机器学习(五) -- 无监督学习(1) --聚类1
系列文章目录及链接
上篇:机器学习(五) -- 监督学习(7) --SVM2
下篇:机器学习(五) -- 无监督学习(1) --聚类2
前言
tips:标题前有“***”的内容为补充内容,是给好奇心重的宝宝看的,可自行跳过。文章内容被“文章内容”删除线标记的,也可以自行跳过。“!!!”一般需要特别注意或者容易出错的地方。
本系列文章是作者边学习边总结的,内容有不对的地方还请多多指正,同时本系列文章会不断完善,每篇文章不定时会有修改。
由于作者时间不算富裕,有些内容的《算法实现》部分暂未完善,以后有时间再来补充。见谅!
文中为方便理解,会将接口在用到的时候才导入,实际中应在文件开始统一导入。
一、通俗理解及定义
1、什么叫聚类(What)
聚类(clustering):数据没有标签,将相似的样本自动分为一类(子集,簇,cluster)。

有监督VS无监督



2、聚类的目的(Why)
通过迭代的方式,将数据划分为K个不同的簇,并使得每个数据点与其所属簇的质心(聚类中心、中心点、均值点)之间的距离之和最小。
聚类方法:
基于划分(距离):K-means
基于层次:BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
基于密度:DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
基于网格:Statistical Information Grid(STING)算法
基于模型:统计和神经网络方法
3、怎么做(How)
K-means:

首先要知道将数据划分成多少类别
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
聚类的结果是簇,评价方式是簇(类)内距离和簇(类)间距离,簇内距离越小越好,簇间距离越大越好
二、原理理解及公式
1、基本概念
聚类任务:根据某种相似性,把一组数据划分成若干个簇的过程。
问题:
- 相似性怎么定义!-------二、1.3、相似性度量
- 可能存在的划分!-------二、1.4、第二类Stirling数
- 若干个簇=有多少个簇?------(其中之一:二、2.3.1、“肘”方法 (Elbow method) — K值确定)
1.1、簇
簇:分组后每个组称为一个簇,每个簇的样本对应一个潜在的类别。样本没有类别标签,因此是聚类一种典型的无监督学习方法。
簇的条件:相同簇的样本之间距离较近;不同簇的样本之间距离较远。
明显分离的簇:每个点到同簇中任意点的距离比到不同簇中所有点的距离更近。
基于中心的簇:每个点到其簇中心的距离比到任何其他簇中心的距离更近。
基于邻近的簇:每个点到该簇中至少一个点的距离比到不同簇中任意点的距离更近。
基于密度的簇:簇是被低密度区域分开的高密度区域。
概念簇:簇中的点具有由整个点集导出的某种一般共同性质。(在两个环相交处的点属于两个环)
1.2、质心
机器学习中“质心”:所有数据的均值u通常被称为这个簇的“质心”(x求均值,y求均值,得到的这个点)

1.3、相似性度量
1.3.1、距离
距离度量具体可看:机器学习(五) -- 监督学习(1) -- k近邻
欧式距离,公式:

曼哈顿距离,,公式:

1.3.2、余弦相似性
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。

1.3.3、Jaccord相似性
Jaccard系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具 体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只关心个体间共同具有的特征是否一致这个问题。

eg:

1.4、第二类Stirling数
聚类问题:可能的划分
假设我们要把 n = 4个不同的数据点放入不相同 的 k = 2 个无差别的盒子里,有几种方案?

集合的一个划分,表示将n 个不同的元素拆分成 k 个集合的方案数, 记为S(n,k)。

随着集合元素𝒏和子集个数𝒌的增加,方案数𝑆(𝑛,𝑘)呈爆炸式增长!!!
2、K-meas
2.1、理解
K-means 是我们最常用的基于距离的聚类算法,其认为两个目标的距离越近,相似度越大。
目标:最小化类内间距
K-means算法针对聚类所得簇划分最小化平方误差,平方误差刻画了簇内样本围绕均值向量的紧密程度,平方误差值越小则簇内样本相似度越高。
2.2、步骤
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程

2.3、公式
对于给定数据x,以及簇的个数k:

c_i:第 i 个簇
m_i:第 i 个簇的中心

SSE随着聚类迭代,其值会越来越小,直到最后趋于稳定
(如果质心的初始值选择不好,SSE只会达到一个不怎么好的局部最优解。)
2.3.1、“肘”方法 (Elbow method) — K值确定

- 对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算每个点到其所属的簇中心的距离的平方和;
- 平方和是会逐渐变小的,直到k==n时平方和为0,因为每个点都是它所在的簇中心本身。
- 在这个平方和变化过程中,会出现一个拐点也即“肘”点,下降率突然变缓时即认为是最佳的k值。
在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
2.3.2、轮廓系数法(Silhouette Coefficient)
K-means性能指标评估--轮廓系数【机器学习(四) -- 模型评估(4)】
公式:S的范围在[-1,1],越大越好

a:样本 i 到同一簇内其他点不相似程度的平均值
b:样本 i 到其他簇的平均不相似程度的最小值

对于每一个样本
1、计算蓝1到自身类别的点距离的平均值a
2、计算蓝1分别到红色类别,绿色类别所有的点的距离,求出平均值b1, b2,取其中最小的值当做b
b>>a: 1完美
a>>b:-1最差
如果s小于0,说明a 的平均距离大于最近的其他簇。聚类效果不好
如果s越大,说明a的平均距离小于最近的其他簇。聚类效果好
轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优
超过0.1,说明聚类效果很好
轮廓系数API
sklearn.metrics.silhouette_score导入:
from sklearn.metrics import silhouette_score语法:
silhouette_score(X, labels)X:特征值labels:被聚类标记的目标值2.4、eg:
step1:随机设置3个初始聚类中心

step2:每一个点根据到每个聚类中心的距离分类

step3:重新计算每个新的聚类中心

step4:重复2、3步(如下3个点被重新分配),直到,聚类中心不在变化

2.5、K-means++
2.5.1、理解
K-means算法得到的聚类结果严重依赖与初始簇中心的选择,如果初始簇中心选择不好,就会陷入局部最优解,因此提出了K-means++算法,它改进了K-means算法初始中心点的选取。
核心思想是:再选择一个新的聚类中心时,距离已有聚类中心越远的点,被选取作为聚类中心的概率越大。
2.5.2、步骤
- 从数据集中随机选择第一个质心。
- 对于每个数据点x,计算其到已选择的所有质心的最短距离D(x)。
- 选择一个新的数据点作为下一个质心,选择的概率与D(x)成正比,即概率P(x) = D(x) / ΣD(x)。
- 重复步骤2和3,直到选择了K个质心。
这种选择策略确保了质心之间的分散性,从而提高了聚类效果。
2.5.3、eg:




3、K-Medoids(k-中心)
3.1、理解
k-中心和k-均值很像,不同的是形心的更新选择,k-均值是通过求得均值进行更新形心的,而k-中心是随机选择k个对象作为初始的k个簇的代表点,反复用非代表点来代替代表点,直到找到误差平方和最小的那个点来作为数据中心点。这样划分方法是基于最小化所有对象与其参照点之间的相异度之和的原则来执行的,这是 k-medoids 方法的基础。
3.2、步骤
- 随机选择 k 个数据点作为初始聚类中心
- 将每个剩余的数据点分配在临近的聚类中心的类中当中去
- 每个类中计算每个数据点为聚类中心时的代价函数的值,选取最小值成为新的聚类中心
- 重复2、3过程,直到所有的聚类中心不再发生变化,或达到设定的最大迭代次数
4、层次聚类
4.1、理解
把每一个单个的观测都视为一个类,而后计算各类之间的距离,选取最相近的两个类,将它们合并为一个类。新的这些类再继续计算距离,合并到最近的两个类。如此往复,最后就只有一个类。然后用树状图记录这个过程,这个树状图就包含了我们所需要的信息。

4.2、方法:
- 凝聚的层次聚类:AGNES算法 (AGglomerative NESting)
- 分裂的层次聚类:DIANA算法 (DIvisive ANALysis)
- 层次聚类优化算法:CF-Tree(Cluster Feature Tree)、BIRCH算法 (平衡迭代削减聚类法)、CURE算法(使用代表点的聚类法)
4.2.1、AGNES
采用自底向上的策略。
凝聚型层次聚类有多种变体,这些变体主要基于不同的距离度量方法和链结标准来定义。以下是一些常见的变体:(AGNES算法中簇间距离:)
最近邻链结(SL聚类)
两个聚簇中最近的两个样本之间的距离(single-linkage聚类法);
最终得到模型容易形成链式结构。
最远邻链结(CL聚类)
两个聚簇中最远的两个样本的距离(complete-linkage聚类法);
如果存在异常值,那么构建可能不太稳定。
平均链结(AL聚类)
两个聚簇中样本间两两距离的平均值(average-linkage聚类法);
两个聚簇中样本间两两距离的中值(median-linkage聚类法);
Ward链结(WL聚类)
两个聚簇中样本合并后产生的方差增加值被用作这两个聚类之间的距离。

4.3、eg:
一组数据D={a,b,c,d,e},它们之间的距离矩阵为:
step1:每个样本都是一个类

step2:将最近的两个类合并为一个新的类,并重新计算类之间的距离然后更新距离矩阵:

step3:重复:选择距离最近的两个类合并为新的类:

step4:不断重复上述两个步骤,最终只剩下一个类的时候,停止:

5、密度聚类
5.1、理解
密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。
通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
核心思想是:在数据空间中找到分散开的密集区域,简单来说就是画圈,其中要定义两个参数,一个是圈的最大半径,一个是一个圈里面最少应该容纳多少个点。
5.2、方法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)

5.3、eg:
step1:设定参数密度阈值N=3,也就是每个圈里必须满足3个点,才能称为一个簇,首先我们随机选取一些候选的核心点:
这些灰色点为核心点的候选:

step2:以这些候选的核心点为圆心按照设定的半径画圆圈:

step3:如果圈内满足三个点,那就是一个簇,簇内点候选的核心点就是核心点:这些红色的点就是核心点,而灰色的点因为其圈内点数不满足阈值,所以不是核心点:

step4:合并重合的簇:

6、网格聚类
6.1、理解
将数据空间划分为网格单元,将数据对象映射到网格单元中,并计算每个单元的密度。根据预设阈值来判断每个网格单元是不是高密度单元,由邻近的稠密单元组成“类”。

6.2、方法
- CLIQUE (Clustering in QUEst)
- STING (Statistical Information Grid 统计信息网格)
- MAFIA (Merging of adaptive interval approach to spatial datamining 空间数据挖掘的自适应区间方法的合并)
- Wave Cluster (小波聚类)
- O-CLUSTER (orthogonal partitioning CLUSTERing 正交分区聚类)
- Axis Shifted Grid ClusteringAlgorithm(轴移动网格聚类算法)
- Adaptive Mesh Refinement (自适应网格细化)
6.3、步骤
- 将数据空间划分为有限数量的单元格;
- 随机选择一个单元格“𝑐”,𝑐不应该事先遍历;
- 计算“𝑐”的密度;
- 如果“𝑐”的密度大于阈值的密度:
- 将单元格“c”标记为新的聚类(cluster);
- 计算“c”所有邻居的密度;
- 如果相邻单元的密度大于阈值密度,将其添加到集群中,并且重复步骤4.2和4.3直到没有相邻单元的密度大于阈值密度
- 重复步骤2,3,4,直到遍历所有单元格
6.4、eg:
step1:选择一定宽度的格子来分割数据空间

step2:设置阈值为2,将相邻稠密的格子合并形成一个“类”
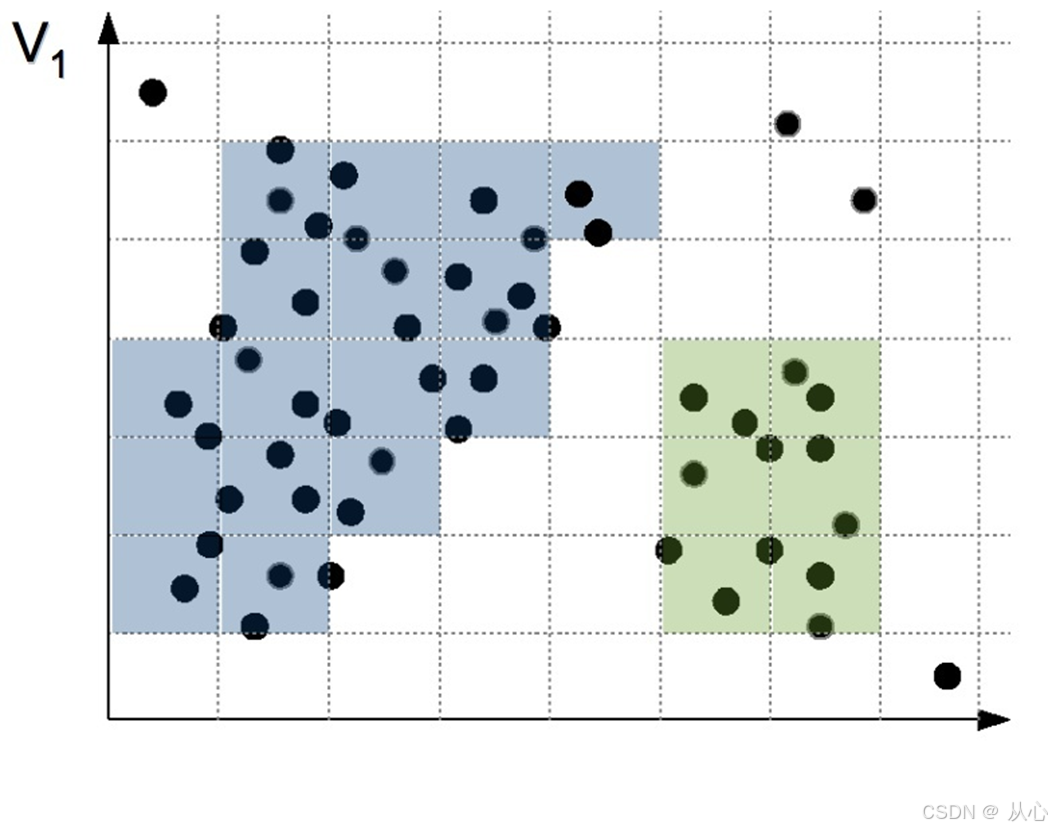
7、优缺点
7.1、K-means优缺点
7.1.1、优点:
- 属于无监督学习,无须准备训练集
- 原理简单,实现起来较为容易
- 结果可解释性较好
7.1.2、缺点:
- 需手动设置k值。 在算法开始预测之前,我们需要手动设置k值,即估计数据大概的类别个数,不合理的k值会使结果缺乏解释性
- 可能收敛到局部最小值, 在大规模数据集上收敛较慢
- 对于异常点、离群点敏感
- 非凸形状无法聚类
7.2、K-means++优点
- 减少局部最优解的风险:更大概率选择相距较远的初始质心,提高聚类质量。
- 理论保证:K-means++能够给出接近最优解的界。
- 效率:虽然初始化复杂度有所增加,但整体算法依然保持高效,尤其是对于大规模数据集。
7.3、K-Medoids优缺点
7.3.1、优势:
- 噪声鲁棒性比较好。(当存在噪音和孤立点时,比K-means效果好)
7.3.2、缺点:
- 运行速度较慢,计算质心的步骤时间复杂度是O(n^2)
- K-medoids 对于小数据集工作得很好, 但不能很好地用于大数据集
7.4、层次聚类优缺点
7.4.1、优点:
- 距离和规则的相似度容易定义,限制少
- 不需要预先制定聚类数
- 可以发现类的层次关系
7.4.2、缺点:
- 计算复杂度太高;
- 异常值也能产生很大影响;
- 算法很可能聚类成链状
7.5、密度聚类优缺点
7.5.1、优点:
- 不需要指定簇的个数;
- 可以对任意形状的稠密数据集进行聚类。相对的,K-Means之类的聚类算法一般只适用于凸数据集;
- 擅长找到离群点(检测任务);
- 只有两个参数𝜀和MinPts
- 聚类结果没有偏倚。K-Means之类的聚类算法初始值对聚类结果有很大影响。
7.5.2、缺点:
- 高维数据有些困难;
- Sklearn中效率很慢(数据削减策略);
- 如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,用DBSCAN聚类一般不适合;
- 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值𝜀,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
7.6、网格聚类优缺点
7.6.1、优点:
- 网格聚类算法相对简单,易于实现和理解;
- 网格聚类算法可以有效地处理大规模数据,因为它可以通过网格结构将数据划分为多个小区域,从而减少计算量;
- 网格聚类算法可以自适应地调整簇的数量和大小,从而更好地适应不同的数据分布;
7.6.2、缺点:
- 网格聚类算法对于数据的形状和密度比较敏感,如果数据分布比较复杂或者存在噪声,可能会导致聚类效果不佳;
- 网格聚类算法需要手动设置一些参数,如网格大小、邻域半径等,这些参数的选择可能会影响聚类效果;
- 网格聚类算法可能会产生重叠的簇,这些簇的边界可能比较模糊,难以解释;
旧梦可以重温,且看:机器学习(五) -- 监督学习(7) --SVM2
欲知后事如何,且看:机器学习(五) -- 无监督学习(1) --聚类2
相关文章:
机器学习(五) -- 无监督学习(1) --聚类1
系列文章目录及链接 上篇:机器学习(五) -- 监督学习(7) --SVM2 下篇:机器学习(五) -- 无监督学习(1) --聚类2 前言 tips:标题前有“***”的内容…...
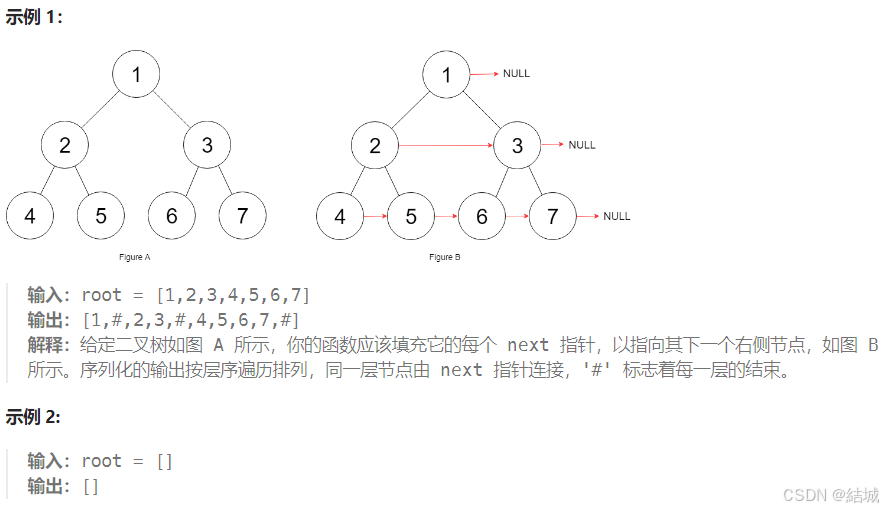
leetcode 116. 填充每个节点的下一个右侧节点指针
leetcode 116. 填充每个节点的下一个右侧节点指针 题目 给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下: struct Node { int val; Node *left; Node *right; Node *next; } 填充它的每个 next …...
[C++]优先级队列
1 .了解优先级队列 优先级队列是一种容器适配器,根据一些严格的弱排序标准,专门设计使其第一个元素始终是它所包含的元素中最大的元素。 此上下文类似于堆,其中可以随时插入元素,并且只能检索最大堆元素(优先级队列中顶…...

学习大数据DAY22 Linux 基 本 指 令 3与 在 Linux 系 统 中 配 置MySQL 和 Oracle
目录 网络配置类 ps 显示系统执行的进程 kill systemctl 服务管理 配置静态 ip 常见错误---虚拟机重启网卡失败或者网卡丢失 mysql 操作 上机练习 6---安装 mysql---参考《mysql 安装》文档 解锁 scott 重启后的步骤 上机练习 7---安装 oracle---参考《oracle 安装》…...

scp 服务器复制命令
步骤如下: 终端执行如下命令 #ssh-keygen -t rsa 2. 密钥生成后会在 /root/.ssh/ 文件夹下产生两个文件 id_rsa id_rsa.pub 将 id_rsa.pub 文件复制到 152.136.121.24 执行如下命令 scp /root/.ssh/id_rsa.pub root152.136.121.24:/root/.ssh/authorized_keys…...

PyQt5学习路线
后续会根据该文章的路线逐步发布对应的教程,订阅专栏不迷路🥰 本专栏纯干货🤩 学习Python的PyQt5库,可以遵循以下的学习路线: 1. Python基础 掌握Python语法:确保你熟悉Python的基本语法,包括…...

2024论文精读:利用大语言模型(GPT)增强上下文学习去做关系抽取任务
文章目录 1. 前置知识2. 文章通过什么来引出他要解决的问题3. 作者通过什么提出RE任务存在上面所提出的那几个问题3.1 问题一:ICL检索到的**示范**中实体个关系的相关性很低。3.2 问题二:示范中缺乏解释输入-标签映射导致ICL效果不佳。 4. 作者为了解决上…...

WEB 手柄 http通信,mcu端解析代码 2024/7/23 日志
WEB 手柄 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>WEB遥控器</title> </head> &l…...

cmake中的正则表达式
以下字符或者字符组合在cmake的正则表达式中的特殊含义: ^ 匹配输入的开始 $ 匹配输入的结束 . 匹配任意一个字符 \<char> 匹配一个字符,如.匹配字符.,\匹配字符\,\a匹配字符a [ ] 匹配在括号里面的任意字符࿰…...

05. Java 三大范式
1. 前言 在面向对象语言中涉及到诸多的设计模式,例如单例模式、适配器模式,设计模式的存在是为了让系统中的代码逻辑更加清晰,帮助开发者建立更加健壮的系统,同时满足易修改特性和易扩展特性。数据库设计时也存在类似设计模式的通…...

opencv 按键开启连续截图,并加载提示图片
背景图小图 键盘监听使用的是pynput 库 保存图片时使用了年月日时分秒命名 原图: from pynput import keyboard import cv2 import time# 键盘监听 def on_press(key):global jieglobal guanif key.char a:jie Trueelif key.char d:jie Falseelif key.char…...

Android-- 集成谷歌地图
引言 项目需求需要在谷歌地图: 地图展示,设备点聚合,设备站点,绘制点和区域等功能。 我只针对我涉及到的技术做一下总结,希望能帮到开始接触谷歌地图的伙伴们。 集成步骤 1、在项目的modle的build.gradle中添加依赖如…...

Jvm是如何处理异常的
异常抛出 当Java程序运行时遇到无法处理的情况时,会抛出一个异常(比如在一个方法中如果发生异常),这时会创建一个异常对象,并转交给JVM,该异常对象包含异常名称,异常描述以及异常发生时应用程序的状态。创建异常对象并转交给JVM的过程称为抛出异常。 异常捕捉 当JVM检测…...

recursion depth exceeded” error
有些时候不可以用jax.jit装饰器 参考资料:使用 JAX 后端在 Keras 3 中训练 GAN |由 Khawaja Abaid |中等 (medium.com)...

虚拟现实和增强现实技术系列—Expressive Talking Avatars
文章目录 1. 概述2. 背景介绍3. 数据集3.1 设计标准3.2 数据采集 4. 方法4.1 概述4.2 架构4.3 目标函数 5. 实验评测5.1 用户研究5.2 我们方法的结果5.3 比较与消融研究 1. 概述 支持远程协作者之间的交互和沟通。然而,明确的表达是出了名的难以创建,主…...

网站验证:确保网络安全与信任的重要步骤
网站验证:确保网络安全与信任的重要步骤 引言 在数字时代,网站验证是确保网络安全和建立用户信任的关键措施。随着网络诈骗和恶意软件的日益增多,验证网站的真实性和安全性变得尤为重要。本文将探讨网站验证的重要性、常见的验证方法以及如…...

C语言——字符串比较函数strcmp和strncmp
目录 strcmp 函数原型如下: 示例 注意事项 strcmp自实现代码: strncmp 函数 函数原型: 参数: 返回值: 特点: 两者之间的区别和联系 strcmp strcmp 是 C 语言标准库中的一个函数,用于…...

redis的集群模式
目录 1. 为什么使用redis集群 2. 主从模式 2.1修改配置文件 2.2 开启三台redis服务 2.3配置主从关系 3. 哨兵模式 3.1 监控功能 3.2 选举的机制 3.3 准备条件 4. 去中心化模式 4.1 准备三主三从 4.2 启动redis 4.3 分配槽以及主从关系 4.4 命令行的客户端 redis提供…...

基于微信小程序+SpringBoot+Vue的青少年科普教学系统平台(带1w+文档)
基于微信小程序SpringBootVue的青少年科普教学系统平台(带1w文档) 基于微信小程序SpringBootVue的青少年科普教学系统平台(带1w文档) 这个工具就是解决上述问题的最好的解决方案。它不仅可以实时完成信息处理,还缩短高校教师成果信息管理流程,使其系统化…...

智能听觉:从任务特定的机器学习到基础模型
关键词:计算机听觉、音频基础模型、多模态学习、声音事件检测 声音无处不在,弥漫于我们生活的每一个角落。鸟儿向伴侣倾诉心意的歌声,浓缩咖啡机中蒸汽的嘶嘶作响,午后阳光下昆虫振翅的嗡嗡声,金属屋顶上雨滴跳跃的滴答…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...