释放自动化测试潜能:性能优化策略与实战技巧!
引言
在当今追求软件快速迭代的环境下,自动化测试的性能瓶颈正成为制约开发流程加速的主要障碍。本文将深入探讨如何通过策略和实践,优化自动化测试的性能,实现测试执行速度的质的飞跃。
自动化性能瓶颈的识别与突破
首先,识别并定位自动化测试过程中的性能瓶颈至关重要,这些瓶颈可能包括脚本执行的延迟、资源的激烈竞争,以及数据库交互的低效等。
核心优化策略
-
数据库连接优化:采用数据库连接池技术,我们显著降低了每次查询所需的准备时间,进而加速了自动化测试的整体执行流程。
-
测试数据动态准备:通过优化测试数据的生成和加载流程,减少了测试用例执行前的等待时间。
-
测试框架效率提升:精简测试初始化流程,及时清理测试数据,合理调度测试任务,提高了资源利用率。
-
UI 自动化性能提升:预加载设备环境,优化元素定位策略,减少查找时间。
实战技巧与代码示例
以下是针对测试用例执行速度和测试框架执行效率优化的代码示例和优化前后的对比。
测试用例执行速度优化
数据库连接优化(使用连接池)
优化前:
import pymysqldef get_db_connection():return pymysql.connect(host='localhost', user='user', password='password', db='testdb')def execute_query(query):connection = get_db_connection()try:with connection.cursor() as cursor:cursor.execute(query)return cursor.fetchall()finally:connection.close()
优化后:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 使用连接池
engine = create_engine('mysql+pymysql://user:password@localhost/testdb', pool_size=10, max_overflow=20)Session = sessionmaker(bind=engine)def execute_query(query):session = Session()try:result = session.execute(query)return result.fetchall()finally:session.close()
测试数据动态准备优化
优化前:
def prepare_test_data():# 模拟数据准备过程,可能包括文件读写、网络请求等data = load_data_from_file('data.txt')return datadef run_test_case(data):# 测试用例逻辑print(data)
优化后:
import pandas as pddef prepare_test_data():# 使用pandas快速读取数据data = pd.read_csv('data.csv')return datadef run_test_case(data):# 测试用例逻辑,使用优化后的数据print(data.values)
测试框架执行效率提升
测试初始化优化
优化前:
def setup_environment():# 模拟环境设置过程print("Setting up environment...")# 执行一些初始化操作# ...def run_test():setup_environment()# 执行测试逻辑# ...
优化后:
def setup_environment():# 精简环境设置过程print("Environment setup optimized...")def run_test():setup_environment()# 执行测试逻辑,确保只加载必要的资源# ...
测试数据清理优化
优化前:
def cleanup_data():# 模拟数据清理过程print("Cleaning up data...")# 执行数据清理操作# ...def run_test():try:# 执行测试逻辑# ...finally:cleanup_data()
优化后:
def cleanup_data():# 自动化测试后立即清理数据print("Data cleaned up immediately...")def run_test():try:# 执行测试逻辑# ...except Exception as e:print(f"An error occurred: {e}")finally:cleanup_data()
这些代码示例展示了如何通过使用数据库连接池、优化数据准备过程、精简环境设置和立即清理数据等方法来提升自动化测试的性能。
实际案例分析
假设有一个自动化测试场景,需要频繁地查询数据库以验证数据的一致性。在优化前,每次查询都需要建立新的数据库连接,这导致测试执行时间较长。优化后,使用连接池显著减少了连接建立的时间,提高了测试的执行效率。
案例数据:
-
优化前平均查询时间:500ms
-
优化后平均查询时间:100ms
分析:通过使用连接池,每次查询的准备时间大幅减少,从而加快了整个自动化测试的执行速度。在实际的生产环境中,这种优化可以显著提高测试的响应速度和整体的软件交付速度。
-
根据
TechBeacon的报告,优化数据库连接管理可以减少高达 30%的自动化测试执行时间。 -
DZone的一篇文章指出,通过优化测试数据的准备和清理过程,可以提高自动化测试的吞吐量多达 50%。
优化前(传统的数据库连接方式)
import pymysqldef get_db_connection():return pymysql.connect(host='localhost', user='user', password='password', db='testdb', charset='utf8mb4')def execute_query(query):connection = get_db_connection()try:with connection.cursor() as cursor:cursor.execute(query)return cursor.fetchall()finally:connection.close()# 使用示例
if __name__ == "__main__":query = "SELECT * FROM test_table"results = execute_query(query)print(results)
优化后(使用SQLAlchemy的连接池)
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.exc import SQLAlchemyError# 创建引擎时指定连接池参数
engine = create_engine('mysql+pymysql://user:password@localhost/testdb', echo=True, pool_size=5, max_overflow=10)Session = sessionmaker(bind=engine)def execute_query(query):session = Session()try:result = session.execute(query)return result.fetchall()except SQLAlchemyError as e:print(f"An error occurred: {e}")finally:session.close()# 使用示例
if __name__ == "__main__":query = "SELECT * FROM test_table"results = execute_query(query)print(results)
在优化后的代码中,我们使用了SQLAlchemy库来管理数据库连接,它提供了连接池功能,可以显著提高数据库操作的效率。echo=True参数用于输出 SQLAlchemy 的日志信息,有助于调试。pool_size和max_overflow参数用于定义连接池的大小和溢出策略。
五、结论
通过精心实施上述优化策略,我们不仅能有效攻克自动化测试的性能难题,还能实现测试执行速率的显著提升,从而引领测试流程迈向一个新的高度。
"您在自动化性能优化方面有哪些经验或技巧?欢迎在评论区分享您的故事。"
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

相关文章:
释放自动化测试潜能:性能优化策略与实战技巧!
引言 在当今追求软件快速迭代的环境下,自动化测试的性能瓶颈正成为制约开发流程加速的主要障碍。本文将深入探讨如何通过策略和实践,优化自动化测试的性能,实现测试执行速度的质的飞跃。 自动化性能瓶颈的识别与突破 首先,识别并…...

如何理解代码的跨平台?
跨平台性: 跨平台性意味着,在多个平台都兼容运行 那么是怎么做到跨平台? 一般来说,window的操作系统和Linux的操作系统肯定是不一样的 那么提供的系统调用接口和诸多细节也是不一样的 但是,我们的c语言和c语言…...

dp:221. 最大正方形
221. 最大正方形 看到这个题目真能立马想到dp吗?貌似很难,即使知道是一个dp题也很难想到解法。 直观来看,使用bfs以一个点为中点进行遍历,需要的时间复杂度为 O ( n 2 m 2 ) O(n^2m^2) O(n2m2) 但是可以很容易发现,…...

花10分钟写个漂亮的后端API接口模板!
你好,我是田哥 在这微服务架构盛行的黄金时段,加上越来越多的前后端分离,导致后端API接口规范变得越来越重要了。 比如:统一返回参数形式、统一返回码、统一异常处理、集成swagger等。 目的主要是规范后端项目代码,以及…...
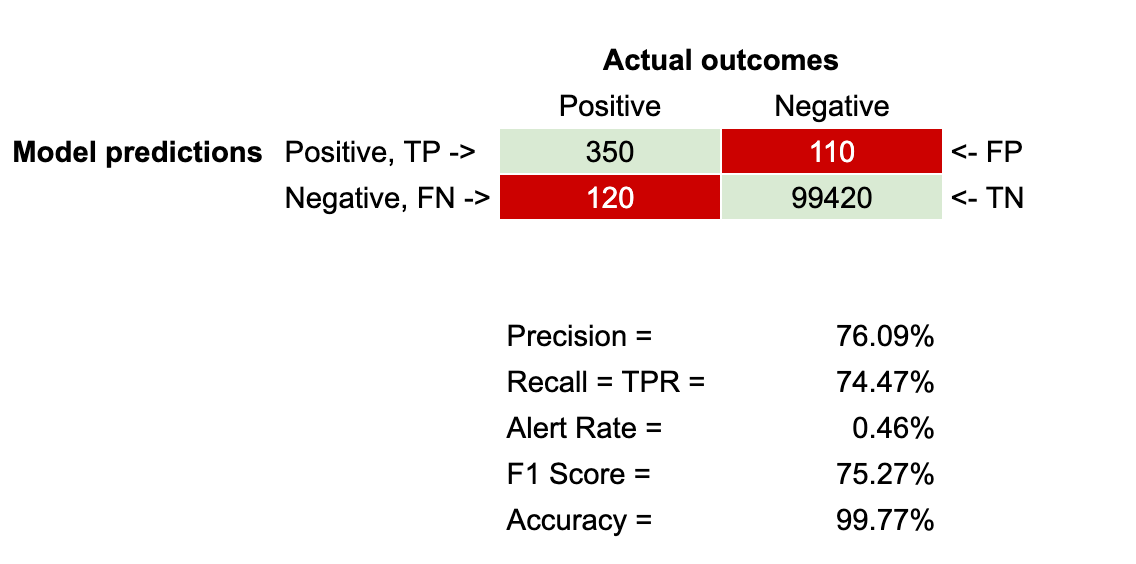
评估分类机器学习模型的指标
欢迎来到雲闪世界。一旦我们训练了一个监督机器学习模型来解决分类问题,如果这就是我们工作的结束,我们会很高兴,我们可以直接向他们输入新数据。我们希望它能正确地对所有内容进行分类。然而,实际上,模型做出的预测并…...

农机自动化:现代农业的未来趋势
随着人口的增长和农业生产的需求不断增加,提高农业生产效率成为现代农业的重要目标。农机自动化作为一种新兴技术,可以大幅度提升农机的使用效率和生产能力。农机自动化是指利用先进的传感技术、数据处理和人工智能技术,使农机能够自动完成农…...

25考研操作系统复习·1.1/1.2/1.3 操作系统的基本概念/发展历程/运行环境
目录 操作系统的基本概念 概念(定义) 功能和目标 资源的管理者 向上层提供服务 给普通用户的 给软件/程序员的 对硬件机器的拓展 操作系统的特征 操作系统的发展历程 操作系统的运行环境 操作系统的运行机制 中断和异常 中断的作用 中断的…...

如何培养学生的创新意识和实践能力
培养学生的创新意识和实践能力是一个复杂而系统的过程,涉及多个方面的努力和措施。以下是一些具体的做法: 一、培养学生的创新意识 提供创新环境: 为学生创造一个开放、自由、支持创新的学习环境,让他们能够自由地表达自己的想法…...
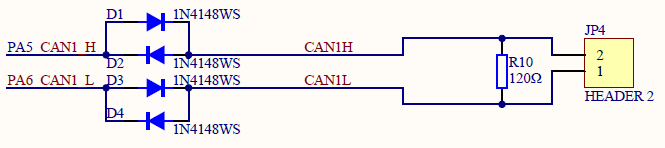
四、GD32 MCU 常见外设介绍(15)CAN 模块介绍
CAN是控制器局域网络(Controller Area Network)的简称,它是由研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO11519),是国际上应用最广泛的现场总线之一。 CAN总线协议已经成为汽车计算机控…...

AIGC大模型产品经理高频面试大揭秘‼️
近期有十几个学生在面试大模型产品经理(薪资还可以,详情见下图),根据他们面试(包括1-4面)中出现高频大于3次的问题汇总如下,一共32道题目(有答案)。 29.讲讲T5和Bart的区…...

【嵌入式笔记】【C语言】struct union
结构体(Struct)定义: struct 结构体名 {member1; // 成员1,可以是任何基本数据类型或复合类型member2; // 成员2... };//例如: struct Point {float x;float y;...
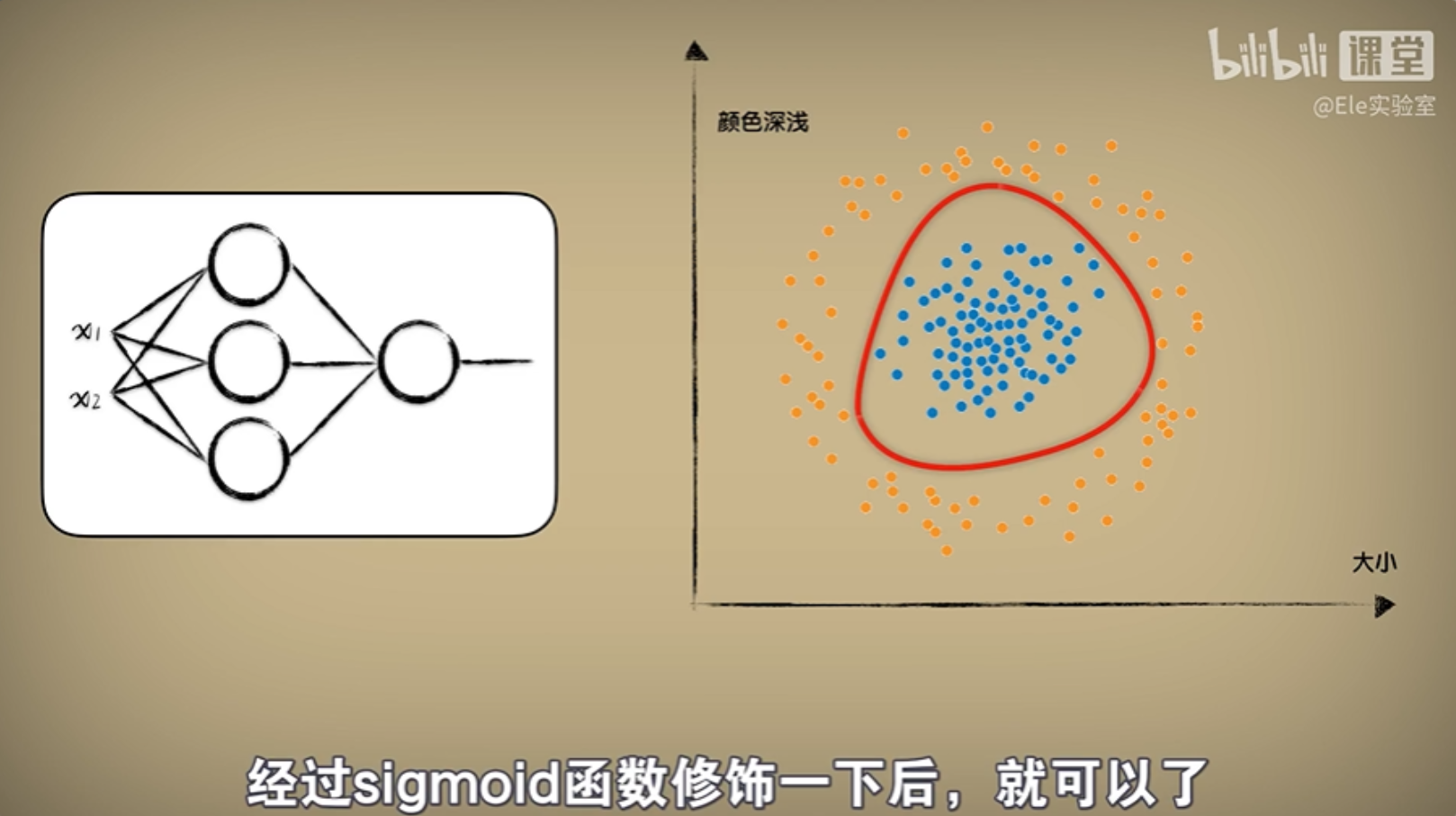
【初学人工智能原理】【9】深度学习:神奇的DeepLearning
前言 本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。 代码及工具箱 本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码 正文 深度…...

[RoarCTF 2019]Easy Calc1
打开题目 查看源码,看到 看到源代码有 calc.php,构造url打开 看到php审计代码, 由于页面中无法上传num,则输入 num,在num前加入一个空格可以让num变得可以上传,而且在进行代码解析时,php会把前…...
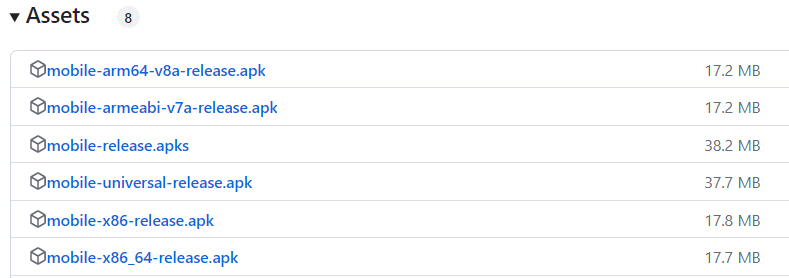
安卓APK安装包arm64-v8a、armeabi-v7a、x86、x86_64有何区别?如何选择?
在GitHub网站下载Android 安装包,Actions资源下的APK文件通常有以下版本供选择: 例如上图是某Android客户端的安装包文件,有以下几个版本可以选择: mobile-release.apk(通用版本,体积最大)mobi…...

【AI大模型】通义千问:开启语言模型新篇章与Function Call技术的应用探索
文章目录 前言一、大语言模型1.大模型介绍2.大模型的发展历程3.大模型的分类a.按内容分类b.按应用分类 二、通义千问1.通义千问模型介绍a.通义千问模型介绍b.应用场景c.模型概览 2.对话a.对话的两种方式通义千问API的使用 b.单轮对话Vue页面代码:Django接口代码 c.多…...

详细教程 MySQL 数据库 下载 安装 连接 环境配置 全面
数据库就是储存和管理数据的仓库,对数据进行增删改查操作,其本质是一个软件。 首先数据有两种,一种是关系型数据库,另一种是非关系型数据库。 关系型数据库是以表的形式来存储数据,表和表之间可以有很多复杂的关系&a…...

门控循环单元GRU
目录 一、GRU提出的背景:1.RNN存在的问题:2.GRU的思想: 二、更新门和重置门:三、GRU网络架构:1.更新门和重置门如何发挥作用:1.1候选隐藏状态H~t:1.2隐藏状态Ht: 2.GRU: 四、底层源码…...

程序员修炼之路
成为一名优秀的程序员,需要广泛而深入地学习多个领域的知识。这些课程不仅帮助建立扎实的编程基础,还培养了问题解决、算法设计、系统思维等多方面的能力。以下是一些核心的必修课: 计算机基础 计算机组成原理:理解计算机的硬件组…...

PHP时间相关函数
时间、日期 time()获取当前时间戳(10位)microtime(true)返回一个浮点时间戳data(格式,时间戳)日期格式化 $time time(); echo date(Y-m-d H:i:s, $time);strtotime&am…...

python进阶——python面向对象
前言 Python是一种面向对象的编程语言,可在Python中使用类和对象来组织和封装代码。面向对象编程(OOP)是一种编程范例,它将数据和操作数据的方法封装在一个对象内部,通过对象之间的交互来实现程序的功能。 1、面向对象…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...