SparkSQL---编程模型的操作,数据加载与落地及自定义函数的使用
一、SparkSQL编程模型的创建与转化
1、DataFrame的构建
people.txt数据:
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
people.json数据:在SparkSQL—简介及RDD V.S DataFrame V.S Dataset编程模型详解里
1、从Spark数据源进行创建
//创建程序入口val spark = SparkSession.builder().appName("dataFrame").master("local[*]").getOrCreate()val sc = spark.sparkContext//设置日志级别sc.setLogLevel("WARN")//加载数据val dataFrame = spark.read.format("json").load("F:\\test\\people.json")//展示数据dataFrame.show()
2、从RDD进行转换
//创建程序入口val spark = SparkSession.builder().appName("dataFrame").master("local[*]").getOrCreate()val sc = spark.sparkContext//设置日志级别sc.setLogLevel("WARN")//导包import spark.implicits._//加载文件val file :RDD[String] = sc.textFile("F:\\test\\person.txt")//按照分隔符进行切分val filemap :RDD[Array[String]] = file.map(_.split(" "))//指定数据类型val tran :RDD[(Int,String,Int)] = filemap.map(x=>(x(0).toInt,x(1),x(2).toInt))//带参数的是指定表头名字val dataFrame2=tran.toDF("id","name","age")
3、通过反射创建DataFrame
case class Person(id:Int,name:String,age:Int)//样例类反射获取列名创建DataFrame//加载文件val file :RDD[String] = sc.textFile("F:\\test\\person.txt")//按照分隔符进行切分val filemap :RDD[Array[String]] = file.map(_.split(" "))//指定数据类型val tran= filemap.map(x1=>Person(x1(0).toInt,x1(1),x1(2).toInt))//将rdd转换为DataFrameval dataFrame1 = tran.toDF()
4、动态编程
//数据和结构分离加载的方式动态创建dataFrame//加载数据val row:RDD[Row] = sc.parallelize(List(Row(1, "李伟", 1, 180.0),Row(2, "汪松伟", 2, 179.0),Row(3, "常洪浩", 1, 183.0),Row(4, "麻宁娜", 0, 168.0)))//指定schema/*val structType = StructType(List(StructField("id", DataTypes.IntegerType, false),StructField("name", DataTypes.StringType, false),StructField("sex", DataTypes.IntegerType, false),StructField("height", DataTypes.DoubleType, false)))*/val structType = new StructType().add("id","Int").add("name","string").add("sex","Int").add("height","Double")//创建DataFrameval dataFrame3 = spark.createDataFrame(row,structType)//Row:代表的是二维表中的一行记录,或者就是一个Java对象//StructType:是该二维表的元数据信息,是StructField的集合//StructField:是该二维表中某一个字段/列的元数据信息(主要包括,列名,类型,是否可以为null)
2、Dataset的构建
case class Student(id: Int, name: String, sex: Int, age: Int)
object Create_DataSet {def main(args: Array[String]): Unit = {//创建程序入口val spark = SparkSession.builder().appName("dataSet").master("local[*]").getOrCreate()//设置日志级别val sc = spark.sparkContextsc.setLogLevel("WARN")//导包import spark.implicits._//加载数据val list = List(new Student(1, "王盛芃", 1, 19),new Student(2, "李金宝", 1, 49),new Student(3, "张海波", 1, 39),new Student(4, "张文悦", 0, 29))//创建DataSetval ds = spark.createDataset[Student](list)//展示输出ds.show()}
注:在创建Dataset的时候,需要注意数据的格式,必须使用case class,或者基本数据类型,同时需要通过import spark.implicts._来完成数据类型的编码,而抽取出对应的元数据信息,否则编译无法通过。
3、RDD和DataFrame以及DataSet的互相转换
//创建程序入口val spark = SparkSession.builder().appName("transform").master("local[*]").getOrCreate()//调用sparkContextval sc = spark.sparkContext//设置日志级别sc.setLogLevel("WARN")//导包import spark.implicits._//加载数据val file = sc.textFile("F:\\test\\person.txt")//切分val fileMap = file.map(_.split(" "))//指定数据类型val tran = fileMap.map(x=>(x(0).toInt,x(1),x(2).toInt))//----------三者之间的转换--------//rdd=>DFval dataFrame = tran.toDF("id","name","age")//rdd=>DSval dataSet = tran.toDS()//DS=>rdddataSet.rdd//DF=>rdddataFrame.rdd//DF=>DSval ds = dataFrame.as[(Int,String,Int)]//DS=>DFval df = ds.toDF()
二、SparkSQL统一数据加载与落地
1、数据加载
//创建程序入口val spark = SparkSession.builder().appName("load").master("local[*]").getOrCreate()//调用sparkContextval sc = spark.sparkContext//设置日志级别sc.setLogLevel("WARN")//加载数据//第一种方式:spark.read.format(数据文件格式).load(path),默认加载的文件格式为parquetspark.read.format("parquet").load("F:\\test\\parquet").show()spark.read.format("json").load("F:\\test\\json").show()spark.read.format("csv").load("F:\\test\\csv").show()//加载数据库中的表的数据spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/mydata").option("user","root").option("password","root").option("dbtable","person").load().show()//第二种方式spark.read.parquet("F:\\test\\parquet").show()spark.read.json("F:\\test\\json").show()spark.read.csv("F:\\test\\csv").show()//加载数据库中的表val pro =new Properties()pro.put("user","root")pro.put("password","root")spark.read.jdbc("jdbc:mysql://localhost:3306/mydata","person",pro).show()
2、数据落地
//创建程序入口val spark = SparkSession.builder().appName("save").master("local[*]").getOrCreate()//调用sparkContextval sc = spark.sparkContext//设置日志级别sc.setLogLevel("WARN")//加载数据val dataFrame = spark.read.json("F:\\test\\people.json")//数据落地//第一种方式,save的默认格式也是parquetdataFrame.write.format("parquet").save("F:\\test\\parquet")dataFrame.write.format("json").save("F:\\test\\json")dataFrame.write.format("csv").save("F:\\test\\csv")*///将数据保存到数据库dataFrame.write.format("jdbc").option("url","jdbc:mysql://localhost:3306/mydata").option("user","root").option("password","root").option("dbtable","person").save()//第二种方式dataFrame.write.parquet("F:\\test\\parquet")dataFrame.write.json("F:\\test\\json")dataFrame.write.csv("F:\\test\\csv")//保存到数据库val pro = new Properties()pro.setProperty("user","root")pro.setProperty("password","root")dataFrame.write.jdbc("jdbc:mysql://localhost:3306/mydata","person",pro)
三、自定义函数的使用
val spark = SparkSession.builder().appName("UDF").master("local[*]").getOrCreate()val sc = spark.sparkContextsc.setLogLevel("WARN")//案例//加载文件val dataFrame = spark.read.json("file:\\F:\\test\\people.json")//sql查询风格//首先将数据注册为一张表dataFrame.createOrReplaceTempView("people")//赋予函数功能val fun=(x:String)=>{x.toUpperCase()}//注册函数spark.udf.register("upper",fun)//使用sql风格查询spark.sql("select name, upper(name) from people").show()
相关文章:

SparkSQL---编程模型的操作,数据加载与落地及自定义函数的使用
一、SparkSQL编程模型的创建与转化 1、DataFrame的构建 people.txt数据: 1 zhangsan 20 2 lisi 29 3 wangwu 25 4 zhaoliu 30 5 tianqi 35 6 kobe 40 people.json数据:在SparkSQL—简介及RDD V.S DataFrame V.S Dataset编程模型详解里 1、从Spark数据…...
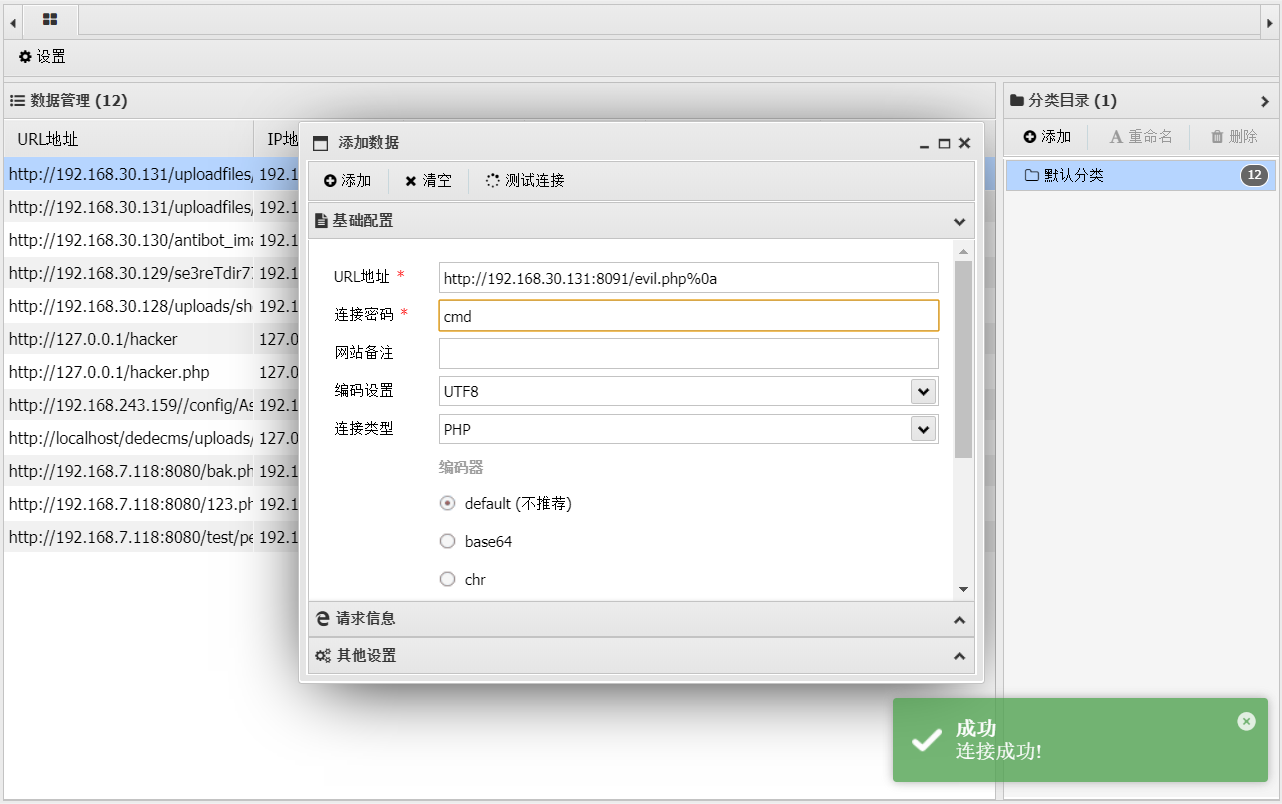
文件解析漏洞--IIS--Vulhub
文件解析漏洞 一、IIS解析漏洞 用windowserver2003安装IIS测试 1.1 IIS6.X 方法一:目录解析 在网站下建立文件夹的名字为.asp/.asa的文件夹,其目录内的任何扩展名的文件都被IIS当作asp文件来解析并执行。 1.txt文件里是asp文件的语法查看当前时间 方…...

你知道缓存的这个问题到底把多少程序员坑惨了吗?
在现代系统中,缓存可以极大地提升性能,减少数据库的压力。 然而,一旦缓存和数据库的数据不一致,就会引发各种诡异的问题。 我们来看看几种常见的解决缓存与数据库不一致的方案,每种方案都有各自的优缺点 先更新缓存&…...

飞创直线模组桁架机械手优势及应用领域
随着工业自动化和智能制造的发展,直线模组桁架机械手极大地减轻了人类的体力劳动负担,在危险性、重复性高的作业环境中展现出了非凡的替代能力,引领着工业生产向自动化、智能化方向迈进。 一、飞创直线模组桁架机械手优势 飞创直线模组桁架…...

TongHttpServer 简介
1. 概述 随着网络技术的飞速发展,高并发大用户场景越来越普遍,单一应用服务节点已经不能满足并发需求,为了提高整个系统可靠性,扩展性,吞吐率,通常将多个应用服务器通过硬负载/软负载组成集群,负载均衡器根据不同负载算法将请求分发到各个应用服务器节点。 Tong…...

回溯法---组合总和
题目: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限…...

将Android Library项目发布到JitPack仓库
将项目代码导入Github 1.将本地项目目录初始化为 Git 仓库。 默认情况下,初始分支称为 main; 如果使用 Git 2.28.0 或更高版本,则可以使用 -b 设置默认分支的名称。 git init -b main 如果使用 Git 2.27.1 或更低版本,则可以使用 git symbo…...

JAVAWeb实战(后端篇)
因为前后端代码内容过多,这篇只写后端的代码,前端的在另一篇写 项目实战一: 1.创建数据库,表等数据 创建数据库 create database schedule_system 创建表,并添加内容 SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS 0;-- ---------…...

【vs】实用调试技巧——学会写优秀的代码!
🦄个人主页:小米里的大麦-CSDN博客 🎏所属专栏:https://blog.csdn.net/huangcancan666/category_12718530.html ⚙️操作环境:Visual Studio 2022 目录 一、前言 二、什么是BUG? 三、调试是什么?有多重要? 一名优秀…...

数组声明方式
数组声明方式 一、 一维数组 元素数据类型[] 数组名; // 推荐元素数据类型 数组名[]; 二、 二维数组 元素数据类型[][] 数组名称; // 推荐元素数据类型 数组名称[][];元素数据类型[] 数组名称[]; 注: 对于第三种方式元素数据类型[] 数组名称[];,可…...

Docker中Docker网络-理解Docker0与自定义网络的使用示例
场景 CentOS7中Docker的安装与配置: CentOS7中Docker的安装与配置_centos docker sock-CSDN博客 在上面安装好Docker之后。 关于对Docker中默认docker0以及自定义网络的使用进行学习。 注: 博客:霸道流氓气质-CSDN博客 实现 理解dock…...
)
领域驱动大型结构之SYSTEM METAPHOR(系统隐喻)
在领域驱动设计(Domain-Driven Design, DDD)中,"System Metaphor" 是一种用于帮助开发团队和业务人员在理解和沟通系统时使用的概念模型。虽然 "System Metaphor" 并不是 DDD 的核心概念,但它在敏捷开发方法&…...

web前端开发一、VScode环境搭建
1、VScode安装live server插件,写完代码后,保存就会在浏览器自动更新,不需要再去浏览器点击刷新了 2、创建html文件 3、在文件中输入感叹号 ! 4、选择第一个,然后回车,就会自动输入html的标准程序 5、…...

DiAD代码use_checkpoint
目录 1、梯度检查点理解2、 torch.utils.checkpoint.checkpoint函数 1、梯度检查点理解 梯度检查点(Gradient Checkpointing)是一种深度学习优化技术,它的目的是减少在神经网络训练过程中的内存占用。在训练深度学习模型时,我们需…...

nginx出现Refused to apply inline style because it violates
Content Security Policy的错误。根据错误提示,nginx拒绝应用内联样式,因为它违反了内容安全策略(Content Security Policy)。内容安全策略是一种浏览器机制,用于防止潜在的安全漏洞,通过限制从外部来源加载…...

【中项第三版】系统集成项目管理工程师 | 第 11 章 规划过程组⑥ | 11.15 - 11.17
前言 第11章对应的内容选择题和案例分析都会进行考查,这一章节属于10大管理的内容,学习要以教材为准。本章上午题分值预计在15分。 目录 11.15 规划资源管理 11.15.1 主要输入 11.15.2 主要工具与技术 11.15.3 主要输出 11.16 估算活动资源 11.1…...

基础警务互联网app
智慧公安以大数据、云计算、人工智能、物联网和移动互联网技术为支撑,以“打、防、管、控”为目的,综合研判为核心,共享信息数据资源,融合业务功能,构建公安智慧大数据平台,实现公安信息数字化、网络化和智…...

为了方便写CURD代码,我在UTools写了个插件SqlConvert来生成代码!
-1. 前言 为了方便摸鱼,我之前写过一个通过sql生成代码的工具,但是服务器到期了,也就懒得重新部署了。 技术框架是 SpringBoot MybatisPlus Velocity Vue ElementUI Sql-ParseeSql-Parser-ui 0. Utools应用安装 官网地址: https://u.too…...

在国产芯片上实现YOLOv5/v8图像AI识别-【2.2】RK3588上C++开发环境准备及测试更多内容见视频
本专栏主要是提供一种国产化图像识别的解决方案,专栏中实现了YOLOv5/v8在国产化芯片上的使用部署,并可以实现网页端实时查看。根据自己的具体需求可以直接产品化部署使用。 B站配套视频:https://www.bilibili.com/video/BV1or421T74f 板子…...

2024数据资产入表财务实操手册
关注公众号《方案驿站》,并私信:2024数据资产入表财务实操手册,可获取本文pdf文件。...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...