快速入门Zookeeper技术.黑马教程
快速入门Zookeeper技术.黑马教程
- 一、初识 Zookeeper
- 二、ZooKeeper 安装与配置
- 三、ZooKeeper 命令操作
- 1.Zookeeper 数据模型
- 2.Zookeeper 服务端常用命令
- 3.Zookeeper 客户端常用命令
- 四、ZooKeeper JavaAPI 操作
- 五、ZooKeeper JavaAPI 操作
- 1.Curator 介绍
- 2.Curator API 常用操作
- 2.1 建立连接
- (1)方式一
- (2)方式二
- 2.2 添加节点
- (1).创建一个基础的节点
- (2).创建一个带有数据的节点
- (3).设置节点的类型
- (4).创建多级节点
- 2.3 删除节点
- (1).删除单个节点
- (2).删除带有子节点的节点
- (3).必须成功的删除节点⭐(推荐)
- (4).回调
- 2.4 修改节点
- (1).修改数据
- (2).根据版本修改数据⭐(推荐)
- 2.5 查询节点
- (1).查询数据
- (2).查询子节点
- (3).查询节点的状态 ls -s
- 2.6 Watch事件监听
- (1).NodeCache
- (2).PathChildrenCache
- (3).TreeCache
- 2.7 分布式锁实现
- 3.分布式锁
- 4.模拟12306售票案例
- 六、ZooKeeper 集群搭建
- 1.ZooKeeper 集群介绍
- 2.ZooKeeper 集群搭建
- 2.1 搭建要求
- 2.2 准备工作
- 2.3 配置集群
- 2.4 启动集群
- 2.5 模拟集群异常
- 七、Zookeeper 核心理论
- 1.Zookeeper 集群角色
一、初识 Zookeeper
• Zookeeper 是 Apache Hadoop 项目下的一个子项目,是一个树形目录服务。
• Zookeeper 翻译过来就是 动物园管理员,他是用来管 Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员,简称zk。
• Zookeeper 是一个分布式的、开源的分布式应用程序的协调服务。
• Zookeeper 提供的主要功能包括:
• (1)配置管理

• (2)分布式锁

• (3)集群管理

二、ZooKeeper 安装与配置
参照三.1即可
三、ZooKeeper 命令操作
1.Zookeeper 数据模型
• ZooKeeper 是一个树形目录服务,其数据模型和Unix的文件系统目录树很类似,拥有一个层次化结构。
• 这里面的每一个节点都被称为: ZNode,每个节点上都会保存自己的数据和节点信息。
• 节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下。
• 节点可以分为四大类:
PERSISTENT 持久化节点
EPHEMERAL 临时节点 :-e 当前会话有效,关掉客户端就没了
PERSISTENT_SEQUENTIAL 持久化顺序节点 :-s
EPHEMERAL_SEQUENTIAL 临时顺序节点 :-es
Unix的树形结构:

Zookeeper树形结构:

2.Zookeeper 服务端常用命令
• 启动 ZooKeeper 服务: ./zkServer.sh start
• 查看 ZooKeeper 服务状态: ./zkServer.sh status
• 停止 ZooKeeper 服务: ./zkServer.sh stop
• 重启 ZooKeeper 服务: ./zkServer.sh restart
3.Zookeeper 客户端常用命令

四、ZooKeeper JavaAPI 操作
• 连接ZooKeeper服务端
./zkCli.sh –server ip:port

• 断开连接
quit

• 查看命令帮助
help

• 显示指定目录下节点
ls 目录
查看根目录

查看dubbo里的信息

• 创建节点
create /节点path value
创建节点app1赋值heima

创建节点app2不赋值

• 设置节点值
set /节点path value
给app2结点设置值 itcast

• 获取节点值
get /节点path
查看app1节点的值

查看app2节点的值

• 删除单个节点
delete /节点path
删除节点app1

以上CRUD操作就结束了,那我们想想创建节点能重复创建吗,我们试一试

虽然不能重复创建节点,但是我们可以创建子节点往下延申
create /app1/p1
create /app1/p2


这下app1下面有2个子节点,我们尝试删除子节点,发现没问题

那么在有子节点的情况下,能直接删除父节点吗,我们验证一下,发现不允许删除

那我们任性,就像删除呢,用下面的指令
• 删除带有子节点的节点
deleteall /节点path

• 创建临时节点
create -e /节点path value
创建临时节点app1

我们看一下,此时是存在的

我们退出会话,重新打开XShell,查询发现临时节点没有了

• 创建持久顺序节点
create -s /节点path value
可以发现,虽然我们创建的是app3但是,真实生成的是app300000000005

生成多次,会发现顺序产生了多个结点

• 查创建顺序临时节点
create -es /节点路径

• 查询节点详细信息(方式一)
ls –s /节点path

• 查询节点详细信息(方式二)
ls2 /

之前使用过Dubbo,这里可以看一下服务提供方的ip地址

czxid:节点被创建的事务ID
ctime: 创建时间
mzxid: 最后一次被更新的事务ID
mtime: 修改时间
pzxid:子节点列表最后一次被更新的事务ID
cversion:子节点的版本号
dataversion:数据版本号
aclversion:权限版本号
ephemeralOwner:用于临时节点,代表临时节点的事务ID,如果为持久节点则为0
dataLength:节点存储的数据的长度
numChildren:当前节点的子节点个数
五、ZooKeeper JavaAPI 操作
1.Curator 介绍
• Curator 是 Apache ZooKeeper 的Java客户端库。
• 常见的ZooKeeper Java API :
(1).原生Java API
(2).ZkClient
(3).Curator
• Curator 项目的目标是简化 ZooKeeper 客户端的使用。
• Curator 最初是 Netfix 研发的,后来捐献了 Apache 基金会,目前是 Apache 的顶级项目。
• 官网:Curator官网
注意
因为Curator是ZooKeeper的Java客户端库,所以二者的版本要对应起来可以看下官网的说明。
Zookeeper 3.5X 的版本可以用Curator4.0版本
低版本的Curator不能用高版本的Zookeeper,反之则可以。
我们的Zookeeper版本是3.5.6,用Curator4.0即可

2.Curator API 常用操作
• 建立连接
• 添加节点
• 删除节点
• 修改节点
• 查询节点
• Watch事件监听
• 分布式锁实现
直接用IDEA创建Java的Maven工程
groupid:com.itheima
artifactid:curator-zk
导入准备好的pom.xml
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.10</version><scope>test</scope></dependency><!--curator--><dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</artifactId><version>4.0.0</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>4.0.0</version></dependency><!--日志--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.21</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.21</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build>
加入log4j,其中log4j.rootLogger = off关掉了日志,想看可以设置info或者debug
log4j.rootLogger=off,stdoutlog4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%d{yyyy-MM-dd HH/:mm/:ss}]%-5p %c(line/:%L) %x-%m%n
创建测试类CuratorTest.java用来测试
整个项目结构如下:

2.1 建立连接
(1)方式一
CuratorTest.java
public class CuratorTest {/*** 建立连接*/@Testpublic void testConnection() {// 1.第一种方式// 重试策略,该策略重试设定的次数,每次重试之间的睡眠时间都会增加/*** 参数:* baseSleepTimeMs – 重试之间等待的初始时间量* 最大重试 次数 – 重试的最大次数*/RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);/*** Create a new client** @param connectString list of servers to connect to 连接字符串,地址+端口 例如“192. 168.149.135:2181, 192.168.149.135”* @param sessionTimeoutMs session timeout 会话超时时间 单位毫秒* @param connectionTimeoutMs connection timeout 连接超时时间 单位毫秒* @param retryPolicy retry policy to use 策略* @return client*/CuratorFramework client =CuratorFrameworkFactory.newClient("192. 168.149.135:2181", 60 * 1000, 15 * 1000, retryPolicy);client.start();}
}
执行结果

注意方法一中retryPolicy有如下几种类型:

(2)方式二
CuratorTest.java
/*** 建立连接 方式二*/@Testpublic void testConnection2() {RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);// 第二种方式CuratorFrameworkFactory.Builder builder = CuratorFrameworkFactory.builder().connectString("192. 168.149.135:2181").sessionTimeoutMs(60 * 1000).connectionTimeoutMs(15 * 1000).retryPolicy(retryPolicy).namespace("itheima");;builder.build().start();}
注意这里建议把namespace加上,相当于是根目录
2.2 添加节点
这里注意,在单元测试类中测试,想添加节点的前提是先创建连接,而创建连接的话,需要调用创建连接的方式,方法有2种
1.方法之间传参,这是单元测试,明显不行
2.提升作用域,用@Before即可
public class CuratorTest {// 声明为成员变量 private CuratorFramework client;/*** 建立连接 方式二*/@Beforepublic void testConnection2() {RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);// 第二种方式client = CuratorFrameworkFactory.builder().connectString("192. 168.149.135:2181").sessionTimeoutMs(60 * 1000).connectionTimeoutMs(15 * 1000).retryPolicy(retryPolicy).namespace("itheima").build();client.start();}/*** 创建节点* 持久、临时、顺序* 设置数据* <p>* 1.基本创建* 2.创建节点,带有数据* 3.设置节点的类型* 4.创建多级节点*/@Testpublic void testCreate() throws Exception {// client操作}@After/*** 关闭连接*/public void close() {if (null != client) {client.close();}}
}(1).创建一个基础的节点
我们先创建一个基础的节点
CuratorTest.java
@Testpublic void testCreate() throws Exception {String path = client.create().forPath("/app4");System.out.println(path);}
执行结果
/app4
查看Zookeeper客户端

注意
如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储

(2).创建一个带有数据的节点
CuratorTest.java
@Testpublic void testCreateValue() throws Exception {String path = client.create().forPath("/app5", "heima".getBytes());System.out.println(path);}
结果
/app5
查看Zookeeper客户端

(3).设置节点的类型
CuratorTest.java
创建临时节点
/*** 设置节点类型** @throws Exception*/@Testpublic void testCreateType() throws Exception {String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app6", "number6".getBytes());System.out.println(path);}
结果:
/app6
但是去ZooKeeper去查询,没有app6的节点

原因如下:创建的app6节点是一个临时节点,Zookeeper Java API建立的连接随着程序结束,会话就失效了。我再用Zookeeper Client端查看肯定是查询不到了。

(4).创建多级节点
CuratorTest.java
/*** 多级节点** @throws Exception*/@Testpublic void testCreateManyTypes() throws Exception {// creatingParentsIfNeeded()如果父节点不存在,就创建一个节点String path = client.create().creatingParentsIfNeeded().forPath("/app8/p8", "number8".getBytes());System.out.println(path);}
结果
/app8/p8
查看Zookeeper Client

2.3 删除节点
(1).删除单个节点
删除前查询

CuratorTest.java
/*** 1.删除单个节点** @throws Exception*/@Testpublic void testDelete() throws Exception {client.delete().forPath("/app5");}
删除后查询

(2).删除带有子节点的节点
删除前节点app7是有子节点的

CuratorTest.java
/*** 2.删除带有子节点的节点** @throws Exception*/@Testpublic void testDeleteWithSon() throws Exception {client.delete().deletingChildrenIfNeeded().forPath("/app7");}
删除后查询,发现没有节点了

(3).必须成功的删除节点⭐(推荐)
删除前app4还在

CuratorTest.java
这里必须删除成功,其实就是失败重试,比如断电或者故障后恢复系统仍然可以删除
/*** 3.必须成功的删除节点** @throws Exception*/@Testpublic void testDeleteSucceed() throws Exception {client.delete().guaranteed().forPath("/app4");}
删除后查询结果

(4).回调
删除前有节点

CuratorTest.java
/*** 4.回调** @throws Exception*/@Testpublic void testDeleteReturnFun() throws Exception {BackgroundCallback callback = new BackgroundCallback() {@Overridepublic void processResult(CuratorFramework client, CuratorEvent event) throws Exception {System.out.println("我被删除了");System.out.println(event);}};client.delete().inBackground(callback).forPath("/app8");}
输出
我被删除了
CuratorEventImpl{type=DELETE, resultCode=0, path='/app9', name='null', children=null, context=null, stat=null, data=null, watchedEvent=null, aclList=null, opResults=null}Process finished with exit code 0删除后查询Zookeeper客户端

2.4 修改节点
(1).修改数据
修改前用Zookeeper查询

CuratorTest.java
/*** 修改数据** @throws Exception*/@Testpublic void testSet() throws Exception {client.setData().forPath("/app7", "dong77".getBytes());}
修改后查询结果

(2).根据版本修改数据⭐(推荐)
CuratorTest.java
/*** 按照版本修改** @throws Exception*/@Testpublic void testSetForVersion() throws Exception {int version = 0;Stat stat = new Stat();client.getData().storingStatIn(stat).forPath("/app7");version = stat.getVersion();System.out.println("当前version是:" + version);client.setData().withVersion(version).forPath("/app7", "luka7".getBytes());}
查看控制台结果
当前version是:1
查看Zookeeper客户端,发现修改后version版本更新了

这种方式推荐使用:防止多线程并发,同时更改数据。
2.5 查询节点
(1).查询数据
CuratorTest.java
/*** 获取、查询* 1.查询数据* 2.查询子节点* 3.查询节点的状态 ls -s*/@Testpublic void testGet() throws Exception {byte[] bytes = client.getData().forPath("/app7");System.out.println(new String(bytes));}
查询结果
number7
(2).查询子节点
CuratorTest.java
/*** 获取、查询* 2.查询子节点*/@Testpublic void testGetSon() throws Exception {List<String> path = client.getChildren().forPath("/app8");System.out.println(path);}
结果
[p8]
(3).查询节点的状态 ls -s
CuratorTest.java
/*** 3.查询节点的状态 ls -s*/@Testpublic void testGetStatus() throws Exception {Stat stat = new Stat();System.out.println("查询前:" + stat);client.getData().storingStatIn(stat).forPath("/app8/p8");System.out.println("查询后:" + stat);}
查询结果
查询前:0,0,0,0,0,0,0,0,0,0,0查询后:357,357,1678784697495,1678784697495,0,0,0,0,7,0,357
对应的是:
private long czxid;
private long mzxid;
private long ctime;
private long mtime;
private int version;
private int cversion;
private int aversion;
private long ephemeralOwner;
private int dataLength;
private int numChildren;
private long pzxid;
2.6 Watch事件监听
• ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
• ZooKeeper 中引入了Watcher机制来实现了发布/订阅功能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态变化时,会通知所有订阅者。
• ZooKeeper 原生支持通过注册Watcher来进行事件监听,但是其使用并不是特别方便。
需要开发人员自己反复注册Watcher,比较繁琐。
• Curator引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。
• ZooKeeper提供了三种Watcher:
NodeCache : 只是监听某一个特定的节点
PathChildrenCache : 监控一个ZNode的子节点.
TreeCache : 可以监控整个树上的所有节点,类似于PathChildrenCache和NodeCache的组合。

创建节点

(1).NodeCache
用代码实现一下:
CuratorTest.java
/*** NodeCache : 只是监听某一个特定的节点** @throws Exception*/@Testpublic void testNodeCache() throws Exception {while (true) {/*** Params:* client – curztor client 客户端* path – the full path to the node to cache 要缓存的节点的完整路径* dataIsCompressed – if true, data in the path is compressed 如果为 true,则路径中的数据被压缩,默认不压缩*/// 1.创建NodeCache对象NodeCache nodeCache = new NodeCache(client, "/app1");// 2.注册监听nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {System.out.println("节点变化了");}});// 3.开启监听 如果为 true,将在此方法返回之前调用, rebuild() 以便获得节点的初始视图nodeCache.start(true);}}
运行相当于后台一直监听
我们用Zookeeper修改一下值

看到IDEA控制台打印
节点变化了
那我们再删除一下

发现IDEA控制台也报了
节点变化了
现在我们想知道节点变成了什么,这里需要修改代码
CuratorTest.java
/*** NodeCache : 只是监听某一个特定的节点** @throws Exception*/@Testpublic void testNodeCache() throws Exception {/*** Params:* client – curztor client 客户端* path – the full path to the node to cache 要缓存的节点的完整路径* dataIsCompressed – if true, data in the path is compressed 如果为 true,则路径中的数据被压缩,默认不压缩*/// 1.创建NodeCache对象NodeCache nodeCache = new NodeCache(client, "/app1");// 2.注册监听nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {System.out.println("节点变化了");// 获取修改节点后的数据byte[] data = nodeCache.getCurrentData().getData();System.out.println("修改后数据是:" + new String(data));}});// 3.开启监听 如果为 true,将在此方法返回之前调用, rebuild() 以便获得节点的初始视图nodeCache.start(true);while (true) {}}
我们再去Zookeeper Client去创建、修改数据

IDEA控制台输出
节点变化了
节点变化了
修改后数据是:123
(2).PathChildrenCache
测试前先给app1节点创建3个子节点

CuratorTest.java
/*** PathChildrenCache : 监控一个ZNode的所有子节点.** @throws Exception*/@Testpublic void testPathChildrenCache() throws Exception {/*** 如果为 true,则除了统计信息之外,还会缓存节点内容*/// 1.创建监听对象PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/app1", true);// 2.绑定监听器pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {System.out.println("子节点变化了");System.out.println(event);}});pathChildrenCache.start();while (true) {}}
这刚启动,发现直接打印内容了
控制台:
子节点变化了
PathChildrenCacheEvent{type=CHILD_ADDED, data=ChildData{path='/app1/p3', stat=406,406,1678789718011,1678789718011,0,0,0,0,0,0,406
, data=null}}
我们在Zookeeper Client中再增加几个节点,修改几个节点

控制台输出如下,这里可以打印了很多是因为创建PathChildrenCache对象的构造器中最后一个参数是true会带缓存。
子节点变化了
PathChildrenCacheEvent{type=CONNECTION_RECONNECTED, data=null}
子节点变化了
PathChildrenCacheEvent{type=CHILD_ADDED, data=ChildData{path='/app1/p1', stat=404,404,1678789712940,1678789712940,0,0,0,0,0,0,404
, data=null}}
子节点变化了
PathChildrenCacheEvent{type=CHILD_ADDED, data=ChildData{path='/app1/p2', stat=405,405,1678789716171,1678789716171,0,0,0,0,0,0,405
, data=null}}
子节点变化了
PathChildrenCacheEvent{type=CHILD_ADDED, data=ChildData{path='/app1/p3', stat=406,406,1678789718011,1678789718011,0,0,0,0,0,0,406
, data=null}}
子节点变化了
PathChildrenCacheEvent{type=CHILD_ADDED, data=ChildData{path='/app1/p4', stat=411,411,1678796545718,1678796545718,0,0,0,0,0,0,411
, data=null}}
子节点变化了
PathChildrenCacheEvent{type=CHILD_UPDATED, data=ChildData{path='/app1/p4', stat=411,412,1678796545718,1678796575904,1,0,0,0,1,0,411
, data=[52]}}
子节点变化了
PathChildrenCacheEvent{type=CHILD_REMOVED, data=ChildData{path='/app1/p4', stat=411,412,1678796545718,1678796575904,1,0,0,0,1,0,411
, data=[52]}}
这里我们要是改变app1这个节点会有打印事件触发吗,我们尝试一下,更改app1的名字为app11

发现控制台没有打印,可见只有子节点改变,才会监听到。
那现在我想看到具体子节点的变化情况和变化的值呢。
修改CuratorTest.java
修改PathChildrenCache构造函数,最后一个值是false,然后输出监听信息。
/*** PathChildrenCache : 监控一个ZNode的所有子节点.** @throws Exception*/@Testpublic void testPathChildrenCache() throws Exception {/*** 如果为 true,则除了统计信息之外,还会缓存节点内容*/// 1.创建监听对象PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/app1", false);// 2.绑定监听器pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {System.out.println("子节点变化了");System.out.println(event);// 1.获取类型PathChildrenCacheEvent.Type type = event.getType();// 2.判断类型是否是updateif (type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)) {byte[] bytes = event.getData().getData();System.out.println("数据被更新了:" + new String(bytes));} else if (type.equals(PathChildrenCacheEvent.Type.CHILD_ADDED)) {byte[] bytes = event.getData().getData();System.out.println("数据被添加了:" + new String(bytes));} else if (type.equals(PathChildrenCacheEvent.Type.CHILD_REMOVED)) {byte[] bytes = event.getData().getData();System.out.println("数据被删除了:" + new String(bytes));}}});pathChildrenCache.start();while (true) {}}
然后我们再重复修改Zookeeper Client端的值

看一下控制台的内容

(3).TreeCache
CuratorTest.java
/*** TreeCache : 可以监控整个树上的所有节点,类似于PathChildrenCache和NodeCache的组合** @throws Exception*/@Testpublic void testTreeCache() throws Exception {TreeCache treeCache = new TreeCache(client, "/app1");treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {System.out.println("整个树节点有变化");System.out.println(event);}});treeCache.start();while (true) {}}
发现刚运行完也是有缓存信息输出
整个树节点有变化
TreeCacheEvent{type=NODE_ADDED, data=ChildData{path='/app1/p9', stat=430,431,1678798509101,1678798526445,1,0,0,0,1,0,430
, data=[57]}}
整个树节点有变化
TreeCacheEvent{type=INITIALIZED, data=null}
我们修改Zookeeper客户端

控制台信息打印:
整个树节点有变化
TreeCacheEvent{type=NODE_ADDED, data=ChildData{path='/app1/p10', stat=439,439,1678798761358,1678798761358,0,0,0,0,0,0,439
, data=null}}
整个树节点有变化
TreeCacheEvent{type=NODE_UPDATED, data=ChildData{path='/app1/p10', stat=439,440,1678798761358,1678798772854,1,0,0,0,2,0,439
, data=[49, 48]}}
整个树节点有变化
TreeCacheEvent{type=NODE_REMOVED, data=ChildData{path='/app1/p10', stat=439,440,1678798761358,1678798772854,1,0,0,0,2,0,439
, data=[49, 48]}}
我们也想输出树节点的信息,继续修改
CuratorTest.java
/*** TreeCache : 可以监控整个树上的所有节点,类似于PathChildrenCache和NodeCache的组合** @throws Exception*/@Testpublic void testTreeCache() throws Exception {TreeCache treeCache = new TreeCache(client, "/app1");treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {System.out.println("整个树节点有变化");System.out.println(event);TreeCacheEvent.Type type = event.getType();if (type.equals(TreeCacheEvent.Type.NODE_UPDATED)) {byte[] bytes = event.getData().getData();System.out.println("树节点数据被更新了:" + new String(bytes));} else if (type.equals(TreeCacheEvent.Type.NODE_ADDED)) {byte[] bytes = event.getData().getData();System.out.println("树节点数据被添加了:" + new String(bytes));} else if (type.equals(TreeCacheEvent.Type.NODE_REMOVED)) {byte[] bytes = event.getData().getData();System.out.println("树节点数据被删除了:" + new String(bytes));} else {System.out.println("树节点无操作");}}});treeCache.start();while (true) {}}
操作Zookeeper Client端

整个树节点有变化
TreeCacheEvent{type=NODE_UPDATED, data=ChildData{path='/app1', stat=401,444,1678789457450,1678799146527,3,14,0,0,6,8,441
, data=[97, 112, 112, 49, 49, 49]}}
树节点数据被更新了:app111
整个树节点有变化
TreeCacheEvent{type=NODE_UPDATED, data=ChildData{path='/app1/p9', stat=430,446,1678798509101,1678799254527,2,0,0,0,3,0,430
, data=[57, 56, 55]}}
树节点数据被更新了:9872.7 分布式锁实现
• Curator实现分布式锁API
在Curator中有五种锁方案:
InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
InterProcessMutex:分布式可重入排它锁
InterProcessReadWriteLock:分布式读写锁
InterProcessMultiLock:将多个锁作为单个实体管理的容器
InterProcessSemaphoreV2:共享信号量
3.分布式锁
• 在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。
• 但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
• 那么就需要一种更加高级的锁机制,来处理种跨机器的进程之间的数据同步问题——这就是分布式锁。

下图左侧为单机,右测是集群

ZooKeeper分布式锁原理
• 核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。

1.客户端获取锁时,在lock节点下创建临时顺序节点。
临时:是害怕某个用户获取节点之后突然宕机,如果是临时锁,宕机恢复后锁将会失效所有用户又可以重新获取锁,而不是都等着1个了。

2.然后获取lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
3.如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。

4.如果发现比自己小的那个节点被删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
4.模拟12306售票案例

创建一个测试类LockTest.java
package com.itheima;/*** @ClassName: LockTest* @Description:* @Author: wty* @Date: 2023/3/14*/public class LockTest {public static void main(String[] args) {Tick12306 tick12306 = new Tick12306();// 创建客户端Thread t1 = new Thread(tick12306, "携程");Thread t2 = new Thread(tick12306, "飞猪");Thread t3 = new Thread(tick12306, "去哪儿");t1.start();t2.start();t3.start();}
}创建实体类模拟12306抢票操作
package com.itheima;/*** @ClassName: Tick12306* @Description:* @Author: wty* @Date: 2023/3/14*/public class Tick12306 implements Runnable {// 数据库的票数private int tickets = 100;@Overridepublic void run() {while (true) {if (tickets > 0) {System.out.println("线程:" + Thread.currentThread().getName() + "买走了票,剩余" + (--tickets));}}}
}运行结果
线程:携程买走了票,剩余99
线程:飞猪买走了票,剩余99
线程:去哪儿买走了票,剩余98
线程:飞猪买走了票,剩余96
发现第99张票被2个APP同时买走了
解决方案:用分布式锁解决
添加工具类ClientConnection.java
public class ClientConnection {public static CuratorFramework getConnection() {ExponentialBackoffRetry retry = new ExponentialBackoffRetry(3000, 10);CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192. 168.149.135:2181").sessionTimeoutMs(60 * 1000).connectionTimeoutMs(15 * 1000).retryPolicy(retry).build();client.start();return client;}
}修改Tick12306.java
public class Tick12306 implements Runnable {private InterProcessMutex lock;// 数据库的票数private int tickets = 100;public Tick12306() {CuratorFramework client = ClientConnection.getConnection();lock = new InterProcessMutex(client, "/itheima/lock");}@Overridepublic void run() {while (true) {// 获取锁try {lock.acquire(3, TimeUnit.SECONDS);if (tickets > 0) {System.out.println("线程:" + Thread.currentThread().getName() + "买走了票,剩余" + (--tickets));Thread.sleep(100);}} catch (Exception e) {e.printStackTrace();} finally {// 释放锁try {lock.release();} catch (Exception e) {e.printStackTrace();}}}}
}输出结果
线程:去哪儿买走了票,剩余99
线程:飞猪买走了票,剩余98
线程:携程买走了票,剩余97
线程:去哪儿买走了票,剩余96
线程:飞猪买走了票,剩余95
线程:携程买走了票,剩余94
线程:去哪儿买走了票,剩余93
可以看到/itheima节点下有了新创建的lock节点,抢票正常

可以看到打印的排序节点的申请情况

六、ZooKeeper 集群搭建
1.ZooKeeper 集群介绍
Leader选举:
• Serverid:服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
• Zxid:数据ID
服务器中存放的最大数据ID.值越大说明数据越新,在选举算法中数据越新权重越大。
• 在Leader选举的过程中,如果某台ZooKeeper
获得了超过半数的选票,
则此ZooKeeper就可以成为Leader了。

2.ZooKeeper 集群搭建
2.1 搭建要求
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动很多个虚拟机内存会吃不消,所以我们通常会搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
我们这里要求搭建一个三个节点的Zookeeper集群(伪集群)。
2.2 准备工作
重新部署一台虚拟机作为我们搭建集群的测试服务器。
(1)安装JDK 【此步骤省略】。
(2)Zookeeper压缩包上传到服务器
(3)将Zookeeper解压 ,建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
/usr/local/zookeeper-cluster/zookeeper-1
/usr/local/zookeeper-cluster/zookeeper-2
/usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper-cluster
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-1
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-2
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-3
(4)创建data目录 ,并且将 conf下zoo_sample.cfg 文件改名为 zoo.cfg
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data
mkdir /usr/local/zookeeper-cluster/zookeeper-2/data
mkdir /usr/local/zookeeper-cluster/zookeeper-3/datamv /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
(5) 配置每一个Zookeeper 的dataDir 和 clientPort 分别为2181 2182 2183
修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfgclientPort=2181
dataDir=/usr/local/zookeeper-cluster/zookeeper-1/data
修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfgclientPort=2182
dataDir=/usr/local/zookeeper-cluster/zookeeper-2/data
修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfgclientPort=2183
dataDir=/usr/local/zookeeper-cluster/zookeeper-3/data
2.3 配置集群
(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid
echo 2 >/usr/local/zookeeper-cluster/zookeeper-2/data/myid
echo 3 >/usr/local/zookeeper-cluster/zookeeper-3/data/myid
(2)在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
集群服务器IP列表如下
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfgserver.1=192.168.149.135:2881:3881
server.2=192.168.149.135:2882:3882
server.3=192.168.149.135:2883:3883
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
2.4 启动集群
启动集群就是分别启动每个实例。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
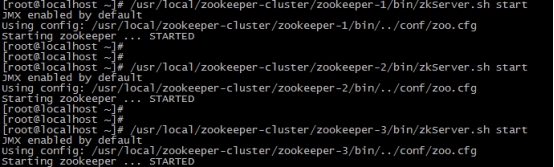
启动后我们查询一下每个实例的运行状态
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
先查询第一个服务

Mode为follower表示是跟随者(从)
再查询第二个服务Mod 为leader表示是领导者(主)

查询第三个为跟随者(从)

2.5 模拟集群异常
(1)首先我们先测试如果是从服务器挂掉,会怎么样
把3号服务器停掉,观察1号和2号,发现状态并没有变化。
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh stop/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
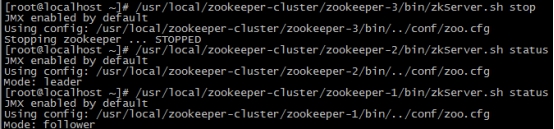
由此得出结论,3个节点的集群,从服务器挂掉,集群正常
(2)我们再把1号服务器(从服务器)也停掉,查看2号(主服务器)的状态,发现已经停止运行了。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status

由此得出结论,3个节点的集群,2个从服务器都挂掉,主服务器也无法运行。因为可运行的机器没有超过集群总数量的半数。
(3)我们再次把1号服务器启动起来,发现2号服务器又开始正常工作了。而且依然是领导者。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status

(4)我们把3号服务器也启动起来,把2号服务器停掉,停掉后观察1号和3号的状态。
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh stop/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
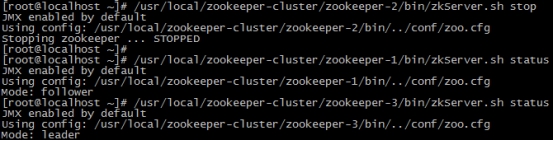
发现新的leader产生了~
由此我们得出结论,当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得leader 。
(5)我们再次测试,当我们把2号服务器重新启动起来启动后,会发生什么?2号服务器会再次成为新的领导吗?我们看结果
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status

我们会发现,2号服务器启动后依然是跟随者(从服务器),3号服务器依然是领导者(主服务器),没有撼动3号服务器的领导地位。
由此我们得出结论,当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
七、Zookeeper 核心理论
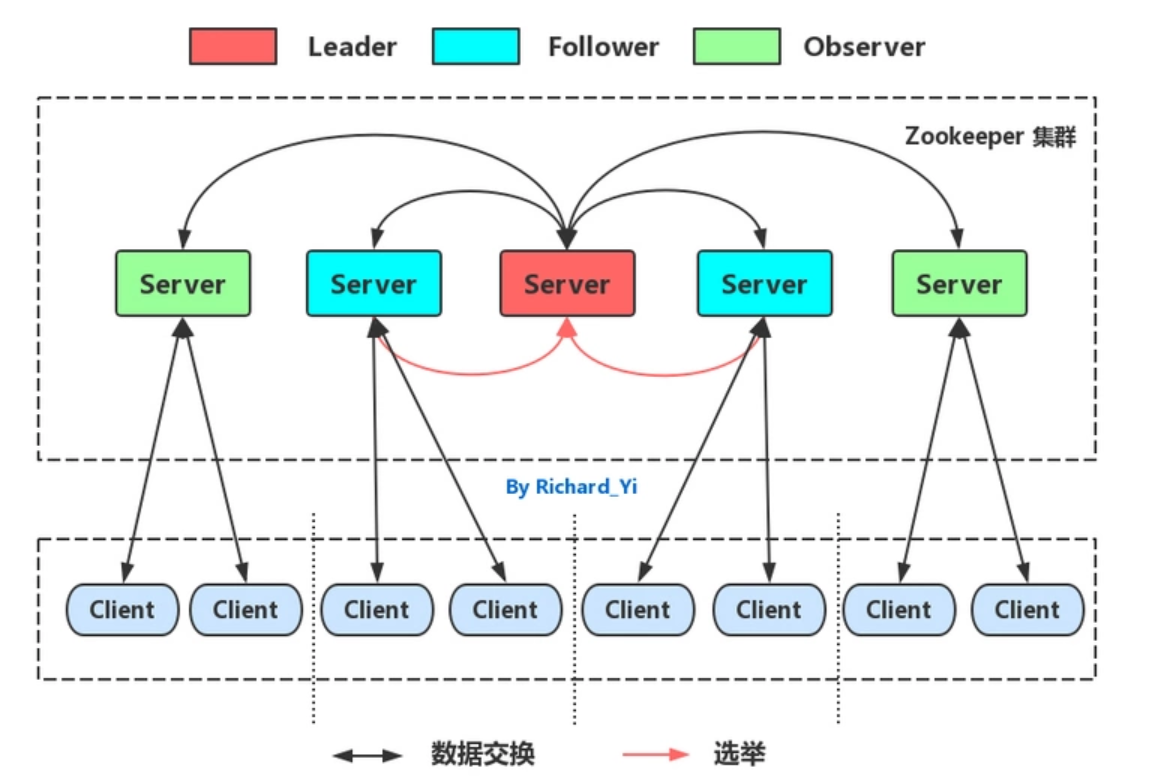
1.Zookeeper 集群角色
在ZooKeeper集群服中务中有三个角色:
• Leader 领导者 :
- 处理事务请求
- 集群内部各服务器的调度者
• Follower 跟随者 : - 处理客户端非事务请求,转发事务请求给Leader服务器
- 参与Leader选举投票
• Observer 观察者: - 处理客户端非事务请求,转发事务请求给Leader服务器
相关文章:
快速入门Zookeeper技术.黑马教程
快速入门Zookeeper技术.黑马教程一、初识 Zookeeper二、ZooKeeper 安装与配置三、ZooKeeper 命令操作1.Zookeeper 数据模型2.Zookeeper 服务端常用命令3.Zookeeper 客户端常用命令四、ZooKeeper JavaAPI 操作五、ZooKeeper JavaAPI 操作1.Curator 介绍2.Curator API 常用操作2.…...

网易C++实习一面
说下C11新特性 auto有没有效率上的问题?为什么?发生在什么时候? 说下单例模式 什么时候需要加锁,什么时候不需要加锁? 像printf这样的函数,自己本身不修改数据,但是其他人会修改数据&#x…...
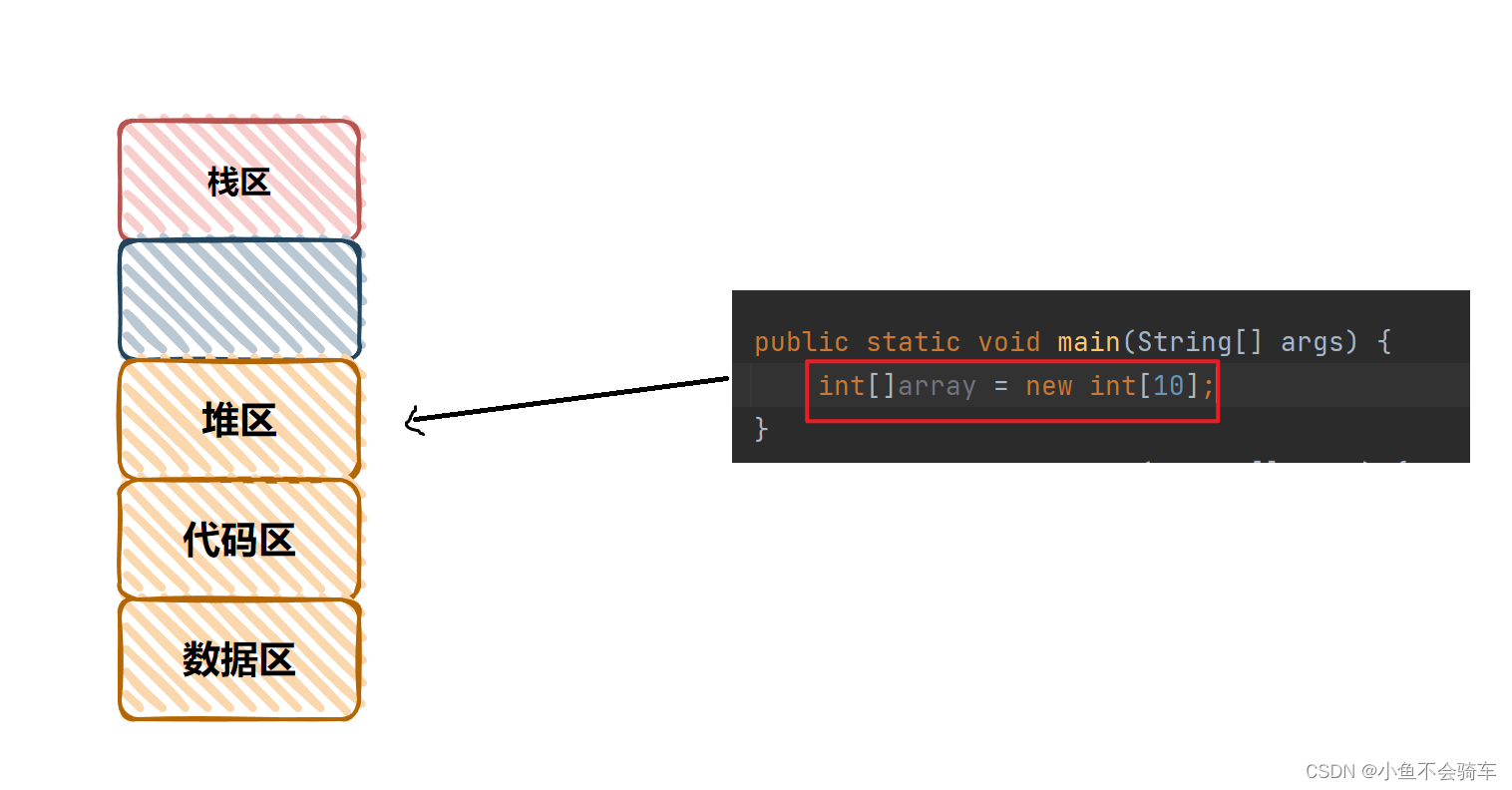
进程和线程的区别和联系
进程和线程的区别和联系1. 认识线程2. 进程和线程的关系3. 进程和线程的区别4. 线程共享了进程哪些资源1. 上下文切换2. 线程共享了进程哪些资源1.代码区2. 数据区3. 堆区1. 认识线程 线程是进程的一个实体,它被包含在进程中,一个进程至少包含一个线程,一个进程也可以包含多个…...

Java学习笔记——集合
目录集合与数组的对比集合体系结构Collection——常见成员方法Collection——迭代器基本使用Collection——迭代器原理分析Collection——迭代器删除方法增强for——基本格式增强for——注意点Collection——练习集合与数组的对比 package top.xxxx.www.CollectionDemo;import …...
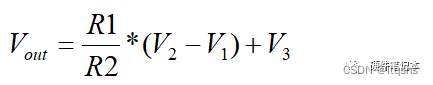
差分运放公式推导-运算放大器
不知道大家有没遇到这种情况,在计算电路的时候,有时候会突然的忘记一些公式啊啥的,需要回去翻看笔记或者查资料,知其然而不知其所以然。今天跟大家一起来一起推导一遍差分运放的计算过程。 计算过程其实归根结底还是根据运放的虚…...

金丹二层 —— 字符串长度求解的四种方法
前言: 1.CSDN由于我的排版不怎么好看,我的有道云笔记比较美观,请移步有道云笔记 2.修炼必备 1)入门必备:VS2019社区版,下载地址:Visual Studio 较旧的下载 - 2019、2017、2015 和以前的版本 (m…...

深入剖析Linux——进程信号
致前行的人: 要努力,但不着急,繁花锦簇,硕果累累都需要过程! 目录 1.信号概念 1.1生活角度的信号 2. 技术应用角度的信号 3.Linux操作系统中查看信号 4.常用信号发送 4.1通过键盘发送信号 4.2调用系统函数发送信号 4.3…...
API-Server的监听器Controller的List分页失效
前言 最近做项目,还是K8S的插件监听器(理论上插件都是通过API-server通信),官方的不同写法居然都能出现争议,争议点就是对API-Server的请求的耗时,说是会影响API-Server。实际上通过源码分析两着有差别&am…...

jupyter notebook 进阶使用:nbextensions,终极避坑
jupyter notebook 进阶使用:nbextensions,终极避坑吐槽安装 jupyter_contrib_nbextensions1. Install the python package(安装python包)方法一,PIP:方法二,Conda(推荐)&…...

C 语言编程 — Doxygen + Graphviz 静态项目分析
目录 文章目录目录安装配置解析Project related configuration optionsBuild related configuration optionsConfiguration options related to warning and progress messagesConfiguration options related to the input filesConfiguration options related to source brows…...
Mybatis报BindingException:Invalid bound statement (not found)异常
一、前言 本文的mybatis是与springboot整合时出现的异常,若使用的不是基于springboot,解决思路也大体一样的。 二、从整合mybatis的三个步骤排查问题 但在这之前,我们先要知道整合mybatis的三个重要的工作,如此才能排查&#x…...
HttpRunner3.x(1)-框架介绍
HttpRunner 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。主要特征继承的所有强大功能requests ,只需以人工方式获得乐趣即可处理HTTP…...

pytest学习和使用20-pytes如何进行分布式测试?(pytest-xdist)
20-pytes如何进行分布式测试?(pytest-xdist)1 什么是分布式测试?2 为什么要进行分布式测试?2.1 场景1:自动化测试场景2.2 场景2:性能测试场景3 分布式测试有什么特点?4 分布式测试关…...

三、Python 操作 MongoDB ----非 ODM
文章目录一、连接器的安装和配置二、新增文档三、查询文档四、更新文档五、删除文档一、连接器的安装和配置 pymongo: MongoDB 官方提供的 Python 工具包。官方文档: https://pymongo.readthedocs.io/en/stable/ pip安装,命令如下࿱…...
)
求最大公约数和最小公倍数---辗转相除法(欧几里得算法)
目录 一.GCD和LCM 1.最大公约数 2.最小公倍数 二.暴力求解 1.最大公约数 2.最小公倍数 三.辗转相除法 1.最大公约数 2.最小公倍数 一.GCD和LCM 1.最大公约数 最大公约数(Greatest Common Divisor,简称GCD)指的是两个或多个整数共有…...
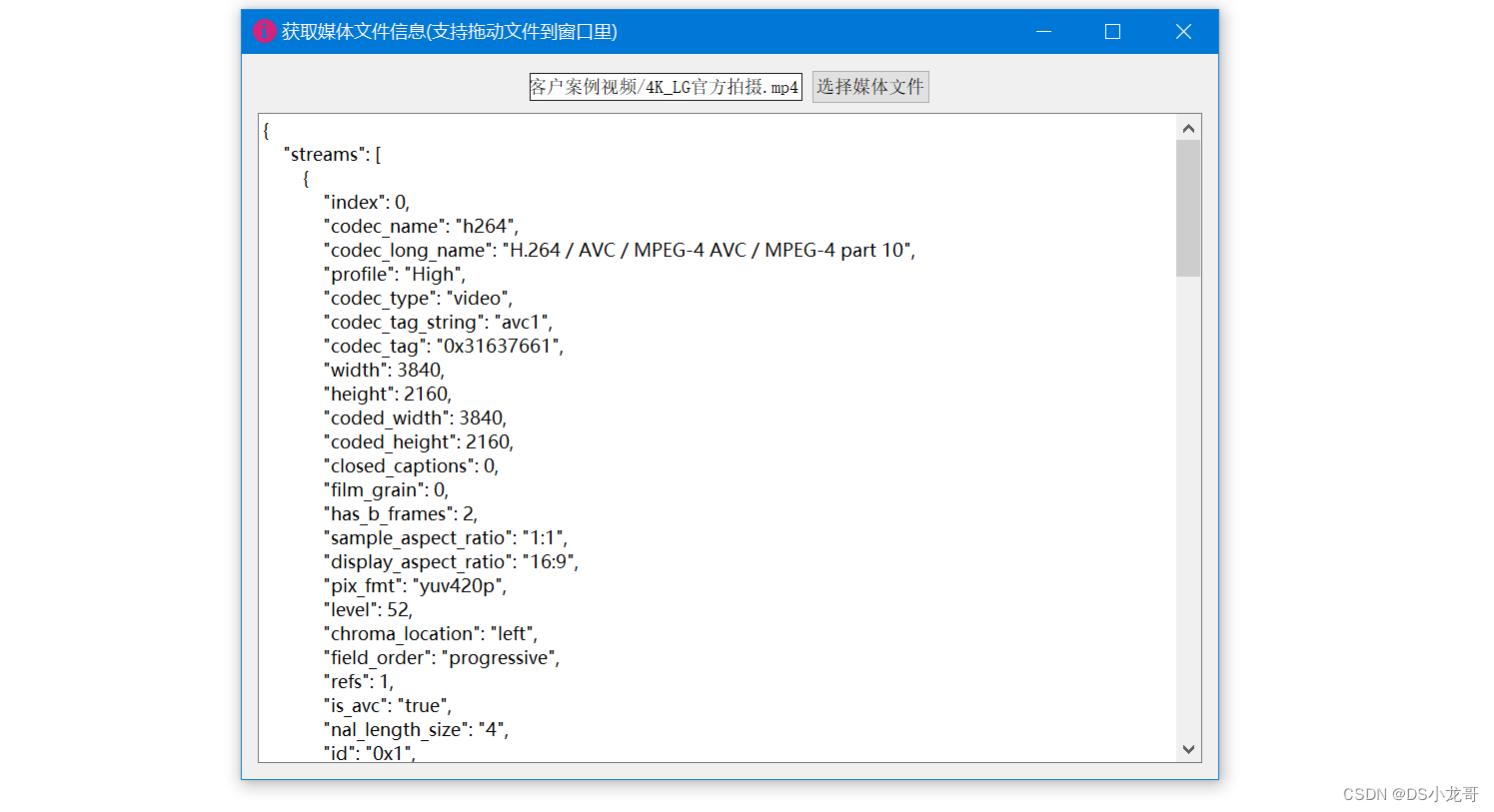
音视频开发_获取媒体文件的详细信息
一、前言 做音视频开发过程中,经常需要获取媒体文件的详细信息。 比如:获取视频文件的总时间、帧率、尺寸、码率等等信息。 获取音频文件的的总时间、帧率、码率,声道等信息。 这篇文章贴出2个我封装好的函数,直接调用就能获取媒体信息返回,copy过去就能使用,非常方便。…...
Springboot集成Swagger
一、Swagger简介注意点! 在正式发布的时候要关闭swagger(出于安全考虑,而且节省内存空间)之前开发的时候,前端只用管理静态页面, http请求到后端, 模板引擎JSP,故后端是主力如今是前…...

Vue全新一代状态管理库 Pinia【一篇通】
文章目录前言1. Pinia 是什么?1.1 为什么取名叫 Pinia?1.2. 为什么要使用 Pinia ?2. 安装 Pinia2.1.创建 Store2.1.1. Option 类型 Store2.1.2 Setup 函数类型 Store2.1.3 模板中使用3. State 的使用事项(Option Store )3.1 读取 State3.2 …...

STM32 -4 关于STM32的RAM、ROM
一 stm32 的flash是什么、有什么用、注意事项、如何查看 一 、说明 它主要用于存储代码,FLASH 存储器的内容在掉电后不会丢失,STM32 芯片在运行的时候,也能对自身的内部 FLASH 进行读写,因此,若内部 FLASH 存储了应用…...
第一个 Qt 程序
第一个 Qt 程序 “hello world ”的起源要追溯到 1972 年,贝尔实验室著名研究员 Brian Kernighan 在撰写 “B 语言教程与指导(Tutorial Introduction to the Language B)”时初次使用(程序),这是目前已 知最早的在计算机著作中将…...

Vue3 + Element Plus 全局 Message、Notification 封装与规范|Vue生态精选篇
前端实战:Vue3 Element Plus 全局 Message、Notification 封装教程,从概念区分、场景选择到统一错误处理、代码落地,一站式学会前端提示框封装,告别混乱代码与重复开发。 📑 文章目录 一、我们为什么要封装ÿ…...

51单片机 6:串口通信
目录 一、串口 1.1 简介 1.2 工作模式 1.3 基本应用 1.3.1 如何配置 1.3.2 如何发送数据 1.3.3 实践 二、串口向电脑发送数据 2.1 思路 2.2 实践 三、电脑通过串口控制LED 3.1 思路 3.2 实践 编辑 编辑 一、串口 1.1 简介 1.2 工作模式 1.3 基本应用 1.3.1…...

量子位专访陶哲轩:我为什么现在创办一个AI x Science组织
数学家陶哲轩,公开了AI新身份——SAIR Foundation联合创始人。 之前,他是举世闻名的数学天才,年少成名的传奇数学家、13岁加冕IMO的最年轻金牌得主……24岁就成为加州大学洛杉矶分校(UCLA)史上最年轻的终身正教授。 …...

洛邑行记_pxj
洛邑行记 作者:pxj(笔名) 丙午星霜赴洛邑, 沈心三载盈相安。 洛水青霞浣穹苍, 白马禅机入梦闲。 王李真传立身策, 铭肌镂骨照肝胆。 承悟道休言天命, 万物齐一绾阴阳。 注解沈:通“沉…...

AI大模型课程|非计算机专业转行人工智能,好就业吗?非常详细收藏我这一篇就够了
很多就业者在看到人工智能领域发展的很好,意识觉醒的人想进入这个行业里面得到一些新兴行业的红利,想转行却担心自己的经历或者是专业被卡,犹豫不决,今天就来和大家聊一聊这个话题,看看能不能解除你的疑惑。 01写在前面…...

【优化配置】基于遗传算法GA配置配电网络IEEE33和69总线附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

Rackstack常见问题解决:打印、组装和使用中的技巧与窍门
Rackstack常见问题解决:打印、组装和使用中的技巧与窍门 【免费下载链接】rackstack A modular 3d-printable mini rack system. 项目地址: https://gitcode.com/gh_mirrors/ra/rackstack Rackstack是一款模块化3D打印迷你机架系统,为电子设备提供…...

收藏!小白程序员轻松入门大模型:重排序技术提升RAG检索效果
本文介绍了重排序技术在RAG检索流程中的重要性,它通过重新排序初始检索结果,提升检索结果的相关性,为生成模型提供更优质的上下文。文章详细阐述了重排序技术的优势,包括优化检索结果、增强上下文相关性和应对复杂查询。此外&…...

Qwen Pixel Art效果展示:支持1:1/4:3/16:9多种宽高比的像素图精准生成
Qwen Pixel Art效果展示:支持1:1/4:3/16:9多种宽高比的像素图精准生成 还记得小时候玩红白机时,那些由一个个小方块组成的游戏世界吗?那种独特的、充满复古魅力的画面风格,就是像素艺术。如今,这种风格不仅没有过时&a…...

2026年春日活动海报复盘:如何快速敲定桃树主题视觉方案
作为一名社群运营,我经常需要为各种小型活动快速制作宣传物料。上周三,我接到了一个紧急任务:为周末的“社区踏春赏桃”活动设计一张宣传海报,要求周四上午就要发到业主群和朋友圈里预热。时间紧,任务急,而…...