DiffusionModel-latent diffusion,VAE,U-Net,Text-encoder
Diffusers
StableDdiffusion
参考: Stable Diffusion原理详解(附代码实现)

Latent Diffusion
自编码器(Variational Autoencoder, VAE):
- 自编码器是一种无监督学习的神经网络,用于学习数据的有效表示或编码。
- 在稳定扩散模型中,VAE用于将高维的图像数据编码到一个低维的潜在空间中,这个空间的维度远小于原始图像空间。
- VAE由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入图像压缩成一个潜在空间的向量,解码器则将这个向量重构回图像空间。
- 在潜在扩散训练过程中,编码器用于获取图像的潜在表示(latent),用于向前扩散过程中逐步增加噪音。在推断过程中,通过反向扩散过程生成的去噪潜在表示将使用VAE解码器转换回图像。在推断过程中,我们只需要VAE解码器。

U-Net:
https://blog.csdn.net/hwjokcq/article/details/140413174
https://blog.csdn.net/Rocky6688/article/details/132390798
https://blog.csdn.net/xd_wjc/article/details/134441396
- U-Net具有对称的U形结构,包括一个收缩(编码)路径和一个对称的扩展(解码)路径。两者都由ResNet块组成。编码器将图像表示压缩为低分辨率图像表示,解码器将低分辨率图像表示解码回原始更高分辨率图像表示
- 为防止U-Net在降采样过程中丢失重要信息,通常在编码器的降采样ResNet和解码器的升采样ResNet之间添加快捷连接(short-cut connections)。
- 稳定扩散U-Net能够通过交叉注意力层将输出条件化为文本嵌入。交叉注意力层通常添加在U-Net的编码器和解码器部分之间,通常在ResNet块之间。
- U-Net主要在“扩散”循环中对高斯噪声矩阵进行迭代降噪,并且每次预测的噪声都由文本和timesteps进行引导,将预测的噪声在随机高斯噪声矩阵上去除,最终将随机高斯噪声矩阵转换成图片的隐特征。


Stable Diffusion中的U-Net,在Encoder-Decoder结构的基础上,增加了Time Embedding模块,Spatial Transformer(Cross Attention)模块和self-attention模块。
- Time Embeddings模块 + Encoder模块中原本的卷积层,组成了一个Residual Block结构。它包含两个卷积层,一个Time Embedding和一个skip Connection。而这里的全连接层将Time Embedding变换为和Latent Feature一样的维度。最后通过两者的加和完成time的编码。

- Spatial Transformer(Cross Attention)模块

U-Net在Stable Diffusion中的完整结构:
文本编码器(Text-encoder):
- 文本编码器是用于处理文本数据的组件,它可以将自然语言描述转换成模型可以理解的向量形式。
- 在稳定扩散模型中,文本编码器通常使用预训练的语言模型,如BERT或GPT,来捕捉文本的语义信息。现在多用CLIP模型
- 这些编码的文本向量随后可以与潜在空间中的图像表示相结合,以生成与文本描述相匹配的图像。








STEPS
https://blog.csdn.net/qq_45752541/article/details/129082742
训练过程:

(1)使用预训练的CLIP模型,对需要训练的图像数据生成对应的描述词语。
(2)使用预训练的通用VAE,先用Encoder,将输入图片降维到 latent space(通常降采样倍数4-16)
(3) 将latent space输入diffusion model,进行扩散(正向采样),一步步生成噪声(在这个过程中,通过权重 β 控制每步生成噪声的强度,直到生成纯噪声,并记录每步生成噪声的数据,作为GT
(4)利用cross attention 将 latent space的特征与另一模态序列的特征融合,并添加到diffusion model的逆向过程,通过Unet逆向预测每一步需要减少的噪音,通过GT噪音与预测噪音的损失函数计算梯度。
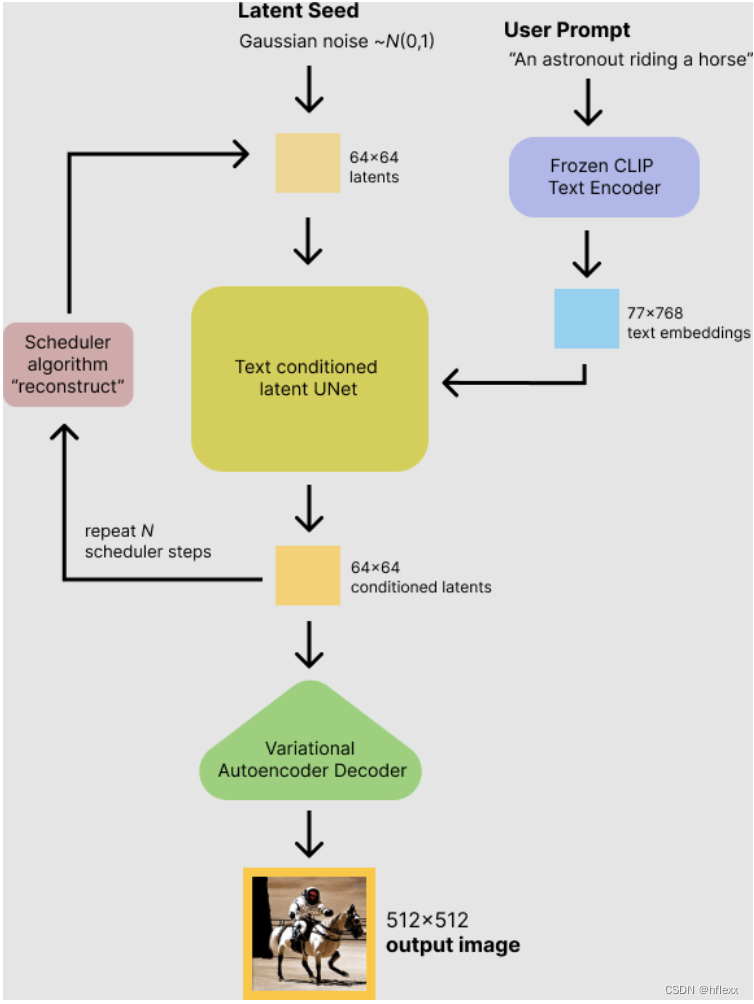
推理过程
-
step1:输入:稳定扩散模型接受两个输入
- 一个是潜在种子(latent seed),用来生成64×64大小的随机潜在图像表示。
- 另一个是文本提示(text prompt),文本提示通过CLIP的文本编码器转换为77×768大小的文本嵌入,用于指导图像的生成。
-
step2:去噪denoise:U-Net在被条件化于文本嵌入的情况下逐步去噪随机潜在图像表示,U-Net的输出是噪声残差,用于通过调度算法计算去噪随机潜在图像表示。
- 调度scheduler算法:去噪后的输出(噪声残差)用于通过调度算法计算去噪后的潜在图像表示。有多种调度算法可供选择,每种算法都有其优缺点。对于Stable Diffusion,推荐使用以下之一:
- PNDM调度器(默认使用)
- K-LMS调度器
- Heun离散调度器
- DPM Solver多步调度器,这种调度器能够在较少的步骤中实现高质量,可以尝试使用25步代替默认的50步。
- 去噪过程:去噪过程大约重复50次,逐步检索更好的潜在图像表示。
- 调度scheduler算法:去噪后的输出(噪声残差)用于通过调度算法计算去噪后的潜在图像表示。有多种调度算法可供选择,每种算法都有其优缺点。对于Stable Diffusion,推荐使用以下之一:
-
step3:解码:完成去噪后,潜在图像表示由变分自编码器的解码器部分解码,生成最终的图像。
Code
Stable Diffusion原理详解(附代码实现)
Stable Diffusion原理+代码
HuggingFace&DiffusionPipeline
官网教程
https://huggingface.co/docs/diffusers/main/zh/quicktour
https://huggingface.co/docs/diffusers/main/zh/api/pipelines/overview#diffusers-summary
https://blog.bot-flow.com/diffusers-quicktour/

#先使用from_pretrained()方法加载模型:from diffusers import DiffusionPipeline
# 这里会下载模型,由于模型一般比较大,默认下载目录为~/.cache/huggingface,可通过export HF_HOME=指定目录,最好写入~/.bashrc持久化
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)#DiffusionPipeline下载并缓存所有model、tokenization、scheduling组件。
'''pipeline
# StableDiffusionPipeline {
# "_class_name": "StableDiffusionPipeline",
# "_diffusers_version": "0.21.4",
# ...,
# "scheduler": [
# "diffusers",
# "PNDMScheduler"
# ],
# ...,
# "unet": [
# "diffusers",
# "UNet2DConditionModel"
# ],
# "vae": [
# "diffusers",
# "AutoencoderKL"
# ]
# }'''
现在,可以在pipeline中输入文本提示生成图像
image = pipeline("An image of a squirrel in Picasso style").images[0]
image.save("image_of_squirrel_painting.png")#保存图像
自定义shceduler()
from diffusers import EulerDiscreteSchedulerpipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
MODEL
大多数模型采用噪声样本,并在每个时间步预测噪声残差。您可以混合搭配模型来创建其他扩散系统。模型是使用from_pretrained()方法启动的,该方法还会在本地缓存模型权重,因此下次加载模型时速度会更快。
#加载 UNet2DModel,这是一个基本的无条件图像生成模型:
from diffusers import UNet2DModelrepo_id = "google/ddpm-cat-256"
model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)model.config#访问模型参数
模型配置(cinfig)是一个冻结字典,这意味着这些参数在模型创建后无法更改。这是有意为之,并确保一开始用于定义模型架构的参数保持不变,而其他参数仍然可以在推理过程中进行调整
- sample_size:输入样本的高度和宽度尺寸。
- in_channels:输入样本的输入通道数。
- down_block_types和up_block_types:用于创建 UNet 架构的下采样和上采样模块的类型。
- block_out_channels:下采样块的输出通道数;也以相反的顺序用于上采样块的输入通道的数量。
- layers_per_block:每个 UNet 块中存在的 ResNet 块的数量。
如需使用推理(inferrence),首先需要使用随机高斯噪声创建图像(在计算机视觉领域,图像往往通过一个复杂的多维张量表示,不同的维度代表不同的含义),具体来说,这里张量的shape是batch * channel * width * height。
- batch:一个批次想生成的图片张数
- channel:一般为3,RGB色彩空间
- width: 图像宽
- height: 图像高
import torchtorch.manual_seed(0)
noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
#randn函数生成服从标准正态分布(均值为0,方差为1)的随机数noisy_sample.shape#输出形状
对于推理,将噪声图像(noisy_sample)和时间步长(timestep)传递给模型。时间步长表示输入图像的噪声程度,开始时噪声多,结束时噪声少。这有助于模型确定其在扩散过程中的位置,是更接近起点还是更接近终点。使用样例方法得到模型输出:
with torch.no_grad():noisy_residual = model(sample=noisy_sample, timestep=2).sample#noisy_residual 对应调度,给定模型输出,调度程序管理从噪声样本到噪声较小的样本
调度程序:与model不同,调度程序没有可训练的权重并且是无参数的
#使用其DDPMScheduler的from_config()
from diffusers import DDPMSchedulerscheduler = DDPMScheduler.from_pretrained(repo_id)
scheduler
- num_train_timesteps:去噪过程的长度,或者换句话说,将随机高斯噪声处理为数据样本所需的时间步数。
- beta_schedule:用于推理和训练的噪声计划类型。
- beta_start和beta_end:噪声表的开始和结束噪声值。
要预测噪声稍低的图像,需要传入:模型输出(noisy residual)、步长(timestep) 和 当前样本(noisy sample)。
less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
less_noisy_sample.shape
import PIL.Image
import numpy as np#首先,创建一个函数,对去噪图像进行后处理并将其显示为PIL.Image:def display_sample(sample, i):image_processed = sample.cpu().permute(0, 2, 3, 1)#匹配PIL的格式image_processed = (image_processed + 1.0) * 127.5image_processed = image_processed.numpy().astype(np.uint8)image_pil = PIL.Image.fromarray(image_processed[0])display(f"Image at step {i}")display(image_pil)#为了加速去噪过程,请将输入和模型移至 GPU:model.to("cuda")
noisy_sample = noisy_sample.to("cuda")现在创建一个去噪循环来预测噪声较小的样本的残差,并使用调度程序计算噪声较小的样本:
# 导入必要的库
import torch
import tqdm# 假设noisy_sample是之前定义的噪声样本张量
sample = noisy_sample# 使用tqdm库来显示进度条,遍历调度器scheduler中的所有时间步
for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):# 1. 预测噪声残差# 使用torch.no_grad()上下文管理器来禁用梯度计算,这通常在推理或评估阶段使用with torch.no_grad():# 调用模型的sample方法来获取噪声残差# 这里model(sample, t)可能代表模型根据当前样本和时间步预测噪声residual = model(sample, t).sample# 2. 计算更少噪声的图像,并更新样本为上一个时间步的值# scheduler.step方法根据残差、时间步和当前样本来更新样本# prev_sample属性保存了更新后的样本sample = scheduler.step(residual, t, sample).prev_sample# 3. 可选地查看图像# 每隔50步检查一次图像,以可视化生成过程# 这里display_sample是一个假设的函数,用于显示或保存图像if (i + 1) % 50 == 0:display_sample(sample, i + 1)论文:https://arxiv.org/abs/1505.04597
Unet code (only complete unet)
代码: https://github.com/yassouali/pytorch-segmentation/blob/master/models/unet.py
# 导入基础模块和PyTorch相关模块
from base import BaseModel
import torch
import torch.nn as nn
import torch.nn.functional as F
from itertools import chain
from base import BaseModel # 这里重复导入了BaseModel,可能是一个错误
from utils.helpers import initialize_weights, set_trainable # 导入初始化权重和设置参数可训练性的函数
from itertools import chain # 再次导入chain,这里也是多余的
from models import resnet # 导入resnet模型,用于UNetResnet变体# 定义一个函数x2conv,用于创建一个卷积块,包含两个卷积层和BN层
def x2conv(in_channels, out_channels, inner_channels=None):# 如果没有指定inner_channels,则将其设置为out_channels的一半inner_channels = out_channels // 2 if inner_channels is None else inner_channels# 创建一个包含两个卷积层和BN层的序列模块down_conv = nn.Sequential(nn.Conv2d(in_channels, inner_channels, kernel_size=3, padding=1, bias=False), # 第一个卷积层,通道数不变,面积收缩nn.BatchNorm2d(inner_channels), # 第一个BN层nn.ReLU(inplace=True), # ReLU激活函数nn.Conv2d(inner_channels, out_channels, kernel_size=3, padding=1, bias=False), # 第二个卷积层,对通道数进行扩张nn.BatchNorm2d(out_channels), # 第二个BN层nn.ReLU(inplace=True) # ReLU激活函数)return down_conv# 定义编码器模块,用于下采样
class encoder(nn.Module):def __init__(self, in_channels, out_channels):super(encoder, self).__init__() # 调用父类的构造函数self.down_conv = x2conv(in_channels, out_channels) # 使用x2conv函数创建卷积块self.pool = nn.MaxPool2d(kernel_size=2, ceil_mode=True) # 创建最大池化层,ceil_mode=True确保输出尺寸为整数def forward(self, x):x = self.down_conv(x) # 通过卷积块x = self.pool(x) # 通过池化层return x # 返回结果# 定义解码器模块,用于上采样
class decoder(nn.Module):def __init__(self, in_channels, out_channels):super(decoder, self).__init__() # 调用父类的构造函数self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) # 创建上采样卷积层self.up_conv = x2conv(in_channels, out_channels) # 使用x2conv函数创建卷积块def forward(self, x_copy, x, interpolate=True):x = self.up(x) # 通过上采样卷积层# 检查尺寸是否一致,如果不一致则进行插值或填充if (x.size(2) != x_copy.size(2)) or (x.size(3) != x_copy.size(3)):if interpolate:x = F.interpolate(x, size=(x_copy.size(2), x_copy.size(3)), mode="bilinear", align_corners=True)else:# 计算需要填充的尺寸diffY = x_copy.size()[2] - x.size()[2]diffX = x_copy.size()[3] - x.size()[3]# 进行填充x = F.pad(x, (diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2))# 将上采样的特征图与编码器的特征图进行拼接x = torch.cat([x_copy, x], dim=1)x = self.up_conv(x) # 通过卷积块return x # 返回结果# 定义UNet模型
class UNet(BaseModel):def __init__(self, num_classes, in_channels=3, freeze_bn=False, **_):super(UNet, self).__init__() # 调用父类的构造函数# 定义模型的各个部分#4个下采样模块self.start_conv = x2conv(in_channels, 64) # 初始卷积层self.down1 = encoder(64, 128) # 第一层编码器self.down2 = encoder(128, 256) # 第二层编码器self.down3 = encoder(256, 512) # 第三层编码器self.down4 = encoder(512, 1024) # 第四层编码器#中间卷积self.middle_conv = x2conv(1024, 1024) # 中间卷积层#上采样self.up1 = decoder(1024, 512) # 第一层解码器self.up2 = decoder(512, 256) # 第二层解码器self.up3 = decoder(256, 128) # 第三层解码器self.up4 = decoder(128, 64) # 第四层解码器#分类self.final_conv = nn.Conv2d(64, num_classes, kernel_size=1) # 最终的分类卷积层self._initialize_weights() # 初始化权重if freeze_bn:self.freeze_bn() # 如果需要,冻结BN层def _initialize_weights(self):# 权重初始化函数for module in self.modules():if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):nn.init.kaiming_normal_(module.weight)if module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.BatchNorm2d):module.weight.data.fill_(1)module.bias.data.zero_()def forward(self, x):# 前向传播函数x1 = self.start_conv(x)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x = self.middle_conv(self.down4(x4))x = self.up1(x4, x)x = self.up2(x3, x)x = self.up3(x2, x)x = self.up4(x1, x)x = self.final_conv(x)return xdef get_backbone_params(self):# 返回模型参数,对于UNet,没有预训练的骨干网络,所以返回空列表return []def get_decoder_params(self):# 返回解码器的参数return self.parameters()def freeze_bn(self):# 冻结BN层for module in self.modules():if isinstance(module, nn.BatchNorm2d):module.eval()# 定义一个带有ResNet骨干网络的UNet变体
class UNetResnet(BaseModel):def __init__(self, num_classes, in_channels=3, backbone='resnet50', pretrained=True, freeze_bn=False, freeze_backbone=False, **_):super(UNetResnet, self).__init__() # 调用父类的构造函数# 根据指定的backbone创建ResNet模型,如果pretrained为True,则加载预训练权重model = getattr(resnet, backbone)(pretrained, norm_layer=nn.BatchNorm2d)# 提取ResNet模型的前四个部分作为初始层self.initial = list(model.children())[:4]# 如果输入通道数不是3,则替换第一个卷积层以匹配输入通道数if in_channels != 3:self.initial[0] = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)# 将初始层转换为Sequential模块self.initial = nn.Sequential(*self.initial)# 将ResNet模型的层1到层4作为编码器的一部分self.layer1 = model.layer1self.layer2 = model.layer2self.layer3 = model.layer3self.layer4 = model.layer4# 定义解码器的卷积层和上采样卷积层self.conv1 = nn.Conv2d(2048, 192, kernel_size=3, stride=1, padding=1)self.upconv1 = nn.ConvTranspose2d(192, 128, 4, 2, 1, bias=False)self.conv2 = nn.Conv2d(1152, 128, kernel_size=3, stride=1, padding=1)self.upconv2 = nn.ConvTranspose2d(128, 96, 4, 2, 1, bias=False)self.conv3 = nn.Conv2d(608, 96, kernel_size=3, stride=1, padding=1)self.upconv3 = nn.ConvTranspose2d(96, 64, 4, 2, 1, bias=False)self.conv4 = nn.Conv2d(320, 64, kernel_size=3, stride=1, padding=1)self.upconv4 = nn.ConvTranspose2d(64, 48, 4, 2, 1, bias=False)self.conv5 = nn.Conv2d(48, 48, kernel_size=3, stride=1, padding=1)self.upconv5 = nn.ConvTranspose2d(48, 32, 4, 2, 1, bias=False)self.conv6 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1)self.conv7 = nn.Conv2d(32, num_classes, kernel_size=1, bias=False)# 初始化权重initialize_weights(self)# 如果需要,冻结BN层if freeze_bn:self.freeze_bn()# 如果需要,冻结ResNet骨干网络的参数if freeze_backbone: set_trainable([self.initial, self.layer1, self.layer2, self.layer3, self.layer4], False)def forward(self, x):# 前向传播函数H, W = x.size(2), x.size(3) # 保存输入的高度和宽度# 通过ResNet的初始层和层1到层4获取编码器的特征图x1 = self.layer1(self.initial(x))x2 = self.layer2(x1)x3 = self.layer3(x2)x4 = self.layer4(x3)# 通过解码器的卷积层和上采样卷积层逐步上采样并合并特征图x = self.upconv1(self.conv1(x4))x = F.interpolate(x, size=(x3.size(2), x3.size(3)), mode="bilinear", align_corners=True)x = torch.cat([x, x3], dim=1)x = self.upconv2(self.conv2(x))x = F.interpolate(x, size=(x2.size(2), x2.size(3)), mode="bilinear", align_corners=True)x = torch.cat([x, x2], dim=1)x = self.upconv3(self.conv3(x))x = F.interpolate(x, size=(x1.size(2), x1.size(3)), mode="bilinear", align_corners=True)x = torch.cat([x, x1], dim=1)x = self.upconv4(self.conv4(x))x = self.upconv5(self.conv5(x))# 如果上采样后的特征图尺寸与输入不一致,则进行插值以匹配输入尺寸if x.size(2) != H or x.size(3) != W:x = F.interpolate(x, size=(H, W), mode="bilinear", align_corners=True)# 通过最后的卷积层得到最终的输出x = self.conv7(self.conv6(x))return xdef get_backbone_params(self):# 返回ResNet骨干网络的参数return chain(self.initial.parameters(), self.layer1.parameters(), self.layer2.parameters(), self.layer3.parameters(), self.layer4.parameters())def get_decoder_params(self):# 返回解码器的参数return chain(self.conv1.parameters(), self.upconv1.parameters(), self.conv2.parameters(), self.upconv2.parameters(),self.conv3.parameters(), self.upconv3.parameters(), self.conv4.parameters(), self.upconv4.parameters(),self.conv5.parameters(), self.upconv5.parameters(), self.conv6.parameters(), self.conv7.parameters())def freeze_bn(self):# 冻结BN层for module in self.modules():if isinstance(module, nn.BatchNorm2d):module.eval()
相关文章:
DiffusionModel-latent diffusion,VAE,U-Net,Text-encoder
Diffusers StableDdiffusion 参考: Stable Diffusion原理详解(附代码实现) Latent Diffusion 自编码器(Variational Autoencoder, VAE): 自编码器是一种无监督学习的神经网络,用于学习数据的有效表示或编码。在稳定扩…...
C# form的移植工作
前言: 目标,将一个项目的form移植到新的工程下,且能够正确编译执行: 1 Copy form的两个文件到新工程下: 比如笔者的logo form 2 修改命名空间: 然后,找到新项目的主程序: 的命名…...

linux防火墙相关命令
防火墙启动关闭 启动防火墙 systemctl start firewalld 关闭防火墙 systemctl stop firewalld 查看状态 systemctl status firewalld 开放或限制端口 开放端口 firewall-cmd --zonepublic --add-port22/tcp --permanent 重新载入一下防火墙设置,使设置生效…...

实习中学到的一点计算机知识(MP4在企业微信打不开?)
我在实习中,常有同事向我反馈说我在微信发的视频格式打不开。这就导致我还要一帧帧的盯着某一个时刻来截图,今天查了一下资料尝试修改视频后缀来解决视频的播放问题。 在网上下载mp4的格式,在本地都能播放,怎么可能发上企业微信就…...

ElasticSearch入门语法基础知识
1、创建测试索引 PUT /test_index_person {"settings": {"analysis": {"analyzer": {"ik_analyzer": {"type": "custom","tokenizer": "ik_smart"}}}},"mappings": {"proper…...
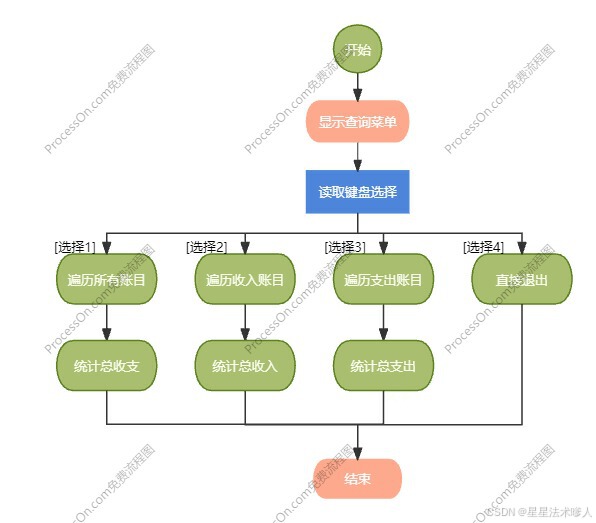
【C++】C++应用案例-dolphin海豚记账本
目录 一、整体介绍 1.1、需求和目标 1.2、整体功能描述 二、页面及功能描述 2.1 主菜单 2.2 记账菜单 2.3 查询菜单 2.4 退出功能 三、流程设计 3.1 主流程 3.2 记账操作流程 3.3 查询操作流程 四、代码设计 4.1 核心思路 4.2 项目文件分类设计 4.2.1 头文件 …...

Matlab数据处理学习笔记
1 :数据清洗 注:数据读取 (1)读取工作表 % 指定要读取的工作表 filename sales_data.xlsx; sheetName Sheet2; % 或者使用工作表编号,例如:sheetNumber 2;% 读取指定工作表的数据 data readtable(fi…...

浏览器中的同源策略、CORS 以及相关的 Fetch API 使用
前言 笔者对前端 Web 技术的认真学习,其实开始于与 Fetch API 的邂逅。当时觉得 fetch() 的设计很不错,也很希望能够请求其它网站下的数据并作处理和展示。学习过程中 HTML 和 CSS 都还好说,由于几乎没有 Web 技术的基础,学习 Fe…...
爬虫 APP 逆向 ---> 粉笔考研
环境: 粉笔考研 v6.3.15:https://www.wandoujia.com/apps/1220941/history_v6031500雷电9 模拟器:https://www.ldmnq.com/安装 magisk:https://blog.csdn.net/Ruaki/article/details/135580772安装 Dia 插件 (作用:禁…...
场 河南大学)
2024河南萌新联赛第(三)场 河南大学
B. 正则表达式 题目: https://ac.nowcoder.com/acm/contest/87865/B 给出n个地址,每个地址的形式为x.x.x.x,找四个x都满足x>0&&x<255的个数 思路: 首先定义四个数组和一个字符,然后按题目所给的形式…...

回溯法---分割回文串
题目:给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文串。返回 s 所有可能的分割方案。 思路: 第一步:确定参数与返回值。参数为字符串s,分割起始下标startIndex,无返回值 第二…...

DDR等长,到底长度差多少叫等长?
DDR4看这一篇就够了 - 知乎 (zhihu.com) 【全网首发】DDR4 PCB设计规范&设计要点PCB资源PCB联盟网 - Powered by Discuz! (pcbbar.com) 终于看到较为权威的DDR4等长要求了: !!!! 依据这个要求,H616项目的等长线不合格:...

程序员面试题------N皇后问题算法实现
N皇后问题是一个著名的计算机科学问题,它要求在NN的棋盘上放置N个皇后,使得它们之间不能相互攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上。这个问题可以看作是一个回溯算法问题,通过逐步尝试不同的放置位置…...
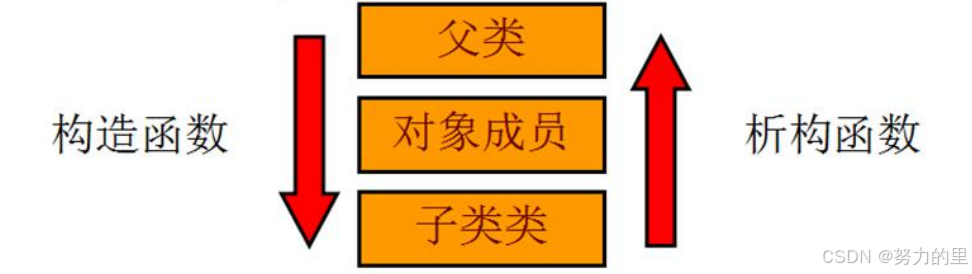
【C++学习】6、继承
1、什么是继承? 继承描述的是类与类之间的关系,A类继承B类,A类就拥有B类的数据和方法。 继承的方式: 公有继承(public) 保护继承(protected) 私有继承(private&…...
 按键与外部中断)
从零开始的MicroPython(三) 按键与外部中断
上一篇:从零开始的MicroPython(二) GPIO及点灯代码 文章目录 前言硬件原理软件原理注意代码编写轮询外部中断其他 前言 点灯是嵌入式GPIO输出的典型,按键则是输入的典型。 硬件原理 按键对角接通。 软件原理 如果是一端接高电平,一端接单…...

Windows下编译安装Kratos
Kratos是一款开源跨平台的多物理场有限元框架。本文记录在Windows下编译Kratos的流程。 Ref. from Kratos KRATOS Multiphysics ("Kratos") is a framework for building parallel, multi-disciplinary simulation software, aiming at modularity, extensibility, a…...
)
汽车-腾讯2023笔试(codefun2000)
题目链接 汽车-腾讯2023笔试(codefun2000) 题目内容 现在塔子哥有 n 个汽车,所有的汽车都在数轴上,每个汽车有1.位置 pos 2.速度 v ,它们都以在数轴上以向右为正方向作匀速直线运动。 塔子哥可以进行任意次以下操作:选择两个汽车…...

软测面试二十问(最新面试)
1.软件测试的流程是什么 参加需求评审会,解决需求疑问---写测试用例---对测试用例进行评审---评审后开始执行测试---提交bug---追踪bug---关闭bug---回归测试---交叉测试---编写测试报告---冒烟测试 2.什么是黑盒测试和白盒测试?它们有何区别 黑盒测试…...

风吸杀虫灯采用新型技术 无公害诱虫捕虫
TH-FD2S】风吸杀虫灯利用害虫的趋光性和对特定波长的光源(如紫外光、蓝光)的敏感性,通过光波引诱害虫成虫扑灯。同时,内置的风扇产生强烈的气流,形成负压区,将害虫迅速吸入到收集器中。害虫在收集器内被风干…...
)
随手记录第十二话 -- JDK8-21版本的新增特性记录(Lambda,var,switch,instanceof,record,virtual虚拟线程等)
本文主要用于记录jdk8以来的新增特性及使用方法! 1.Java8 Lambda表达式(8) 1.1 方法引用 List<String> list List.of("1", "2", "3");list.forEach(i -> System.out.println(i));//方法引用list.forEach(System.out::println);1.2 接…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...