【Golang 面试 - 基础题】每日 5 题(七)
✍个人博客:Pandaconda-CSDN博客
📣专栏地址:http://t.csdnimg.cn/UWz06📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~
❤️如果有收获的话,欢迎点赞👍收藏📁,您的支持就是我创作的最大动力💪
31. Go Map 查找
在 Go 语言中,使用 map 查找一个键值对的过程可以通过 map[key] 来完成,返回值是对应的值和一个表示是否存在的布尔值。
具体来说,如果 map 中存在该键,则返回对应的值和布尔值 true;如果不存在该键,则返回值类型的零值和布尔值 false。例如:
m := make(map[string]int)
m["apple"] = 1
value, ok := m["apple"]
if ok {fmt.Println(value) // 输出 1
}另外,也可以直接使用一个值来获取键值对中的值,但是如果键值对中不存在该键,会返回该值类型的零值。例如:
m := make(map[string]int)
m["apple"] = 1
value := m["banana"]
fmt.Println(value) // 输出 0需要注意的是,map 的键类型必须支持相等运算,例如,数字、字符串、指针、通道、接口类型、结构体类型等都是支持的,但是数组、切片、函数类型等不支持。
底层实现
在 Golang 中,Map 的查找是通过哈希表实现的。当程序执行 map 查找操作时,会先根据哈希函数将 key 转换成一个哈希值,然后在哈希表中查找该哈希值对应的桶 (bucket),再在桶中查找对应的键值对。
具体来说,当 Map 中的键值对数量超过一定阈值时,会触发自动扩容操作。扩容操作会重新分配更大的桶数组,并将原有的键值对重新哈希分布到新的桶中。
在查找时,Golang 的 Map 会先通过哈希值定位到对应的桶 (bucket),然后在桶中遍历链表(每个桶可能对应多个键值对)查找对应的键值对。在遍历链表的过程中,如果发现某个键值对的 key 与要查找的 key 相等,则返回该键值对的 value。
需要注意的是,如果 Map 中的键值对过多,桶中的链表会很长,查找时效率会降低,因此需要根据实际情况合理设置 Map 的容量和哈希函数,以充分利用哈希表的优势。同时,当 Map 中的键值对类型为复杂类型(如结构体)时,需要重载对应的哈希函数和比较函数,以确保哈希表的正确性。
32. Go Ma p 如何查找?
Go 语言中读取 map 有两种语法:带 comma 和 不带 comma。当要查询的 key 不在 map 里,带 comma 的用法会返回一个 bool 型变量提示 key 是否在 map 中;而不带 comma 的语句则会返回一个 value 类型的零值。如果 value 是 int 型就会返回 0,如果 value 是 string 类型,就会返回空字符串。
// 不带 comma 用法
value := m["name"]
fmt.Printf("value:%s", value)// 带 comma 用法
value, ok := m["name"]
if ok {fmt.Printf("value:%s", value)
}map 的查找通过生成汇编码可以知道,根据 key 的不同类型/返回参数,编译器会将查找函数用更具体的函数替换,以优化效率:
| key 类型 | 查找 |
| uint32 | mapaccess1_fast32(t maptype, h hmap, key uint32) unsafe.Pointer |
| uint32 | mapaccess2_fast32(t maptype, h hmap, key uint32) (unsafe.Pointer, bool) |
| uint64 | mapaccess1_fast64(t maptype, h hmap, key uint64) unsafe.Pointer |
| uint64 | mapaccess2_fast64(t maptype, h hmap, key uint64) (unsafe.Pointer, bool) |
| string | mapaccess1_faststr(t maptype, h hmap, ky string) unsafe.Pointer |
| string | mapaccess2_faststr(t maptype, h hmap, ky string) (unsafe.Pointer, bool) |
查找流程

1. 写保护监测
函数首先会检查 map 的标志位 flags。如果 flags 的写标志位此时被置 1 了,说明有其他协程在执行“写”操作,进而导致程序 panic,这也说明了 map 不是线程安全的。
if h.flags&hashWriting != 0 {throw("concurrent map read and map write")
}2. 计 算 hash 值
hash := t.hasher(key, uintptr(h.hash0))key 经过哈希函数计算后,得到的哈希值如下(主流 64 位机下共 64 个 bit 位),不同类型的 key 会有不同的 hash 函数。
10010111 | 000011110110110010001111001010100010010110010101010 │ 010103. 找 到 hash 对应的 bucket
bucket 定位:哈希值的低 B 个 bit 位,用来定位 key 所存放的 bucket。
如果当前正在扩容中,并且定位到的旧 bucket 数据还未完成迁移,则使用旧的 bucket(扩容前的 bucket)。
hash := t.hasher(key, uintptr(h.hash0))
// 桶的个数m-1,即 1<<B-1,B=5时,则有0~31号桶
m := bucketMask(h.B)
// 计算哈希值对应的bucket
// t.bucketsize为一个bmap的大小,通过对哈希值和桶个数取模得到桶编号,通过对桶编号和buckets起始地址进行运算,获取哈希值对应的bucket
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 是否在扩容
if c := h.oldbuckets; c != nil {// 桶个数已经发生增长一倍,则旧bucket的桶个数为当前桶个数的一半if !h.sameSizeGrow() {// There used to be half as many buckets; mask down one more power of two.m >>= 1}// 计算哈希值对应的旧bucketoldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))// 如果旧bucket的数据没有完成迁移,则使用旧bucket查找if !evacuated(oldb) {b = oldb}
}4. 遍 历 bucket 查找
tophash 值定位:哈希值的高 8 个 bit 位,用来快速判断 key 是否已在当前 bucket 中(如果不在的话,需要去 bucket 的 overflow 中查找)。
用步骤 2 中的 hash 值,得到高 8 个 bit 位,也就是 10010111,转化为十进制,也就是 151。
top := tophash(hash)
func tophash(hash uintptr) uint8 {top := uint8(hash >> (goarch.PtrSize*8 - 8))if top < minTopHash {top += minTopHash}return top
}上面函数中 hash 是 64 位的,sys.PtrSize 值是 8,所以 top := uint8(hash >> (sys.PtrSize*8 - 8)) 等效 top = uint8(hash >> 56),最后 top 取出来的值就是 hash 的高 8 位值。
在 bucket 及 bucket 的 overflow 中寻找 tophash 值(HOB hash)为 151* 的 槽位,即为 key 所在位置,找到了空槽位或者 2 号槽位,这样整个查找过程就结束了,其中找到空槽位代表没找到。
for ; b != nil; b = b.overflow(t) {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {// 未被使用的槽位,插入if b.tophash[i] == emptyRest {break bucketloop}continue}// 找到tophash值对应的的keyk := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))if t.key.equal(key, k) {e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))return e}}} 
5. 返回 key 对应的指针
如果通过上面的步骤找到了 key 对应的槽位下标 i,我们再详细分析下 key/value 值是如何获取的:
// keys的偏移量
dataOffset = unsafe.Offsetof(struct{b bmapv int64
}{}.v)// 一个bucket的元素个数
bucketCnt = 8// key 定位公式
k :=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))// value 定位公式
v:= add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))bucket 里 keys 的起始地址就是 unsafe.Pointer(b)+dataOffset。
第 i 个下标 key 的地址就要在此基础上跨过 i 个 key 的大小;
而我们又知道,value 的地址是在所有 key 之后,因此第 i 个下标 value 的地址还需要加上所有 key 的偏移。
33. Go Map 冲突的解决方式?
比较常用的 Hash 冲突解决方案有链地址法和开放寻址法:
1. 链地址法
当哈希冲突发生时,创建新单元,并将新单元添加到冲突单元所在链表的尾部。
2. 开放寻址法
当哈希冲突发生时,从发生冲突的那个单元起,按照一定的次序,从哈希表中寻找一个空闲的单元,然后把发生冲突的元素存入到该单元。开放寻址法需要的表长度要大于等于所需要存放的元素数量。
开放寻址法有多种方式:线性探测法、平方探测法、随机探测法和双重哈希法。这里以线性探测法来帮助读者理解开放寻址法思想。
线性探测法
设 Hash(key) 表示关键字 key 的哈希值, 表示哈希表的槽位数(哈希表的大小)。
线性探测法则可以表示为:
如果 Hash(x) % M 已经有数据,则尝试 (Hash(x) + 1) % M ;
如果 (Hash(x) + 1) % M 也有数据了,则尝试 (Hash(x) + 2) % M ;
如果 (Hash(x) + 2) % M 也有数据了,则尝试 (Hash(x) + 3) % M ;
两种解决方案比较
对于链地址法,基于数组 + 链表进行存储,链表节点可以在需要时再创建,不必像开放寻址法那样事先申请好足够内存,因此链地址法对于内存的利用率会比开方寻址法高。链地址法对装载因子的容忍度会更高,并且适合存储大对象、大数据量的哈希表。而且相较于开放寻址法,它更加灵活,支持更多的优化策略,比如可采用红黑树代替链表。但是链地址法需要额外的空间来存储指针。
对于开放寻址法,它只有数组一种数据结构就可完成存储,继承了数组的优点,对 CPU 缓存友好,易于序列化操作。但是它对内存的利用率不如链地址法,且发生冲突时代价更高。当数据量明确、装载因子小,适合采用开放寻址法。
总结
在发生哈希冲突时,Python 中 dict 采用的开放寻址法,Java 的 HashMap 采用的是链地址法,而 Go map 也采用链地址法解决冲突,具体就是插入 key 到 map 中时,当 key 定位的桶填满 8 个元素后(这里的单元就是桶,不是元素),将会创建一个溢出桶,并且将溢出桶插入当前桶所在链表尾部。
if inserti == nil {// all current buckets are full, allocate a new one.newb := h.newoverflow(t, b)// 创建一个新的溢出桶inserti = &newb.tophash[0]insertk = add(unsafe.Pointer(newb), dataOffset)elem = add(insertk, bucketCnt*uintptr(t.keysize))
}34. Go Map 的负载因子为什么是 6.5?
什么是负载因子?
负载因子(load factor),用于衡量当前哈希表中空间占用率的核心指标,也就是每个 bucket 桶存储的平均元素个数。
负载因子 = 哈希表存储的元素个数/桶个数
另外负载因子与扩容、迁移等重新散列(rehash)行为有直接关系:
-
在程序运行时,会不断地进行插入、删除等,会导致 bucket 不均,内存利用率低,需要迁移。
-
在程序运行时,出现负载因子过大,需要做扩容,解决 bucket 过大的问题。
负载因子是哈希表中的一个重要指标,在各种版本的哈希表实现中都有类似的东西,主要目的是为了平衡 buckets 的存储空间大小和查找元素时的性能高低。
在接触各种哈希表时都可以关注一下,做不同的对比,看看各家的考量。
为什么是 6.5?
为什么 Go 语言中哈希表的负载因子是 6.5,为什么不是 8 ,也不是 1。这里面有可靠的数据支撑吗?
测试报告
实际上这是 Go 官方的经过认真的测试得出的数字,一起来看看官方的这份测试报告。
报告中共包含 4 个关键指标,如下:
| loadFactor | %overflow | bytes/entry | hitprobe | missprobe |
| 4 | 2.13 | 20.77 | 3 | 4 |
| 4.5 | 4.05 | 17.3 | 3.25 | 4.5 |
| 5 | 6.85 | 14.77 | 3.5 | 5 |
| 5.5 | 10.55 | 12.94 | 3.75 | 5.5 |
| 6 | 15.27 | 11.67 | 4 | 6 |
| 6.5 | 20.9 | 10.79 | 4.25 | 6.5 |
| 7 | 27.14 | 10.15 | 4.5 | 7 |
| 7.5 | 34.03 | 9.73 | 4.75 | 7.5 |
| 8 | 41.1 | 9.4 | 5 | 8 |
-
loadFactor:负载因子,也有叫装载因子。
-
%overflow:溢出率,有溢出 bukcet 的百分比。
-
bytes/entry:平均每对 key/value 的开销字节数.
-
hitprobe:查找一个存在的 key 时,要查找的平均个数。
-
missprobe:查找一个不存在的 key 时,要查找的平均个数。
选择数值
Go 官方发现:装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元素越少,冲突发生的几率减小,但空间浪费也会变得更多,而且还会提高扩容操作的次数。
根据这份测试结果和讨论,Go 官方取了一个相对适中的值,把 Go 中的 map 的负载因子硬编码为 6.5,这就是 6.5 的选择缘由。
这意味着在 Go 语言中,当 map存储的元素个数大于或等于 6.5 * 桶个数 时,就会触发扩容行为。
35. Go Map 的底层实现原理
Go 中的 map 是一个指针,占用 8 个字节,指向 hmap 结构体。
源码包中 src/runtime/map.go 定义了 hmap 的数据结构:
hmap 包含若干个结构为 bmap 的数组,每个 bmap 底层都采用链表结构,bmap 通常叫其 bucket。

hmap 结构体
// A header for a Go map.
type hmap struct {count int // 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。flags uint8 // 状态标志(是否处于正在写入的状态等)B uint8 // buckets(桶)的对数// 如果B=5,则buckets数组的长度 = 2^B=32,意味着有32个桶noverflow uint16 // 溢出桶的数量hash0 uint32 // 生成hash的随机数种子buckets unsafe.Pointer // 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。oldbuckets unsafe.Pointer // 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。nevacuate uintptr // 表示扩容进度,小于此地址的buckets代表已搬迁完成。extra *mapextra // 存储溢出桶,这个字段是为了优化GC扫描而设计的,下面详细介绍}bmap 结构体
bmap 就是我们常说的 “桶”,一个桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果的低 B 位是相同的,关于 key 的定位我们在 map 的查询中详细说明。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有 8 个位置)。
// A bucket for a Go map.
type bmap struct {tophash [bucketCnt]uint8 // len为8的数组// 用来快速定位key是否在这个bmap中// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}上面 bmap 结构是静态结构,在编译过程中 runtime.bmap 会拓展成以下结构体:
type bmap struct{tophash [8]uint8keys [8]keytype // keytype 由编译器编译时候确定values [8]elemtype // elemtype 由编译器编译时候确定overflow uintptr // overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}tophash 就是用于实现快速定位 key 的位置,在实现过程中会使用 key 的 hash 值的高 8 位作为 tophash 值,存放在 bmap 的 tophash 字段中。
tophash 字段不仅存储 key 哈希值的高 8 位,还会存储一些状态值,用来表明当前桶单元状态,这些状态值都是小于 minTopHash 的。
为了避免 key 哈希值的高 8 位值和这些状态值相等,产生混淆情况,所以当 key 哈希值高 8 位若小于 minTopHash 时候,自动将其值加上 minTopHash 作为该 key 的 tophash。桶单元的状态值如下:
emptyRest = 0 // 表明此桶单元为空,且更高索引的单元也是空
emptyOne = 1 // 表明此桶单元为空
evacuatedX = 2 // 用于表示扩容迁移到新桶前半段区间
evacuatedY = 3 // 用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 // 用于表示此单元已迁移
minTopHash = 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值func tophash(hash uintptr) uint8 {top := uint8(hash >> (goarch.PtrSize*8 - 8))if top < minTopHash {top += minTopHash}return top
}mapextra 结构体
当 map 的 key 和 value 都不是指针类型时候,bmap 将完全不包含指针,那么 gc 时候就不用扫描 bmap。bmap 指向溢出桶的字段 overflow 是 uintptr 类型,为了防止这些 overflow 桶被 gc 掉,所以需要 mapextra.overflow 将它保存起来。如果 bmap 的 overflow 是 *bmap 类型,那么 gc 扫描的是一个个拉链表,效率明显不如直接扫描一段内存 (hmap.mapextra.overflow)。
type mapextra struct {overflow *[]*bmap// overflow 包含的是 hmap.buckets 的 overflow 的 bucketsoldoverflow *[]*bma// oldoverflow 包含扩容时 hmap.oldbuckets 的 overflow 的 bucketnextOverflow *bmap // 指向空闲的 overflow bucket 的指针
}总结
bmap(bucket)内存数据结构可视化如下:
注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式,当 key 和 value 类型不一样的时候,key 和 value 占用字节大小不一样,使用 key/value 这种形式可能会因为内存对齐导致内存空间浪费,所以 Go 采用 key 和 value 分开存储的设计,更节省内存空间。
相关文章:
【Golang 面试 - 基础题】每日 5 题(七)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...

教你如何从Flink小白成为Contributor最终拿到腾讯的Offer
简言:一开始我也是怀揣着成为一个技术大老的梦想开始的,尽管我现在已经入职腾讯三年多了有时候觉得自己还是一个菜鸡哈..... 写这个文章希望可以帮助到刚刚接触大数据,并且对技术怀揣着梦想的朋友们,大家互相学习哈(对Flink不是很…...

java-数据结构与算法-02-数据结构-07-优先队列
1. 概念 队列是一种先进先出的结构,但是有些时候,要操作的数据带有优先级,一般出队时,优先级较高的元素先出队,这种数据结构就叫做优先级队列。 比如:你在打音游的时候,你的朋友给你打了个电话…...

从0开始搭建vue + flask 旅游景点数据分析系统(一):创建前端项目
基于scrapy爬取到的景点和评论数据,本期开始搭建一个vueflask的前后端分离的数据分析系统。 本教程为麦麦原创,也可以去B站找我 👉🏻 我的空间 🧑🎓 前置课程 🕸 scrapy实战 爬取景点信息和…...

支持AI的好用的编辑器aieditor
一、工具概述 AiEditor 是一个面向 AI 的下一代富文本编辑器,她基于 Web Component,因此支持 Layui、Vue、React、Angular 等几乎任何前端框架。她适配了 PC Web 端和手机端,并提供了 亮色 和 暗色 两个主题。除此之外,她还提供了…...

数据结构之《栈》
在之前我们已经学习了数据结构中线性表里面的顺序表与链表,了解了如何实现顺序表与链表增、删、查、该等功能。其实在线性表中除了顺序表和链表还有其他的类别,在本篇中我们就将学习另外一种线性表——栈,在通过本篇的学习后,你将…...

Vue3基础语法
一:创建Vue3工程(适用Vite打包工具) Vite官网:Home | Vite中文网 (vitejs.cn) 直接新建一个文件夹,打开cmd运行: npm create vitelatest 选择Vue和TS语言即可 生成一个项目。 Vue3的核心语法ÿ…...

【Python】基础学习技能提升代码样例4:常见配置文件和数据文件读写ini、yaml、csv、excel、xml、json
一、 配置文件 1.1 ini 官方-configparser config.ini文件如下: [url] ; section名称baidu https://www.zalou.cnport 80[email]sender ‘xxxqq.com’import configparser # 读取 file config.ini # 创建配置文件对象 con configparser.ConfigParser() # 读…...

JavaScript基础——JavaScript调用的三种方式
JavaScript简介 JavaScript的作用 JavaScript的使用方式 内嵌JS 引入外部js文件 编写函数 JavaScript简介 JavaScript(简称“JS”)是一种具有函数优先的轻量级,解释型或即时编译型的编程语言。它是Web开发中最常用的脚本语言之一&#x…...

ITSS:IT服务工程师
证书亮点:适中的费用、较低的难度、广泛的应用范围以及专业的运维认证。 总体评价:性价比良好! 证书名称:ITSS服务工程师 证书有效期:持续3年 培训要求:必须参加培训,否则将无法参与考试 发…...

鸿蒙开发——axios封装请求、拦截器
描述:接口用的是PHP,框架TP5 源码地址 链接:https://pan.quark.cn/s/a610610ca406 提取码:rbYX 请求登录 HttpUtil HttpApi 使用方法...

Scikit-Learn中的分层特征工程:构建更精准的数据洞察
Scikit-Learn中的分层特征工程:构建更精准的数据洞察 在机器学习中,特征工程是提升模型性能的核心技术之一。Scikit-Learn(简称sklearn),作为Python中广受欢迎的机器学习库,提供了多种方法来进行特征工程&…...

CSOL遭遇DDOS攻击如何解决
CSOL遭遇DDOS攻击如何解决?在错综复杂的数字网络丛林中,《Counter-Strike Online》(简称CSOL)犹如一座坚固的堡垒,屹立在游戏世界的中心,吸引着无数玩家的目光与热情。这座堡垒并非无懈可击,DDo…...
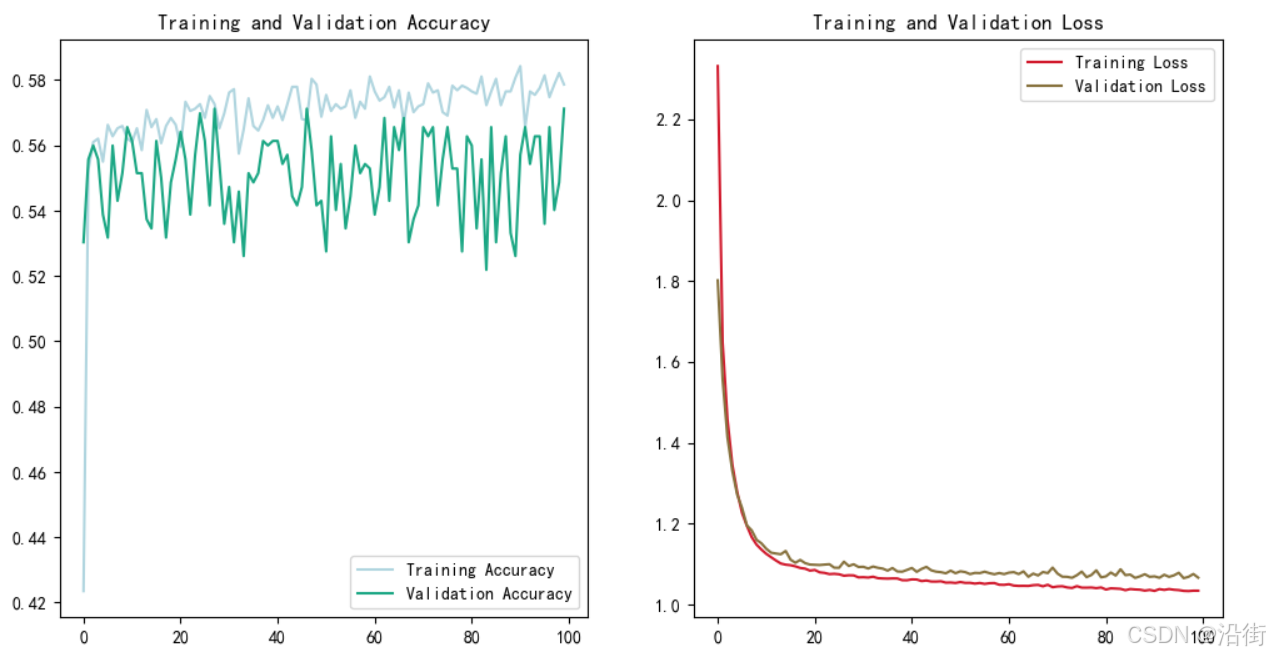
基于python的BP神经网络红酒品质分类预测模型
1 导入必要的库 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Sequential from tenso…...

Kylin与Spark:大数据技术集成的深度解析
引言 在大数据时代,企业面临着海量数据的处理和分析需求。Kylin 和 Spark 作为两个重要的大数据技术,各自在数据处理领域有着独特的优势。Kylin 是一个开源的分布式分析引擎,专为大规模数据集的 OLAP(在线分析处理)查…...

⌈ 传知代码 ⌋ 利用scrapy框架练习爬虫
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...
)
深入了解 Python 面向对象编程(最终篇)
大家好!今天我们将继续探讨 Python 中的类及其在面向对象编程(OOP)中的应用。面向对象编程是一种编程范式,它使用“对象”来模拟现实世界的事务,使代码更加结构化和易于维护。在上一篇文章中,我们详细了解了…...

手把手教你实现基于丹摩智算的YoloV8自定义数据集的训练、测试。
摘要 DAMODEL(丹摩智算)是专为AI打造的智算云,致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署。 官网链接:https://damodel.com/register?source6B008AA9 平台的优势 💡 超友好! …...

SSH相关
前言 这篇是K8S及Rancher部署的前置知识。因为项目部署测试需要,向公司申请了一个虚拟机做服务器用。此前从未接触过服务器相关的东西,甚至命令也没怎么接触过(接触最多的还是git命令,但我日常用sourceTree)。本篇SSH…...
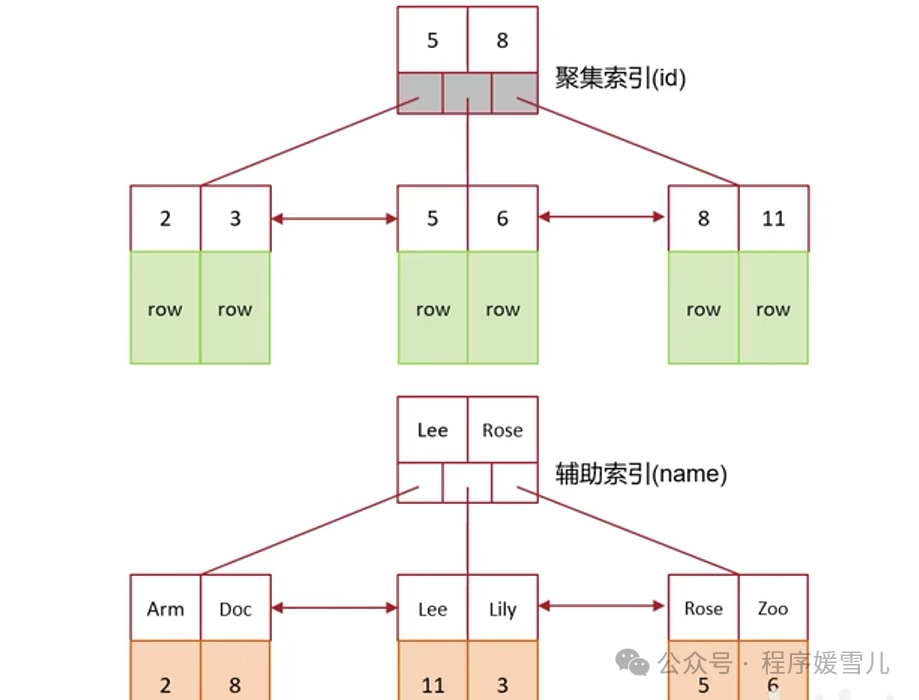
mysql超大分页问题处理~
大家好,我是程序媛雪儿,今天咱们聊mysql超大分页问题处理。 超大分页问题是什么? 数据量很大的时候,在查询中,越靠后,分页查询效率越低 例如 select * from tb_sku limit 0,10; select * from tb_sku lim…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...
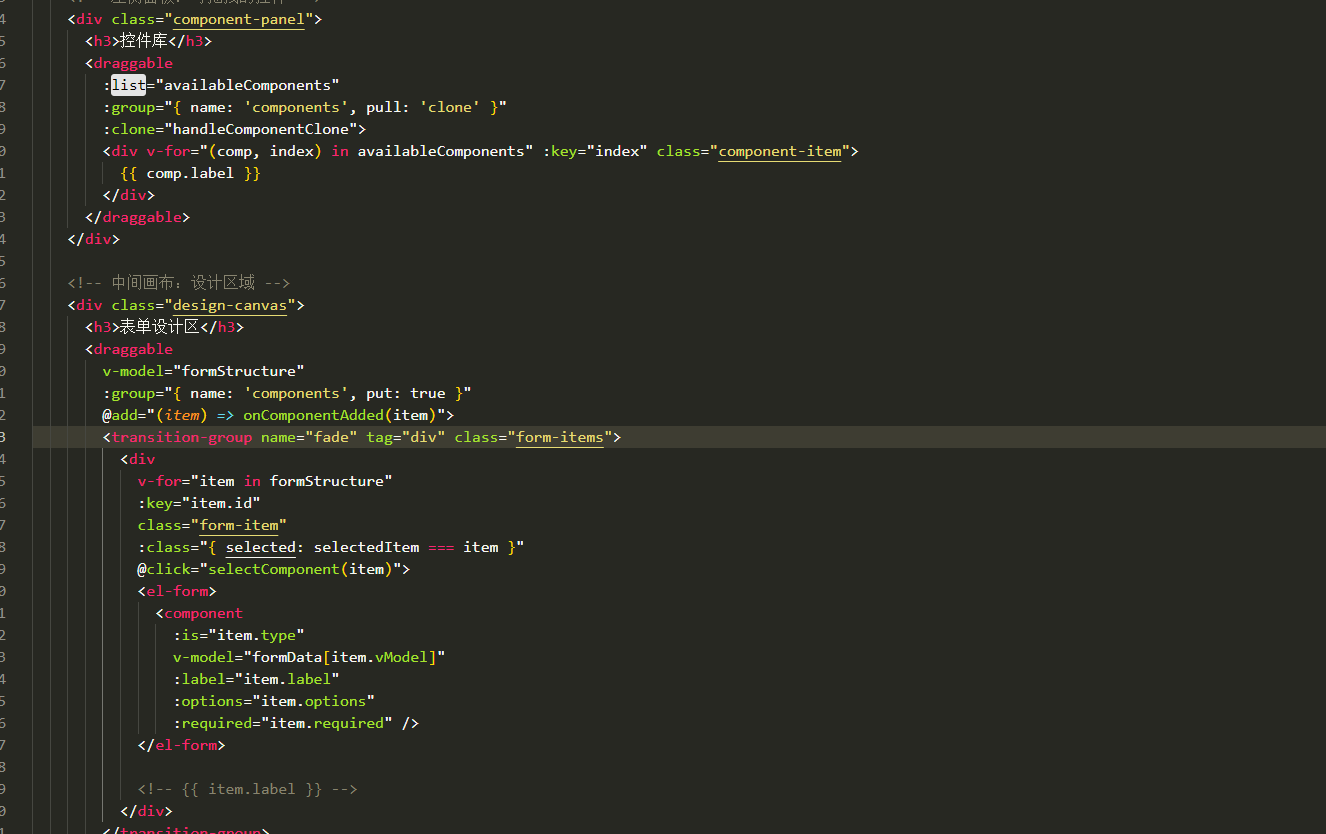
表单设计器拖拽对象时添加属性
背景:因为项目需要。自写设计器。遇到的坑在此记录 使用的拖拽组件时vuedraggable。下面放上局部示例截图。 坑1。draggable标签在拖拽时可以获取到被拖拽的对象属性定义 要使用 :clone, 而不是clone。我想应该是因为draggable标签比较特。另外在使用**:clone时要将…...