实战:安装ElasticSearch 和常用操作命令
概叙
科普文:深入理解ElasticSearch体系结构-CSDN博客
Elasticsearch各版本比较

ElasticSearch 单点安装
1 创建普通用户
#1 创建普通用户名,密码
[root@hlink1 lyz]# useradd lyz
[root@hlink1 lyz]# passwd lyz#2 然后 关闭xshell 重新登录 ip 地址 用 lyz 用户登录#3 为 lyz 用户分配 sudoer 权限
[lyz@hlink1 ~]$ su
[lyz@hlink1 ~]$ vi /etc/sudoers
# 在 root ALL=(ALL) ALL 下面添加普通用户权限lyz ALL=(ALL) ALL2 下载安装 ES
# 4 下载安装包
[lyz@hlink1 ~]$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.2-linux-x86_64.tar.gz
# 5 解压安装包
[lyz@hlink1 ~]$ tar -xzf elasticsearch-7.15.2-linux-x86_64.tar.gz# 6 修改配置
[lyz@hlink1 ~]# cd elasticsearch-7.15.2/config
[lyz@hlink1 elasticsearch-7.15.2]# mkdir log
[lyz@hlink1 elasticsearch-7.15.2]# mkdir data
[lyz@hlink1 elasticsearch-7.15.2]# cd config
[lyz@hlink1 config]# rm -rf elasticsearch.yml
[lyz@hlink1 config]# vim elasticsearch.yml# 粘贴如下内容# 配置集群名称,保证每个节点的名称相同,如此就能都处于一个集群之内了
cluster.name: lyz-es
# # 每一个节点的名称,必须不一样
node.name: hlink1
path.data: /home/lyz/elasticsearch-7.15.2/log
path.logs: /home/lyz/elasticsearch-7.15.2/data
network.host: 0.0.0.0
# # http端口(使用默认即可)
http.port: 9200
# # 集群列表,你es集群的ip地址列表
discovery.seed_hosts: ["hlink1"]
# # 启动的时候使用一个master节点
cluster.initial_master_nodes: ["hlink1"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"3 修改 jvm.option
修改 jvm.option 配置文件,调整 jvm 堆内存大小,每个人根据自己服务器的内存大小来进行调整
# 7 修改 jvm.option 配置文件
[lyz@hlink1 config]# vim jvm.options
-Xms2g
-Xmx2g4 修改系统配置,解决启动问题
由于使用普通用户来安装 es 服务,且 es 服务对服务器的资源要求比较多,包括内存大小,线程数等。所以我们需要给普通用户解开资源的束缚
ES 因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux 系统当中打开文件最大数目的限制,不然 ES 启动就会抛错
进入 Root 用户
# 8 进入 root 用户
[lyz@hlink1 config]# su
Password:# 9 在最下面添加如下内容: 注意*不要去掉了
[root@hlink1 config]# sudo vim /etc/security/limits.conf* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 40965 普通用户启动线程数限制
修改普通用户可以创建的最大线程数
10 若为 Centos7,执行下面的命令
[root@hlink1 config]# sudo vim /etc/security/limits.d/20-nproc.conf# 找到如下内容:
* soft nproc 1024#修改为
* soft nproc 40966 普通用户调大虚拟内存
# 11 调大系统的虚拟内存
[root@hlink1 config]# vim /etc/sysctl.confvm.max_map_count=262144# 12 执行 sysctl -p
# 行完了 sysctl -p 若输出的结果和你配置的一样,说明配置成功了.
[root@hlink1 config]# sysctl -p
vm.max_map_count = 2621447 启动 ES 服务
# 13 切换用户
[root@hlink1 config]# exit
exit
[lyz@hlink1 config]$# 直接启动 es 或者 后台启动 es
[lyz@hlink1 config]$ cd ..
[lyz@hlink1 elasticsearch-7.15.2]$ cd bin
# 直接启动
[lyz@hlink1 bin]$ ./elasticsearch
# 后台启动 nohup ./elasticsearch 2>&1 &# 浏览器访问 http://hlink1:9200/?pretty
Elasticsearch集群搭建
一、环境配置
一主亮从;3节点
角色 IP地址 操作系统
master 99.99.10.30 CentOS Linux release 7.9.2009 (Core)
slave 99.99.10.31 CentOS Linux release 7.9.2009 (Core)
slave 99.99.10.32 CentOS Linux release 7.9.2009 (Core)# Elasticsearch 不能以 root 用户运行,创建一个新用户并赋予适当权限。
sudo adduser es
sudo passwd 123456
sudo usermod -aG sudo es
# 调整 vm.max_map_count 参数,以满足 Elasticsearch 的需求。
sudo sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
# 增加文件描述符限制。
sudo echo "elasticsearch - nofile 65535" | sudo tee -a /etc/security/limits.conf
sudo echo "elasticsearch - nproc 4096" | sudo tee -a /etc/security/limits.conf
# 调整内存锁定:
sudo echo "elasticsearch soft memlock unlimited" | sudo tee -a /etc/security/limits.conf
sudo echo "elasticsearch hard memlock unlimited" | sudo tee -a /etc/security/limits.conf
# 安装java
sudo yum install java-11-openjdk-devel -y
# 配置 JAVA_HOME 环境变量(在.bash_profile 文件,添加以下内容)
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk
export PATH=$JAVA_HOME/bin:$PATH
# 然后重新加载配置:
source ~/.bashrc
#检查Java版本
java -version
openjdk version "11.0.23" 2024-04-16 LTS
OpenJDK Runtime Environment (Red_Hat-11.0.23.0.9-2.el7_9) (build 11.0.23+9-LTS)
OpenJDK 64-Bit Server VM (Red_Hat-11.0.23.0.9-2.el7_9) (build 11.0.23+9-LTS, mixed mode, sharing)
二、安装elasticsearch
es官方下载地址,es和kibana尽量下载同一版本
elasticsearch各版本下载地址
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
kibana (es的可视化管理工具)
https://www.elastic.co/cn/downloads/past-releases/#kibana
# 解压elasticsearch包到/usr/local/下面:
tar -zxvf elasticsearch-7.10.0-linux-x86_64.tar.gz -C /usr/local/
#将elasticsearch-7.10.0重命名为es
cd /usr/local/
mv elasticsearch-7.10.0 es
# 这个文件夹用于存储 Elasticsearch 的数据,它将所有的索引数据和相关元数据存储在这个目录中
mkdir -p /data/elasticsearch_data/data
# 这个文件夹用于存储 Elasticsearch 的日志文件,记录了 Elasticsearch 的运行状态、错误信息和性能指标。
mkdir -p /data/elasticsearch_data/logs
sudo chown -R es:es /data/elasticsearch_data
sudo chmod -R 755 /data/elasticsearch_data
# 这个文件夹用于存储 Elasticsearch 的备份数据。
mkdir -p /opt/backup/es
mkdir -p /opt/backup/es1
sudo chown -R es:es /opt/backup/
sudo chmod -R 755 /opt/backup/
三、配置elasticsearch
1.先搭建单个节点,再复制到其他节点:
path.data: /opt/data
path.logs: /opt/logs#http访问端口,程序或kibana使用
http.port: 9200xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
# 尝试启动
./bin/elasticsearch
设置安全账号信息(ES要启动状态):执行以下命令,给各账号设置密码(演示使用的密码都为:123456), 整个集群只需要设置一次即可警告:设置账户密码切记要在单实例非集群模式时配置,不能添加任何集群的配置,否则会设置失败./bin/elasticsearch-setup-passwords interactive
2.集群配置:
cluster.name: elasticsearchnode.name: node1path.data: /data/elasticsearch_data/datapath.logs: /data/elasticsearch_data/logs#数据备份和恢复使用,可以一到多个目录
path.repo: ["/opt/backup/es", "/opt/backup/es1"]http.port: 9200#是否可以参与选举主节点
node.master: true#是否是数据节点
node.data: true#允许访问的ip,4个0的话则允许任何ip进行访问
network.host: 0.0.0.0#es各节点通信端口
transport.tcp.port: 9300#集群每个节点IP地址。
discovery.seed_hosts: ["99.99.10.30:9300", "99.99.10.31:9300", "99.99.10.32:9300"]#es7.x新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]#配置是否压缩tcp传输时的数据,默认为false,不压缩
transport.tcp.compress: true# 是否支持跨域,es-header插件使用
http.cors.enabled: true# *表示支持所有域名跨域访问
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length#集群模式开启安全 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.keystore.password: "123456"
xpack.security.transport.ssl.truststore.password: "123456"#默认为1s,指定了节点互相ping的时间间隔。
discovery.zen.fd.ping_interval: 1s#默认为30s,指定了节点发送ping信息后等待响应的时间,超过此时间则认为对方节点无响应。
discovery.zen.fd.ping_timeout: 30s#ping失败后重试次数,超过此次数则认为对方节点已停止工作。
discovery.zen.fd.ping_retries: 3
四、复制elasticsearch到其他节点
scp -r /usr/local/es/ root@99.99.10.31:/usr/local/
scp -r /usr/local/es/ root@99.99.10.32:/usr/local/sudo chown -R es:es /usr/local/es/
sudo chmod -R 755 /usr/local/es/五、测试elasticsearch集群
集群信息查看
# 切换到es用户
su es# 启动es
cd /usr/local/es/
./bin/elasticsearch# 查看集群信息
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/health?pretty"
{"cluster_name" : "elasticsearch","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 1,"active_shards" : 2,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
这个 JSON 响应显示了 Elasticsearch 集群的健康状态及其一些关键指标。指标解读如下:集群基本信息
cluster_name: "elasticsearch"
集群的名称。这是你在 elasticsearch.yml 配置文件中指定的名称。
集群健康状态
status: "green"
集群的健康状态。可能的状态有三种:
green: 所有主分片和副本分片都是可用的。
yellow: 所有主分片都是可用的,但有一些副本分片不可用。
red: 有一些主分片不可用。
timed_out: false
表示查询是否超时。false 表示查询在规定时间内完成。节点和分片信息
number_of_nodes: 3
集群中的节点总数。这里表示集群中有 3 个节点。
number_of_data_nodes: 3
集群中的数据节点总数。数据节点存储数据并处理搜索请求。这里表示所有 3 个节点都是数据节点。分片状态
active_primary_shards: 1
当前活动的主分片数量。主分片是实际存储数据的分片。
active_shards: 2
当前活动的总分片数量,包括主分片和副本分片。这里有 1 个主分片和 1 个副本分片。
relocating_shards: 0
正在重新分配的分片数量。重新分配是指将分片从一个节点移动到另一个节点。
initializing_shards: 0
正在初始化的分片数量。这些分片正在被分配和恢复。
unassigned_shards: 0
未分配的分片数量。可能是因为没有足够的节点来分配这些分片。
delayed_unassigned_shards: 0
延迟分配的未分配分片数量。这些分片被延迟分配,通常是因为某些节点暂时不可用。任务和队列信息
number_of_pending_tasks: 0
当前待处理的任务数量。任务可以是索引刷新、分片移动等。
number_of_in_flight_fetch: 0
当前正在获取的分片数量。通常是在执行搜索请求时从不同的分片获取数据。
task_max_waiting_in_queue_millis: 0
当前任务队列中等待时间最长的任务的等待时间(毫秒)。这里表示没有任务在队列中等待。活动分片百分比
active_shards_percent_as_number: 100.0
当前活动分片占所有分片的百分比。100% 表示所有分片都是活动的,没有分片是未分配的或初始化中的。创建索引验证
# 创建一个索引看集群中每个节点索引数据
curl -XPUT -u elastic:123456 "http://127.0.0.1:9200/test-index"curl -XGET -u elastic:123456 "http://localhost:9200/_cat/indices?pretty"
green open test-index _hNfQpNqTZWAsPKrqa51XA 1 1 0 0 416b 208b
green open .security-7 L6YSY_F0Sl207ijttvv4CQ 1 1 7 0 51.5kb 25.7kb
六、安装kibana和es-header插件:(可选)
# 下载kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.10.0-linux-x86_64.tar.gz# 解压到/usr/local/,并重命名为kibana
tar -zxvf kibana-7.10.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local/
mv kibana-7.10.0-linux-x86_64/ kibana# 配置kibana,并加入下面的配置
vim /usr/local/kibana/config/kibana.yml
--------------------------------------
#设置为中文
i18n.locale: "zh-CN"
#允许其它IP可以访问
server.host: "0.0.0.0"
elasticsearch.username: "kibana_system"
elasticsearch.password: "elastic123"
#es集群地址,填写真实的节点地址
elasticsearch.hosts: ["http://xxx.xx.xx.xx:9200","http://xxx.xx.xx.xx:9200","http://xxx.xx.xx.xx:9200"]
--------------------------------------# 启动kibana
cd /usr/local/kibana/
./bin/kibana
es-head安装如下面的官方文档所示:
https://github.com/mobz/elasticsearch-head
七、Elasticsearch如何合理的设置分片:
科普文:深入理解ElasticSearch体系结构-CSDN博客
一、什么是分片
在 Elasticsearch 中,索引是由一个或多个分片组成的。每个分片是一个完整的 Lucene 索引,独立存储数据并执行搜索操作。通过分片,Elasticsearch 可以将数据分布到多个节点上,从而提高系统的吞吐量和容错能力。
二、分片的类型
主分片(Primary Shard):
- 每个索引默认包含的分片。
- 数据首先写入主分片,然后再复制到副本分片。
- 主分片的数量在索引创建时确定,之后不能更改。
副本分片(Replica Shard):
- 主分片的副本,用于提高数据的高可用性和搜索性能。
- 默认情况下,每个主分片有一份副本分片。
- 可以动态调整副本的数量。
三、分片的工作原理
数据分布:当你向 Elasticsearch 索引文档时,Elasticsearch 会根据文档的 ID 计算一个哈希值,并根据这个哈希值决定将文档存储到哪个主分片。这种方式确保了文档在主分片间的均匀分布。
数据存储:当你向 Elasticsearch 索引文档时,Elasticsearch 会根据文档的 ID 计算一个哈希值,并根据这个哈希值决定将文档存储到哪个主分片。这种方式确保了文档在主分片间的均匀分布。
数据存储:每个分片是一个独立的 Lucene 索引,包含多个倒排索引。这些倒排索引用于高效的全文搜索。分片将文档分成多个段(segment),每个段是一个不可变的索引文件。随着文档的添加,新的段会不断创建,旧的段会被合并以优化性能和存储空间。
数据副本:副本分片存储在不同的节点上,以防止单点故障。如果一个主分片节点故障,Elasticsearch 可以将副本分片升级为主分片,并继续提供服务。副本分片不仅用于故障恢复,还可以分担搜索请求的负载,从而提高查询性能。
请求处理
写请求(Indexing Request):
- 写请求首先发送到主分片。
- 主分片将数据写入自身,然后将数据复制到对应的副本分片。
- 所有分片都成功写入后,返回确认响应。
读请求(Search Request):
- 读请求可以发送到任意一个副本分片,包括主分片。
- 通过这种方式,读请求可以被均衡地分配到所有分片,提高查询性能。
四、分片的优点
水平扩展:通过增加分片和节点,可以轻松扩展 Elasticsearch 集群以处理更多数据和更高的查询负载。
高可用性:通过副本分片,Elasticsearch 提供了数据冗余,确保在节点故障时数据不会丢失。
高性能:分片使得搜索和索引请求可以并行处理,提高了系统的吞吐量。
五、分片如何设置
分片的官方建议:我在 Elasticsearch 集群内应该设置多少个分片? | Elastic Blog
1、分片过小会导致段过小,进而致使开销增加。您要尽量将分片的平均大小控制在至少几 GB 到几十 GB 之间。
对时序型数据用例而言,分片大小通常介于 20GB 至 40GB 之间。
2、由于单个分片的开销取决于段数量和段大小,所以通过 forcemerge 操作强制将
较小的段合并为较大的段能够减少开销并改善查询性能。理想状况下,
应当在索引内再无数据写入时完成此操作。请注意:这是一个极其耗费资源的操作,
所以应该在非高峰时段进行。
3、每个节点上可以存储的分片数量与可用的堆内存大小成正比关系,但是 Elasticsearch并未
强制规定固定限值。这里有一个很好的经验法则:确保对于节点上已配置的每个 GB,将分片数量
保持在 20 以下。如果某个节点拥有 30GB 的堆内存,那其最多可有 600 个分片,但是在此限值范围内,您设置的分片数量越少,效果就越好。一般而言,这可以帮助集群保持良好的运行状态。
(编者按:从 8.3 版开始,我们大幅减小了每个分片的堆使用量,
因此对本博文中的经验法则也进行了相应更新。请按照以下提示了解 8.3+ 版本的
Elasticsearch。)
在网上总结的:
每个分片的数据量不超过最大JVM堆空间设置,一般不超过32G。如果一个索引大概500G,那分片大概在16个左右比较合适。
单个索引分片个数一般不超过节点数的3倍,推荐是1.5 ~ 3倍之间。假如一个集群3个节点,根据索引数据量大小分片数在5-9之间比较合适。
主分片、副本和节点数,分配时也可以参考以下关系:节点数<= 主分片数 * (副本数 +1 )
创建索引时指定分片数量:
PUT /my_index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
Elasticsearch常用操作命令:
# es启动:./bin/elasticsearch# 访问地址:http://localhost:9200/ 默认9200端口# Kibana 启动:./bin/Kibana# 访问地址:http://localhost:5600/ 默认5600端口
# 查看集群状态
# 检查集群运行情况:
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/health?v"# 查看集群节点列表:
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/nodes"# 查看所有索引:
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/indices?v"
# 索引操作API
# 1.查询查看分片状态-Authorization方式(postman通过账密获取token)
curl -XGET ‘http://127.0.0.1:9200/_cluster/allocation/explain?pretty’ --header ‘Authorization’: Basic ZWxhc3RpYzphcDIwcE9QUzIw’# 2.查询查看分片状态-账密方式
curl -XGET -u elastic "http://127.0.0.1:9200/_cluster/allocation/explain?pretty" -H ‘Content-Type:application/json’# 3.查询集群状态命令
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/health?pretty"# 4.查询Es全局状态
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/stats?pretty"# 5.查询集群设置
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cluster/settings?pretty"# 6.查询集群文档总数
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/count?v"# 7.查看当前集群索引分片信息
curl -XGET -u elastic:123456 "http://127.0.0.1:9200/_cat/shards?v"# 8.查看集群实例存储详细信息
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/allocation?v"# 9.查看当前集群的所有实例
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/nodes?v"# 10.查看当前集群等待任务
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/pending_tasks?v"# 11.查看集群查询线程池任务
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/thread_pool/search?v"# 12.查看集群写入线程池任务
curl -XGET -u elastic "http://127.0.0.1:9200/_cat/thread_pool/bulk?v"# 13.清理ES所有缓存
curl -XPOST "http://127.0.0.1:9200/_cache/clear"# 14.查询索引信息
curl -XGET -u : ‘https://127.0.0.1:9200/licence_info_test?pretty’# 15.关闭索引
curl -XGET -u : ‘https://127.0.0.1:9200/my_index/_close?pretty’# 16.打开索引
curl -XGET -u : ‘https://127.0.0.1:9200/my_index/_open?pretty’01 ES索引搜索查询(MySQL和ES对比)

简单梳理了一下ES JavaAPI的相关体系,感兴趣的可以自己研读一下源码。


02 词条查询
所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。
2.1 等值查询-term
等值查询,即筛选出一个字段等于特定值的所有记录。
SQL:
| 1 |
|
而使用ES查询语句却很不一样(注意查询字段带上keyword):
| 1 2 3 4 5 6 7 8 9 10 11 |
|
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
查询结果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
Java 中构造 ES 请求的方式:(后续例子中只保留 SearchSourceBuilder 的构建语句)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
仔细观察查询结果,会发现ES查询结果中会带有_score这一项,ES会根据结果匹配程度进行评分。打分是会耗费性能的,如果确认自己的查询不需要评分,就设置查询语句关闭评分:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
Java构建查询语句:
| 1 2 3 |
|
2.2 多值查询-terms
多条件查询类似 Mysql 里的IN 查询,例如:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
Java 实现:
| 1 2 3 4 |
|
2.3 范围查询-range
范围查询,即查询某字段在特定区间的记录。
SQL:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
Java构建查询条件:
| 1 2 3 4 |
|
2.4 前缀查询-prefix
前缀查询类似于SQL中的模糊查询。
SQL:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 |
|
Java构建查询条件:
| 1 2 3 4 |
|
2.5 通配符查询-wildcard
通配符查询,与前缀查询类似,都属于模糊查询的范畴,但通配符显然功能更强。
SQL:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 |
|
Java构建查询条件:
| 1 2 3 |
|
03 负责查询
前面的例子都是单个条件查询,在实际应用中,我们很有可能会过滤多个值或字段。先看一个简单的例子:
| 1 |
|
这样的多条件等值查询,就要借用到组合过滤器了,其查询语句是:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
Java构造查询语句:
| 1 2 3 4 5 6 |
|
3.1 布尔查询
布尔过滤器(bool filter)属于复合过滤器(compound filter)的一种 ,可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合。
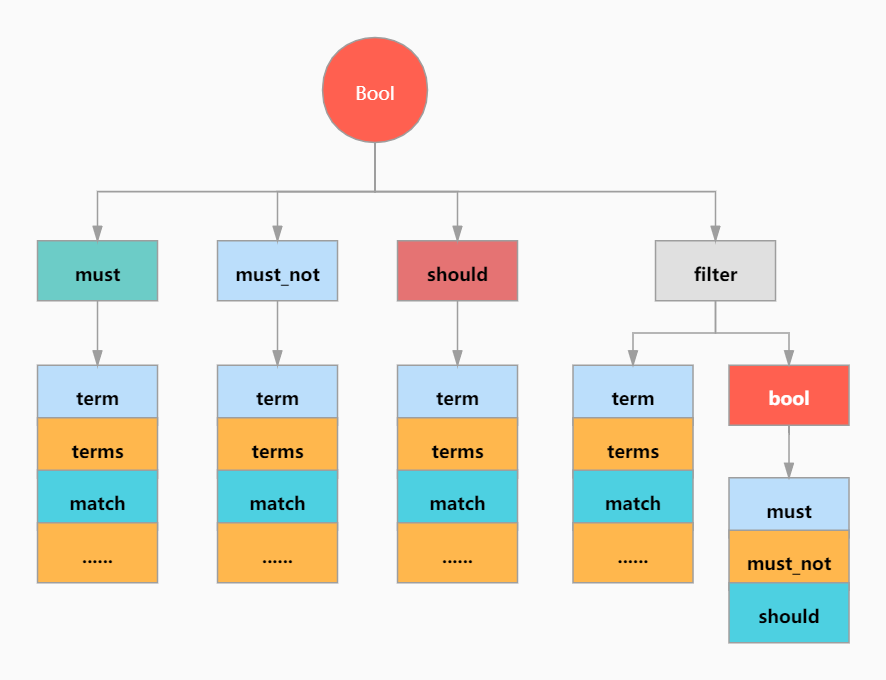
bool 过滤器下可以有4种子条件,可以任选其中任意一个或多个。filter是比较特殊的,这里先不说。
| 1 2 3 4 5 6 7 |
|
- must:所有的语句都必须匹配,与 ‘=’ 等价。
- must_not:所有的语句都不能匹配,与 ‘!=’ 或 not in 等价。
- should:至少有n个语句要匹配,n由参数控制。
精度控制:
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢?默认情况下,没有 should 语句是必须匹配的,只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
我们可以通过 minimum_should_match 参数控制需要匹配的 should 语句的数量,它既可以是一个绝对的数字,又可以是个百分比:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
Java构建查询语句:
| 1 2 3 4 5 6 7 8 |
|
最后,看一个复杂些的例子,将bool的各子句联合使用:
| 1 |
|
用 Elasticsearch 来表示上面的 SQL 例子:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
|
用Java构建这个查询条件:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
3.2 Filter查询
query和filter的区别:query查询的时候,会先比较查询条件,然后计算分值,最后返回文档结果;而filter是先判断是否满足查询条件,如果不满足会缓存查询结果(记录该文档不满足结果),满足的话,就直接缓存结果,filter不会对结果进行评分,能够提高查询效率。
filter的使用方式比较多样,下面用几个例子演示一下。
方式一,单独使用:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
单独使用时,filter与must基本一样,不同的是filter不计算评分,效率更高。
Java构建查询语句:
| 1 2 3 4 5 |
|
方式二,和must、must_not同级,相当于子查询:
| 1 |
|
ES查询语句:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
Java:
| 1 2 3 4 5 6 |
|
方式三,将must、must_not置于filter下,这种方式是最常用的:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
|
Java:
| 1 2 3 4 5 6 7 8 |
|
04 聚合查询
接下来,我们将用一些案例演示ES聚合查询。
4.1 最值、平均值、求和
案例:查询最大年龄、最小年龄、平均年龄。
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 |
|
Java:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
使用聚合查询,结果中默认只会返回10条文档数据(当然我们关心的是聚合的结果,而非文档)。返回多少条数据可以自主控制:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
而Java中只需增加下面一条语句即可:
| 1 |
|
与max类似,其他统计查询也很简单:
| 1 2 3 4 |
|
4.2 去重查询
案例:查询一共有多少个门派。
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 |
|
Java:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
4.3 分组聚合
4.3.1 单条件分组
案例:查询每个门派的人数
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
Java:
| 1 2 3 4 5 6 |
|
4.3.2 多条件分组
案例:查询每个门派各有多少个男性和女性
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
4.4 过滤聚合
前面所有聚合的例子请求都省略了 query ,整个请求只不过是一个聚合。这意味着我们对全部数据进行了聚合,但现实应用中,我们常常对特定范围的数据进行聚合,例如下例。
案例:查询明教中的最大年龄。这涉及到聚合与条件查询一起使用。
SQL:
| 1 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
Java:
| 1 2 3 4 5 6 7 |
|
另外还有一些更复杂的查询例子。
案例:查询0-20,21-40,41-60,61以上的各有多少人。
SQL:
| 1 2 3 4 5 6 7 |
|
ES:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
查询结果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
相关文章:
实战:安装ElasticSearch 和常用操作命令
概叙 科普文:深入理解ElasticSearch体系结构-CSDN博客 Elasticsearch各版本比较 ElasticSearch 单点安装 1 创建普通用户 #1 创建普通用户名,密码 [roothlink1 lyz]# useradd lyz [roothlink1 lyz]# passwd lyz#2 然后 关闭xshell 重新登录 ip 地址…...

React-Native 宝藏库大揭秘:精选开源项目与实战代码解析
1. 引言 1.1 React-Native 简介 React-Native 是由 Facebook 开发的一个开源框架,它允许开发者使用 JavaScript 和 React 的编程模型来构建跨平台的移动应用。React-Native 的核心理念是“Learn Once, Write Anywhere”,即学习一次 React 的编程模型&am…...

数据结构:二叉树(链式结构)
文章目录 1. 二叉树的链式结构2. 二叉树的创建和实现相关功能2.1 创建二叉树2.2 二叉树的前,中,后序遍历2.2.1 前序遍历2.2.2 中序遍历2.2.3 后序遍历 2.3 二叉树节点个数2.4 二叉树叶子结点个数2.5 二叉树第k层结点个数2.6 二叉树的深度/高度2.7 二叉树…...

召唤生命,阻止轻生——《生命门外》
本书的目的,就是阻止自杀!拉回那些深陷在这样的思维当中正在挣扎犹豫的人,提醒他们珍爱生命,让更多的人,尤其是年轻人从执迷不悟的犹豫徘徊中幡然醒悟,回归正常的生活。 网络上抱孩子跳桥轻生的母亲&#…...

JVM:栈上的数据存储
文章目录 一、Java虚拟机中的基本数据类型 一、Java虚拟机中的基本数据类型 在Java中有8大基本数据类型: 这里的内存占用,指的是堆上或者数组中内存分配的空间大小,栈上的实现更加复杂。 Java中的8大数据类型在虚拟机中的实现:…...

C#实战 - C#实现发送邮件的三种方法
作者:逍遥Sean 简介:一个主修Java的Web网站\游戏服务器后端开发者 主页:https://blog.csdn.net/Ureliable 觉得博主文章不错的话,可以三连支持一下~ 如有疑问和建议,请私信或评论留言! 前言 当使用 C# 编程…...

数模原理精解【5】
文章目录 二元分布满足要求边际分布条件概率例子1例子2 损失函数概率分布期望值例 参考文献 二元分布 满足要求 连续情况下, φ ( x , y ) \varphi (x,y) φ(x,y)为随机变量 X 、 Y X、Y X、Y的联合概率分布(二元分布),如果以下条件满足: …...

C语言篇——使用运算符将16进制数据反转
比如:将一个16进制0xFD,即11111101,反向,输出10111111,即0xBF。 #include <stdio.h>unsigned char reverseBits(unsigned char num) {unsigned char reverse_num 0;int i;for (i 0; i < 8; i) {if ((num &…...
)
2025年和2024CFA一级SchweserKaplan Notes 全集 (内附分享链接)
CFA一级notes百度网盘下载 2024年和2025年 CFA一级考纲已经正式发布,相比与老考纲,新考纲变化实在不算小。 2024年和2025年 CFA一级notes完整版全 https://drive.uc.cn/s/6394c0b6b1a54?public1 2024年和2025年 cfa二级notes完整版全 https://driv…...

B树的实现:代码示例与解析
B树的实现:代码示例与解析 引言 B树是一种自平衡的树数据结构,广泛应用于文件系统和数据库系统中。它是一种多路搜索树,旨在保持数据有序并允许高效的查找、插入和删除操作。本文将深入探讨B树的实现,提供完整的代码示例和详细的…...

HCIA总结
一、情景再现:ISP网络为学校提供了DNS服务,所以,DNS服务器驻留在ISP网络内,而不再学校网络内。DHCP服务器运行在学校网络的路由器上 小明拿了一台电脑,通过网线,接入到校园网内部。其目的是为了访问谷歌网站…...

软件测试_接口测试面试题
接口测试是软件测试中的重要环节,它主要验证系统不同模块之间的通信和数据交互是否正常。在软件开发过程中,各个模块之间的接口是实现功能的关键要素,因此对接口进行全面而准确的测试是确保系统稳定性和可靠性的关键步骤。 接口测试的核心目…...
)
C++初阶学习第五弹——类与对象(下)
类与对象(上):C初阶学习第三弹——类与对象(上)-CSDN博客 类和对象(中):C初阶学习第四弹——类与对象(中)-CSDN博客 一.赋值运算符重载 1.1 运算符重载 C为…...

最低工资标准数据(2001-2023年不等)、省市县,整理好的面板数据(excel格式)
时间范围:2001-2022年 具体内容:一:最低工资数据标准时间:2012-2021包含指标: 省份城市/区县小时最低工资标准(非全日制)月最低工资标准实施日期 样例数据: 二:各省最低…...

计算机毕业设计选题推荐-戏曲文化体验系统-Java/Python项目实战
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

【深度学习】CosyVoice,论文
CosyVoice_v1.pdf 文章目录 CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens摘要1 引言2 CosyVoice: 使用监督语义标记的可扩展TTS模型2.1 用于语音的监督语义标记2.2 用于TTS的大型语言模型2.3 最优传输条件流…...
PHP8.3.9安装记录,Phpmyadmin访问提示缺少mysqli
ubuntu 22.0.4 腾讯云主机 下载好依赖 sudo apt update sudo apt install -y build-essential libxml2-dev libssl-dev libcurl4-openssl-dev pkg-config libbz2-dev libreadline-dev libicu-dev libsqlite3-dev libwebp-dev 下载php8.3.9安装包 nullhttps://www.php.net/d…...

[译] 深入浅出Rust基金会
本篇是对 RustConf 2023中的Rust Foundation: Demystified这一视频的翻译与整理, 过程中为符合中文惯用表达有适当删改, 版权归原作者所有. 大家好,我是Sage Griffin,我的代词是they/them。我今天来这里是要谈谈Rust基金会。 要了解基金会实际做什么,我们需要理解美国国内税收…...

Postman:API开发与测试的强大伴侣
在当今的数字化时代,API(应用程序编程接口)已成为不同软件系统之间通信的桥梁,它们如同数字世界的“翻译官”,使得数据和服务能够在不同的平台和应用程序之间无缝流动。然而,API的开发、测试和维护并非易事…...

Web应用的视界革命:WebKit支持屏幕方向API的深度解析
Web应用的视界革命:WebKit支持屏幕方向API的深度解析 在现代Web应用开发中,屏幕方向的适应性是一个重要的考虑因素。屏幕方向API(Screen Orientation API)提供了一种方法,允许Web应用知道并响应屏幕的方向变化&#x…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...