从微架构到向量化--CPU性能优化指北
引入
定位程序性能问题,相信大家都有很多很好的办法,比如用top/uptime观察负载和CPU使用率,用dstat/iostat观察io情况,ptrace/meminfo/vmstat观察内存、上下文切换和软硬中断等等,但是如果具体到CPU问题,我们可能只能够分析到CPU占用率很高或者系统负载很高,更细化的指标确无从着手;就算能够知道IPC或者Retiring很高,优化可能也一筹莫展。毕竟现代CPU微架构十分复杂,而且无论是Intel® 64 and IA-32 Architectures Software Developer Manuals还是Intel® 64 and IA-32 Architectures Optimization Reference Manual都太长了,作为软件开发人员很难在里面找到自己想要的知识,这篇文章就结合Top-down Micro-architecture Analysis Methodology(TMAM)、ClickHouse源码的优化经验,聊一聊CPU高性能优化具体该怎么分析怎么做。
微架构分析的TMAM方法
定位CPU问题,我们可以采用Intel的TMAM方法:https://cdrdv2.intel.com/v1/dl/getContent/671488?explicitVersion=true&fileName=248966-046A-software-optimization-manual.pdf
首先介绍下现代微架构的结构,如图所示:
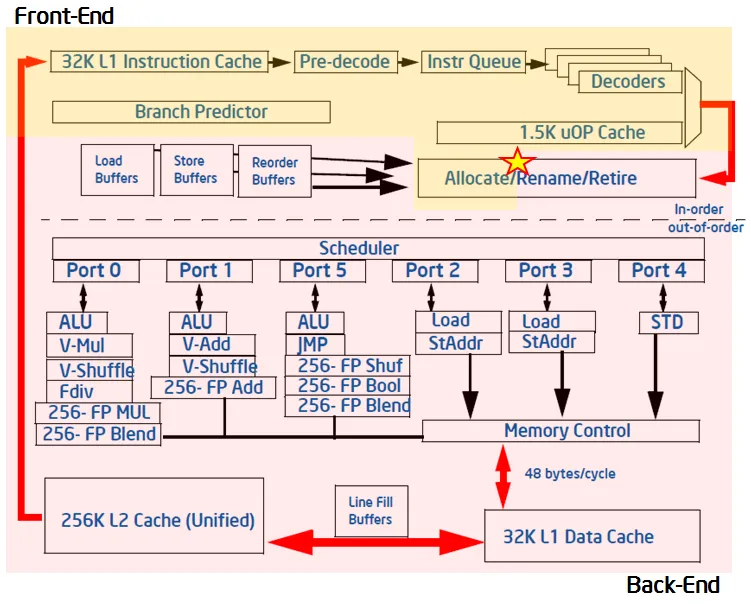
前端负责内存取指(fetch instructions from memory)和转译微指令(translate them into micro-operations / uops)。转译后得到的微指令将被馈送到后端部分。
后端负责对每个微指令进行调度(schedule)、执行(execute)和提交退役(commit / retire)。这种生产-消费的流水线模型就是使用队列(“ready-uops-queue”)来缓存微指令,以待后端消费。
TMAM是什么?如何定位CPU问题?
而TMAM根据cpu时钟周期(cycle)和CPU pipeline slot将CPU瓶颈分为Retiring、Fountend Bound、Backend Bound、Bad Speculation四种:
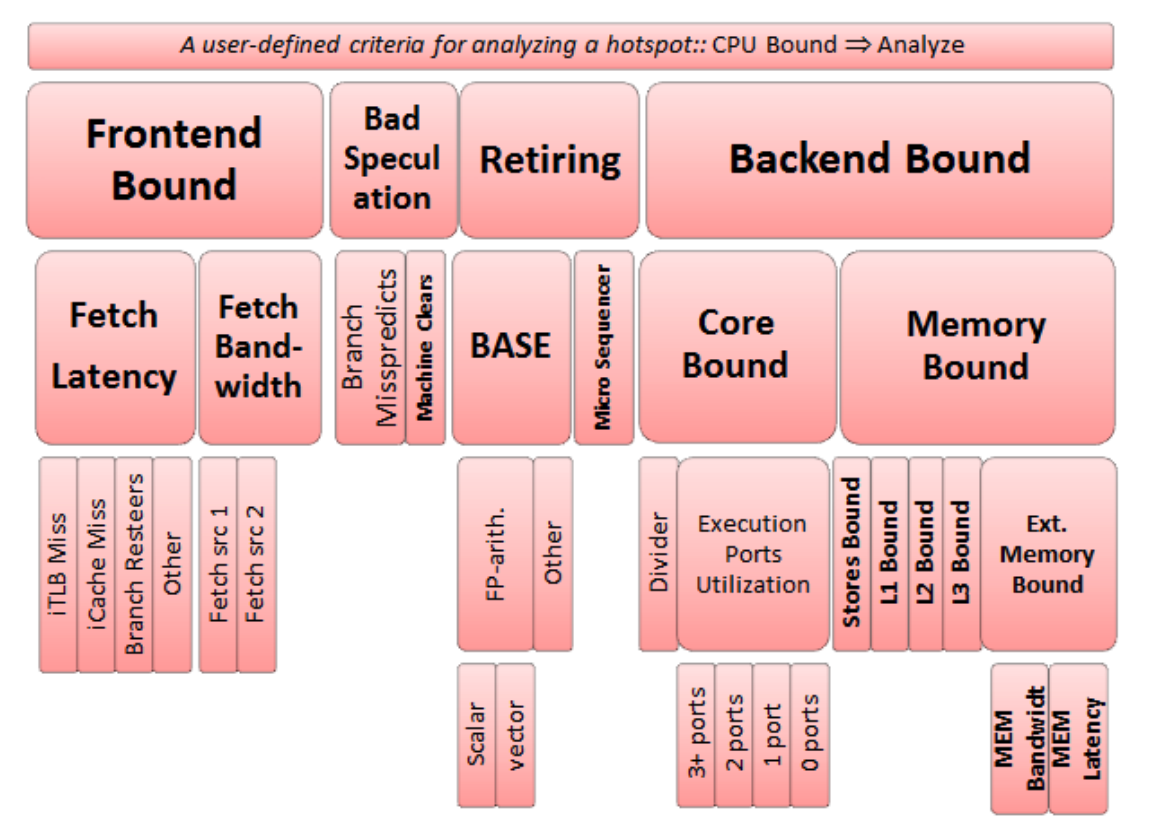
接下来我们看下引起这四种瓶颈的原因。
引起这四种瓶颈的原因是什么?
Bad Speculation
错误分支预测,是由于提交了不会retired的uops引起的。
分为两类,一类是分支预测错误(Branch Misspredict),一类是机器清除(Machine Clears)。
若该分类的值大于一定程度时,需先调查解决该分类。因为哪怕此时其他分支也占据很大的比重,但可能暴露出这些问题的都是那些处于错误分支上的指令,并不能真实地反映出CPU运行该程序正确指令流的特性,所以需要先解决该分类的问题,再去调查研究其他的分支。
Branch Misspredict
Branch Misspredict
错误的分支预测导致的bound。
Machine Clears
Machine Clears
当CPU检测到某些条件时,便会触发Machine Clears操作,清除流水线上的指令,以保证CPU的合理正确运行。比如发生错误的Memory访问顺序(memory ordering violations);自修改代码(self-modifying code);访问非法地址空间(load illegal address ranges),这些操作都会触发Machine Clear。
Frontend Bound
Front-End 职责:
- 取指令
- 将指令进行解码成微指令
- 将指令分发给Back-End,每个周期最多分发4条微指令
所以这里指的是指令获取、解码过程中的瓶颈,可能是因为取指延迟、取指带宽、指令Cache Miss、指令解码效率低(如CPUID等)。
具体来说,它可以分成Frontend Latency和Frontend Bandwidth两类。
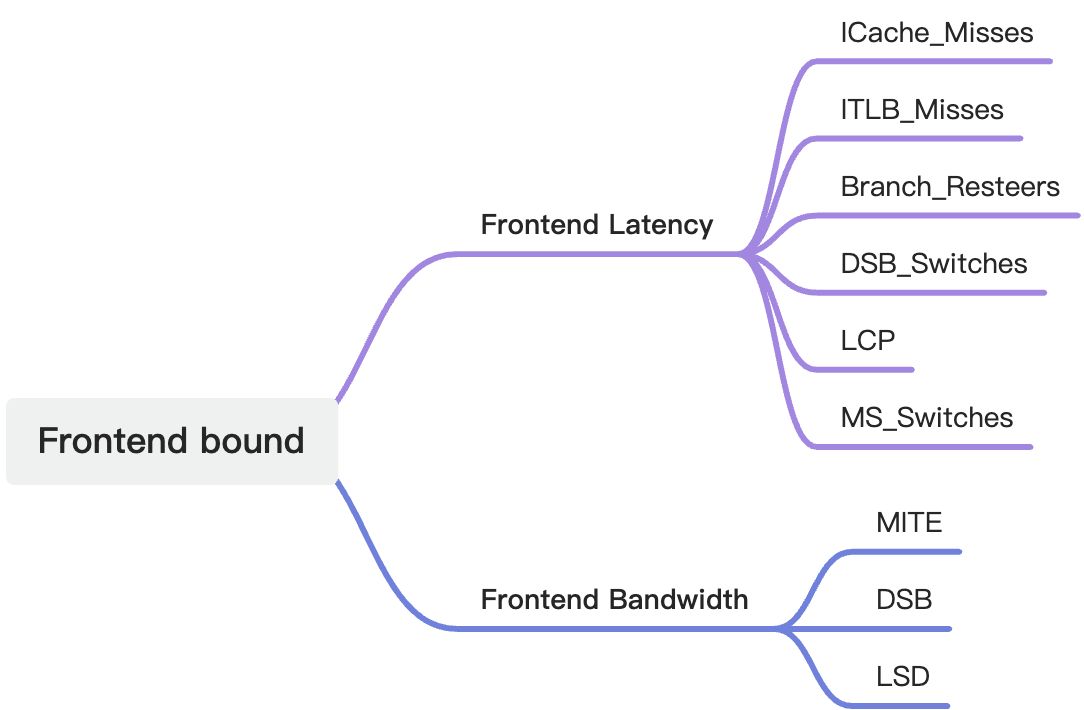
接下来我们结合SkyLake微架构来分别看一下这些指标的含义,具体的计算方法可以参考https://github.com/andikleen/pmu-tools,知乎上也有一篇讲解https://zhuanlan.zhihu.com/p/61015720
Frontend Latency
ICache_Misses
ICache就是我们通常指的L1指令缓存,ICache_Misses指的是L1指令缓存未命中。
ITLB_Misses
ITLB_Misses就是我们熟悉的TLB(Translation Lookaside Buffer,转换后援缓冲器)未命中。
Branch_Resteers
Branch Resteers 是指当 CPU 预测分支指令(如条件跳转指令)错误时,需要回滚到正确的程序路径重新执行分支指令的过程。这种情况通常发生在 CPU 预测错误的分支目标地址与实际分支目标地址不一致时,需要进行分支重定向(Branch Redirect)或者分支修正(Branch Correction)。Branch Resteers,还能继续向下展开为三类,分别为Branch Misprediction,Machine Clears和new branch address clears三类。
DSB_Switches
这里指的是微指令译码器(Decode Pipeline)和微指令缓存(Decoded ICache)之间切换产生的延迟。
LCP
对于正在decode的指令,若发生dynamically changing prefix length,即有LCP,长度改变前缀,便会出现几个周期的Stall。LCP就是指的这部分的延迟。
MS_Switches
MS ROM会存放一些CISC指令的uops流,比如CPUID指令,MS_Switches指的是微指令译码器(Decode Pipeline)和微指令缓存(Decoded ICache)切换到MSROM的开销。
Frontend Bandwidth
MITE
微指令译码器(Decode Pipeline)效率问题引起的bound。
DSB
微指令缓存(Decoded ICache)的效率问题,没有利用好DSB cache structure,或者在读取的时候发生了Bank conflict引起的bound。
LSD
LSD是Loop Stream Detector的缩写,它位于uOp Queue内部,当检测到循环指令全部在uOp Queue中时,只需要不断从LSD中取出相应的uops序列即可,不需要前端译码。如果uops循环的大小与当前硬件的LSD结构不匹配,就会出现LSD带宽不足的情况。
Backend Bound
Back-End 的职责:
- 接收Front-End 提交的微指令
- 必要时对Front-End 提交的微指令进行重排
- 从内存中获取对应的指令操作数
- 执行微指令、提交结果到内存
这里指的是指令执行过程中获取内存、更新内存、指令过载导致的瓶颈。
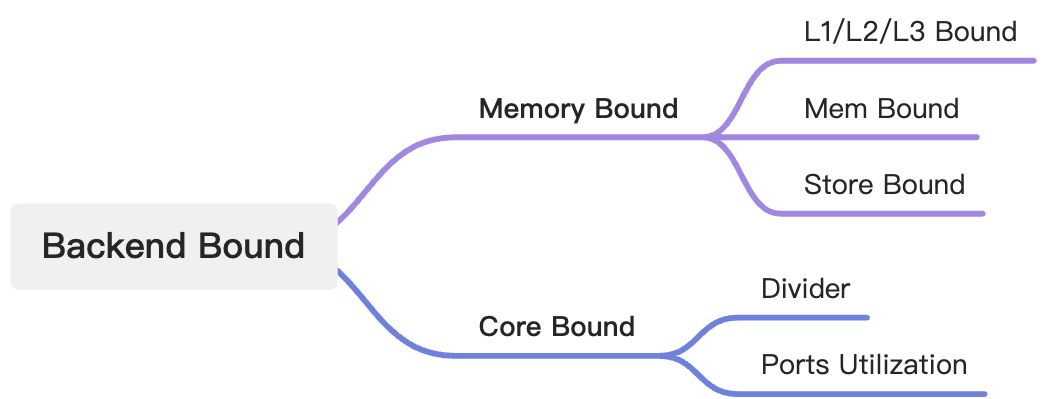
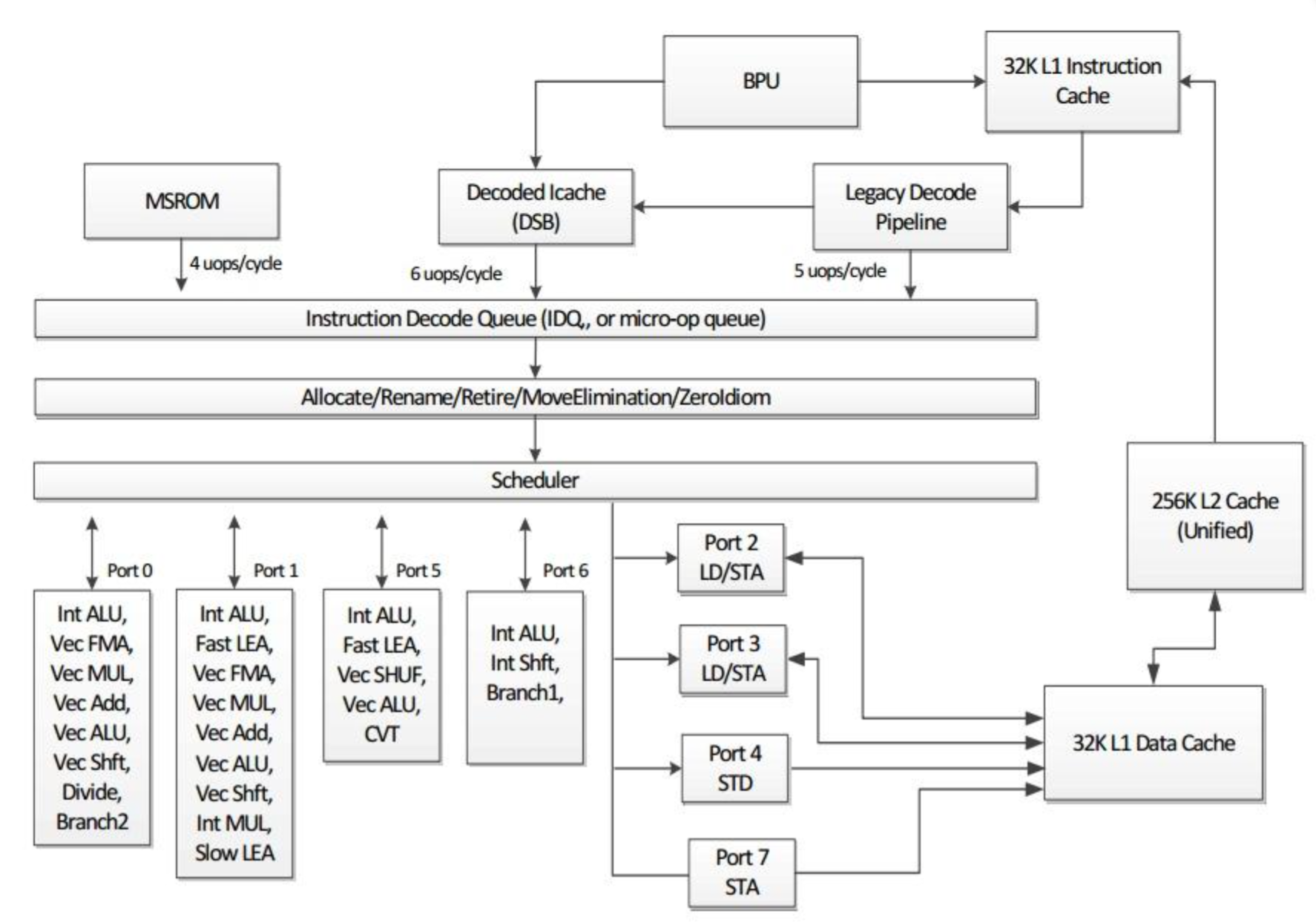
我们结合下面这个图来看一下Backend Bound
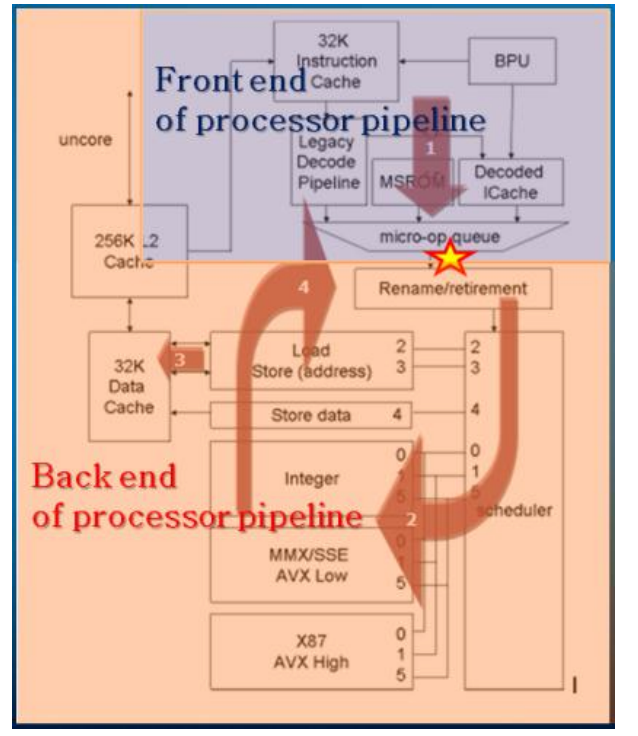
Memory Bound
Memory Bound分为Store Buffer Bound、L1/L2/L3 Bound和Mem Bound。
Cache Line很小,在Scheduler中,没被列进来。
判断方法如下图所示:
Core Bound
Core Bound分为Divider和Ports Utilization。
Divider指的是长延迟的除法操作可能会导致执行串行化,造成短期执行的饥饿期。
Ports Utilization指的是处理器中的指令流被迫按顺序执行,这反映了程序中指令级并行性(ILP)的缺乏。
Retiring
有效的uops(微指令)
**Retiring分为两类:MicroCode Sequence和Base。**MicroCode Sequence就是我们上面提到的MSROM中的指令,它是通过Microcode Sequencer (MS) unit来生成的复杂CISC指令,
Retiring不代表没有优化空间,Micro Sequencer例如Floating Point之类的指令要避免。
高的Base往往意味着向量化能够得到很大的提升。
怎么优化这四个瓶颈?
熟悉语言和平台特性、编译优化选项、通用属性选项、Pragmas和编译器内置函数
从前面我们已经知道了造成瓶颈的原因,那么从代码层面我们可以怎么优化呢?
要对于比较底层的问题进行优化,那么对于编译器做了什么、能提供什么必须有所了解。
下面我就从语言和平台特性、编译优化选项、通用属性选项和编译器内置函数这几个方面简单总结一下。
优化选项、通用属性选项、Pragmas详见:
https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
https://www.rowleydownload.co.uk/arm/documentation/gnu/gcc/index.html#SEC_Contents
https://gcc.gnu.org/onlinedocs/gcc/Pragmas.html
语言和平台特性
相信大家很清楚,熟悉语言和平台特性是一切优化的基础,比如现代C++的STL、零拷贝、原地构造、移动语义、智能指针、constexpr等基础知识;线程进程同步方法、内存序以及不同同步方法/内存序(屏障)的执行开销;Linux系统的特性比如SMP/NUMA、THP、IO_Uring、ebpf等等。这些方面不是本文的重点,因此不在此赘述。
优化选项
除了我们熟知的静态单赋值(SSA)、NRVO(具名返回值优化)、寄存器图着色、死代码消除、常量传播、循环展开、尾递归优化、指令重排、自动内联、缓存预取、分支预测……外,现代编译器还能进行很多强大的优化,下面列出了O2和O3执行的优化,熟悉这些选项是很有用的。
O2
-fauto-inc-dec:对自增和自减操作进行优化,将其转换为更高效的指令序列。
-fbranch-count-reg:使用寄存器来统计分支指令的执行次数,用于分支预测优化。
-fcombine-stack-adjustments:合并连续的堆栈调整操作,以减少不必要的指令。
-fcompare-elim:消除不必要的比较操作,减少程序的运行时间。
-fcprop-registers:通过寄存器传播常量的值,以减少内存访问。
-fdce:删除未使用的代码。
-fdefer-pop:推迟对堆栈的调整操作,以减少指令的数量。
-fdelayed-branch:推迟分支指令的执行,以减少流水线的停顿。
-fdse:进行死代码消除优化,删除不可达的代码。
-fforward-propagate:进行常量传播优化,将常量传播到使用该常量的代码中。
-fguess-branch-probability:根据先前的执行信息猜测分支指令的概率,以优化分支预测。
-fif-conversion:对if语句进行优化,将条件表达式转换为更简单的形式。
-fif-conversion2:进行更复杂的if语句优化,包括通过更改条件的计算顺序来提高性能。
-finline-functions-called-once:对只被调用一次的函数进行内联展开。
-fipa-modref:进行模块间引用分析优化,减少不必要的内存操作。
-fipa-profile:根据程序的执行信息进行优化。
-fipa-pure-const:将纯函数和常量传播进行优化。
-fipa-reference:进行引用分析优化,减少不必要的内存操作。
-fipa-reference-addressable:进行可寻址引用分析优化,减少不必要的内存操作。
-fmerge-constants:合并重复的常量,以减少内存的使用。
-fmove-loop-invariants:将循环不变式移动到循环外部,以减少循环迭代次数。
-fomit-frame-pointer:优化代码以减少堆栈帧的使用。
-freorder-blocks:重新排序基本块以优化执行路径。
-fshrink-wrap:将变量的生命周期范围缩小到最小,以减少内存的使用。
-fshrink-wrap-separate:在函数中单独进行缩小作用域的操作。
-fsplit-wide-types:将宽类型的变量分割为多个较窄的变量,以减少内存的使用。
-fssa-backprop:通过SSA(静态单赋值)形式的数据流分析来优化代码。
-fssa-phiopt:通过SSA形式的Phi函数优化来优化代码。
-ftree-bit-ccp:进行位级的常量传播优化。
-ftree-ccp:进行常量传播优化。
-ftree-ch:进行复杂表达式优化。
-ftree-coalesce-vars:合并变量来减少内存的使用。
-ftree-copy-prop:进行复制传播优化。
-ftree-dce:进行死代码消除优化。
-ftree-dominator-opts:进行支配关系优化。
-ftree-dse:进行死存储消除优化。
-ftree-forwprop:进行常量传播和复制传播的优化。
-ftree-fre:进行冗余表达式消除优化。
-ftree-phiprop:对Phi函数进行优化。
-ftree-pta:进行指针分析优化。
-ftree-scev-cprop:进行简单标量表达式和常量传播优化。
-ftree-sink:将表达式移动到循环外部,以减少循环迭代次数。
-ftree-slsr:进行简单局部标量替换优化。
-ftree-sra:进行标量寄存器分配优化。
-ftree-ter:进行三元表达式优化。
-falign-functions:强制函数在内存中按指定的对齐方式对齐。
-falign-jumps:强制跳转指令在内存中按指定的对齐方式对齐。
-falign-labels:强制标签在内存中按指定的对齐方式对齐。
-falign-loops:强制循环开始地址在内存中按指定的对齐方式对齐。
-fcaller-saves:在函数调用时,保存调用者寄存器的值,以便被调用函数可以修改这些寄存器的值。
-fcode-hoisting:将可能的计算移动到循环外部,以减少循环迭代次数。
-fcrossjumping:在不同的控制流路径中查找重复的代码块,并将其合并为一个共享的代码块。
-fcse-follow-jumps:在跳转指令后面的代码中进行公共子表达式消除。
-fcse-skip-blocks:跳过指定数量的基本块,以提高公共子表达式消除的效率。
-fdelete-null-pointer-checks:删除空指针检查,以提高代码的执行速度。
-fdevirtualize:对虚函数调用进行优化,将虚函数调用转化为直接调用。
-fdevirtualize-speculatively:假设虚函数调用的目标是唯一的,并将其转化为直接调用。
-fexpensive-optimizations:进行一些代价较高的优化,可能会增加编译时间。
-ffinite-loops:假设循环最多执行有限次数,进行一些循环优化。
-fgcse:进行全局公共子表达式消除,删除重复计算的代码。
-fgcse-lm:对循环进行公共子表达式消除,删除循环内重复计算的代码。
-fhoist-adjacent-loads:将相邻的加载指令移动到循环外部,以减少循环迭代次数。
-finline-functions:对函数进行内联展开,将函数调用处替换为函数体。
-finline-small-functions:对小函数进行内联展开。
-findirect-inlining:对间接函数调用进行内联展开。
-fipa-bit-cp:进行位级的常量传播优化。
-fipa-cp:进行常量传播优化。
-fipa-icf:进行间接代码优化,合并相似的间接调用。
-fipa-ra:进行间接寄存器分配优化。
-fipa-sra:进行间接寄存器分配优化,同时进行标量寄存器分配优化。
-fipa-vrp:进行值范围传播优化。
-fisolate-erroneous-paths-dereference:对错误路径上的指针解引用进行隔离。
-flra-remat:在循环中重新材料化值范围,以减少循环迭代次数。
-foptimize-sibling-calls:对兄弟函数调用进行优化。
-foptimize-strlen:对strlen函数进行优化。
-fpartial-inlining:对函数进行部分内联展开。
-fpeephole2:进行指令级别的优化。
-freorder-blocks-algorithm=stc:按指定的算法对基本块进行重新排序。
-freorder-blocks-and-partition:对基本块进行重新排序和分区,以提高指令级优化效果。
-freorder-functions:对函数进行重新排序,以提高指令级优化效果。
-frerun-cse-after-loop:在循环后重新运行公共子表达式消除。
-fschedule-insns:对指令进行调度以提高执行效率。
-fschedule-insns2 -fsched-interblock:对指令进行调度以提高执行效率。
-fstore-merging:合并存储操作,减少存储操作的数量。
-fstrict-aliasing:启用严格别名规则,优化代码对内存的访问。
-fthread-jumps:在多线程环境中,对线程间的跳转进行优化。
-ftree-builtin-call-dce:删除未使用的内建函数调用。
-ftree-pre:进行部分复写消除优化。
-ftree-switch-conversion:对switch语句进行转换优化。
-ftree-tail-merge:合并尾递归函数的调用。
-ftree-vrp:进行值范围传播优化。
O3
-fgcse-after-reload:在寄存器分配之后进行全局公共子表达式消除(GCSE)优化。
-fipa-cp-clone:通过复制函数来进行间接代码传播优化。
-floop-interchange:进行循环交换优化,改变循环的顺序。
-floop-unroll-and-jam:进行循环展开和循环合并的优化。
-fpeel-loops:将循环分解成多个部分,以减少循环迭代次数。
-fpredictive-commoning:通过提前计算和共享结果来进行预测性共享优化。
-fsplit-loops:将循环分割为多个部分,以便更好地利用指令级并行性。
-fsplit-paths:将控制流路径分割为多个部分,以便更好地利用指令级并行性。
-ftree-loop-distribution:将循环分布到多个线程或处理器上,以进行并行化处理。
-ftree-loop-vectorize:对循环进行向量化优化,以利用SIMD指令。
-ftree-partial-pre:进行局部部分预测优化,提前计算和共享部分结果。
-ftree-slp-vectorize:对循环进行超标量指令优化,将多条指令合并为一条指令。
-funswitch-loops:对循环进行开关优化,将循环展开成多个版本,通过开关语句来选择执行哪个版本。
-fvect-cost-model:使用向量化优化的成本模型进行优化。
-fvect-cost-model=dynamic:使用动态的向量化优化成本模型进行优化。
-fversion-loops-for-strides:对循环进行版本化优化,根据迭代步长来选择不同的版本进行执行。
通用属性选项
下面列出跟性能相关的Common Attributes,更多Attributes详见https://www.rowleydownload.co.uk/arm/documentation/gnu/gcc/index.html#SEC_Contents
aligned (alignment)
aligned属性指定函数第一条指令的最小对齐方式,以字节为单位。指定后,对齐方式必须是整数常数 2 的常量幂。不指定对齐参数意味着目标的理想对齐。
alloc_align (position)
该属性可以应用于返回指针并采用至少一个整数或枚举类型的参数的函数。它指示返回的指针在函数参数 alloc_alignposition处给出的边界上对齐。有意义的对齐是 2 大于 1 的幂。GCC 使用此信息来改进指针对齐分析。
例如
void* my_memalign (size_t, size_t) attribute ((alloc_align (1)));
always_inline
强制内联函数,无法内联会产生error
cold
函数上的cold属性用于通知编译器该函数不太可能被执行。
const
告诉 GCC,对具有相同参数值的函数的后续调用可以替换为第一次调用的结果,而不管两者之间的语句如何
例如:
int square (int) attribute ((const));
flatten
对于标记有此属性的函数,如果可能的话,此函数内的每个调用都是内联的。用特性noinline和类似的函数声明的函数不内联。是否考虑函数本身进行内联取决于其大小和当前的内联参数。
hot
函数上的属性用于通知编译器该函数是已编译程序的热点。该函数进行了更积极的优化,在许多目标上,它被放置在文本部分的特殊子部分中,因此所有热门函数看起来都很接近,从而改善了局部性。
pure
对pure函数的调用,如果函数除了返回值之外对程序的状态没有可观察的影响,则可能需要进行优化,例如常见的子表达式消除。使用 该属性声明此类函数允许 GCC 避免在重复调用具有相同参数值的函数时发出某些调用。
returns_nonnull
该属性指定函数返回值应为非 null 指针。例如,声明:
extern void *
mymalloc (size_t len) __attribute__((returns_nonnull));
允许编译器根据返回值永远不会为 null 的知识来优化调用方。
target (string, )
多个目标后端实现 target 属性,以指定要使用与命令行上指定的目标选项不同的目标选项来编译函数。原始目标命令行选项将被忽略。可以提供一个或多个字符串作为参数。每个字符串都由一个或多个逗号分隔的 -m 前缀后缀组成,共同构成与计算机相关的选项的名称。
编译器内置函数
提醒:除了具有库等价物的内置函数(如标准C库函数),或者扩展到库调用的内置函数外,GCC内置函数总是内联扩展的,因此没有相应的入口点,并且无法获得它们的地址。试图在函数调用以外的表达式中使用它们会导致编译时错误。
void __builtin___clear_cache (void *begin, void *end)
此函数用于为包含开始和排除结束之间的内存区域刷新处理器指令缓存。一些目标要求在修改包含代码的内存后刷新指令缓存,以获得确定性行为。
void __builtin_prefetch (const void *addr, …)
此函数用于在访问数据之前将数据移动到缓存中,从而最大限度地减少缓存未命中延迟。您可以将对__builtin_prefetch的调用插入到您知道内存中可能很快被访问的数据地址的代码中。如果目标支持它们,则会生成数据预取指令。如果预取在访问之前足够早地完成,那么在访问数据时数据将在缓存中。
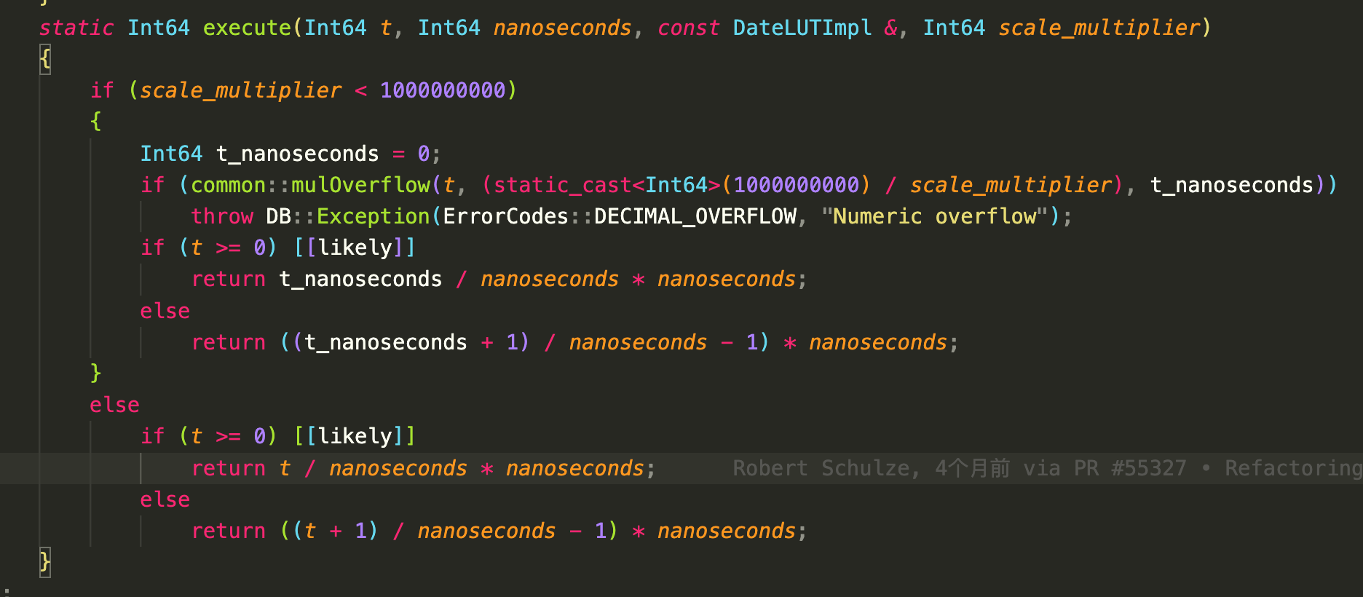
long __builtin_expect (long exp, long c)
可以使用__builtin_expect为编译器提供分支预测信息。一般来说,pgo是更好的(-fprofile arcs),因为程序员在预测程序实际执行方面是出了名的糟糕。然而,有些应用程序很难收集这些数据。
下面是一个在clickhouse中使用分支预测的例子:
Pragmas
循环展开
循环展开现在编译器都会自动做了,有时候可能需要限制循环展开。
比如clickhouse里面的一段:
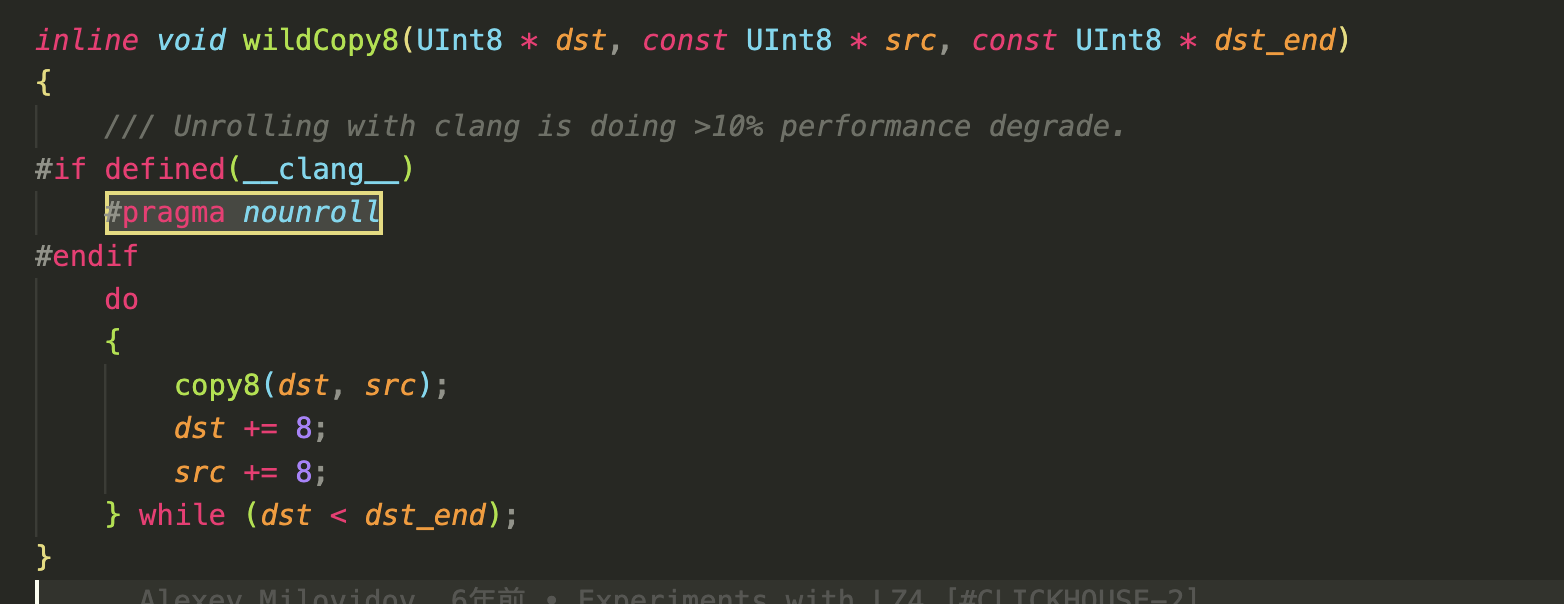
对小的循环体进行 unroll 可能是划算的,但最好不要 unroll 大的循环体,否则会造成uop decode pipeline的压力反而变慢。
对齐
从整个体系结构的角度来看,对齐有几个纬度:
- 总线寻址对齐
- 内存页对齐
- Cache Line对齐
- 缓存对齐
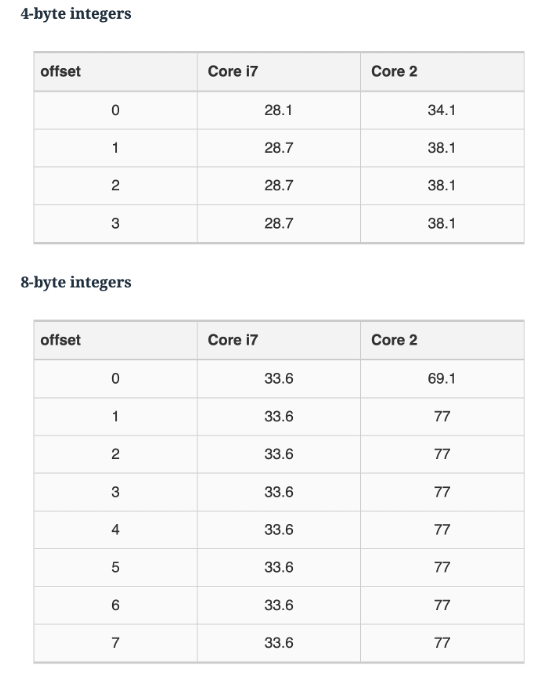
总线寻址对齐
总线对齐,64位机器就是8byte对齐,这一点在现代CPU中已经不重要了。编程时不需要考虑这个问题(见下图[见下图,图片来自https://lemire.me/blog/2012/05/31/data-alignment-for-speed-myth-or-reality/])。
内存页对齐
内存页对齐,也就是4K对齐,内核线性区分配和b+树中间节点都会使用4k页对齐,这主要是一些磁盘和内存结构需要考虑的。
Cache Line对齐
cpu缓存行对齐,也就是64byte对齐。这是最关键的一点:首先它可以防止(UMP架构下)MESI协议导致的缓存行失效(伪共享)。其次,它对性能有很大影响
(见下图,图片来自https://github.com/zhangz/KnowledgeBase/blob/master/Essential%20.NET/Gallery%20of%20Processor%20Cache%20Effects.pdf)。
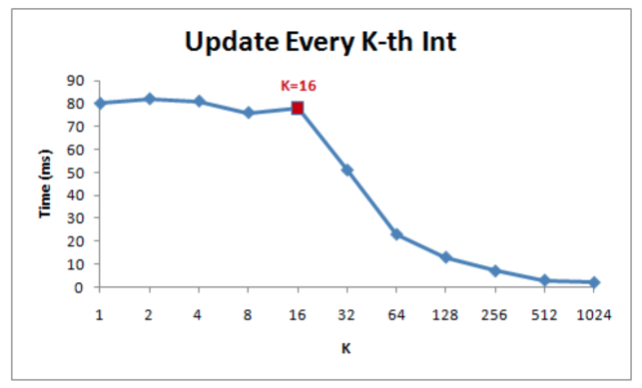
L1/L2缓存对齐
L1 L2缓存,一般是64k和**256KB to 32MB,**同样对性能有较大影响。如下图:
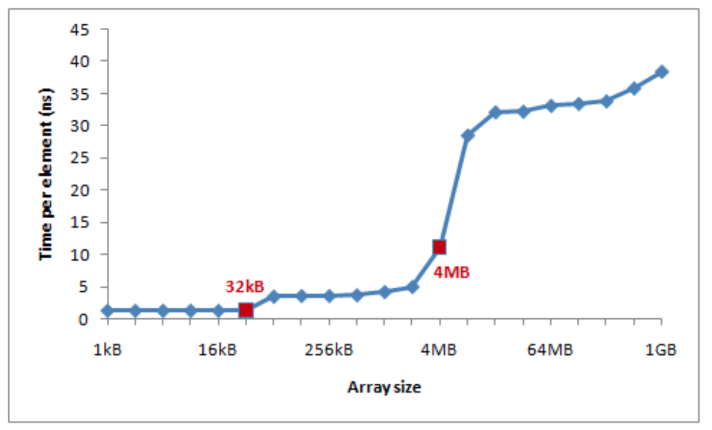
比如使用avx-512,将数据与64个字节对齐时可以通过_mm512_load_pd将数据直接加载到zmmm寄存器中,并在其上应用SIMD指令,然后通过_mm512 _stream_pd将其存储回。
注意谨慎使用这里的指令,如果不进行大量的向量化计算,只会造成内存浪费。
相反,大多数情况下需要的是1字节填充来节省内存。
比如:
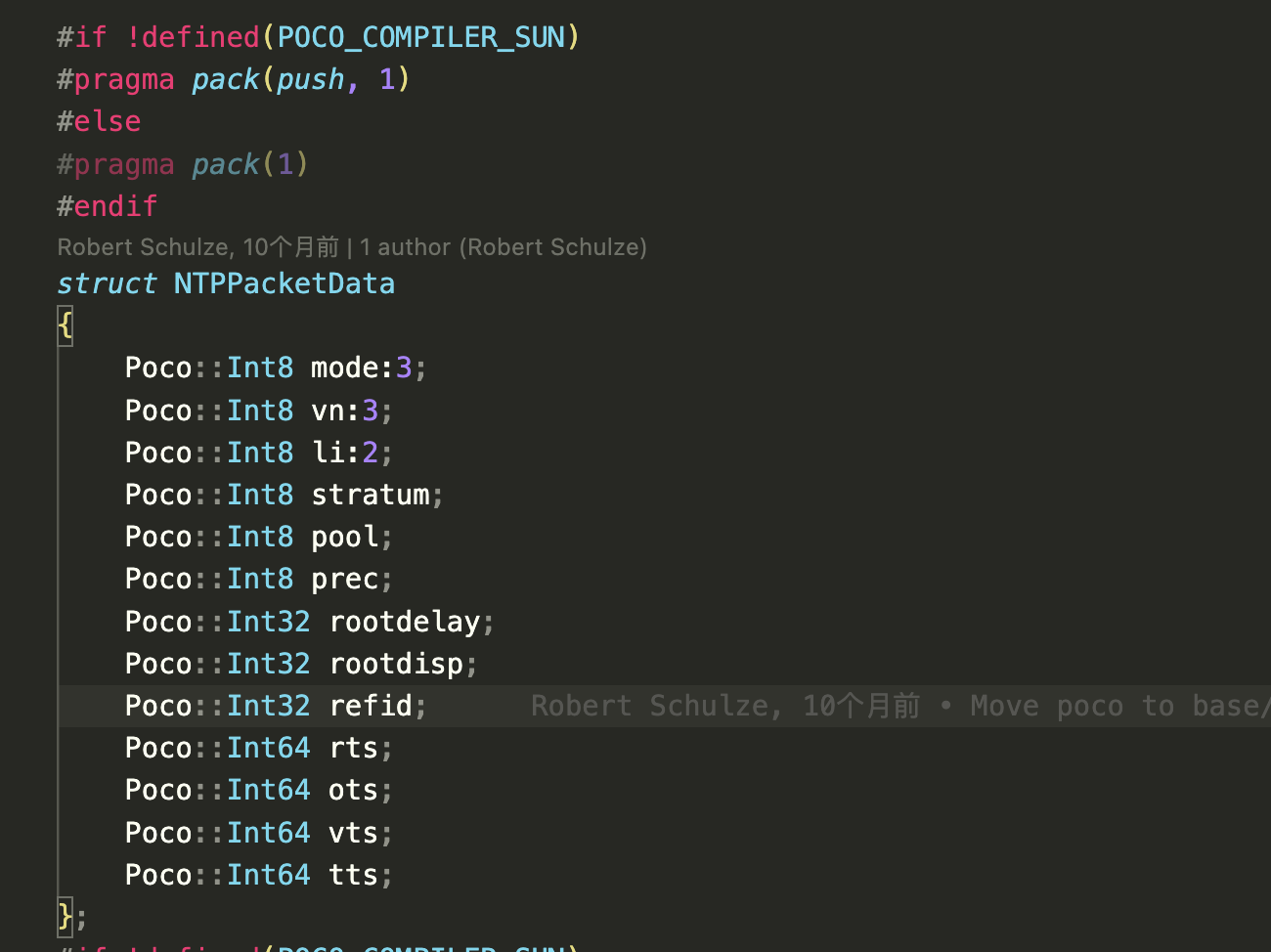
restrict和#pargma ivdep
使用__restrict__ 显式告诉编译器参数是内存中的不同位置,这可以节省一条指令。
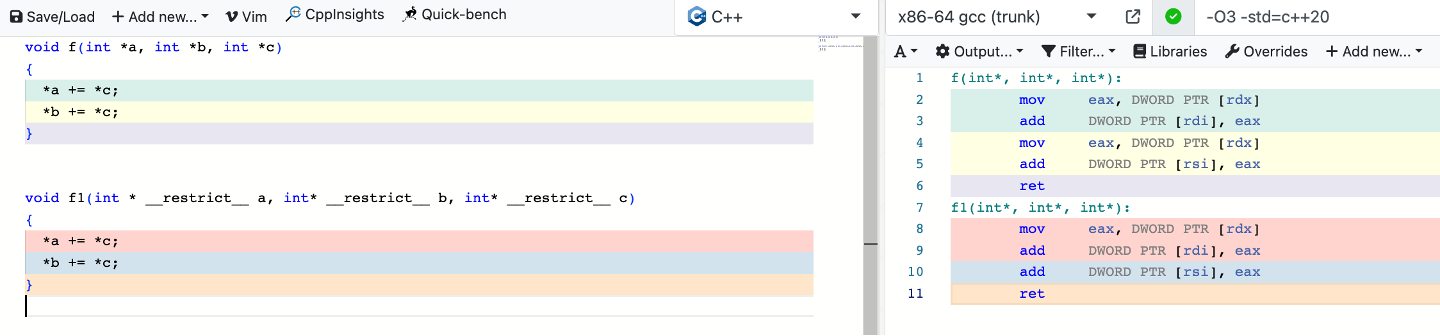
使用#pargma ivdep 断言循环不携带依赖项
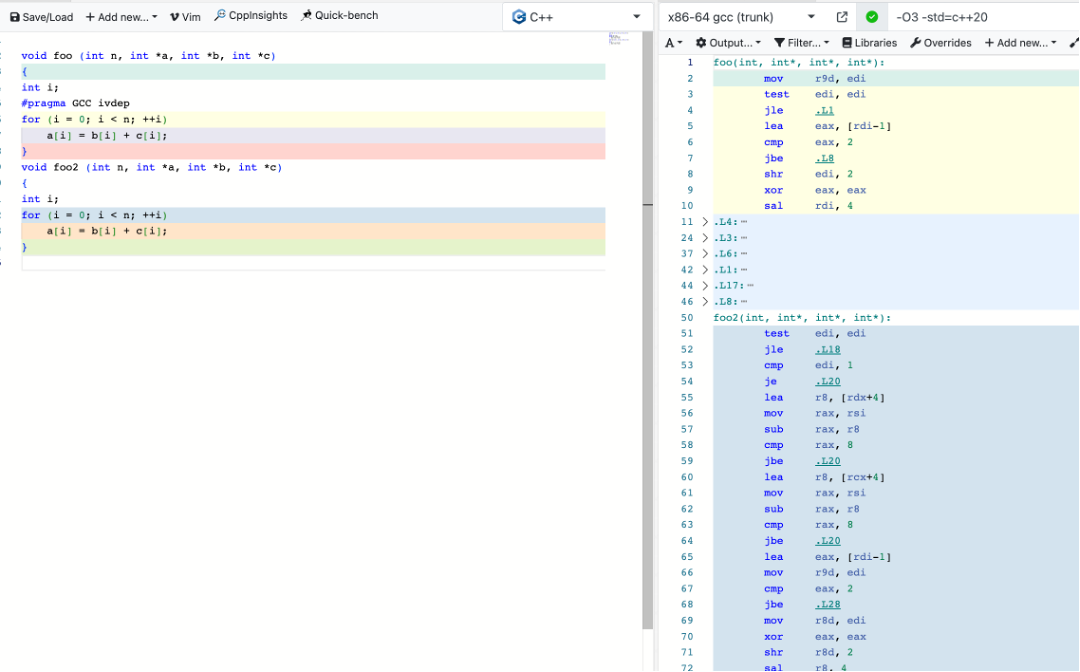
自动向量化和自动并行
#pargma simd 提示编译器向量化, 如果不能向量化则警告
#pargma vector 强制向量化,忽略启发式规则
#pargma omp 使用openmp自动并行
比如:

优化Frontend Bound
如果Frontend Bound是瓶颈的话,那么我们可以考虑从下面几个方面进行优化:
ICache_Misses
对于ICache_Misses,正确识别热点代码很重要,需要我们充分利用编译器的PGO 特性:-fprofile-generate -fprofile-use,LTO则会加大内联,对于这方面有反作用。
另外,可以通过手动标识__attribute__ ((hot)) attribute ((cold)) 和long __builtin_expect (long exp, long c)调整代码命中率来优化ICache_Misses。
ITLB_Misses
ITLB_Misses优化可以考虑通过减少上下文切换和THP(内存大页)来实现。
Branch_Resteers
Branch_Resteers主要是要减少分支预测的错误率,这个会在优化Bad Speculation中集中说。
LCP
LCP是一个平台相关的问题,比如产生了0x66,0x67前缀的指令或者REX.W指令,这个时候要结合汇编代码看下为什么产生这个瓶颈。
MS_Switches
减少CISC指令比如CPUID指令的使用
MITE
如果微指令译码器(Decode Pipeline)出现了效率问题,那主要考虑微码长度问题,是不是需要nounroll,比如上面举的clang的例子。
LSD
LSD主要考虑减小uop循环的大小。
优化Bad Speculation
消除Bad Speculation主要是通过优化分支预测进行,参考https://zhuanlan.zhihu.com/p/357699203
- 消除分支可以减少预测的可能性能:比如小的循环可以展开比如循环次数小于64次(可以使用GCC选项 -funroll-loops将循环全部展开),当然选用激进的优化选项要做好bench
- 尽量用if 代替:? ,不建议使用a=b>0? x:y 后者不能做分支预测
- 尽可能减少组合条件,使用单一条件比如:if(a||b) {}else{}
- 对于多case的switch,尽可能将最可能执行的case 放在最前面
- 在使用if的地方尽可能使用gcc的内置分支预测特性
- 避免间接跳转和调用 在c++中比如switch、函数指针或者虚函数在生成汇编语言的时候都可能存在多个跳转目标,这个也是会影响分支预测的结果,虽然BTB可改善这些但是毕竟BTB的资源是很有限的。
优化Retiring和BackendBound的利器–向量化
优化BackendBound,我们需要尽量使用数据对齐并且利用缓存行,还要避免伪共享。
接下来主要是介绍今天的另一个重点:向量化。当我们遇到Retiring和BackendBound瓶颈的时候,大多可以使用向量化来优化它们。
什么是SIMD向量化和SIMT向量化以及如何选择
无论是CPU还是GPU,基本的并行手段主要有三种:
(1) instruction-level parallelism (ILP) 指令并行 如超标量、流水线(在GPU中叫做流水线并行)
(2) thread-level parallelism (TLP) 如openmp 和 pthread (在GPU中叫数据并行或者SIMT)
(3) vector-level parallelism 如SIMD(在GPU中叫张量并行)
但是GPU和CPU的侧重点是不一样的,CPU是大核模式,天生支持指令并行,包括超标量、流水线等技术,主要致力于提升IPC;GPU是众核模式,天生支持数据并行或者说线程并行,主要致力于提升并行计算能力。
那么什么样的应用适合于GPU加速呢?考虑下面几个问题:
- 瓶颈是memory latency bound还是memory bandwidth bound,一般以带宽为瓶颈的程序更适合使用GPU加速。https://www.brendangregg.com/blog/2017-05-09/cpu-utilization-is-wrong.html 这篇文章给出了分析方法
- PCIE传输性能 加速效果能超过CPU和GPU间的PCIE传输的开销吗?
- 是否是并发场景?GPU在高并发场景下会有明显性能下降。
- 是否需要落盘?例如,在物化算子中(必须使用全量数据进行运算的算子),内存往往不够用,必须落盘,GPU就不适用于这种场景。或者有比较大的中间结果,往往也是不合适的。
- 瓶颈是计算吗?如果瓶颈既有IO,又有CPU,那么使用GPU往往是不划算的。
可以说,除了图像处理、机器学习等领域,一般都不需要使用GPU加速。
使用Intrinsics替代汇编
随着优化越来越靠近底层,语言的抽象层次越深,那么我们能感受到的Gap也就越大,比如如果在微架构的层面进行优化,那么C++已经力不从心了,有时候可能需要嵌入式汇编的帮助。
但是,汇编并不是好的范式。因为它难以维护、容易出错、可移植性差。
我们看几个高性能开源库的实践:
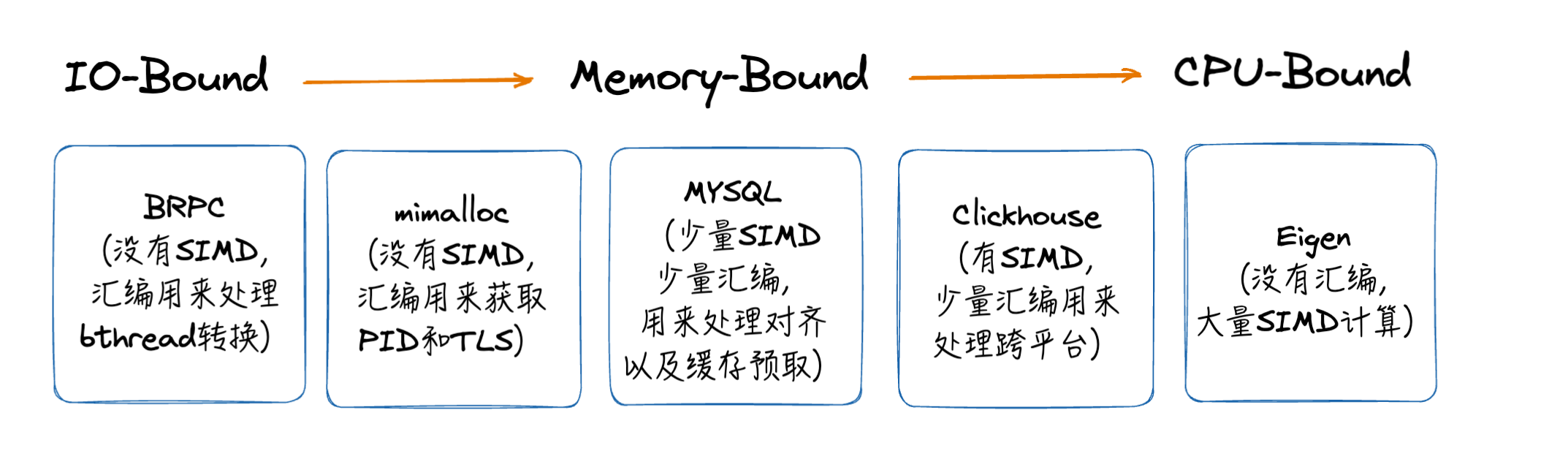
从这些优秀开源的实践我们能总结出来:什么时候使用汇编,什么时候使用SIMD有几个基本原则:
- 如果编译器能知道怎么优化是最好的(绝大多数情况下),那么不要复杂化代码。
- 编译器的优势是聪明,但你的优势是知道的多,因此提示编译器而不是手写汇编/SIMD。
- 99%的情况下不要使用SIMD,如果你发现无法成功提示编译器,并且这里的性能 _真的 _很重要,那么可以使用SIMD,但是要注意跨平台的问题,并测试你的代码真的超过了-O3下的编译器。
- 尽量不要使用汇编,除非你找到了SIMD库(https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html**)的问题 或者 你要控制内核态资源(比如进程切换和进程栈资源)[比如mimalloc brpc等等] **
经常使用的SIMD操作
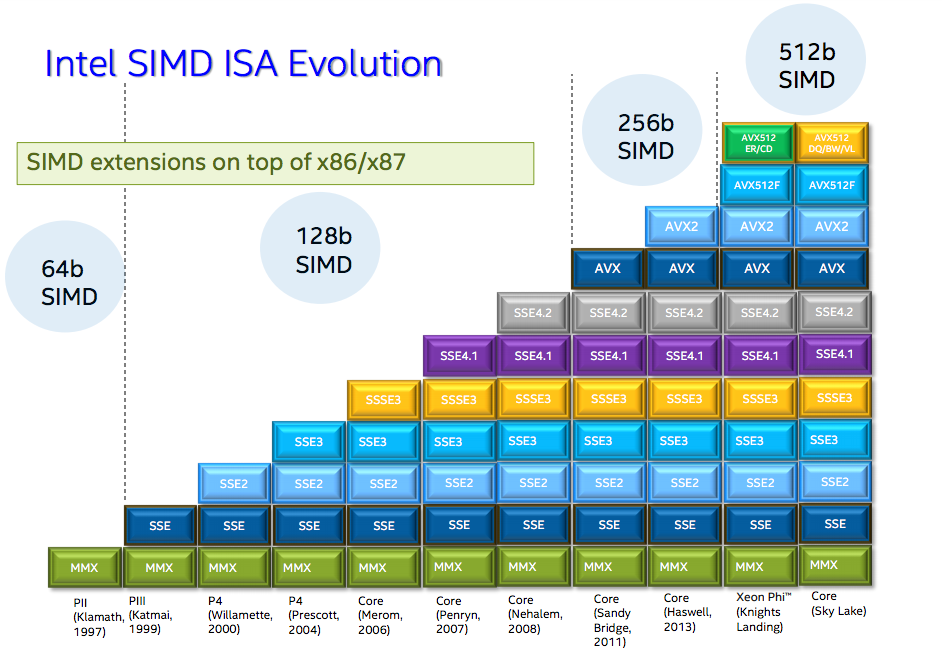
所谓的SIMD,就是用MMX指令集(64位SIMD寄存器)或者SSE/AVX/AVX512指令集(128位SIMD寄存器),做数据的并行化处理。它有如下几个基本操作:
- 遮罩 Masking
- 排列
- 选择性加载 / 存储
- 压缩 / 扩展
- 选择性聚集 / 散开
这部分可以参考Pavlo的15721课程: 15721.courses.cs.cmu.edu/spring2023/slides/08-vectorization.pdf
遮罩
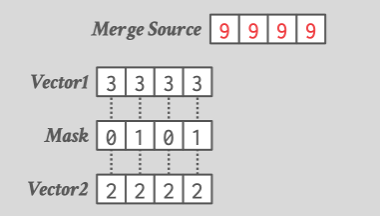
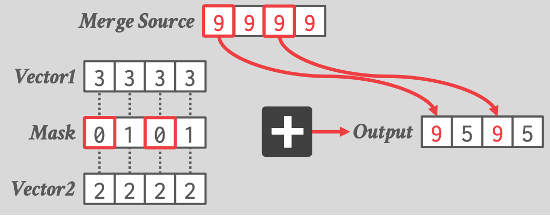
比如:
__m128i _mm_mask_abs_epi16 (__m128i src, __mmask8 k, __m128i a)
- src:一个__m128i类型的SIMD向量,用作结果的初始值。
- k:一个__mmask8类型的掩码向量,指示哪些数据元素需要执行绝对值操作。
- a:一个__m128i类型的SIMD向量,作为绝对值操作的输入。
函数的功能是将a向量中根据k掩码指示的元素取绝对值,然后将结果存储到src向量对应的位置上。换句话说,只有k掩码向量中对应位置为1的元素会被执行绝对值操作。
例如,假设有以下输入:
- src向量:[4, -6, 3, -2, -7, 8, -1, 5]
- k掩码向量:[1, 0, 1, 0, 1, 0, 1, 0]
- a向量:[2, -3, 6, -4, 1, -9, 5, -2]
则执行_mm_mask_abs_epi16(src, k, a)操作后,结果向量将为:
[2, -6, 6, -2, 1, 8, 5, 5]
又比如:
int _mm_movemask_epi8 (__m128i a)
重排
对于每个通道,将索引向量中指定的偏移量处的输入向量的值复制到目标向量中。在 AVX-512 之前,数据库管理系统必须将数据从 SIMD 寄存器写入内存,然后再写回 SIMD 寄存器。而 AVX-512 指令集引入了新的 PERMUTE 操作,可以直接在 SIMD 寄存器内部完成元素重排,大大提高了性能。
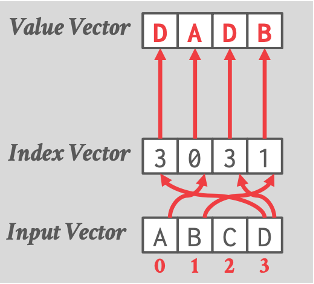
blend:
在SIMD(Single Instruction, Multiple Data)编程中,Blend(混合)是一种操作,用于将两个向量按照指定的规则进行混合。混合操作通常是将两个向量的对应元素进行混合,生成一个新的向量。
选择性加载 / 存储
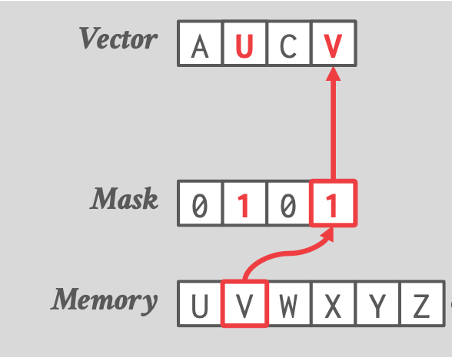
选择性加载从内存中读取满足特定条件的数据元素,而选择性存储将数据元素写回内存
压缩 / 扩展
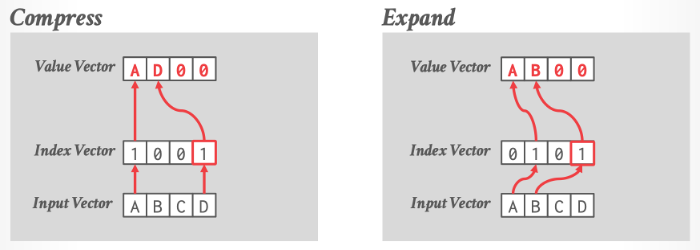
用于减少数据存储需求和提高内存访问效率。
压缩操作将数据集中的冗余信息删除,减小数据的存储空间。扩展操作则是压缩的逆过程,将压缩后的数据还原为原始格式
选择性聚集 / 散开
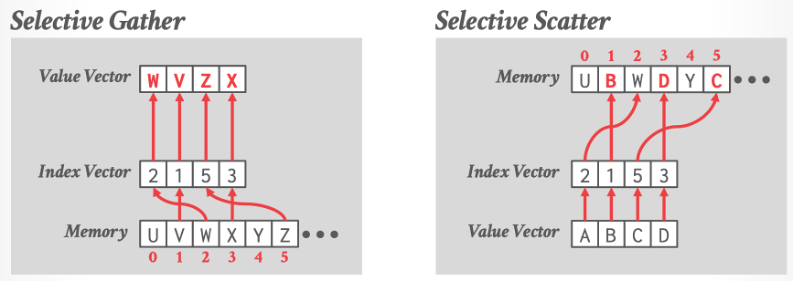
用于重组数据的技术。
选择性聚集从一个数据集中提取满足特定条件的元素,并将它们组合成一个新的、更紧凑的数据集。
选择性散开是选择性聚集的逆操作,它将数据集中的元素根据特定条件分散到一个更大的数据集中。
这两种操作可以提高数据处理效率,特别是在需要对数据进行过滤、合并或分组等操作时。
Make the most out of your SIMD investments: counter control flow divergence in compiled query pipelines
AVX512 降频问题
以下情况不需要担心降频:
- 没有或者较少有浮点运算或整数乘法的指令
- 目标平台不具有512位寄存器
- 对于AVX512,从轻量到重量使用,降频在15%~40%
从Clickhouse看SIMD优化
clickhouse里面针对三种SIMD指令集进行了优化,分别是SSE、AVX、NEON。前面也提到了,这几个指令集用的都是128位寄存器。
#ifdef __SSE2__
#include <emmintrin.h>
#endif#if USE_MULTITARGET_CODE
#include <immintrin.h>
#endif#if defined(__aarch64__) && defined(__ARM_NEON)
# include <arm_neon.h>
# pragma clang diagnostic ignored "-Wreserved-identifier"
#endif
一共在代码里出现了7处。
所以,就算是OLAP这种CPU密集+访存密集型的应用,手写SIMD也只是小部分情况。
memcpy
https://github.com/ClickHouse/ClickHouse/blob/b0eb670776c58af040dc488f1428c313f9eea1ab/base/glibc-compatibility/memcpy/memcpy.h#L97
clickhouse重写了glibc的memcpy,这里作者提到:
- 如果用 -ftree-loop-distribute-patterns可能会导致编译器优化为自带的memcpy,而又会重新调用到重写的memcpy,导致递归调用,所以必须禁用掉。
- 用AVX512有两个问题:一个是降频,第二个是SSE切换AVX512的性能开销。
- 然后作者列了几个影响性能的因素:
- 预取指令,因为预取指令的大小不确定,而且在ARM中性能比较差,所以这里没有预取
- 对齐,这里使用不对齐的加载和对齐的存储
- 循环展开次数,这里固定为8次
- attribute((no_sanitize(“coverage”)))禁用行数统计
- 最后作者提到memcpy可能会在编译时被优化为比较小的其它指令,可以使用-fbuiltin-memcpy或者手动调用__builtin_memcpy来避免
#include <stddef.h>#include <emmintrin.h>/** Custom memcpy implementation for ClickHouse.* It has the following benefits over using glibc's implementation:* 1. Avoiding dependency on specific version of glibc's symbol, like memcpy@@GLIBC_2.14 for portability.* 2. Avoiding indirect call via PLT due to shared linking, that can be less efficient.* 3. It's possible to include this header and call inline_memcpy directly for better inlining or interprocedural analysis.* 4. Better results on our performance tests on current CPUs: up to 25% on some queries and up to 0.7%..1% in average across all queries.** Writing our own memcpy is extremely difficult for the following reasons:* 1. The optimal variant depends on the specific CPU model.* 2. The optimal variant depends on the distribution of size arguments.* 3. It depends on the number of threads copying data concurrently.* 4. It also depends on how the calling code is using the copied data and how the different memcpy calls are related to each other.* Due to vast range of scenarios it makes proper testing especially difficult.* When writing our own memcpy there is a risk to overoptimize it* on non-representative microbenchmarks while making real-world use cases actually worse.** Most of the benchmarks for memcpy on the internet are wrong.** Let's look at the details:** For small size, the order of branches in code is important.* There are variants with specific order of branches (like here or in glibc)* or with jump table (in asm code see example from Cosmopolitan libc:* https://github.com/jart/cosmopolitan/blob/de09bec215675e9b0beb722df89c6f794da74f3f/libc/nexgen32e/memcpy.S#L61)* or with Duff device in C (see https://github.com/skywind3000/FastMemcpy/)** It's also important how to copy uneven sizes.* Almost every implementation, including this, is using two overlapping movs.** It is important to disable -ftree-loop-distribute-patterns when compiling memcpy implementation,* otherwise the compiler can replace internal loops to a call to memcpy that will lead to infinite recursion.** For larger sizes it's important to choose the instructions used:* - SSE or AVX or AVX-512;* - rep movsb;* Performance will depend on the size threshold, on the CPU model, on the "erms" flag* ("Enhansed Rep MovS" - it indicates that performance of "rep movsb" is decent for large sizes)* https://stackoverflow.com/questions/43343231/enhanced-rep-movsb-for-memcpy** Using AVX-512 can be bad due to throttling.* Using AVX can be bad if most code is using SSE due to switching penalty* (it also depends on the usage of "vzeroupper" instruction).* But in some cases AVX gives a win.** It also depends on how many times the loop will be unrolled.* We are unrolling the loop 8 times (by the number of available registers), but it not always the best.** It also depends on the usage of aligned or unaligned loads/stores.* We are using unaligned loads and aligned stores.** It also depends on the usage of prefetch instructions. It makes sense on some Intel CPUs but can slow down performance on AMD.* Setting up correct offset for prefetching is non-obvious.** Non-temporary (cache bypassing) stores can be used for very large sizes (more than a half of L3 cache).* But the exact threshold is unclear - when doing memcpy from multiple threads the optimal threshold can be lower,* because L3 cache is shared (and L2 cache is partially shared).** Very large size of memcpy typically indicates suboptimal (not cache friendly) algorithms in code or unrealistic scenarios,* so we don't pay attention to using non-temporary stores.** On recent Intel CPUs, the presence of "erms" makes "rep movsb" the most beneficial,* even comparing to non-temporary aligned unrolled stores even with the most wide registers.** memcpy can be written in asm, C or C++. The latter can also use inline asm.* The asm implementation can be better to make sure that compiler won't make the code worse,* to ensure the order of branches, the code layout, the usage of all required registers.* But if it is located in separate translation unit, inlining will not be possible* (inline asm can be used to overcome this limitation).* Sometimes C or C++ code can be further optimized by compiler.* For example, clang is capable replacing SSE intrinsics to AVX code if -mavx is used.** Please note that compiler can replace plain code to memcpy and vice versa.* - memcpy with compile-time known small size is replaced to simple instructions without a call to memcpy;* it is controlled by -fbuiltin-memcpy and can be manually ensured by calling __builtin_memcpy.* This is often used to implement unaligned load/store without undefined behaviour in C++.* - a loop with copying bytes can be recognized and replaced by a call to memcpy;* it is controlled by -ftree-loop-distribute-patterns.* - also note that a loop with copying bytes can be unrolled, peeled and vectorized that will give you* inline code somewhat similar to a decent implementation of memcpy.** This description is up to date as of Mar 2021.** How to test the memcpy implementation for performance:* 1. Test on real production workload.* 2. For synthetic test, see utils/memcpy-bench, but make sure you will do the best to exhaust the wide range of scenarios.** TODO: Add self-tuning memcpy with bayesian bandits algorithm for large sizes.* See https://habr.com/en/company/yandex/blog/457612/*/__attribute__((no_sanitize("coverage")))
static inline void * inline_memcpy(void * __restrict dst_, const void * __restrict src_, size_t size)
{/// We will use pointer arithmetic, so char pointer will be used./// Note that __restrict makes sense (otherwise compiler will reload data from memory/// instead of using the value of registers due to possible aliasing).char * __restrict dst = reinterpret_cast<char * __restrict>(dst_);const char * __restrict src = reinterpret_cast<const char * __restrict>(src_);/// Standard memcpy returns the original value of dst. It is rarely used but we have to do it./// If you use memcpy with small but non-constant sizes, you can call inline_memcpy directly/// for inlining and removing this single instruction.void * ret = dst;tail:/// Small sizes and tails after the loop for large sizes./// The order of branches is important but in fact the optimal order depends on the distribution of sizes in your application./// This order of branches is from the disassembly of glibc's code./// We copy chunks of possibly uneven size with two overlapping movs./// Example: to copy 5 bytes [0, 1, 2, 3, 4] we will copy tail [1, 2, 3, 4] first and then head [0, 1, 2, 3].// 不对齐的加载 两个重叠的movsif (size <= 16){if (size >= 8){/// Chunks of 8..16 bytes.__builtin_memcpy(dst + size - 8, src + size - 8, 8);__builtin_memcpy(dst, src, 8);}else if (size >= 4){/// Chunks of 4..7 bytes.__builtin_memcpy(dst + size - 4, src + size - 4, 4);__builtin_memcpy(dst, src, 4);}else if (size >= 2){/// Chunks of 2..3 bytes.__builtin_memcpy(dst + size - 2, src + size - 2, 2);__builtin_memcpy(dst, src, 2);}else if (size >= 1){/// A single byte.*dst = *src;}/// No bytes remaining.}else{// 这里src和dst不可能同时128对齐,因此/// Medium and large sizes.if (size <= 128){/// Medium size, not enough for full loop unrolling./// We will copy the last 16 bytes._mm_storeu_si128(reinterpret_cast<__m128i *>(dst + size - 16), _mm_loadu_si128(reinterpret_cast<const __m128i *>(src + size - 16)));/// Then we will copy every 16 bytes from the beginning in a loop./// The last loop iteration will possibly overwrite some part of already copied last 16 bytes./// This is Ok, similar to the code for small sizes above.while (size > 16){_mm_storeu_si128(reinterpret_cast<__m128i *>(dst), _mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));dst += 16;src += 16;size -= 16;}}else{/// Large size with fully unrolled loop./// Align destination to 16 bytes boundary.size_t padding = (16 - (reinterpret_cast<size_t>(dst) & 15)) & 15;/// If not aligned - we will copy first 16 bytes with unaligned stores.if (padding > 0){__m128i head = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src));_mm_storeu_si128(reinterpret_cast<__m128i*>(dst), head);dst += padding;src += padding;size -= padding;}/// Aligned unrolled copy. We will use half of available SSE registers./// It's not possible to have both src and dst aligned./// So, we will use aligned stores and unaligned loads.__m128i c0, c1, c2, c3, c4, c5, c6, c7;while (size >= 128){c0 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 0);c1 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 1);c2 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 2);c3 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 3);c4 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 4);c5 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 5);c6 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 6);c7 = _mm_loadu_si128(reinterpret_cast<const __m128i*>(src) + 7);src += 128;_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 0), c0);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 1), c1);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 2), c2);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 3), c3);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 4), c4);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 5), c5);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 6), c6);_mm_store_si128((reinterpret_cast<__m128i*>(dst) + 7), c7);dst += 128;size -= 128;}/// The latest remaining 0..127 bytes will be processed as usual.goto tail;}}return ret;
}这里使用了一半的SSE寄存器(8个)来做,可能是考虑到32位平台上只有8个,而64位平台则可以进行展开。
我们同样可以参考一些别的memcpy实现,比如韦易笑的FastMemcpy:
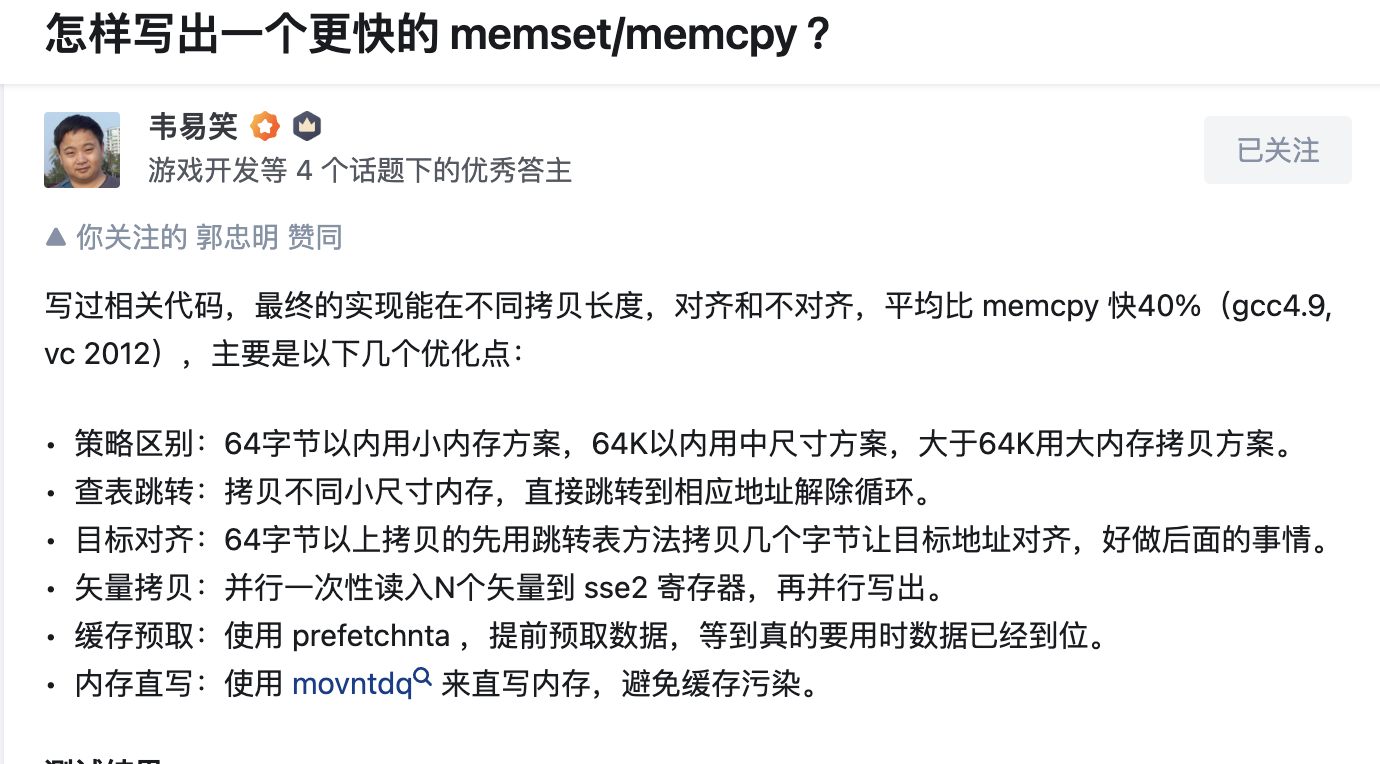
FastMemcpy使用了预取指令,clickhouse里面也有完整代码作为benchmark https://github.com/skywind3000/FastMemcpy/blob/master/FastMemcpy.h

FastMemcpy的问题在于引入了大量的跳转表导致缓存行失效,因此CK并没有将它作为默认的Memcpy实现。
MergeTreeRangeReader
mergetree是clickhouse的列式存储结构,跟ORC很像,不过索引是分开存的(而且没有bloomfilter)。具体可以看:https://bohutang.me/2020/06/26/clickhouse-and-friends-merge-tree-disk-layout/
在读取 ClickHouse 的 MergeTree 表时,首先会对表中的数据进行预过滤,以减少读取的数据量,从而提高查询性能,它将 current_filter 和已有的 final_filter (如果存在)进行组合,创建一个新的过滤条件 filter,这个过滤条件将被应用在每个数据块的开头。
使用向量化的代码在https://github.com/ClickHouse/ClickHouse/blob/4279dd2bf11841d8f68bdea78f3d8668a2c4289b/src/Storages/MergeTree/MergeTreeRangeReader.cpp#L730
这段代码的作用就是计算两个地址之间0位的大小。
使用godbolt分析下:
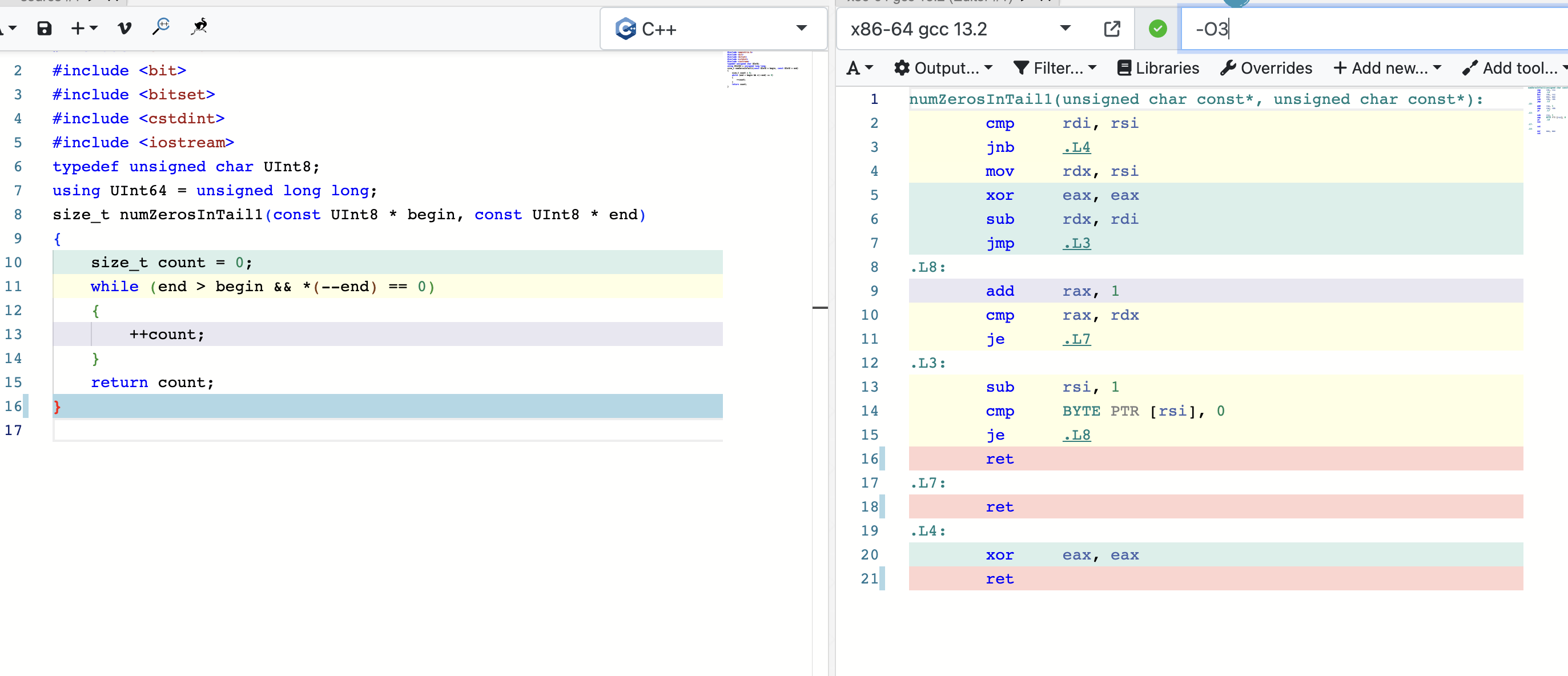
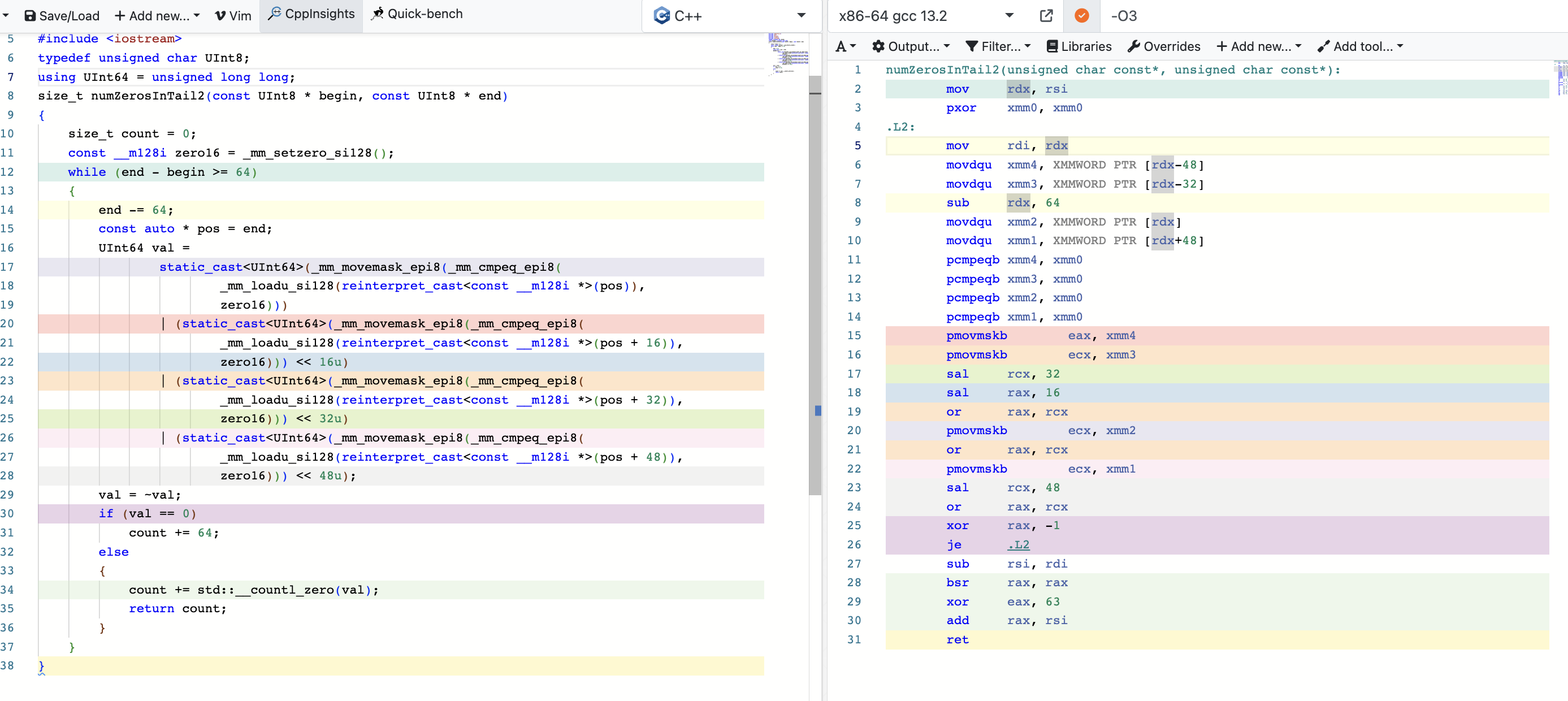
因为是逐位次比较,编译器不知道中间位数的多少,如果引入表跳转会导致缓存行失效的问题,所以编译器只使用普通寄存器进行。
但是在clickhouse场景下,这两个地址之间往往差距很大,所以这里加了分支。
bytes64MaskToBits64Mask
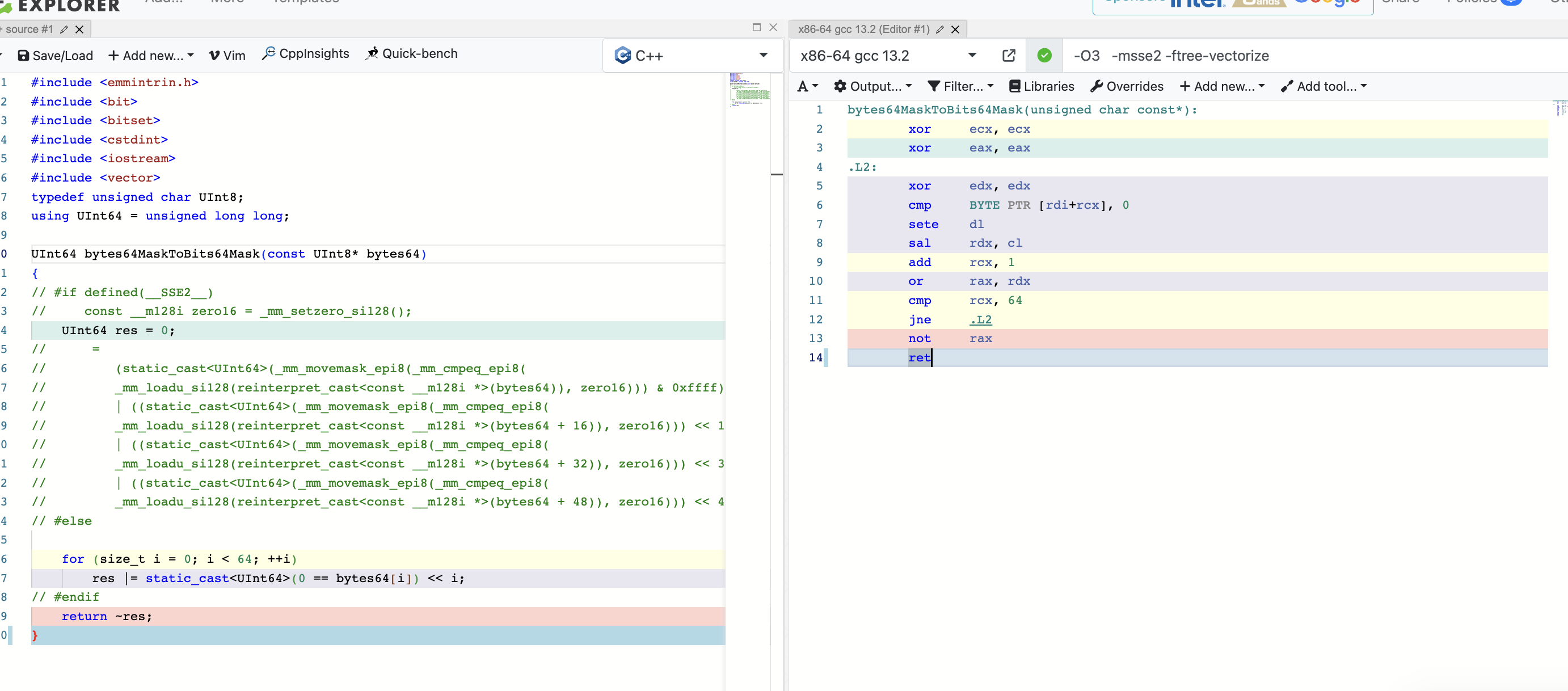
https://github.com/ClickHouse/ClickHouse/blob/fc67d2c0e984098e492c1111c8b5e3c705a80e86/src/Columns/ColumnsCommon.h#L27C1-L27C1
这段代码就很简单,取64*64位的掩码到64位中。
/// Transform 64-byte mask to 64-bit mask
inline UInt64 bytes64MaskToBits64Mask(const UInt8 * bytes64)
{
#if defined(__AVX512F__) && defined(__AVX512BW__)const __m512i vbytes = _mm512_loadu_si512(reinterpret_cast<const void *>(bytes64));UInt64 res = _mm512_testn_epi8_mask(vbytes, vbytes);
#elif defined(__AVX__) && defined(__AVX2__)const __m256i zero32 = _mm256_setzero_si256();UInt64 res =(static_cast<UInt64>(_mm256_movemask_epi8(_mm256_cmpeq_epi8(_mm256_loadu_si256(reinterpret_cast<const __m256i *>(bytes64)), zero32))) & 0xffffffff)| (static_cast<UInt64>(_mm256_movemask_epi8(_mm256_cmpeq_epi8(_mm256_loadu_si256(reinterpret_cast<const __m256i *>(bytes64+32)), zero32))) << 32);
#elif defined(__SSE2__)const __m128i zero16 = _mm_setzero_si128();UInt64 res =(static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64)), zero16))) & 0xffff)| ((static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64 + 16)), zero16))) << 16) & 0xffff0000)| ((static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64 + 32)), zero16))) << 32) & 0xffff00000000)| ((static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64 + 48)), zero16))) << 48) & 0xffff000000000000);
#elif defined(__aarch64__) && defined(__ARM_NEON)const uint8x16_t bitmask = {0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80, 0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80};const auto * src = reinterpret_cast<const unsigned char *>(bytes64);const uint8x16_t p0 = vceqzq_u8(vld1q_u8(src));const uint8x16_t p1 = vceqzq_u8(vld1q_u8(src + 16));const uint8x16_t p2 = vceqzq_u8(vld1q_u8(src + 32));const uint8x16_t p3 = vceqzq_u8(vld1q_u8(src + 48));uint8x16_t t0 = vandq_u8(p0, bitmask);uint8x16_t t1 = vandq_u8(p1, bitmask);uint8x16_t t2 = vandq_u8(p2, bitmask);uint8x16_t t3 = vandq_u8(p3, bitmask);uint8x16_t sum0 = vpaddq_u8(t0, t1);uint8x16_t sum1 = vpaddq_u8(t2, t3);sum0 = vpaddq_u8(sum0, sum1);sum0 = vpaddq_u8(sum0, sum0);UInt64 res = vgetq_lane_u64(vreinterpretq_u64_u8(sum0), 0);
#elseUInt64 res = 0;for (size_t i = 0; i < 64; ++i)res |= static_cast<UInt64>(0 == bytes64[i]) << i;
#endifreturn ~res;
}
这里无论我用STL容器还是指针,加什么编译选项,GCC都无法优化为SIMD指令,Clang的优化效果也不好,所以我们可以看出,编译器对SIMD的支持大部分情况不如手写的好。
相关文章:
从微架构到向量化--CPU性能优化指北
引入 定位程序性能问题,相信大家都有很多很好的办法,比如用top/uptime观察负载和CPU使用率,用dstat/iostat观察io情况,ptrace/meminfo/vmstat观察内存、上下文切换和软硬中断等等,但是如果具体到CPU问题,我…...

声声入耳,事事如意 爱可声「如意」助听器即将上市!
如意助听器 Charm 爱可声全新系列「如意」助听器即将上市! 此次新品充分考虑了不同听损以及年龄的用户需求, 融合三大强劲性能。 1、多群体覆盖,定制个性化方案 如意助听器针对不同听损程度的听障患者设计了不同款式助听器,贴…...

生物实验室设备文件采集如何才能质量和效率双管齐下?
生物实验室的设备文件采集是实验室运营、科研活动和数据科学实践应用中不可或缺的一环。通过数据采集,实验室可以优化资源配置、提高实验结果的准确性和可靠性、支持科研水平的提升,并确保数据的安全性和可追溯性。因此,实验室应高度重视设备…...

Framework源码整编、单编、烧录过程
目录 一.背景 二.整编方式 二.单编方式 三.烧录 一.背景 源码编译分为整编和单编,整编通常耗时较长,单编则速度很多,如果我们进行一个小的修改想要立马验证的话单编就很合适 二.整编方式 开始执行编译操作,总共三步. 执行source操作source build/envsetup.sh .执行lunc…...

TypeScript类型断言
TypeScript类型断言是TypeScript中一个强大且有用的特性,它允许开发者在编译时明确指定一个值的类型,即使TypeScript无法自动推断出这个类型。类型断言类似于其他编程语言中的类型转换,但它不会改变变量的运行时值,而只是告诉编译…...
Mallet:一款针对任意协议的安全拦截代理工具
关于Mallet Mallet是一款功能强大的协议安全分析工具,该工具支持针对任意协议创建用于安全审计的拦截代理,该工具本质上与我们所熟悉的拦截Web代理类似,只是通用性更强。 工具运行机制 Mallet建立在Netty框架之上,并且依赖于Net…...

【IEEE出版】第五届大数据、人工智能与软件工程国际研讨会(ICBASE 2024,9月20-22)
第五届大数据、人工智能与软件工程国际研讨会(ICBASE 2024)将于2024年09月20-22日在中国温州隆重举行。 会议主要围绕大数据、人工智能与软件工程等研究领域展开讨论。会议旨在为从事大数据、人工智能与软件工程研究的专家学者、工程技术人员、技术研发人…...

自修室预约小程序的设计
管理员账户功能包括:系统首页,个人中心,学生管理,公告通知管理,自修室管理,座位预约管理,预约取消管理,管理员管理,系统管理 微信端账号功能包括:系统首页&a…...
用于跟踪个人图书馆的BookLogr
什么是 BookLogr ? BookLogr 是一款网络应用,旨在帮助您轻松管理个人图书馆。这项自托管服务可确保您完全控制数据,提供安全且私密的方式来跟踪您拥有、阅读或希望阅读的所有书籍。您也可以选择向公众自豪地展示您的图书馆,与您的…...

深入解析JVM垃圾回收机制:Full GC、Minor GC与Major GC
目录 引言垃圾回收的基本概念 什么是垃圾回收GC的分类JVM内存模型 堆内存非堆内存Minor GC 触发条件运行机制对性能的影响...

Windows10点击文件夹右键卡死的解决办法
1、首先同时按下【WinR】打开运行页面,输入命令【regedit】按下回车或者点击确定。 2、打开注册表编辑器后,定位到如下位置“HKEY_CLASSES_ROOT\Directory\Background\Shellex\ContextMenuHandlers”。 3、然后在其中将所有名为“New”的文件或项全部删…...

C# 设计模式之单例模式
总目录 前言 本文是个人基于C#学习设计模式总结的学习笔记,希望对你有用! 1 基本介绍 定义:确保一个类只有一个实例,并提供一个全局访问点。 本质就是保证在整个应用程序的生命周期中,任何一个时刻,单例…...

【组合数学】【Python】【小练习】一、斯特灵近似式求阶乘
一、问题介绍 斯特灵(Stirling)近似式,是数学分析中,用于求阶乘近似值的一个常用公式,其简单的表述形式为: 二、Python实现 使用Python,循环从n1至n98,分别输出n的阶乘值、斯特灵公…...

【IEEE Fellow特邀报告,JPCS独立出版】第四届电子通信与计算机科学技术国际学术会议(ECCST 2024,9月20-22)
2024年第四届电子通信与计算机科学技术国际学术会议将于2024年9月20-22日在中国上海举行。 会议旨在为从电子与通信、网络、人工智能与计算机技术研究的专家学者、工程技术人员、技术研发人员提供一个共享科研成果和前沿技术,了解学术发展趋势,拓宽研究思…...

DockerCompose部署示例
目录 前言 1. 初识DockerCompose 2. 安装DockerCompose 3. 部署微服务项目 1)找一个目录,创建一个新的cloud-demo文件夹。 2)在cloud-demo文件夹创建一个docker-compose.yml文件,然后编写下面内容: 3)…...

【云原生】Helm来管理Kubernetes集群的详细使用方法与综合应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

电源插头应该统一方向
大家在使用插排的时候就会发现,有的横向,有的竖向。 国家强制规定,统一方向,插排能方便使用。...

大学新生编程入门最佳攻略
引言 编程的重要性:简述编程在当今社会的地位,为何它是大学生的必备技能。目标设定:明确文章旨在帮助新生从零基础开始,逐步成长为编程高手。 方向一:编程语言选择 1. 编程语言概览 介绍几种流行语言:如…...

MySQL 的binlog 、undolog 、redolog
Binlog (二进制日志) bin Log 作用 用于记录所有修改数据库数据的 SQL 语句或行级别的变化,主要用于主从复制和数据恢复。 binlog格式 STATEMENT模式:binlog里面记录的就是SQL语句的原文。优点是并不需要记录每一行的数据变化,减少了binlo…...

【计算机网络】三次握手、四次挥手
问:三次握手 四次挥手 TCP 连接过程是 3 次握手,终止过程是 4 次挥手 3次握手 第一步:客户端向服务器发送一个带有 SYN(同步)标志的包,指示客户端要建立连接。 第二步:服务器收到客户端的请求…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...