传统自然语言处理(NLP)与大规模语言模型(LLM)详解
自然语言处理(NLP)和大规模语言模型(LLM)是理解和生成人类语言的两种主要方法。本文将介绍传统NLP和LLM的介绍、运行步骤以及它们之间的比较,帮助新手了解这两个领域的基础知识。

传统自然语言处理(NLP)

定义: 是一种利用计算机科学和语言学的技术,通过规则和算法来理解和生成人类语言的方法。传统NLP方法注重使用手工构建的规则和特征来分析和处理文本。这种方法主要依赖于语言学家的知识和经验。
主要技术:
- 词法分析(Tokenization): 将文本拆分为单词或词组。
- 词性标注(POS Tagging): 给每个词分配词性标签,如名词、动词等。
- 命名实体识别(NER): 识别文本中的专有名词,如人名、地名等。
- 句法分析(Parsing): 分析句子的语法结构。
- 语义分析(Semantic Analysis): 理解句子的含义,包括词义消歧和语义角色标注。
- 情感分析(Sentiment Analysis): 分析文本中的情感倾向。
- 机器翻译(Machine Translation): 将一种语言翻译成另一种语言。
运行步骤:(为了更容易理解,我们可以把传统NLP的步骤比作一系列处理文本的流程,就像加工原材料一样,逐步将生涩的文本加工成计算机可以理解和使用的格式。以下是对这些步骤的详细解释:)
-
文本预处理:
- 词法分析(Tokenization): 将文本拆分成单词或词组。
定义: 将一段文字分解成一个个单词或词组,就像把一篇文章切成一片片的单词。
例子: 句子“我喜欢吃苹果”会被分解成“我”、“喜欢”、“吃”、“苹果”。 - 去除停用词(Stop Words Removal): 去掉无实际意义的常用词如“的”、“了”等。
定义: 删除那些在文本处理中没有太大意义的常用词,比如“的”、“是”、“在”等
目的: 提高处理效率,聚焦于更有意义的单词。
- 词法分析(Tokenization): 将文本拆分成单词或词组。
-
特征提取:
- 词性标注(POS Tagging): 给每个词分配词性标签(如名词、动词)。
定义: 给每个单词分配一个词性标签,比如名词、动词、形容词等。
目的: 帮助理解句子结构和单词的功能。
例子: 在句子“我喜欢吃苹果”中,“我”是代词,“喜欢”是动词,“苹果”是名词。 - 词嵌入(Word Embedding): 将词转换成向量表示,如Word2Vec、GloVe等。
定义: 将单词转换成计算机可以处理的数字向量。
目的: 让计算机能够理解单词之间的关系和相似性。
例子: “苹果”和“橘子”在向量空间中可能会很接近,因为它们都是水果。
- 词性标注(POS Tagging): 给每个词分配词性标签(如名词、动词)。
-
语法和语义分析:
- 句法分析(Parsing): 分析句子的语法结构。
定义: 分析句子的语法结构,理解单词如何组合成句子。
目的: 理解句子的整体意思。
例子: 句子“我喜欢吃苹果”可以解析成主语(我)、谓语(喜欢)、宾语(吃苹果)。 - 命名实体识别(NER): 识别文本中的专有名词(如人名、地名)。
定义: 识别文本中的专有名词,如人名、地名、组织名等。
目的: 提取有用的信息。
例子: 在句子“乔布斯创立了苹果公司”中,识别出“乔布斯”是人名,“苹果公司”是组织名。
- 句法分析(Parsing): 分析句子的语法结构。
-
高级任务:
- 情感分析(Sentiment Analysis): 分析文本中的情感倾向。
定义: 分析文本中表达的情感,如积极、消极、中性。
目的: 了解人们对某事物的情感倾向。
例子: “我非常喜欢这本书”表达了积极情感。 - 机器翻译(Machine Translation): 将一种语言翻译成另一种语言。
定义: 将一种语言的文本翻译成另一种语言。
目的: 实现跨语言的交流。
例子: 将“你好”翻译成英语“Hello”。
- 情感分析(Sentiment Analysis): 分析文本中的情感倾向。
过程: 传统NLP通常涉及多个模块,每个模块使用不同的算法和规则来处理特定任务。这种方法需要语言学专家的参与来设计和优化各个模块的规则和算法。

应用: 传统NLP应用广泛,包括文本分类、信息检索、问答系统、语音识别和合成等。
部分应用示例:
1. 信息检索(Information Retrieval):
- 定义: 从大量文本数据中检索相关信息。
- 应用场景: 搜索引擎(如Google),学术文献检索系统。
- 实现方法: 使用关键词匹配、布尔搜索、TF-IDF等方法。
2. 文本分类(Text Classification):
- 定义: 将文本分类到预定义的类别中。
- 应用场景: 垃圾邮件过滤,新闻分类,情感分析。
- 实现方法: 使用朴素贝叶斯分类器、支持向量机(SVM)等传统机器学习算法。
3. 机器翻译(Machine Translation):
- 定义: 将一种语言的文本翻译成另一种语言。
- 应用场景: Google翻译,自动字幕生成。
- 实现方法: 使用统计机器翻译(SMT)和基于规则的翻译方法。
4. 命名实体识别(Named Entity Recognition, NER):
- 定义: 识别文本中的专有名词,如人名、地名、组织名等。
- 应用场景: 信息抽取,生物医学文本分析。
- 实现方法: 使用条件随机场(CRF)、隐马尔可夫模型(HMM)等。
5. 语法和句法分析(Syntax and Parsing):
- 定义: 分析句子的语法结构。
- 应用场景: 语言学习工具,自动语法纠错。
- 实现方法: 使用上下文无关文法(CFG)、依存句法分析等。
大规模语言模型(LLM)

定义: 大规模语言模型是一种基于深度学习和神经网络技术,通过在海量文本数据上进行训练来生成和理解人类语言的模型。与传统NLP依赖手工构建的规则和特征不同,LLM依赖于数据驱动的方法,通过自动学习数据中的语言模式和结构来实现对语言的处理。代表性的模型有OpenAI的GPT系列和Google的BERT。
主要技术:
- 神经网络(Neural Networks): 特别是深度学习中的递归神经网络(RNNs)和变换模型(Transformers)。
- 预训练和微调(Pre-training and Fine-tuning): 先在大量文本上进行无监督预训练,然后在特定任务上进行有监督微调。
- 自注意力机制(Self-Attention Mechanism): 允许模型关注输入序列中的不同部分,捕捉长距离依赖关系。
- 大规模训练数据: 使用海量文本数据进行训练,覆盖广泛的知识和语言现象。
运行步骤:(为了更容易理解,我们可以把大规模语言模型的工作过程比作一个学习语言的大脑,逐步从大量的阅读和实践中学会理解和生成语言。以下是对这些步骤的详细解释:)
-
预训练(Pre-training):
- 数据收集: 收集大量文本数据,如维基百科、新闻文章等。
定义: 收集大量的文本数据,包括书籍、文章、网页内容等。
目的: 提供丰富的语言素材,使模型能够学习语言的多样性和复杂性。
例子: LLM通常使用维基百科、新闻网站、社交媒体内容等作为训练数据来源。 -
数据预处理:清洗和处理收集到的数据,去除HTML标签、特殊字符等噪音和无关内容。
定义: 清洗和处理收集到的数据,去除噪音和无关内容。
目的: 提高数据质量,使其更适合模型训练。
例子: 去除HTML标签、特殊字符和重复内容。 - 模型训练: 使用这些数据训练深度学习模型,通过自监督学习方法(如掩盖语言模型)来学习语言结构和知识。
3.1 预训练(Pre-training):
定义: 在大规模文本数据上进行无监督学习,使模型学习语言的基本结构和知识。
方法: 使用自监督学习方法,如掩码语言模型(Masked Language Model)和自回归模型(Autoregressive Model)。
例子: GPT模型通过预测句子中的下一个单词进行训练,BERT模型通过预测被掩盖的单词进行训练。
3.2 模型架构:
定义: 使用神经网络(特别是Transformer架构)来构建模型。
特点: Transformer模型通过自注意力机制(Self-Attention Mechanism)来处理输入序列,使其能够捕捉长距离依赖关系。
例子: GPT(生成预训练变换器)和BERT(双向编码器表示变换器)是常见的Transformer模型。
- 数据收集: 收集大量文本数据,如维基百科、新闻文章等。
-
微调(Fine-tuning):
- 特定任务数据集: 收集和准备用于特定任务的小规模数据集。
定义: 收集和准备用于特定任务的小规模数据集,如情感分析数据集、问答系统数据集等。
目的: 使预训练模型适应具体任务,提高任务性能。
例子: 为了进行情感分析,可以收集标注了情感标签的电影评论数据集。 - 任务微调: 在特定任务的数据集上进一步训练预训练模型,使其适应具体任务,如文本分类、问答系统等。
定义: 在特定任务的数据集上进一步训练预训练模型。
方法: 使用有监督学习方法,通过提供输入和对应的标签来调整模型参数。
例子: 在情感分析任务中,模型通过学习标注了情感标签的评论来预测新评论的情感倾向。
- 特定任务数据集: 收集和准备用于特定任务的小规模数据集。
-
推理(Inference):
- 模型应用: 使用训练好的模型进行推理,根据输入生成输出,如生成文本、回答问题等。
定义: 使用训练好的模型进行推理,根据输入生成输出。
方法: 将新的文本输入模型,生成相应的输出,如生成文本、回答问题等。
例子: 输入一句话“我喜欢吃”,模型可以生成补全的句子“我喜欢吃苹果”。
- 模型应用: 使用训练好的模型进行推理,根据输入生成输出,如生成文本、回答问题等。
过程: LLM依赖于大规模数据和计算资源,通过深度学习模型自动学习语言特征和知识。训练和微调过程通常需要大量计算能力和时间。

应用: LLM广泛应用于生成文本、对话系统、机器翻译、文本摘要、情感分析和其他NLP任务。
部分应用示例:
1. 生成文本(Text Generation):
- 定义: 根据输入生成自然语言文本。
- 应用场景: 自动写作,聊天机器人,智能客服。
- 实现方法: 使用GPT系列模型,生成与上下文相关的连贯文本。
2. 问答系统(Question Answering, QA):
- 定义: 根据用户提问生成准确的回答。
- 应用场景: 智能助手(如Siri,Alexa),在线客服。
- 实现方法: 使用BERT等模型在大量问答对上进行微调。
3. 机器翻译(Machine Translation):
- 定义: 将一种语言的文本翻译成另一种语言。
- 应用场景: 实时翻译应用,跨语言交流。
- 实现方法: 使用Transformer架构的模型,如Google的翻译模型。
4. 情感分析(Sentiment Analysis):
- 定义: 分析文本中的情感倾向,如积极、消极、中性。
- 应用场景: 社交媒体监控,产品评论分析。
- 实现方法: 使用预训练模型(如BERT)进行微调,识别情感标签。
5. 文本摘要(Text Summarization):
- 定义: 生成文本的简短摘要。
- 应用场景: 新闻摘要生成,文档摘要。
- 实现方法: 使用深度学习模型(如BART,T5)生成简洁明了的摘要。
6. 语言模型微调(Language Model Fine-tuning):
- 定义: 在特定任务数据集上进一步训练预训练模型,使其适应具体任务。
- 应用场景: 专业领域的文本处理,如医学文献分析,法律文档解析。
- 实现方法: 在特定任务的数据集上进行微调,优化模型性能。
传统NLP与LLM的比较
| 特点 | 传统NLP | 大规模语言模型(LLM) |
|---|---|---|
| 技术基础 | 规则和手工算法 | 深度学习和神经网络 |
| 依赖 | 语言学理论和人工特征提取 | 海量数据和计算资源 |
| 性能 | 在特定任务上表现较好 | 通用性强,多任务性能优越 |
| 灵活性 | 需要为不同任务定制方法 | 通过微调适应不同任务 |
| 可解释性 | 具有一定可解释性 | 难以解释内部工作机制 |
| 数据需求 | 对数据需求较低 | 对数据需求巨大 |
| 开发复杂度 | 需要领域专家设计规则和特征 | 需要大量计算资源和数据 |
| 应用范围 | 专用于特定任务 | 广泛适用于多种任务 |
总结
传统NLP和大规模语言模型各有优势和劣势。传统NLP方法依赖于语言学家的知识和经验,通过手工构建的规则和特征来实现对文本的处理,适用于特定任务,但在处理复杂语言现象时可能表现不足。与传统NLP方法依赖手工构建的规则和特征不同,LLM依赖数据驱动的方法,通过预训练和微调实现对语言的理解和生成。LLM通过深度学习和大量数据训练,具有更强的通用性和表现力,但需要大量的计算资源和数据支持。随着技术的发展,LLM在很多应用中已经逐渐取代了传统NLP方法,但在某些需要高可解释性和低资源消耗的场景下,传统NLP仍然具有其优势。
相关文章:
传统自然语言处理(NLP)与大规模语言模型(LLM)详解
自然语言处理(NLP)和大规模语言模型(LLM)是理解和生成人类语言的两种主要方法。本文将介绍传统NLP和LLM的介绍、运行步骤以及它们之间的比较,帮助新手了解这两个领域的基础知识。 传统自然语言处理(NLP&…...
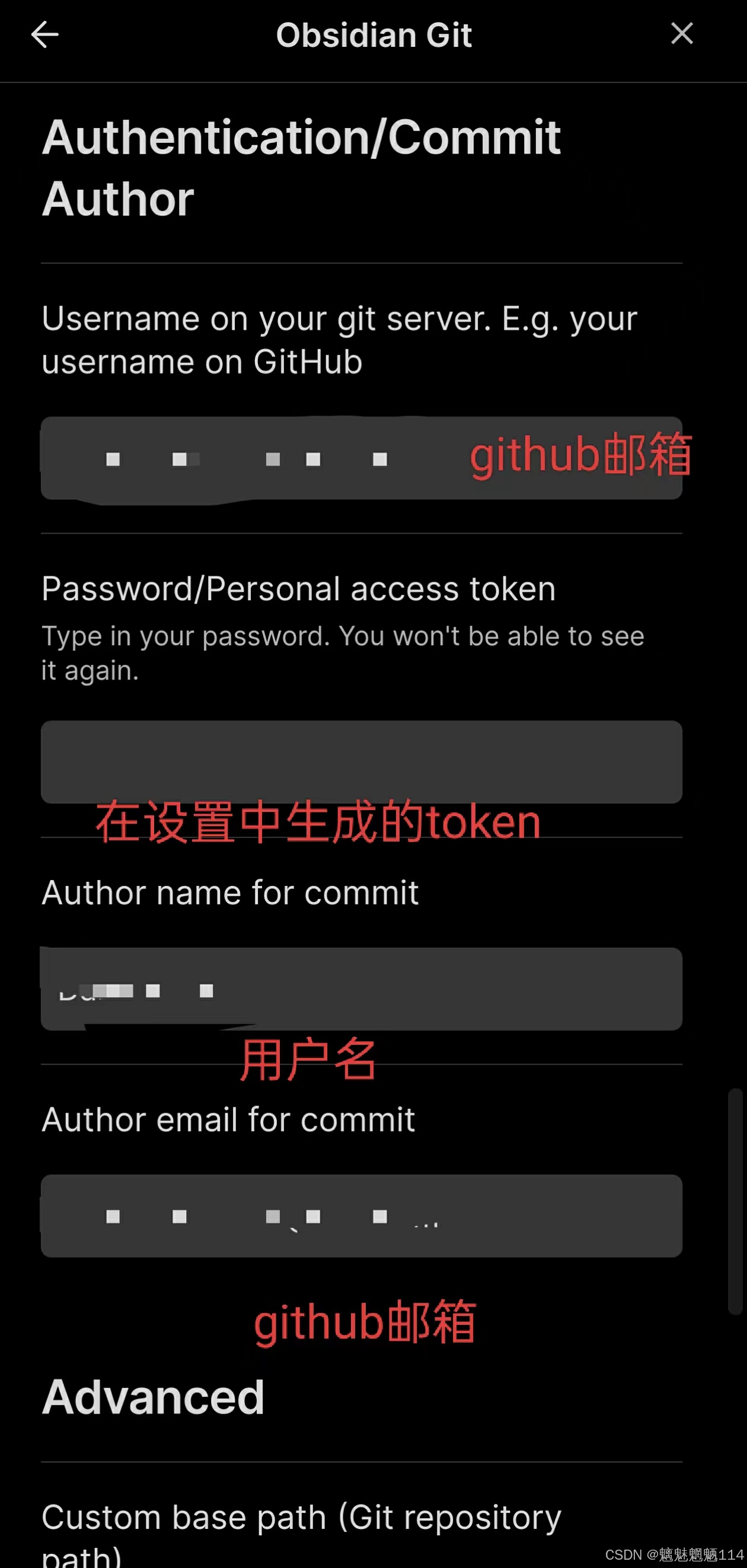
实现Obsidian PC端和手机端(安卓)同步
步骤 1:在PC端设置Obsidian 安装Obsidian和Git:确保你的PC上已经安装了Obsidian和Git。你可以从Obsidian官网和Git官网下载并安装。 克隆GitHub代码库:在PC上打开命令行(例如Windows的命令提示符或Mac/Linux的终端)&a…...

基于大模型的 Agent 进行任务规划的10种方式
基于大模型的 Agent 基本组成应该包含规划(planning),工具(Tools),执行(Action),和记忆(Memory)四个方面,本节将从 Agent 的概念、ReAct 框架、示例、以及一些论文思路来具体聊下任务规划的话题,…...
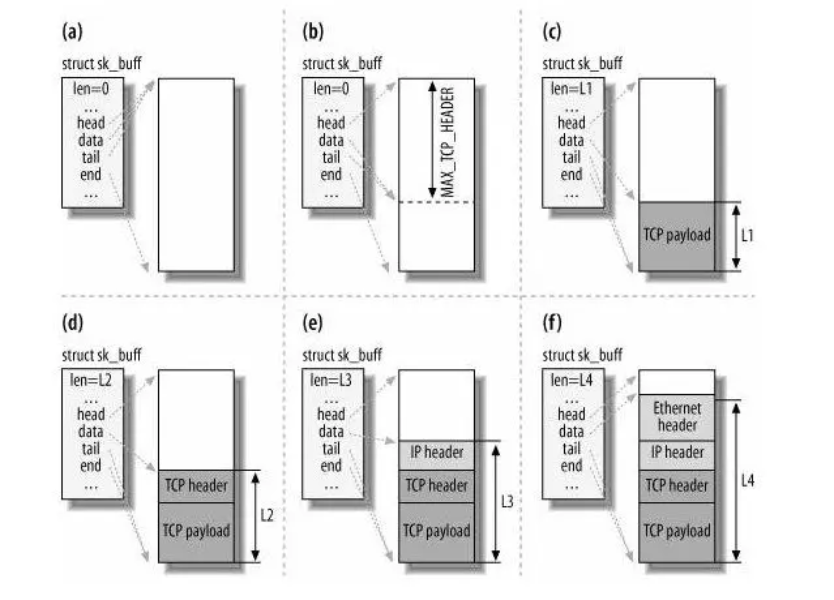
计算机网络01
文章目录 浏览器输入URL后发生了什么?Linux 系统是如何收发网络包的?Linux 网络协议栈Linux 接收网络包的流程Linux 发送网络包的流程 浏览器输入URL后发生了什么? URL解析 当在浏览器中输入URL后,浏览器首先对拿到的URL进行识别…...

基于SpringBoot微服务架构下前后端分离的MVVM模型浅析
基于SpringBoot微服务架构下前后端分离的MVVM模型浅析 “A Brief Analysis of MVVM Model in Front-end and Back-end Separation based on Spring Boot Microservices Architecture” 完整下载链接:基于SpringBoot微服务架构下前后端分离的MVVM模型浅析 文章目录 基于Spring…...

44444444444
4444444444444444...

数据结构与算法-二分搜索树节点的查找
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 文章目录 引言一、二分搜…...

C++|设计模式(七)|⭐️观察者模式与发布/订阅模式,你分得清楚吗
本文内容来源于B站: 【「观察者模式」与「发布/订阅模式」,你分得清楚吗?】 文章目录 观察者模式(Observer Pattern)的代码优化观察者模式 与 发布订阅模式 他们是一样的吗?发布订阅模式总结 我们想象这样一…...

计算机毕业设计选题推荐-学院教学工作量统计系统-Java/Python项目实战
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

人机交互不仅仅是科技问题
人机交互不仅仅局限于物理和数理科学的应用,还涉及到更广泛的管理、文理、哲学、艺术、伦理以及法律等领域。下面这些领域在人机协同和智能系统应用中扮演着重要角色: 智能系统在企业管理、资源分配、决策支持等方面的应用,可以帮助管理者优化…...

Lua Debug.GetInfo
在 Lua 中,debug.getinfo 函数的第一个参数指定了要获取信息的函数的级别。这个级别是一个整数,表示调用栈的深度。以下是一些常见的级别和它们的含义: - 1:当前函数(即调用 debug.getinfo 的函数)。 - 2&a…...

每日刷题(最短路、图论)
目录 游戏 思路 代码 魔法 思路 代码 P1364 医院设置 思路 代码 P1144 最短路计数 思路 代码 游戏 I-游戏_河南萌新联赛2024第(三)场:河南大学 (nowcoder.com) 思路 利用dijkstra去寻找起点到其余所有点的最短路径,当…...

远程服务器训练网络之tensorboard可视化
cd到tensorboard events存储的位置 启动tensorboard tensorboard --logdir./ 得到运行结果: TensorBoard 1.13.1 at http://work:6006 (Press CTRLC to quit) 创建tunnel映射到本地,在本地ssh,最好使用公网地址 ssh -N -L 8080:localhost:60…...

MySQL锁详解
锁是计算机在执行多线程或线程时用于并发访问同一共享资源时的同步机制,MySQL中的锁是在服务器层或者存储引擎层实现的,保证了数据访问的一致性与有效性。 MySQL锁: 按粒度分为:全局锁、表级锁、页级锁、行级锁。按模式分为&…...

面试问题记录:
1,hashmap扩容的时候,链表超长但不满足转变成红黑树的条件时: 【HashMap】链表和红黑树互相转换的几种情况和数组的扩容机制_hashmap红黑树转链表条件-CSDN博客 2,cglib与proxy区别 JDK 动态代理和 CGLIB 动态代理对比_动态代理…...

vue如何在组件中监听路由参数的变化
使用 watch 监听 $route 对象 的变化,从而捕捉路由参数的变化 beforeRouteUpdate 导航守卫 当前组件路由更新时调用 beforeRouteUpdate 钩子只在组件被复用时调用,即当组件实例仍然存在时。如果组件是完全重新创建的,那么应该使用 beforeR…...

antd中form表单校验文件上传
antd中文件上传需要单独设置this.model中得数据 this.$set(this.model, filePath,上传成功后返回得文件路径地址)...

商家转账到零钱2024最新开通必过攻略
微信支付商家转账到零钱功能申请设置了人工审核的门槛,本意是为了防止没有合规使用场景的商户滥用该功能,但这也让相当多的真实用户被一次次拒之门外。结合过去6年开通此类产品的经验,今天我们就以2024年最新的的商家转账到零钱的开通流程做一…...

2024全新Thinkphp聊天室H5实时聊天室群聊聊天室自动分配账户完群组/私聊/禁言等功能/全开源运营版本
全开源运营版本聊天室H5实时聊天室群聊聊天室自动分配账户完群组/私聊/禁言等功能 运营版本的聊天室,可以添加好友,建立群组,私聊,禁言功能 H5TP5.0mysqlPHP 源码开源不加密...
javascript中class类)
(一)javascript中class类
在 JavaScript 中使用 class 语法可以定义类的结构,其中可以包括静态属性/方法、私有属性/方法、公共属性/方法和受保护属性/方法。这些概念有助于封装和数据隐藏,使得代码更加模块化和安全。下面我会解释这些不同的属性和方法,以及如何在类中…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...