WeNet环境配置与aishell模型训练
WeNet环境配置与aishell模型训练
1环境配置
踩坑记录: 系统使用win11,我根据wenet官方文档,使用conda虚拟环境安装了cuda12.1,安装wenet依赖库,其中deepspeed报错,根据报错信息查询github,发现缺少libaio库,它通常在Linux系统上使用,根据githubu找到解决办法,重新编译了deepspeed,成功安装依赖。分析和运行wenet时发现,仍然有很多报错。随后我尝试在本机VMware+ubuntu22.04,wenet在不进行跑数据的情况下没有问题,开始数据测试后,发现VMware基于主机的显卡虚拟映射出了一个供uhuntu系统使用的显卡,这个显卡没有合适的驱动。随后查询到一个解决办法,显卡直连,尝试好几种博主的方法,均失败告终。
解决方法:已老实,求放过,使用带GPU的服务器,本文服务器使用ubuntu22.04。
1.1安装Miniconda
#下载
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py310_24.5.0-0-Linux-x86_64.sh
#安装:根据提示输入enter或yes
bash Miniconda3-py38_4.9.2-Linux-x86_64.sh
#验证:重启终端(必须),运行下方命令,显示版本号则安装成功
conda --version
1.2更换清华源
#在用户目录(/home/xxx)下新建.condarc文件
touch .condarc
#用vim打开.condarc文件,写入下方内容保存后退出
channels:- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud#清除索引缓存conda clean -i#配置完毕,执行以下命令查看是否已经换源,可以看到已经更换为清华源了conda config --show
1.3在服务器中安装CUDA
踩坑记录:在此之前,我一直尝试的是在虚拟环境中使用conda install进行安装cudatoolkit,如果你使用的cuda版本过高,则无法使用清华源(最高11.8.0),初次尝试使用的cudatoolkit-11.3.1,安装完成后,使用nvcc -v不能显示cuda版本,使用conda list不能显示cudatoolkit,使用conda list cuda可以显示,查阅博客,没有找到答案。于是忽略此条继续配置,根绝conda search cudnn查看对应版本cudnn,随之conda install cudnn=8.2.1安装完成。随后使用conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch安装成功,随后进行相关python代码验证,均失败,conda list发现没有torch。于是忽略此条继续配置,随后根据requirements.txt进行pip,出现大量不兼容情况,主要是torch版本引起的,版本过高,因为官方文档使用的是cuda12.1对应的torch>=2.1.2。我降低torch版本,使其兼容。此时再次进行python代码验证均失败。
**解决方法:**采用在base环境中安装cuda,配置环境变量,即可使用nvcc。在虚拟环境中继续后续的配置,我在base环境中安装了cuda11.3和cuda12.1,wenet代码均可运行。使用cuda11.3,安装conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch,随后使用requirements.txt进行pip时,注意torch==2.1.2和torchaudio==2.1.2版本即可(已老实,求放过,这个方法我个人认为不是很完美,但是它让我的代码成功运行了起来)
本文采用wenet官方文档推荐的CUDA12.1
其他版本的CUDA配置方法可查看:CUDA and cuDNN — k2 1.24.4 documentation (k2-fsa.github.io)
#下载CUDA12.1 官方地址:https://developer.nvidia.com/cuda-toolkit-archive
wget https://developer.nvidia.com/cuda-12-2-1-download-archive
#安装,此处采用静默模式安装,交互模式可参考:https://blog.csdn.net/qq_46699596/article/details/134552021
sh ./cuda_12.1.1_530.30.02_linux.run \--silent \--toolkit \--installpath=/s6home/lnj524/module/cuda/cuda-12.1 \--no-opengl-libs \--no-drm \--no-man-page
#./cuda_12.1.1_530.30.02_linux.run:CUDA 12.1.1 的安装程序文件。
#--silent:以静默模式安装,不需要用户交互。
#--toolkit:只安装 CUDA Toolkit,而不安装其他组件(如驱动程序等)。
#--installpath=/home/xxx/module/cuda/cuda-12.1:指定安装路径。
#--no-opengl-libs:不安装 OpenGL 库。
#--no-drm:不安装 Direct Rendering Manager(DRM)模块。DRM 模块用于图形硬件加速的直接渲染。
#--no-man-page:不安装手册页。
#添加环境变量
vim ~/.bashrc
#将下方内容写入.bashrc
export CUDA_HOME=/s6home/lnj524/module/cuda/cuda-12.1
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$CUDA_HOME/extras/CUPTI/lib64:$LD_LIBRARY_PATH
export CUDAToolkit_ROOT_DIR=$CUDA_HOME
export CUDAToolkit_ROOT=$CUDA_HOMEexport CUDA_TOOLKIT_ROOT_DIR=$CUDA_HOME
export CUDA_TOOLKIT_ROOT=$CUDA_HOME
export CUDA_BIN_PATH=$CUDA_HOME
export CUDA_PATH=$CUDA_HOME
export CUDA_INC_PATH=$CUDA_HOME/targets/x86_64-linux
export CFLAGS=-I$CUDA_HOME/targets/x86_64-linux/include:$CFLAGS
export CUDAToolkit_TARGET_DIR=$CUDA_HOME/targets/x86_64-linux
#更新用户环境
source ~/.bashrc
#验证
nvcc -V
#到此cuda安装完成
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
1.3创建虚拟环境
#创建虚拟环境
conda create -n wenet python=3.10
#启动虚拟环境
conda activate wenet
1.4在虚拟环境中完成后续安装
#安装conda-forge::sox
conda install conda-forge::sox
#查看cuda对应的cudnn版本
conda search cudnn
#下载cudnn
conda install cudann=8.9.2.26
#配置pip清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#查看pip源
pip config list
global.index-url='https://pypi.tuna.tsinghua.edu.cn/simple'
#安装torch和torchaudio,清华源中没有找个包,只能从官网下载,静静等待。
pip install torch==2.2.2+cu121 torchaudio==2.2.2+cu121 -f https://download.pytorch.org/whl/torch_stable.html
#根据requirements.txt安装其他其他依赖
pip install -r requirements.txt
#完成
1.5aishell模型训练
cd /s6home/lnj524/module/wenet/examples/aishell/s0
chmod +x run.sh
./run.sh --stage -1 #采用默认配置从数据集下载到完成模型训练。
./run.sh --stage 4 --stop_stage 4 #执行模型训练
2Wenet文件分析
2.1run.sh
-
下载数据(阶段 -1)此步骤将AIShell-1数据集下载到本地路径。这可能需要几个小时。如果已经下载了数据,请在
run.sh脚本中调整$data变量,并从阶段0开始。请确保为$data设置绝对路径,例如/home/username/asr-data/aishell/。 -
准备训练数据(阶段 0)将原始的AIShell-1数据组织成两个文件:
-
wav.scp:每行包含两列,分别是wav_id和wav_path。 -
text:每行包含两列,分别是wav_id和text_label。
-
-
提取可选的CMVN特征(阶段 1)使用原始的WAV文件作为输入。标准化文本标签,去除空格,在此步骤中,将训练的
wav.scp和text文件复制到raw_wav/train/目录中。使用tools/compute_cmvn_stats.py提取全局倒谱均值和方差归一化(CMVN)统计信息。 -
生成标签令牌字典(阶段 2)创建标签令牌(AIShell-1中的字符)与整数索引之间的映射。字典包括特殊令牌,如
<blank>(用于CTC)、<unk>(未知令牌)和<sos/eos>(开始/结束语音)。 -
准备数据的所需格式(阶段 3)将数据转换为模型训练所需的格式。对于小型数据集,使用原始格式raw;对于大型数据集,使用shard,将数据分片以提高读取和训练速度。
-
模型训练(阶段 4)配置并启动模型训练。根据配置,选择使用DeepSpeed或Torch DDP进行分布式训练。这一步包含了设置分布式训练的各种参数,如节点数、每个节点的进程数、训练配置文件等。
-
模型评估(阶段 5)使用训练好的模型进行推理和评估,计算WER(Word Error Rate)。如果启用了模型平均,会首先对多个检查点进行平均以得到最终的评估模型。
-
导出模型(阶段 6)导出训练好的模型,生成可用于推理的模型文件。这一步通常包括导出标准模型和量化模型,以便在不同的设备和环境中进行高效推理。
-
语言模型准备和解码(阶段 7)准备语言模型和解码工具,进行语言模型的训练和解码。这包括生成字典、训练语言模型、编译FST(Finite State Transducer)图并进行解码测试。
-
使用HLG图进行解码(阶段 8)使用HLG(HMM-Lexicon-Grammar)图进行解码,以进一步提升模型的解码性能。这一步需要预先准备HLG图并进行推理和评估。
-
使用LF-MMI进行训练(阶段 9)使用LF-MMI(Lattice-Free Maximum Mutual Information)进行模型训练,以进一步优化模型性能。这一步包括准备LF-MMI所需的FST图,并在之前的基础上进行进一步的模型训练和评估。
#!/bin/bash# Copyright 2019 Mobvoi Inc. All Rights Reserved.
. ./path.sh || exit 1;# 自动检测 GPU 的数量
if command -v nvidia-smi &> /dev/null; then # 检查 nvidia-smi 是否存在num_gpus=$(nvidia-smi -L | wc -l) # 获取 GPU 的数量gpu_list=$(seq -s, 0 $((num_gpus-1))) # 生成 GPU 列表,例如 "0,1,2,3"
elsenum_gpus=-1 # 如果没有检测到 GPU,则设置 num_gpus 为 -1gpu_list="-1" # 设置默认 GPU 列表为 "-1"
fi# 您还可以手动指定 CUDA_VISIBLE_DEVICES
# 如果您不想使用所有可用的 GPU 资源,请手动设置 CUDA_VISIBLE_DEVICES
# export CUDA_VISIBLE_DEVICES="${gpu_list}"
export CUDA_VISIBLE_DEVICES="0,7" # 手动设置使用 GPU 0 和 7
echo "CUDA_VISIBLE_DEVICES is ${CUDA_VISIBLE_DEVICES}"stage=0 # 从阶段0开始,如果需要从数据准备开始
stop_stage=5 # 停止阶段设置为5# 如果进行多机训练,您需要更改以下两个参数,
# 请参阅 https://pytorch.org/docs/stable/elastic/run.html
HOST_NODE_ADDR="localhost:0" # 主节点地址
num_nodes=1 # 节点数量
job_id=2023 # 作业ID# AIShell 数据集位置,请将此路径更改为您自己的路径
# 请确保使用绝对路径,不要使用相对路径
data=/s6home/lnj524/module/data/opensource_data/aishell
data_url=www.openslr.org/resources/33 # 数据集下载地址nj=16 # 并行作业数量
dict=data/dict/lang_char.txt # 字典文件路径# 数据类型可以是 `raw` 或 `shard`。通常,raw 用于小型数据集,
# shard 用于超过 1k 小时的大型数据集,shard 在读取数据和训练时更快。
data_type=raw # 数据类型设置为 raw
num_utts_per_shard=1000 # 每个 shard 包含的 utt 数量train_set=train # 训练集名称
# 可选的训练配置文件
# 1. conf/train_transformer.yaml: 标准 transformer
# 2. conf/train_conformer.yaml: 标准 conformer
# 3. conf/train_unified_conformer.yaml: 统一动态块因果 conformer
# 4. conf/train_unified_transformer.yaml: 统一动态块 transformer
# 5. conf/train_u2++_conformer.yaml: U2++ conformer
# 6. conf/train_u2++_transformer.yaml: U2++ transformer
# 7. conf/train_u2++_conformer.yaml: U2++ lite conformer,必须加载一个训练好的模型,并冻结编码器模块,否则会出现自动梯度错误
train_config=conf/train_conformer.yaml # 选择训练配置文件
dir=exp/conformer # 模型保存目录
tensorboard_dir=tensorboard # Tensorboard 日志目录
checkpoint= # 检查点文件
num_workers=8 # 数据加载线程数
prefetch=10 # 数据预取数量# 使用 average_checkpoint 将获得更好的结果
average_checkpoint=true # 启用检查点平均
decode_checkpoint=$dir/final.pt # 解码使用的检查点
average_num=30 # 平均的检查点数量
decode_modes="ctc_greedy_search ctc_prefix_beam_search attention attention_rescoring" # 解码模式train_engine=torch_ddp # 训练引擎deepspeed_config=conf/ds_stage2.json # DeepSpeed 配置文件
deepspeed_save_states="model_only" # DeepSpeed 保存状态. tools/parse_options.sh || exit 1; # 解析脚本选项# 阶段 -1:数据下载
if [ ${stage} -le -1 ] && [ ${stop_stage} -ge -1 ]; thenecho "stage -1: Data Download"local/download_and_untar.sh ${data} ${data_url} data_aishell # 下载并解压数据集local/download_and_untar.sh ${data} ${data_url} resource_aishell # 下载并解压资源文件
fi# 阶段 0:数据准备
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; thenlocal/aishell_data_prep.sh ${data}/data_aishell/wav \${data}/data_aishell/transcript # 准备数据
fi# 阶段 1:文本标签处理和计算 CMVN 统计信息
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then# 删除汉语数据集中文本标签之间的空格for x in train dev test; docp data/${x}/text data/${x}/text.org # 备份原始文本标签文件paste -d " " <(cut -f 1 -d" " data/${x}/text.org) \<(cut -f 2- -d" " data/${x}/text.org | tr -d " ") \> data/${x}/text # 删除空格后生成新文本标签文件rm data/${x}/text.org # 删除备份文件donetools/compute_cmvn_stats.py --num_workers 16 --train_config $train_config \--in_scp data/${train_set}/wav.scp \--out_cmvn data/$train_set/global_cmvn # 计算 CMVN 统计信息
fi# 阶段 2:生成字典文件
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; thenecho "Make a dictionary"mkdir -p $(dirname $dict) # 创建字典目录echo "<blank> 0" > ${dict} # 为 CTC 生成 <blank> 标签echo "<unk> 1" >> ${dict} # 为未知标签生成 <unk>echo "<sos/eos> 2" >> $dict # 为开始/结束生成 <sos/eos>tools/text2token.py -s 1 -n 1 data/train/text | cut -f 2- -d" " \| tr " " "\n" | sort | uniq | grep -a -v -e '^\s*$' | \awk '{print $0 " " NR+2}' >> ${dict} # 生成标签令牌与整数索引的映射
fi# 阶段 3:准备数据的所需格式
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; thenecho "Prepare data, prepare required format"for x in dev test ${train_set}; doif [ $data_type == "shard" ]; thentools/make_shard_list.py --num_utts_per_shard $num_utts_per_shard \--num_threads 16 data/$x/wav.scp data/$x/text \$(realpath data/$x/shards) data/$x/data.list # 生成 shard 格式的数据列表elsetools/make_raw_list.py data/$x/wav.scp data/$x/text \data/$x/data.list # 生成 raw 格式的数据列表fidone
fi# 阶段 4:模型训练
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; thenmkdir -p $dir # 创建模型保存目录num_gpus=$(echo $CUDA_VISIBLE_DEVICES | awk -F "," '{print NF}') # 计算使用的 GPU 数量# 如果可用,使用 "nccl",否则使用 "gloo"dist_backend="nccl"# train.py 将 $train_config 重写为 $dir/train.yaml,包括模型输入和输出维度# $dir/train.yaml 将用于推理和导出。if [ ${train_engine} == "deepspeed" ]; thenecho "$0: using deepspeed"elseecho "$0: using torch ddp"fi# 注:torchrun 可以同时启动 ddp 和 deepspeed# 为了统一单节点和多节点训练,我们添加了所有相关参数。# 您应该更改 `nnodes` 和 `rdzv_endpoint` 以进行多节点训练,# 参见 https://pytorch.org/docs/stable/elastic/run.html#usage# 和 https://github.com/wenet-e2e/wenet/pull/2055#issuecomment-1766055406# `rdzv_id` - 用户定义的 ID,用于唯一标识作业的工作组。# `rdzv_endpoint` - rendezvous 后端端点,通常形式为 <host>:<port>。# 注:在多节点训练中,一些集群需要在训练前设置特殊的 NCCL 变量。# 例如:`NCCL_IB_DISABLE=1` + `NCCL_SOCKET_IFNAME=enp` + `NCCL_DEBUG=INFO`# 如果没有 NCCL_IB_DISABLE=1# 运行时错误:NCCL 错误:内部错误,NCCL 版本 xxx# 如果没有 NCCL_SOCKET_IFNAME=enp (IFNAME 可通过 `ifconfig` 获取)# 运行时错误:服务器套接字无法监听任何本地网络地址。服务器套接字无法绑定到 [::]:xxx# 参考:https://github.com/google/jax/issues/13559#issuecomment-1343573764echo "$0: num_nodes is $num_nodes, proc_per_node is $num_gpus"torchrun --nnodes=$num_nodes --nproc_per_node=$num_gpus \--rdzv_id=$job_id --rdzv_backend="c10d" --rdzv_endpoint=$HOST_NODE_ADDR \wenet/bin/train.py \--train_engine ${train_engine} \--config $train_config \--data_type $data_type \--train_data data/$train_set/data.list \--cv_data data/dev/data.list \${checkpoint:+--checkpoint $checkpoint} \--model_dir $dir \--tensorboard_dir ${tensorboard_dir} \--ddp.dist_backend $dist_backend \--num_workers ${num_workers} \--prefetch ${prefetch} \--pin_memory \--deepspeed_config ${deepspeed_config} \--deepspeed.save_states ${deepspeed_save_states}
fi# 阶段 5:模型测试
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then# 测试模型,请通过 --checkpoint 指定要测试的模型if [ ${average_checkpoint} == true ]; thendecode_checkpoint=$dir/avg_${average_num}.ptecho "do model average and final checkpoint is $decode_checkpoint"python wenet/bin/average_model.py \--dst_model $decode_checkpoint \--src_path $dir \--num ${average_num} \--val_best # 进行模型检查点平均fi# 请为统一流式和非流式模型指定 decoding_chunk_size。默认值为 -1,表示全块非流式推理。decoding_chunk_size=ctc_weight=0.3reverse_weight=0.5python wenet/bin/recognize.py --gpu 0 \--modes $decode_modes \--config $dir/train.yaml \--data_type $data_type \--test_data data/test/data.list \--checkpoint $decode_checkpoint \--beam_size 10 \--batch_size 32 \--blank_penalty 0.0 \--ctc_weight $ctc_weight \--reverse_weight $reverse_weight \--result_dir $dir \${decoding_chunk_size:+--decoding_chunk_size $decoding_chunk_size}for mode in ${decode_modes}; dopython tools/compute-wer.py --char=1 --v=1 \data/test/text $dir/$mode/text > $dir/$mode/wer # 计算词错误率(WER)done
fi# 阶段 6:导出模型
if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; then# 导出最佳模型python wenet/bin/export_jit.py \--config $dir/train.yaml \--checkpoint $dir/avg_${average_num}.pt \--output_file $dir/final.zip \--output_quant_file $dir/final_quant.zip # 导出量化模型
fi# 可选,您可以添加语言模型(LM)并在运行时测试。
if [ ${stage} -le 7 ] && [ ${stop_stage} -ge 7 ]; then# 7.1 准备字典unit_file=$dictmkdir -p data/local/dictcp $unit_file data/local/dict/units.txttools/fst/prepare_dict.py $unit_file ${data}/resource_aishell/lexicon.txt \data/local/dict/lexicon.txt # 准备词典# 7.2 训练语言模型(LM)lm=data/local/lmmkdir -p $lmtools/filter_scp.pl data/train/text \$data/data_aishell/transcript/aishell_transcript_v0.8.txt > $lm/textlocal/aishell_train_lms.sh # 训练语言模型# 7.3 构建解码 TLG 图tools/fst/compile_lexicon_token_fst.sh \data/local/dict data/local/tmp data/local/langtools/fst/make_tlg.sh data/local/lm data/local/lang data/lang_test || exit 1;# 7.4 运行时解码chunk_size=-1./tools/decode.sh --nj 16 \--beam 15.0 --lattice_beam 7.5 --max_active 7000 \--blank_skip_thresh 0.98 --ctc_weight 0.5 --rescoring_weight 1.0 \--chunk_size $chunk_size \--fst_path data/lang_test/TLG.fst \--dict_path data/lang_test/words.txt \data/test/wav.scp data/test/text $dir/final.zip \data/lang_test/units.txt $dir/lm_with_runtime # 运行时解码# 请查看 $dir/lm_with_runtime 中的 WER
fi# 可选,您可以使用 k2 HLG 进行解码
if [ ${stage} -le 8 ] && [ ${stop_stage} -ge 8 ]; thenif [ ! -f data/local/lm/lm.arpa ]; thenecho "Please run prepare dict and train lm in Stage 7" || exit 1;fi# 8.1 构建解码 HLG 图required="data/local/hlg/HLG.pt data/local/hlg/words.txt"for f in $required; doif [ ! -f $f ]; thentools/k2/make_hlg.sh data/local/dict/ data/local/lm/ data/local/hlgbreakfidone# 8.2 使用 HLG 进行解码decoding_chunk_size=lm_scale=0.7decoder_scale=0.1r_decoder_scale=0.7decode_modes="hlg_onebest hlg_rescore"python wenet/bin/recognize.py --gpu 0 \--modes $decode_modes \--config $dir/train.yaml \--data_type $data_type \--test_data data/test/data.list \--checkpoint $decode_checkpoint \--beam_size 10 \--batch_size 16 \--blank_penalty 0.0 \--dict $dict \--word data/local/hlg/words.txt \--hlg data/local/hlg/HLG.pt \--lm_scale $lm_scale \--decoder_scale $decoder_scale \--r_decoder_scale $r_decoder_scale \--result_dir $dir \${decoding_chunk_size:+--decoding_chunk_size $decoding_chunk_size}for mode in ${decode_modes}; dopython tools/compute-wer.py --char=1 --v=1 \data/test/text $dir/$mode/text > $dir/$mode/wer # 计算词错误率(WER)done
fi# 可选,您可以使用 k2 进行 LF-MMI 训练
# 基于 20210601_u2++_conformer_exp/final.pt,我们训练 50 轮,学习率为 1e-5
# 平均 10 个最佳模型,使用 HLG 解码,达到 4.11 的 CER
# 实际上,通过调整 lm_scale/decoder_scale/r_decoder_scale,可以达到更低的 CER
if [ ${stage} -le 9 ] && [ ${stop_stage} -ge 9 ]; then# 9.1 构建 LF-MMI 训练的二元 FSTtools/k2/prepare_mmi.sh data/train/ data/dev data/local/lfmmi# 9.2 从阶段 4 开始运行 LF-MMI 训练,修改 train.yaml 中的以下参数# model: k2_model# model_conf:# lfmmi_dir data/local/lfmmi# 9.3 从阶段 8.2 运行 HLG 解码
fi
2.2训练配置文件train_conformer.yaml
# 网络架构
# 编码器相关设置
encoder: conformer
encoder_conf:output_size: 256 # 注意力机制的输出维度attention_heads: 4 # 注意力头的数量linear_units: 2048 # 位置前馈网络的隐藏层单元数num_blocks: 12 # 编码器块的数量dropout_rate: 0.1 # Dropout 概率,用于防止过拟合positional_dropout_rate: 0.1 # 位置编码的 Dropout 概率attention_dropout_rate: 0.0 # 注意力机制的 Dropout 概率input_layer: conv2d # 编码器的输入类型,可以选择 conv2d, conv2d6 和 conv2d8normalize_before: true # 是否在每个子层之前应用层归一化cnn_module_kernel: 15 # CNN 模块的卷积核大小use_cnn_module: True # 是否使用 CNN 模块activation_type: 'swish' # 激活函数类型pos_enc_layer_type: 'rel_pos' # 位置编码层的类型selfattention_layer_type: 'rel_selfattn' # 自注意力层的类型# 解码器相关设置
decoder: transformer
decoder_conf:attention_heads: 4 # 注意力头的数量linear_units: 2048 # 位置前馈网络的隐藏层单元数num_blocks: 6 # 解码器块的数量dropout_rate: 0.1 # Dropout 概率,用于防止过拟合positional_dropout_rate: 0.1 # 位置编码的 Dropout 概率self_attention_dropout_rate: 0.0 # 自注意力机制的 Dropout 概率src_attention_dropout_rate: 0.0 # 来源注意力机制的 Dropout 概率# 分词器设置
tokenizer: char
tokenizer_conf:symbol_table_path: 'data/dict/lang_char.txt' # 符号表路径split_with_space: false # 是否以空格分割bpe_path: null # BPE(Byte-Pair Encoding)模型路径non_lang_syms_path: null # 非语言符号路径is_multilingual: false # 是否支持多语言num_languages: 1 # 语言数量special_tokens: # 特殊符号<blank>: 0 # 空白符<unk>: 1 # 未知符号<sos>: 2 # 句子开始符<eos>: 2 # 句子结束符# CTC(连接时间分类)相关设置
ctc: ctc
ctc_conf:ctc_blank_id: 0 # CTC 空白符的 ID# CMVN(倒谱均值方差归一化)设置
cmvn: global_cmvn
cmvn_conf:cmvn_file: 'data/train/global_cmvn' # CMVN 文件路径is_json_cmvn: true # CMVN 文件是否为 JSON 格式# 混合 CTC/注意力模型设置
model: asr_model
model_conf:ctc_weight: 0.3 # CTC 损失的权重lsm_weight: 0.1 # 标签平滑(Label Smoothing)权重length_normalized_loss: false # 是否使用长度归一化的损失# 数据集设置
dataset: asr
dataset_conf:filter_conf: # 数据过滤配置max_length: 40960 # 数据最大长度min_length: 0 # 数据最小长度token_max_length: 200 # 令牌最大长度token_min_length: 1 # 令牌最小长度resample_conf: # 重采样配置resample_rate: 16000 # 重采样率speed_perturb: true # 是否使用语速扰动fbank_conf: # 过滤器组配置num_mel_bins: 80 # 梅尔频率倒谱系数(MFCC)数量frame_shift: 10 # 帧移(毫秒)frame_length: 25 # 帧长(毫秒)dither: 0.1 # 添加噪声的强度spec_aug: true # 是否使用频谱增强spec_aug_conf: # 频谱增强配置num_t_mask: 2 # 时间掩码数量num_f_mask: 2 # 频率掩码数量max_t: 50 # 最大时间掩码宽度max_f: 10 # 最大频率掩码宽度shuffle: true # 是否打乱数据shuffle_conf: # 数据打乱配置shuffle_size: 1500 # 打乱缓冲区大小sort: true # 是否排序数据sort_conf: # 数据排序配置sort_size: 500 # 排序缓冲区大小,应该小于 shuffle_sizebatch_conf: # 批处理配置batch_type: 'static' # 批处理类型,可选 static 或 dynamicbatch_size: 16 # 批处理大小grad_clip: 5 # 梯度剪裁阈值
accum_grad: 4 # 梯度累加步数
max_epoch: 240 # 最大训练轮数
log_interval: 100 # 日志间隔optim: adam # 优化器设置
optim_conf:lr: 0.002 # 学习率
# 学习率调度器设置
scheduler: warmuplr # 需要 pytorch v1.1.0 及以上版本
scheduler_conf:warmup_steps: 25000 # 预热步数
3训练结果和预测 (尚未结束,后续完善)

相关文章:
WeNet环境配置与aishell模型训练
WeNet环境配置与aishell模型训练 1环境配置 踩坑记录: 系统使用win11,我根据wenet官方文档,使用conda虚拟环境安装了cuda12.1,安装wenet依赖库,其中deepspeed报错,根据报错信息查询github,发现…...

【C++的剃刀】我不允许你还不会AVL树
学习编程就得循环渐进,扎实基础,勿在浮沙筑高台 循环渐进Forward-CSDN博客 Hello,这里是kiki,今天继续更新C部分,我们继续来扩充我们的知识面,我希望能努力把抽象繁多的知识讲的生动又通俗易懂,今天要…...

React搭建Vite项目及各种项目配置
1. 创建Vite项目 在操作系统的命令终端,输入以下命令: yarn create vite 输入完成以后输入项目名称、选择开发框架,选择开发语言,如下图所示,即可完成项目创建。 注意事项: 1. Node版本必须符合要求&…...

Linux Vim教程:多文件编辑与窗口管理
目录 1. 多文件编辑基础 1.1 缓冲区管理 1.2 标签页管理 1.3 分屏管理 2. 多文件编辑的高级技巧 2.1 同时编辑多个文件 2.2 使用会话 2.3 使用寄存器 3. 窗口管理的实用技巧 3.1 窗口调整 3.2 窗口排列 3.3 快速切换 4. 使用插件增强多文件编辑与窗口管理 4.1 NE…...

C语言进阶 11.结构体
C语言进阶 11.结构体 文章目录 C语言进阶 11.结构体11.1. 枚举11.2. 结构类型11.3. 结构与函数11.4. 结构中的结构11.5. 类型定义11.6. 联合11.7. PAT11-0. 平面向量加法(10)11-1. 通讯录的录入与显示(10) 11.1. 枚举 常量符号化: 用符号而不是具体的数字表示程序中的数字 cons…...

Vue--解决error:0308010C:digital envelope routines::unsupported
原文网址:Vue--解决error:0308010C:digital envelope routines::unsupported_IT利刃出鞘的博客-CSDN博客 简介 本文介绍如何解决node.js在运行Vue项目时的报错:error:0308010C:digital envelope routines::unsupported。 问题描述 使用node.js运行Vu…...

go-kratos 学习笔记(6) 数据库gorm使用
数据库是项目的核心,数据库的链接数据是data层的操作,选择了比较简单好用的gorm作为数据库的工具;之前是PHP开发,各种框架都是orm的操作;gorm还是很相似的,使用起来比较顺手 go-kratos官网的实例是ent&…...

记录:vite打包报错 error during build: Error: Parse error @:1:1
vant从3升级到4后,本地运行没问题, 但是打包就会报如下错误:error during build: Error: Parse error :1:1 一直以为是vant的问题,各种升级,替换插件,发现没什么用, 网上搜索了下,…...

Python 消费Kafka手动提交 批量存入Elasticsearch
一、第三方包选择 pip install kafka,对比了kafka和pykafka,还是选择kafka,消费速度更快pip install elasticsearch7.12.0(ES版本) 二、创建es连接对象 from elasticsearch import Elasticsearch from elasticsearch.helpers import bulkc…...

oracle 基础知识表的主键
一、表的约束条件 •约束条件是施加在表的字段上的一组限制条件,它使得只有符合限制条件要求的数据才能输入表。 •保证了表中的数据的正确性 i.约束条件包括了:非空和唯一和核对,即not null 和unique 和check null的含义:不确定 3个人去捡苹…...

opencascade AIS_MouseGesture AIS_MultipleConnectedInteractive源码学习
AIS_MouseGesture //! 鼠标手势 - 同一时刻只能激活一个。 enum AIS_MouseGesture { AIS_MouseGesture_NONE, //!< 无激活手势 // AIS_MouseGesture_SelectRectangle, //!< 矩形选择; //! 按下按钮开始,移动鼠标定义矩形&…...
Unity Apple Vision Pro 开发:如何把 PolySpatial 和 Play To Device 的版本从 1.2.3 升级为 1.3.1
XR 开发社区: SpatialXR社区:完整课程、项目下载、项目孵化宣发、答疑、投融资、专属圈子 📕教程说明 本教程将介绍如何把 Unity 的 PolySpatial 和 Play To Device 版本从 1.2.3 升级为 1.3.1。 📕Play To Device 软件升级 ht…...

大数据时代,区块链是如何助力数据开放共享的?
在大数据时代,区块链技术以其独特的优势,为数据开放共享提供了强有力的支持。以下是区块链助力数据开放共享的几个主要方面: 1. 增强数据安全性与隐私保护 加密安全:区块链技术采用先进的加密算法,如国密非对称加密技…...

睿抗2024省赛----RC-u4 章鱼图的判断
题目 对于无向图 G(V,E),我们将有且只有一个环的、大于 2 个顶点的无向连通图称之为章鱼图,因为其形状像是一个环(身体)带着若干个树(触手),故得名。 给定一个无向图,请你判断是不…...

py2exe,一个神奇的 Python 库
在众多Python打包工具中,py2exe无疑是一款出色的选择。它能够将Python脚本转换成可在Windows平台上独立运行的可执行文件,极大地方便了程序的分发与部署。本文将深入探讨py2exe的特性和使用方法,让你在创建桌面应用程序时更加游刃有余。 安装…...

博途PLC网络连接不上
博途PLC网络连接不上其中的一个原因就是网线接触不好,各种原因都试了,任然连接不上,大家可以把网线拔下,重新插拔或者直接更换一根网线。 1、无线网络网段和PLC连接网段冲突 。。。。...

哪个邮箱最安全最好用啊
企业邮箱安全至关重要,需保护隐私、防财务损失、维护通信安全、避免纠纷,并维持业务连续性。哪个企业邮箱最安全好用呢?Zoho企业邮箱,采用加密技术、反垃圾邮件和病毒保护,支持多因素认证,确保数据安全合规…...

企业微信开发智能升级:AIGC技术赋能,打造高效沟通平台
文章目录 一、AIGC在企业微信开发中的核心价值1. 智能化客服体验2. 自动化工作流程3. 个性化内容推荐4. 深度数据分析与洞察 二、使用AIGC进行企业微信开发的实践路径1. 需求分析与场景定义2. 技术选型与平台搭建3. 模型训练与调优4. 接口对接与功能集成5. 测试与优化 《企业微…...
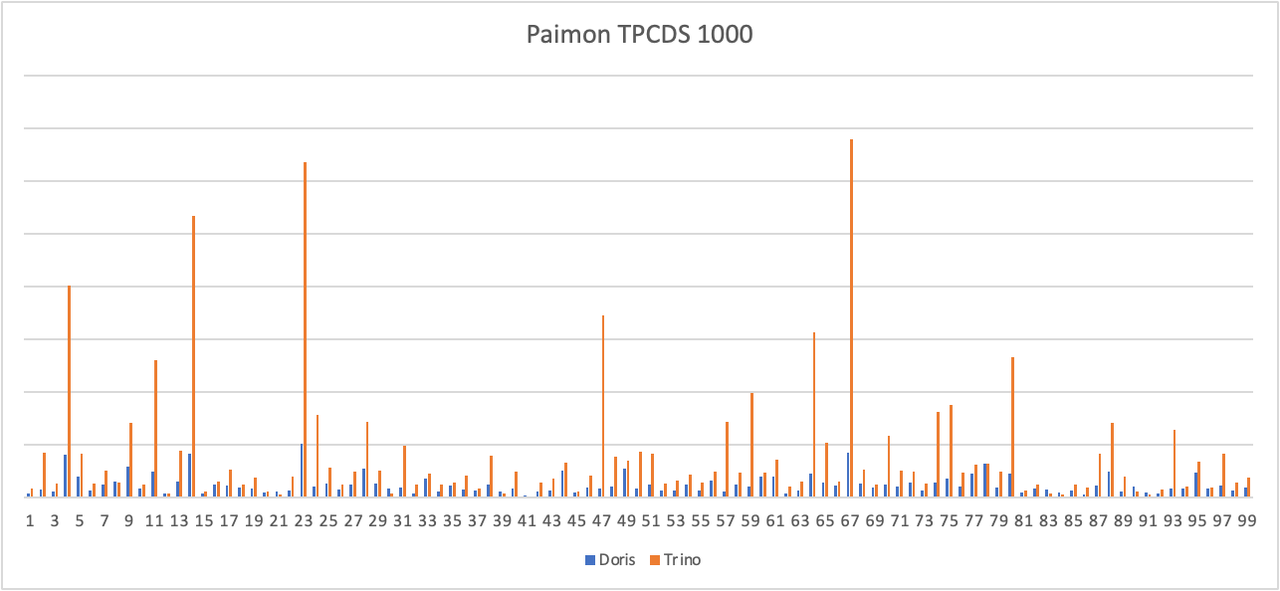
Apache Doris + Paimon 快速搭建指南|Lakehouse 使用手册(二)
湖仓一体(Data Lakehouse)融合了数据仓库的高性能、实时性以及数据湖的低成本、灵活性等优势,帮助用户更加便捷地满足各种数据处理分析的需求。在过去多个版本中,Apache Doris 持续加深与数据湖的融合,已演进出一套成熟…...

Inno setup pascal编码下如何美化安装界面支持带边框,圆角,透明阴影窗口
inno setup自带的安装界面太老套了,如何实现类似网易,微信那种带界面的安装?一般有两种思路:提供一个单独的下载器,然后通过下载器将你用innosetup 打包后的软件下载下来,然后,静默安装这个包&a…...

GLM-OCR与YOLOv8协同实战:实现视频流中的动态文字检测与识别
GLM-OCR与YOLOv8协同实战:实现视频流中的动态文字检测与识别 最近在做一个项目,需要从监控视频里自动读取车牌号码,从会议录像里提取PPT上的文字,甚至想试试从直播流里抓取滚动的新闻字幕。这些需求听起来挺酷,但做起…...

TikTok引发算法竞赛,Meta与TikTok陷有害内容争议
算法竞赛下,Meta与TikTok有害内容增多举报人向BBC透露,TikTok凭借极具吸引力的短视频推荐算法颠覆社交媒体行业后,引发了算法竞赛。Meta和TikTok在对自家算法进行内部研究后发现,愤怒情绪能推动用户参与度,于是做出了一…...

项目文章 | Nat Commun CUTTag+RNA-seq助力解析组蛋白乳酸化介导的增生性疤痕形成机制
增生性疤痕(hypertrophic scar, HS)是一种以成纤维细胞过度活化和细胞外基质异常沉积为特征的纤维增生性疾病。代谢重组(向有氧糖酵解转变)和组蛋白乳酸化修饰在多种纤维化疾病中被发现,但其在增生性疤痕中的具体作用和…...

云原生安全实战:如何在 K8s 集群中为 Ingress 开启 HTTPS 绿锁?
🔒 云原生安全实战:如何在 K8s 集群中为 Ingress 开启 HTTPS 绿锁? 在生产环境(Prod)的架构设计中,安全永远是“第一优先级”。对于涉及敏感数据的微服务平台,全站 HTTPS 加密是不可逾越的合规底…...

免费大模型 API 调用量被限制?试试这个企业级多账号轮询与高可用代理方案!
标签:大模型开发 | API 网关 | FastAPI | 负载均衡 | 架构设计 | 降本增效📖 引言:天下苦 “429 Too Many Requests” 久矣! 随着各类国产大模型(如 Kimi、DeepSeek、智谱等)以及国际巨头(OpenA…...

计算机毕业设计之基于SpringBoot的自驾游出行一站式物资商城
随着社会的发展,系统的管理形势越来越严峻。越来越多的用户利用互联网获得信息,但各种信息鱼龙混杂,信息真假难以辨别。为了方便用户更好的获得自驾游出行物资信息,因此,设计一种安全高效的基于SpringBoot的自驾游出行…...

卫星姿态轨道控制Simulink仿真:一个基于资料的学习实践
卫星姿态轨道控制simulink仿真/姿轨控 卫星姿轨控仿真,基于simulink 自己在国外文献和资料基础上修改 资料包含源程序和英文版报告,是学习卫星姿轨控和simulink仿真的好资料一、引言随着航天技术的飞速发展,卫星姿态轨道控制(姿轨…...

OpenClaw都能做哪些事
OpenClaw AI 助手的核心功能与应用场景OpenClaw AI 助手是一款基于人工智能的多功能自动化工具,旨在帮助用户高效完成重复性任务、优化工作流程并提升生产力。其功能覆盖浏览器自动化、文件整理、网页抓取、邮件管理等多个领域,同时支持小红书运营、云端…...

Pampy与函数式编程:如何构建更优雅的Python应用
Pampy与函数式编程:如何构建更优雅的Python应用 【免费下载链接】pampy Pampy: The Pattern Matching for Python you always dreamed of. 项目地址: https://gitcode.com/gh_mirrors/pa/pampy 在Python开发中,函数式编程范式正逐渐成为提升代码可…...

Fenjing源码解析:核心组件与规则引擎的设计思路
Fenjing源码解析:核心组件与规则引擎的设计思路 【免费下载链接】Fenjing 项目地址: https://gitcode.com/gh_mirrors/fe/Fenjing Fenjing是一款功能强大的安全测试工具,其核心组件与规则引擎的设计思路为安全测试提供了高效解决方案。本文将深入…...