Redis底层数据结构的实现
文章目录
- 1、Redis数据结构
- 1.1 动态字符串
- 1.2 intset
- 1.3 Dict
- 1.4 ZipList
- 1.5 ZipList的连锁更新问题
- 1.6 QuickList
- 1.7 SkipList
- 1.8 RedisObject
- 2、五种数据类型
- 2.1 String
- 2.2 List
- 2.3 Set
- 2.4 ZSET
- 2.5 Hash
1、Redis数据结构
1.1 动态字符串
Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。
不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题:
- 获取字符串长度的需要通过运算:字符串都以
\0结尾,因此计算长度时,需要遍历一遍,直到读到\0- 非二进制安全:C语言不允许字符串中字符有
\0,因为有的话会被当做字符串结束标识- 不可修改:字符串在内存常量池,不能修改
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS
例如:我们执行set name zs这条命令,Redis将在底层创建两个SDS,其中一个是包含name的SDS,另一个是包含zs的SDS。
Redis中SDS源码
Redis中的SDS有5种类型,根据占用的空间,使用不同的类型,例如sdshdr8中len和alloc都是uint8_t类型的,表示最多255个字节,其中有一个字节是\0,因此最多存储254个字节数据,flags字段就表示当前SDS是那种类型的,buf中存储的就是真正的字符串
struct __attribute__ ((__packed__)) sdshdr5 {unsigned char flags; /* 3 lsb of type, and 5 msb of string length */char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* buf已保存的字符串字节数,不包含结束标识 */uint8_t alloc; /* buf申请的总字节数 */unsigned char flags; /* 不同的SDS类型(0,1,2,3,4) */char buf[]; /* 真正存放字符串的地方 */
};
struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len; /* used */uint16_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len; /* used */uint32_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* used */uint64_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];
};#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
一个包含字符串name的sds结构如下:第一次申请时,len和alloc长度是一样的,他们记录的值不包括\0,因此实际数据占用5个字节

SDS的扩容


一个内容为hi的字符串,初始时len和alloc都为2,此时要给SDS追加一段字符串,Amy,这里首先会申请新内存空间:
-
如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1,这里+1其实是给
\0使用的 -
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配,因为申请内存需要从用户态转为内核态,非常消耗性能,采用内存预分配后,下次再追加字符串,只要不超过最大长度,就不用去申请内存,提升性能
因此原字符串hi追加,Amy后长度为6个字节,小于1M,所以申请新内存空间为13字节,此时len为6表示字符串占用空间,alloc为12表示申请的空间,不包括\0的这一个字节
SDS优点
- 获取字符串长度的时间复杂度为
O(1),直接读取len字段即可 - 支持动态扩容
- 减少内存分配次数
- 二进制安全,读取字符串时,按照
len指定长度读取,即使读取到\0也不会有影响
1.2 intset
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
typedef struct intset {uint32_t encoding; // 编码方式,支持存放16位,32位,64位整数,下边有定义uint32_t length; // 元素个数int8_t contents[]; // 整数数组,contents类型为int8_t原因是它是一个指针,指向的是数组首地址,数组中元素的数据类型是通过encoding指定的
} intset;
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中
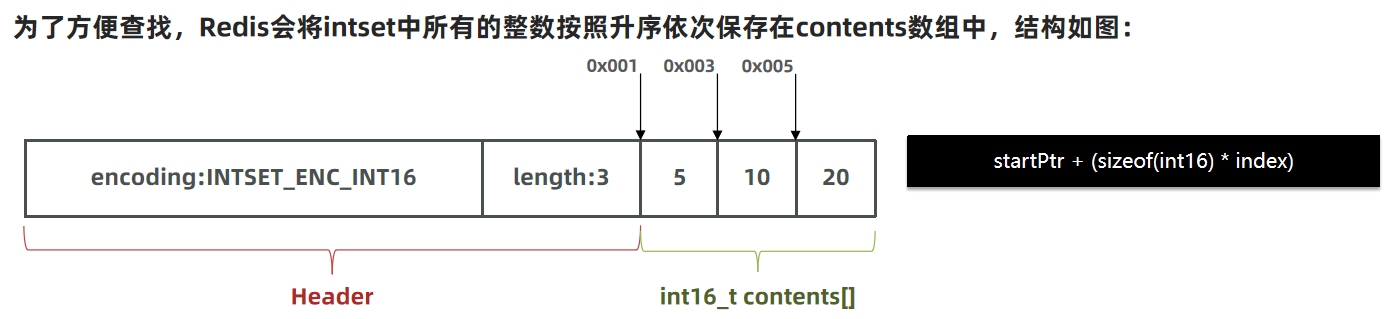
现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16
encoding:4字节length:4字节contents:2字节 * 3 = 6字节
此时,我们向其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
- 升级编码为
INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组 - 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将待添加的元素放入数组末尾
- 最后,将inset的
encoding属性改为INTSET_ENC_INT32,将length属性改为4

源码分析
inset添加元素
// is是当前inset集合,value是添加的元素
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {// 获取当前元素编码uint8_t valenc = _intsetValueEncoding(value);// 记录添加的位置uint32_t pos;if (success) *success = 1;// 判断编码是不是超过了当前inset的编码if (valenc > intrev32ifbe(is->encoding)) {// 超出编码,需要升级return intsetUpgradeAndAdd(is,value);} else {// 通过二分在inset中查找当前元素,如果当前元素存在,就直接退出,保证元素唯一,不存在,pos记录大于当前元素的第一个值if (intsetSearch(is,value,&pos)) {if (success) *success = 0;return is;}// 数组扩容,扩容为length+1is = intsetResize(is,intrev32ifbe(is->length)+1);// 移动数组,将pos之后的元素往后移动一个位置if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);}// 插入新元素_intsetSet(is,pos,value);// 重置元素长度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;
}
升级编码
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {// 拿到当前inset集合的编码uint8_t curenc = intrev32ifbe(is->encoding);// 插入元素的编码uint8_t newenc = _intsetValueEncoding(value);// inset集合的长度int length = intrev32ifbe(is->length);// 如果value小于0,那么应该插入到所有元素之前,大于0插入所有元素之后int prepend = value < 0 ? 1 : 0;// 修改inset集合的编码is->encoding = intrev32ifbe(newenc);// 数组扩容为length+1is = intsetResize(is,intrev32ifbe(is->length)+1);// 倒序拷贝元素,length+prepend就是要拷贝的位置,如果prepend为0表示新元素插入数组最后,为1表示插入数组第一个位置while(length--)_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));// 插入新元素if (prepend)_intsetSet(is,0,value);else_intsetSet(is,intrev32ifbe(is->length),value);// 设置长度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;
}
1.3 Dict
Redis是一个键值型的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系是通过Dict来实现的。但是他内存不连续,一个指针8字节,浪费内存
Dict由三部分组成:
-
哈希表(DictHashTable)
typedef struct dictht {// entry数组,table是指向DictEntry数组的指针dictEntry **table;// 哈希表大小unsigned long size;// 哈希表大小的掩码,size-1,与key的hash值做与运算找到key在哈希表中的位置unsigned long sizemask;// entry个数,可能大于size,因为会出现hash冲突unsigned long used; } dictht; -
哈希节点(DictEntry)
typedef struct dictEntry {void *key; // 键union {void *val;uint64_t u64;int64_t s64;double d;} v; // 值struct dictEntry *next; // 下一个Entry的指针 } dictEntry; -
字典(Dict)
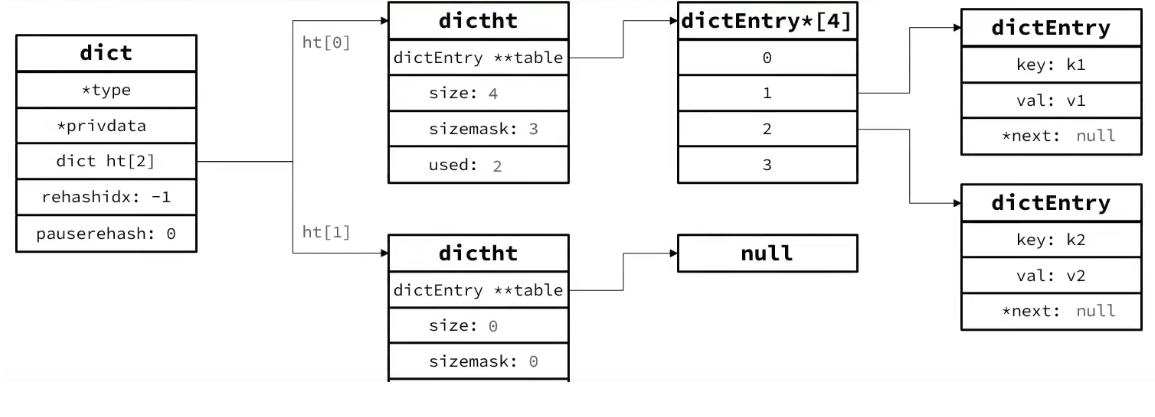
typedef struct dict {dictType *type; // dict类型,内置不同的hash函数void *privdata; // 私有数据,做特殊hash运算时使用dictht ht[2]; // 一个Dict包含两个hash表,其中一个存储当前数据,另一个一般为空,rehash时使用long rehashidx; // rehash进度,-1表示未进行int16_t pauserehash; // rehash是否暂停,1暂停,0继续 } dict;
当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。
我们存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1位置。
存储k2=v2,假设k2的哈希值h =1,则1&3 =1,因此k2=v2要存储到数组角标1位置,此时发生hash冲突,采用头插法将k2=v2这个entry插入链表头部

Dict结构
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行
BGSAVE或者BGREWRITEAOF等后台进程,因为这些进程需要大量的IO,可能导致进程阻塞 - 哈希表的 LoadFactor > 5 ;

int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{if (malloc_failed) *malloc_failed = 0;/* 如果正在做rehash或者当前hash表中entry数量大于size,报错 */if (dictIsRehashing(d) || d->ht[0].used > size)return DICT_ERR;// 新的hash表dictht n; /* the new hash table */// 找到大于等于size的第一个2^nunsigned long realsize = _dictNextPower(size);/* Detect overflows */if (realsize < size || realsize * sizeof(dictEntry*) < realsize)return DICT_ERR;/* 扩容大小和原大小一样,报错 */if (realsize == d->ht[0].size) return DICT_ERR;/* 重置hash表的大小和掩码 */n.size = realsize;n.sizemask = realsize-1;if (malloc_failed) {n.table = ztrycalloc(realsize*sizeof(dictEntry*));*malloc_failed = n.table == NULL;if (*malloc_failed)return DICT_ERR;} else // 分配内存n.table = zcalloc(realsize*sizeof(dictEntry*));// 已使用初始化为0n.used = 0;/* 如果是第一次,直接把n赋值给ht[0]即可 */if (d->ht[0].table == NULL) {d->ht[0] = n;return DICT_OK;}/* 否则,执行rehash */d->ht[1] = n;d->rehashidx = 0; // 表示rehash进度return DICT_OK;
}
Dict在删除元素的时候,删除成功后,也需要检查是否需要重置Dict的大小,如果size大于hash表初始大小同时负载因子小于0.1,那么就对hash表进行收缩
...
if (dictDelete((dict*)o->ptr, field) == C_OK) {deleted = 1;// 删除成功后,检查是否需要重置Dict大小,如果需要就调用dictResize方法重置if (htNeedsResize(o->ptr)) dictResize(o->ptr);
}
...// htNeedsResize方法
int htNeedsResize(dict *dict) {long long size, used;size = dictSlots(dict); // hash表大小used = dictSize(dict); // entry个数// size大于4并且 used*100/size < 10 就返回truereturn (size > DICT_HT_INITIAL_SIZE &&(used*100/size < HASHTABLE_MIN_FILL));
}// dictResize方法
int dictResize(dict *d)
{unsigned long minimal;// 正在做bgsave或者bgrewriteof或者rehash,就返回错误if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;// 获取entry数量minimal = d->ht[0].used;// 如果minimal小于4,则重置为4if (minimal < DICT_HT_INITIAL_SIZE)minimal = DICT_HT_INITIAL_SIZE;// 通过dictExpand重置hash表大小return dictExpand(d, minimal);
}
Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的
size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash
1、计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于
dict.ht[0].used + 1的2^n - 如果是收缩,则新size为第一个大于等于
dict.ht[0].used的2^n(不得小于4)
2、按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
3、设置dict.rehashidx = 0,标示开始rehash
4、将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
5、将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
6、将rehashidx赋值为-1,代表rehash结束
7、在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
Dict的rehash不是一次性完成的,因为如果Dict中包含数百万个entry,要在一次rehash中完成,可能导致主线程阻塞。因此Dict的rehash是分多次、渐进式的完成的,称为渐进式rehash,在上边第4步reshah时,按如下流程:
1、每次执行增、删、改、查操作时,都检查一下dict.rehashidx是否大于-1,如果是就将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并将rehashidx++,直到dict.ht[0]中所有数据都rehash到dict.ht[1]
2、将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
3、将rehashidx赋值为-1,代表rehash结束
4、在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
1.4 ZipList
ZipList 是一种特殊的 “双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
-
zlbytes固定4字节,记录整个压缩列表长度 -
zltail固定4字节,记录压缩列表尾节点距离压缩列表的起始地址有多少字节 -
zllen固定2字节,记录entry个数 -
zlend固定1字节,内容为0xff

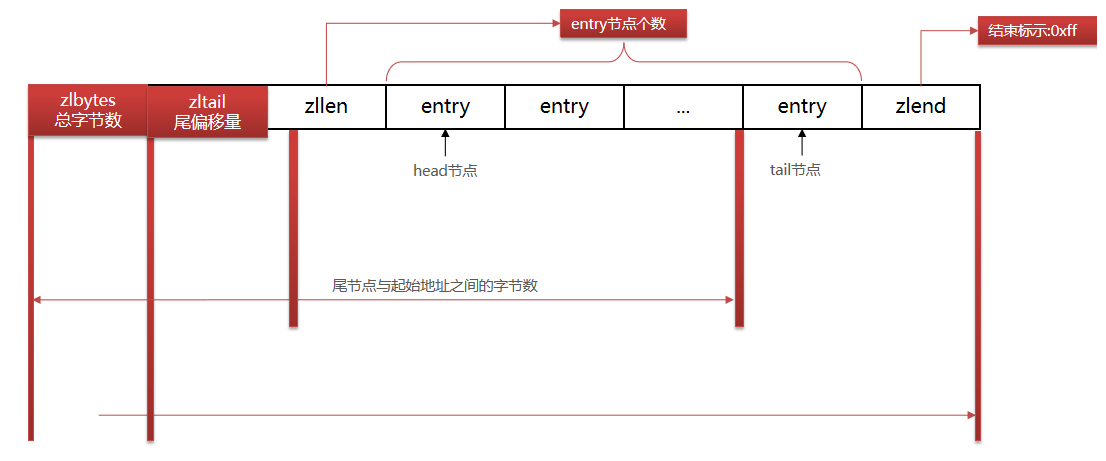
| 属性 | **类型 ** | **长度 ** | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ZipListEntry
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

previous_entry_length:前一节点的字节数,占1个或5个字节。- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe【254】,后四个字节才是真实长度数据
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节contents:负责保存节点的数据,可以是字符串或整数
previous_entry_length和encoding的长度可以确定,content长度可以根据encoding得出,因此这个entry的整体长度可以求出,知道当前这个entry的地址,就可以知道下一个entry的地址了,实现正序遍历。同时,知道当前这个entry的地址后,通过previous_entry_length知道上一个entry的长度,可以知道 上一个entry的起始地址,从而实现倒序遍历。
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。
例如:数值0x1234,采用小端字节序后实际存储值为:0x3412
Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种:
- 字符串:如果encoding是以
00、01或者10开头,则证明content是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab”和 “bc”

- 整数:如果encoding是以
11开始,则证明content是整数,且encoding固定只占用1个字节。因为整数最大是long类型,8字节,所以encoding最大记录8,一字节就够用了,因为整数就这几种类型,所以可以根通过不同编码表示不同类型整数
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整数(3 bytes) |
| 11111110 | 1 | 8位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存数值,范围从0001~1101,减1后结果为实际值 |
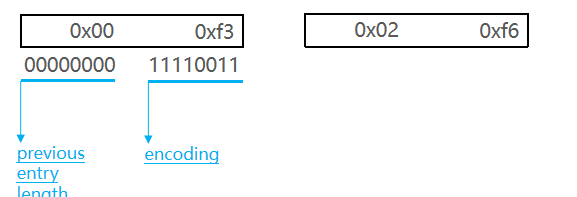
1111xxxx编码:当content中存储数字太小的时候,可以直接存储在encoding的后四位上,这样可以节省一个字节,0000-1111,由于0000和1110已经被使用,所以范围就是0001-1101,是1到13,因为是从0开始存,所以0001-1101实际存储的范围为0-12
例如,我们要保存整数:2和5,因为2和5都是小于12,所以直接通过1111xxxx的形式存储,2就存储为11110011,5存储为11110110,存储结构如下图:

1.5 ZipList的连锁更新问题
ZipList的每个Entry都通过
previous_entry_length来记录上一个节点的大小,长度是1个或5个字节
如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示

现在往头部插入了一个长度为254字节的entry,所以原来第一个entry的previous_entry_length需要使用5个字节来存储,然后这个entry的整体大小变为254字节,从而导致他的下一个entry也需要使用4字节的previous_entry_length来保存,后边都是如此,发生连锁更新问题。这样会导致每个entry都需要向后移动,如果内存不够,还会频繁申请内存,用户态和内核态频繁切换,导致性能下降,但是这种情况出现的概率很低

1.6 QuickList
1、ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。
- 为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
2、我们要存储大量数据,超出了ZipList最佳的上限该怎么办
- 可以创建多个ZipList来分片存储数据。
3、数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
- Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
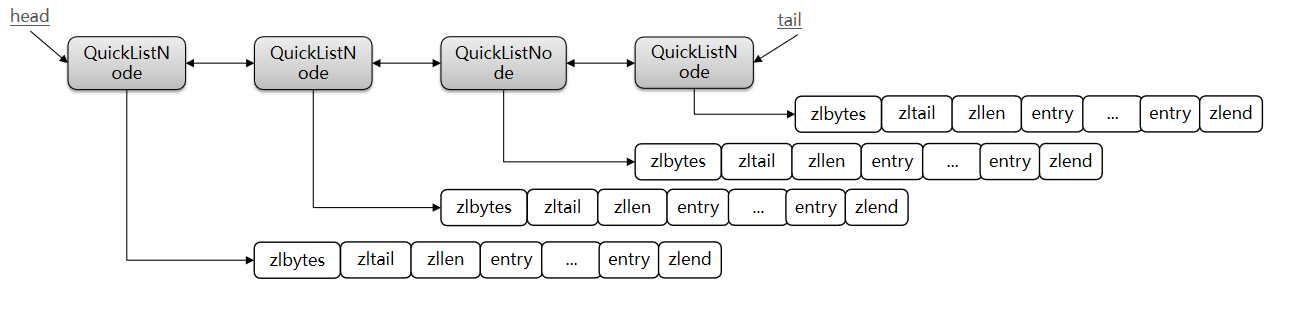
这样每个节点的ziplist内存连续,不同节点的内存是非连续的
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
-
如果值为正,则代表ZipList的允许的entry个数的最大值
-
如果值为负,则代表ZipList的最大内存大小,默认值为-2
-
-1:每个ZipList的内存占用不能超过4kb
-
-2:每个ZipList的内存占用不能超过8kb
-
-3:每个ZipList的内存占用不能超过16kb
-
-4:每个ZipList的内存占用不能超过32kb
-
-5:每个ZipList的内存占用不能超过64kb
-
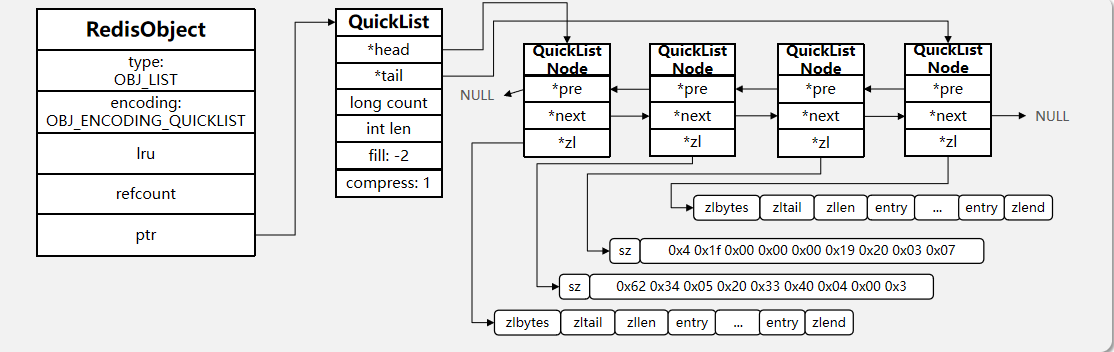
quicklist源码
typedef struct quicklist {// 头结点指针quicklistNode *head;// 尾结点指针quicklistNode *tail;// 所有zipList的entry数量unsigned long count; /* total count of all entries in all ziplists */// ziplist总数量unsigned long len; /* number of quicklistNodes */// ziplist的entry上限,默认为-2int fill : QL_FILL_BITS; /* fill factor for individual nodes */// 首位不压缩的节点个数,默认为0,全都不压缩,大于0,就表示前后有几个节点不压缩,中间的压缩unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;
quicklistNode源码
typedef struct quicklistNode {// 前一个节点指针struct quicklistNode *prev;// 后一个节点指针struct quicklistNode *next;// 当前节点ziplist的指针unsigned char *zl;// 当前节点ziplist的大小unsigned int sz; /* ziplist size in bytes */// 当前节点的ziplist的entry个数unsigned int count : 16; /* count of items in ziplist */// 编码方式:1.ziplist 2.lzf压缩模式unsigned int encoding : 2; /* RAW==1 or LZF==2 */unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */unsigned int recompress : 1; /* was this node previous compressed? */unsigned int attempted_compress : 1; /* node can't compress; too small */unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
这里compress为1,表示前后1个entry不压缩,中间的entry都压缩
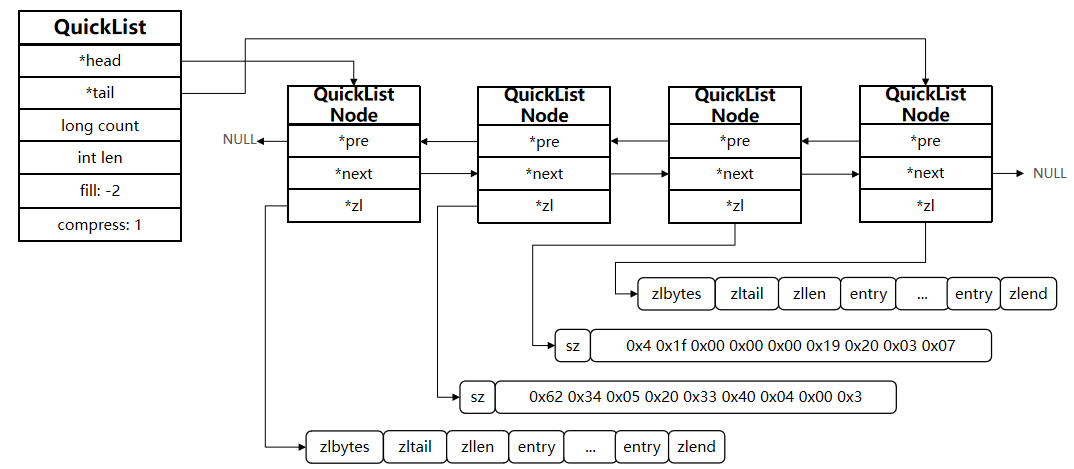
QuickList的特点
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
1.7 SkipList
skipList(跳表)首先是链表,但与传统链表相比有几点差异:
- 元素按照升序【每个元素是一个SDS字符串,是根据得分进行排序】排列存储
- 节点可能包含多个指针,指针跨度不同【这样就不用像普通链表一样,访问元素需要一个一个遍历,可以类似于二分的方式直接到中间】。
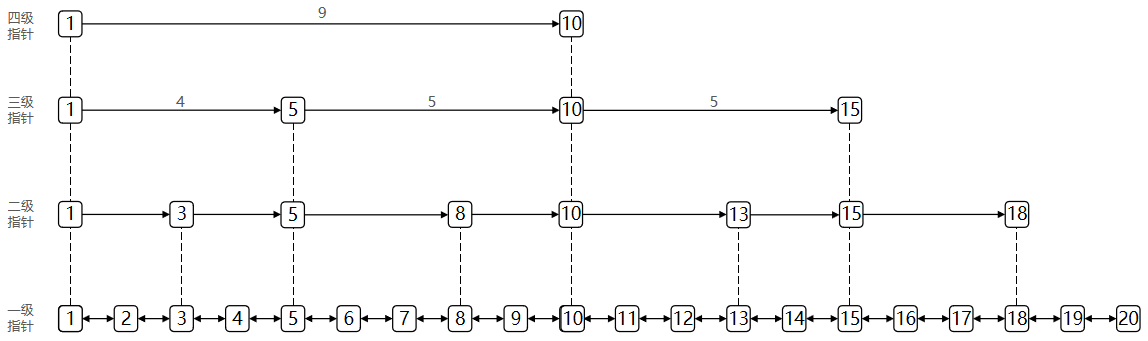
zskiplist
typedef struct zskiplist {// 头尾指针节点struct zskiplistNode *header, *tail;// 节点数量unsigned long length;// 最大索引层数,默认是1int level;
} zskiplist;
zskiplistNode
typedef struct zskiplistNode {sds ele; // 节点存储的值double score; // 节点分数,用于排序,查找struct zskiplistNode *backward; // 前一个节点指针struct zskiplistLevel {struct zskiplistNode *forward; // 下一个节点指针unsigned long span; // 索引跨度} level[]; // 多级索引数组
} zskiplistNode;
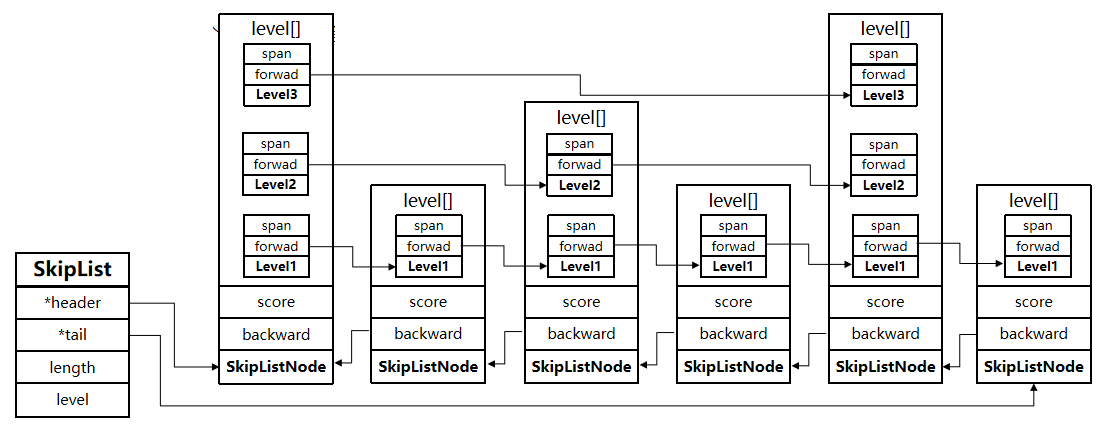
SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数【通过算法选择最佳层数】
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
1.8 RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象
RedisObject的头信息占用了16字节,如果使用string类型,一个string类型的数据就有16字节的头信息。而如果使用list这些集合结构,那么就只会有一个16字节的头信息
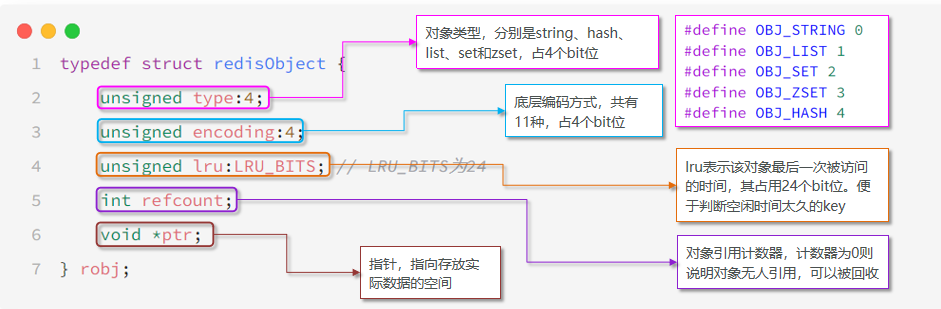
-
从Redis的使用者的角度来看,⼀个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系。这个映射关系的key是固定的string类型,⽽value可以是多种数据类型,比如:
string,list,hash,set,sorted -
从Redis内部实现的⾓度来看,database内的这个映射关系是用⼀个dict来维护的。dict的key固定用⼀种数据结构来表达就够了,这就是动态字符串sds。而value则比较复杂,为了在同⼀个dict内能够存储不同类型的value,这就需要⼀个通⽤的数据结构,这个通用的数据结构就是robj,全名是redisObject。
Redis的编码方式
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含11种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
五种数据结构
Redis中会根据存储的数据类型不同,选择不同的编码方式。基本数据类型就是这5种,像bitMap、Hyperloglog都是基本string实现的,geo是基于zset实现的
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
2、五种数据类型
2.1 String
String是Redis中最常见的数据存储类型
-
其基本编码方式是
RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。申请内存时,需要申请两次,Object头一次,SDS字符串一次 -
如果存储的SDS长度小于等于44字节,则会采用
EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。为什么是44字节?
1、因为现在字符串长度小于等于44字节,所以
len和alloc都占用1字节,flags占用1字节,结束位占用1字节,加上字符串的44字节,一共是48字节。48字节加上Object头的16字节,刚好是64字节。2、Redis底层内存分配算法使用的是
jemalloc,分配内存时会以2^n进行分配,64恰好是一个分片大小,不会产生内存碎片,因此申请一次内存就可以存储Object头和字符串的内容了 -
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
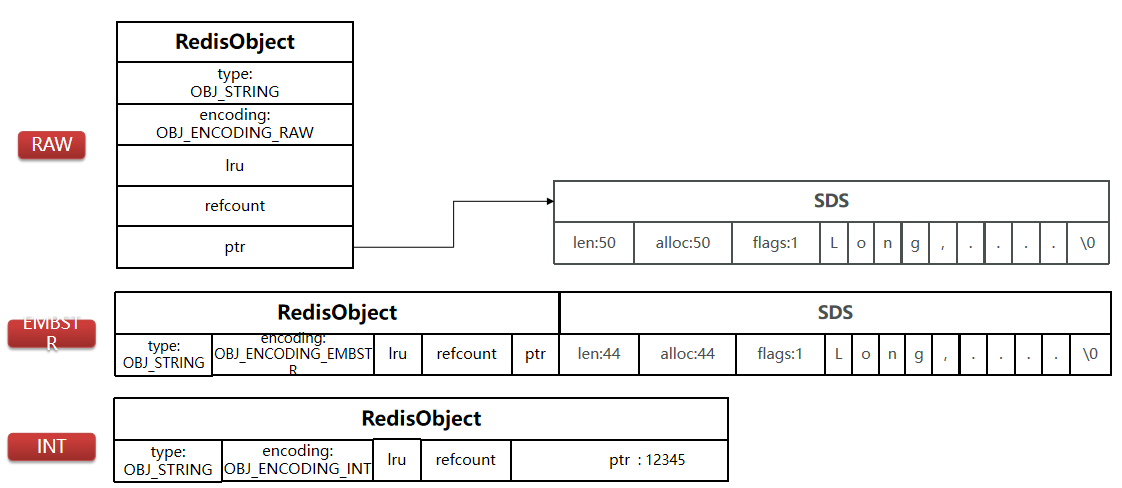
1、String在Redis中是⽤⼀个robj来表示的。用来表示String的robj可能编码成3种内部表⽰:
OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT2、其中前两种编码使⽤的是
sds来存储,最后⼀种OBJ_ENCODING_INT编码直接把string存成了long型。3、在对string进行
incr,decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作。4、对⼀个内部表示成long型的string执行
append,setbit,getrange这些命令,针对的仍然是string的值(即⼗进制表示的字符串),而不是针对内部表⽰的long型进⾏操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。⽽如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执⾏setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。
2.2 List
Redis的List类型可以从首、尾操作列表中的元素
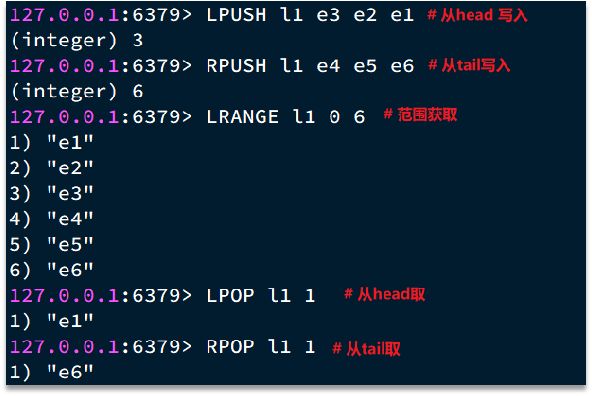
LinkedList:普通链表,可以从双端访问,内存占用较高【指针占用内存】,内存碎片较多ZipList:压缩列表,可以从双端访问,内存占用低,存储上限低QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List
源码分析
执行lpush或者rpush命令后,都是执行pushGenericCommand命令,只不过插入位置不同
void lpushCommand(client *c) {pushGenericCommand(c,LIST_HEAD,0);
}void rpushCommand(client *c) {pushGenericCommand(c,LIST_TAIL,0);
}
pushGenericCommand函数
/*xx为true表示只有当前这个list存在,才会push,否则不会push,xx为false,插入时list不存在会自动创建redis的客户端和服务端建立连接后都会被封装为一个client对象,包含客户端的各种信息,包括客户端要执行的命令
*/
void pushGenericCommand(client *c, int where, int xx) {int j;// lpush key v1 v2 v3// j=2,就是从v1开始,遍历插入的元素,判断元素大小是否超过LIST_MAX_ITEM_SIZE(1<<32 -1024)for (j = 2; j < c->argc; j++) {if (sdslen(c->argv[j]->ptr) > LIST_MAX_ITEM_SIZE) {addReplyError(c, "Element too large");return;}}// 找到key对应的list,c->db表示客户端使用的是哪个数据库,c->argv[1]就是key,根据key找value,value就是List,封装为robjrobj *lobj = lookupKeyWrite(c->db, c->argv[1]);// 检查类型是否正确if (checkType(c,lobj,OBJ_LIST)) return;// 检测是否为空if (!lobj) {// 如果list为空,同时xx为true就不能插入if (xx) {addReply(c, shared.czero);return;}// 否则创建Quicklistlobj = createQuicklistObject();/*对Quicklist做一些限制server.list_max_ziplist_size表示每个ziplist的大小,默认-2,即8kbserver.list_compress_depth表示头尾不压缩的个数,默认为0,不压缩*/ quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,server.list_compress_depth);// 将key对应的value设置为创建的QuicklistdbAdd(c->db,c->argv[1],lobj);}// 将所有的value插入Quicklistfor (j = 2; j < c->argc; j++) {listTypePush(lobj,c->argv[j],where);server.dirty++;}addReplyLongLong(c, listTypeLength(lobj));char *event = (where == LIST_HEAD) ? "lpush" : "rpush";signalModifiedKey(c,c->db,c->argv[1]);notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}robj *createQuicklistObject(void) {// 申请内存并初始化quicklistquicklist *l = quicklistCreate();// 创建RedisObject,type为OBJ_LIST,ptr指向quicklistrobj *o = createObject(OBJ_LIST,l);// 设置编码为QUICKLISTo->encoding = OBJ_ENCODING_QUICKLIST;return o;
}int checkType(client *c, robj *o, int type) {/* A NULL is considered an empty key */if (o && o->type != type) {addReplyErrorObject(c,shared.wrongtypeerr);return 1;}return 0;
}
2.3 Set
Set是Redis中的单列集合
- 不保证有序性
- 保证元素唯一
- 求交集、并集、差集
Set集合在添加元素时需要判断元素是否存在,对查询元素的效率要求非常高,因此使用Dict结构。
- Dict中的key用来存储元素,value统一为null。
- 当存储的所有数据都是整数,并且元素数量不超过
set-max-intset-entries【默认512,可以在服务端设置】时,Set会采用IntSet编码,以节省内存
源码分析
1、创建Set集合
robj *setTypeCreate(sds value) {// 判断添加元素的类型,如果是long,就创建INTSETif (isSdsRepresentableAsLongLong(value,NULL) == C_OK)return createIntsetObject();// 否则创建Setreturn createSetObject();
}// 创建INTSET
robj *createIntsetObject(void) {intset *is = intsetNew();robj *o = createObject(OBJ_SET,is);o->encoding = OBJ_ENCODING_INTSET;return o;
}//创建Set
robj *createSetObject(void) {dict *d = dictCreate(&setDictType,NULL);robj *o = createObject(OBJ_SET,d);o->encoding = OBJ_ENCODING_HT;return o;
}
2、添加元素
- 如果当前是HT类型,那么元素直接添加进去
- 如果当前是
INTSET- 当前元素为long类型,直接添加进去,如果元素数量超过
set_max_intset_entries【默认512】,就转为HT类型 - 否则,将
INTSET转为HT结构,然后添加元素
- 当前元素为long类型,直接添加进去,如果元素数量超过
int setTypeAdd(robj *subject, sds value) {long long llval;if (subject->encoding == OBJ_ENCODING_HT) { // 已经是HT结构,直接添加元素dict *ht = subject->ptr;dictEntry *de = dictAddRaw(ht,value,NULL);if (de) {dictSetKey(ht,de,sdsdup(value));dictSetVal(ht,de,NULL);return 1;}} else if (subject->encoding == OBJ_ENCODING_INTSET) { // INTSET结构// 判断value是否是longif (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {uint8_t success = 0;// 是整数,直接添加元素到setsubject->ptr = intsetAdd(subject->ptr,llval,&success);if (success) {/* Convert to regular set when the intset contains* too many entries. */// 当元素数量超出set_max_intset_entries,转为HTsize_t max_entries = server.set_max_intset_entries;/* limit to 1G entries due to intset internals. */if (max_entries >= 1<<30) max_entries = 1<<30;if (intsetLen(subject->ptr) > max_entries)setTypeConvert(subject,OBJ_ENCODING_HT);return 1;}// vlaue不是long类型,将INSET结构转为HT结构} else {/* Failed to get integer from object, convert to regular set. */setTypeConvert(subject,OBJ_ENCODING_HT);/* The set *was* an intset and this value is not integer* encodable, so dictAdd should always work. */serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);return 1;}} else {serverPanic("Unknown set encoding");}return 0;
}// 添加元素,key就是插入的元素
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{long index;dictEntry *entry;dictht *ht;if (dictIsRehashing(d)) _dictRehashStep(d);/* Get the index of the new element, or -1 if* the element already exists. */// 找到key应该插入的位置,如果key已经存在,就返回-1退出if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)return NULL;// 如果正在rehash,就添加到ht[1],否则添加到ht[0]ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];// 创建entryentry = zmalloc(sizeof(*entry));// 头插法entry->next = ht->table[index];ht->table[index] = entry;ht->used++;/* Set the hash entry fields. */dictSetKey(d, entry, key);return entry;
}
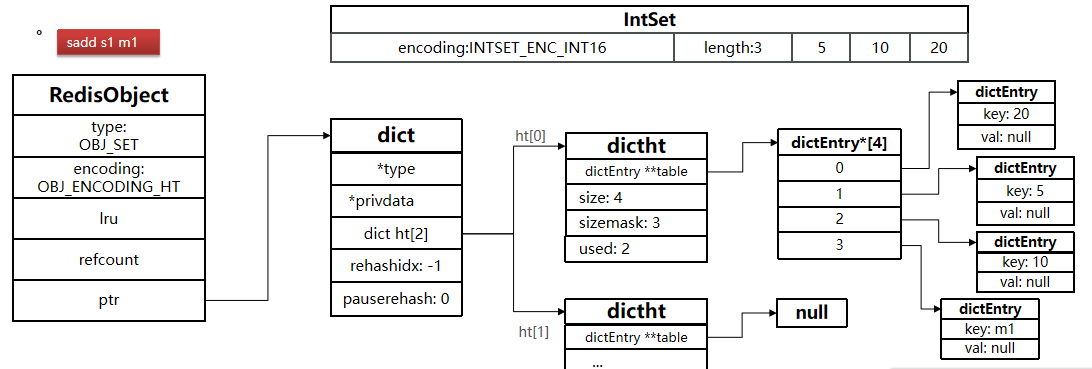
初始为
INTSET,执行sadd s1 m1后,将INTSET转为HT
2.4 ZSET
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值
- 可以根据score值排序
- member必须唯一
- 可以根据member查询分数

因此,ZSET底层数据结构必须满足键值存储、键唯一、可排序这几个需求。
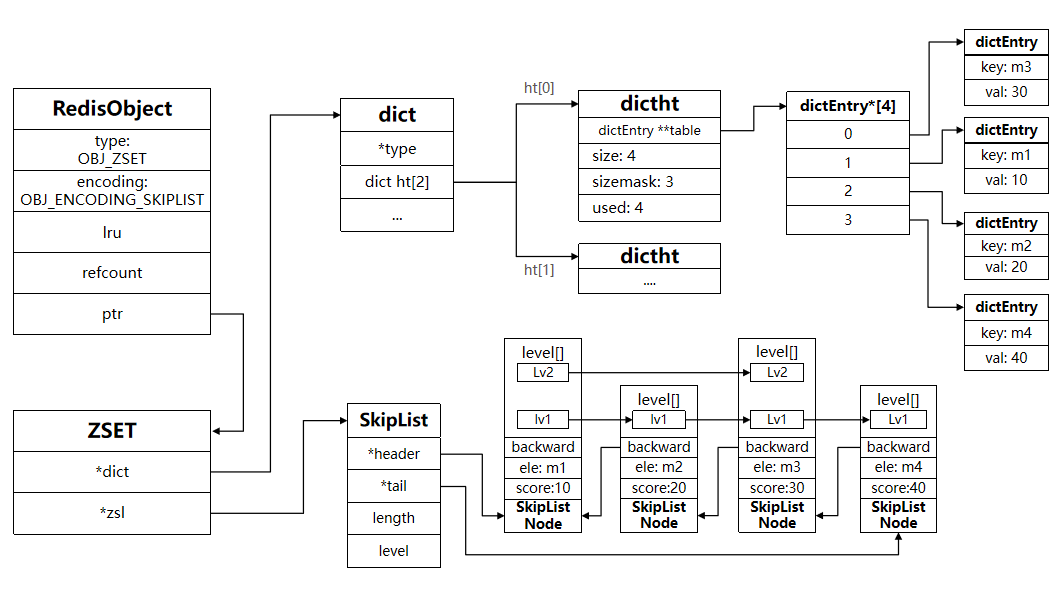
SkipList:可以排序,并且可以同时存储score和ele值(member)HT(Dict):可以键值存储,并且可以根据key找value
所以ZSET底层采用的是SkipList和Dict结合的方式实现,不过缺点是内存占用大,一份数据存了两次,属于空间换时间
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于
zset_max_ziplist_entries,默认值128 - 每个元素都小于
zset_max_ziplist_value字节,默认值64
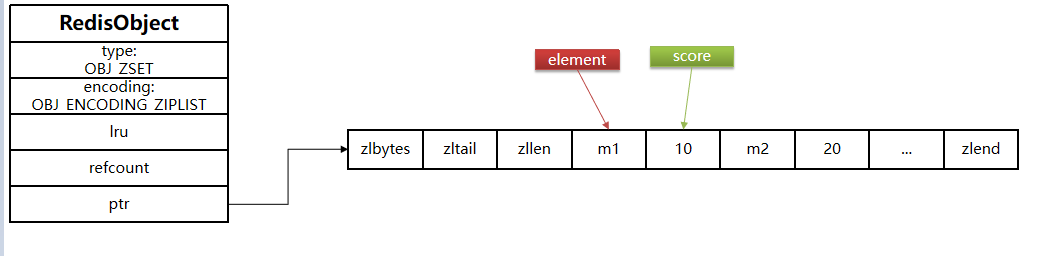
ziplist本身没有排序功能,而且没有键值对的概念,因此需要由zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
源码分析
1、zset结构
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
2、创建zset
- 通过key找value,如果value不存在
- 如果
zset_max_ziplist_entries为0或者zset_max_ziplist_value小于添加元素的大小,就创建zset - 否则创建
ziplist
- 如果
void zaddGenericCommand(client *c, int flags) {...robj *key = c->argv[1];robj *zobj;// zadd添加元素时,先根据key找到zsetzobj = lookupKeyWrite(c->db,key);if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;// 如果zset不存在,就创建if (zobj == NULL) {if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */// 如果zset_max_ziplist_entries为0,表示不会创建ziplist,如果当前添加元素的大小大于zset_max_ziplist_value,那么就创建zsetif (server.zset_max_ziplist_entries == 0 ||server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)){zobj = createZsetObject();} else { // 否则创建ziplistzobj = createZsetZiplistObject();}dbAdd(c->db,key,zobj);}...
}// 创建zset
robj *createZsetObject(void) {zset *zs = zmalloc(sizeof(*zs));robj *o;zs->dict = dictCreate(&zsetDictType,NULL);zs->zsl = zslCreate();o = createObject(OBJ_ZSET,zs);o->encoding = OBJ_ENCODING_SKIPLIST;return o;
}// 创建ziplist
robj *createZsetZiplistObject(void) {unsigned char *zl = ziplistNew();robj *o = createObject(OBJ_ZSET,zl);o->encoding = OBJ_ENCODING_ZIPLIST;return o;
}
3、添加元素
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) {// 如果当前是ZIPLIST类型if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {unsigned char *eptr;// 判断当前元素是否存在,如果存在,直接更新score值即可if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {/* NX? Return, same element already exists. */if (nx) {*out_flags |= ZADD_OUT_NOP;return 1;}/* Prepare the score for the increment if needed. */if (incr) {score += curscore;if (isnan(score)) {*out_flags |= ZADD_OUT_NAN;return 0;}}/* GT/LT? Only update if score is greater/less than current. */if ((lt && score >= curscore) || (gt && score <= curscore)) {*out_flags |= ZADD_OUT_NOP;return 1;}if (newscore) *newscore = score;/* Remove and re-insert when score changed. */if (score != curscore) {zobj->ptr = zzlDelete(zobj->ptr,eptr);zobj->ptr = zzlInsert(zobj->ptr,ele,score);*out_flags |= ZADD_OUT_UPDATED;}return 1;// 当前元素不存在} else if (!xx) {// 添加元素后,元素数量如果大于server.zset_max_ziplist_entries 或者 当前元素大小大于 server.zset_max_ziplist_value// 或者元素总大小超过阈值,就将ziplist转为Dict+Skiplist的结构if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries ||sdslen(ele) > server.zset_max_ziplist_value ||!ziplistSafeToAdd(zobj->ptr, sdslen(ele))){zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);} else { // 否则添加元素zobj->ptr = zzlInsert(zobj->ptr,ele,score);if (newscore) *newscore = score;*out_flags |= ZADD_OUT_ADDED;return 1;}} else {*out_flags |= ZADD_OUT_NOP;return 1;}}// 当前编码为SKIPLIST,无需转换if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {zset *zs = zobj->ptr;zskiplistNode *znode;dictEntry *de;de = dictFind(zs->dict,ele);if (de != NULL) {/* NX? Return, same element already exists. */if (nx) {*out_flags |= ZADD_OUT_NOP;return 1;}curscore = *(double*)dictGetVal(de);/* Prepare the score for the increment if needed. */if (incr) {score += curscore;if (isnan(score)) {*out_flags |= ZADD_OUT_NAN;return 0;}}/* GT/LT? Only update if score is greater/less than current. */if ((lt && score >= curscore) || (gt && score <= curscore)) {*out_flags |= ZADD_OUT_NOP;return 1;}if (newscore) *newscore = score;/* Remove and re-insert when score changes. */if (score != curscore) {znode = zslUpdateScore(zs->zsl,curscore,ele,score);/* Note that we did not removed the original element from* the hash table representing the sorted set, so we just* update the score. */dictGetVal(de) = &znode->score; /* Update score ptr. */*out_flags |= ZADD_OUT_UPDATED;}return 1;} else if (!xx) {ele = sdsdup(ele);znode = zslInsert(zs->zsl,score,ele);serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);*out_flags |= ZADD_OUT_ADDED;if (newscore) *newscore = score;return 1;} else {*out_flags |= ZADD_OUT_NOP;return 1;}} else {serverPanic("Unknown sorted set encoding");}return 0; /* Never reached. */
}
2.5 Hash
Hash结构与Redis中的Zset非常类似
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash则无需排序
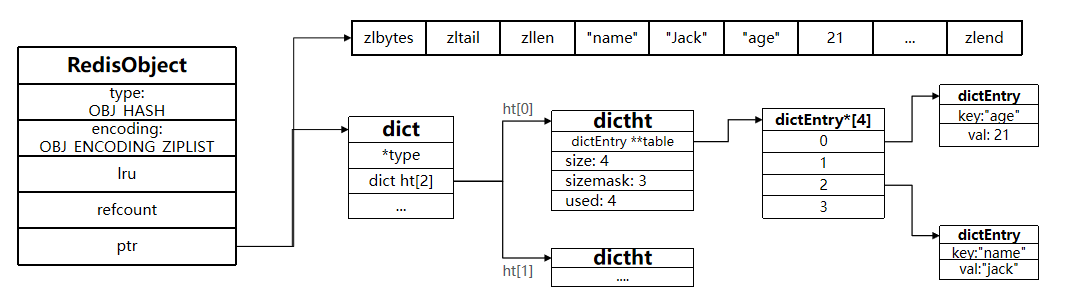
由于hash结构不需要排序,默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
- 当Hash中数据满足以下条件,使用ziplist进⾏存储数据,否则使用Dict
- 元素数量小于
hash-max-ziplist-entries,默认值512 - 每个元素都小于
hash-max-ziplist-value字节,默认值64
- 元素数量小于
Redis的hash之所以这样设计,是因为当ziplist变得很⼤的时候,它有如下几个缺点:
- 每次插⼊或修改引发的realloc操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当ziplist数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存realloc,可能导致内存拷贝。
源码分析
void hsetCommand(client *c) {int i, created = 0;robj *o;if ((c->argc % 2) == 1) {addReplyErrorFormat(c,"wrong number of arguments for '%s' command",c->cmd->name);return;}// hset user name xrj age 20,argv[1]就是user,通过key判断hash结构是否存在,不存在就创建一个新的,默认采用ZipList编码if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;// 判断是否需要把ziplist转为DicthashTypeTryConversion(o,c->argv,2,c->argc-1);// 遍历每一对field和value,执行hset命令for (i = 2; i < c->argc; i += 2)created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);/* HMSET (deprecated) and HSET return value is different. */char *cmdname = c->argv[0]->ptr;if (cmdname[1] == 's' || cmdname[1] == 'S') {/* HSET */addReplyLongLong(c, created);} else {/* HMSET */addReply(c, shared.ok);}signalModifiedKey(c,c->db,c->argv[1]);notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);server.dirty += (c->argc - 2)/2;
}robj *hashTypeLookupWriteOrCreate(client *c, robj *key) {// 通过key查找robjrobj *o = lookupKeyWrite(c->db,key);if (checkType(c,o,OBJ_HASH)) return NULL;// 不存在就创建if (o == NULL) {o = createHashObject();dbAdd(c->db,key,o);}return o;
}
robj *createHashObject(void) {// 默认采用ziplist编码unsigned char *zl = ziplistNew();robj *o = createObject(OBJ_HASH, zl);o->encoding = OBJ_ENCODING_ZIPLIST;return o;
}void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {int i;size_t sum = 0;// 本身就不是ziplist编码,直接退出if (o->encoding != OBJ_ENCODING_ZIPLIST) return;// 遍历插入的field和valuefor (i = start; i <= end; i++) {// 如果不是sds类型,跳过if (!sdsEncodedObject(argv[i]))continue;size_t len = sdslen(argv[i]->ptr);// 如果field或者value的长度大于hash_max_ziplist_value,就转为HTif (len > server.hash_max_ziplist_value) {hashTypeConvert(o, OBJ_ENCODING_HT);return;}sum += len;}// 如果总大小大于1G,也转为HTif (!ziplistSafeToAdd(o->ptr, sum))hashTypeConvert(o, OBJ_ENCODING_HT);
}
int hashTypeSet(robj *o, sds field, sds value, int flags) {int update = 0;// 当前编码为ziplistif (o->encoding == OBJ_ENCODING_ZIPLIST) {unsigned char *zl, *fptr, *vptr;zl = o->ptr;// 查询head指针fptr = ziplistIndex(zl, ZIPLIST_HEAD);if (fptr != NULL) { // head不为空,说明ziplist不为空,查找keyfptr = ziplistFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);if (fptr != NULL) { // 如果key存在,就更新value/* Grab pointer to the value (fptr points to the field) */vptr = ziplistNext(zl, fptr);serverAssert(vptr != NULL);update = 1;/* Replace value */zl = ziplistReplace(zl, vptr, (unsigned char*)value,sdslen(value));}}// 如果key不存在,就添加进入if (!update) {/* Push new field/value pair onto the tail of the ziplist */zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),ZIPLIST_TAIL);zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),ZIPLIST_TAIL);}o->ptr = zl;/* 插入新元素,检查长度是否超出,超出就转为HT结构 */if (hashTypeLength(o) > server.hash_max_ziplist_entries)hashTypeConvert(o, OBJ_ENCODING_HT);// 当前编码为HT,直接插入即可} else if (o->encoding == OBJ_ENCODING_HT) {dictEntry *de = dictFind(o->ptr,field);if (de) {sdsfree(dictGetVal(de));if (flags & HASH_SET_TAKE_VALUE) {dictGetVal(de) = value;value = NULL;} else {dictGetVal(de) = sdsdup(value);}update = 1;} else {sds f,v;if (flags & HASH_SET_TAKE_FIELD) {f = field;field = NULL;} else {f = sdsdup(field);}if (flags & HASH_SET_TAKE_VALUE) {v = value;value = NULL;} else {v = sdsdup(value);}dictAdd(o->ptr,f,v);}} else {serverPanic("Unknown hash encoding");}/* Free SDS strings we did not referenced elsewhere if the flags* want this function to be responsible. */if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);return update;
}
相关文章:
Redis底层数据结构的实现
文章目录 1、Redis数据结构1.1 动态字符串1.2 intset1.3 Dict1.4 ZipList1.5 ZipList的连锁更新问题1.6 QuickList1.7 SkipList1.8 RedisObject 2、五种数据类型2.1 String2.2 List2.3 Set2.4 ZSET2.5 Hash 1、Redis数据结构 1.1 动态字符串 Redis中保存的Key是字符串…...

制作excel模板,用于管理后台批量导入船舶数据
文章目录 引言I 数据有效性:基于WPS在Excel中设置下拉框选择序列内容II 数据处理:基于easyexcel工具实现导入数据的持久化2.1 自定义枚举转换器2.2 ExcelDataConvertExceptionIII 序列格式化: 基于Sublime Text 文本编辑器进行批量字符操作引言 需求: excel数据导入模板制…...

领略诗词之妙,发觉生活之美。
文章目录 引言落霞与孤鹜齐飞,秋水共长天一色。野渡无人舟自横。吹灭读书灯,一身都是月。我醉欲眠卿且去,明朝有意抱琴来。赌书消得泼茶香,当时只道是寻常。月上柳梢头,人约黄昏后。最是人间留不住,朱颜辞镜花辞树。山中何事?松花酿酒,春水煎茶。似此星辰非昨夜,为谁风…...
基于FFmpeg和SDL的音视频解码播放的实现过程与相关细节
目录 1、视频播放器原理 2、FFMPEG解码 2.1 FFMPEG库 2.2、数据类型 2.3、解码 2.3.1、接口函数 2.3.2、解码流程 3、SDL播放 3.1、接口函数 3.2、视频播放 3.3、音频播放 4、音视频的同步 4.1、获取音频的播放时间戳 4.2、获取当前视频帧时间戳 4.3、获取视…...

SSIS_SQLITE
1.安装 SQLite ODBC 驱动程序 2.添加SQLite数据源 在“用户DSN”或“系统DSN”选项卡中,点击“添加”。选择“SQLite3 ODBC Driver”,然后点击“完成”。在弹出的配置窗口中,设置数据源名称(DSN),并指定S…...

Redis 7.x 系列【27】集群原理之通信机制
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 概述2 节点和节点2.1 集群拓扑2.2 集群总线协议2.3 流言协议2.4 心跳机制2.5 节点握…...
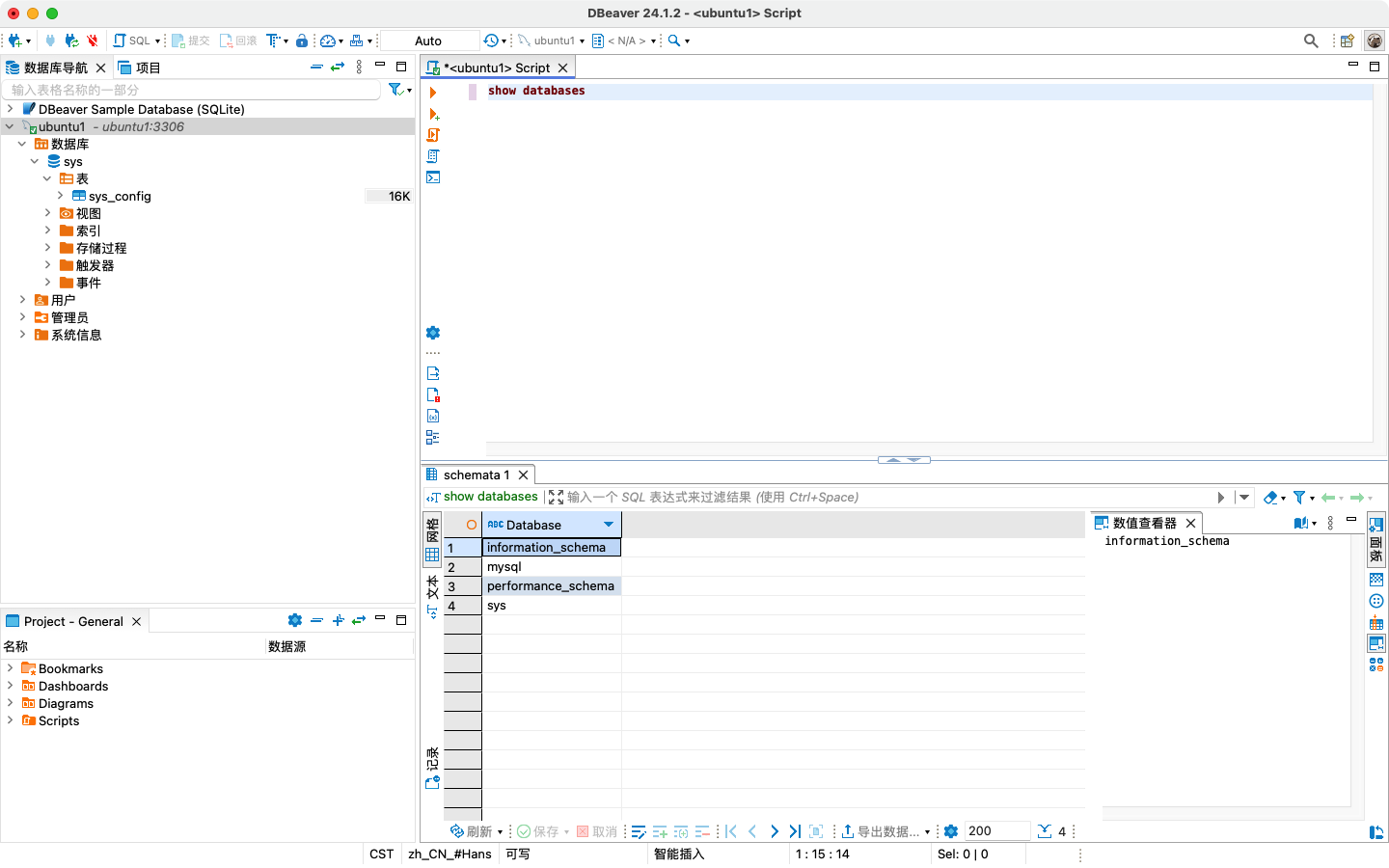
【五】MySql8基于m2芯片arm架构Ubuntu24虚拟机安装
文章目录 1. 更新系统包列表2. 安装 MySQL APT Repository3. 更新系统包列表4. 安装 MySQL Server5. 运行安全安装脚本6. 验证 MySQL 安装7. 配置远程连接7.1 首先要确认 MySQL 配置允许远程连接:7.2 重启 MySQL 服务:7.3 检查 MySQL 用户权限࿱…...

【Hot100】LeetCode—279. 完全平方数
目录 题目1- 思路2- 实现⭐完全平方数——题解思路 3- ACM 实现 题目 原题连接:279. 完全平方数 1- 思路 思路 动规五部曲 2- 实现 ⭐完全平方数——题解思路 class Solution {public int numSquares(int n) {// 1. 定义 dpint[] dp new int[n1];//2. 递推公式…...

腾讯云开发者《中国数据库前世今生》有奖创作季
在数字化潮流席卷全球的今天,数据库作为IT技术领域的“活化石”,已成为数字经济时代不可或缺的基础设施。那么,中国的数据库技术发展经历了怎样的历程?我们是如何在信息技术的洪流中逐步建立起自己的数据管理帝国的呢?…...

redis:清除缓存的最简单命令示例
清除redis缓存命令(执行命令列表见截图) 1.打开cmd窗口,并cd进入redis所在目录 2.登录redis redis-cli 3.查询指定队列当前的记录数 llen 队列名称 4.清除指定队列所有记录 ltrim 队列名称 1 0 5.再次查询,确认队列的记录数是否已清除...

基于深度学习算法,支持再学习功能,不断提升系统精准度的智慧地产开源了。
智慧地产视觉监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。通过计算机视觉和…...

Cmake生成的Xcode工程相对路径与绝对路径的问题
Cmake生成的Xcode工程相对路径与绝对路径的问题 文章目录 Cmake生成的Xcode工程相对路径与绝对路径的问题前言修改.pbxproj文件验证工程小结 前言 由于Cmake的跨平台的自动化构建的方便性以及他广泛应用于编译过程的管理,在开发过程中难免用到Cmake。我也使用Cmake…...

“机器说人话”-AI 时代的物联网
万物互联的物联网愿景已经提了许多年了,但是实际效果并不理想,除了某些厂商自己的产品生态中的产品实现了互联之外,就连手机控制空调,电视机和调光灯都没有实现。感觉小米做的好一点,而华为的鸿蒙的全场景,…...
 关键字))
C#高级:数据库中使用SQL作分组处理3(ROW_NUMBER() 关键字)
一、分组后找出指定序号的数据 【需求】查出每个班级第三个注册入学的学生信息 【表和字段】Student: ID Class Name Registrationtime 【实现SQL】 WITH RankedStudents AS (SELECT ID,Class,Name,Registrationtime,ROW_NUMBER() OVER(PARTITION BY Class ORDER BY Registra…...

光明乳业:以科技赋能品质,引领乳业绿色新未来
近日,光明乳业再次成为行业焦点,其在科技创新与绿色发展方面的卓越表现赢得了广泛赞誉。作为中国乳制品行业的领军企业,光明乳业始终坚守品质至上的原则,不断探索科技创新之路,致力于为消费者提供更高品质、更健康的乳…...
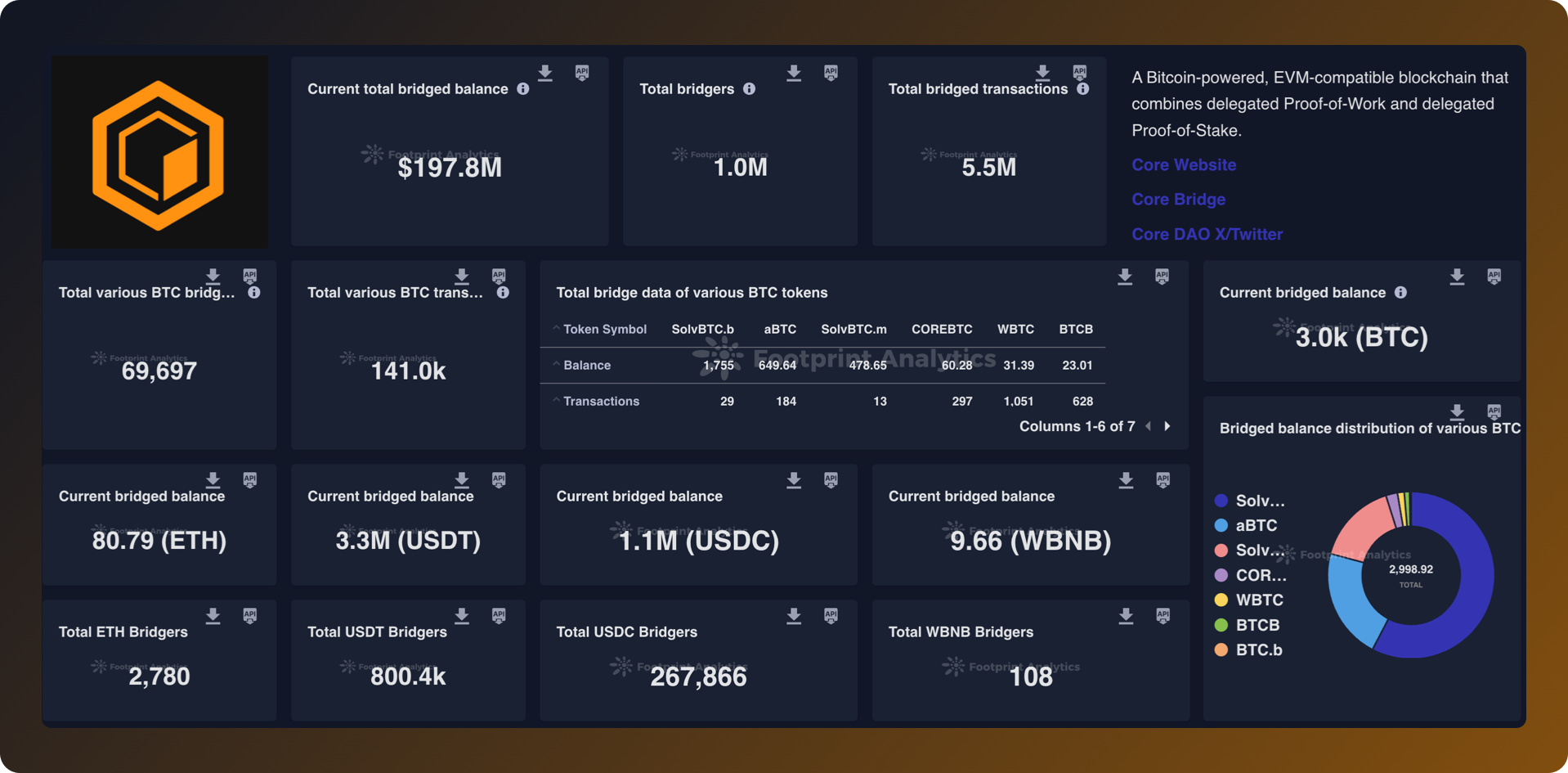
Footprint Analytics 助力 Core 区块链实现数据效率突破
Core 是一个基于比特币并兼容 EVM 的 Layer 1 区块链,正通过其创新解决方案引革新特币金融。作为首个引入非托管 BTC 质押协议及全球首个发行收益型 BTC ETP 产品的区块链,Core 站在了区块链技术的最前沿。通过利用超过 50% 的比特币挖矿哈希算力&#x…...

从零搭建pytorch模型教程(八)实践部分(二)目标检测数据集格式转换
前言 图像目标检测领域有一个非常著名的数据集叫做COCO,基本上现在在目标检测领域发论文,COCO是不可能绕过的Benchmark。因此许多的开源目标检测算法框架都会支持解析COCO数据集格式。通过将其他数据集格式转换成COCO格式可以无痛的使用这些开源框架来训…...
 高级查询)
MYSQL(2) 高级查询
文章目录 概述高级查询基础查询条件查询范围查询判空查询模糊查询分页查询查询后排序分组查询 小结 概述 接上篇,上篇写到增删改查。这篇继续。 高级查询 基础查询 -- 全部查询 select * from student; -- 只查询部分字段 select sname, class_id from student;…...

小程序的运营方法:从入门到精通
随着科技的快速发展,小程序已成为我们日常生活和工作中不可或缺的一部分。小程序无需下载安装,即用即走的特点深受用户喜爱。那么,如何运营好一个小程序呢?下面就为大家分享一些小程序的运营方法。 一、明确目标用户 在运营小程序…...

【优秀python算法毕设】基于python时间序列模型分析气温变化趋势的设计与实现
1 绪论 1.1 研究背景与意义 在气候变化日益受到全球关注的背景下,天气气温的变化已经对人们的生活各方面都产生了影响,人们在外出时大多都会在手机上看看天气如何,根据天气的变化来决定衣物的穿着和出行的安排。[1]如今手机能提供的信息已经…...
)
【2026年最新600套毕设项目分享】springboot基于 Web的图书借阅管理信息系统(14155)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

《ShardingSphere解读》04 配置驱动:ShardingSphere 中的配置体系是如何设计的?
ShardingSphere 提供了高度抽象的配置体系,开发者只需通过声明式配置即可定义分片规则、读写分离策略、数据脱敏规则等,而无需关心底层的复杂实现。那么,这套配置体系究竟是如何设计的?它包含了哪些核心概念?不同的配置…...

MATLAB/Simulink 下锂电池 SOC 均衡的奇妙之旅
MATLAB/Simulink仿真,蓄电池SOC均衡(锂电池) 根据微网内功率盈余,两组SOC不同的蓄电池采用分段下垂控制,随着出力的不同SOC趋于一致;同时对直流母线电压进行补偿、功率保持稳定无波动。 相对于传统的SOC均衡…...

[特殊字符] Python 自动化神器:10 分钟搞定 CSDN 批量发文
Python 异步编程完全指南 引言 你是否曾经为了发布系列博客而头疼?手动复制粘贴太麻烦了! 本文将介绍如何使用 Python 和 Playwright 实现 CSDN 自动发布。 一、什么是异步编程? 异步编程是一种编程范式,允许程序同时处理多个任务…...

Python+Uni-APP的宠物领养系统的设计与实现小程序
目录需求分析与功能规划技术选型与架构设计数据库设计核心功能实现接口定义示例测试与部署注意事项项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与功能规划 明确宠物领养系统的核心需求&am…...

【GitHub项目推荐--Aegis Authenticator:安全优先的开源双因素认证应用】⭐⭐⭐
Screenshots 简介 Aegis Authenticator 是由Beem Development开发并维护的开源项目,其核心使命是为Android用户提供一个免费、安全且功能完整的双因素认证(2FA)应用。在数字安全日益重要的今天,双因素认证已成为保护在线账户的…...

PiliPlus 2.0.1 | 基于Flutter开发的第三方哔哩,目前最好用的一款
PiliPlus是一款基于Flutter开发的第三方哔哩哔哩客户端,它为用户提供了无广告干扰的观影环境。该应用整合了B站的所有核心功能,包括直播、番剧、影视和分区等内容,并支持原画质播放。最新版增加了记笔记功能,优化了字幕加载速度&a…...

Java Web MVC自习室管理和预约系统系统源码-SpringBoot2+Vue3+MyBatis-Plus+MySQL8.0【含文档】
摘要 随着高校教育规模的不断扩大,自习室资源的管理和分配问题日益突出。传统的人工管理方式效率低下,容易出现资源浪费和分配不均的情况。尤其是在考试周或毕业季,学生对于自习室座位的需求激增,如何高效、公平地分配座位资源成为…...
Qwen Pixel Art实战教程:用Python requests调用API生成带透明通道的像素图标
Qwen Pixel Art实战教程:用Python requests调用API生成带透明通道的像素图标 想不想亲手打造一套风格统一、背景透明的像素风图标?无论是用于游戏开发、UI设计,还是个人项目,自己生成专属的像素图标总是充满乐趣。今天࿰…...

FireRed-OCR Studio完整指南:FireRed-OCR Studio API服务化封装与FastAPI集成
FireRed-OCR Studio完整指南:FireRed-OCR Studio API服务化封装与FastAPI集成 1. 产品概述 FireRed-OCR Studio是一款基于Qwen3-VL模型开发的工业级文档解析工具,它重新定义了文档数字化的标准。不同于传统OCR工具只能识别文字内容,FireRed…...