【Linux】缓冲区的理解
目录
- 一、实验现象
- 二、初步认知缓冲区
- 2.1 缓冲区的刷新策略
- 2.2 缓冲区在哪里
- 三、缓冲区模拟实现
- 四、再次全面理解缓冲区
- 4.1 用户强制刷新缓冲区(fflush/fsync)
一、实验现象
我们先来看一个现象:

在显示器中打印内容时,fprintf先打印出来,write后打印出来,这也是非常正常的现象,因为fprintf代码在write之前嘛,但是我们可以看到将1号下标重定向到log.txt,此时write函数的内容先进行打印了??这是什么原因??
下面我们再来看一个奇怪的现象:

上述实验中fprintf打印了两次,这必定与fork函数有关!!而向显示器中打印内容与向文件中打印内容fprintf与write打印的顺序不一致,fprintf函数是C库函数,而write是系统调用函数,我们初步猜想这必定与两者的内部实现有关系!!事实上这是由于两者的刷新策略不同而导致的,而刷新策略又跟缓冲区有联系,所以下面我们将一步引出缓冲区的概念对它进行着重分析。
二、初步认知缓冲区
实际上我们的数据并不是立马就被显示出来的,我们的C库以及操作系统都会提供一个缓冲区,数据先会被保存在这个缓冲区当中,然后结合一定的刷新策略数据才显示出来!!
缓冲区的本质其实就是充当一个内存暂存数据的地方!!
为什么要引入缓冲区这个概念?有什么意义?我们通过一个例子感性的理解一下:
假设你的朋友小库要生日了,你想在他生日当天送一个礼物给他,但是小库跟你不在同一个地方,小库在美国,而你在湖南。那么你将礼物交给他有两种方式,一种方式是你自己订机票飞往小库的地方将礼物交给他,另外一种方式是去快递点将礼物交给快递公司让它送给小库。那么你会选择哪种方式呢?我想大部分都应该会选择用快递的方式将礼物送给他吧。那么其实快递公司就充当了缓冲区的角色,快递公司会通过它的方式将礼物交给小库,不需要你亲自送给小库,这有什么好处呢?它节省了你的时间,你将礼物交给了快递公司,那么你就可以继续去干你自己的事情,剩下的事交给快递公司就可以了。那么在进程中假设我们调用了fprintf函数,它就会转而将数据拷贝到缓冲区中让缓冲区帮你实现功能,然后立马返回进程继续执行剩下的任务!!
所以为什么要有缓冲区呢?有什么意义?
提高了IO效率,节省了调用者的时间!!
2.1 缓冲区的刷新策略
引出缓冲区的概念之后,那么在缓冲区的数据是如何被使用的呢?这就需要采取一定的刷新策略了。
缓冲区的刷新策略
- 无缓冲:数据直接传送到目标设备,不经过缓冲区。这种方式的特点是数据传输速度快,但效率低下,容易产生垃圾数据。
- 行缓冲:数据存储在缓冲区中,当填满一行或遇到换行符时,就会将整行数据一起刷新到目标设备中。行缓冲的特点是占用空间小,效率较高,但无法立即显示输出(当未填满一行或未遇到换行符时会一直存留在缓冲区中,无法立即输出到目标设备中)。显示器采用的刷新策略。
- 全缓冲:数据存储在缓冲区中,缓冲区填满后,将整个缓冲区一次性刷新到目标设备中。全缓冲的特点是效率高,但需要占用大量的存储空间。普通文件采用的刷新策略。
- 特殊情况:
1、进程退出时需要刷新缓冲区:在进程退出时,操作系统会自动关闭该进程的所有文件,并刷新缓冲区,确保数据正确保存。
2、关闭文件(close)时需要刷新缓冲区:在关闭文件时,操作系统会自动刷新该文件的缓冲区,确保数据正确保存。
3、用户强制刷新缓冲区:有些操作系统提供了命令或函数可以手动刷新缓冲区,例如Unix/Linux中的sync命令或fsync函数,Windows中的FlushFileBuffers函数等。
上述我说的是基于用户层的缓冲区刷新策略,实际上操作系统的缓冲区刷新策略更为复杂,采用定时刷新、事件触发刷新、混合策略刷新等等,但是大致的思想肯定是一样的,下面我们重点讲解用户层缓冲区的刷新策略就可以了。
行缓冲是现阶段语言层面我们用的最多的一种刷新策略,通过找到\n将缓冲区中的数据刷新出来,这也就是我们通常在printf中带\n数据能立马将缓冲区中的数据刷新出来最终在显示器上看到的原因。有了这个概念,我们就能对printf带\n有了更进一步的了解了,实际上\n不仅仅是为了调整格式,而且能使我们保存在缓冲区的数据刷新出来,最终显示在显示器上!!
为什么显示器通常采用的是行缓冲?
这是为了用户有更好的体验,我们通常希望看到一次一次的现象,而不是把缓冲区填满之后再一次性的刷新缓冲区最终在显示器上只看到一次现象。
对于缓冲区的设计者来说,为了极大的提高IO效率,通常采用的是类似全缓冲的刷新策略,因为需要刷新的数据量非常大,数据将缓冲区填满之后再进行刷新。这样为什么能提高IO效率?
对于显示器文件来说,我们使用的是行缓冲,找到\n就刷新缓冲区,刷新缓冲区的本质就是进行写入,最终将数据写入到显示器文件中,而数据写入外设必定要遵循冯诺依曼体系,换句话说每刷新一次就进行一次IO;而对于全缓冲来说,我们将缓冲区填满之后才刷新一次,不发生刷新的本质,不进行写入,就是不进行IO,不进行调用系统调用,所以fwrite函数调用会非常快,数据会暂时保存在缓冲区中,可以在缓冲区中积压多份数据,最后再统一进行刷新写入,换句话说就是就是一次IO可以IO更多的数据。IO是需要花费时间的,我们通过全缓冲减少了IO的次数,不就是节省了时间,提高了效率吗!!
注:进行IO必定需要访问外设,调用库函数将数据拷贝到缓冲区都不IO,叫拷贝数据!!
2.2 缓冲区在哪里
在之前的实验现象中,我们看到1号下标重定向到log.txt文件后调用write与fprintf,此时在普通文件中打印内容采用的是全缓冲策略,那么fprintf比write先进行调用,但是write比fprintf先进行打印,write是系统调用接口,而fprintf是C库函数。由此说明缓冲区一定不在内核层,所以此时的缓冲区一定是在用户层,它是C库提供的,更具体的来说它在FILE结构体中!!
接下来我们回答一下之前出现的奇怪现象:
用户先调用fprintf函数,实际fprintf会调用fwrite函数将数据先写入缓冲区中,fwrite在这里就充当一个拷贝函数。发生重定向之后我们采用的全缓冲刷新策略,此时"hello fprintf"暂存在缓冲区中,而write它是系统调用接口它的数据根本不放在用户级缓冲区中,而是放在内核层缓冲区中,然后结合操作系统的刷新策略将数据写入到显示器文件,所以它会较fprintf先打印出来。在最后我们使用fork创建子进程,在进程退出前要刷新缓冲区,此时谁先刷新缓冲区就要发生写时拷贝,所以最终我们可以看到两份fprintf打印的内容!!
关于缓冲区的理解到现在还是不够的,我们后续讲完缓冲区的模拟实现之后还会再次进行谈论,到时候我们就能彻底明白缓冲区以及它的刷新策略了。
三、缓冲区模拟实现
下面是我们进行缓冲区的简单模拟实现代码:
mystdio.h
#pragma once#include <stdio.h>#define NUM 1024
#define BUFF_NONE 0x1
#define BUFF_LINE 0x2
#define BUFF_ALL 0x4typedef struct _MY_FILE
{int fd; // 文件描述符int flags; // flush method, 刷新策略char outputbuffer[NUM]; // 缓冲区int current; // 当前指向缓冲区字符的位置
} MY_FILE;MY_FILE *my_fopen(const char *path, const char *mode); // fopen函数
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb,MY_FILE *stream); // fwrite函数
int my_fclose(MY_FILE *fp); // fclose函数
int my_fflush(MY_FILE *fp); // fflush函数
mystdio.c
#include "mystdio.h"
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <malloc.h>
#include <unistd.h>
#include <assert.h>MY_FILE *my_fopen(const char *path, const char *mode)
{//1. 识别标志位int flag = 0;if(strcmp(mode, "r") == 0) flag |= O_RDONLY;else if(strcmp(mode, "w") == 0) flag |= (O_CREAT | O_WRONLY | O_TRUNC);else if(strcmp(mode, "a") == 0) flag |= (O_CREAT | O_WRONLY | O_APPEND);else {//other operator...//"r+", "w+", "a+"}//2. 尝试打开文件mode_t m = 0666; // 文件权限int fd = 0;// 如果文件需要不存在需要创建,此时我们就需要设置文件权限if(flag & O_CREAT) fd = open(path, flag, m);else fd = open(path, flag);if(fd < 0) return NULL;//3. 给用户返回MY_FILE对象,需要先进行构建MY_FILE *mf = (MY_FILE*)malloc(sizeof(MY_FILE));// 如果创建结构体失败就关闭文件if(mf == NULL) {close(fd);return NULL;}//4. 初始化MY_FILE对象mf->fd = fd;mf->flags = 0;mf->flags |= BUFF_LINE; // 默认为行缓冲刷新策略memset(mf->outputbuffer, '\0',sizeof(mf->outputbuffer)); // 初始化缓冲区//mf->outputbuffer[0] = 0; //初始化缓冲区mf->current = 0; // 当前指向缓冲区字符的位置//5. 返回打开的文件return mf;
}void my_fflush(MY_FILE *fp)
{assert(fp);//刷新的本质是将用户缓冲区中的数据,通过系统调用接口,冲刷给OSwrite(fp->fd, fp->outputbuffer, fp->current);fp->current = 0; // 刷新缓冲区之后将指向缓冲区字符的置为0 -- 起始位置fsync(fp->fd); // 用户强制将缓冲区的数据刷新到外设中
}size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{// 1. 缓冲区如果已经满了,就先刷新缓冲区if(stream->current == NUM) my_fflush(stream);// 2. 根据缓冲区剩余情况,进行数据拷贝即可size_t user_size = size * nmemb; // 用户需要传入的字节大小size_t my_size = NUM - stream->current; // 缓冲区剩余字节大小size_t writen = 0;// 如果缓冲区剩余字节大小大于等于用户传入的字节大小,此时将数据拷贝至current之后;反之则最多拷贝my_size字节到current后if(my_size >= user_size){memcpy(stream->outputbuffer+stream->current, ptr, user_size);//3. 更新当前位置stream->current += user_size;writen = user_size;}else{memcpy(stream->outputbuffer+stream->current, ptr, my_size);stream->current += my_size;writen = my_size;}// 4. 开始计划刷新// 全缓冲if(stream->flags & BUFF_ALL){if(stream->current == NUM) my_fflush(stream);}// 行缓冲else if(stream->flags & BUFF_LINE){if(stream->outputbuffer[stream->current-1] == '\n') my_fflush(stream);}// 无缓冲else{//...}return writen;
}void my_fclose(MY_FILE *fp)
{assert(fp);//1. 冲刷缓冲区if(fp->current > 0) my_fflush(fp);//2. 关闭文件close(fp->fd);//3. 释放堆空间free(fp);fp = NULL;
}main.c
// main.c读者可以自行去进行测试
#include "mystdio.h"
#include <string.h>
#include <unistd.h>#define MYFILE "log.txt"int main()
{MY_FILE *fp = my_fopen(MYFILE, "w");if(fp == NULL) return 1;const char *str = "hello my fwrite";int cnt = 500;//操作文件while(cnt){char buffer[1024];snprintf(buffer, sizeof(buffer), "%s:%d", str, cnt--);//snprintf(buffer, sizeof(buffer), "%s:%d\n", str, cnt--);size_t size = my_fwrite(buffer, strlen(buffer), 1, fp);sleep(1);printf("当前成功写入: %lu个字节\n", size);//my_fflush(fp);}my_fclose(fp);return 0;
}
我们先来看看行缓冲区的现象:
当snprintf带\n时,我们发现数据一次一次的回显在log.txt文件中:

当snprintf不带\n时,此时默认还是行缓冲刷新,当行缓冲区未满一行或找不到\n时,此时数据在缓冲区中一直积压,直到此时进程结束该缓冲区刷新,此时一下在文件中一次就看到了缓冲区的所有数据:

如果我们一次一次的回显到文件中,我们可以通过我们自己实现的my_fflush强制刷新缓冲区:

四、再次全面理解缓冲区
有了上述缓冲区的模拟实现,我们对缓冲区的刷新策略有了更近一步的了解。
接下来我们谈谈用户进行IO的整个流程:
这里以用户使用C语言调用printf打印数据到显示器上为例,在用户层printf会先调用fwrite函数将数据拷贝到用户层缓冲区当中,然后结合一定的刷新策略->通过系统调用(write)将数据拷贝到内核层缓冲区当中,随后操作系统也同样的采取一定的刷新策略将数据最终写入磁盘,所以最终我们就能在显示器文件中看到我们打印的数据了。
我们平时在语言级别中提到的缓冲区其实都是用户层缓冲区,因为内核级缓冲区我们也见不到。

4.1 用户强制刷新缓冲区(fflush/fsync)
下面我想重点讲讲fflush库函数与fsync系统调用接口:
fflush()函数
fflush()函数是用来刷新标准I/O库的缓冲区的,其中包括用户层的缓冲区。当我们使用C语言中的输出函数(如printf())向文件中写入数据时,这些数据首先被写入用户层的缓冲区中,而不是直接写入磁盘中。只有在缓冲区已满、文件关闭或调用fflush()函数时,才会将缓冲区的数据刷新到内核缓冲区中。那么如果此时我的刷新策略不符合第一二点,此时就使用fflush()函数将数据强制刷新到内核缓冲区中。刷新缓冲区的本质是什么?将用户缓冲区的数据通过系统调用(write)冲刷给操作系统,那么实际上fflush函数强制刷新缓冲区在底层就是通过调用系统调用(write)来完成这项工作的!!
结论:fflush()函数并不会直接将数据写入磁盘,而是将数据写入内核缓冲区中,由操作系统决定何时将数据写入磁盘。
fsync函数

fsync()函数会强制将一个文件的所有缓冲区数据和元数据(如文件大小、修改时间等)都写入磁盘中,包括文件的用户层缓冲区和内核缓冲区。当fsync()函数返回时,表示数据已经写入磁盘并且已经被持久化保存。这个函数在需要确保数据被持久化保存的场景中非常有用,比如在操作系统崩溃或断电时,而内存具有断点易失的性质,一旦断电文件中所有的数据就丢失了。但是,由于磁盘I/O的性能非常低,所以fsync()函数的执行速度也较慢,尤其是在写入大量数据时。因此,如果需要频繁调用fsync()函数来写入小量的数据,可能会对性能造成一定的影响。一个很常见的例子:我们在CSDN写博客时,我们边写它会边自动保存,实际它就是调用了fsync函数使我们的数据被持久化保存,防止我们突然断网断电导致数据丢失的问题,而且我们也知道有时候这种自动保存的方式是有点卡顿的,这是很常见的问题!!
值得注意的是,对于某些文件系统(如ext3、ext4等),即使使用fsync()函数,操作系统仍然可能会将数据先写入到内存中,然后再在后台将数据写入磁盘中。这种行为被称为延迟写(delayed write)或异步写(asynchronous write),可以提高磁盘I/O的性能。因此,在使用fsync()函数时,不能保证数据一定已经写入磁盘中,只能保证已经被提交到操作系统,并由操作系统尽快写入磁盘。
结论:fsync()函数用于确保数据被持久化保存。
本篇文章的内容就讲到这里了,关于本文如果有任何疑问或者错处欢迎大家评论区相互交流orz~🙈🙈
相关文章:
【Linux】缓冲区的理解
目录 一、实验现象二、初步认知缓冲区2.1 缓冲区的刷新策略2.2 缓冲区在哪里 三、缓冲区模拟实现四、再次全面理解缓冲区4.1 用户强制刷新缓冲区(fflush/fsync) 一、实验现象 我们先来看一个现象: 在显示器中打印内容时,fprintf先打印出来,w…...

基于单片机的电梯控制系统的设计
摘 要: 本文提出了一种基于单片机的电梯控制系统设计 。 设计以单片机为核心,通过使用和设计新型先进的硬件和控制程序来模拟和控制整个电梯的运行,在使用过程中具有成本低廉、 维护方便、 运行稳定 、 易于操作 、 安全系数高等优点 。 主要设计思路是…...

IP-GUARD文档云备份服务器迁移数据操作说明
一、功能简介 使用文档云备份过程可能出现需要迁移旧数据到新目录的情况(如一开始存储目录设置 不合理,之后变更存储目录),下面介绍迁移备份数据到新目录的方法,迁移后可正常查看、 下载、删除原备份文件。 二、同一计算机上迁移存储目录 当仅需要将存储目录迁移到同一计…...

linux常用命令ls详细说明
目录 1.ls的基本功能就是显示当前目录的文件和目录 2.ls输出是按照字母顺序排列的 3.默认不显示隐藏内容,加上参数-a可以显示隐藏的文件和文件夹 4.-R参数可以地柜列出当前目录以及它包含的字目录中的文件 5.-l参数辉显示长列表,也可以显示文件更多信…...
数据的存储)
Python3网络爬虫开发实战(4)数据的存储
文章目录 一、文本文件存储1. os 文件 mode2. TXT3. JSON4. CSV 二、数据库存储1. SQLAlchemy2. MongoDB3. Redis1) 键操作2) 字符串操作3) 列表操作4) 集合操作5) 有序集合操作6) 散列操作 4. Elasticsearch1) 检索数据:利用 elasticsearch-analysis-ik 进行分词2)…...

《C++基础入门与实战进阶》专栏介绍
🚀 前言 本文是《C基础入门与实战进阶》专栏的说明贴(点击链接,跳转到专栏主页,欢迎订阅,持续更新…)。 专栏介绍:以多年的开发实战为基础,总结并讲解一些的C/C基础与项目实战进阶内…...
- 数据清洗)
每天一个数据分析题(四百五十)- 数据清洗
数据在真正被使用前需进行必要的清洗,使脏数据变为可用数据。下列不属于“脏数据”的是() A. 重复数据 B. 错误数据 C. 交叉数据 D. 缺失数据 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据…...

昇思25天学习打卡营第XX天|Pix2Pix实现图像转换
Pix2Pix是一种基于条件生成对抗网络(cGAN)的图像转换模型,由Isola等人在2017年提出。它能够实现多种图像到图像的转换任务,如从草图到彩色图像、从白天到夜晚的场景变换等。与传统专用机器学习方法不同,Pix2Pix提供了一…...

数据结构经典测试题5
1. int main() { char arr[2][4]; strcpy (arr[0],"you"); strcpy (arr[1],"me"); arr[0][3]&; printf("%s \n",arr); return 0; }上述代码输出结果是什么呢? A: you&me B: you C: me D: err 答案为A 因为arr是一个2行4列…...

React Native初次使用遇到的问题
Write By Monkeyfly 以下内容均为原创,如需转载请注明出处。 前提:距离上次写博文已经过去了5年之久,诸多原因导致的,写一篇优质博文确实费时费力,中间有其他更感兴趣的事要做(打游戏、旅游、逛街、看电影…...

2024西安铁一中集训DAY28 ---- 模拟赛(简单dp + 堆,模拟 + 点分治 + 神秘dp)
文章目录 前言时间安排及成绩题解A. 江桥不会做的签到题(简单dp)B. 江桥树上逃(堆,模拟)C. 括号平衡路径(点分治)D. 回到起始顺序(dp,组合数学) 前言 T2好难…...

【论文阅读笔记 + 思考 + 总结】MoMask: Generative Masked Modeling of 3D Human Motions
创新点: VQ-VAE 👉 Residual VQ-VAE,对每个 motion sequence 输出一组 base motion tokens 和 v 组 residual motion tokensbidirectional 的 Masked transformer 用来生成 base motion tokensResidual Transformer 对 residual motion toke…...

Mojo控制语句详解
Mojo 包含几个传统的控制流结构,用于有条件和重复执行代码块。 The if statement Mojo 支持条件代码执行语句。有了它,当给定的布尔表达式计算结果为 时,if您可以有条件地执行缩进的代码块 。True temp_celsius = 25 if temp_celsius > 20:print("It is warm.&quo…...

web安全基础学习
http基础 HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式和超媒体信息系统的应用层协议。本文将介绍如何使用HTTP协议,以及在Linux操作系统中如何使用curl工具发起HTTP请求。 一、HTTP特性 无状态…...

天气预报的爬虫内容打印并存储用户操作
系统名称: 基于网络爬虫技术的天气数据查询系统文档作者:清馨创作时间:2024-7-29最新修改时间:2024-7-29最新版本号: 1.0 1.背景描述 该系统将基于目前比较流行的网络爬虫技术,对网站上(NowAPI…...
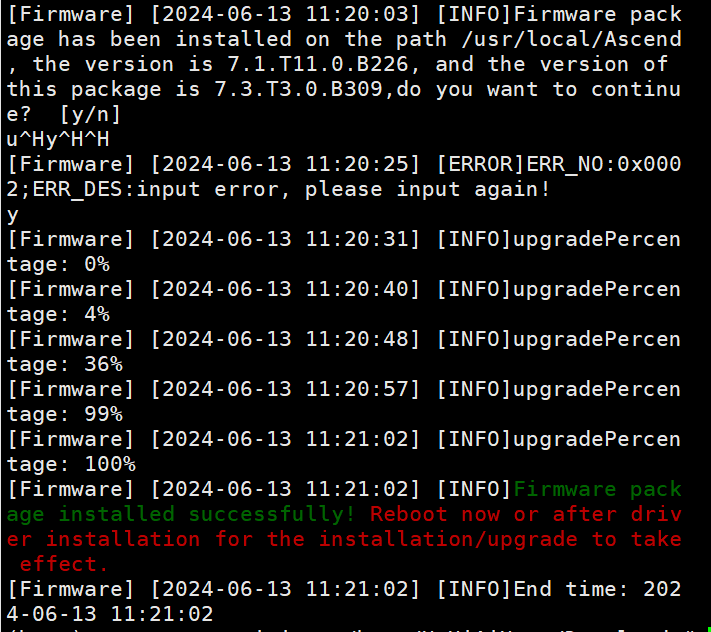
OrangePi AI Pro 固件升级 —— 让主频从 1.0 GHz 到 1.6 GHz 的巨大升级
前言 OrangePi AI Pro 最近发布了Ascend310B-firmware 固件包,据说升级之后可以将 CPU 主频从 1.0 GHz 提升至 1.6 GHz,据群主大大说,算力也从原本的 8T 提升到了 12T,这波开发板的成长让我非常的 Amazing 啊!下面就来…...

学习大数据DAY27 Linux最终阶段测试
满分:100 得分:72 目录 一选择题(每题 3 分,共计 30 分) 二、编程题(共 70…...

ctr管理containerd基本命令
1. 创建命名空间 创建名为custom的命令空间 ctr ns create custom2. 导入镜像 把镜像导入到刚刚创建的空间 ctr -n custom images improt restfulapi.tar3. 创建容器 创建一个test_api的容器 ctr -n custom run --null-io --net-host -d --mount typebind,src/etc,dst/ho…...
)
rust 初探 -- 路径(path)
rust 初探 – 路径Path 路径(Path) 目的:为了在 Rust 的模块中找到某个条目,需要使用 路径两种形式: 绝对路径:从 crate root 开始,使用 crate 名或字面值 crate相对路径:从当前模…...
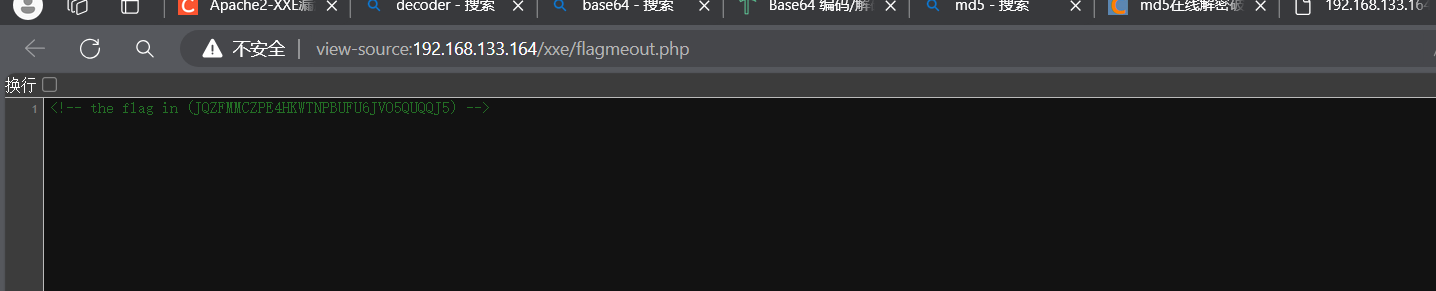
XXE -靶机
XXE靶机 一.扫描端口 进入xxe靶机 1.1然后进入到kali里 使用namp 扫描一下靶机开放端口等信息 1.2扫描他的目录 二 利用获取的信息 进入到 robots.txt 按他给出的信息 去访问xss 是一个登陆界面 admin.php 也是一个登陆界面 我们访问xss登陆界面 随便输 打开burpsuite抓包 发…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...
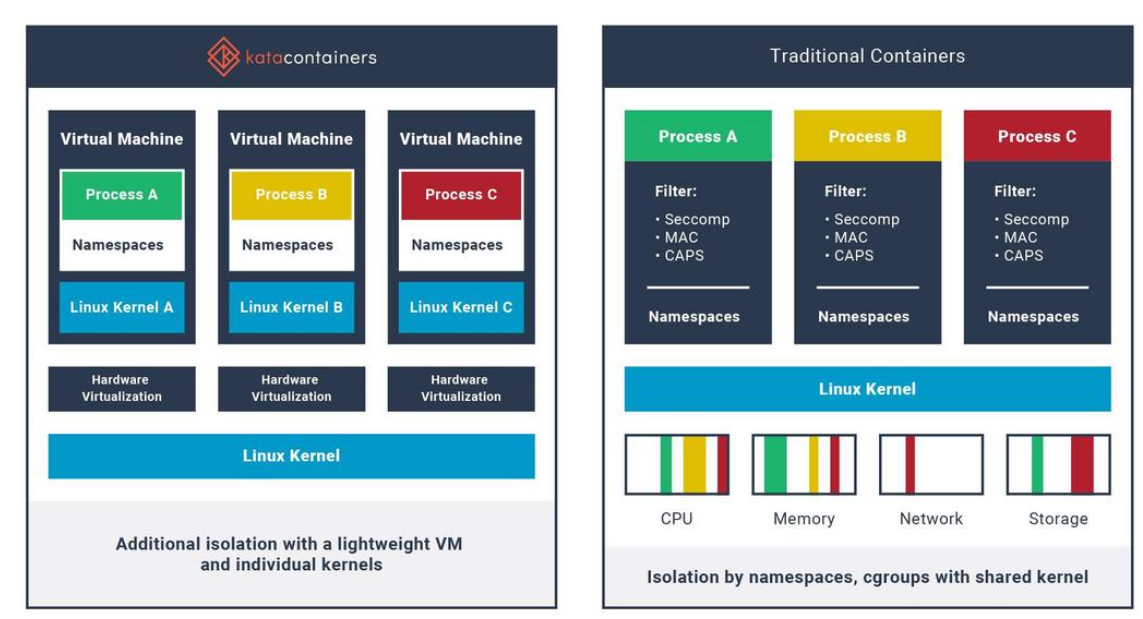
沙箱虚拟化技术虚拟机容器之间的关系详解
问题 沙箱、虚拟化、容器三者分开一一介绍的话我知道他们各自都是什么东西,但是如果把三者放在一起,它们之间到底什么关系?又有什么联系呢?我不是很明白!!! 就比如说: 沙箱&#…...
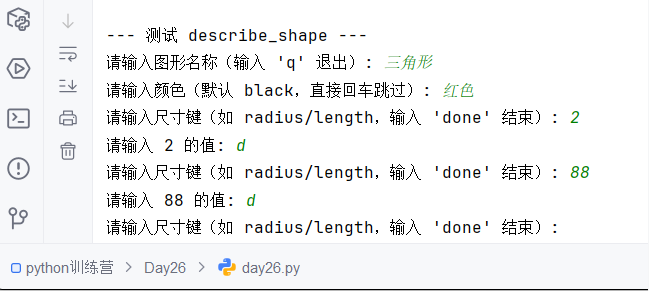
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...