【Django5】模型定义与使用
系列文章目录
第一章 Django使用的基础知识
第二章 setting.py文件的配置
第三章 路由的定义与使用
第四章 视图的定义与使用
第五章 二进制文件下载响应
第六章 Http请求&HttpRequest请求类
第七章 会话管理(Cookies&Session)
第八章 文件上传实现
第九章 多种视图view
第十章 Django5模板引擎
第十一章 模型定义与使用
第十二章 ORM执行SQL语句和事务
第十三章 表单定义与使用
第十四章 内置Admin系统
第十五章 内置Auth认证系统
文章目录
- 系列文章目录
- 前言
- 模型定义
- 模型数据迁移
- 模型查询
- 模型分页查询
- 高级查询匹配符
- 模型多表查询
- 模型数据新增
- 模型数据修改
- 模板删除数据
- 总结
前言
Django5对各种数据库提供了很好的支持,包括PostgreSQL、MySQL、SQLite和 Oracle,而且为这些数据库提供了统一的API方法,这些API统称为ORM框架。通过使用Django5内置的ORM框架可以实现数据库连接和读写操作。
模型定义
ORM框架是一种程序技术,用于实现面向对象编程语言中不同类型系统的数据之间的转换。 从效果上说,它创建了一个可在编程语言中使用的“虚拟对象数据库”,通过对虚拟对象数据库的操作从而实现对目标数据库的操作,虚拟对象数据库与目标数据库是相互对应的。在 Django5中,虚拟对象数据库也称为模型,通过模型实现对目标数据库的读写操作,实现方法如下:
1.配置目标数据库,在settings.py中设置配置属性
2.构建虚拟对象数据库,在App 的models.py文件中以类的形式定义模型。
3.通过模型在目标数据库中创建相应的数据表。
4.在其他模块(如视图函数)里使用模型来实现目标数据库的读写操作。
settings.py下我们配置mysql数据库:

模型字段类型如下:
-
AutoField:自增长类型,数据表的字段类型为整数,长度为11位。
-
BigAutoField:自增长类型,数据表的字段类型为bigint,长度为20位。
-
CharField:字符类型。
-
BooleanField:布尔类型。
-
CommaSeparatedIntegerField:用逗号分割的整数类型。
-
DateField:日期( Date)类型。
-
DateTimeField:日期时间( Datetime)类型。Decimal:十进制小数类型。
-
EmailField:字符类型,存储邮箱格式的字符串。
-
FloatField:浮点数类型,数据表的字段类型变成Double类型。IntegerField:整数类型,数据表的字段类型为11位的整数。
-
BigIntegerField:长整数类型。
-
IPAddressField:字符类型,存储Ipv4地址的字符串。
-
GenericIPAddressField:字符类型,存储Ipv4和Ipv6地址的字符串。
-
NullBooleanField:允许为空的布尔类型。
-
PositiveIntegerFiel:正整数的整数类型。
-
PositiveSmallIntegerField:小正整数类型,取值范围为0~32767。
-
SlugField:字符类型,包含字母、数字、下画线和连字符的字符串。
-
SmallIntegerField:小整数类型,取值范围为-32,768~+32,767。
-
TextField:长文本类型。
-
TimeField:时间类型,显示时分秒HH:MM[ :ss[.uuuuuu]]。
-
URLField:字符类型,存储路由格式的字符串。
-
BinaryField:二进制数据类型。
-
FileField:字符类型,存储文件路径的字符串。
-
ImageField:字符类型,存储图片路径的字符串。
-
FilePathField:字符类型,从特定的文件目录选择某个文件。
模型字段参数如下:
-
verbose_name:默认为None,在 Admin站点管理设置字段的显示名称。
-
primary_key:默认为False,若为True,则将字段设置成主键。
-
max_length:默认为None,设置字段的最大长度。
-
unique:默认为False,若为True,则设置字段的唯一属性。
-
blank:默认为False,若为True,则字段允许为空值,数据库将存储空字符串。
-
null:默认为False,若为True,则字段允许为空值,数据库表现为NULL。
-
db_index:默认为False,若为True,则以此字段来创建数据库索引。default:默认为NOT_PROVIDED对象,设置字段的默认值。
-
editable:默认为True,允许字段可编辑,用于设置Admin的新增数据的字段。
-
serialize:默认为True,允许字段序列化,可将数据转化为JSON格式。
-
unique_for_date:默认为None,设置日期字段的唯一性。
-
unique_for_month:默认为None,设置日期字段月份的唯一性。
-
unique_for_year:默认为None,设置日期字段年份的唯一性。choices:默认为空列表,设置字段的可选值。
-
help_text:默认为空字符串,用于设置表单的提示信息。
-
db_column:默认为None,设置数据表的列名称,若不设置,则将字段名作为数据表的列名。
-
db_tablespace:默认为None,如果字段已创建索引,那么数据库的表空间名称将作为该字段的索引名。注意:部分数据库不支持表空间。
-
auto_created:默认为False,若为True,则自动创建字段,用于一对一的关系模型。validators:默认为空列表,设置字段内容的验证函数。
-
error_messages:默认为None,设置错误提示。
ForeignKey方法参数如下:
| 参数名 | 参数说明 |
|---|---|
| to | 指定关联的目标模型类。可以使用字符串表示模型类的路径,也可以直接使用模型类的引用。 |
| on_delete | 指定当关联对象被删除时的行为。CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET0、DO_NOTHING。 |
| related_name | 指定反向关联的名称,默认为模型类名_set。 |
| to_field | 指定关联的目标模型类中用于关联的字段名称。默认为主键字段。 |
| db_index | 如果为True,则在目标模型的关联字段上创建索引。 |
| null | 指定关联字段是否可以为空。如果 null=True,则数据库中该字段将允许 NULL值。 |
| blank | 指定关联字段是否可以为空。如果blank=True,则表单中该字段可以为空。 |
| limit_choices_to | 指定关联对象的过滤条件。可以是一个字典、一个 QuerySet或一个函数。 |
| verbose_name | 用于在 Django Admin后台中显示字段名称。 |
| help_text | 用于在 Django Admin后台中显示帮助文本。 |
on_delete的models属性有下面设置选项:
-
CASCADE:这就是默认的选项,级联删除,你无需显性指定它。
-
PROTECT: 保护模式,如果采用该选项,删除的时候,会抛出ProtectedError错误。
-
SET_NULL: 置空模式,删除的时候,外键字段被设置为空,前提就是blank=True, null=True,定义该字段的时候,允许为空。
-
SET_DEFAULT: 置默认值,删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
-
SET(): 自定义一个值,该值当然只能是对应的实体了
根据上述信息,我们去模型models.py中建图书信息和图书种类各一张表,属于1对N关系。
from django.db import modelsclass BookTypeInfo(models.Model):id = models.AutoField(primary_key=True)bookTypeName = models.CharField(max_length=20)class Meta:db_table = "t_bookType"verbose_name = "图书类别"class BookInfo(models.Model):id = models.AutoField(primary_key=True)bookName = models.CharField(max_length=20)price = models.FloatField()publishDate = models.DateField()bookType = models.ForeignKey(BookTypeInfo,on_delete=models.PROTECT)class Meta:db_table = "t_book"verbose_name = "图书信息"
模型数据迁移
然后我们执行:python manage.py makemigrations生成数据库迁移文件
所谓的迁移文件, 是类似模型类的迁移类,主要是描述了数据表结构的类文件;
这个生成的迁移文件在migrations目录下;每执行一次,都会生成一个新文件。

插入几条数据:
INSERT INTO `t_booktype` VALUES (1, '计算机类');
INSERT INTO `t_booktype` VALUES (2, '数学类');
INSERT INTO `t_book` VALUES (1, 'Python从入门到放弃', 98.8, '2004-03-16', 1);
INSERT INTO `t_book` VALUES (2, 'Java编程思想', 100, '2004-03-16', 1);
INSERT INTO `t_book` VALUES (3, 'Head First设计模式', 88, '2020-03-16', 1);
INSERT INTO `t_book` VALUES (4, '数学的秘密', 50, '2019-03-06', 2);

模型查询
我们知道数据库设有多种数据查询方式,如单表查询、多表查询、子查询和联合查询等,而 Django 的ORM框架对不同的查询方式定义了相应的API方法。下面我们通过实例来深入学习下;
我们来实现下图书信息的查询,顺便通过外键关联配置,把图书类别信息也级联查询出来。我们通过all()方法查询出所有图书信息;
views.py里我们加下bookList方法:
def bookList(request):title = '图书列表'bookList = BookInfo.objects.all()content_value = {'title': title, 'bookList': bookList}return render(request, 'bookList.html', context=content_value)
urls.py里加下映射配置:
path('book/list', helloWorld.views.bookList)
templates下新建book目录,book目录下新建list.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{ title }}</title>
</head>
<body>
<h1>{{ title }}</h1>
<table border="1"><tr><th>序号</th><th>书名</th><th>价格</th><th>出版日期</th><th>分类</th></tr>{% for book in bookList %}<tr><td>{{ book.id }}</td><td>{{ book.bookName }}</td><td>{{ book.price }}</td><td>{{ book.publishDate|date:"Y-m-d" }}</td><td>{{ book.bookType.bookTypeName }}</td></tr>{% endfor %}
</table>
</body>
</html>测试运行,浏览器输入:http://127.0.0.1:8000/book/list

可以看到表中所有内容。接下来我们使用高级点的查表语法。
下面我们继续学习下ORM框架给我们提供的一些其他常用方法;
# 查询所有信息
bookList = BookInfo.objects.all()
# 获取数据集的第一条数据的bookName属性值
print(bookList[0].bookName)
# 返回前2条数据 select * from t_book limit 2
bookList = BookInfo.objects.all()[:2]
# 查询指定字段
bookList = BookInfo.objects.values("bookName", "price")
# 查询指定字段 数据以列表方式返回,列表元素以元组表示
bookList = BookInfo.objects.values_list("bookName", "price")
ORM框架提供了get()方法,返回满足条件的单个数据:# 获取单个对象,一般是根据id查询
book = BookInfo.objects.get(id=2)
print(book.bookName)
ORM框架提供了filter()方法,返回满足条件的数据:
# 返回满足条件id=2的数据,返回类型是列表
bookList = BookInfo.objects.filter(id=2)
bookList = BookInfo.objects.filter(price=100, id=1)
# filter的查询条件可以设置成字典格式
d = dict(price=100, id=1)
bookList = BookInfo.objects.filter(**d)
# SQL的or查询,需要引入Q,from django.db.models import Q
# 语法格式:Q(field=value)|Q(field=value) 多个Q之间用"|"隔开
bookList = BookInfo.objects.filter(Q(id=1) | Q(price=88))
# SQL的不等于查询,在Q查询中用“~”即可
# SQL select * from t_book where not (id=1)
bookList = BookInfo.objects.filter(~Q(id=1))
ORM框架提供了exclude()方法,返回不满足条件的数据:
# 也可以使用exclude 返回满足条件之外的数据 实现不等于查询
bookList = BookInfo.objects.exclude(id=1)
ORM框架提供了count()方法,返回满足查询条件后的数据量:# 使用count()方法,返回满足查询条件后的数据量
t = BookInfo.objects.filter(id=2).count()
print(t)
ORM框架提供了distinct()方法,返回去重后的数据:# distinct()方法,返回去重后的数据
bookList = BookInfo.objects.values('bookName').distinct()
print(bookList)
ORM框架提供了order_by()方法,对结果进行排序;默认是升序;如果需要降序,只需要在字段前面加“-”即可;
# 使用order_by设置排序
# bookList = BookInfo.objects.order_by("price")
bookList = BookInfo.objects.order_by("-id")
ORM框架提供了annotate方法来实现聚合查询,比如数据值求和,求平均值等。
# annotate类似于SQL里面的GROUP BY方法
# 如果不设置values,默认对主键进行GROUIP BY分组
# SQL: select bookType_id,SUM(price) AS 'price_sum' from t_book GROUP BY bookType_id
r = BookInfo.objects.values('bookType').annotate(Sum('price'))
# SQL: select bookType_id,AVG(price) AS 'price_sum' from t_book GROUP BY bookType_id
模型分页查询
在Django中实现分页通常使用Paginator类。以下是一个简单的示例,展示了如何在Django视图中实现分页功能:
bookList = BookInfo.objects.all()
# Paginator(object_list ,per_page)
# object_list 结果集/列表
# per_page 每页多少条记录
p = Paginator(bookList, 2)
# 获取第几页的数据
bookListPage = p.page(2)
print("总记录数:", BookInfo.objects.count())
高级查询匹配符
由于是通过参数来传递字段限制条件,例如当我们要查询年龄大于12的学生,我们并不能直接这样使用
querystudent1 = Student.objects.filter(age>12)
Django通过字段后加__条件=值的方式来解决这样的问题,例如上面就可以这样进行查询
querystudent1 = Student.objects.filter(age__gt=12)
1. 等于 exact。
例:查询name等于‘xiao ming’的学生
Student.objects.filter(name='xiao ming')
Student.objects.filter(name__exact='xiao ming')#此处的exact可以省略2. 模糊查询 like包含 contains
例:查询姓名包含'xiao'的学生。
Student.objects.filter(name__contains='xiao')
开头:startswith 结尾:endswith
例:查询姓名以'xiao'开头的学生 以'ming'结尾的学生
Student.objects.filter(name__startswith='xiao')
Student.objects.filter(name__endswith='ming')3. 空查询 isnull
例:查询姓名不为空的学生
Student.objects.filter(name__isnull=False)4. 范围查询 in
例:查询年龄12或15或16的学生
Student.objects.filter(age__in=[12,15,16])5. 比较查询 gt大于 lt(less than) gte(equal) lte
例:查询年龄大于等于12的学生
Student.objects.filter(age__gte=12)6. 日期查询 date
例:查询1994年出生的学生。
Student.objects.filter(birthyear__date=1994)
例:查询1994年1月1日后出生的学生。
Student.objects.filter(birthyear__date__gt = date(1994,1,1))7. 返回不满足条件的数据 exclude
例:查询id不为3的学生。
Student.objects.exclude(id=3)
模型多表查询
我们在日常的开发中,常常需要对多张数据表同时进行数据查询。多表查询需要在数据表之间建立表关系才能够实现。一对多或一对一的表关系是通过外键实现关联的,而多表查询分为正向查询和反向查询。
以模型BookInfo和BokkTypeInfo为例,如果查询主题是BookInfo,通过外键bookType_id去查询BooKTypeInfo的关联数据,那么该查询称为正向查询;如果查询对象的主题是模型BookTypeInfo,要查询它与模型BookInfo的关联数据,那么该查询称为反向查询;
下面是一个实例:
def bookList2(request):"""多表查询 正常查询 和反向查询:param request::return:"""# 正向查询book: BookInfo = BookInfo.objects.filter(id=2).first()print(book.bookType.bookTypeName)# 反向查询bookType = BookTypeInfo.objects.filter(id=1).first()print(bookType.bookinfo_set.first().bookName)print(bookType.bookinfo_set.all())content_value = {"title": "图书列表"}return render(request, 'book/list.html')
模型数据新增
Django对数据库的数据进行增、删、改操作是借助内置ORM框架所提供的API方法实现的,简单来说,它在模型基础类 Model里定义数据操作方法,通过类继承将这些操作方法传给开发者自定义的模型对象,再由模型对象调用即可实现数据操作。
添加操作通过模型的save方法实现,添加下可以返回主键id值。
我们在前面实例的基础上,来实现这个例子。
因为添加页面是需要图书类别的数据,我们用下拉框实现。所以这里需要一个预处理操作。
先在views.py里定义一个添加预处理方法preAdd
def preAdd(request):"""预处理,添加操作:param request::return:"""bookTypeList = BookTypeInfo.objects.all()print(bookTypeList)content_value = {"title": "图书添加", "bookTypeList": bookTypeList}return render(request, 'book/add.html', context=content_value)
urls.py里加下映射:
path('booklist/preadd', helloWorld.views.preAdd),
原先的list.html,加上添加的链接:
<a href="/book/preAdd">添加</a><br/>
再创建下图书添加页面add.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{ title }}</title>
</head>
<body>
<h1>{{ title }}</h1>
<form action="/booklist/add" method="post">{% csrf_token %}书名:<input type="text" name="bookName"><br>价格:<input type="text" name="price"><br>出版日期:<input type="date" name="publishDate"><br>分类:<select name="bookType_id">{% for bookType in bookTypeList %}<option value="{{ bookType.id }}">{{ bookType.bookTypeName }}</option>{% endfor %}
</select><br><input type="submit" value="提交">
</form>
</body>
</html>
最后在views.py里创建图书添加函数add:
def add(request):"""图书添加:param request::return:"""# print(request.POST.get("bookName"))# print(request.POST.get("publishDate"))# print(request.POST.get("bookType_id"))# print(request.POST.get("price"))book = BookInfo()book.bookName = request.POST.get("bookName")book.publishDate = request.POST.get("publishDate")book.bookType_id = request.POST.get("bookType_id")book.price = request.POST.get("price")book.save()# 数据添加后,获取新增数据的主键idprint(book.id)return bookList(request)
运行测试:浏览器输入:http://127.0.0.1:8000/booklist


模型数据修改
模型数据修改和添加都是用的save方法。
我们结合案例先实现下;
我们在views.py里先定义preUpdate方法,修改预处理,根据id获取图书信息,以及获取图书类别列表;
def preUpdate(request, id):"""预处理,修改操作:param request::return:"""print("id:", id)book = BookInfo.objects.get(id=id)print(book)bookTypeList = BookTypeInfo.objects.all()print(bookTypeList)content_value = {"title": "图书修改", "bookTypeList": bookTypeList, "book": book}return render(request, 'book/edit.html', context=content_value)
运行运行
urls.py里加下映射:
path('book/preUpdate/<int:id>', helloWorld.views.preUpdate),
book/list.html修改下,加下修改操作链接:
<a href="/book/preUpdate/{{ book.id }}">修改</a>
新建编辑页面edit.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{ title }}</title>
</head>
<body>
<h3>{{ title }}</h3>
<form action="/book/update" method="post">{% csrf_token %}<table><tr><td>图书名称:</td><td><input type="text" name="bookName" value="{{ book.bookName }}"></td></tr><tr><td>出版日期:</td><td><input type="text" name="publishDate" value="{{ book.publishDate | date:'Y-m-d' }}"></td></tr><tr><td>图书类别:</td><td><select name="bookType_id">{% for bookType in bookTypeList %}<option value="{{ bookType.id }}"{% if book.bookType.id == bookType.id %}selected{% endif %}>{{ bookType.bookTypeName }}</option>{% endfor %}</select></td></tr><tr><td>图书价格:</td><td><input type="text" name="price" value="{{ book.price }}"></td></tr><tr><td colspan="2"><input type="hidden" name="id" value="{{ book.id }}"><input type="submit" value="提交"></td></tr></table>
</form>
</body>
</html>
再写一个update方法,保存图书信息
def update(request):"""图书修改:param request::return:"""book = BookInfo()book.id = request.POST.get("id")book.bookName = request.POST.get("bookName")book.publishDate = request.POST.get("publishDate")book.bookType_id = request.POST.get("bookType_id")book.price = request.POST.get("price")book.save()return bookList(request)
运行运行
urls.py里再加下映射:
path('book/update', helloWorld.views.update),
我们来测试下,浏览器输入:http://127.0.0.1:8000/booklist



模板删除数据
Django5 ORM框架提供了delete()方法来实现数据删除操作,下面是一些常用的方式,删除所有数据,删除指定id数据,根据filter条件删除删除。
删除所有数据
BookInfo.objects.all().delete()
删除指定id数据
BookInfo.objects.get(id=1).delete()
根据条件删除多条数据
BookInfo.objects.filter(price__gte=90).delete()
我们来完善下前面的实例:
views.py里先定义delete方法。
def delete(request, id):"""图书删除:param request::return:"""# 删除所有数据# BookInfo.objects.all().delete()# 删除指定id数据BookInfo.objects.get(id=id).delete()# 根据条件删除多条数据# BookInfo.objects.filter(price__gte=90).delete()return bookList(request)
urls.py里加下映射:
path('book/delete/<int:id>', helloWorld.views.delete),
book/list.html里加下删除操作:
<a href="/book/delete/{{ book.id }}">删除</a>

删除后数据就消失了,不信你自己试试
总结
本章主要认识了ORM框架 虚拟对象数据库,也学习了如何对虚拟对象数据库进行增删改查操作。继续加油吧。
相关文章:
【Django5】模型定义与使用
系列文章目录 第一章 Django使用的基础知识 第二章 setting.py文件的配置 第三章 路由的定义与使用 第四章 视图的定义与使用 第五章 二进制文件下载响应 第六章 Http请求&HttpRequest请求类 第七章 会话管理(Cookies&Session) 第八章 文件上传…...

HTML--JavaScript操作DOM对象
目录 本章目标 一.DOM对象概念 编辑 二.节点访问方法 常用方法: 层次关系访问节点 三.节点信息 四.节点的操作方法 操作节点的属性 创建节点 删除替换节点 五.节点操作样式 style属性 class-name属性 六.获取元素位置 总结 本章目标 了解DOM的分类和节…...

Redis 缓存
安装 安装 Redis 下载: Releases tporadowski/redis (github.com) winr ----services.msc-----将redis 设置为手动(只是学习,如果经常用可以设置为自动) 安装 redis-py 库 pip install redis-py Redis 和 StrictRedis redis-py 提供 Redis 和 Str…...
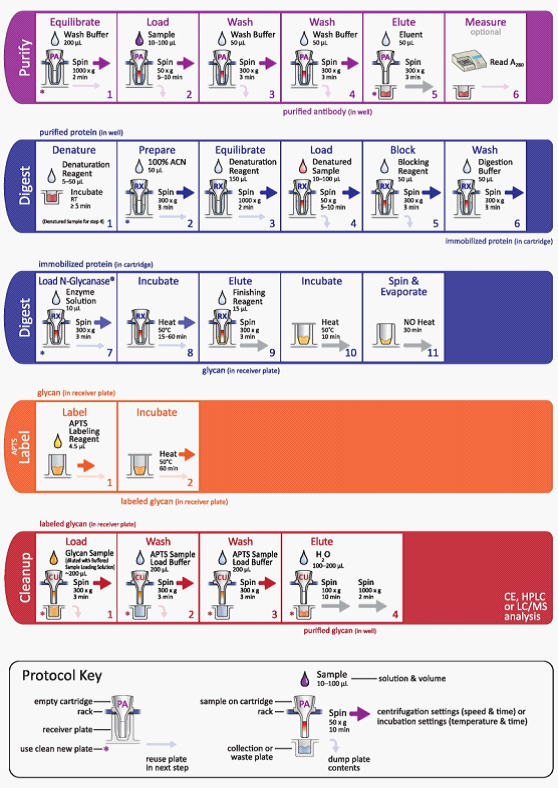
Prozyme糖样本检测平台--GlykoPrep® Rapid N-Glycan Preparation with APTS
单克隆抗体已成为生物制药行业具有潜力的新兴蛋白候选药物。其药物研发流程包括一系列精细的控制和评估步骤,需要仔细、严格地监测目标化合物的治疗稳定性及有效性。因此,在商业化前的每个阶段对单克隆抗体进行全面表征是极其有益的。在大量研究成熟的蛋…...
)
力扣面试题(一)
1、给你两个字符串 word1 和 word2 。请你从 word1 开始,通过交替添加字母来合并字符串。如果一个字符串比另一个字符串长,就将多出来的字母追加到合并后字符串的末尾。 char * mergeAlternately(char * word1, char * word2){int len1 strlen(word1);i…...

Python 输入输出
重点内容: 1、梳理掌握输入和输出函数的应用。 2、熟练使用int() float() str()等函数进行数据转换 3、常用转义字符在数据输入、输出中的应用 4、熟练使用ljust()、center()、rjust()等方法对字符位置进行控制。 5、灵活应用ASCII码、字母、数字及特殊字符解决…...

国服最强文字转音频?Fish Speech
官网文档与示例 Fish Speech V1.2 是一款领先的文本到语音 (TTS) 模型,使用 30 万小时的英语、中文和日语音频数据进行训练。我尝试用1066运行,但是质量不尽如人意,建议使用RTX系列的显卡进行推理。 使用结果展示 text """20…...

数据结构(6):图
1 图的基本概念 1.1 基本概念 1.1.1 定义【多对多的关系】 一个图不可能是空图!!!一个图的顶点集一定是非空集,但是边集可以为空集! 1.1.2 应用 1.2 无向图和有向图 弧头是有箭头的那一边,弧尾是没有箭头…...

kaggle使用api下载数据集
背景 kaggle通过api并配置代理下载数据集datasets 步骤 获取api key 登录kaggle,点个人资料,获取到自己的api key 创建好的key会自动下载 将key放至家目录下的kaggle.json文件中 我这里是windows的administrator用户。 装包 我用了虚拟环境 pip …...

前缀表达式(波兰式)和后缀表达式(逆波兰式)的计算方式
缀是指操作符。 1. 前缀表达式(波兰式) (1)不需用括号; (2)不用考虑运算符的优先级; (3)操作符置于操作数的前面。(如 3 2 ) 1.1 中…...

智能井盖管理系统:城市窨井的井下“保镖”
随着城市化进程的加速,城市的生命线基础设施面临着越来越多的挑战。其中,旭华智能智能井盖传感器技术的发展为提升城市基础设施的安全性和管理效率提供了新的解决方案。它专门用于监控市政窨井、燃气井、供水井内的积水状况以及井盖状态,以增…...

vue3-环境变量-JavaScript-axio-基础使用-lzstring-字符串压缩-python
文章目录 1.Vue3环境变量1.1.简介1.2.全局变量的引用1.3.package.json文件 2.axio2.1.promise2.2.安装2.3.配置2.3.1.全局 axios 默认值2.3.2.响应信息格式 2.4.Axios的拦截器2.4.1.请求拦截器2.4.2.响应拦截器2.4.3.移除拦截器2.4.4.自定义实例添加拦截器 3.lz-string3.1.java…...

ubuntu下载docker依赖包
Ubuntu下载docker依赖包 公司对外客户一直偏向对安全性要求较高,因此在外部署服务得时候,安装docker是一件极为重要得事情,之前得服务器得系统是centos7。在上一家公司的时候,已经把docker所需得rpm包已经集成打包好了。并且d…...

java面向对象进阶进阶篇--《JDK8,JDK9接口中新增的方法、接口的应用、适配器设计模式》
个人主页→VON 收录专栏→java从入门到起飞 接口→接口和接口与抽象类综合案例 一、JDK8接口中新增的方法 在JDK 8中,接口新增了几个重要的特性和方法,其中最显著的是默认方法(Default Methods)和静态方法(Static Met…...

15.2 zookeeper java client
15.2 zookeeper java client 1. Zookeeper官方1.1 依赖1.2 Zookeeper客户端连接测试1.3***************************************************************************************1. Zookeeper官方 1.1 依赖 <!-- 集成方式一:官方集成zookeeper依赖 --><dependenc…...

素材管理太繁琐?有这一个就够了!
引言: 在创意行业中,素材管理一直是设计师们的痛点。从灵感的捕捉到作品的完成,每一步都离不开素材的积累与整理。然而,传统的素材管理方式往往繁琐且效率低下,让人头疼不已。今天,我要介绍的这款智能素材管…...
KubeSphere 部署向量数据库 Milvus 实战指南
作者:运维有术星主 Milvus 是一个为通用人工智能(GenAI)应用而构建的开源向量数据库。它以卓越的性能和灵活性,提供了一个强大的平台,用于存储、搜索和管理大规模的向量数据。Milvus 能够执行高速搜索,并以…...

前端canvas——贝塞尔曲线
曲线之美,不在于曲线本身,而在于用的人。 所以就有了这期贝塞尔曲线。 新规矩,先上个GIT。 效果图 开局一张图,代码全靠编。 代码 画骨 先想着怎么画一个心形吧,等你想好了,就知道怎么画了。 首先就还…...

Elasticsearch模糊查询之Wildcard
{“wildcard” : { “LPR.keyword” : { “wildcard” : “${Keyword}”} }},你的示例中使用了 wildcard 查询,它适用于模糊搜索,允许使用通配符(* 和 ?)来匹配字段值。你使用了 keyword 子字段来确保精确匹配,这是一…...

【人工智能】穿越科技迷雾:解锁人工智能、机器学习与深度学习的奥秘之旅
文章目录 前言一、人工智能1. 人工智能概述a.人工智能、机器学习和深度学习b.人工智能发展必备三要素c.小案例 2.人工智能发展历程a.人工智能的起源b.发展历程 3.人工智能的主要分支 二、机器学习1.机器学习工作流程a.什么是机器学习b.机器学习工作流程c.特征工程 2.机器学习算…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...

数据库——redis
一、Redis 介绍 1. 概述 Redis(Remote Dictionary Server)是一个开源的、高性能的内存键值数据库系统,具有以下核心特点: 内存存储架构:数据主要存储在内存中,提供微秒级的读写响应 多数据结构支持&…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...