.1
sniffio 1.3.1
soupsieve 2.5
SQLAlchemy 2.0.31
stack-data 0.6.3
sympy 1.13.0
tbb 2021.13.0
tensorboard 2.17.0
tensorboard-data-server 0.7.2
terminado 0.18.1
threadpoolctl 3.5.0
tinycss2 1.3.0
tokenizers 0.13.3
torch 2.3.1+cu121
torchaudio 2.3.1+cu121
torchvision 0.18.1+cu121
tornado 6.4.1
tqdm 4.66.4
traitlets 5.14.3
transformers 4.24.0
types-python-dateutil 2.9.0.20240316
typing_extensions 4.12.2
tzdata 2024.1
uri-template 1.3.0
urllib3 2.2.2
wandb 0.17.5
wcwidth 0.2.13
webcolors 24.6.0
webencodings 0.5.1
websocket-client 1.8.0
Werkzeug 3.0.3
wheel 0.43.0
widgetsnbextension 4.0.11
xxhash 3.4.1
yarl 1.9.4
相关文章:
AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理
AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理 目录 AGI 之 【Hugging Face】 的【从零训练Transformer模型】之二 [ 从零训练一个模型 ] 的简单整理 一、简单介绍 二、Transformer 1、模型架构 2、应用场景 3、Hugging …...

十大排序的稳定性和时间复杂度
十大排序算法的稳定性和时间复杂度是数据结构和算法中的重要内容。 以下是对这些算法的稳定性和时间复杂度的详细分析: 稳定性 稳定性指的是排序算法在排序过程中是否能够保持相等元素的原始相对顺序。根据这个定义,我们可以将排序算法分为稳定排序和…...
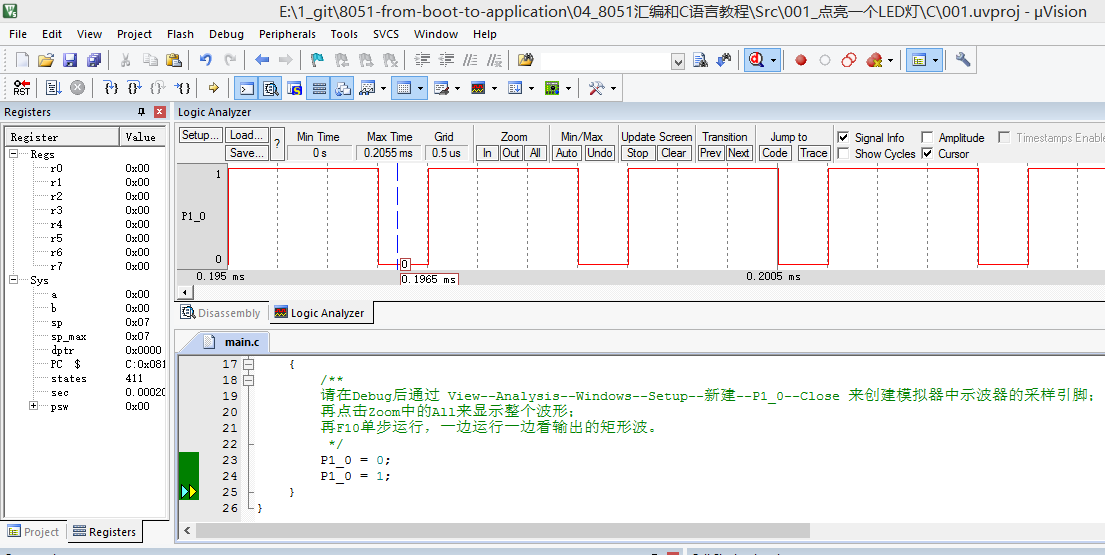
【系列教程之】1、点亮一个LED灯
1、点亮一个LED灯 作者将狼才鲸创建日期2024-07-23 CSDN教程目录地址:【目录】8051汇编与C语言系列教程本Gitee仓库原始地址:才鲸嵌入式/8051_c51_单片机从汇编到C_从Boot到应用实践教程 本源码包含C语言和汇编工程,能直接在电脑中通过Keil…...

搜维尔科技:Manus Metagloves使用精确的量子跟踪技术捕捉手部每一个细节动作
Manus Metagloves使用精确的量子跟踪技术捕捉手部每一个细节动作 搜维尔科技:Manus Metagloves使用精确的量子跟踪技术捕捉手部每一个细节动作...

机器学习 | 阿里云安全恶意程序检测
目录 一、数据探索1.1 数据说明1.2 训练集数据探索1.2.1 数据特征类型1.2.2 数据分布1.2.3 缺失值1.2.4 异常值1.2.5 标签分布探索 1.3 测试集探索1.3.1 数据信息1.3.2 缺失值1.3.3 数据分布1.3.4 异常值 1.4 数据集联合分析1.4.1 file_id 分析1.4.2 API 分析 二、特征工程与基…...

python打包exe文件-实现记录
1、使用pyinstaller库 安装库: pip install pyinstaller打包命令标注主入库程序: pyinstaller -F.\程序入口文件.py 出现了一个问题就是我在打包运行之后会出现有一些插件没有被打包。 解决问题: 通过添加--hidden-importcomtypes.strea…...

基本的DQL语句-单表查询
一、DQL语言 DQL(Data Query Language 数据查询语言)。用途是查询数据库数据,如SELECT语句。是SQL语句 中最核心、最重要的语句,也是使用频率最高的语句。其中,可以根据表的结构和关系分为单表查询和多 表联查。 注意:所有的查询…...

Vue3 对比 Vue2
相关信息简介2020年9月18日,Vue.js发布3.0版本,代号:One Piece(海贼王) 2 年多开发, 100位贡献者, 2600次提交, 600次 PR、30个RFC Vue3 支持 vue2 的大多数特性 可以更好的支持 Typescript,提供了完整的…...

2024中国大学生算法设计超级联赛(1)
🚀欢迎来到本文🚀 🍉个人简介:陈童学哦,彩笔ACMer一枚。 🏀所属专栏:杭电多校集训 本文用于记录回顾总结解题思路便于加深理解。 📢📢📢传送门 A - 循环位移解…...

offer题目51:数组中的逆序对
题目描述:在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。例如,在数组{7,5,6,4}中,一共存在5个逆序对,分别是(7…...

45、PHP 实现滑动窗口的最大值
题目: PHP 实现滑动窗口的最大值 描述: 给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。 例如: 如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3, 那么一共存在6个滑动窗口, 他们的最大值…...

【计算机视觉】siamfc论文复现实现目标追踪
什么是目标跟踪 使用视频序列第一帧的图像(包括bounding box的位置),来找出目标出现在后序帧位置的一种方法。 什么是孪生网络结构 孪生网络结构其思想是将一个训练样本(已知类别)和一个测试样本(未知类别)输入到两个CNN(这两个CNN往往是权值共享的)中࿰…...

数学建模学习(111):改进遗传算法(引入模拟退火、轮盘赌和网格搜索)求解JSP问题
文章目录 一、车间调度问题1.1目前处理方法1.2简单案例 二、基于改进遗传算法求解车间调度2.1车间调度背景介绍2.2遗传算法介绍2.2.1基本流程2.2.2遗传算法的基本操作和公式2.2.3遗传算法的优势2.2.4遗传算法的不足 2.3讲解本文思路及代码2.4算法执行结果: 三、本文…...

Golang | Leetcode Golang题解之第241题为运算表达式设计优先级
题目: 题解: const addition, subtraction, multiplication -1, -2, -3func diffWaysToCompute(expression string) []int {ops : []int{}for i, n : 0, len(expression); i < n; {if unicode.IsDigit(rune(expression[i])) {x : 0for ; i < n &…...

Unity客户端接入原生Google支付
Unity客户端接入原生Google支付 1. Google后台配置2. 开始接入Java部分C#部分Lua部分 3. 导出工程打包测试参考踩坑注意 1. Google后台配置 找到内部测试(这个测试轨道过审最快),打包上传,这个包不需要接入支付,如果已…...

Spring Cloud之五大组件
Spring Cloud 是一系列框架的有序集合,为开发者提供了快速构建分布式系统的工具。这些组件可以帮助开发者做服务发现,配置管理,负载均衡,断路器,智能路由,微代理,控制总线等。以下是 Spring Cl…...
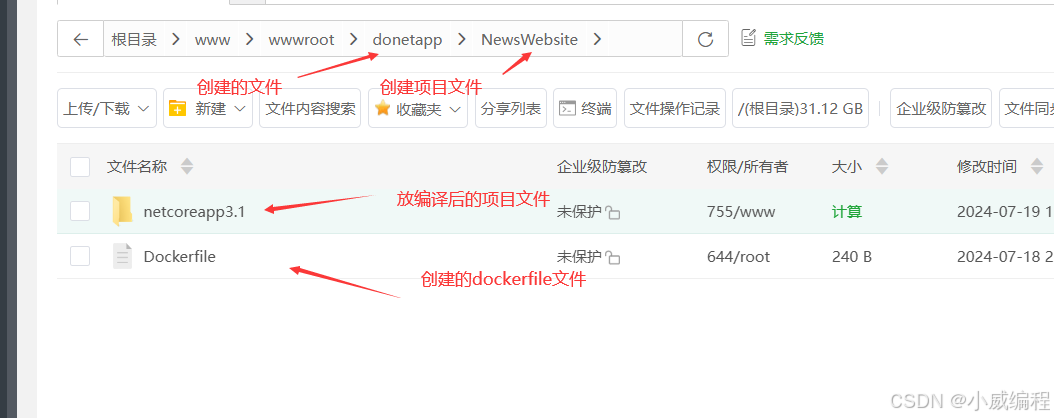
在 CentOS 7 上安装 Docker 并安装和部署 .NET Core 3.1
1. 安装 Docker 步骤 1.1:更新包索引并安装依赖包 先安装yum的扩展,yum-utils提供了一些额外的工具,这些工具可以执行比基本yum命令更复杂的任务 sudo yum install -y yum-utils sudo yum update -y #更新系统上已安装的所有软件包到最新…...

redis的学习(一):下载安装启动连接
简介 redis的下载,安装,启动,连接使用 nosql nosql,即非关系型数据库,和传统的关系型数据库的对比: sqlnosql数据结构结构化非结构化数据关联关联的非关联的查询方式sql查询非sql查询事务特性acidbase存…...

前端设计模式面试题汇总
面试题 1. 简述对网站重构的理解? 参考回答: 网站重构:在不改变外部行为的前提下,简化结构、添加可读性,而在网站前端保持一致的行为。也就是说是在不改变UI的情况下,对网站进行优化, 在扩展的…...
安装python3.12.2环境)
linux(CentOS、Ubuntu)安装python3.12.2环境
1.下载官网Python安装包 wget https://www.python.org/ftp/python/3.12.2/Python-3.12.2.tar.xz 1.1解压 tar -xf Python-3.12.2.tar.xz 解压完后切换到Python-3.12.2文件夹(这里根据自己解压的文件夹路径) cd /usr/packages/Python-3.12.2/ 1.2升级软件包管理器 CentOS系…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...