常用的python程序汇总——入门级
只用于记录最近的一些日常程序。
目录
前言
一、文件和目录管理
1.读取文件结构
读取所有文件夹和文件
读取到N级子文件夹和文件
只读取到N级子文件夹
2.遍历文件并处理(复制、删除)
说明:
二、数据分析和处理
三、数据可视化
四、文本处理
总结
前言
Python 是一种高级编程语言,因其简洁易读、功能强大和广泛的应用而受到许多开发者的喜爱。
一、文件和目录管理
- os 和 shutil:处理文件和目录操作,如复制、移动、删除文件。
- glob:文件模式匹配,查找符合特定模式的文件。
import os
import shutil# 创建目录
os.makedirs('example_dir', exist_ok=True)# 创建文件
with open('example_dir/example_file.txt', 'w') as f:f.write('Hello, World!')# 移动文件
shutil.move('example_dir/example_file.txt', 'example_dir/new_file.txt')# 删除文件
os.remove('example_dir/new_file.txt')# 删除目录
os.rmdir('example_dir')
1.读取文件结构
读取所有文件夹和文件
下面是一个 Python 脚本,它可以读取当前文件夹并打印出文件框架。这个脚本使用 os 模块来遍历文件夹中的文件和子文件夹,并打印出每个文件和文件夹的结构。
import osdef print_directory_structure(root_dir, indent=""):for item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)if os.path.isdir(item_path):print(f"{indent}[Folder] {item}")print_directory_structure(item_path, indent + " ")else:print(f"{indent}[File] {item}")if __name__ == "__main__":current_directory = os.getcwd()print(f"Directory structure of: {current_directory}")print_directory_structure(current_directory)
这个脚本会输出当前文件夹及其所有子文件夹和文件的层级结构。例如:
Directory structure of: /path/to/current/directory
[Folder] subfolder1
[File] file1.txt
[File] file2.txt
[Folder] subfolder2
[Folder] subsubfolder1
[File] file3.txt
[File] file4.txt
[File] file5.txt
如果想要的文件结构输出应该是以层级结构显示的目录和文件。下面是一个脚本,它会按照你所描述的方式来打印当前文件夹的文件框架。
import osdef print_directory_structure(root_dir, indent=""):for item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)if os.path.isdir(item_path):print(f"{indent}— {item}/")print_directory_structure(item_path, indent + " ")else:print(f"{indent}— {item}")if __name__ == "__main__":current_directory = os.getcwd()print(f"— {os.path.basename(current_directory)}/")print_directory_structure(current_directory, " ")
运行这个脚本后,会输出当前文件夹及其所有子文件夹和文件的结构。例如:
— current_directory/
— subfolder1/
— file1.txt
— file2.txt
— subfolder2/
— subsubfolder1/
— file3.txt
— file4.txt
— file5.txt
可以将将文件结构输出到 readme.txt 文件中:
import osdef save_directory_structure_to_file(root_dir, file, indent=""):for item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)if os.path.isdir(item_path):file.write(f"{indent}— {item}/\n")save_directory_structure_to_file(item_path, file, indent + " ")else:file.write(f"{indent}— {item}\n")if __name__ == "__main__":current_directory = os.getcwd()with open("readme.txt", "w") as file:file.write(f"— {os.path.basename(current_directory)}/\n")save_directory_structure_to_file(current_directory, file, " ")
运行这个脚本后,会在当前目录下生成一个 readme.txt 文件,内容是当前文件夹及其所有子文件夹和文件的结构。例如:
— current_directory/
— subfolder1/
— file1.txt
— file2.txt
— subfolder2/
— subsubfolder1/
— file3.txt
— file4.txt
— file5.txt
读取到N级子文件夹和文件
可以通过限制递归的深度来实现只读取三级子文件夹。下面是修改后的脚本,将文件结构输出到 readme.txt 文件中,并且只读取到三级子文件夹:
import osdef save_directory_structure_to_file(root_dir, file, indent="", depth=0, max_depth=3):if depth > max_depth:returnfor item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)if os.path.isdir(item_path):file.write(f"{indent}— {item}/\n")save_directory_structure_to_file(item_path, file, indent + " ", depth + 1, max_depth)else:file.write(f"{indent}— {item}\n")if __name__ == "__main__":current_directory = os.getcwd()with open("readme.txt", "w") as file:file.write(f"— {os.path.basename(current_directory)}/\n")save_directory_structure_to_file(current_directory, file, " ", 1, 3)
运行这个脚本后,readme.txt 文件的内容将是当前文件夹及其最多三级子文件夹和文件的结构。例如:
— current_directory/
— subfolder1/
— file1.txt
— file2.txt
— subfolder2/
— subsubfolder1/
— file3.txt
— file4.txt
— file5.txt
只读取到N级子文件夹
例如最多只读取四级子文件夹,并且不包含文件名称:
import osdef save_directory_structure_to_file(root_dir, file, indent="", depth=0, max_depth=4):if depth > max_depth:returnfor item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)if os.path.isdir(item_path):file.write(f"{indent}— {item}/\n")save_directory_structure_to_file(item_path, file, indent + " ", depth + 1, max_depth)if __name__ == "__main__":current_directory = os.getcwd()with open("readme.txt", "w") as file:file.write(f"— {os.path.basename(current_directory)}/\n")save_directory_structure_to_file(current_directory, file, " ", 1, 4)
运行这个脚本后,readme.txt 文件的内容将是当前文件夹及其最多四级子文件夹的结构,不包含文件名称。例如:
— current_directory/
— subfolder1/
— subfolder2/
— subsubfolder1/
— subsubsubfolder1/
— subfolder3/
读取每级别子文件夹,不读取文件名称:
import osdef save_directory_structure_to_file(root_dir, file, indent=""):for item in os.listdir(root_dir):item_path = os.path.join(root_dir, item)if os.path.isdir(item_path):file.write(f"{indent}— {item}/\n")save_directory_structure_to_file(item_path, file, indent + " ")if __name__ == "__main__":current_directory = os.getcwd()with open("readme.txt", "w") as file:file.write(f"— {os.path.basename(current_directory)}/\n")save_directory_structure_to_file(current_directory, file, " ")
2.遍历文件并处理(复制、删除)
遍历指定文件夹下的文件,并根据文件的类型或文件名称是否包含 "kgtbg" 来选择进行处理(复制到指定文件夹或删除)。你可以根据实际需求调整处理逻辑和目标文件夹路径。
import os
import shutildef process_files(src_dir, dest_dir, keyword="kgtbg"):# 确保目标文件夹存在os.makedirs(dest_dir, exist_ok=True)for root, dirs, files in os.walk(src_dir):for file_name in files:file_path = os.path.join(root, file_name)if keyword in file_name:# 复制到指定文件夹shutil.copy(file_path, dest_dir)print(f"Copied: {file_path} to {dest_dir}")# 删除原文件os.remove(file_path)print(f"Deleted: {file_path}")else:print(f"Skipped: {file_path}")if __name__ == "__main__":source_directory = 'path/to/source_directory' # 替换为源文件夹路径destination_directory = 'path/to/destination_directory' # 替换为目标文件夹路径process_files(source_directory, destination_directory)
说明:
-
os.makedirs(dest_dir, exist_ok=True):确保目标文件夹存在。如果目标文件夹不存在,os.makedirs会创建它。 -
os.walk(src_dir):遍历源文件夹及其所有子文件夹中的文件。 -
if keyword in file_name:检查文件名是否包含指定的关键字"kgtbg"。如果包含,执行处理操作。 -
shutil.copy(file_path, dest_dir):将符合条件的文件复制到目标文件夹。 -
os.remove(file_path):删除原文件。 -
print:用于打印处理过程中的信息,便于跟踪操作。
二、数据分析和处理
- Pandas:数据处理和分析,尤其适用于表格数据。
- NumPy:数值计算,支持大规模的数组和矩阵运算。
- SciPy:科学计算,包括优化、线性代数、积分等。
Pandas 数据分析示例
import pandas as pd# 读取数据
df = pd.read_csv('data.csv')# 显示前几行
print(df.head())# 数据统计
print(df.describe())# 数据过滤
filtered_df = df[df['column_name'] > 10]# 保存处理后的数据
filtered_df.to_csv('filtered_data.csv', index=False)
三、数据可视化
- Matplotlib:生成静态、动态和交互式的图表。
- Seaborn:基于 Matplotlib,提供更高级的统计图表。
- Plotly:交互式图表和仪表盘。
Matplotlib 示例
import matplotlib.pyplot as plt# 示例数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]# 创建图表
plt.plot(x, y, marker='o')
plt.xlabel('X axis')
plt.ylabel('Y axis')
plt.title('Sample Plot')
plt.grid(True)
plt.savefig('plot.png') # 保存图表
plt.show() # 显示图表
四、文本处理
- re:正则表达式,用于复杂的字符串匹配和替换。
- nltk 和 spaCy:自然语言处理库,用于文本分析和处理。
import retext = "The rain in Spain stays mainly in the plain."# 查找所有出现的 'in'
matches = re.findall(r'in', text)
print(f'Matches: {matches}')# 替换 'in' 为 'on'
new_text = re.sub(r'in', 'on', text)
print(f'New Text: {new_text}')
总结
以上就是今天要讲的内容,本文仅仅简单介绍了一些常用 Python 程序的示例代码,涵盖数据分析、数据可视化、文件管理等。
相关文章:

常用的python程序汇总——入门级
只用于记录最近的一些日常程序。 目录 前言 一、文件和目录管理 1.读取文件结构 读取所有文件夹和文件 读取到N级子文件夹和文件 只读取到N级子文件夹 2.遍历文件并处理(复制、删除) 说明: 二、数据分析和处理 三、数据可视化 四、…...
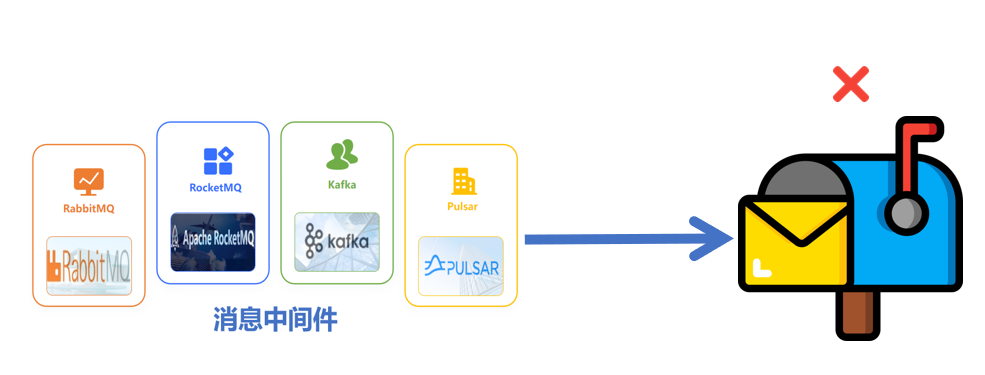
被问到MQ消息已丢失,该如何处理?
在分布式系统中,消息中间件(如 RabbitMQ、RocketMQ、Kafka、Pulsar 等)扮演着关键角色,用于解耦生产者和消费者,并确保数据传输的可靠性和顺序性。尽管我们通常会采取多种措施来防止消息丢失,如消息持久化、…...
)
open3d:ransac分割多个平面(源码)
1、背景介绍 随机采样一致性算法(RANSAC Random Sample Consensus)是一种迭代的参数估计算法,主要用于从包含大量噪声数据的样本中估计模型参数。其核心思想是通过随机采样和模型验证来找到数据中最符合模型假设的点。因此,只要事先给定要提取的参数模型,即可从点云中分割…...
Github 2024-07-17 开源项目日报 Top10
根据Github Trendings的统计,今日(2024-07-17统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量非开发语言项目3Python项目3Rust项目2TypeScript项目2MDX项目1项目化学习 创建周期:2538 天协议类型:MIT LicenseStar数量:161973 个Fork数量…...

vue3中Composition API写法 <script setup>标签中哪些可以不用导入即可使用?
在 Vue 3 中使用 <script setup> 时,确实有一些全局的 API 和宏可以直接使用,而不需要显式地从 vue 包中导入它们。这是因为 <script setup> 是专门为了提供更简洁的组件编写方式而设计的,它内部利用了编译时的语法糖。 以下是在…...

Facebook Dating:社交平台的约会新体验
随着社交媒体的普及和技术的发展,传统的社交方式正在经历革新,尤其是在约会这个领域。Facebook作为全球领先的社交平台,推出了Facebook Dating,旨在为用户提供一个全新的约会体验。本文将探讨Facebook Dating如何重新定义社交平台…...

【系统架构设计 每日一问】五 搜索型业务,采用MySQL+ES,如何保证数据一致性
将数据从MySQL同步到Elasticsearch(ES)中并保证一致性是一个常见的需求,特别是在需要快速全文搜索和分析功能的应用中。以下是一些常见的方法和实践来确保数据一致性: 1. 使用双写策略 描述:在应用程序层面ÿ…...
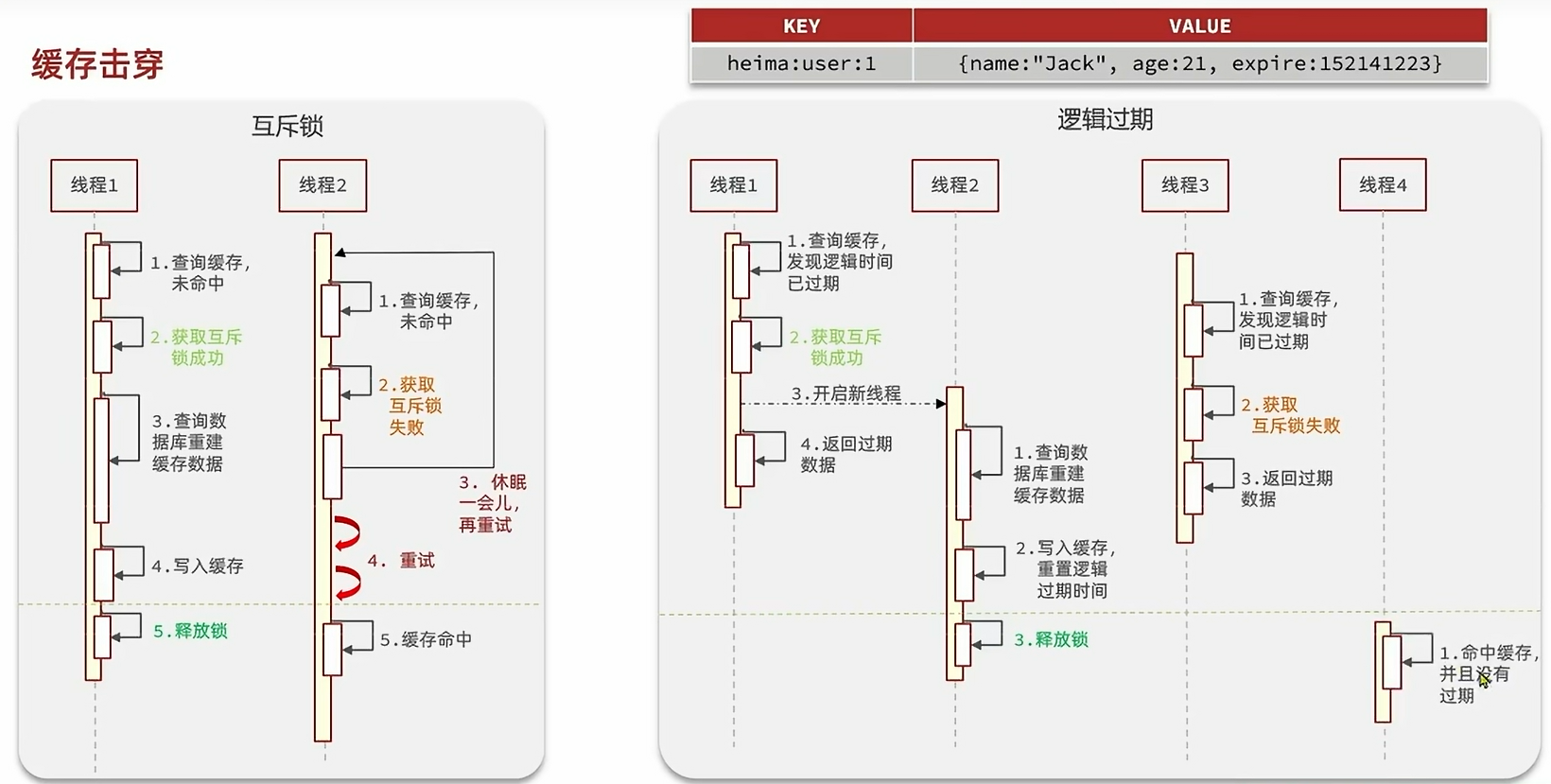
缓存穿透,缓存击穿,缓存雪崩
目录 介绍 缓存穿透 缓存击穿 缓存雪崩 原因 影响 解决方案 缓存穿透 防止缓存穿透->空值缓存案例 缓存击穿 使用互斥锁解决缓存击穿 介绍 缓存穿透 定义:缓存穿透是指用户查询数据,缓存和数据库中都不存在该数据(一般是发起恶意…...

运维 | 清理 Linux 磁盘空间方法汇总
清理 Linux 磁盘空间方法汇总 前言 系统磁盘不够用或占满了,导致部分应用或程序无法正常使用。 本章节将记录一些常用或常见的方法清理系统磁盘(持续更新中)。 常见操作 查看磁盘使用情况 cd / df -Th查找大文件和目录(根目…...

googleTest 源码主线框架性分析——TDD 01
TDD,测试驱动开发,英文全称Test-Driven Development,简称TDD,是一种不同于传统软件开发流程的新型的开发方法。它要求在编写某个功能的代码之前先编写测试代码,然后只编写使测试通过的功能代码,通过测试来推…...

Python:对常见报错导致的崩溃的处理
Python的注释: mac用cmd/即可 # 注释内容 代码正常运行会报以0退出,如果是1,则表示代码崩溃 age int(input(Age: )) print(age) 如果输入非数字,程序会崩溃,也就是破坏了程序,终止运行 解决方案…...

linux系统进程占cpu 100%解决步骤
1.查找进程 ps aux 查看指定进程: ps aux | grep process_name2.根据进程查找对应的主进程 pstree -p | grep process_name 3.查看主进程目录并删除 ps -axu | grep process_name rm -rf /usr/bin/2cbbb...

数据传输安全--IPSEC
目录 IPSEC IPSEC可以提供的安全服务 IPSEC 协议簇 两种工作模式 传输模式 隧道模式 两个通信保护协议(两个安全协议) AH(鉴别头协议) 可以提供的安全服务 报头 安全索引参数SPI 序列号 认证数据 AH保护范围 传输模…...

Unity XR Interaction Toolkit的安装(二)
提示:文章有错误的地方,还望诸位大神不吝指教! 文章目录 前言一、安装1.打开unity项目2.打开包管理器(PackageManage)3.导入Input System依赖包4.Interaction Layers unity设置总结 前言 安装前请注意:需要…...

什么是PCB流锡槽焊盘/C型焊盘,如何设计?-捷配笔记
在PCB进行机器组装器件时(如波峰焊),为了防止部分需要二次焊接的元器件的焊盘堵孔,就需要在PCB焊盘上面开个过锡槽,以便过波峰焊时,这些焊锡会流掉。开流锡槽就是在焊盘裸铜(敷锡)部…...

电缆故障精准定位系统
简介 电缆故障精准定位系统应用于35~500kV电压等级电缆线路故障精准定位与故障识别。基于百兆高速采样、北斗高精度授时、信号相位误差精确校准等 先进技术的应用,其定位精度小于5米,业内领先。 基于人工智能深度学习算法核心模块可自动、 快速进行故障…...

Google Chrome 浏览器在链接上点右键的快捷键
如今,越来越多的软件都懒得设个快捷键,就算设置了连个下划线也懒得加了。 谷歌浏览器右键 > 链接另存为... 和 复制链接地址 的快捷键 (如图)...

Redis在SpringBoot中遇到的问题:预热,雪崩,击穿,穿透
缓存预热 预热即在产品上线前,先对产品进行访问或者对产品的Redis中存储数据。 原因: 1. 请求数量较高 2. 主从之间数据吞吐量较大,数据同步操作频度较高,因为刚刚启动时,缓存中没有任何数据 解决方法: 1. 使用脚…...

Pytorch 6
罗切斯特回归模型 加了激活函数 加了激活函数之后类 class LogisticRegressionModel(torch.nn.Module):def __init__(self):super(LogisticRegressionModel, self).__init__()self.linear torch.nn.Linear(1,1)def forward(self, x):# y_pred F.sigmoid(self.linear(x))y_p…...

iterator(迭代器模式)
引入 在想显示数组当中所有元素时,我们往往会使用下面的for循环语句来遍历数组 #include <iostream> #include <vector>int main() {std::vector<int> v({ 1, 2, 3 });for (int i 0; i < v.size(); i){std::cout << v[i] << &q…...

Cursor Composer 2 技术报告拆解:MoE 预训练、RL 环境设计与 CursorBench 基准的工程实践
在生产级代码仓库里,一个 AI Agent 面对的往往不是“实现某个功能”这样清晰的任务,而是“新特性上线后出现诡异 bug,日志里只有 954 个 JSON 响应,栈踪迹完全不可靠”。它必须自己跨文件定位、写启发式检测器、调参避免误报&…...

Wan2.2-I2V-A14B效果展示:复杂提示词‘雨夜霓虹街道行人撑伞行走’生成效果
Wan2.2-I2V-A14B效果展示:复杂提示词雨夜霓虹街道行人撑伞行走生成效果 1. 模型能力概览 Wan2.2-I2V-A14B是一款专为高质量视频生成设计的先进模型,能够将文字描述转化为生动的动态画面。这款模型特别擅长处理复杂场景和细腻氛围的渲染,在以…...
)
别再只盯着EMD了!滚动轴承故障诊断,试试VMD和MCKD这些新方法(附Python代码对比)
滚动轴承故障诊断:VMD与MCKD的实战对比与Python实现 滚动轴承作为旋转机械的核心部件,其健康状态直接影响设备运行安全。传统经验模态分解(EMD)虽广泛应用,但在处理强噪声和非平稳信号时存在明显局限。本文将深入解析变…...

深入理解 MySQL 事务:从基础到实战,一篇吃透
在开发和运维 MySQL 数据库的过程中,事务(Transaction) 是绕不开的核心知识点,它是保证数据库数据安全、一致、可靠的基石。无论是电商下单、银行转账、支付结算,还是日常的业务数据操作,都离不开事务的支撑…...

Arduino_Threads:Mbed OS平台的嵌入式多线程实践框架
1. Arduino_Threads 库深度解析:面向 Mbed OS 的嵌入式多线程实践框架1.1 库定位与工程价值Arduino_Threads 是 Arduino 官方为基于 Mbed OS 核心的 Arduino 开发板(如 Nano RP2040 Connect、Portenta H7、Nicla Sense ME 等)设计的轻量级多线…...
)
告别僵硬数字人:用InfiniteTalk V2的WebUI,让照片开口唱歌(保姆级参数设置指南)
告别僵硬数字人:用InfiniteTalk V2的WebUI,让照片开口唱歌(保姆级参数设置指南) 当一张静态照片突然流畅地唱起你上传的歌曲,嘴角弧度与歌词节奏完美匹配,甚至伴随旋律自然摆动头部——这种魔法般的体验&am…...

Qwen3-TTS开源大模型实战:复古HUD界面下的AI语音创作工作流
Qwen3-TTS开源大模型实战:复古HUD界面下的AI语音创作工作流 1. 引言:当AI语音合成遇上复古游戏风 想象一下,你不再需要面对枯燥的音频参数调节界面,而是走进一个像素风的游戏世界。在这里,生成一段AI语音就像玩一款复…...

UnityLockstep:构建零延迟多人游戏的终极同步框架
UnityLockstep:构建零延迟多人游戏的终极同步框架 【免费下载链接】UnityLockstep Deterministic Lockstep with clientside prediction and rollback 项目地址: https://gitcode.com/gh_mirrors/un/UnityLockstep 在多人游戏开发中,你是否曾为网…...

告别硬件烧钱!用Proteus仿真Arduino UNO做智能小车传感器方案选型
告别硬件烧钱!用Proteus仿真Arduino UNO做智能小车传感器方案选型 在创客和电子竞赛领域,智能小车一直是热门项目,但高昂的硬件成本常常让爱好者望而却步。一套完整的智能车系统可能包含多个传感器、电机驱动模块和控制器,实体采购…...

从VGG到ResNet:我是如何用PyTorch复现经典,并理解‘残差’如何拯救了深度学习的
从VGG到ResNet:用PyTorch复现经典,理解残差如何重塑深度学习 2014年ImageNet竞赛冠军VGG网络将深度卷积神经网络推向了19层的里程碑,但研究者们很快发现:单纯堆叠更多层数反而会导致模型性能下降。这种现象被称作"网络退化&q…...