PyTorch深度学习快速入门(下)
PyTorch深度学习快速入门(下)
- 一、现有网络模型的使用及修改
- (一)背景知识
- (二)修改网络模型的三种方法
- 二、网络模型的保存与加载
- (一)保存网络模型的两种方法
- (二)加载网络模型的两种方法
- 三、完整的模型训练套路
- (一)背景知识
- (二)代码实战
- 四、GPU 训练
- (一)训练方式1 — 调用 .cuda( ) 来改
- (二)训练方式2 — 调用 .to( device ) 来改
- 五、完整的模型验证套路(测试 / demo)
- 六、看看GitHub上的开源项目
- (一)看一个项目,先看README
- (二)再看 train.py 文件中的整体架构
- (三)将函数中 required=True 的地方用 default= ……替换
一、现有网络模型的使用及修改
(一)背景知识
(1)本质:迁移学习,即利用现有的网络,去改变它的结构(微调)
(2)所用模型与数据集的解介绍



(3)pretrained设置为True或False的区别
- False:只是加载了网络架构,参数都是初始化的默认参数
- True:从网络中下载每个卷积层在数据集上训练好的参数

(二)修改网络模型的三种方法
import torchvision
from torch import nn# traindata = torchvision.datasets.ImageNet("./data_image_net",split='train',download=True,
# transform=torchvision.transforms.ToTensor())
# The dataset is no longer publicly accessible. You need to download the archives externally and place them in the root directory.# False:只是加载了网络架构,参数都是初始化的默认参数
# True:从网络中下载每个卷积层在数据集上训练好的参数
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)print(vgg16_true)
# CIFAR10 只把数据分成了 10 类,而加载的 vgg16 这个模型把数据分成了 1000 个类,需要修改
# vgg16_true.add_module('add_linear',nn.Linear(1000,10)) # 加在 VGG 大类中加
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10)) #在 classifier 最后加
print(vgg16_true)print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096,10) # 修改网络模型
print(vgg16_false)

二、网络模型的保存与加载
(一)保存网络模型的两种方法
- 保存方式一:保存了 模型结构 + 模型参数
- 保存方式二:将网络模型中的参数保存成字典,没有了结构,只保存了模型参数(官方推荐,文件小)

model_save.py文件
import torch
import torchvision
from torch import nnvgg16 = torchvision.models.vgg16(pretrained=False)# 保存方式一:保存了 模型结构 + 模型参数
# pth文件是 PyTorch 中常用的一种文件格式,主要用于 保存和加载 模型的参数
torch.save(vgg16,"vgg16_method1.pth")# 保存方式二:将网络模型中的参数保存成字典,没有了结构,只保存了模型参数(官方推荐,文件小)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")# 陷阱
class Li(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,64,3)def forward(self,x):x = self.conv(x)return xli = Li()
torch.save(li,"li_method1.pth")
运行完程序后,在终端中输入 dir即可查看到文件相关信息

mac 里面的 ls(list) == windows 里面的 dir(directory)
(二)加载网络模型的两种方法
- 加载模型方式一 对应 保存方式一
- 加载模型方式二 对应 保存方式二:字典形式,无结构
另:如果要恢复网络模型结构
Step1:新建网络模型结构(默认没有参数)
Step2:通过字典形式加载参数(别人训练好的参数)
model_load.py文件
# import torch
# import torchvision
from model_save import * # *代表导入当前目录下的所有函数 (陷阱的解决方法)# 加载模型方式一:--> 保存方式一
model = torch.load("vgg16_method1.pth")
print(model)# 加载模型方式二:--> 保存方式二:字典形式,无结构
# model = torch.load("vgg16_method2.pth")
# 如果要恢复网络模型结构
# Step1:新建网络模型结构,但是没有参数
vgg16 = torchvision.models.vgg16(pretrained=False)
# Step2:通过字典形式加载参数(别人训练好的参数)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
# 此方式在自己的数据集上训练达到理想的效果了之后# 陷阱
model = torch.load("li_method1.pth")
print(model)
# Can't get attribute 'Li' on <module '__main__' from 'D:\\Python\\pythonProject3\\model_load.py'>
# 要把 model_save 中的网络架构复制过来才行,或者直接 import 过来
注:
加载模型的时候,要把 model_save 中的网络架构复制过来才行,或者直接 import 过来
三、完整的模型训练套路
(一)背景知识
(1)有 Dropout,BatchNorm 层才需要在 训练/测试前 把网络设置成 训练/测试模式


(2)分类问题中,正确率指标的计算方法

outputs = torch.tensor([0.1,0.2],[0.3,0.4])
# print(outputs.argmax(1)) # 填 1 的时候横向看,填 0 的时候纵向看(填标号的方向)
# 输出 tensor([1,1]) --> 横向来看:第一行预测在 1 位置,第二行也预测在 1 位置
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
# print(preds == targets) # 输出 tensor([False,True])
print((preds == targets).sum()) # 输出 tensor(1) 计算出对应位置相等的个数,这里正确的个数为1
(3)tensor 类型加不加 .item( ) 的区别
a = torch.tensor(5)
print(a) # 打印 tensor(5)
print(a.item()) # 打印 5
(4)验证集 != 测试集
数据集分3部分:
1)训练集:训练神经网络(平时练习)
2)验证集:看网络效果、修改参数,防止模型过拟合(模拟考)
3)测试集:是最后一步,看网络怎么样(高考)
(5)训练网络的大体流程
准备数据集、dataloader加载数据集,搭建网络模型,创建网络模型实例,定义损失函数,定义优化器,设置网络训练的参数,开始训练,验证模型,最后保存模型。可以将训练结果展示
(二)代码实战
model.py
import torch
from torch import nnclass Li(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self,x):x = self.model(x)return x# 可测试网络的正确性
if __name__ == '__main__': # 相当于 mainli = Li()input = torch.ones((64,3,32,32)) # batch_size = 64,代表有 64 张图片output = li(input)print(output.shape)# 输出 torch.Size([64, 10]) # 含义:返回 64 行数据,每一行数据上面有 10 个数据(代表每一张图片在 10 个类别当中的概率)
# 另:__name__ == '__main__':下的代码只有在文件作为脚本直接执行时,才会被执行
# 而该.py脚本被 import 到其他脚本中去时,其下的代码就不会被执行
train.py
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import * # 1、被引用的 python 文件首字母不能为数字符号 2、两个文件必须在一个文件夹底下# 准备数据集 (下载数据集,并加载到内存中)
train_data = torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 数据集的长度 (批量处理数据,提供一个迭代访问的接口)
train_data_size = len(train_data) # ctr + D 复制此行内容到下一行
test_data_size = len(test_data)
print(f"训练数据集的长度为:{train_data_size}")
print(f"测试数据集的长度为:{test_data_size}")
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64) # DataLoader 是类,Dataloader 是库
test_dataloader = DataLoader(test_data,batch_size=64)# 搭建神经网络
# 创建网络模型
li = Li()# 创建损失函数 mse用于回归,crossentropy 用于分类
loss_fn = nn.CrossEntropyLoss() # 参数为 optional 即为可选的
# 优化器 SGD(随机梯度下降) parameter:参数
# learning_rate = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(li.parameters(),lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10# 添加 tensorboard,画图出来
writer = SummaryWriter("../logs_train")for i in range(epoch):print(f"-----------第{i+1}轮训练开始-----------")# Step1:训练步骤开始li.train() # 有 Dropout, BatchNorm 层才需要调用for data in train_dataloader:imgs,targets = dataoutputs = li(imgs) # 是 10 个类别中的某一个,也就是训练的标准loss = loss_fn(outputs,targets)# 优化器优化模型 --> 梯度清零、反向传播、参数优化、变量加一optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print(f"训练次数:{total_train_step},Loss:{loss.item()}")writer.add_scalar("train_loss",loss.item(),total_train_step)# Step2:测试步骤开始(不需要调优,在现有的模型上测试),看看模型有没有训练好,是否达到需求li.eval() # 有 Dropout,BatchNorm 层才需要调用total_test_loss = 0 # 想求整个数据集上的 losstotal_accuracy = 0 # 想知道整体正确的个数,正确率:分类问题中特有的衡量指标with torch.no_grad(): # 不调优了for data in test_dataloader:imgs,targets = dataoutputs = li(imgs)loss = loss_fn(outputs,targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum() # outputs.argmax(1) 横向比较单张图片的各种类别概率,求最大total_accuracy = total_accuracy + accuracy # 整个测试集上正确的个数total_test_step = total_test_step + 1print(f"整体测试集上的Loss:{total_test_loss}")print(f"整体测试集上的正确率:{total_accuracy/test_data_size}")writer.add_scalar("test_loss",total_test_loss,total_test_step) # 深色线:平滑处理,浅色线:真实曲线writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)# Step3:保存每一轮训练的模型结果torch.save(li,f"li_{i}.pth")# torch.save(li.state_dict(),f"li_{}.pth")print("模型已保存")writer.close()


四、GPU 训练
用GPU训练,只需要改动代码中网络模型、数据(输入图片&标注)、损失函数这三个部分即可
(一)训练方式1 — 调用 .cuda( ) 来改
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time # 用来计时# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练数据集的长度为:{train_data_size}")
print(f"测试数据集的长度为:{test_data_size}")
# 加载数据集
train_dataloader = DataLoader(train_data,batch_size=64) # DataLoader是类,Dataloader是库
test_dataloader = DataLoader(test_data,batch_size=64)# 搭建神经网络
class Li(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self,x):x = self.model(x)return x# <<<<<<<<<<<网络模型>>>>>>>>>>>>>
li = Li()
#################################################################
if torch.cuda.is_available():li = li.cuda() # Moves all model parameters and buffers to the GPU
################################################################## <<<<<<<<<<<损失函数>>>>>>>>>>>>>
loss_fn = nn.CrossEntropyLoss()
#################################################################
if torch.cuda.is_available():loss_fn = loss_fn.cuda()
################################################################## 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(li.parameters(),lr=learning_rate)total_train_step = 0
total_test_step = 0
epoch = 10writer = SummaryWriter("../logs_train")
start_time = time.time() # 用 time 库中的 .time() 记录当前时间for i in range(epoch):print(f"-----------第{i+1}轮训练开始-----------")# 训练步骤开始li.train() for data in train_dataloader:# <<<<<<<<<<<数据>>>>>>>>>>>>>imgs,targets = data########################################if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()########################################outputs = li(imgs) loss = loss_fn(outputs,targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time() # 用 time 库中的 .time() 记录当前时间print(end_time - start_time)print(f"训练次数:{total_train_step},Loss:{loss.item()}")writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始li.eval()total_test_loss = 0total_accuracy = 0 with torch.no_grad(): for data in test_dataloader:# <<<<<<<<<<<数据>>>>>>>>>>>>>imgs,targets = data########################################if torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()########################################outputs = li(imgs)loss = loss_fn(outputs,targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracyprint(f"整体测试集上的Loss:{total_test_loss}")print(f"整体测试集上的正确率:{total_accuracy/test_data_size}")writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step = total_test_step + 1# 保存每一轮训练的结果torch.save(li,f"li_{i}.pth")# torch.save(li.state_dict(),f"li_{}.pth")print("模型已保存")writer.close()
查看云端GPU的配置
运行程序


(二)训练方式2 — 调用 .to( device ) 来改
可以用 device = torch.device(“cuda:序号”) 来指定用电脑中那一张显卡
device = torch.device(“cuda”) 和 device = torch.device(“cuda:0”) 两者无差别
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time ##########################################################
# <<<<<<<<<<<<<定义训练的设备>>>>>>>>>>>>>>>
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 语法糖
device = torch.device("cuda") # 更常用
########################################################### 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练数据集的长度为:{train_data_size}")
print(f"测试数据集的长度为:{test_data_size}")
# 加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 搭建神经网络
class Li(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self,x):x = self.model(x)return x# <<<<<<<<<<<<<网络模型>>>>>>>>>>>>>>>
li = Li()
##########################################################
# li = li.to(device) # 将网络转移到设备上去
li.to(device)
########################################################### <<<<<<<<<<<<<损失函数>>>>>>>>>>>>>>>
loss_fn = nn.CrossEntropyLoss()
##########################################################
# loss_fn = loss_fn.to(device)
loss_fn.to(device)
########################################################### 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(li.parameters(),lr=learning_rate)total_train_step = 0
total_test_step = 0
epoch = 10writer = SummaryWriter("../logs_train")
start_time = time.time()for i in range(epoch):print(f"-----------第{i+1}轮训练开始-----------")# 训练步骤开始li.train()for data in train_dataloader:imgs,targets = data#################################################imgs = imgs.to(device)targets = targets.to(device)#################################################outputs = li(imgs) loss = loss_fn(outputs,targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print(f"训练次数:{total_train_step},Loss:{loss.item()}")writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始li.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs,targets = data##########################################imgs = imgs.to(device)targets = targets.to(device)##########################################outputs = li(imgs)loss = loss_fn(outputs,targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracyprint(f"整体测试集上的Loss:{total_test_loss}")print(f"整体测试集上的正确率:{total_accuracy/test_data_size}")writer.add_scalar("test_loss",total_test_loss,total_test_step) writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step = total_test_step + 1# 保存每一轮训练的结果torch.save(li,f"li_{i}.pth")# torch.save(li.state_dict(),f"li_{}.pth")print("模型已保存")writer.close()
五、完整的模型验证套路(测试 / demo)
利用已经训练好的模型,给它提供输入(应用到实际的环境当中,下面随便找到物体图片就是应用)

import torch
import torchvision
from PIL import Image
from torch import nnimage_path = "../imgs/dog.png" # ../ 到上一层级文件夹里找
image = Image.open(image_path)
print(image)
# <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=348x238 at 0x135148BC6A0>
# png格式是 4 通道(RGBA):除 RGB 三通道外,还有一个透明度通道。但我们只想保留其颜色通道
image = image.convert('RGB')# 要将图片调整成符合要调用的网络模型的大小,才可正常输入
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])image = transform(image)
print(image.shape)class Li(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self,x):x = self.model(x)return x# 加载网络模型
# 注:在CPU上加载GPU上训练的模型,要加映射 map_location
model = torch.load("../complete_model_training/li_29_gpu.pth",map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image,(1,3,32,32)) # 网络训练往往需要bach_sizes
model.eval() # 将模型转化为测试类型
with torch.no_grad(): # with 自动处理对文件的关闭操作output = model(image)
print(output)print(output.argmax(1))



六、看看GitHub上的开源项目
(一)看一个项目,先看README
里面有安装、训练、测试模型的方法,需要环境配置的版本,还需要注意什么等


(二)再看 train.py 文件中的整体架构



(三)将函数中 required=True 的地方用 default= ……替换


完
相关文章:
PyTorch深度学习快速入门(下)
PyTorch深度学习快速入门(下) 一、现有网络模型的使用及修改(一)背景知识(二)修改网络模型的三种方法 二、网络模型的保存与加载(一)保存网络模型的两种方法(二ÿ…...

轻松入门Linux—CentOS,直接拿捏 —/— <1>
一、什么是Linux Linux是一个开源的操作系统,目前是市面上占有率极高的服务器操作系统,目前其分支有很多。是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统 Linux能运行主要的UNIX工具软件、应用程序和网络协议 Linux支持 32…...

pandas安装以及导入CSV
安装pandas pip install pandas速度慢可以切换国内镜像源 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas执行导入csv操作 import pandas as pd# 读取csv文件 data pd.read_csv(yourPath)输入data查看数据 导入成功!...
新能源车浪潮来袭,同时存在高压低压系统,如何准确进行高低压布线间距EMC分析?
摘要 随着车辆电气化水平的逐步提升,电气零部件布局和布线面临着前所未有的挑战,在不断的压缩电气零部件间间距后,EMC性能成为非常关键的性能指标。特别是对于新能源车型,同时存在高压和低压系统,高低压耦合若处理的不…...

QUIC 协议
详解 QUIC 协议:它为何比 TCP 更优越?...
【软件测试】--接口测试
1. 接口用例设计 接口测试的测试点 功能测试 单接口功能: 手工测试中的单个业务模块,一般对应一个接口 登陆业务 --> 登陆接口加入购物车业务 --> 加入购物车接口订单业务 --> 订单接口支付业务 --> 支付接口 借助工具、代码。绕开前端界面…...

【前端】上传视频,截取第一帧图片
使用input上传视频,获得视频的第一帧 参考:JavaScript获取视频的尺寸信息和第一帧图片 - 掘金 (juejin.cn) html: <inputbind:this{uploadRef}on:change{handleUpload}accept"video/*"type"file"/>视频类型校验&a…...

Redis-GEO数据结构的基本用法
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有: GEOADD:添加一个地理空间信息,包含:经度…...

【Linux C | 网络编程】进程池大文件传输的实现详解(三)
上一篇实现了进程池的小文件传输,使用自定义的协议,数据长度数据本身,类似小火车的形式,可以很好的解决TCP“粘包”的问题。 【Linux C | 网络编程】进程池小文件传输的实现详解(二) 当文件的内容大小少于…...

Mac如何通过SSH连接Github
目录 前言 一、实现步骤 1.生成 SSH 密钥对 2.添加 SSH 密钥到 GitHub: 3.配置 SSH 连接 1.更新远程仓库 URL 2.测试 SSH 连接 前言 GitHub 在 2021 年 8 月 13 日停止了对使用密码进行身份验证的支持。因此,你需要使用其他认证方式,如…...

成就巴西休闲游戏如何借助Google谷歌广告投放优势
在探讨巴西休闲游戏如何借助谷歌广告投放优势实现市场扩张的过程中,我们不得不深入分析巴西市场的独特属性、休闲游戏的兴起背景,以及谷歌广告平台在全球范围内的强大影响力。近年来,随着移动游戏市场的快速发展,特别是中轻度休闲…...

利用python检查磁盘空间使用情况
目录 一.前言 二.使用的库介绍 三.代码实现以及解析 3.1导入模块 3.2邮件发送函数 send_email 3.3检查磁盘空间函数 check_and_clean_disk 3.4主程序逻辑 四.致谢 一.前言 在信息技术飞速发展的今天,数据量的激增使得磁盘空间管理成为系统运维中的一项基…...

卷积神经网络(五)---图像增强的方法
前面的部分专注于卷积神经网络的层结构介绍,同时还介绍了到目前为止比较出名的卷积神经网络,接着使用比较复杂的卷积神经网络提高了 MNIST 数据集的准确率。下面将从另外的角度——图像增强的方面入手,提高模型的准确率和泛化能力。 一直以来…...

矩阵常见分解算法及其在SLAM中的应用
文章目录 常见特殊矩阵定义Cholesky分解(正定Hermittian矩阵,分解结果唯一)Cholesky分解应用 SVD分解(将singularvalues排序后分解唯一)SVD 分解的应用(任意矩阵) QR分解(任意矩阵&a…...
【排序】快速排序详解
✨✨欢迎大家来到Celia的博客✨✨ 🎉🎉创作不易,请点赞关注,多多支持哦🎉🎉 所属专栏:排序 个人主页:Celias blog~ 一、快速排序的思想 快速排序的核心思想是: 选定一个…...

贪心算法总结(2)
一、买卖股票的最佳时机 . - 力扣(LeetCode) class Solution { public:int maxProfit(vector<int>& prices) {int miniINT_MAX;int ret0;for(int&price:prices){//遍历的时候,我们随时去更新最小的值,然后让每一位…...

弘景光电:技术实力与创新驱动并进
在光学镜头及摄像模组产品领域,广东弘景光电科技股份有限公司(以下简称“弘景光电”)无疑是一颗耀眼的明星。自成立以来,弘景光电凭借其强大的研发实力、卓越的产品性能、精密的制造工艺以及严格的质量管理体系,在光学…...

2024年7月23日~2024年7月29日周报
目录 一、前言 二、完成情况 2.1 一种具有边缘增强特点的医学图像分割网络 2.2 融合边缘增强注意力机制和 U-Net 网络的医学图像分割 2.3 遇到的困难 三、下周计划 一、前言 上周参加了一些师兄师姐的论文讨论会议,并完成了初稿。 本周继续修改论文࿰…...

M3U8流视频数据爬虫
M3U8流视频数据爬虫 HLS技术介绍 现在大部分视频客户端都采用HTTP Live Streaming(HLS,Apple为了提高流播效率开发的技术),而不是直接播放MP4等视频文件。HLS技术的特点是将流媒体切分为若干【TS片段】(比如几秒一段…...

保护您的数字财富:模块化沙箱在源代码防泄露中的突破
在数字化浪潮中,企业面临着前所未有的数据安全挑战。源代码、商业机密、客户数据……这些宝贵的数字资产一旦泄露,后果不堪设想。SDC沙盒防泄密系统,以其卓越的技术实力和创新的解决方案,为企业提供了一个坚不可摧的安全屏障。 核…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...
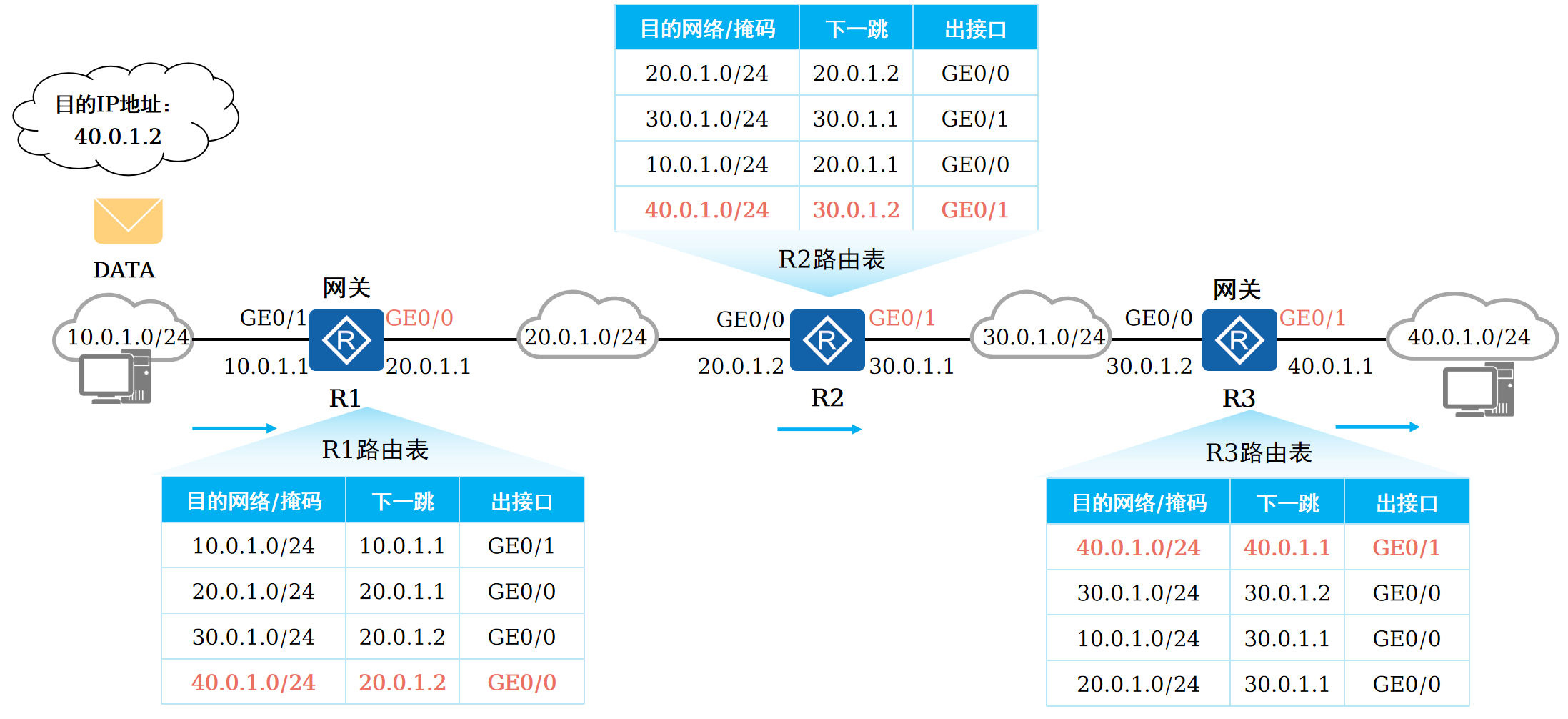
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...