LangChain4j-RAG基础
RAG是什么
简而言之,RAG 是一种在将数据发送到 LLM 之前从数据中查找相关信息并将其注入到提示中的方法。这样LLM将获得(希望)相关信息,并能够使用这些信息进行回复,这应该会减少产生幻觉的可能性。
实现方法:
- 全文(关键字)搜索。该方法使用 TF-IDF 和 BM25 等技术,通过将查询中的关键字(例如,用户询问的内容)与文档数据库进行匹配来搜索文档。它根据每个文档中这些关键字的频率和相关性对结果进行排名。
- 矢量搜索,也称为“语义搜索”。使用嵌入模型将文本文档转换为数字向量。然后,它根据查询向量和文档向量之间的余弦相似度或其他相似度/距离度量来查找文档并对其进行排名,从而捕获更深层次的语义。
- 结合多种搜索方法(例如全文+向量)通常可以提高搜索的效率。
RAG的两个步骤
RAG 过程分为 2 个不同的阶段:索引(indexing) 和 检索(retrieval)。
索引(Indexing)
此过程可能会根据所使用的信息检索方法而有所不同。对于矢量搜索,这通常涉及清理文档,用额外的数据和元数据丰富它们,将它们分成更小的片段(也称为分块),嵌入这些片段,最后将它们存储在嵌入存储(又称为矢量数据库)中。
索引阶段通常离线进行,这意味着它不需要最终用户等待其完成。例如,这可以通过 cron 定时任务来实现,该定时任务每周在周末重新索引一次公司内部文档。负责索引的代码也可以是仅处理索引任务的单独应用程序。
但是,在某些情况下,最终用户可能希望上传其自定义文档,以便 LLM 可以访问它们。在这种情况下,索引应该在线执行并成为主应用程序的一部分。
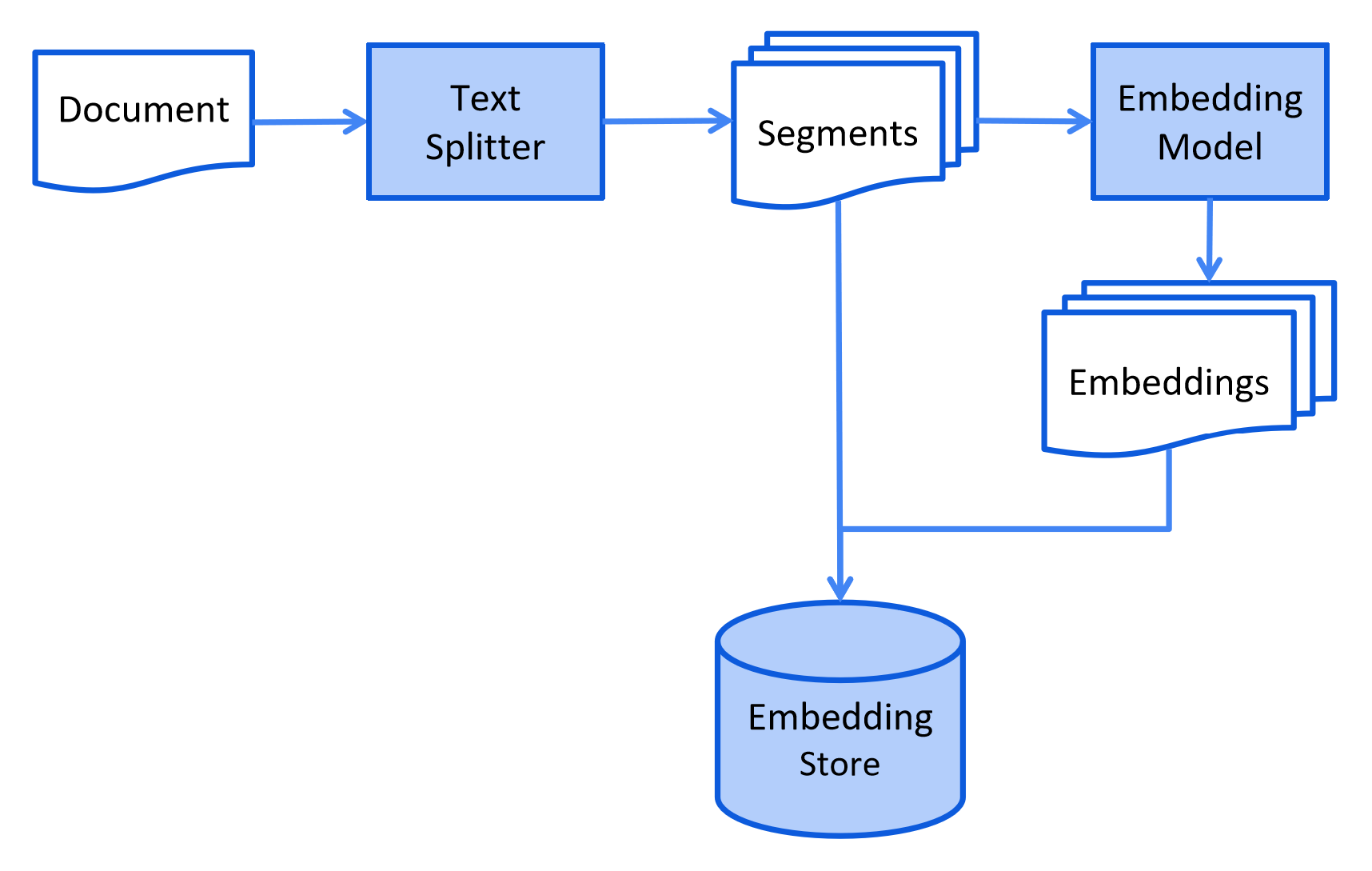
检索(Retrieval)
检索过程通常发生在用户提交文档使用索引回答用户问题时。
此过程可能会根据所使用的信息检索方法而有所不同。对于向量搜索,这通常涉及嵌入用户的查询(问题)并在嵌入存储中执行相似性搜索。然后相关片段(原始文档的片段)被注入到提示中并发送到LLM。
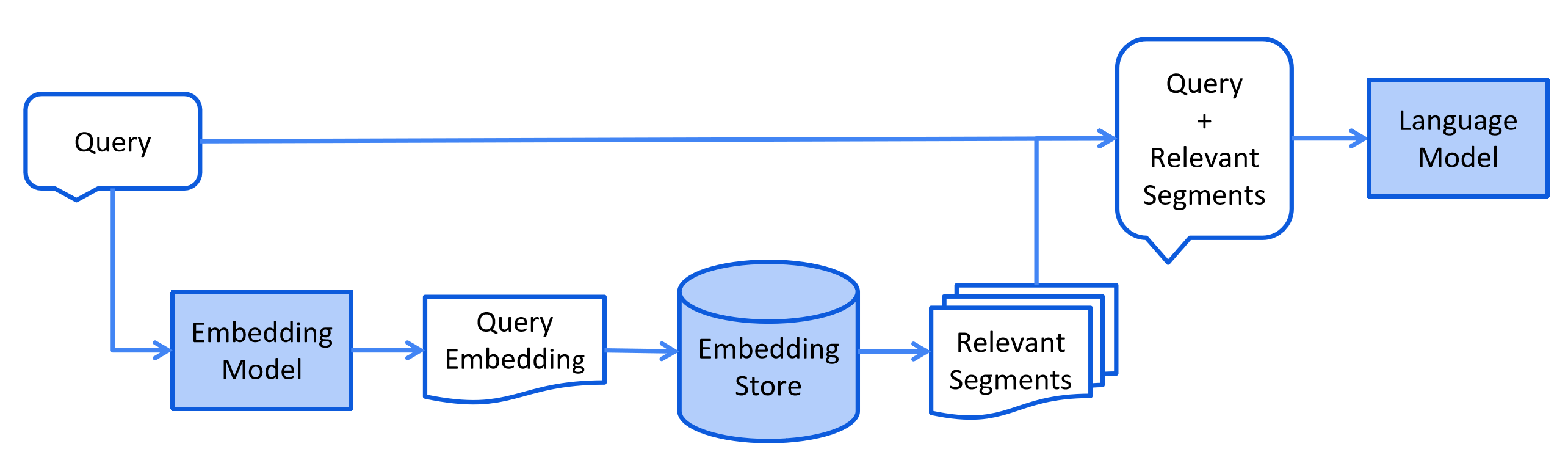
Easy RAG
LangChain4j 有一个“Easy RAG”功能,可以让 RAG 上手变得尽可能简单。不必了解嵌入、选择向量存储、找到正确的嵌入模型、弄清楚如何解析和分割文档等。只需指向您的文档,LangChain4j 就会发挥其魔力。
导入angchain4j-easy-rag依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-easy-rag</artifactId><version>0.33.0</version>
</dependency>官方示例:
public class Easy_RAG_Example {/*** This example demonstrates how to implement an "Easy RAG" (Retrieval-Augmented Generation) application.* By "easy" we mean that we won't dive into all the details about parsing, splitting, embedding, etc.* All the "magic" is hidden inside the "langchain4j-easy-rag" module.* <p>* If you want to learn how to do RAG without the "magic" of an "Easy RAG", see {@link Naive_RAG_Example}.*/public static void main(String[] args) {// First, let's load documents that we want to use for RAGList<Document> documents = loadDocuments(toPath("documents/"), glob("*.txt"));// Second, let's create an assistant that will have access to our documentsAssistant assistant = AiServices.builder(Assistant.class).chatLanguageModel(OpenAiChatModel.builder().baseUrl(OPENAI_API_URL).apiKey(OPENAI_API_KEY).build()) // it should use OpenAI LLM.chatMemory(MessageWindowChatMemory.withMaxMessages(10)) // it should remember 10 latest messages.contentRetriever(createContentRetriever(documents)) // it should have access to our documents.build();// Lastly, let's start the conversation with the assistant. We can ask questions like:// - Can I cancel my reservation?// - I had an accident, should I pay extra?startConversationWith(assistant);}private static ContentRetriever createContentRetriever(List<Document> documents) {// Here, we create and empty in-memory store for our documents and their embeddings.InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();// Here, we are ingesting our documents into the store.// Under the hood, a lot of "magic" is happening, but we can ignore it for now.EmbeddingStoreIngestor.ingest(documents, embeddingStore);// Lastly, let's create a content retriever from an embedding store.return EmbeddingStoreContentRetriever.from(embeddingStore);}
}List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");LangChain4j支持了15种向量存储的方式, 为了简单起见, 这里的Easy RAG就是用了内存存储。
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);最后一步: 创建一个AI服务来调用LLM的API
interface Assistant {String chat(String userMessage);
}Assistant assistant = AiServices.builder(Assistant.class).chatLanguageModel(OpenAiChatModel.withApiKey(OPENAI_API_KEY)).chatMemory(MessageWindowChatMemory.withMaxMessages(10)).contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore)).build();现在就可以正常聊天了
String answer = assistant.chat("How to do Easy RAG with LangChain4j?");Accessing Sources
如果想要获取访问源(检索到的 Content 用于扩充消息),您可以通过将返回类型包装在 Result 类中轻松实现:
interface Assistant {Result<String> chat(String userMessage);
}Result<String> result = assistant.chat("How to do Easy RAG with LangChain4j?");String answer = result.content();
List<Content> sources = result.sources();RAG APIs
LangChain4j 提供了一组丰富的 API,可以轻松构建自定义 RAG 管道,从简单的管道到高级的管道。
Document 文件
Document 类代表整个文档,例如单个 PDF 文件或网页。目前, Document 只能表示文本信息,但未来的更新将使其能够支持图像和表格。
使用方法:
Document.text()返回Document的文本Document.metadata()返回Document的Metadata(见下文)Document.toTextSegment()将Document转换为TextSegment(见下文), 主要是为了更好的将文档分段向量化,在上下文窗口限制比较小的时候比较适用。Text Segment 文本段Document.from(String, Metadata)从文本和Metadata创建DocumentDocument.from(String)从带有空Metadata的文本创建Document
Metadata 元数据
每个 Document 包含 Metadata 。它存储有关 Document 的元信息,例如其名称、来源、上次更新日期、所有者或任何其他相关详细信息。
Metadata 存储为键值映射,其中键为 String 类型,值可以为以下类型之一: String 、 Integer 、 Long 、 Float 、 Double 。
Metadata 很有用,有几个原因:
- 当在 LLM 的提示中包含
Document的内容时,还可以包含元数据条目,为 LLM 提供要考虑的附加信息。例如,提供Document名称和来源可以帮助提高LLM对内容的理解。 - 当搜索要包含在提示中的相关内容时,可以按
Metadata条目进行过滤。例如,您可以将语义搜索范围缩小到仅属于特定所有者的Document。 - 当 Document 的来源更新时(例如,文档的特定页面),可以通过其元数据条目(例如“id”、 “源”等)并在 EmbeddingStore 中更新它以保持同步。
这里需要结合官方的示例学习, Metadata算是一个很重要的东西, 可以按照我们想要的方式把不同的文档数据进行隔离和过滤, 这样可以实现私有知识库的隔离。会对特定的回答达到更精确的效果。
静态过滤使用示例
void Static_Metadata_Filter_Example() {// givenTextSegment dogsSegment = TextSegment.from("Article about dogs ...", metadata("animal", "dog"));TextSegment birdsSegment = TextSegment.from("Article about birds ...", metadata("animal", "bird"));EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();embeddingStore.add(embeddingModel.embed(dogsSegment).content(), dogsSegment);embeddingStore.add(embeddingModel.embed(birdsSegment).content(), birdsSegment);// embeddingStore contains segments about both dogs and birdsFilter onlyDogs = metadataKey("animal").isEqualTo("dog");ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder().embeddingStore(embeddingStore).embeddingModel(embeddingModel).filter(onlyDogs) // by specifying the static filter, we limit the search to segments only about dogs.build();Assistant assistant = AiServices.builder(Assistant.class).chatLanguageModel(chatLanguageModel).contentRetriever(contentRetriever).build();// whenString answer = assistant.answer("Which animal?");// thenassertThat(answer).containsIgnoringCase("dog").doesNotContainIgnoringCase("bird");
}按用户id动态过滤示例
interface PersonalizedAssistant {String chat(@MemoryId String userId, @dev.langchain4j.service.UserMessage String userMessage);
}@Test
void Dynamic_Metadata_Filter_Example() {// 这里就是将文本设置Meta的userId, 区分所属用户TextSegment user1Info = TextSegment.from("My favorite color is green", metadata("userId", "1"));TextSegment user2Info = TextSegment.from("My favorite color is red", metadata("userId", "2"));EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();embeddingStore.add(embeddingModel.embed(user1Info).content(), user1Info);embeddingStore.add(embeddingModel.embed(user2Info).content(), user2Info);// embeddingStore contains information about both first and second userFunction<Query, Filter> filterByUserId =(query) -> metadataKey("userId").isEqualTo(query.metadata().chatMemoryId().toString());ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder().embeddingStore(embeddingStore).embeddingModel(embeddingModel)// 动态过滤, 只检索MemoryId等于当前用户id的文档数据.dynamicFilter(filterByUserId).build();PersonalizedAssistant personalizedAssistant = AiServices.builder(PersonalizedAssistant.class).chatLanguageModel(chatLanguageModel).contentRetriever(contentRetriever).build();// whenString answer1 = personalizedAssistant.chat("1", "Which color would be best for a dress?");// thenassertThat(answer1).containsIgnoringCase("green").doesNotContainIgnoringCase("red");// whenString answer2 = personalizedAssistant.chat("2", "Which color would be best for a dress?");// thenassertThat(answer2).containsIgnoringCase("red").doesNotContainIgnoringCase("green");
}动态字段过滤实现一个简单的推荐系统
@Test
void LLM_generated_Metadata_Filter_Example() {// givenTextSegment forrestGump = TextSegment.from("Forrest Gump", metadata("genre", "drama").put("year", 1994));TextSegment groundhogDay = TextSegment.from("Groundhog Day", metadata("genre", "comedy").put("year", 1993));TextSegment dieHard = TextSegment.from("Die Hard", metadata("genre", "action").put("year", 1998));// 将元数据键描述为SQL表中的字段, 模拟sql表的结构TableDefinition tableDefinition = TableDefinition.builder().name("movies").addColumn("genre", "VARCHAR", "one of: [comedy, drama, action]").addColumn("year", "INT").build();LanguageModelSqlFilterBuilder sqlFilterBuilder = new LanguageModelSqlFilterBuilder(chatLanguageModel, tableDefinition);EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();embeddingStore.add(embeddingModel.embed(forrestGump).content(), forrestGump);embeddingStore.add(embeddingModel.embed(groundhogDay).content(), groundhogDay);embeddingStore.add(embeddingModel.embed(dieHard).content(), dieHard);ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder().embeddingStore(embeddingStore).embeddingModel(embeddingModel).dynamicFilter(query -> sqlFilterBuilder.build(query)) // LLM will generate the filter dynamically.build();Assistant assistant = AiServices.builder(Assistant.class).chatLanguageModel(chatLanguageModel).contentRetriever(contentRetriever).build();// whenString answer = assistant.answer("Recommend me a good drama from 90s");System.out.println(answer);// thenassertThat(answer).containsIgnoringCase("Forrest Gump").doesNotContainIgnoringCase("Groundhog Day").doesNotContainIgnoringCase("Die Hard");
}核心使用方法
Metadata底层实际上就是一个HashMap
Metadata.from(Map)从Map创建MetadataMetadata.put(String key, String value) / put(String, int)/等等,向Metadata添加一个条目Metadata.getString(String key) / getInteger(String key)/等等,返回Metadata条目的值,将其转换为所需的类型Metadata.containsKey(String key)检查Metadata是否包含具有指定keyMetadata.remove(String key)通过键从Metadata中删除对应键值对Metadata.copy()返回Metadata的副本Metadata.toMap()将Metadata转换为Map
Document Loader 文档加载器
可以从 String 创建 Document ,但更简单的方法是使用库中包含的文档加载器之一:
langchain4j模块下的FileSystemDocumentLoader: 根据本地文件路径加载文档langchain4j模块下的UrlDocumentLoader: 读取可以url访问下载的文档langchain4j-document-loader-amazon-s3模块下的AmazonS3DocumentLoaderlangchain4j-document-loader-azure-storage-blob模块的AzureBlobStorageDocumentLoaderlangchain4j-document-loader-github模块的GitHubDocumentLoader: 读取github上文档的工具, 可以选择仓库,分支,和文件路径langchain4j-document-loader-tencent-cos模块的TencentCosDocumentLoader: 根据腾云cos读取文档
Document Parser 文档解析器
Document 可以表示各种格式的文件,例如 PDF、DOC、TXT 等。为了解析这些格式中的每一种,库中有一个 DocumentParser 接口,其中包含多个实现:
TextDocumentParser来自langchain4j模块,它可以解析纯文本格式的文件(例如TXT、HTML、MD等)ApachePdfBoxDocumentParser来自langchain4j-document-parser-apache-pdfbox模块,可以解析PDF文件- 来自
langchain4j-document-parser-apache-poi模块的ApachePoiDocumentParser,它可以解析MS Office文件格式(例如DOC,DOCX,PPT,PPTX,XLS,XLSX等) ApacheTikaDocumentParser来自langchain4j-document-parser-apache-tika模块,可以自动检测和解析几乎所有现有的文件格式
// 加载单个文档
Document document = FileSystemDocumentLoader.loadDocument("/home/langchain4j/file.txt", new TextDocumentParser());// 加载目录下所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", new TextDocumentParser());// 加载目录下所有".txt"结尾的文档
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.txt");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j", pathMatcher, new TextDocumentParser());// 加载目录下和子目录下的所有文档
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j", new TextDocumentParser());Document Transformer 文档转换器
DocumentTransformer 实现可以执行各种文档转换,例如:
- cleaning:这涉及从
Document文本中删除不必要的噪音,这可以节省 tokens 并减少干扰。 - Filtering:从搜索中完全排除特定的
Document。(这里就可以结合前面提到的Metadata来进行条件过滤) - Enriching: 可以将附加信息添加到
Document中,以潜在地增强搜索结果。 Summarizing:Document可以被总结,它的简短总结可以存储在 Metadata 中,稍后包含在每个TextSegment中(我们将在下面介绍)以潜在地改进搜索。
官方只提供了一个实现类: HtmlTextExtractor实现了对原始HTML文件提取文本内容和Metadata元数据。
后续可能官方会有更多的实现工具,官方建议可以根据自己的需求来实现DocumentTransformer满足自己的文档解析的需求。
官方示例:
@Test
public void test() {List<Document> docs = new ArrayList<>();docs.add(Document.document("abc xyz", Metadata.metadata("lang", "en")));docs.add(Document.document("jkl 123", Metadata.metadata("lang", "en")));docs.add(Document.document("mno qrs", Metadata.metadata("lang", "fr")));List<Document> results = ((DocumentTransformer) document -> {if (document.metadata().get("lang").equals("en")) {return Document.document(document.text().toUpperCase(Locale.ROOT),document.metadata());} else {return null;}}).transformAll(docs);assertThat(results).containsOnly(Document.document("ABC XYZ", Metadata.metadata("lang", "en")),Document.document("JKL 123", Metadata.metadata("lang", "en")));
}这里就是一个实例,DocumentTransformer实现一个如果是Metadata中的lang标识为en的英文文档,则将文本内容进行大写的转换。
Text Segment 文本段
一旦 Document 被加载,就可以将它们分割(块)成更小的段(片)。 LangChain4j 的域模型包含一个 TextSegment 类,它表示 Document 的一部分。顾名思义, TextSegment 只能表示文本信息。
有时候可能只想在提示中包含几个相关部分而不是整个知识库,原因有多种:
- LLMs 的上下文窗口有限,因此整个知识库可能不适合
- 在提示中提供的信息越多,LLM 处理该信息并做出响应的时间就越长
- 提示中不相关的信息可能会分散 LLM 的注意力并增加产生幻觉的机会
- 在提示中提供的信息越多,就越难根据 LLM 响应的信息进行解释
我们可以通过将知识库分成更小、更容易理解的部分来解决这些问题。
目前有两种广泛使用的方法
- 每个文档(例如 PDF 文件、网页等)都是原子且不可分割的。在 RAG 管道中检索期间,将检索 N 个最相关的文档并将其注入到提示中。在这种情况下,您很可能需要使用长上下文 LLM,因为文档可能会很长。如果检索完整文档很重要(不能错过某些细节时),则适合使用此方法。
- 优点:不会丢失上下文。
- 缺点:
-
- 消耗更多的tokens。
- 有时,文档可以包含多个部分/主题,并且并非所有部分/主题都与查询相关。
- 矢量搜索质量会受到影响,因为各种大小的完整文档被压缩为单个固定长度的矢量。
- 文档被分成更小的部分,例如章节、段落,有时甚至是句子。在 RAG 管道中检索期间,将检索 N 个最相关的段并将其注入到提示中。挑战在于确保每个细分都为 LLM 提供足够的上下文/信息来理解它。缺少上下文可能会导致 LLM 误解给定的片段并产生幻觉。一种常见的策略是将文档分割成重叠的片段,但这并不能完全解决问题。一些先进的技术可以在这里提供帮助,例如“句子窗口检索”、“自动合并检索”和“父文档检索”。但本质上,这些方法有助于获取有关检索到的段的更多上下文,为 LLM 提供检索到的段之前和之后的附加信息。
- 优点:
-
- 更好的矢量搜索质量。
- 减少代币消耗。
- 缺点:一些上下文可能仍然丢失。
核心使用方法
TextSegment.text()返回TextSegment的文本TextSegment.metadata()返回TextSegment的MetadataTextSegment.from(String, Metadata)从文本创建TextSegment和MetadataTextSegment.from(String)从带有空Metadata的文本创建TextSegment
Document Splitter 文档分割器
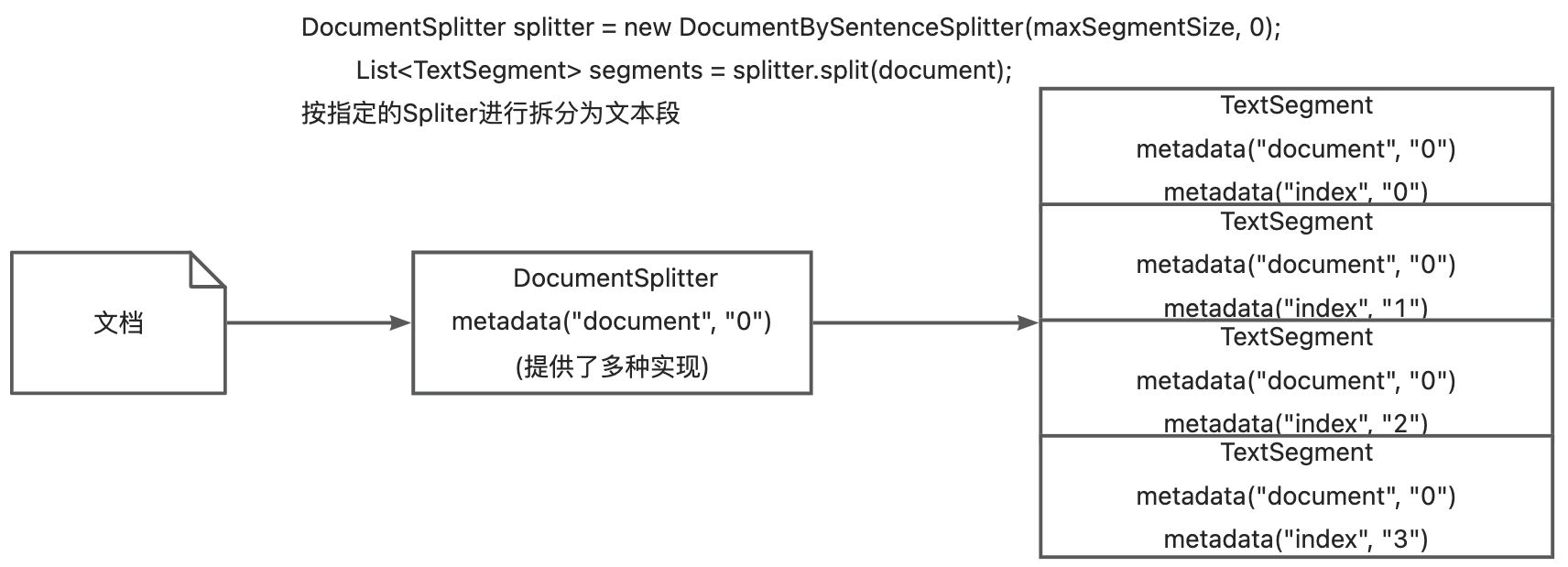
原理:
DocumentSplitter,指定TextSegment的所需大小,以及字符或tokens的重叠(可选)。- 调用
DocumentSplitter的split(Document)或splitAll(List<Document>)方法。 DocumentSplitter将给定的Document分割成更小的单元,其性质随分割器的不同而变化。例如:
-
DocumentByParagraphSplitter将文档分割为段落(由两个或多个连续换行符定义)DocumentBySentenceSplitter使用OpenNLP库的句子检测器将文档分割为句子,等等。
DocumentSplitter将这些较小的单元(段落、句子、单词等)组合成TextSegment,尝试在单个TextSegment不超过步骤 1 中设置的限制。如果某些单元仍然太大而无法放入TextSegment中,则会调用子拆分器。这是另一个能够将不适合更细化单元的单元拆分的DocumentSplitter。所有Metadata条目都从Document复制到每个TextSegment。唯一的元数据条目“索引”被添加到每个文本段。第一个TextSegment将包含index=0,第二个index=1,依此类推。
Text Segment Transformer 文本段转换器
官方只是提供了定义,仍然建议我们自行去根据业务去实现自定义的转换器。
使用场景: 一种对于提高检索效果非常有效的技术是在每个 TextSegment 中包含 Document 标题或简短摘要。
官方的使用示例:
class TextSegmentTransformerTest implements WithAssertions {public static class LowercaseFnordTransformer implements TextSegmentTransformer {@Overridepublic TextSegment transform(TextSegment segment) {//对文本进行小写转换String result = segment.text().toLowerCase();//对包含指定字符的文本段进行过滤, 可以考虑安全隐患的一些数据过滤场景if (result.contains("fnord")) {return null;}return TextSegment.from(result, segment.metadata());}}@Testpublic void test_transformAll() {TextSegmentTransformer transformer = new LowercaseFnordTransformer();TextSegment ts1 = TextSegment.from("Text");ts1.metadata().put("abc", "123"); // metadata is copied over (not transformedTextSegment ts2 = TextSegment.from("Segment");TextSegment ts3 = TextSegment.from("Fnord will be filtered out");TextSegment ts4 = TextSegment.from("Transformer");List<TextSegment> segmentList = new ArrayList<>();segmentList.add(ts1);segmentList.add(ts2);segmentList.add(ts3);segmentList.add(ts4);assertThat(transformer.transformAll(segmentList)).containsExactly(TextSegment.from("text", ts1.metadata()),TextSegment.from("segment"),TextSegment.from("transformer"));}}Embedding 嵌入
Embedding 类封装了一个数值向量,表示已嵌入内容(通常是文本,例如 TextSegment )的“语义含义”。
使用方法:
Embedding.dimension()返回嵌入向量的维度(其长度)CosineSimilarity.between(Embedding, Embedding)计算 2 个Embedding之间的余弦相似度Embedding.normalize()标准化嵌入向量
Embedding Model 嵌入模型
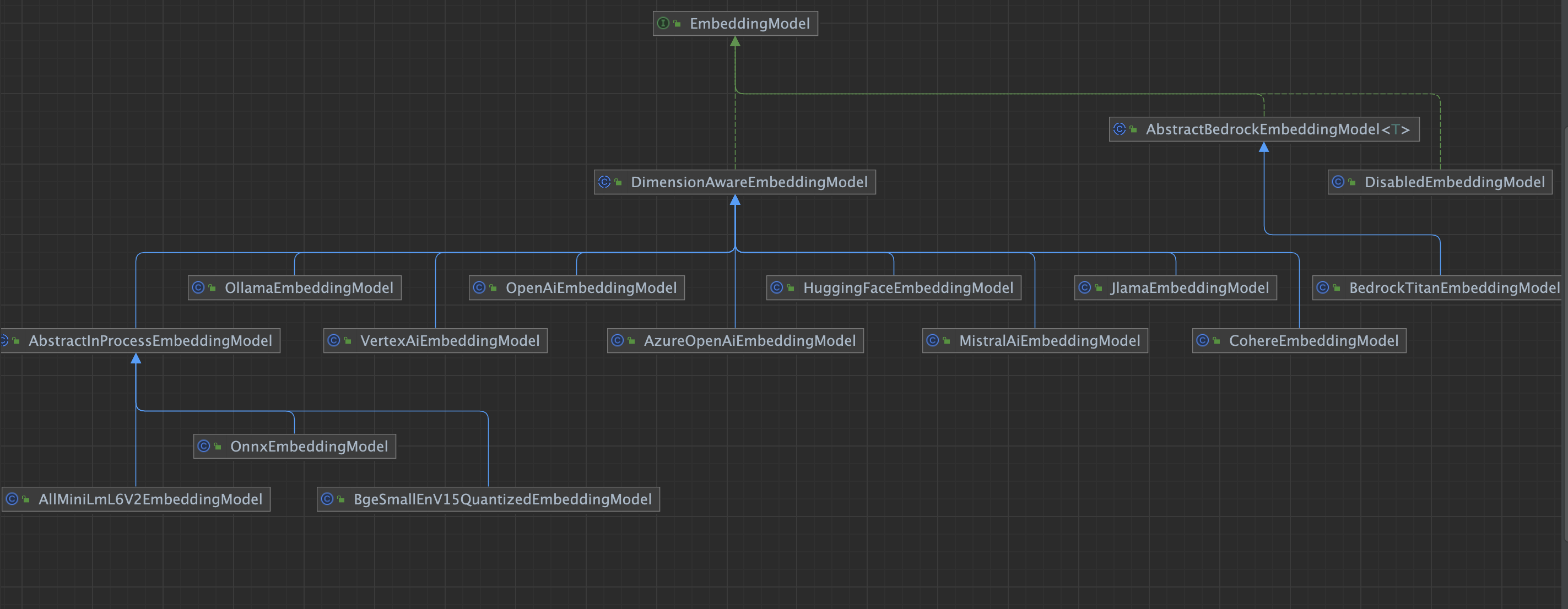
使用方法:
EmbeddingModel.embed(String)嵌入给定的文本EmbeddingModel.embed(TextSegment)嵌入给定的TextSegmentEmbeddingModel.embedAll(List<TextSegment>)嵌入所有给定的TextSegmentEmbeddingModel.dimension()返回此模型生成的Embedding的尺寸
Embedding Store 嵌入存储
EmbeddingStore 接口代表 Embedding 的存储,也称为矢量数据库。它允许存储和有效搜索相似的(在嵌入空间中接近的) Embedding 。
EmbeddingStore 可以单独存储 Embedding ,也可以与相应的 TextSegment 一起存储:
- 它只能通过 ID 存储
Embedding。原始嵌入数据可以存储在其他地方并使用 ID 进行关联。 - 它可以存储
Embedding和已嵌入的原始数据(通常是TextSegment)。
使用方法:
EmbeddingStore.add(Embedding)将给定的Embedding添加到存储并返回随机 IDEmbeddingStore.add(String id, Embedding)将具有指定 ID 的给定Embedding添加到存储中EmbeddingStore.add(Embedding, TextSegment)将给定的Embedding以及关联的TextSegment添加到存储中并返回随机 IDEmbeddingStore.addAll(List<Embedding>)将给定Embedding的列表添加到存储中并返回随机 ID 的列表EmbeddingStore.addAll(List<Embedding>, List<TextSegment>)将给定的Embedding列表以及关联的TextSegment列表添加到存储中并返回随机 ID 列表EmbeddingStore.search(EmbeddingSearchRequest)搜索最相似的EmbeddingEmbeddingStore.remove(String id)根据 ID 从存储中删除单个EmbeddingEmbeddingStore.removeAll(Collection<String> ids)通过 ID 从存储中删除多个EmbeddingEmbeddingStore.removeAll(Filter)从存储中删除与指定Filter匹配的所有EmbeddingEmbeddingStore.removeAll()从存储中删除所有Embedding
官方 ElasticsearchEmbeddingStore 的存储使用示例:
public class ElasticsearchEmbeddingStoreExample {public static void main(String[] args) throws InterruptedException {try (ElasticsearchContainer elastic = new ElasticsearchContainer("docker.elastic.co/elasticsearch/elasticsearch:8.9.0").withEnv("xpack.security.enabled", "false")) {elastic.start();EmbeddingStore<TextSegment> embeddingStore = ElasticsearchEmbeddingStore.builder().serverUrl("http://" + elastic.getHttpHostAddress()).dimension(384).build();EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();TextSegment segment1 = TextSegment.from("I like football.");Embedding embedding1 = embeddingModel.embed(segment1).content();embeddingStore.add(embedding1, segment1);TextSegment segment2 = TextSegment.from("The weather is good today.");Embedding embedding2 = embeddingModel.embed(segment2).content();embeddingStore.add(embedding2, segment2);Thread.sleep(1000); // to be sure that embeddings were persistedEmbedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.findRelevant(queryEmbedding, 1);EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);System.out.println(embeddingMatch.score()); // 0.81442887System.out.println(embeddingMatch.embedded().text()); // I like football.}}
}Embedding Store Ingestor 嵌入存储摄取器
EmbeddingStoreIngestor 表示摄取管道,负责将 Document 摄取到 EmbeddingStore 中。
在最简单的配置中, EmbeddingStoreIngestor 使用指定的 EmbeddingModel 嵌入提供的 Document ,并将它们及其 Embedding 存储在指定的 EmbeddingStore :
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder().embeddingModel(embeddingModel).embeddingStore(embeddingStore).build();ingestor.ingest(document1);
ingestor.ingest(document2, document3);
ingestor.ingest(List.of(document4, document5, document6));一般在使用 EmbeddingStoreIngestor 之前会使用 DocumentTransformer对Document 进行清理、丰富或格式化,有助于后续在向量提取的时候效果更好。
官方示例:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()// adding userId metadata entry to each Document to be able to filter by it later.documentTransformer(document -> {document.metadata().put("userId", "12345");return document;})// splitting each Document into TextSegments of 1000 tokens each, with a 200-token overlap.documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenizer()))// adding a name of the Document to each TextSegment to improve the quality of search.textSegmentTransformer(textSegment -> TextSegment.from(textSegment.metadata("file_name") + "\n" + textSegment.text(),textSegment.metadata())).embeddingModel(embeddingModel).embeddingStore(embeddingStore).build();documentTransformer: 它为每个文档添加了一个userId的元数据项,值为"12345"。这意味着无论处理多少文档,所有文档都将被标记为属于同一个用户ID。这在需要按用户过滤结果时非常有用。documentSplitter: 分割器以1000个令牌为单位进行分割,但每个片段之间会有200个令牌的重叠。这有助于确保在搜索时,即使查询文本落在片段边界附近,也能检索到相关的文本片段。textSegmentTransformer: 它将每个文本片段的原始文本与其file_name元数据项的值(文件名)相结合,中间用换行符分隔。这样做的目的是在搜索时,不仅考虑文本片段的内容,还考虑它所属的文档(或文件)的名称,这可能会提高搜索的相关性。
相关文章:
LangChain4j-RAG基础
RAG是什么 简而言之,RAG 是一种在将数据发送到 LLM 之前从数据中查找相关信息并将其注入到提示中的方法。这样LLM将获得(希望)相关信息,并能够使用这些信息进行回复,这应该会减少产生幻觉的可能性。 实现方法: 全文…...

git--本地仓库修改同步到远程仓库
尝试将本地分支推送到远程仓库时,出现一个非快速前进的错误。通常是因为远程仓库中的分支包含本地分支没有的提交。在推送之前,需要将远程仓库的更改合并到本地分支。 解决步骤如下: 切换到你的本地分支: 确保处于想要推送的分支…...

剑和沙盒 3 - 深度使用和解析Windows Sandbox
介绍 两年前,微软作为Insiders build 18305的一部分发布了一项新功能- Windows Sandbox。 该沙箱具有一些有用的规格: Windows 10(Pro/Enterprise)的集成部分。在 Hyper-V 虚拟化上运行。原始且可抛弃 – 每次运行时都干净地开…...

深度学习loss
pytorch模型训练demo代码 在PyTorch中,模型训练通常涉及几个关键步骤:定义模型、定义损失函数、选择优化器、准备数据加载器、编写训练循环。以下是一个简单的PyTorch模型训练演示代码,该代码实现了一个用于手写数字识别(使用MNIS…...

编写一个Chrome插件,网页选择文字后,右键出现菜单“search with bing”,选择菜单后用bing搜索文字
kimi ai 生成,测试可用,需要自行准备图标文件 创建一个简单的Chrome插件来实现选择文本后的搜索功能,你需要完成以下几个步骤: 创建插件的基础文件夹和文件: 创建一个文件夹用于存放插件的所有文件。在该文件夹中创建以…...

【算法】分割回文串
难度:中等 题目: 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串。返回 s 所有可能的分割方案。 示例 1: 输入:s = “aab” 输出:[[“a”,“a”,“b”],[“aa”,“b”]] 示例 2: 输入:s = “a” 输出:[[“a”]] 提示: 1 <= s.length <…...
lua 游戏架构 之 游戏 AI (三)ai_attack
这段Lua脚本定义了一个名为 ai_attack 的类,继承自 ai_base 类。 lua 游戏架构 之 游戏 AI (一)ai_base-CSDN博客文章浏览阅读119次。定义了一套接口和属性,可以基于这个基础类派生出具有特定行为的AI组件。例如,可以…...

大数据之Oracle同步Doris数据不一致问题
数据同步架构如下: 出现的问题: doris中的数据条数 源库中的数据条数 总数完全不一致。 出现问题的原因: 在Dinky中建立表结构时,缺少对主键属性的限制 primary key(ID) not enforced 加上如上语句,数据条数解决一致 …...

visual studio 问题总结
一. Visual Studio: 使用简体中文(GB2312)编码加载文件, 有些字节已用Unicode替换字符更换 解决方法:vs 工具-》选项-》文本编辑器...

go-错误码的最佳实践
一、背景 在工程开发中,我们有以下场景可以用错误码解决 我们不太方便直接将内部的错误原因暴露给外部,可以根据错误码得到对应的外部暴露消息通过设定错误码判断是客户端或者服务端的问题,避免不必要的排障浪费方便查找日志,定…...

Python面试题:使用Matplotlib和Seaborn进行数据可视化
使用Matplotlib和Seaborn进行数据可视化是数据分析中非常重要的一部分。以下示例展示了如何使用这两个库来创建各种图表,包括基本的线图、柱状图、散点图和高级的分类数据可视化图表。 安装 Matplotlib 和 Seaborn 如果你还没有安装这两个库,可以使用以…...

模拟实现c++中的vector模版
目录 一vector简述: 二vector的一些接口函数: 1初始化: 2.vector增长: 3vector增删查改: 三vector模拟实现部分主要函数: 1.size,capacity,empty,clear接口: 2.reverse的实现࿱…...

uniapp安卓通过绝对路径获取文件
uniapp安卓通过绝对路径获取文件 在uniapp中,如果你想要访问安卓设备上的文件,你需要使用uniapp提供的plus.io API。这个API允许你在应用内访问设备的文件系统。 以下是一个示例代码,展示了如何使用plus.io API来获取文件: fun…...

Known框架实战演练——进销存业务单据
本文介绍如何实现进销存管理系统的业务单据模块,业务单据模块包括采购进货单、采购退货单、销售出货单、销售退货单4个菜单页面。由于进销单据字段大同小异,因此设计共用一个页面组件类。 项目代码:JxcLite开源地址: https://git…...

解决npm依赖树冲突的方法以及npm ERR! code ERESOLVE错误的解决方案
一、问题描述 在使用ng new myapp --skip-install 构建Angular 项目后,尝试用npm install 安装依赖的时候报了以下错误。 (base) PS C:\Users\Administrator\Desktop\agtest\myapp> npm i npm ERR! code ERESOLVE npm ERR! ERESOLVE unable to resolve dependenc…...

Spring Boot + Spring Batch + Quartz 整合定时批量任务
博客主页: 南来_北往 系列专栏:Spring Boot实战 前言 最近一周,被借调到其他部门,赶一个紧急需求,需求内容如下: PC网页触发一条设备升级记录(下图),后台要定时批量设备更…...
)
C++STL简介(二)
目录 1.模拟实现string 1.string基本属性和大体框架 2.基本函数 2.1size() 2.2 [] 2.3 begin() 和end() 2.4capacity() 2.5 reserve 2.6push_back 2.7 append 2.8 2.9insert 2.10find 2.11substr 2.12 2.12 < …...
)
嵌入式高频面试题100道及参考答案(3万字长文)
目录 解释嵌入式系统的定义和主要特点 描述微处理器与微控制器的主要区别 什么是ARM体系结构?它在嵌入式系统中有哪些优势? 解释GPIO(通用输入输出)的工作原理 什么是ADC和DAC?它们在嵌入式系统中的作用是什么? 解释中断的概念及其在实时系统中的重要性 描述SPI(串…...

python爬虫-事件触发机制
今天想爬取一些政策,从政策服务 (smejs.cn) 这个网址爬取,html源码找不到链接地址,通过浏览器的开发者工具,点击以下红框 分析预览可知想要的链接地址的id有了,进行地址拼接就行 点击标头可以看到请求后端服务器的api地…...

LeetCode-day27-3106. 满足距离约束且字典序最小的字符串
LeetCode-day27-3106. 满足距离约束且字典序最小的字符串 题目描述示例示例1:示例2:示例3: 思路代码 题目描述 给你一个字符串 s 和一个整数 k 。 定义函数 distance(s1, s2) ,用于衡量两个长度为 n 的字符串 s1 和 s2 之间的距…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...