【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)

一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks),共计覆盖32万个模型。

今天介绍Audio的第三篇,文本转音频(text-to-audio/text-to-speech),在huggingface库内共有1978个音频分类模型,其中1141个是由facebook生成的不同语言版本,其他公司发布的仅有837个。
二、文本转音频(text-to-audio/text-to-speech)
2.1 概述
文本转音频(TTS),与上一篇音频转文本(STT)是对称技术,给定文本生成语音,实际使用上,更多与语音克隆技术相结合:先通过一段音频(few-show)进行声音克隆,再基于克隆的音色和文本生成语音。应用场景极多,也是人工智能领域最易看到成果的技术,主要应用场景有读文章、音乐生成、短视频智能配音、游戏角色智能配音等。

2.2 技术原理
2.2.1 原理概述
当前比较流行的做法还是基于transformer对文本编码与声音编码进行对齐,声音方面先产生一个对数梅尔频谱图,再使用一个额外的神经网络(声码器)转换为波形。

模型类别上,以suno/bark为代表的语音生成和以xtts为代表的声音克隆+语音生成各占据半壁江山,使用比较多的模型如下
2.2.2 语音生成(zero-shot)
- suno/bark:suno出品,天花板,支持笑容、男女声设定、音乐设定等。支持pipeline
- 2noise/ChatTTS:国产品牌,突破天花板。不支持pipeline,需要下载项目包
- BytedanceSpeech/seed-tts-eval:字节出品。不支持pipeline,需要下载项目包
2.2.3 声音克隆+语音生成(few-shot)
- coqui/XTTS-v2:酷趣青蛙,几秒的语音样本即可完成克隆。支持pipeline生成,但克隆需要使用pypi的TTS包
- fishaudio/fish-speech-1.2:鱼语,国产,同样几秒的语音样本即可完成克隆。支持pipeline生成,但克隆需要下载项目。
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
( *args, vocoder = None, sampling_rate = None, **kwargs )
2.3.2 pipeline对象使用参数
- text_inputs(
str或List[str])——要生成的文本。- forward_params(
dict,可选)— 传递给模型生成/转发方法的参数。forward_params始终传递给底层模型。- generate_kwargs(
dict,可选generate_config)—用于生成调用的临时参数化字典。
2.3.3 pipeline对象返回参数
- audio(
np.ndarray形状(nb_channels, audio_length))——生成的音频波形。- samples_rate (
int) — 生成的音频波形的采样率。
2.4 pipeline实战
2.4.1 suno/bark-small(默认模型)
pipeline对于text-to-audio/text-to-speech的默认模型是suno/bark-small,使用pipeline时,如果仅设置task=text-to-audio或task=text-to-speech,不设置模型,则下载并使用默认模型。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"import scipy
from IPython.display import Audio
from transformers import pipeline
pipe = pipeline("text-to-speech")
result = pipe("Hello, my dog is cooler than you!")
sampling_rate=result["sampling_rate"]
audio=result["audio"]
print(sampling_rate,audio)
scipy.io.wavfile.write("bark_out.wav", rate=sampling_rate, data=audio)
Audio(audio, rate=sampling_rate)可以将文本转换为语音bark_out.wav。
bark支持对笑声、男女、歌词、强调语气等进行设定,直接在文本添加:
[laughter][laughs][sighs][music][gasps][clears throat]—或...犹豫♪歌词- 大写以强调单词
[MAN]并[WOMAN]分别使 Bark 偏向男性和女性说话者
同时,pipeline可以指定任意的模型,模型列表参考TTS模型库。
2.4.2 coqui/XTTS-v2语音克隆
参考官方文档:可以使用python或命令行2种方式轻松使用model_list内的模型,优先要安装TTS的pypi包:
pip install TTS -i https://mirrors.cloud.tencent.com/pypi/simple2.4.2.1 语音转换(参考语音,将语音生成语音)
python版本:
import torch
from TTS.api import TTS# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"# List available 🐸TTS models
print(TTS().list_models())# Init TTS
tts = TTS(model_name="voice_conversion_models/multilingual/vctk/freevc24", progress_bar=False).to("cuda")
tts.voice_conversion_to_file(source_wav="my/source.wav", target_wav="my/target.wav", file_path="output.wav")命令行版本:
tts --out_path ./speech.wav --model_name "tts_models/multilingual/multi-dataset/xtts_v2" --source_wav "./source_wav.wav" --target_wav "./target_wav.wav"2.4.2.2 文字转语音(参考语音,将文字生成语音)
python版本:
import torch
from TTS.api import TTS# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"# List available 🐸TTS models
print(TTS().list_models())# Init TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)# Run TTS
# ❗ Since this model is multi-lingual voice cloning model, we must set the target speaker_wav and language
# Text to speech list of amplitude values as output
wav = tts.tts(text="Hello world!", speaker_wav="my/cloning/audio.wav", language="en")
# Text to speech to a file
tts.tts_to_file(text="Hello world!", speaker_wav="my/cloning/audio.wav", language="en", file_path="output.wav")tts = TTS("tts_models/de/thorsten/tacotron2-DDC")
tts.tts_with_vc_to_file("Wie sage ich auf Italienisch, dass ich dich liebe?",speaker_wav="target/speaker.wav",file_path="output.wav"
)命令行版本:
$ tts --text "Text for TTS" --model_name "<model_type>/<language>/<dataset>/<model_name>" --target_wav <path/to/reference/wav> --out_path output/path/speech.wav2.5 模型排名
在huggingface上,我们筛选自动语音识别模型,并按近期热度从高到低排序:

看起来有1978个,实际上有1141是由facebook生成的不同语言版本,其他公司发布的仅有837个:

三、总结
本文对transformers之pipeline的文本生成语音(text-to-audio/text-to-speech)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline以及tts的python和命令行工具完成文字生成语音、文字参考语音生成语音、语音参考语音生成语音,应用于有声小说、音乐创作、变音等非常广泛的场景。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)
相关文章:
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)
一、引言 pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理&#x…...

前端入门知识分享:HTML 页面中 head 标签之间的代码详解
前端入门知识分享:HTML 页面中 head 标签之间的代码详解 在HTML代码中HEAD之间的代码就是网页头元素,里面的内容不会显现在网页中,因此很容易被别人遗忘,但它对网页的渲染和功能性至关重要。如果能够掌握它的概念和使用方法&#…...
【Spring Boot】手撕搜索引擎项目,深度复盘在开发中的重难点和总结(长达两万6千字的干货,系好安全带,要发车了......)
目录 搜索引擎搜索引擎的核心思路 一、解析模块1.1 枚举所有文件1.2 解析每个文件的标题,URL以及正文1.2.1 解析标题1.2.2 解析URL1.2.3 解析正文 1.3 线程池优化代码 二 、创建排序模块2.1 构建正排索引2.2 构建倒排索引2.3 序列化2.4 反序列化 三、搜索模块3.1 引…...
—— 接口测试什么时候介入)
测试面试宝典(四十二)—— 接口测试什么时候介入
回答一: 接口测试通常在项目开发的早期阶段就可以介入。一般来说,在接口定义和设计完成后,开发人员开始进行接口的初步实现时,测试人员就可以着手进行接口测试了。比如,在需求分析和评审阶段,明确了接口的功…...
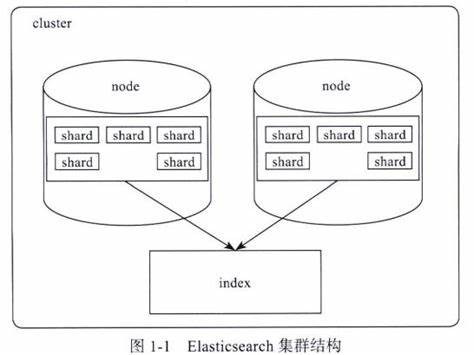
【Elasticsearch】Elasticsearch的分片和副本机制
文章目录 📑前言一、分片(Shard)1.1 分片的定义1.2 分片的重要性1.3 分片的类型1.4 分片的分配 二、副本(Replica)2.1 副本的定义2.2 副本的重要性2.3 副本的分配 三、分片和副本的机制3.1 分片的创建和分配3.2 数据写…...

鸿蒙开发入门指南
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 引言 一、鸿蒙系统概述 1.1 简介 1.2 鸿蒙开发的优势 二、鸿蒙开发环境搭建 2.1 安装鸿蒙DevEco Studi…...
从分散到整合,细说比特币发展史
原文标题:《Layered Bitcoin》 撰文:Saurabh Deshpande 编译:Chris,Techub News 古往今来,货币在社会中都具有三个关键的功能:财富的储存手段、交换媒介和计量单位。虽然货币的形式在不断变化,…...

TreeSelect增加可筛选功能
TreeSelect官方可筛选示例 <template><el-tree-selectv-model"value":data"data"filterablestyle"width: 240px"/><el-divider /><el-divider />filter node method:<el-tree-selectv-model"value":data&q…...

星环科技与宁夏银行“大数据联合实验室”揭牌,持续打造金融科技新范式
5月30-31日,2024向星力未来数据技术峰会期间,在峰会现场来宾共同见证下,星环科技与宁夏银行“大数据联合实验室”正式揭牌,宁夏银行股份有限公司首席信息官崔彦刚与星环科技副总裁邱磊共同为联合实验室揭牌。 星环科技与宁夏银行借…...

React native页面突然白屏
背景:某个时间段突然收到破100的用户反馈,商品详情(React native页面)打不开,一片空白,无法正常使用 设备:部分华为手机Harmoney4.0,华为相关Android系统 可临时恢复方案ÿ…...

一段直接路径读取文件LINUX C代码
最近搞个MYBATIS-PLUS里面的MAPPER DAO方法审计.就是把里面的SQL提取出来,然后使用SQL质量工具进行审计! SQLE 在这方面功能强大,就是细节不够完美,它有SCANDR工具可以把某个目录下XML文件扫描并上传到SQLE里面进行审计. 通过自由裁剪的MYSQL 审核规则,一条条SQL进行! 问题是那…...

Android让所有APK横屏显示
在Android6.0.1里面,Box产品的HDMI输出都是以横屏显示,而有些APK会申请竖屏显示,此时通过修改frameworks/base/services/core/java/com/android/server/wm/WindowManagerService.java文件里面的updateRotationUncheckedLocked函数的如下语句&…...

【智能制造-26】PLC标准-SICAR
什么是SICAR? SICAR 是西门子基于 TIA Portal 的汽车行业自动化标准。 SICAR 标准具有以下特点和优势: 提供了统一的硬件和软件标准,以及统一的接口。涵盖了从 PLC 程序、HMI 画面到特定工艺功能块(如机器人、阀岛、视觉系统等&…...

浅学爬虫-处理复杂网页
在处理实际项目时,网页通常比示例页面复杂得多。我们需要应对分页、动态加载和模拟用户行为等问题。以下是一些常见的场景及其解决方案。 处理分页 许多网站将内容分成多个页面,称为分页。要抓取这些数据,需要编写一个能够遍历所有分页的爬…...

nginx反向代理严重错误[crit] (13: Permission denied) while reading upstream问题
nginx作为使用最广泛的一款反向代理软件,其性能也是非常优秀的,一般情况下,直接配置就可以使用,而且也都是稳定高效的,但是在实际应用中,对于不同的应用场景,总是会出现各种各样的问题ÿ…...

精通Python爬虫中的XPath:从安装到实战演示
🔸 插件安装 首先,我们需要安装用于处理XPath的库lxml。在命令行中运行以下命令: pip install lxml🔹 lxml是一个强大的库,支持XPath查询和XML处理,是爬虫开发中的重要工具。 🔸 DOM节点学习 …...

redis的使用场景
目录 1. 热点数据缓存 1.1 什么是缓存? 1.2 缓存的原理 1.3 什么样的数据适合放入缓存中 1.4 哪个组件可以作为缓存 1.5 java使用redis如何实现缓存功能 1.5.1 需要的依赖 1.5.2 配置文件 1.5.3 代码 1.5.4 发现 1.6 使用缓存注解完成缓存功能 2. 分布式锁…...
的各种方法以及时间差的计算方法)
记录new Date()的各种方法以及时间差的计算方法
new Date().toLocaleDateString() —— 2024/8/2new Date().toLocaleTimeString() —— 10:21:48new Date().toLocaleString() —— 2024/8/2 10:21:48new Date().toLocaleDateString() —— Fri Aug 02 2024new Date().toDateString() —— Fri Aug 02 2024new Date…...
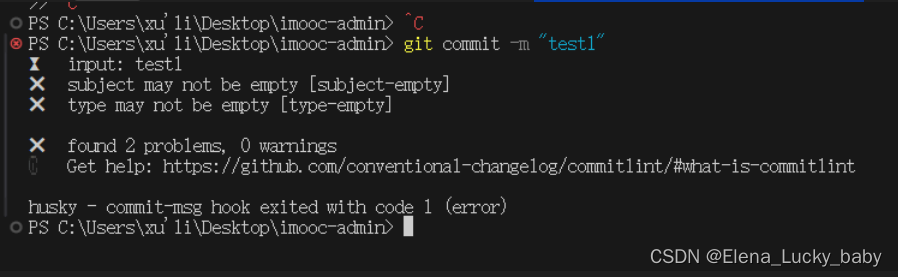
vue项目创建+eslint+Prettier+git提交规范(commitizen+hooks+husk)
# 步骤 1、使用 vue-cli 创建项目 这一小节我们需要创建一个 vue3 的项目,而创建项目的方式依然是通过 vue-cli 进行创建。 不过这里有一点大家需要注意,因为我们需要使用最新的模板,所以请保证你的 vue-cli 的版本在 4.5.13 以上ÿ…...

从Docker拉取镜像一直失败超时?这些解决方案帮你解决烦恼
设置国内源: 提示:常规方案(作用不大) 阿里云提供了镜像源:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors 登录后你会获得一个专属的地址 使用命令设置国内镜像源:通过vim /etc/docker/d…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...
6.9-QT模拟计算器
源码: 头文件: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QMouseEvent>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr);…...