密码学原理精解【8】
文章目录
- 概率分布
- 哈夫曼编码实现
- julia官方文档建议的变量命名规范:
- julia源码
- 熵
- 一、信息熵的定义
- 二、信息量的概念
- 三、信息熵的计算步骤
- 四、信息熵的性质
- 五、应用举例
- 哈夫曼编码(Huffman Coding)
- 基本原理
- 编码过程
- 特点
- 应用
- 具体过程
- 1. 排序概率
- 2. 合并最小概率
- 3. 更新概率序列
- 4. 重复合并
- 5. 生成码表
- 6. 编码数据
- 示例
- 哈夫曼编码的具体算法
- 一、算法步骤
- 二、算法特点
- 三、应用实例
- 四、算法实现
- 五、注意事项
- 乘积密码
- 乘积密码的基本概念和原理
- 乘积密码的应用场景与优势
- 乘积密码的算法设计与实现
- 乘积密码的实例
- 乘积密码的发展趋势与挑战
- 参考文献
概率分布
-
bayes概率
P r ( X = x ) 为明文的先验概率 P r ( Y = y ) 为密文的先验概率 P r ( K = k ) 为密钥的先验概率 C ( K ) = ( e k ( x ) ∣ k ∈ P ) , P 为明文, C ( K ) 为密文 ∀ y ∈ C , P r ( Y = y ) = Σ k : y ∈ C ( K ) P r ( K = k ) P r ( x = d k ( y ) ) P r ( Y = y ∣ X = x ) = Σ k : x = d k ( y ) P r ( K = k ) 所有先验概率准备完毕,下面是 b a y e s 概率了 P r ( X = x ∣ Y = y ) = P r ( X = x ) × Σ k : x = d k ( y ) P r ( K = k ) Σ k : y ∈ C ( k ) P r ( K = k ) P r ( x = d x ( y ) ) Pr(X=x)为明文的先验概率 \\Pr(Y=y)为密文的先验概率 \\Pr(K=k)为密钥的先验概率 \\C(K)=(e_k(x)|k \in P),P为明文,C(K)为密文 \\\forall y \in C,Pr(Y=y)=\Sigma_{k:y \in C(K)} Pr(K=k)Pr(x=d_k(y)) \\Pr(Y=y|X=x)=\Sigma_{k:x=d_k(y)}Pr(K=k) \\所有先验概率准备完毕,下面是bayes概率了 \\Pr(X=x|Y=y)=\frac {Pr(X=x)\times \Sigma_{k:x=d_k(y)}Pr(K=k)}{\Sigma_{k:y \in C(k)}Pr(K=k)Pr(x=d_x(y))} Pr(X=x)为明文的先验概率Pr(Y=y)为密文的先验概率Pr(K=k)为密钥的先验概率C(K)=(ek(x)∣k∈P),P为明文,C(K)为密文∀y∈C,Pr(Y=y)=Σk:y∈C(K)Pr(K=k)Pr(x=dk(y))Pr(Y=y∣X=x)=Σk:x=dk(y)Pr(K=k)所有先验概率准备完毕,下面是bayes概率了Pr(X=x∣Y=y)=Σk:y∈C(k)Pr(K=k)Pr(x=dx(y))Pr(X=x)×Σk:x=dk(y)Pr(K=k) -
例子
设明文集合 P = { 1 , 2 , 3 , 4 , 5 } ,密文集合 C = { a , b , c , d , e } ∀ i ∈ P , P r ( i ) = 1 2 i , P r ( 1 ) = 1 2 , P r ( 2 ) = 1 4 , P r ( 3 ) = 1 6 , . . . K = { K 1 , K 2 } , P r ( K i ) = 1 − 1 2 i , P r ( K 1 ) = 1 2 , P r ( K 2 ) = 3 4 0 ≤ j < 5 , j ∈ Z e K i ( P j ) = C ( j + i + 1 ) m o d 5 e K 1 ( 1 ) = c , e K 1 ( 2 ) = d , e K 1 ( 3 ) = e , e K 1 ( 4 ) = a , e K 1 ( 5 ) = b e K 2 ( 1 ) = d , e K 2 ( 2 ) = e , e K 2 ( 3 ) = a , e K 2 ( 4 ) = b , e K 2 ( 5 ) = c 1. C 概率分布 P r ( a ) = ( 1 / 2 ) × ( 1 / 8 ) + ( 3 / 4 ) × ( 1 / 6 ) = 3 / 16 P r ( b ) = ( 1 / 2 ) × ( 1 / 10 ) + ( 3 / 4 ) × ( 1 / 8 ) P r ( c ) = ( 1 / 2 ) × ( 1 / 2 ) + ( 3 / 4 ) × ( 1 / 10 ) P r ( d ) = ( 1 / 2 ) × ( 1 / 4 ) + ( 3 / 4 ) × ( 1 / 2 ) P r ( e ) = ( 1 / 2 ) × ( 1 / 4 ) + ( 3 / 4 ) × ( 1 / 6 ) 2. 给定密文后,明文空间上条件概率分布为 P r ( X = x ∣ Y = y ) P r ( 1 ∣ a ) = 0 P r ( 2 ∣ a ) = 0 . . . . P r ( 4 ∣ a ) = P r ( X = 4 ) × P r ( K = K 1 ) P r ( Y = a ) = 1 / 8 × 1 / 2 3 / 16 = 1 3 . . . . 3. 密码机制具有完善保密性 < = 对于任意 x ∈ P , y ∈ C , P r ( x ∣ y ) = P r ( x ) 上面例子的密码机制不具有完善保密性 : P r ( 4 ∣ a ) = 1 / 3 , P ( 4 ) = 1 / 8 设明文集合P=\{1,2,3,4,5\},密文集合C=\{a,b,c,d,e\} \\ \forall i \in P,Pr(i)=\frac 1 {2i},Pr(1)=\frac 1 2,Pr(2)= \frac 1 4,Pr(3)=\frac 1 6,... \\K=\{K_1,K_2\},Pr(K_i)=1-\frac 1 {2i},Pr(K_1)=\frac 1 2,Pr(K_2) =\frac 3 4 \\0 \le j < 5,j \in Z \\e_{K_i}(P_j)=C_{(j+i+1) mod5} \\e_{K_1}(1)=c,e_{K_1}(2)=d,e_{K_1}(3)=e,e_{K_1}(4)=a,e_{K_1}(5)=b \\e_{K_2}(1)=d,e_{K_2}(2)=e,e_{K_2}(3)=a,e_{K_2}(4)=b,e_{K_2}(5)=c \\1.C概率分布 \\Pr(a)=(1/2) \times (1/8)+(3/4)\times(1/6)=3/16 \\Pr(b)=(1/2)\times(1/10)+(3/4)\times(1/8) \\Pr(c)=(1/2)\times(1/2)+(3/4)\times(1/10) \\Pr(d)=(1/2)\times(1/4)+(3/4)\times(1/2) \\Pr(e)=(1/2)\times(1/4)+(3/4)\times(1/6) \\2.给定密文后,明文空间上条件概率分布为Pr(X=x|Y=y) \\Pr(1|a)=0 \\Pr(2|a)=0 \\.... \\Pr(4|a)=\frac {Pr(X=4)\times Pr(K=K_1)} {Pr(Y=a)}=\frac {1/8 \times1/2}{3/16}=\frac 1 3 \\.... \\3.密码机制具有完善保密性<=对于任意x \in P,y \in C,Pr(x|y)=Pr(x) \\上面例子的密码机制不具有完善保密性:Pr(4|a)=1/3,P(4)=1/8 设明文集合P={1,2,3,4,5},密文集合C={a,b,c,d,e}∀i∈P,Pr(i)=2i1,Pr(1)=21,Pr(2)=41,Pr(3)=61,...K={K1,K2},Pr(Ki)=1−2i1,Pr(K1)=21,Pr(K2)=430≤j<5,j∈ZeKi(Pj)=C(j+i+1)mod5eK1(1)=c,eK1(2)=d,eK1(3)=e,eK1(4)=a,eK1(5)=beK2(1)=d,eK2(2)=e,eK2(3)=a,eK2(4)=b,eK2(5)=c1.C概率分布Pr(a)=(1/2)×(1/8)+(3/4)×(1/6)=3/16Pr(b)=(1/2)×(1/10)+(3/4)×(1/8)Pr(c)=(1/2)×(1/2)+(3/4)×(1/10)Pr(d)=(1/2)×(1/4)+(3/4)×(1/2)Pr(e)=(1/2)×(1/4)+(3/4)×(1/6)2.给定密文后,明文空间上条件概率分布为Pr(X=x∣Y=y)Pr(1∣a)=0Pr(2∣a)=0....Pr(4∣a)=Pr(Y=a)Pr(X=4)×Pr(K=K1)=3/161/8×1/2=31....3.密码机制具有完善保密性<=对于任意x∈P,y∈C,Pr(x∣y)=Pr(x)上面例子的密码机制不具有完善保密性:Pr(4∣a)=1/3,P(4)=1/8
哈夫曼编码实现
julia官方文档建议的变量命名规范:
- 变量名用小写。 单词用下划线"_"分隔,建议只对复杂的名称使用。
- 类型、模块的名称以大写字母开头,单词以驼峰方式间隔。
- 函数名和宏名用不带下划线的小写字母。
- 改变输入参数值的函数,函数名以’!'为结尾
julia源码
mutable struct NodeDatadata::Stringdata_pr::Realbm::Union{String,Nothing}
endmutable struct TreeNodedata::NodeDataleft::Union{TreeNode, Nothing}right::Union{TreeNode, Nothing}
end# 插入节点的函数
function newnode(data::String,data_pr::Real,bm=nothing)ndata=NodeData(data,data_pr,bm)tnode=TreeNode(ndata,nothing,nothing)return tnode
end
function insertleft(node::TreeNode, leftsubnode::TreeNode)node.left=leftsubnode
end
function insertright(node::TreeNode, rightsubnode::TreeNode)node.right=rightsubnode
endfunction printPaths(node::TreeNode, nodetype::String="L",path = []) if node == nothing return end if nodetype=="L"node.data.bm="0"elsenode.data.bm="1"end# 将当前节点的值添加到路径中 push!(path, node.data) # 如果是叶节点,则打印路径 if node.left == nothing && node.right == nothing println("===",path,"===") else # 递归遍历左子树和右子树 printPaths(node.left,"L",path) printPaths(node.right,"R",path) end # 回溯,移除当前节点值 pop!(path) end# 使用
strtxt="Fedora Workstation is Fedora’s official desktop edition. It provides a powerful, easy to use desktop experience. Workstation is intended to be a great general purpose desktop. It also aims to be a fantastic platform for software developers.Workstation is part of the Fedora project. As such, it shares components, tools, and processes with other Fedora Editions and Spins. However, Workstation is also an independent project, which is able to make its own design and technical decisions, and is a distinct product of its own.The Workstation Working Group is the team that has responsibility for Fedora Workstation. However, Workstation wouldn’t be possible without the hard work of teams and individuals across the entire Fedora community.
"
#计算概率
word_pr=Dict{String,Real}()
for i in eachindex(strtxt)global word_prif haskey(word_pr,string(strtxt[i]))word_pr[string(strtxt[i])]+=1elseword_pr[string(strtxt[i])]=1end
end
allwordcount=sum(values(word_pr))
map!(x->x/allwordcount, values(word_pr))nodelist=Dict{String,TreeNode}()
#构建优先队列
wordslist=collect(word_pr)sort!(wordslist,by=x->x[2])while length(wordslist)>1global nodelistglobal wordslist#从优先队列中取出两个频率最小的节点,创建一个新的父节点,其频率为这两个子节点频率之和。c1=popfirst!(wordslist)c2=popfirst!(wordslist)if !haskey(nodelist,c1[1])nodelist[c1[1]]=newnode(c1[1],c1[2])endif !haskey(nodelist,c2[1])nodelist[c2[1]]=newnode(c2[1],c2[2])end#将新节点作为这两个子节点的父节点,并将新节点插入回优先队列。if !haskey(nodelist,c1[1]*c2[1])parentnode=newnode(c1[1]*c2[1],c1[2]+c2[2])nodelist[c1[1]*c2[1]]=parentnodeinsertleft(parentnode,nodelist[c1[1]])insertright(parentnode,nodelist[c2[1]])endpush!(wordslist,c1[1]*c2[1]=>c1[2]+c2[2])sort!(wordslist,by=x->x[2])
end printPaths(nodelist[wordslist[1][1]])===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("o", 0.08847184986595175, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("h,m", 0.04289544235924933, "0"), NodeData("h", 0.021447721179624665, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("h,m", 0.04289544235924933, "0"), NodeData(",m", 0.021447721179624665, "1"), NodeData(",", 0.010723860589812333, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("h,m", 0.04289544235924933, "0"), NodeData(",m", 0.021447721179624665, "1"), NodeData("m", 0.010723860589812333, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("g’j", 0.010723860589812333, "0"), NodeData("g", 0.005361930294906166, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("g’j", 0.010723860589812333, "0"), NodeData("’j", 0.005361930294906166, "1"), NodeData("’", 0.002680965147453083, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("g’j", 0.010723860589812333, "0"), NodeData("’j", 0.005361930294906166, "1"), NodeData("j", 0.002680965147453083, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("HITxAE", 0.010723860589812333, "1"), NodeData("HI", 0.005361930294906166, "0"), NodeData("H", 0.002680965147453083, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("HITxAE", 0.010723860589812333, "1"), NodeData("HI", 0.005361930294906166, "0"), NodeData("I", 0.002680965147453083, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("HITxAE", 0.010723860589812333, "1"), NodeData("TxAE", 0.005361930294906166, "1"), NodeData("Tx", 0.002680965147453083, "0"), NodeData("T", 0.0013404825737265416, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("HITxAE", 0.010723860589812333, "1"), NodeData("TxAE", 0.005361930294906166, "1"), NodeData("Tx", 0.002680965147453083, "0"), NodeData("x", 0.0013404825737265416, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("HITxAE", 0.010723860589812333, "1"), NodeData("TxAE", 0.005361930294906166, "1"), NodeData("AE", 0.002680965147453083, "1"), NodeData("A", 0.0013404825737265416, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData("g’jHITxAE", 0.021447721179624665, "0"), NodeData("HITxAE", 0.010723860589812333, "1"), NodeData("TxAE", 0.005361930294906166, "1"), NodeData("AE", 0.002680965147453083, "1"), NodeData("E", 0.0013404825737265416, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData(".u", 0.02546916890080429, "1"), NodeData(".", 0.012064343163538873, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("oh,mg’jHITxAE.u", 0.17828418230563003, "0"), NodeData("h,mg’jHITxAE.u", 0.08981233243967829, "1"), NodeData("g’jHITxAE.u", 0.04691689008042896, "1"), NodeData(".u", 0.02546916890080429, "1"), NodeData("u", 0.013404825737265416, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("nr", 0.10455764075067024, "0"), NodeData("n", 0.05093833780160858, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("nr", 0.10455764075067024, "0"), NodeData("r", 0.05361930294906166, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("vGSyfp", 0.05630026809651474, "0"), NodeData("vGSyf", 0.02815013404825737, "0"), NodeData("vGSy", 0.013404825737265416, "0"), NodeData("v", 0.006702412868632708, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("vGSyfp", 0.05630026809651474, "0"), NodeData("vGSyf", 0.02815013404825737, "0"), NodeData("vGSy", 0.013404825737265416, "0"), NodeData("GSy", 0.006702412868632708, "1"), NodeData("GS", 0.002680965147453083, "0"), NodeData("G", 0.0013404825737265416, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("vGSyfp", 0.05630026809651474, "0"), NodeData("vGSyf", 0.02815013404825737, "0"), NodeData("vGSy", 0.013404825737265416, "0"), NodeData("GSy", 0.006702412868632708, "1"), NodeData("GS", 0.002680965147453083, "0"), NodeData("S", 0.0013404825737265416, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("vGSyfp", 0.05630026809651474, "0"), NodeData("vGSyf", 0.02815013404825737, "0"), NodeData("vGSy", 0.013404825737265416, "0"), NodeData("GSy", 0.006702412868632708, "1"), NodeData("y", 0.004021447721179625, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("vGSyfp", 0.05630026809651474, "0"), NodeData("vGSyf", 0.02815013404825737, "0"), NodeData("f", 0.014745308310991957, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("vGSyfp", 0.05630026809651474, "0"), NodeData("p", 0.028150134048257374, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("oh,mg’jHITxAE.unrvGSyfpa", 0.4008042895442359, "0"), NodeData("nrvGSyfpa", 0.22252010723860588, "1"), NodeData("vGSyfpa", 0.11796246648793565, "1"), NodeData("a", 0.06166219839142091, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData("iwbFkl", 0.1327077747989276, "0"), NodeData("i", 0.06568364611260054, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData("iwbFkl", 0.1327077747989276, "0"), NodeData("wbFkl", 0.06702412868632707, "1"), NodeData("wbF", 0.030831099195710455, "0"), NodeData("w", 0.014745308310991957, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData("iwbFkl", 0.1327077747989276, "0"), NodeData("wbFkl", 0.06702412868632707, "1"), NodeData("wbF", 0.030831099195710455, "0"), NodeData("bF", 0.0160857908847185, "1"), NodeData("b", 0.00804289544235925, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData("iwbFkl", 0.1327077747989276, "0"), NodeData("wbFkl", 0.06702412868632707, "1"), NodeData("wbF", 0.030831099195710455, "0"), NodeData("bF", 0.0160857908847185, "1"), NodeData("F", 0.00804289544235925, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData("iwbFkl", 0.1327077747989276, "0"), NodeData("wbFkl", 0.06702412868632707, "1"), NodeData("kl", 0.03619302949061662, "1"), NodeData("k", 0.01742627345844504, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData("iwbFkl", 0.1327077747989276, "0"), NodeData("wbFkl", 0.06702412868632707, "1"), NodeData("kl", 0.03619302949061662, "1"), NodeData("l", 0.01876675603217158, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("iwbFkl ", 0.28284182305630023, "0"), NodeData(" ", 0.15013404825737264, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("st", 0.15281501340482573, "0"), NodeData("s", 0.07238605898123325, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("st", 0.15281501340482573, "0"), NodeData("t", 0.08042895442359249, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("ed\nWc", 0.16353887399463807, "1"), NodeData("e", 0.08176943699731903, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("ed\nWc", 0.16353887399463807, "1"), NodeData("d\nWc", 0.08176943699731903, "1"), NodeData("d", 0.040214477211796246, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("ed\nWc", 0.16353887399463807, "1"), NodeData("d\nWc", 0.08176943699731903, "1"), NodeData("\nWc", 0.04155495978552279, "1"), NodeData("\nW", 0.020107238605898123, "0"), NodeData("\n", 0.00938337801608579, "0")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("ed\nWc", 0.16353887399463807, "1"), NodeData("d\nWc", 0.08176943699731903, "1"), NodeData("\nWc", 0.04155495978552279, "1"), NodeData("\nW", 0.020107238605898123, "0"), NodeData("W", 0.010723860589812333, "1")]===
===Any[NodeData("oh,mg’jHITxAE.unrvGSyfpaiwbFkl sted\nWc", 1.0, "0"), NodeData("iwbFkl sted\nWc", 0.599195710455764, "1"), NodeData("sted\nWc", 0.3163538873994638, "1"), NodeData("ed\nWc", 0.163538873994638
上述程序构造了从根结点到叶子结点的所有路径。
熵
以下内容取自文心一言自动生成。
一、信息熵的定义
- 信息学中的熵,特别是在信息论中,用于量化信息的不确定性或随机性。熵的计算是基于随机变量的概率分布来进行的。具体来说,信息熵的计算公式为:
[ H ( X ) = − ∑ i = 1 n P ( x i ) log 2 ( P ( x i ) ) ] [ H(X) = -\sum_{i=1}^{n} P(x_i) \log_2(P(x_i)) ] [H(X)=−i=1∑nP(xi)log2(P(xi))]
其中,X 表示随机变量,n 是 X可能取值的总数, P ( x i ) P(x_i) P(xi)是 X取值为 x i x_i xi的概率, log 2 \log_2 log2 表示以2为底的对数。
这个公式表示了随机变量 X 的信息熵 H(X),它是 X 所有可能取值的信息量的加权平均,权重是各个取值的概率。信息量 I ( x i ) I(x_i) I(xi)被定义为 − log 2 ( P ( x i ) ) -\log_2(P(x_i)) −log2(P(xi)),它表示了当随机变量 X取值为 x i x_i xi时,我们所获得的信息量。
在信息论中,熵(Entropy)是一个用来量化信息不确定性或随机性的重要概念。信息学熵的计算主要基于概率分布,其计算公式和信息量的概念紧密相关。
以下是对信息学熵的详细阐述:
- 信息熵是随机变量不确定性的度量,它表示了随机变量所有可能取值的信息量的期望。对于离散随机变量X,其信息熵H(X)的定义如下:
[ H ( X ) = − ∑ i = 1 n P ( x i ) log b P ( x i ) ] [ H(X) = -\sum_{i=1}^{n} P(x_i) \log_b P(x_i) ] [H(X)=−∑i=1nP(xi)logbP(xi)]
其中, P ( x i ) P(x_i) P(xi)是随机变量X取值为 x i x_i xi的概率,n是X所有可能取值的数量,b是对数的底数(在信息论中,常用2作为底数,此时单位称为比特;也有用自然对数作为底数的,此时单位称为奈特)。
二、信息量的概念
信息量与信息熵紧密相关,它度量的是一个具体事件发生了所带来的信息。对于某一事件X,其信息量I(X)的计算公式为:
[ I ( X ) = − log b P ( X ) ] [ I(X) = -\log_b P(X) ] [I(X)=−logbP(X)]
其中,P(X)是事件X发生的概率。这个公式表明,一个事件发生的概率越小,它所包含的信息量就越大;反之,概率越大,信息量就越小。
三、信息熵的计算步骤
-
确定随机变量的所有可能取值及其概率:首先,需要明确随机变量X的所有可能取值,并计算出每个取值对应的概率 P ( x i ) P(x_i) P(xi)。
-
计算每个取值的信息量:根据信息量的计算公式,计算随机变量X每个取值的信息量 I ( x i ) = − log b P ( x i ) I(x_i) = -\log_b P(x_i) I(xi)=−logbP(xi)。
-
计算信息熵:最后,将每个取值的信息量乘以其对应的概率,并求和,即可得到随机变量X的信息熵 H ( X ) = − ∑ i = 1 n P ( x i ) log b P ( x i ) H(X) = -\sum_{i=1}^{n} P(x_i) \log_b P(x_i) H(X)=−∑i=1nP(xi)logbP(xi)。
四、信息熵的性质
-
非负性:信息熵总是非负的,即 H ( X ) ≥ 0 H(X) \geq 0 H(X)≥0。这是因为概率P的取值范围是[0,1],而对数函数在(0,1]区间内是负的,所以加上负号后变为正数或0。
-
极值性:当随机变量X的所有取值概率相等时(即均匀分布),信息熵取得最大值。这是因为此时不确定性最大。
-
可加性:对于多个相互独立的随机变量,它们联合分布的信息熵等于各随机变量信息熵之和。
五、应用举例
- 以世界杯冠军预测为例,如果假设有32支球队参赛,且每支球队夺冠的概率相等(即1/32),则“谁是世界杯冠军”这一信息的信息熵为:
[ H ( X ) = − ∑ i = 1 32 1 32 log 2 1 32 = − log 2 1 32 = 5 比特 ] [H(X) = -\sum_{i=1}^{32} \frac{1}{32} \log_2 \frac{1}{32} = -\log_2 \frac{1}{32} = 5 \text{比特} ] [H(X)=−∑i=132321log2321=−log2321=5比特]
这表示,为了确定世界杯冠军,平均需要5比特的信息量。然而,在实际情况下,由于各支球队的夺冠概率并不相等,因此所需的信息量通常会小于5比特。
- 假设有一个随机变量 (X),它只有两个可能的取值:0和1,且 P ( X = 0 ) = 0.5 P(X=0) = 0.5 P(X=0)=0.5, P ( X = 1 ) = 0.5 P(X=1) = 0.5 P(X=1)=0.5。则 X X X 的信息熵为:
[ H ( X ) = − ( 0.5 log 2 ( 0.5 ) + 0.5 log 2 ( 0.5 ) ) = − ( 0.5 × ( − 1 ) + 0.5 × ( − 1 ) ) = 1 bit ] [ H(X) = - (0.5 \log_2(0.5) + 0.5 \log_2(0.5)) = - (0.5 \times (-1) + 0.5 \times (-1)) = 1 \text{ bit} ] [H(X)=−(0.5log2(0.5)+0.5log2(0.5))=−(0.5×(−1)+0.5×(−1))=1 bit]
这表示在平均意义上,我们需要1比特的信息来完全确定 (X) 的取值。
哈夫曼编码(Huffman Coding)
又称霍夫曼编码,是一种可变字长编码(VLC, Variable Length Coding)方式,由David A. Huffman在1952年提出。它是一种用于无损数据压缩的熵编码算法,通常用于压缩重复率比较高的字符数据。哈夫曼编码完全依据字符出现概率来构造异字头的平均长度最短的码字,因此有时也称之为最佳编码。
基本原理
哈夫曼编码的基本方法是先对图像数据或文本数据扫描一遍,计算出各种字符或像素出现的概率,然后按概率的大小指定不同长度的唯一码字,由此得到一张该数据的哈夫曼码表。编码后的数据记录的是每个字符或像素的码字,而码字与实际字符或像素值的对应关系则记录在码表中。
编码过程
- 统计频率:计算字符串或数据集中每个字符或像素出现的频率。
- 排序:将字符或像素按照出现频率由低到高进行排序。
- 构建哈夫曼树:
- 创建一个空节点,将最小频率的两个字符或像素作为该节点的左右子节点,并将它们的频率相加作为父节点的频率。
- 将这两个子节点从队列中删除,并将父节点添加到队列中。
- 重复上述步骤,直到队列中只剩下一个节点,即根节点,此时哈夫曼树构建完成。
- 生成编码:从根节点开始,为每个字符或像素生成一个唯一的编码。对于每个非叶子节点,将0分配给连接线的左侧,1分配给连接线的右侧。从根节点到叶子节点的路径上的0和1序列即为该叶子节点代表的字符或像素的编码。
特点
- 编码效率高:由于哈夫曼编码根据字符或像素的出现频率分配码长,因此出现频率高的字符或像素使用较短的编码,而出现频率低的则使用较长的编码,从而实现了数据的有效压缩。
- 编码不唯一:由于构建哈夫曼树时可以为左右子节点任意分配0和1,以及当两个字符或像素的频率相等时排序的随机性,因此生成的哈夫曼编码并不唯一。但所有有效的哈夫曼编码都具有相同的平均码长。
- 前缀码:哈夫曼编码的一个重要特性是任何一个编码都不是其他编码的前缀,这保证了在解码时能够准确地分离出每个字符或像素的编码。
应用
哈夫曼编码已被广泛应用于数据压缩领域,如文件压缩、图像压缩、视频压缩等。此外,在通信和网络传输中,哈夫曼编码也常被用于减少数据传输量,提高传输效率。
综上所述,哈夫曼编码是一种基于字符或像素出现频率的无损数据压缩算法,通过构建哈夫曼树并为每个字符或像素生成唯一的编码来实现数据的压缩。由于其高效的压缩性能和广泛的应用场景,哈夫曼编码在数据压缩领域具有重要的地位。
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是由David A. Huffman在1952年提出的一种编码方法,它完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码。哈夫曼编码是可变字长编码(VLC)的一种,其基本原理是表示符号的码字长度随符号的出现概率而变化,对出现概率大的符号赋予短码字,出现概率小的符号赋予长码字,并且码字长度严格按照所对应符号出现概率大小逆序排列。以下是哈夫曼编码的具体过程:
具体过程
1. 排序概率
- 将信源符号的概率按从大到小的顺序排队,即P(1) > P(2) > … > P(Sm-1) > P(Sm)。
2. 合并最小概率
- 从概率最小的两个符号开始,将它们合并为一个新的符号,合并后的新符号概率为这两个符号概率之和。
- 在合并时,可以给这两个符号分别赋予“0”和“1”(或相反)作为它们的编码,这取决于合并时的具体实现。
3. 更新概率序列
- 将合并后的新符号的概率与未处理的其余符号的概率重新按从大到小的顺序排列,形成一个新的概率序列。
4. 重复合并
- 重复步骤2和步骤3,直到所有的符号都被合并为一个概率为1的符号为止。在这个过程中,每次合并都会生成一个新的符号,并给这个新符号赋予一个编码(由前面合并时赋予的“0”和“1”组成)。
5. 生成码表
- 最后,从合并得到的概率总和为1的符号开始,逆向追踪每个符号的编码路径,从而得到每个原始符号的哈夫曼码字。
- 这些码字和它们对应的原始符号一起构成了哈夫曼码表。
6. 编码数据
- 使用生成的哈夫曼码表对原始数据进行编码,即用每个符号的哈夫曼码字替换原始数据中的符号。
示例
假设有以下符号及其概率:a(0.4), b(0.2), c(0.2), d(0.1), e(0.1)。
- 排序:a, b=c, d=e
- 合并b和c,得到新符号bc(0.4),赋予编码“0”(或“1”),假设为“0”
- 合并d和e,得到新符号de(0.2),赋予编码“1”(或“0”),假设为“1”
- 排序:a, bc, de
- 合并a和bc,得到新符号abc(0.8),赋予编码“0”(或“1”),假设为“0”
- 现在只剩下一个符号de,其编码为“1”
- 逆向追踪:a的编码为“00”,bc的编码为“01”(假设b为“0”,c为“1”),de的编码为“1”
这样,就得到了每个符号的哈夫曼码字,并可以据此对包含这些符号的数据进行编码。
哈夫曼编码由于其编码长度与符号出现概率的逆序关系,使得编码后的数据平均长度最短,因此在实际应用中常用于数据压缩领域。
哈夫曼编码的具体算法
哈夫曼编码是一种广泛用于数据文件压缩的非常有效的编码方法,其核心思想是利用字符频率信息,通过贪心策略构建一棵最优二叉树(哈夫曼树),使得高频字符使用较短的编码,低频字符使用较长的编码,从而实现数据压缩。以下是哈夫曼编码的具体算法步骤:
一、算法步骤
-
统计频率:
- 遍历数据,统计每个字符在数据中出现的频率。
-
构建优先队列:
- 将每个字符及其频率作为一个节点,并按照频率从小到大的顺序放入优先队列(最小堆)。
- 如果两个字符频率相同,则它们的顺序可以任意,因为哈夫曼编码不唯一,但都能正常工作。
-
构建哈夫曼树:
- 重复执行以下步骤,直到优先队列中只剩下一个节点(即哈夫曼树的根节点):
- 从优先队列中取出两个频率最小的节点。
- 创建一个新的父节点,其频率为这两个子节点频率之和。
- 将新节点作为这两个子节点的父节点,并将新节点插入回优先队列。
- 重复执行以下步骤,直到优先队列中只剩下一个节点(即哈夫曼树的根节点):
-
生成编码:
- 从根节点开始,为哈夫曼树的每个节点规定编码:
- 左子树路径编码为“0”,右子树路径编码为“1”。
- 从根节点到每个叶子节点的路径(包括经过的“0”和“1”)构成了该叶子节点所代表字符的哈夫曼编码。
- 从根节点开始,为哈夫曼树的每个节点规定编码:
二、算法特点
- 前缀码:哈夫曼编码是一种前缀码,即任何一个字符的编码都不是另一个字符编码的前缀,这使得解码过程变得非常简单和高效。
- 变长编码:高频字符使用较短的编码,低频字符使用较长的编码,从而减少了整体编码的长度,提高了压缩效率。
- 最优性:在给定字符频率分布的情况下,哈夫曼编码生成的编码方案是平均码长最短的编码方案。
三、应用实例
假设有一个字符串“aaaaabbcdddeee”,我们可以按照以下步骤进行哈夫曼编码:
-
统计频率:
- a: 5
- b: 2
- c: 1
- d: 3
- e: 3
-
构建优先队列和哈夫曼树(这里省略详细构建过程,仅给出结果):
- 最终构建的哈夫曼树将包含这些字符作为叶子节点,并根据它们的频率进行合并。
-
生成编码:
- 假设生成的哈夫曼编码为(注意:实际编码可能因构建过程的具体实现而异):
- a: 0
- b: 101
- c: 100
- d: 111
- e: 110
- 假设生成的哈夫曼编码为(注意:实际编码可能因构建过程的具体实现而异):
四、算法实现
哈夫曼编码的算法实现相对简单,主要涉及到频率统计、优先队列操作以及树的构建。在实际应用中,可以使用各种编程语言中的数据结构(如优先队列、二叉树等)来实现该算法。
五、注意事项
- 在实际应用中,需要注意哈夫曼编码的解码过程,由于它是前缀码,所以解码时无需回溯。
- 哈夫曼编码是一种无损压缩算法,可以保证压缩后的数据可以完全还原成原始数据。
- 哈夫曼编码的压缩效率取决于字符频率的分布情况,对于频率分布差异较大的数据,哈夫曼编码的压缩效果更为显著。
- 乘积密码是一种密码学中的概念,它指的是通过连续执行两个或多个密码系统(或加密算法),以使得所得到的最后结果或乘积从密码编码的角度比其任意一个组成密码都更强。这种密码体制的主要作用是提高加密的安全性,通过多次加密,增加攻击者破解密文的难度,从而保护数据的机密性和完整性。
乘积密码
以下内容取自文心一言自动生成。
乘积密码的基本概念和原理
- 定义:乘积密码以某种方式连续执行两个或多个密码,使得最终结果的密码强度高于每个单独密码的强度。这是公钥密码学中的一个重要概念,尤其在实现复杂的安全需求时非常有用。
- 原理:乘积密码基于扩散和混乱两种基本密码操作的组合变换。通过多次加密变换,可以产生比单独使用任何一个密码时更强大的密码系统。
乘积密码的应用场景与优势
- 保密性:乘积密码通过对数据进行多次加密,确保在传输过程中数据不被未经授权的第三方窃取或窥探。
- 完整性:通过使用哈希函数等密码学工具,乘积密码能够检测数据在传输过程中是否被篡改,保证数据的完整性。
- 不可否认性:结合数字签名技术,乘积密码可以确保发送方和接收方都无法否认已发送或接收的数据,提供不可否认的证据。
- 身份认证和访问控制:乘积密码支持用户身份认证,确保只有授权用户能够访问特定资源或服务。同时,结合身份认证,乘积密码可实现细粒度的访问控制,根据用户角色和权限限制对资源的访问。
乘积密码的算法设计与实现
- 选择加密算法:根据安全需求和性能要求,选择合适的加密算法,如AES、DES、RSA等。
- 确定加密模式:根据加密算法的特性,选择合适的加密模式,如ECB、CBC、CFB等。
- 设置加密参数:设置加密算法所需的密钥、初始化向量等参数。
- 执行加密操作:将明文输入到加密算法中,经过多次加密变换,最终得到密文输出。
乘积密码的实例
- 古典密码学中的乘积密码:如转子机(Rotor Machines),它是非常复杂的多轮替代技术,广泛应用于第二次世界大战中。
- 现代密码学中的乘积密码:在现代密码学中,乘积密码的概念被广泛应用于各种加密协议和系统中,以提高数据的安全性和保护用户的隐私。
乘积密码的发展趋势与挑战
随着计算机技术和密码学的发展,乘积密码也在不断演进。一方面,新的加密算法和技术的出现为乘积密码提供了更多的选择和可能性;另一方面,随着计算能力的提升和攻击技术的发展,乘积密码也面临着更大的挑战。因此,在设计和实现乘积密码时,需要充分考虑其安全性和效率之间的平衡,以确保其在实际应用中的有效性和可靠性。
参考文献
1.《密码学原理与实践(第三版)》
2. 文心一言
相关文章:

密码学原理精解【8】
文章目录 概率分布哈夫曼编码实现julia官方文档建议的变量命名规范:julia源码 熵一、信息熵的定义二、信息量的概念三、信息熵的计算步骤四、信息熵的性质五、应用举例 哈夫曼编码(Huffman Coding)基本原理编码过程特点应用具体过程1. 排序概…...
2024年钉钉杯大数据竞赛A题超详细解题思路+python代码手把手保姆级运行讲解视频+问题一代码分享
初赛A:烟草营销案例数据分析 AB题综合难度不大,难度可以视作0.4个国赛,题量可以看作0.35个国赛题量。适合于国赛前队伍练手,队伍内磨合。竞赛获奖率50%,八月底出成绩,参赛人数3000队左右。本文将为大家进行…...
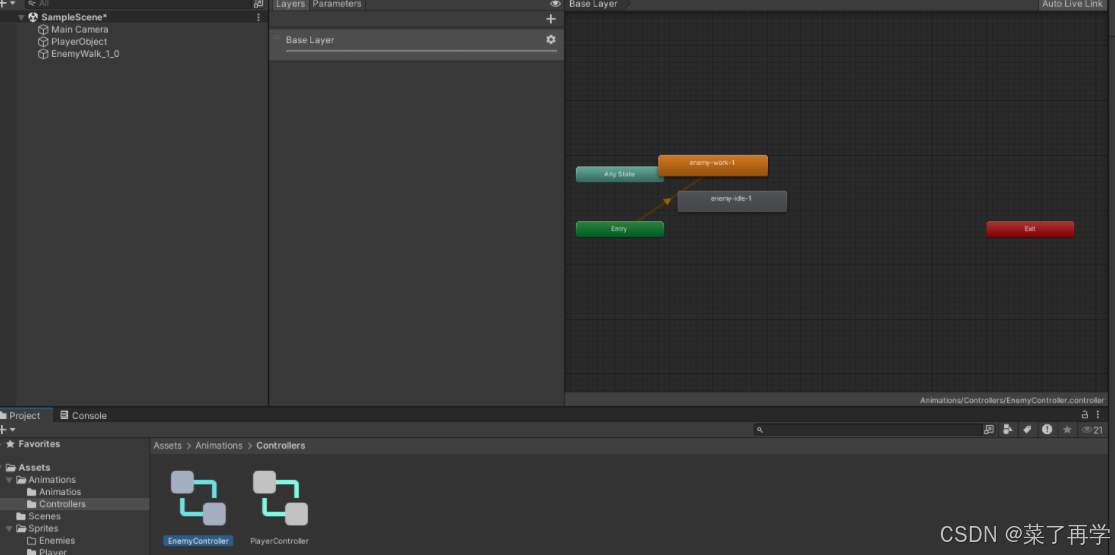
unity2D游戏开发01项目搭建
1新建项目 选择2d模板,设置项目名称和存储位置 在Hierarchy面板右击,create Empty 添加组件 在Project视图中右键新建文件夹 将图片资源拖进来(图片资源在我的下载里面) 点击Player 修改属性,修好如下 点击Sprite Editor 选择第二…...

删除的视频怎样才能恢复?详尽指南
在日常生活中,我们有时会不小心删除一些重要的视频文件,或者在整理存储空间时不慎丢失了珍贵的记忆片段。这时候,我们可以通过一些数据恢复工具和技巧,找回这些被删除的视频。本文将详细介绍几种常见且有效的视频恢复方法…...

LeetCode160 相交链表
前言 题目: 160. 相交链表 文档: 代码随想录——链表相交 编程语言: C 解题状态: 没思路… 思路 依旧是双指针法,很巧妙的方法,有点想不出来。 代码 先将两个链表末端对齐,然后两个指针齐头并…...

高性能响应式UI部件DevExtreme v24.1.4全新发布
DevExtreme拥有高性能的HTML5 / JavaScript小部件集合,使您可以利用现代Web开发堆栈(包括React,Angular,ASP.NET Core,jQuery,Knockout等)构建交互式的Web应用程序。从Angular和Reac,…...

Python实现Java mybatis-plus 产生的SQL自动化测试SQL速度和判断SQL是否走索引
Python实现Java mybatis-plus 产生的SQL自动化测试SQL速度和判断SQL是否走索引 文件目录如下 │ sql_speed_test.py │ ├─input │ data-report_in_visit_20240704.log │ resource_in_sso_20240704.log │ └─outputdata-report_in_visit_20240704.cs…...
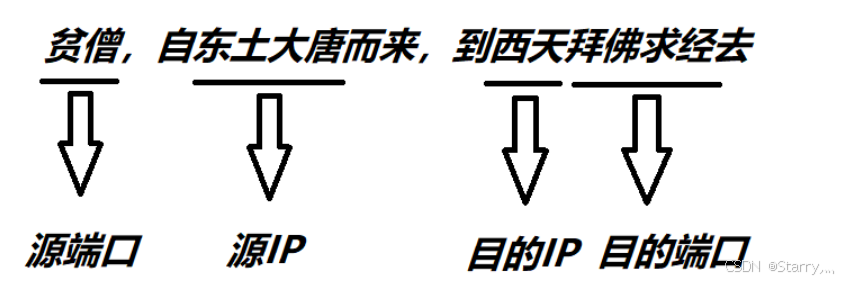
UDP的报文结构及其注意事项
1. 概述 UDP(User Datagram Protocol)是一种无连接的传输层协议,它提供了一种简单的数据传输服务,不保证数据的可靠传输。在网络通信中,UDP通常用于一些对实时性要求较高、数据量较小、传输延迟较低的应用,…...

MySQL深度分页问题深度解析与解决方案
文章目录 引言深度分页问题的原因解决方案方案一:使用主键索引优化方案二:使用子查询优化方案三:使用INNER JOIN优化方案四:使用搜索引擎 最佳实践结论 引言 在处理包含数百万条记录的大型数据表时,使用MySQL的LIMIT进…...

C#类型基础Part1-值类型与引用类型
C#类型基础Part1-值类型与引用类型 参考资料前言值类型引用类型装箱和拆箱 参考资料 《.NET之美–.NET关键技术深入与解析》 前言 C#中的类型一共分为两类,一类是值类型(Value Type),一类是引用类型(Reference Type)…...

被上市公司预判的EPS增速分析
EPS增速对二级市场投资和估值有着很显著的影响,上市公司显然也知道这一点。对于想要做市值管理的上市公司来说,调节EPS增速比调节EPS更加有效。因此《穿透财报:读懂财报中的逻辑与陷阱》中的作者在第四章正式提出了二级市场财务分析中的额动态…...
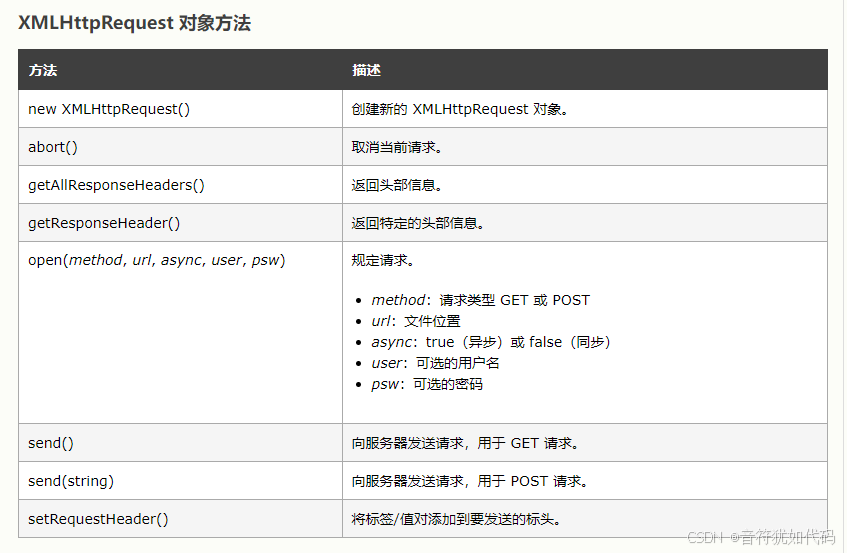
快速入门了解Ajax
博客主页:音符犹如代码系列专栏:JavaWeb关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Ajax的初识 意义:AJAX(Asynchronous JavaScript and…...
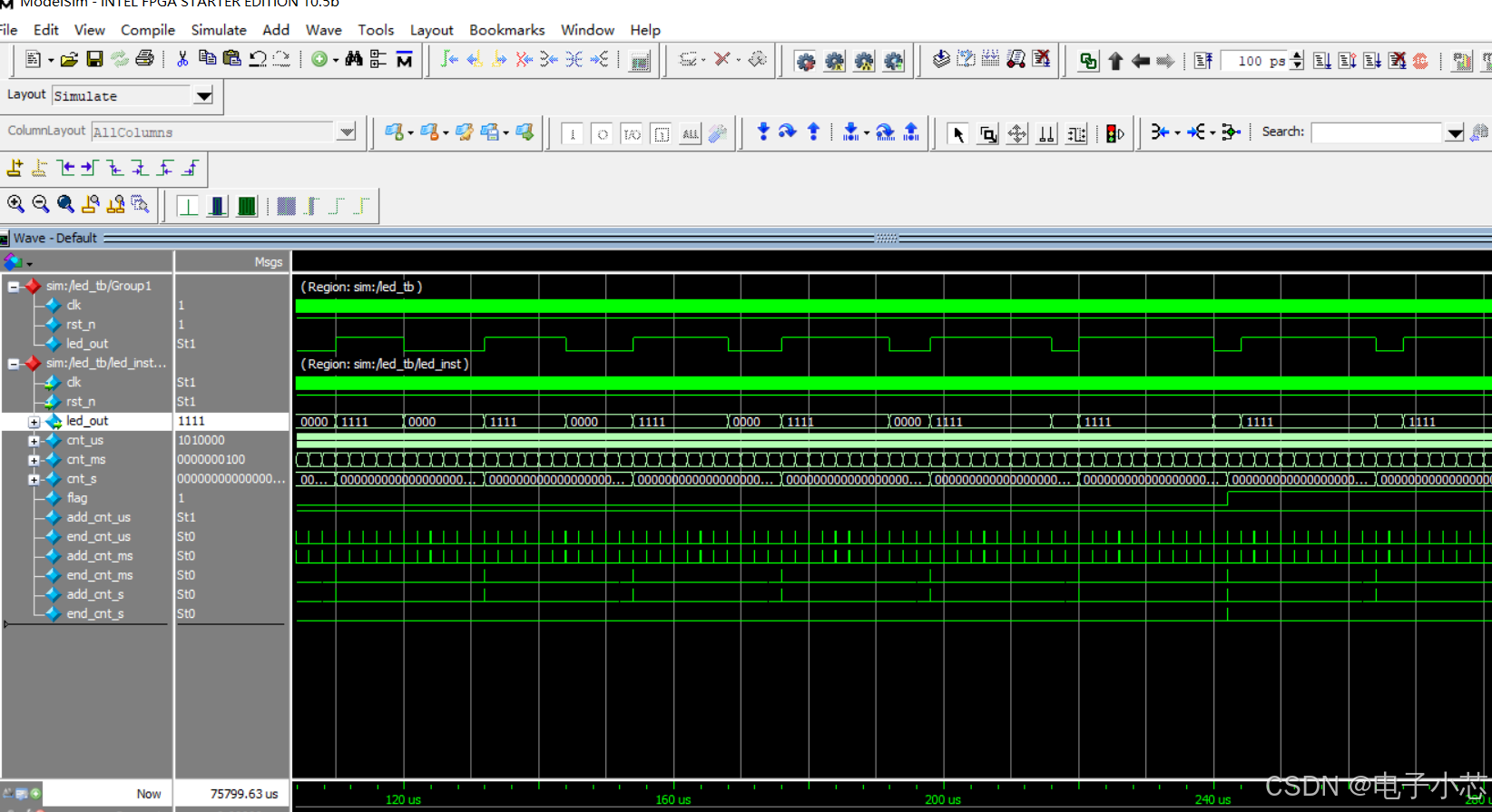
FPGA开发——呼吸灯的设计
一、原理 呼吸灯的原理主要基于PWM(脉冲宽度调制)技术,通过控制LED灯的占空比来实现亮度的逐渐变化。这种技术通过调整PWM信号的占空比,即高电平在一个周期内所占的比例,来控制LED灯的亮度。当占空比从0%逐渐变化到1…...

【数据结构】二叉树链式结构——感受递归的暴力美学
前言: 在上篇文章【数据结构】二叉树——顺序结构——堆及其实现中,实现了二叉树的顺序结构,使用堆来实现了二叉树这样一个数据结构;现在就来实现而二叉树的链式结构。 一、链式结构 链式结构,使用链表来表示一颗二叉树…...
开始尝试从0写一个项目--后端(三)
器材管理 和员工管理基本一致,就不赘述,展示代码为主 新增器材 表设计: 字段名 数据类型 说明 备注 id bigint 主键 自增 name varchar(32) 器材名字 img varchar(255) 图片 number BIGINT 器材数量 comment VARC…...

2024年7月解决Docker拉取镜像失败的实用方案,亲测有效
在Ubuntu 16.04、Debian 8、CentOS 7系统中,若遇到Docker拉取镜像失败的问题,以下是一些亲测有效的解决方案: 配置加速地址 首先,创建Docker配置目录:sudo mkdir -p /etc/docker然后,编辑daemon.json文件…...

基于内容的音乐推荐网站/基于ssm的音乐推荐系统/基于协同过滤推荐的音乐网站/基于vue的音乐平台
获取源码联系方式请查看文末🍅 摘 要 随着信息化时代的到来,系统管理都趋向于智能化、系统化,音乐推荐网站也不例外,但目前国内的有些公司仍然都使用人工管理,公司规模越来越大,同时信息量也越来越庞大&…...

STM32智能工业监控系统教程
目录 引言环境准备智能工业监控系统基础代码实现:实现智能工业监控系统 4.1 数据采集模块 4.2 数据处理与控制模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:工业监控与优化问题解决方案与优化收尾与总结 1. 引言 智能工业监控系统通…...
)
WEB渗透Web突破篇-SQL注入(MYSQL)
注释符 # -- 注意这里有个空格 /* hello */ /*! hello */ /*!32302 10*/ MYSQL version 3.23.02联合查询 得到列数 order by或group by 不断增加数字,直到得到报错响应 1 ORDER BY 1-- #True 1 ORDER BY 2-- #True 1 ORDER BY 3-- #True 1 ORDER BY 4-- #Fal…...
PDF解锁网站
https://smallpdf.com/cn/unlock-pdfhttps://smallpdf.com/cn/unlock-pdfhttps://www.freemypdf.comhttps://www.freemypdf.com...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...

二维FDTD算法仿真
二维FDTD算法仿真,并带完全匹配层,输入波形为高斯波、平面波 FDTD_二维/FDTD.zip , 6075 FDTD_二维/FDTD_31.m , 1029 FDTD_二维/FDTD_32.m , 2806 FDTD_二维/FDTD_33.m , 3782 FDTD_二维/FDTD_34.m , 4182 FDTD_二维/FDTD_35.m , 4793...

yaml读取写入常见错误 (‘cannot represent an object‘, 117)
错误一:yaml.representer.RepresenterError: (‘cannot represent an object’, 117) 出现这个问题一直没找到原因,后面把yaml.safe_dump直接替换成yaml.dump,确实能保存,但出现乱码: 放弃yaml.dump,又切…...