线性回归和逻辑回归揭示数据的隐藏模式:理论与实践全解析
机器学习之线性回归和逻辑回归
- 1. 简介
- 1.1 机器学习概述
- 1.2 监督学习的定义与重要性
- 1.3 线性回归和逻辑回归在监督学习中的作用
- 1.3.1 线性回归
- 1.3.2 逻辑回归
- 2. 线性回归(Linear Regression)
- 2.1 定义与目标
- 2.1.1 回归问题的定义
- 2.1.2 预测连续目标变量
- 2.2 模型概述
- 2.2.1 线性模型的数学形式
- 2.2.2 多变量线性回归
- 2.3 损失函数
- 2.3.1 均方误差(MSE)
- 2.4 模型训练
- 2.4.1 最小二乘法(OLS)
- 2.4.2 梯度下降算法(Gradient Descent)
- 2.5 评估指标
- 2.5.1 决定系数(\( R^2 \))
- 2.5.2 调整决定系数(Adjusted \( R^2 \))
- 2.6 假设检验
- 2.6.1 t检验
- 2.6.2 F检验
- 2.7 扩展与变体
- 2.7.1 岭回归(Ridge Regression)
- 2.7.2 拉索回归(Lasso Regression)
- 3. 逻辑回归(Logistic Regression)
- 3.1 定义与目标
- 3.1.1 分类问题的定义
- 3.1.2 预测离散目标变量(分类标签)
- 3.2 模型概述
- 3.2.1 逻辑回归模型的数学形式
- 3.2.2 Sigmoid函数与概率预测
- 3.3 损失函数
- 3.3.1 对数损失函数(Log Loss)
- 3.3.2 交叉熵损失(Cross-Entropy Loss)
- 3.4 模型训练
- 3.4.1 最大似然估计(Maximum Likelihood Estimation, MLE)
- 3.4.2 梯度上升算法(Gradient Ascent)
- 3.5 评估指标
- 3.5.1 准确率(Accuracy)
- 3.5.2 精确率(Precision)与召回率(Recall)
- 3.5.3 F1分数
- 3.5.4 ROC曲线与AUC值
- 3.6 假设检验
- 3.6.1 Wald检验
- 3.6.2 尤尔检验(Likelihood Ratio Test)
- 3.7 扩展与变体
- 3.7.1 多项逻辑回归(Multinomial Logistic Regression)
- 3.7.2 逐步回归(Stepwise Regression)
- 4. 线性回归与逻辑回归的比较
- 4.1 目标变量类型
- 线性回归
- 逻辑回归
- 4.2 模型假设
- 线性回归模型假设
- 逻辑回归模型假设
- 4.3 损失函数的不同
- 线性回归的损失函数
- 逻辑回归的损失函数
- 4.4 应用场景
- 线性回归的应用场景
- 逻辑回归的应用场景
- 4.5 结论
- 5. 实践中的应用与案例分析
- 5.1 数据预处理
- 5.1.1 特征标准化(Feature Scaling)
- 5.1.2 特征选择与工程(Feature Engineering)
- 5.2 模型评估与调优
- 5.2.1 交叉验证(Cross-Validation)
- 5.2.2 超参数调整
- 5.3 实际案例
- 5.3.1 线性回归案例:房价预测
- 5.3.2 逻辑回归案例:客户流失预测
- 结论
1. 简介
1.1 机器学习概述
机器学习是人工智能的一个重要分支,旨在通过算法让计算机系统利用数据自动学习和改进。它通过从数据中学习模式和规律,使得计算机能够进行预测、分类或者决策,而无需显式地进行编程。随着数据量的急剧增加和计算能力的提升,机器学习在各个领域如图像识别、自然语言处理和推荐系统等方面展现了强大的应用潜力。

1.2 监督学习的定义与重要性
监督学习是机器学习的一种重要范式,其核心是从标记数据(带有输入和预期输出的数据)中学习规律,以便对新数据进行预测或分类。在监督学习中,算法通过训练集中的示例来学习输入与输出之间的映射关系,从而使得算法能够对未见过的数据进行泛化。监督学习的重要性在于它能够利用已有的数据进行模型训练,并且能够对新数据进行准确的预测或分类,这使得监督学习成为了许多实际问题解决方案的基础。
1.3 线性回归和逻辑回归在监督学习中的作用
线性回归和逻辑回归是监督学习中两个基础且广泛应用的算法。
1.3.1 线性回归
线性回归是一种用于预测数值型输出的监督学习算法。其基本思想是建立一个线性模型来描述输入变量(自变量)与连续型输出变量(因变量)之间的关系。在最简单的情况下,线性回归模型假设自变量和因变量之间存在线性关系,通过拟合数据找到最佳拟合直线(或超平面),以进行预测或分析。例如,预测房屋价格、股票走势等。
线性回归的数学表达式通常为:
[ y = w_0 + w_1x_1 + w_2x_2 + \ldots + w_nx_n ]
其中,( y ) 是预测值,( w_0, w_1, \ldots, w_n ) 是模型参数,( x_1, x_2, \ldots, x_n ) 是输入特征。
1.3.2 逻辑回归
逻辑回归是一种用于解决二分类问题的监督学习算法。尽管名为“回归”,但实际上是一种分类算法,其输出是一个介于0和1之间的概率值,表示属于某一类的可能性。逻辑回归模型通过将线性模型的输出应用到一个逻辑函数(如sigmoid函数)来实现分类。
逻辑回归的数学表达式通常为:
[ P(y=1|x) = \sigma(w_0 + w_1x_1 + w_2x_2 + \ldots + w_nx_n) ]
[ P(y=0|x) = 1 - P(y=1|x) ]
其中,( \sigma ) 是sigmoid函数,( P(y=1|x) ) 是预测为正类的概率,( P(y=0|x) ) 是预测为负类的概率。
逻辑回归广泛应用于各种领域,如医学诊断、信用评分、广告点击预测等,其简单而有效的特性使其成为许多分类问题的首选算法之一。
2. 线性回归(Linear Regression)
2.1 定义与目标
线性回归是一种用于回归分析的基本方法,其主要目标是建立一个模型来预测一个连续的目标变量。回归问题的核心在于预测一个数值型的输出(目标变量),而不是分类问题中的离散类别。线性回归假设目标变量与一个或多个自变量(特征)之间存在线性关系。具体来说,线性回归试图找到一个最佳拟合直线,使得预测值与实际观测值之间的差距最小。
2.1.1 回归问题的定义
回归问题是指在给定一个或多个自变量的情况下,预测一个连续的因变量。与分类问题不同,回归问题的目标是输出一个连续的数值,而不是一个类别标签。例如,在房价预测中,给定房子的特征(如面积、房间数量等),我们希望预测房子的实际价格。这类问题通常需要通过回归模型来建立自变量与因变量之间的关系。
2.1.2 预测连续目标变量
在回归分析中,我们关注的是如何预测一个连续的目标变量。例如,预测一个学生的考试成绩、公司未来的收入或某个产品的销售量。线性回归模型通过找到一个最佳拟合的线性关系来实现这一目标。
2.2 模型概述
线性回归模型的目标是通过线性组合来预测目标变量。其基本形式为:
[ y = \beta_0 + \beta_1 x + \epsilon ]
2.2.1 线性模型的数学形式
- 截距(( \beta_0 )): 截距是回归线与y轴的交点,表示当自变量 ( x ) 为0时,因变量 ( y ) 的预测值。
- 斜率(( \beta_1 )): 斜率表示自变量 ( x ) 变化一个单位时,因变量 ( y ) 的变化量。斜率的绝对值越大,说明自变量对因变量的影响越大。
- 误差项(( \epsilon )): 误差项表示模型预测值与实际观测值之间的差距,反映了模型未能捕捉到的部分。
2.2.2 多变量线性回归
当有多个自变量时,模型的数学形式扩展为:
[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \epsilon ]
其中,( x_1, x_2, \ldots, x_p ) 是多个自变量,( \beta_1, \beta_2, \ldots, \beta_p ) 是相应的回归系数。
2.3 损失函数
损失函数用于评估模型的预测效果。在线性回归中,均方误差(MSE)是最常用的损失函数,它通过计算实际观测值与预测值之间的平均平方误差来衡量模型的性能。
2.3.1 均方误差(MSE)
均方误差的公式为:
[ \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 ]
- ( y_i ) 是实际的目标值
- ( \hat{y}_i ) 是模型的预测值
- ( n ) 是样本数量
MSE 越小,表示模型的预测效果越好。均方误差对异常值较为敏感,因此在处理数据时需要考虑其影响。
2.4 模型训练
模型训练的目的是找到使损失函数最小化的参数。常用的方法包括最小二乘法和梯度下降算法。
2.4.1 最小二乘法(OLS)
最小二乘法(Ordinary Least Squares, OLS)是线性回归中最常用的参数估计方法。其基本思想是通过最小化观测值与预测值之间的均方误差来估计回归参数。
数学推导:
通过最小化下述目标函数来求解参数 ( \beta ):
[ \text{Objective Function} = \sum_{i=1}^{n} (y_i - (\beta_0 + \beta_1 x_i))^2 ]
代码示例:
import numpy as np
from sklearn.linear_model import LinearRegression# 创建示例数据
X = np.array([[1], [2], [3]])
y = np.array([1, 2, 3])# 实例化模型
model = LinearRegression()# 拟合模型
model.fit(X, y)# 打印参数
print(f"截距: {model.intercept_}, 斜率: {model.coef_}")
2.4.2 梯度下降算法(Gradient Descent)
梯度下降是一种迭代优化方法,通过不断更新模型参数来最小化损失函数。梯度下降算法适用于大规模数据集和复杂模型。
算法步骤:
- 初始化参数
- 计算损失函数的梯度
- 根据梯度更新参数
- 重复步骤2和3,直到收敛
代码示例:
def gradient_descent(X, y, learning_rate=0.01, epochs=1000):m, n = X.shapetheta = np.zeros(n) # 初始化参数for _ in range(epochs):predictions = X @ thetaerrors = predictions - ygradients = (1 / m) * (X.T @ errors)theta -= learning_rate * gradientsreturn theta# 示例数据
X = np.array([[1], [2], [3]])
y = np.array([1, 2, 3])# 执行梯度下降
theta = gradient_descent(X, y)
print(f"估计的参数: {theta}")
2.5 评估指标
评估指标用于衡量回归模型的性能和预测效果。
2.5.1 决定系数(( R^2 ))
决定系数 ( R^2 ) 表示模型解释的方差比例。其计算公式为:
[ R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)2}{\sum_{i=1}{n} (y_i - \bar{y})^2} ]
- ( y_i ) 是实际的目标值
- ( \hat{y}_i ) 是模型的预测值
- ( \bar{y} ) 是目标值的均值
( R^2 ) 的值范围从0到1,值越接近1表示模型的解释能力越强。
2.5.2 调整决定系数(Adjusted ( R^2 ))
调整决定系数用于调整 ( R^2 ) 对自变量数量的敏感性。其计算公式为:
[ \text{Adjusted } R^2 = 1 - \left( \frac{1 - R^2}{n - p - 1} \right) \times (n - 1) ]
- ( n ) 是样本数量
- ( p ) 是自变量的数量
调整决定系数可以有效评估模型在多个自变量情况下的拟合效果。
2.6 假设检验
假设检验用于确定模型参数的显著性以及整体模型的有效性。
2.6.1 t检验
t检验用于检验单个回归系数是否显著不为零。t值计算公式为:
[ t = \frac{\hat{\beta}_j}{\text{SE}(\hat{\beta}_j)} ]
- ( \hat{\beta}_j ) 是回归系数的估计值
- ( \text{SE}(\hat{\beta}_j) ) 是回归系数的标准误差
2.6.2 F检验
F检验用于检验整体回归模型的显著性。其计算公式为:
[ F = \frac{\text{MSR}}{\text{MSE}} ]
- MSR 是回归平方和的均值
- MSE 是残差平方和的均值
F检验可以帮助我们判断自变量是否对因变量有整体的影响。
2.7 扩展与变体
在实际应用中,线性回归模型可能会遇到一些问题,如多重共线性或特征选择。为了解决这些问题,出现了多种线性回归的变体,如岭回归和拉索回归。
2.7.1 岭回归(Ridge Regression)
岭回
归通过在损失函数中添加L2正则化项来解决多重共线性问题。其目标函数为:
[ \text{Objective Function} = \sum_{i=1}^{n} (y_i - \hat{y}i)^2 + \lambda \sum{j=1}^{p} \beta_j^2 ]
其中,( \lambda ) 是正则化参数,用于控制正则化的强度。
代码示例:
from sklearn.linear_model import Ridge# 创建岭回归模型
ridge_model = Ridge(alpha=1.0)# 拟合模型
ridge_model.fit(X, y)# 打印参数
print(f"截距: {ridge_model.intercept_}, 斜率: {ridge_model.coef_}")
2.7.2 拉索回归(Lasso Regression)
拉索回归通过在损失函数中添加L1正则化项来实现特征选择。其目标函数为:
[ \text{Objective Function} = \sum_{i=1}^{n} (y_i - \hat{y}i)^2 + \lambda \sum{j=1}^{p} |\beta_j| ]
L1正则化可以将部分回归系数缩小到零,从而实现特征选择。
代码示例:
from sklearn.linear_model import Lasso# 创建拉索回归模型
lasso_model = Lasso(alpha=0.1)# 拟合模型
lasso_model.fit(X, y)# 打印参数
print(f"截距: {lasso_model.intercept_}, 斜率: {lasso_model.coef_}")
3. 逻辑回归(Logistic Regression)
逻辑回归是一种广泛用于分类任务的统计模型,尽管名字中有“回归”,但它实际应用于分类问题,尤其是二分类问题。以下是对逻辑回归的详细讲解,包括其定义、模型概述、损失函数、模型训练、评估指标、假设检验及其扩展和变体。
3.1 定义与目标
逻辑回归主要用于处理分类问题,即预测一个离散的类别标签。其核心目标是估计输入特征对应的分类概率。
3.1.1 分类问题的定义
在分类问题中,我们试图将样本分到预定义的类别中。这与回归任务(例如预测房价或温度)不同,因为回归任务的目标是预测一个连续的数值。分类任务通常涉及以下几个方面:
- 目标变量(标签):离散的类别标签,例如“癌症”与“非癌症”。
- 特征(输入变量):用于预测标签的连续或离散变量,例如患者的年龄、性别、医学测试结果等。
分类问题的目标是通过输入特征 ( X ) 预测目标变量 ( Y ) 的类别。对于二分类问题,目标是预测 ( Y ) 是1(正类)还是0(负类)。在逻辑回归中,我们使用概率模型来预测 ( P(Y=1|X) ) 的概率,并根据这个概率做出分类决策。
3.1.2 预测离散目标变量(分类标签)
逻辑回归的预测过程如下:
-
计算线性组合:模型首先计算特征的线性组合,即 ( z = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n ),其中 ( \beta_i ) 是模型的参数,( x_i ) 是输入特征。
-
应用Sigmoid函数:将线性组合 ( z ) 通过Sigmoid函数转换为概率值 ( P(Y=1|X) ):
[
P(Y=1|X) = \frac{1}{1 + e^{-z}}
]这个概率值表示样本属于正类的可能性。
-
分类决策:根据设定的阈值(通常为0.5),将概率值转化为类别标签。如果 ( P(Y=1|X) \geq 0.5 ),则预测类别为1;否则,预测类别为0。
3.2 模型概述
逻辑回归模型通过Sigmoid函数将线性模型的输出映射到(0, 1)区间,从而进行概率预测。以下是逻辑回归模型的详细数学形式和解释。
3.2.1 逻辑回归模型的数学形式
逻辑回归模型的核心公式是:
[
P(Y=1|X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n)}}
]
其中:
- ( \beta_0 ) 是偏置项。
- ( \beta_1, \beta_2, \ldots, \beta_n ) 是特征的权重。
- ( x_1, x_2, \ldots, x_n ) 是输入特征。
Sigmoid函数定义为:
[
\sigma(z) = \frac{1}{1 + e^{-z}}
]
它将任何实数 ( z ) 转换为介于0和1之间的值,因此可以用作概率值。这个函数的特点是:
- 当 ( z ) 很大(即 ( z \to +\infty ))时,( \sigma(z) ) 接近1。
- 当 ( z ) 很小(即 ( z \to -\infty ))时,( \sigma(z) ) 接近0。
- 当 ( z = 0 ) 时,( \sigma(z) = 0.5 )。
3.2.2 Sigmoid函数与概率预测
Sigmoid函数的输出是一个概率值,表示样本属于正类的概率。具体应用中,Sigmoid函数将线性回归模型的输出转换为0到1之间的概率,从而将模型的预测结果解释为分类概率。这使得逻辑回归不仅可以进行分类,还可以给出分类的置信度。
3.3 损失函数
损失函数用于评估模型的预测效果并指导模型的训练。逻辑回归主要使用对数损失函数和交叉熵损失函数来衡量模型的性能。
3.3.1 对数损失函数(Log Loss)
对数损失函数度量预测概率与实际标签之间的差异,其公式为:
[
\text{Log Loss} = - \frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right]
]
其中:
- ( N ) 是样本总数。
- ( y_i ) 是样本 ( i ) 的真实标签(0或1)。
- ( p_i ) 是样本 ( i ) 的预测概率 ( P(Y=1|X) )。
对数损失函数具有以下特点:
- 如果真实标签是1但预测概率接近0,则损失很大。
- 如果真实标签是0但预测概率接近1,则损失也很大。
- 损失函数值越小,模型的预测效果越好。
3.3.2 交叉熵损失(Cross-Entropy Loss)
交叉熵损失是对数损失的一种推广,适用于多分类问题。对于二分类问题,交叉熵损失与对数损失等价。其公式为:
[
\text{Cross-Entropy Loss} = - \sum_{i=1}^{C} y_i \log(p_i)
]
其中:
- ( C ) 是类别数。
- ( y_i ) 是样本在第 ( i ) 类上的真实标签(通常是独热编码形式)。
- ( p_i ) 是样本在第 ( i ) 类上的预测概率。
交叉熵损失函数用于度量模型输出的概率分布与实际标签分布之间的差异。其值越小,表示模型的预测概率分布越接近真实标签分布。
3.4 模型训练
逻辑回归的训练过程包括确定模型的最优参数,以最小化损失函数。常用的方法有最大似然估计和梯度上升算法。
3.4.1 最大似然估计(Maximum Likelihood Estimation, MLE)
最大似然估计的目标是找到一组参数,使得在这些参数下观察到的数据的概率最大。在逻辑回归中,我们通过最大化对数似然函数来估计模型参数。对数似然函数定义为:
[
\text{Log-Likelihood} = \sum_{i=1}^{N} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right]
]
其中 ( p_i ) 是样本 ( i ) 的预测概率。通过最大化对数似然函数,我们可以获得最优的模型参数 ( \beta )。
3.4.2 梯度上升算法(Gradient Ascent)
梯度上升算法是一种优化算法,用于最大化对数似然函数。该算法通过迭代更新参数来寻找最优解。更新公式为:
[
\beta := \beta + \alpha \nabla_{\beta} \text{Log-Likelihood}
]
其中:
- ( \alpha ) 是学习率,控制参数更新的步长。
- ( \nabla_{\beta} \text{Log-Likelihood} ) 是对数似然函数关于参数 ( \beta ) 的梯度。
梯度上升算法的步骤包括:
- 初始化参数:通常将参数初始化为零或小的随机值。
- 计算预测概率:通过当前参数计算预测概率。
- 计算梯度:计算对数似然函数的梯度。
- 更新参数:根据梯度和学习率更新参数。
- 迭代优化:重复上述步骤,直到损失函数收敛或达到最大迭代次数。
import numpy as np
from scipy.special import expitdef sigmoid(z):return expit(z)def compute_cost(y, p):return -np.mean(y * np.log(p) + (1 - y) * np.log(1 - p))def gradient_ascent(X, y, learning_rate, num_iterations):m, n = X.shapebeta = np.zeros(n)for _ in range(num_iterations):predictions= sigmoid(np.dot(X, beta))error = y - predictionsgradient = np.dot(X.T, error) / mbeta += learning_rate * gradientreturn beta
3.5 评估指标
为了评估逻辑回归模型的性能,我们使用一系列指标来衡量模型的分类效果。常用的评估指标包括准确率、精确率与召回率、F1分数、ROC曲线及AUC值。
3.5.1 准确率(Accuracy)
准确率是最基本的评估指标,表示模型正确分类的样本占总样本的比例。其公式为:
[
\text{Accuracy} = \frac{\text{Number of Correct Predictions}}{\text{Total Number of Predictions}}
]
准确率适用于类别平衡的情况,但在类别不平衡的情况下,可能不能很好地反映模型的性能。
3.5.2 精确率(Precision)与召回率(Recall)
-
精确率(Precision):表示被模型预测为正类的样本中,真正正类的比例。公式为:
[
\text{Precision} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Positives}}
]精确率高意味着模型对正类样本的预测较为准确,假阳性率较低。
-
召回率(Recall):表示所有实际正类样本中,被模型正确预测为正类的比例。公式为:
[
\text{Recall} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}}
]召回率高意味着模型能正确识别更多的正类样本,假阴性率较低。
3.5.3 F1分数
F1分数是精确率和召回率的调和平均值,用于综合考虑模型的精确性和全面性。公式为:
[
\text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}
]
F1分数在类别不平衡的情况下特别有用,因为它考虑了假阳性和假阴性的影响。
3.5.4 ROC曲线与AUC值
-
ROC曲线(Receiver Operating Characteristic Curve):绘制真正率(True Positive Rate)与假正率(False Positive Rate)之间的关系。真正率计算公式为:
[
\text{True Positive Rate} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}}
]假正率计算公式为:
[
\text{False Positive Rate} = \frac{\text{False Positives}}{\text{False Positives} + \text{True Negatives}}
]ROC曲线展示了模型在不同阈值下的性能。
-
AUC值(Area Under Curve):ROC曲线下的面积,表示模型区分正负样本的能力。AUC值越接近1,模型的性能越好。
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, aucdef plot_roc_curve(y_true, y_scores):fpr, tpr, _ = roc_curve(y_true, y_scores)roc_auc = auc(fpr, tpr)plt.figure()plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver Operating Characteristic')plt.legend(loc="lower right")plt.show()
3.6 假设检验
假设检验用于评估模型参数的显著性,以确保特征对模型的影响是显著的。常用的检验方法包括Wald检验和尤尔检验。
3.6.1 Wald检验
Wald检验用于检验回归系数是否显著。其原理是计算每个回归系数的标准误差,并将系数与其标准误差的比值用于检验。Wald统计量的计算公式为:
[
W = \frac{\hat{\beta}_j}{\text{SE}(\hat{\beta}_j)} \sim \text{Normal}(0, 1)
]
其中,( \hat{\beta}_j ) 是第 ( j ) 个回归系数的估计值,( \text{SE}(\hat{\beta}_j) ) 是其标准误差。如果Wald统计量显著偏离零,则说明回归系数显著不为零,特征对目标变量有显著影响。
3.6.2 尤尔检验(Likelihood Ratio Test)
尤尔检验用于比较嵌套模型的拟合优度。其原理是比较全模型(包含所有特征)和简化模型(不包含某些特征)的对数似然值。尤尔检验的统计量计算公式为:
[
G^2 = -2 \left[ \text{Log-Likelihood}(\text{Simplified Model}) - \text{Log-Likelihood}(\text{Full Model}) \right]
]
该统计量服从卡方分布(Chi-Square Distribution)。如果尤尔统计量显著高于阈值,则说明简化模型的拟合效果显著差于全模型,即被省略的特征对模型有显著影响。
3.7 扩展与变体
逻辑回归有多种扩展和变体,可以处理更复杂的分类任务。
3.7.1 多项逻辑回归(Multinomial Logistic Regression)
多项逻辑回归用于处理多分类问题,即目标变量有多个类别。与二分类逻辑回归不同,多项逻辑回归预测每个类别的概率,并使用Softmax函数将线性组合映射到多个类别的概率分布。Softmax函数定义为:
[
P(Y=k|X) = \frac{e{\beta_kT X}}{\sum_{j=1}^{K} e{\beta_jT X}}
]
其中,( K ) 是类别总数,( \beta_k ) 是第 ( k ) 类的回归系数。
3.7.2 逐步回归(Stepwise Regression)
逐步回归是一种特征选择技术,通过逐步添加或删除特征来构建最优模型。它包括前向选择(从空模型开始,逐步添加特征)和后向淘汰(从全模型开始,逐步删除特征)。逐步回归可以帮助选择对模型预测最有用的特征,并提高模型的解释性和泛化能力。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegressiondef stepwise_selection(X, y):model = LogisticRegression()rfe = RFE(model, n_features_to_select=5) # 选择5个特征fit = rfe.fit(X, y)return fit.support_# 示例用法
# selected_features = stepwise_selection(X, y)
# print("Selected features:", selected_features)
4. 线性回归与逻辑回归的比较
在机器学习领域,线性回归和逻辑回归是两种非常基础但极其重要的回归模型。尽管它们有着相似的名字,但在实际应用和理论基础上却存在着显著的差异。在本部分,我们将详细比较线性回归和逻辑回归,探讨它们在目标变量类型、模型假设、损失函数和应用场景等方面的异同,以帮助读者更好地理解这两种回归方法的特点和适用范围。
4.1 目标变量类型
线性回归
线性回归模型主要用于处理连续目标变量。在这种模型中,预测的目标变量(也称为因变量或响应变量)是一个连续的数值。例如,我们可以使用线性回归预测房价、气温或销售额等连续值。这种模型的主要目标是拟合一条最佳的直线,以最小化预测值与实际值之间的差距。
逻辑回归
与线性回归不同,逻辑回归模型用于处理离散目标变量,特别是二分类问题。离散目标变量通常是有限个类别中的一个。例如,我们可以使用逻辑回归来预测一个客户是否会购买某个产品(购买与否),或者某个邮件是否是垃圾邮件。逻辑回归通过计算样本属于某个类别的概率,并使用阈值将概率转换为类别标签。
| 回归类型 | 目标变量类型 |
|---|---|
| 线性回归 | 连续变量 |
| 逻辑回归 | 离散变量(通常是二分类) |
4.2 模型假设
线性回归模型假设
线性回归模型的核心假设是线性关系。这意味着预测变量(自变量)与目标变量之间的关系是线性的。线性回归模型试图通过一个线性方程来表示这种关系:
[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n + \epsilon ]
其中,( y ) 是目标变量,( x_1, x_2, \ldots, x_n ) 是自变量,( \beta_0, \beta_1, \beta_2, \ldots, \beta_n ) 是回归系数,( \epsilon ) 是误差项。线性回归假设预测值与实际值之间的差异(即残差)是均值为零、方差为常数的正态分布。
逻辑回归模型假设
逻辑回归模型假设非线性关系。具体来说,逻辑回归使用Sigmoid函数(又称为逻辑函数)将线性组合的预测结果映射到0到1的概率范围内。Sigmoid函数的形式为:
[ \sigma(z) = \frac{1}{1 + e^{-z}} ]
其中,( z ) 是线性组合的结果(即 ( \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n ))。逻辑回归模型的目标是最大化似然函数,从而找到最佳的回归系数,使得预测的类别概率与实际类别的匹配程度最佳。
| 回归类型 | 模型假设 |
|---|---|
| 线性回归 | 线性关系 |
| 逻辑回归 | Sigmoid函数映射到概率空间 |
4.3 损失函数的不同
线性回归的损失函数
线性回归模型的损失函数通常是均方误差(Mean Squared Error, MSE),它测量了预测值与实际值之间的平方差的平均值。均方误差的公式为:
[ \text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 ]
其中,( y_i ) 是实际值,( \hat{y}_i ) 是预测值,( n ) 是样本数量。均方误差的目标是最小化这种平方差,使得模型对数据的拟合度最大化。
逻辑回归的损失函数
逻辑回归模型使用对数损失(Log Loss,也称为交叉熵损失)来衡量模型的性能。对数损失的公式为:
[ \text{Log Loss} = -\frac{1}{n} \sum_{i=1}^n [y_i \log(\hat{p}_i) + (1 - y_i) \log(1 - \hat{p}_i)] ]
其中,( y_i ) 是实际类别标签(0或1),( \hat{p}_i ) 是样本 ( i ) 属于类别1的预测概率。对数损失度量了模型预测的概率分布与实际类别分布之间的差异,目标是最小化这个损失函数,从而提高模型的分类性能。
| 回归类型 | 损失函数 |
|---|---|
| 线性回归 | 均方误差 (MSE) |
| 逻辑回归 | 对数损失 (Log Loss) |
4.4 应用场景
线性回归的应用场景
线性回归在许多实际应用中表现出色,尤其是在预测连续变量时。常见的应用场景包括:
- 房价预测:利用房屋的各种特征(如面积、房间数量、位置等)来预测房价。
- 销售预测:根据历史销售数据和市场趋势来预测未来的销售额。
- 气候预测:根据历史气候数据预测未来的气温、降水量等。
然而,线性回归也有一定的限制。例如,它无法有效处理非线性关系,且对异常值非常敏感。
逻辑回归的应用场景
逻辑回归主要用于分类任务,特别是在需要概率预测的情况下。常见的应用场景包括:
- 疾病预测:根据患者的症状和体检数据预测某种疾病的发生概率。
- 信用评分:根据客户的信用历史和财务状况预测其违约的概率。
- 市场营销:根据客户的行为和特征预测他们是否会响应某个营销活动。
逻辑回归模型适合处理线性可分的分类问题,但在面对复杂的非线性分类任务时可能表现不佳。
| 应用场景 | 线性回归 | 逻辑回归 |
|---|---|---|
| 房价预测 | 适合 | 不适合 |
| 销售预测 | 适合 | 不适合 |
| 疾病预测 | 不适合 | 适合 |
| 信用评分 | 不适合 | 适合 |
| 市场营销 | 不适合 | 适合 |
4.5 结论
线性回归和逻辑回归是两种基本但功能强大的回归模型,它们在目标变量类型、模型假设、损失函数和应用场景等方面具有明显的不同。线性回归适用于连续目标变量的预测,并且其假设和损失函数简单明了。而逻辑回归则适用于分类问题,能够处理离散的目标变量,并通过对数损失函数来优化模型。了解这两种回归模型的特点和适用场景,可以帮助我们在实际应用中选择最合适的模型来解决具体问题。
5. 实践中的应用与案例分析
5.1 数据预处理
数据预处理是确保机器学习模型表现优异的基础。处理不当的特征可能导致模型性能不佳,因此了解和掌握数据预处理的技术至关重要。
5.1.1 特征标准化(Feature Scaling)
特征标准化的目的是将不同特征的数值范围转化为相同的标准,以提高模型的训练效率和性能。标准化方法主要包括Z-score标准化和Min-Max标准化。
Z-score标准化:
Z-score标准化将特征的均值调整为0,方差调整为1,使得特征具有标准正态分布。公式如下:
[ z = \frac{x - \mu}{\sigma} ]
其中,(x) 是原始特征值,(\mu) 是特征的均值,(\sigma) 是特征的标准差。
Min-Max标准化:
Min-Max标准化将特征的值缩放到[0, 1]区间。公式如下:
[ x’ = \frac{x - \min(x)}{\max(x) - \min(x)} ]
这种方法在数据分布非常不均衡时较为有效。
示例代码:
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import pandas as pd# 创建示例数据
data = pd.DataFrame({'面积': [1500, 2500, 3500, 4500],'房间数量': [3, 4, 5, 6]
})# Z-score标准化
scaler = StandardScaler()
data_scaled_z = scaler.fit_transform(data)
data_scaled_z = pd.DataFrame(data_scaled_z, columns=data.columns)# Min-Max标准化
scaler = MinMaxScaler()
data_scaled_mm = scaler.fit_transform(data)
data_scaled_mm = pd.DataFrame(data_scaled_mm, columns=data.columns)print("Z-score标准化结果:\n", data_scaled_z)
print("Min-Max标准化结果:\n", data_scaled_mm)
选择标准化方法的注意事项:
- Z-score标准化适用于特征数据呈正态分布的情况。
- Min-Max标准化适用于特征范围已知且数据分布范围限制在特定区间的情况。
5.1.2 特征选择与工程(Feature Engineering)
特征选择与工程的目标是从原始数据中提取或选择出对模型预测有帮助的特征。特征工程可以显著提高模型的性能。
特征选择:
特征选择旨在减少模型的复杂度和过拟合风险。常用方法包括:
- 过滤法(Filter Methods):通过统计指标如方差、相关系数等选择特征。
- 包裹法(Wrapper Methods):通过训练和评估模型来选择特征,例如递归特征消除(RFE)。
- 嵌入法(Embedded Methods):在模型训练过程中进行特征选择,如基于L1正则化的特征选择(Lasso回归)。
特征工程:
特征工程包括创建新的特征,或者将现有特征转化为对模型更有用的形式。例如,在房价预测中,可以创建一个“房龄”特征,表示房屋建造的时间,从而可能揭示与房价的关系。
示例代码:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression# 创建示例数据
X = pd.DataFrame({'面积': [1500, 2500, 3500, 4500],'房间数量': [3, 4, 5, 6],'房龄': [10, 5, 20, 15]
})
y = pd.Series([300000, 450000, 600000, 750000])# 特征选择:递归特征消除
model = LinearRegression()
selector = RFE(model, n_features_to_select=2)
selector = selector.fit(X, y)print("选择的特征:", X.columns[selector.support_])
特征选择的注意事项:
- 特征选择可以帮助减少数据维度,降低模型复杂性。
- 特征工程能通过创造性地转换特征来显著提升模型性能。
5.2 模型评估与调优
在构建模型后,对其进行评估和调优是确保其性能和泛化能力的关键步骤。评估方法包括交叉验证,调优方法包括超参数调整。
5.2.1 交叉验证(Cross-Validation)
交叉验证是一种模型验证方法,通过将数据集分成多个子集(折),轮流使用每个子集作为验证集,其余作为训练集。这种方法能够有效地评估模型的泛化能力。
常见的交叉验证方法:
- k折交叉验证:将数据集分成k个子集,依次用每个子集作为验证集,其余k-1个子集作为训练集。
- 留一交叉验证(Leave-One-Out, LOOCV):每次只留一个样本作为验证集,其余作为训练集,适用于数据量较小的情况。
示例代码:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression# 创建示例数据
X = pd.DataFrame({'面积': [1500, 2500, 3500, 4500],'房间数量': [3, 4, 5, 6],'房龄': [10, 5, 20, 15]
})
y = pd.Series([300000, 450000, 600000, 750000])# 线性回归模型
model = LinearRegression()# 进行k折交叉验证
scores = cross_val_score(model, X, y, cv=3)
print("交叉验证的平均分数:", scores.mean())
交叉验证的注意事项:
- k折交叉验证能有效减少模型的过拟合现象。
- LOOCV适用于样本较少的情况,但计算开销较大。
5.2.2 超参数调整
超参数调整是优化模型性能的另一关键步骤。超参数是模型训练前需要设定的参数,例如线性回归中的正则化参数,逻辑回归中的C参数。
网格搜索(Grid Search):
网格搜索通过穷举所有可能的超参数组合,找出最佳的参数组合。可以使用交叉验证来评估每组参数的性能。
随机搜索(Random Search):
随机搜索通过随机选择超参数组合进行测试,通常比网格搜索更高效,特别是当超参数空间非常大时。
示例代码:
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression# 创建示例数据
X = pd.DataFrame({'访问频率': [10, 20, 30, 40],'服务投诉次数': [1, 2, 3, 4]
})
y = pd.Series([0, 1, 1, 0])# 逻辑回归模型
model = LogisticRegression()# 超参数网格
param_grid = {'C': [0.1, 1, 10],'penalty': ['l1', 'l2']
}# 网格搜索
grid_search = GridSearchCV(model, param_grid, cv=3)
grid_search.fit(X, y)print("最佳超参数组合:", grid_search.best_params_)
超参数调整的注意事项:
- 网格搜索适用于超参数空间较小的情况,计算开销较大。
- 随机搜索适用于超参数空间较大或计算资源有限的情况。
5.3 实际案例
5.3.1 线性回归案例:房价预测
房价预测是线性回归的经典应用场景。通过分析房屋特征数据(如面积、房间数量、房龄等),我们可以建立一个线性回归模型来预测房价。
数据准备:
收集房屋的特征数据和对应的房价,并进行数据预处理和特征选择。
模型训练:
使用线性回归模型进行训练,评估模型的性能,使用交叉验证来避免过拟合。
示例代码:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split# 创建示例数据
X = pd.DataFrame({'面积': [1500, 2500, 3500, 4500],'房间数量': [3, 4, 5, 6],'房龄': [10, 5, 20, 15]
})
y = pd.Series([300000, 450000, 600000, 750000])# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)# 模型预测
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)print("均方误差:", mse)
分析:
- 房价预测模型能够帮助房地产公司根据房屋特征预测价格,为买卖双方提供参考。
- 特征重要性分析能够揭示哪些特征对房价的影响最大。
5.3.2 逻辑回归案例:客户流失预测
客户流失预测是逻辑回归的常见应用场景。通过分析客户的行为数据(如访问频率、服务投诉次数等),可以建立逻辑回归模型来预测客户是否会流失。
数据准备:
收集客户行为数据和流失标签,进行数据清洗和特征工程。
模型训练:
使用逻辑回归模型进行训练,评估模型性能,利用交叉验证和超参数调优来提高模型的准确性。
示例代码:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split# 创建示例数据
X = pd.DataFrame({'访问频率': [10, 20, 30, 40],'服务投诉次数': [1, 2, 3, 4]
})
y = pd.Series([0, 1, 1, 0])# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 模型训练
model = LogisticRegression()
model.fit(X_train, y_train)# 模型预测
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
分析:
- 客户流失预测模型能够帮助企业识别潜在流失客户,制定挽留策略。
- 模型的预测结果可以用于制定有针对性的营销和客户服务计划。
结论
在实际应用中,线性回归和逻辑回归模型的有效性不仅取决于算法本身,还依赖于数据预处理、模型评估与调优等多个环节。通过合理的数据预处理、准确的特征选择和工程、有效的模型评估与调优,可以显著提升模型的性能和可靠性。实际案例中的分析展示了如何将理论应用于实践,解决现实世界中的复杂问题。
相关文章:
线性回归和逻辑回归揭示数据的隐藏模式:理论与实践全解析
机器学习之线性回归和逻辑回归 1. 简介1.1 机器学习概述1.2 监督学习的定义与重要性1.3 线性回归和逻辑回归在监督学习中的作用1.3.1 线性回归1.3.2 逻辑回归 2. 线性回归(Linear Regression)2.1 定义与目标2.1.1 回归问题的定义2.1.2 预测连续目标变量 …...

掌握采购询价软件:高效比较供应商报价的技巧
在企业运营中,获取所需的产品往往是一项复杂且耗时的任务,这涉及多个环节和流程。然而,借助电子采购询价(RFQ)系统,许多原本需要采购员手动完成的任务可以自动化运行,从而提高了效率。 那么问题…...

AMQP-核心概念-终章
本文参考以下链接摘录翻译: https://www.rabbitmq.com/tutorials/amqp-concepts 连接(Connections) AMQP 0-9-1连接通常是长期保持的。AMQP 0-9-1是一个应用级别的协议,它使用TCP来实现可靠传输。连接使用认证且可以使用TLS保护…...
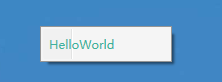
在WPF中使用WebView2详解
Microsoft Edge WebView2 Microsoft Edge WebView2 控件允许在本机应用中嵌入 web 技术(HTML、CSS 以及 JavaScript)。 WebView2 控件使用 Microsoft Edge 作为绘制引擎,以在本机应用中显示 web 内容。 使用 WebView2 可以在本机应用的不同部分嵌入 Web 代码&…...

僵尸进程的例子
以下是一个简单的C语言程序示例,该程序将创建一个子进程,然后子进程退出,但是父进程不会调用wait()或waitpid()来回收子进程的状态,从而使得子进程成为僵尸进程。 #include <stdio.h> #include <stdlib.h> #include …...

消息中间件分享
消息中间件分享 1 为什么使用消息队列2 消息队列有什么缺点3 如何保证消息队列的高可用4 如何处理消息丢失的问题?5 如何保证消息的顺序性1 为什么使用消息队列 解耦、异步、削峰 解耦 不使用中间件的场景 使用中间件的场景 异步 不使用中间件 使用中间件 削峰 不使…...

12. kubernetes调度——污点Taint和容忍Toleration
kubernetes调度——污点Taint和容忍Toleration 一、通过节点属性调度1、节点名称2、节点标签2.1 查看节点标签2.2 添加标签2.3 修改标签2.4 删除标签2.5 通过节点标签进行调度 二、污点Taint和容忍Toleration1、污点Taint1.1 查看Master节点的污点1.2 添加污点1.3 删除污点 2、…...

第100+18步 ChatGPT学习:R实现SVM分类
基于R 4.2.2版本演示 一、写在前面 有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。 答曰:可!用GPT或者Kimi转一下就得了呗。 加上最近也没啥内容写了,就帮各位搬运一下吧。 二、R代码实现SVM分类 (1&a…...

react函数学习——useState函数
在 React 中,useState 是一个钩子(hook),用于在函数组件中添加状态管理功能。它返回一个数组,包含两个元素: 当前状态值(selectedValue):这是状态的当前值。更新状态的函…...

方天云智慧平台系统 GetCompanyItem SQL注入漏洞复现
0x01 产品简介 方天云智慧平台系统,作为方天科技公司的重要产品,是一款面向企业全流程的业务管理功能平台,集成了ERP(企业资源规划)、MES(车间执行系统)、APS(先进规划与排程)、PLM(产品生命周期)、CRM(客户关系管理)等多种功能模块,旨在通过云端服务为企业提供…...

C语言同时在一行声明指针和整型变量
如果这么写, int *f, g; 并没有声明2个指针,编译器自己会识别,f是一个指针,g是一个整型变量; void CTszbView::OnDraw(CDC* pDC) {CTszbDoc* pDoc GetDocument();ASSERT_VALID(pDoc);// TODO: add draw code for nat…...

thinkphp框架远程代码执行
一、环境 vulfocus网上自行下载 启动命令: docker run -d --privileged -p 8081:80 -v /var/run/docker.sock:/var/run/docker.sock -e VUL_IP192.168.131.144 8e55f85571c8 一定添加--privileged不然只能拉取环境首页不显示 二、thinkphp远程代码执行 首页&a…...

【公式】博弈论中的核心算法:纳什均衡公式解析
博弈论中的核心算法:纳什均衡公式解析 纳什均衡的基本概念 纳什均衡是博弈论中的一个核心概念,它描述了一个博弈中所有参与者都无法通过单方面改变自己的策略来增加收益的状态。在纳什均衡状态下,每个参与者的策略都是对其他参与者策略的最优反应。纳什均衡的公式可以表示…...

计算机网络面试题2
WebSocket相关知识 什么是WebSocket? WebSocket是一种基于TCP连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据 WebSocket和HTTP有什么区别? 1.WebSocket是双向通信协议,HTTP是单向通信协议 2.WebSocket使用ws://或者wss:/…...

Linux网络——深入理解传入层协议TCP
目录 一、前导知识 1.1 TCP协议段格式 1.2 TCP全双工本质 二、三次握手 2.1 标记位 2.2 三次握手 2.3 捎带应答 2.4 标记位 RST 三、四次挥手 3.1 标记位 FIN 四、确认应答(ACK)机制 五、超时重传机制 六 TCP 流量控制 6.1 16位窗口大小 6.2 标记位 PSH 6.3 标记…...

快速搞定分布式RabbitMQ---RabbitMQ进阶与实战
本篇内容是本人精心整理;主要讲述RabbitMQ的核心特性;RabbitMQ的环境搭建与控制台的详解;RabbitMQ的核心API;RabbitMQ的高级特性;RabbitMQ集群的搭建;还会做RabbitMQ和Springboot的整合;内容会比较多&#…...
)
5万字长文吃透快手大数据面试题及参考答案(持续更新)
目录 Flink为什么用aggregate()不用process() 为什么使用aggregate() 为什么不用process() 自定义UDF, UDTF实现步骤,有哪些方法?UDTF中的ObjectInspector了解吗? 自定义UDF实现步骤 自定义UDTF实现步骤 UDTF中的ObjectInspector Spark Streaming和Flink的区别 Flu…...

WordPress原创插件:启用关闭经典编辑器和小工具
WordPress原创插件:启用关闭经典编辑器和小工具 主要功能 如图所示,用于启用或禁用经典编辑器和经典小工具,以替代Gutenberg编辑器。 插件下载 https://download.csdn.net/download/huayula/89592822...

萝卜快跑:自动驾驶的先锋与挑战
萝卜快跑:自动驾驶的先锋与挑战 萝卜快跑作为自动驾驶领域的重要参与者,被视为自动驾驶的先锋。它代表了自动驾驶技术在实际应用中的重要突破,为人们的出行方式带来了革新。萝卜快跑的发展展示了自动驾驶技术的巨大潜力,如提高交通…...

得到xml所有label 名字和数量 get_xml_lab.py,get_json_lab.py
import os import xml.etree.ElementTree as ETrootdir2 r"F:\images3\xmls" file_list os.listdir(rootdir2) # 列出文件夹下所有的目录与文件# 初始化字典 classes_dict {}for file_name in file_list:path os.path.join(rootdir2, file_name)if os.path.isfi…...

Flutter 布局系统:构建响应式界面
Flutter 布局系统:构建响应式界面掌握 Flutter 布局系统的核心概念和最佳实践。一、布局系统概述 作为一名追求像素级还原的 UI 匠人,我深知布局系统在 Flutter 开发中的重要性。Flutter 提供了一套强大的布局系统,让我们能够创建各种复杂的界…...

Python flask django框架的社区残障人士服务平台的设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商功能模块设计用户管理模块服务匹配模块无障碍交互模块社区支持模块数据安全与后台管理技术实现要点Flask/Django选型对比数据库设计关键API示例(Django)无障碍前端适配部署与扩展项目技术支持源码获取详细视频…...

Unity3D WEBGL避坑指南:从AssetBundle初始化到PDF显示的全流程解决方案
Unity3D WEBGL开发实战:AssetBundle与PDF显示的深度优化方案 在跨平台游戏开发领域,Unity3D的WEBGL导出功能为开发者打开了浏览器端部署的大门。然而,从桌面端到WEBGL平台的转换远非简单的导出操作,特别是当项目涉及AssetBundle动…...

给嵌入式新人的第一课:用CubeMX和HAL库,5分钟搞定STM32F407ZGT6的LED灯
给嵌入式新人的第一课:用CubeMX和HAL库,5分钟搞定STM32F407ZGT6的LED灯 当你第一次听说"嵌入式开发"时,脑海中浮现的可能是密密麻麻的电路板和复杂的寄存器配置。但今天我要告诉你一个秘密:现代嵌入式开发已经变得像在V…...

彻底告别风扇噪音:用FanControl 264版实现电脑静音控制的终极指南
彻底告别风扇噪音:用FanControl 264版实现电脑静音控制的终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_…...

汇川PLC编写,设备状态机的实现以及实际案例使用,针对设备的多种状态进行区分,有单独状态和叠加...
汇川PLC编写,设备状态机的实现以及实际案例使用,针对设备的多种状态进行区分,有单独状态和叠加态的实现方式在工业自动化项目里,设备状态机就像给机器装了个智能开关板。最近调试包装产线时发现,设备动不动就卡在"…...

从零构建ZigBee开发环境:IAR for 8051 10.30.1实战指南
1. 为什么选择IAR for 8051开发ZigBee? 刚接触ZigBee开发的朋友们可能都有这样的困惑:市面上有那么多开发工具,为什么要用IAR for 8051?这个问题我十年前刚开始做智能家居时就遇到过。当时为了给一个智能灯泡项目选型,…...

拒绝代码审查:神经民主开发模式宣言
一场迟到的变革在软件开发的漫长历史中,代码审查(Code Review)已被奉为保障质量的金科玉律。无数指南、流程和工具围绕它构建,将其塑造成交付可靠软件不可或缺的环节。对于测试从业者而言,它更是质量防线前移、从“验证…...
5步掌握HSTracker:炉石传说开源套牌管理工具全攻略
5步掌握HSTracker:炉石传说开源套牌管理工具全攻略 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 在炉石传说的对战中,你是否曾因记不清对手剩余…...

WSABuilds:3种架构适配+5分钟部署,打造Windows安卓开发与运行环境
WSABuilds:3种架构适配5分钟部署,打造Windows安卓开发与运行环境 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk …...