每日学术速递8.2
1.A Scalable Quantum Non-local Neural Network for Image Classification

标题: 用于图像分类的可扩展量子非局部神经网络
作者: Sparsh Gupta, Debanjan Konar, Vaneet Aggarwal
文章链接:https://arxiv.org/abs/2407.18906
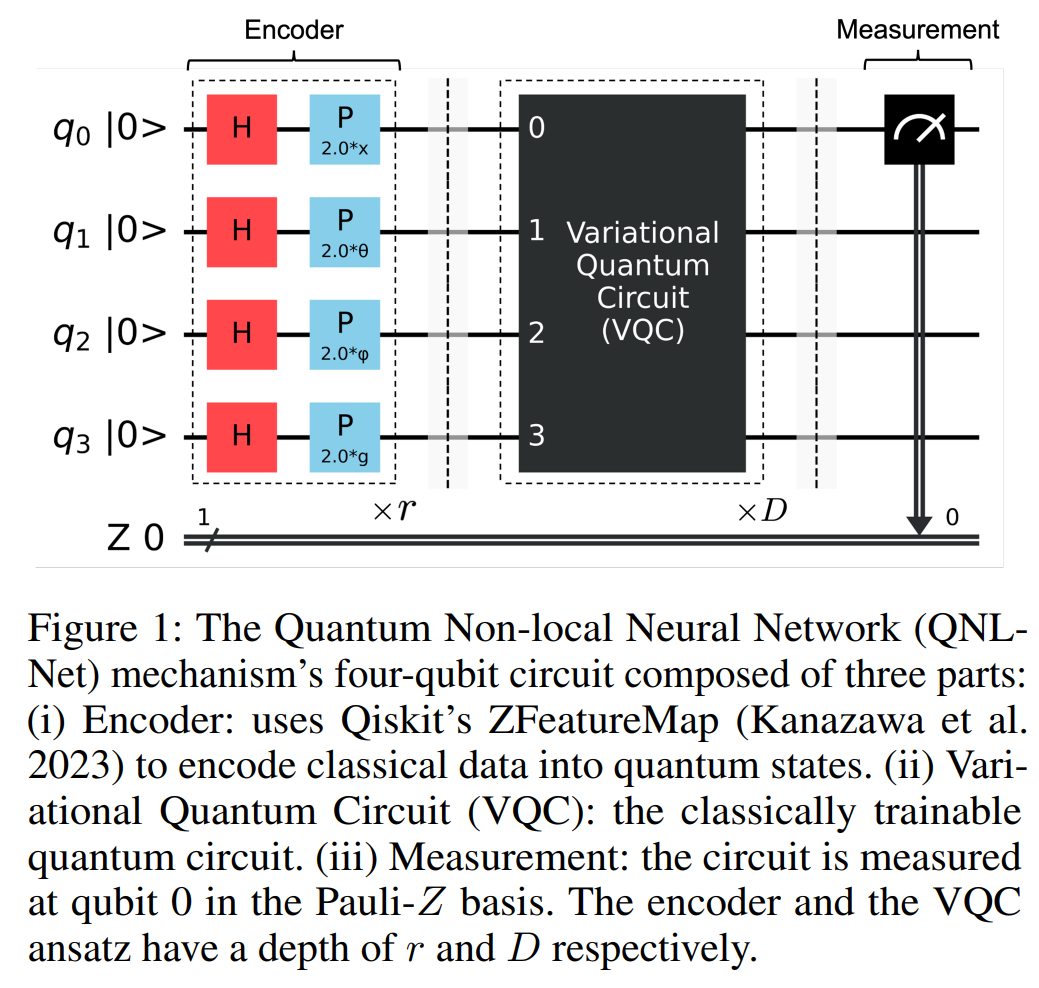
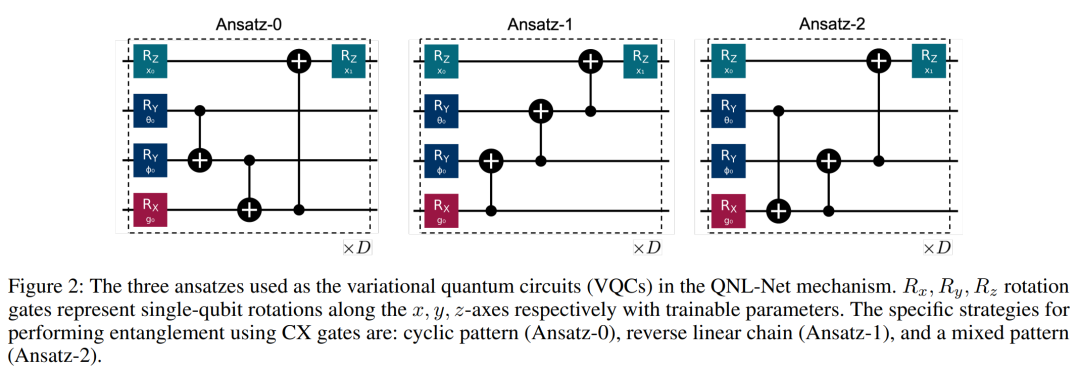

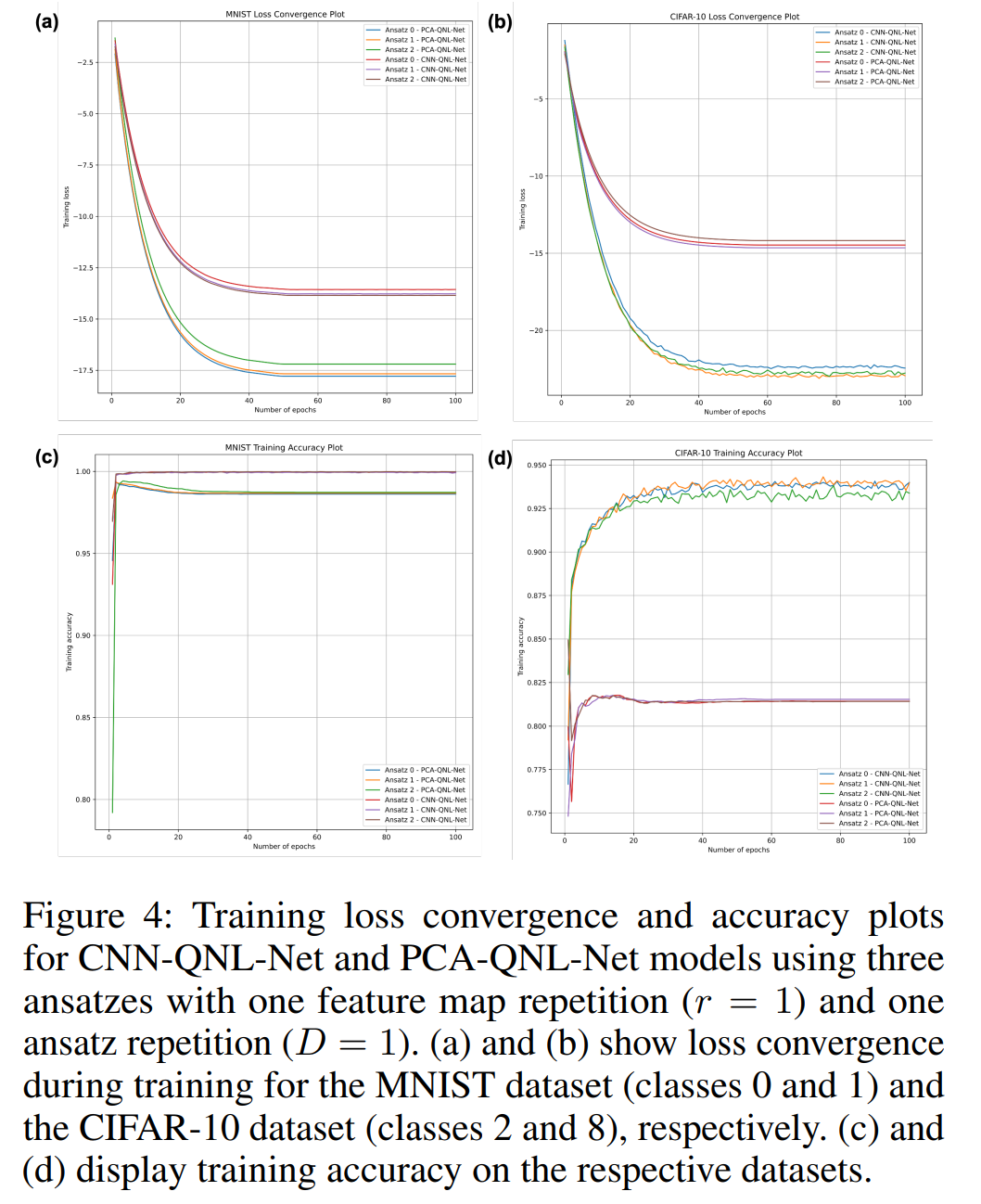
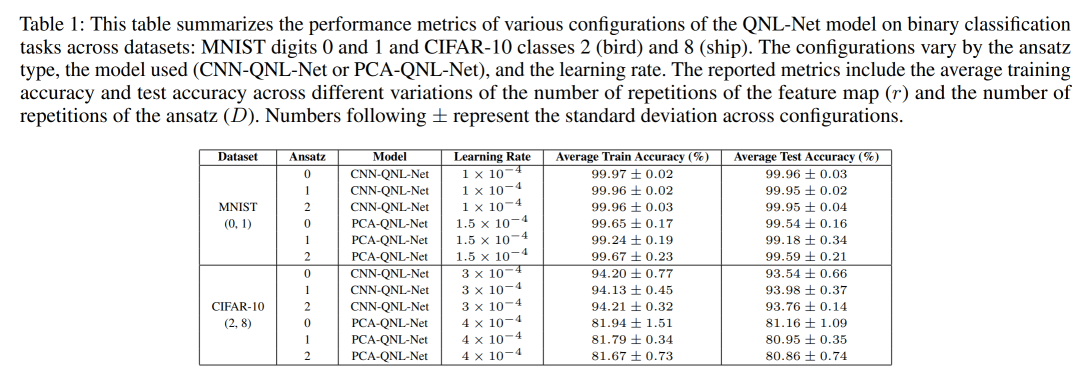
摘要:
非局部运算在计算机视觉中发挥着至关重要的作用,能够通过输入特征的加权和来捕获远程依赖关系,超越了仅关注局部邻域的传统卷积运算的限制。非局部操作通常需要计算集合中所有元素之间的成对关系,从而导致时间和内存方面的复杂度呈二次方。由于计算和内存需求较高,将非局部神经网络扩展到大规模问题可能具有挑战性。本文介绍了一种混合量子经典可扩展非局部神经网络,称为量子非局部神经网络(QNL-Net),以增强模式识别。所提出的 QNL-Net 依靠固有的量子并行性来允许同时处理大量输入特征,从而在量子增强特征空间中实现更高效的计算,并通过量子纠缠涉及成对关系。我们将我们提出的 QNL-Net 与其他量子对应物进行基准测试,以使用数据集 MNIST 和 CIFAR-10 进行二元分类。模拟结果表明,我们的 QNL-Net 在利用更少的量子位的同时,在量子分类器中的二值图像分类中实现了最先进的准确度水平。
这篇论文试图解决什么问题?
这篇论文介绍了一种名为量子非局域神经网络(Quantum Non-Local Neural Network, QNL-Net)的混合量子-经典可扩展非局域神经网络,旨在解决以下几个问题:
-
非局域操作的计算复杂性:传统的非局域操作需要计算输入集中所有元素之间的成对关系,导致时间和内存复杂度呈二次方增长。这限制了非局域神经网络在大规模问题上的应用。
-
量子计算的利用:量子机器学习(Quantum Machine Learning, QML)是一个新兴领域,利用量子力学原理来增强机器学习。量子计算的量子并行性和量子纠缠特性理论上可以加速计算,解决传统计算中可能成本高昂且效率低下的问题。
-
量子与经典计算的结合:论文提出了一种混合量子-经典的方法,通过量子电路作为核心算法,结合经典优化技术,以提高模型的训练效率和性能。
-
图像分类任务中的长距离依赖捕获:在计算机视觉中,图像分类是一个关键任务,传统的卷积神经网络(CNNs)受限于局部感受野,难以捕获图像中的全局上下文和长距离依赖。非局域神经网络通过计算所有位置的加权和来解决这个问题。
-
量子硬件的局限性:尽管量子计算提供了理论上的优势,但当前的量子硬件仍处于嘈杂中等规模量子(Noisy Intermediate-Scale Quantum, NISQ)时代,存在容错能力和量子错误校正技术的不足,限制了量子算法的实际应用。
通过提出QNL-Net,论文试图提高模式识别和二元分类任务的性能,通过更有效地捕获数据中的长距离依赖,同时利用量子力学的优势来增强机器学习的性能和能力
论文如何解决这个问题?
论文通过提出一个名为量子非局域神经网络(Quantum Non-Local Neural Network, QNL-Net)的混合量子-经典模型来解决上述问题。以下是论文中提出的解决方案的关键点:
-
量子非局域操作的实现:QNL-Net利用量子电路来实现非局域操作,这些操作能够有效地捕获输入数据中的长距离依赖性。
-
量子与经典计算的结合:QNL-Net采用了混合量子-经典的方法,其中量子电路作为核心算法,而参数的优化则使用经典方法。这种方法结合了量子计算的高并行性和经典计算的优化能力。
-
量子电路的设计:论文设计了可训练的量子电路(Variational Quantum Circuits, VQCs),这些电路可以被经典算法优化,以实现量子态的精细控制。
-
量子纠缠的利用:通过量子纠缠,QNL-Net能够在量子比特之间建立非局域相关性,这模仿了经典非局域操作中的行为。
-
特征空间的量子增强:使用Qiskit的ZFeatureMap将经典数据编码到量子态中,利用量子增强的特征空间来提升分类问题的性能。
-
维度和特征的降维:在将数据输入到QNL-Net之前,使用经典机器学习技术(如CNN或PCA)进行特征的降维和提取。
-
模型的可扩展性和定制性:QNL-Net的设计允许它根据具体问题进行扩展和定制,以适应不同的应用场景。
-
性能评估:通过在MNIST和CIFAR-10等标准数据集上的基准测试,展示了QNL-Net在二元图像分类任务中的性能,特别是在使用较少量子比特的情况下。
-
鲁棒性分析:论文还评估了QNL-Net在不同条件下的鲁棒性,包括不同数量的特征映射重复和量子电路重复。
通过这些方法,QNL-Net旨在提高图像分类任务中的模式识别能力,同时减少所需的量子资源,为量子增强型机器学习应用提供了一个可扩展的解决方案。
论文做了哪些实验?
论文中进行了一系列的实验来评估和展示QNL-Net(量子非局域神经网络)的性能。以下是实验的主要方面:
-
数据集选择:实验使用了两个广泛使用的图像处理数据集:MNIST和CIFAR-10。MNIST数据集用于数字0和1的二元分类,而CIFAR-10数据集用于类别2(鸟类)和8(船只)的二元分类。
-
模型配置:实验探索了不同的模型配置,包括不同的特征映射重复次数(r = 1, 2, 或 3)和量子电路(ansatz)重复次数(D = 1, 2, 或 3)。
-
性能度量:实验报告了每种特定ansatz和模型配置的平均训练精度和测试精度。这些精度是通过对所有运行进行平均得出的。
-
模型比较:实验比较了CNN-QNL-Net和PCA-QNL-Net两种模型的性能。CNN-QNL-Net模型在MNIST数据集上表现出略高于PCA-QNL-Net模型的性能,达到了接近完美的平均分类测试精度99.96%,而PCA-QNL-Net的测试精度为99.59%。
-
训练和测试精度:实验记录了不同模型在训练和测试数据集上的精度,以及不同ansatz配置下的表现。
-
损失函数和优化器:使用了负对数似然(NLL)损失函数和Adam优化器进行模型训练,配置了不同的学习率。
-
训练周期:模型训练了100个周期,使用批量大小为1。
-
学习率调度:使用了指数学习率调度器来调整学习率,以加快收敛。
-
性能对比:将QNL-Net模型的结果与相关工作中讨论的其他量子二元分类模型进行了比较,特别是在MNIST数据集上。
-
训练损失和精度曲线:展示了CNN-QNL-Net和PCA-QNL-Net模型在训练过程中的损失收敛和精度曲线。
-
硬件和软件环境:实验在配备M2 Max芯片和64GB RAM的MacBook Pro上进行,使用了Qiskit Machine Learning和PyTorch等工具。
这些实验结果不仅展示了QNL-Net在图像分类任务中的有效性,而且还证明了其在量子资源利用和性能上的潜在优势。
论文的主要内容:
这篇论文提出了一种新型的量子非局域神经网络(Quantum Non-Local Neural Network, QNL-Net),旨在通过结合量子计算的优势来提升图像分类任务中的模式识别能力。以下是论文的主要内容总结:
-
问题背景:传统的非局域神经网络虽然能够捕获图像中的长距离依赖性,但其计算复杂性高,难以扩展到大规模问题。量子机器学习(QML)提供了一种新的方法,利用量子力学原理来加速计算和提高效率。
-
QNL-Net介绍:论文提出了QNL-Net,这是一个混合量子-经典的神经网络模型,利用量子并行性和量子纠缠来处理非局域操作,以提高计算效率。
-
量子电路设计:QNL-Net使用了可训练的量子电路(Variational Quantum Circuits, VQCs),这些电路结合了不同的量子门和纠缠策略,以实现对输入数据的非局域处理。
-
混合模型架构:QNL-Net与经典机器学习技术结合,如卷积神经网络(CNN)和主成分分析(PCA),用于特征提取和降维。
-
性能评估:通过在MNIST和CIFAR-10数据集上的实验,论文展示了QNL-Net在二元分类任务中的高准确性,并与现有的量子分类器进行了比较。
-
实验结果:实验结果显示,QNL-Net在使用较少量子比特的情况下,达到了与或超过了其他量子分类器的性能水平。
-
挑战与局限性:尽管取得了积极的结果,但论文也指出了QNL-Net在多类别分类、处理更大规模数据集的效率以及对经典预处理方法的依赖等方面的局限性。
-
未来工作:论文提出了未来研究的方向,包括探索新的量子编码策略、优化量子电路设计、提高模型的可解释性以及将QNL-Net应用于实际问题。
-
结论:QNL-Net展现了量子增强型机器学习应用的潜力,并为量子计算在实际应用中的使用奠定了基础。
论文通过提出QNL-Net,不仅在理论上探索了量子计算在机器学习领域的应用,而且在实际的数据集上验证了其有效性,为未来的量子机器学习研究提供了新的思路和方法。
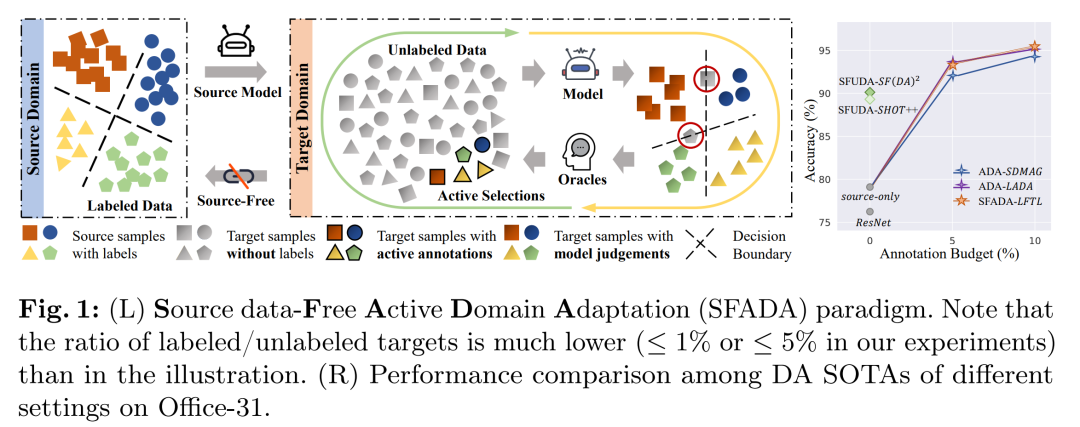
2.Learn from the Learnt: Source-Free Active Domain Adaptation via Contrastive Sampling and Visual Persistence

标题:吸取经验教训:通过对比采样和视觉持久性实现无源主动域适应
作者: Mengyao Lyu, Tianxiang Hao, Xinhao Xu, Hui Chen, Zijia Lin, Jungong Han, Guiguang Ding
文章链接:https://arxiv.org/abs/2407.18899
项目代码:https://github.com/lyumengyao/lftl

摘要:
领域适应 (DA) 促进知识从源领域转移到相关目标领域。本文研究了一种实用的 DA 范式,即无源数据主动域适应(SFADA),其中源数据在适应过程中变得不可访问,并且目标域中可用的注释预算最少。在不参考源数据的情况下,在识别信息最丰富的目标样本进行标记、在适应过程中建立跨域对齐以及通过迭代查询和适应过程确保持续性能改进等方面出现了新的挑战。作为回应,我们提出了从学习中学习(LFTL),这是 SFADA 的一种新颖范式,可以利用从源预训练模型和主动迭代模型中学到的知识,而无需额外的开销。我们提出对比主动采样来从前面模型的假设中学习,从而查询既能为当前模型提供信息又在主动学习过程中持续具有挑战性的目标样本。在适应过程中,我们从以前的中间模型获得的主动选择的锚点的特征中学习,以便视觉持久引导的适应可以促进特征分布对齐和主动样本利用。对三个广泛使用的基准进行的大量实验表明,我们的 LFTL 实现了最先进的性能、卓越的计算效率,并随着注释预算的增加而不断改进。
这篇论文试图解决什么问题?
这篇论文研究了一个名为Source-Free Active Domain Adaptation (SFADA)的实际领域适应范式。在SFADA中,源数据在适应过程中变得不可访问,同时目标领域只有很少量的标注预算。该论文解决的问题包括:
-
目标样本的选择:在没有源数据参考的情况下,如何识别目标领域中最有信息量、最有助于当前模型学习并在整个主动学习过程中持续具有挑战性的样本。
-
跨领域对齐:在没有源数据的情况下,如何建立源域和目标域之间的对齐,以促进特征分布的一致性。
-
迭代查询与适应过程的持续性能改进:如何利用新获得的知识,同时巩固在适应过程中学到的领域不变信息,并确保随着标注预算的增加,模型性能能够持续改进。
为了应对这些挑战,论文提出了一种名为"Learn from the Learnt" (LFTL)的新范式,通过对比采样和视觉持久性引导的适应方法,利用从源预训练模型和主动迭代模型中学到的知识,以最小的额外开销实现领域适应。
论文如何解决这个问题?
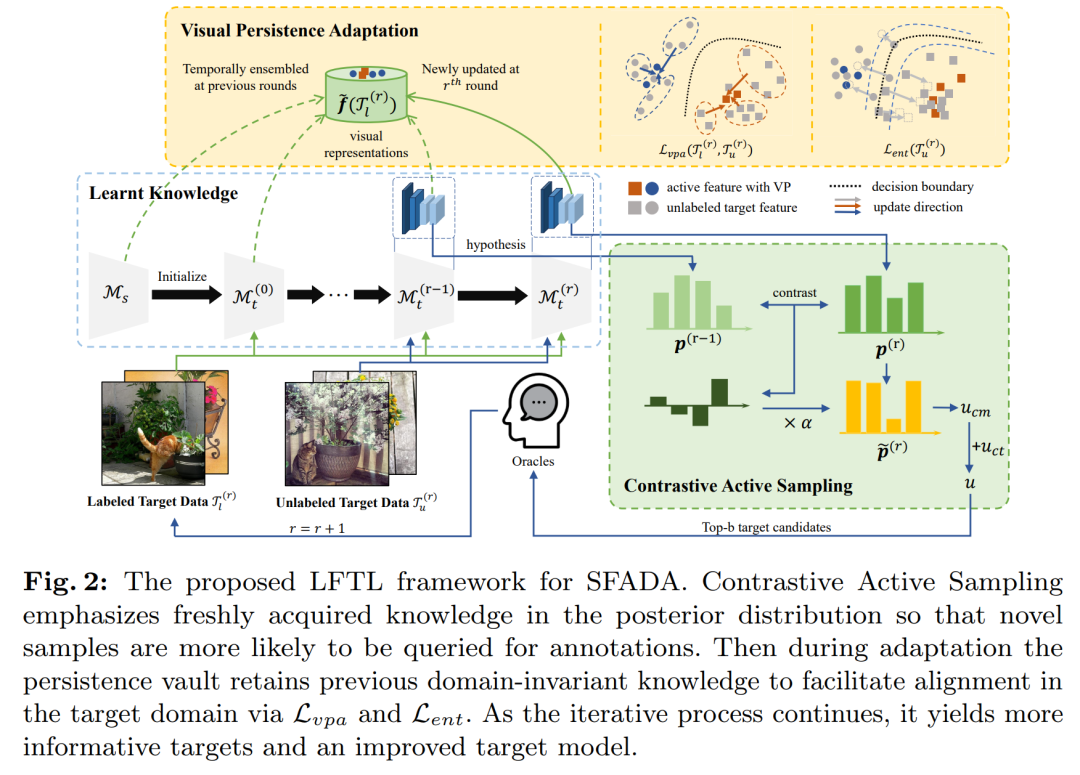
论文提出了一个名为"Learn from the Learnt" (LFTL) 的框架来解决Source-Free Active Domain Adaptation (SFADA)问题。LFTL框架主要通过以下两个关键策略来解决这个问题:
-
对比主动采样(Contrastive Active Sampling, CAS):
-
CAS策略利用从先前模型中得到的假设来识别目标样本,这些样本对当前模型具有信息量,并且在主动学习过程中持续具有挑战性。
-
通过比较当前模型与先前模型的预测置信度,CAS强调那些当前模型预测置信度提高的样本,这些样本反映了模型新获得的见解。
-
通过考虑类别级别的跨域可转移性,CAS还倾向于选择那些对当前模型来说难以转移的类别样本。
-
-
视觉持久性引导的适应(Visual Persistence-guided Adaptation, VPA):
-
VPA策略通过保持整个过程中主动选择的锚点样本的特征表示来促进特征分布的对齐和目标特定知识的利用。
-
通过使用指数移动平均来维护从源域和先前主动学习轮次中获得的理解,VPA策略在适应过程中有效地支持目标域中的对齐。
-
结合监督交叉熵损失、视觉持久性引导损失和熵最小化损失来进行模型优化。
-
LFTL框架的这两个策略相互协作,使得在源数据不可访问的情况下,模型能够从已经学习到的知识中进行有效的领域适应。通过这种方式,LFTL能够在有限的标注预算下,实现目标领域的知识转移,并随着迭代查询和适应过程的进行,持续提高模型性能。
论文做了哪些实验?
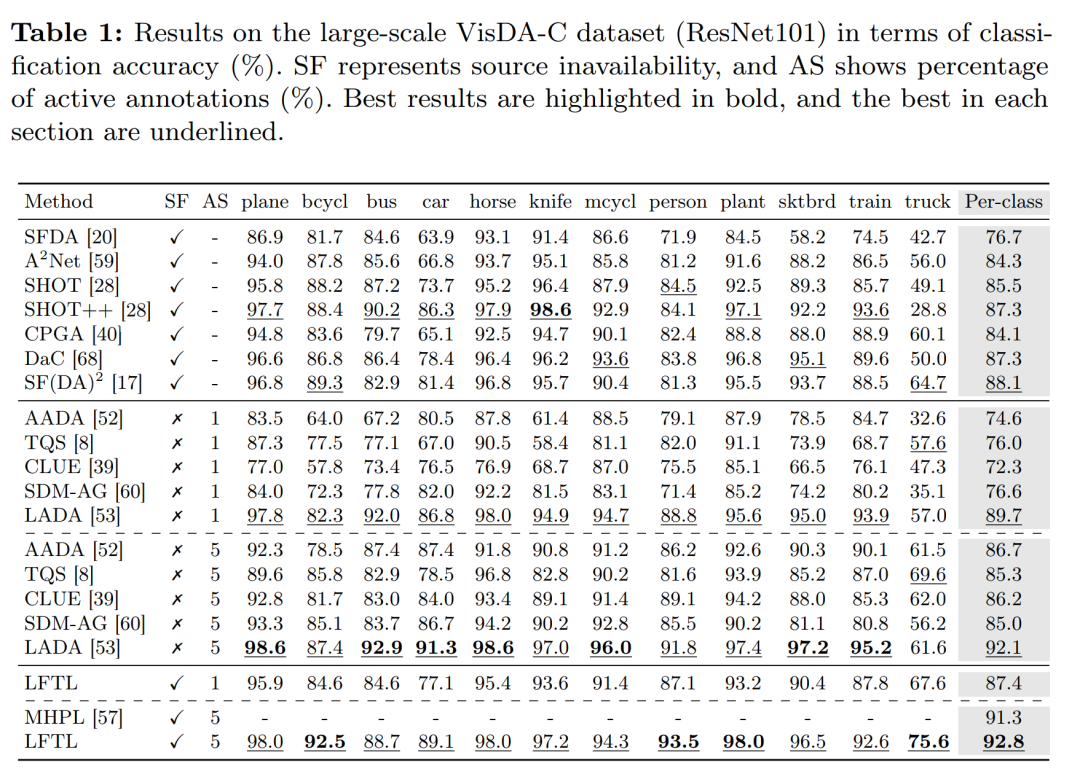
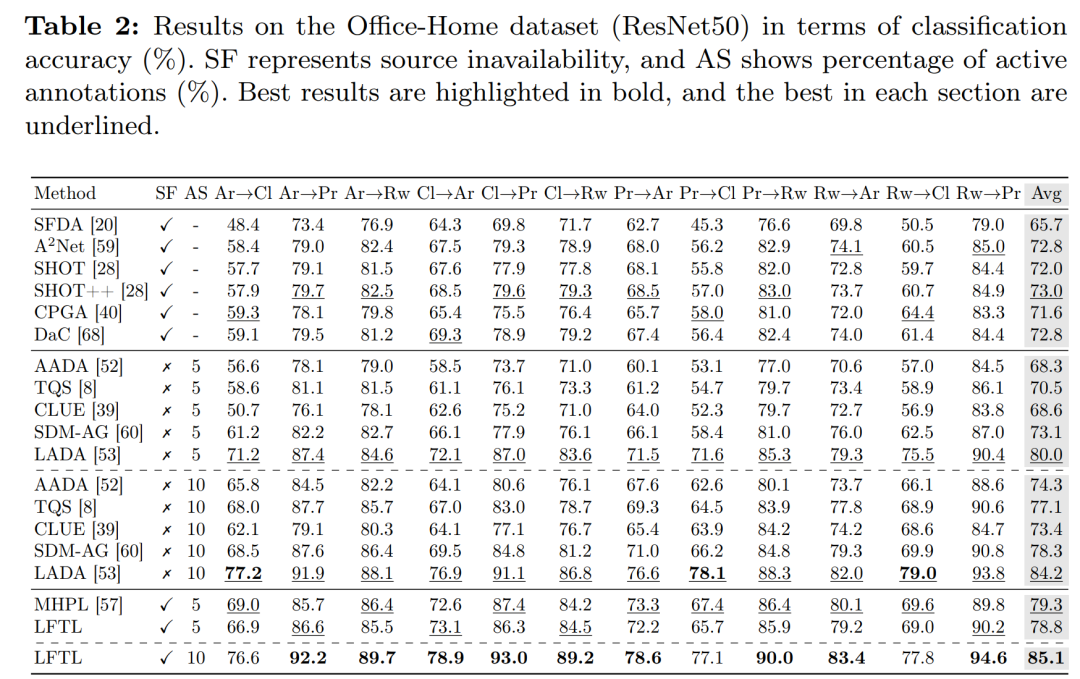
论文中进行了广泛的实验来验证所提出的LFTL框架的性能。以下是实验的主要方面:
-
实验设置:
-
使用了三个广泛使用的领域适应基准数据集:VisDA-C、Office-Home和Office-31。
-
在不同规模的数据集上进行了不同比例的标注预算实验,例如在VisDA-C上使用1%和5%的标注预算,在Office数据集上使用5%和10%的标注预算。
-
-
与最新技术的比较:
-
将LFTL与多种源自由无监督领域适应(SFUDA)和主动领域适应(ADA)方法进行了比较,包括SFDA、A2Net、SHOT、SHOT++、CPGA、DaC、SF(DA)2、AADA、TQS、CLUE、SDM-AG和LADA等。
-
-
效率分析:
-
对比了LFTL与其他SFUDA和ADA方法在实际时间消耗(包括模型训练、主动采样和人工标注时间)上的表现。
-
-
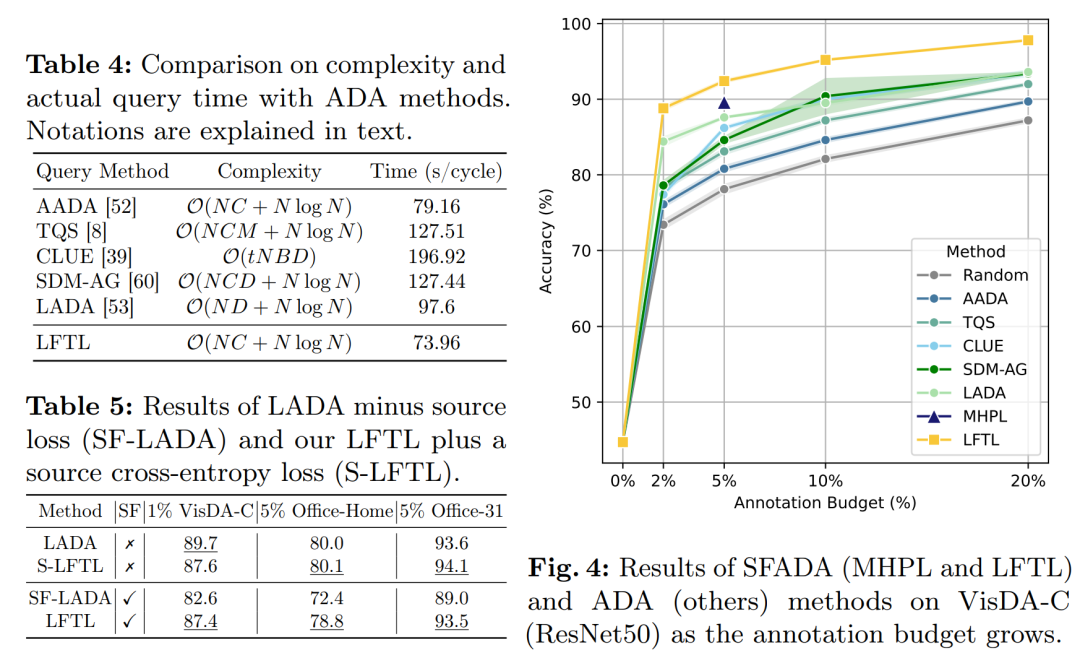
持续性能增长的承诺:
-
探索了随着标注预算增加,LFTL在不同预算情况下的性能和鲁棒性,包括2%、5%、10%和20%的标注预算。
-
-
源数据可用性的讨论:
-
通过对比LADA方法在移除源域损失(SF-LADA)和LFTL在添加源域交叉熵损失(S-LFTL)后的性能,探讨了源数据在适应过程中的作用。
-
-
与主动学习基线的比较:
-
将LFTL提出的主动查询策略与多种主动学习基线方法进行了比较,包括随机采样、基于不确定性的方法等。
-
-
定性分析:
-
使用t-SNE可视化展示了模型对目标数据的理解以及在主动学习和领域适应过程中信息样本的选择。
-
-
组件验证:
-
进行了消融研究来验证LFTL框架的各个组成部分的影响,并分析了参数敏感性。
-
-
实现细节:
-
提供了模型训练过程中使用的优化器、学习率、批量大小等实现细节。
-
这些实验结果表明,LFTL在准确性、计算效率和持续改进方面均优于现有的SFADA和ADA方法,展示了其在不同条件和约束下的有效性和灵活性。
论文的主要内容:
这篇论文提出了一种名为"Learn from the Learnt" (LFTL) 的框架,旨在解决源数据无关的主动领域适应(Source-Free Active Domain Adaptation, SFADA)问题。SFADA是一种实际的领域适应范式,其中源数据在适应过程中变得不可访问,并且目标领域只有有限的标注预算。以下是论文的主要内容总结:
-
问题背景:介绍了领域适应的重要性和挑战,特别是在没有源数据和只有少量目标数据标注的情况下。
-
LFTL框架:提出了一个新颖的框架,利用从源预训练模型和主动迭代模型中学到的知识,通过对比采样和视觉持久性引导的适应方法来实现领域适应。
-
对比主动采样(CAS):提出了一种新的主动学习策略,通过学习前一个模型的假设来选择对当前模型既有信息量又在整个迭代过程中持续具有挑战性的目标样本。
-
视觉持久性引导的适应(VPA):在适应过程中,通过保持目标样本的特征表示来促进特征分布的对齐和目标特定知识的利用。
-
实验验证:在三个广泛使用的领域适应基准数据集(VisDA-C、Office-Home和Office-31)上进行了实验,验证了LFTL框架与现有的SFUDA和ADA方法相比,在准确性、计算效率和持续改进方面的优势。
-
效率分析:对比了LFTL与其他方法在实际时间消耗上的表现,包括模型训练、主动采样和人工标注时间。
-
持续性能增长:探索了随着标注预算增加,LFTL在不同预算情况下的性能和鲁棒性。
-
源数据可用性讨论:通过对比实验,讨论了源数据在适应过程中的作用,并展示了LFTL即使在没有源数据的情况下也能有效地学习。
-
与主动学习基线的比较:将LFTL提出的主动查询策略与多种主动学习基线方法进行了比较,证明了其有效性。
-
定性分析和组件验证:通过t-SNE可视化和消融研究,进一步分析了LFTL框架的各个组成部分的影响。
-
实现细节:提供了模型训练过程中使用的优化器、学习率、批量大小等实现细节。
论文的主要贡献在于提出了一个简单、有效且灵活的SFADA解决方案,能够在资源有限的情况下实现领域适应,并且随着标注预算的增加持续提高性能。
3.Unifying Visual and Semantic Feature Spaces with Diffusion Models for Enhanced Cross-Modal Alignment 
标题:通过扩散模型统一视觉和语义特征空间以增强跨模态对齐
作者: Yuze Zheng, Zixuan Li, Xiangxian Li, Jinxing Liu, Yuqing Wang, Xiangxu Meng, Lei Meng
文章链接:https://arxiv.org/abs/2407.18854


摘要:
由于图像信息的变化(由主体对象的不同视觉视角和照明差异驱动),图像分类模型在实际应用中通常表现出不稳定的性能。为了缓解这些挑战,现有的研究通常会结合与视觉数据匹配的附加模态信息来规范模型的学习过程,从而能够从复杂的图像区域中提取高质量的视觉特征。具体来说,在多模态学习领域,跨模态对齐被认为是一种有效的策略,通过学习视觉和语义特征的领域一致的潜在特征空间来协调不同的模态信息。然而,由于多模态信息之间的异质性,例如特征分布和结构的差异,这种方法可能面临局限性。为了解决这个问题,我们引入了多模态对齐和重建网络(MARNet),旨在增强模型对视觉噪声的抵抗力。重要的是,MARNet 包含一个跨模态扩散重建模块,用于平滑、稳定地混合不同领域的信息。在 Vireo-Food172 和 Ingredient-101 两个基准数据集上进行的实验表明,MARNet 有效提高了模型提取的图像信息的质量。它是一个即插即用的框架,可以快速集成到各种图像分类框架中,从而提高模型性能。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是图像分类模型在现实世界应用中由于图像信息的变化(例如不同的视觉角度和光照差异)导致的不稳定性能。为了缓解这些挑战,论文提出了一种多模态对齐和重建网络(Multimodal Alignment and Reconstruction Network, MARNet),以增强模型对视觉噪声的抵抗力。具体来说,MARNet通过跨模态对齐策略和跨模态扩散重建模块,有效地改善了模型提取的图像信息的质量,并通过学习一个领域一致的潜在特征空间来协调视觉和语义特征之间的差异。这有助于从复杂的图像区域中提取高质量的视觉特征。
论文如何解决这个问题?
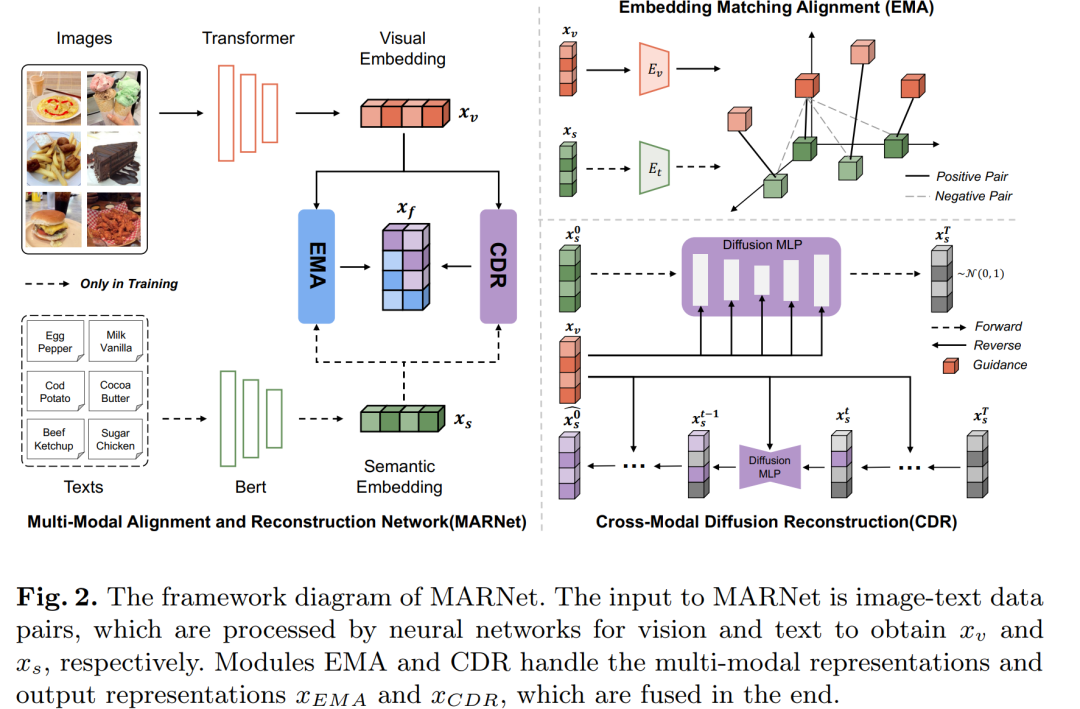
论文通过提出一种名为MARNet(Multimodal Alignment and Reconstruction Network)的新型网络架构来解决图像分类中的视觉噪声问题和跨模态对齐问题。MARNet的设计包括以下几个关键组件和步骤:
-
嵌入匹配对齐模块(Embedding Matching Alignment, EMA):
-
使用对比学习策略,通过正负样本匹配方法来微调跨模态表示,生成对齐后的表示
xEMA。 -
通过计算图像-文本表示对在特征空间内的匹配相似度,作为对齐跨域信息的约束。
-
-
跨模态扩散重建模块(Cross-Modal Diffusion Reconstruction, CDR):
-
利用扩散模型来重建跨模态表示,通过逐步添加噪声并重建来减轻视觉表示中的背景噪声影响。
-
将语义表示作为扩散模型的输入,并使用视觉表示作为引导条件,通过扩散过程平滑地交互跨模态表示信息。
-
-
扩散模型的背景:
-
扩散模型包括正向过程(添加噪声)和逆向过程(去噪重建)。
-
通过最大化真实数据分布的似然估计来训练模型,使用神经网络学习扩散过程。
-
-
多模态嵌入融合:
-
在最终阶段,将EMA和CDR模块输出的表示
xEMA和xCDR进行融合,以实现跨模态信息的互补和增强。
-
-
实验验证:
-
在两个基准数据集Vireo-Food172和Ingredient-101上进行实验,验证MARNet在图像分类任务中的有效性。
-
通过与现有对齐框架的比较,展示MARNet在视觉表示质量和下游任务性能上的显著提升。
-
-
案例分析:
-
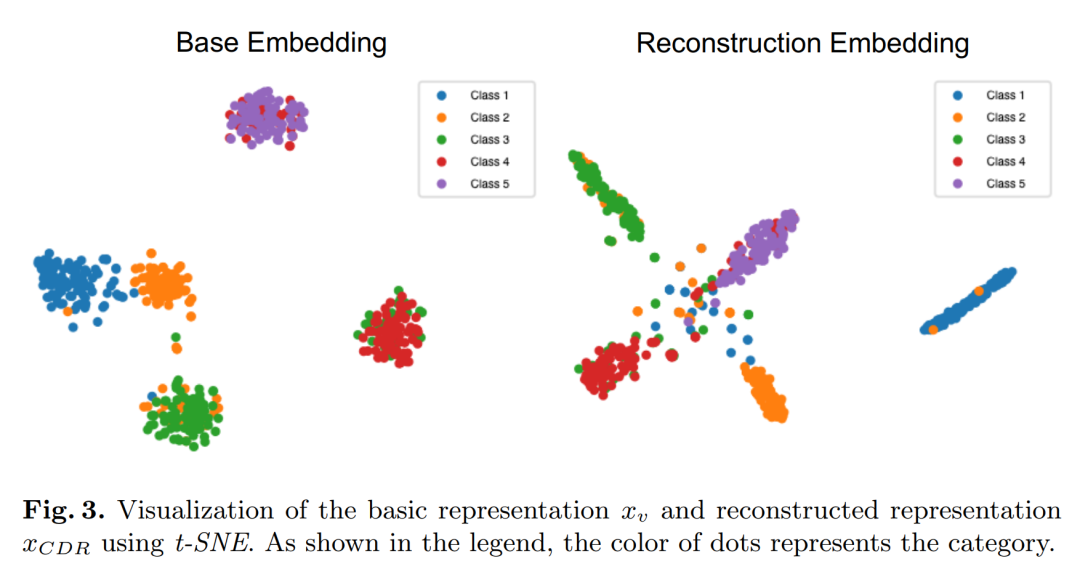
通过t-SNE可视化展示了基本表示
xv和重建表示xCDR,分析了扩散模型如何改善表示的分布并有效分离原始表示中的混淆样本。
-
通过这些方法,MARNet能够有效地提高图像信息的质量,优化表示的分布,从而增强模型在视觉域中的决策能力,并提高多模态学习领域的实用性。
论文做了哪些实验?
论文中进行了以下实验来验证MARNet(Multimodal Alignment and Reconstruction Network)的有效性:
-
实验设置:
-
使用了两个数据集:Vireo-Food172和Ingredient-101,这两个数据集都是单标签分类数据集。
-
性能评估指标为准确率(Accuracy),计算了top-1和top-5的准确率。
-
-
性能分析:
-
对比了不同的视觉网络结构(如ResNet, VGG, WRN, WISeR, RepVGG, RepMLPNet, ViT, Swin-T)在视觉分类任务上的性能。
-
对比了不同的跨模态对齐方法(如SWD, SSAN, CDD, SDM, TEAM, ITA)在结合文本信息进行视觉网络对齐时的性能。
-
-
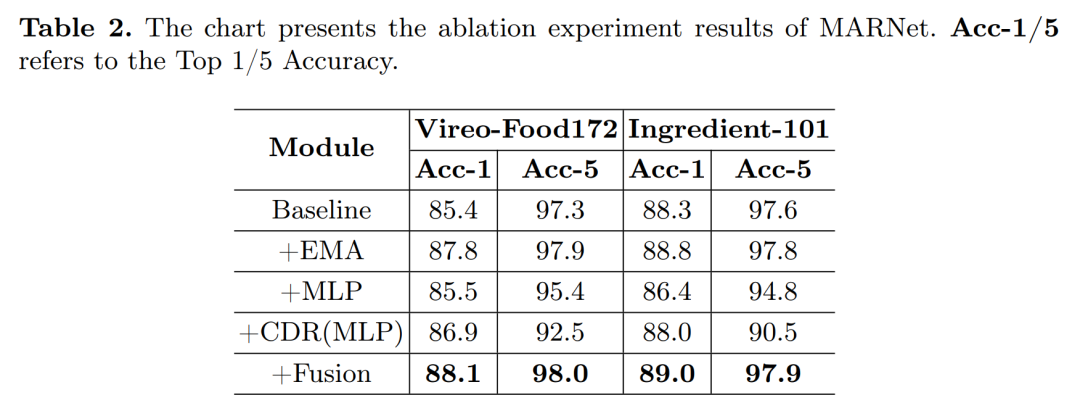
消融研究(Ablation Study):
-
使用ViT模型作为基线,逐步添加EMA(嵌入匹配对齐模块)、MLP(多层感知器)、CDR(跨模态扩散重建模块)和融合策略,观察每个组件对模型性能的影响。
-
-
案例研究(Case Study):
-
使用t-SNE可视化技术,展示了ViT基础模型和CDR模块的特征表示,分析了扩散模型如何改善特征表示的分布。
-
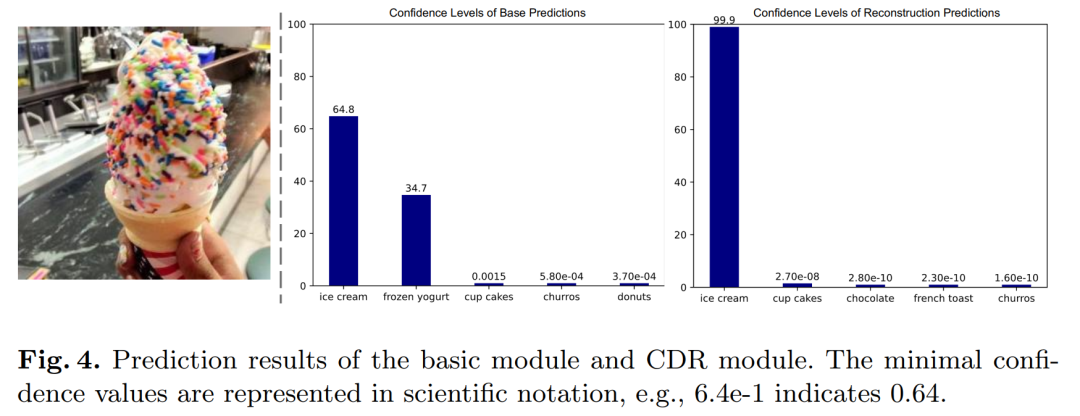
分析了基础视觉模块和CDR模块的预测结果,探讨了扩散模型在预测时的置信度分布。
-
-
实验结果:
-
展示了MARNet在Vireo-Food172和Ingredient-101数据集上的分类性能,证明了其在图像分类任务中的有效性。
-
通过消融实验,验证了EMA和CDR模块对提升模型性能的贡献。
-
-
结论:
-
论文得出结论,MARNet通过EMA和CDR模块显著提高了视觉信息的质量,并优化了表示的分布。
-
这些实验结果表明,MARNet作为一种模型不可知的算法框架,能够显著提高视觉表示的质量,并在下游任务中提高框架的性能。
论文的主要内容:
这篇论文的主要内容包括以下几个方面:
-
问题背景:
-
论文指出图像分类模型在实际应用中可能因图像信息的变化(如视觉角度和光照差异)而表现出不稳定的性能。
-
-
研究目标:
-
为了提高模型对视觉噪声的抵抗力,论文提出了一种新的多模态对齐和重建网络(MARNet),旨在通过跨模态对齐策略和跨模态扩散重建模块来改善图像信息的提取质量。
-
-
关键技术:
-
嵌入匹配对齐模块(EMA):通过对比学习策略,对图像和文本的表示进行微调,以减少不同模态间表示的异质性。
-
跨模态扩散重建模块(CDR):利用扩散模型来重建跨模态表示,通过逐步添加噪声并重建来减轻视觉表示中的背景噪声影响。
-
-
方法论:
-
论文详细介绍了MARNet的架构,包括视觉编码器、文本编码器、EMA模块、CDR模块以及多模态嵌入融合策略。
-
描述了如何通过对比学习来优化EMA模块,以及如何利用扩散模型来实现CDR模块的跨模态重建。
-
-
实验验证:
-
在Vireo-Food172和Ingredient-101两个基准数据集上进行了广泛的实验,验证了MARNet在图像分类任务中的有效性。
-
通过与现有对齐框架的比较,展示了MARNet在视觉表示质量和下游任务性能上的显著提升。
-
-
消融研究:
-
通过消融实验,验证了EMA和CDR模块对提升模型性能的贡献。
-
-
案例分析:
-
使用t-SNE可视化技术,展示了基础模型和CDR模块的特征表示,分析了扩散模型如何改善特征表示的分布。
-
-
结论:
-
论文得出结论,MARNet通过EMA和CDR模块显著提高了视觉信息的质量,并优化了表示的分布。
-
-
未来工作:
-
论文提出了未来可能的研究方向,包括扩散模型的噪声控制、模型泛化能力的提升、计算效率的优化等。
-
-
致谢:
-
论文最后感谢了支持该研究的资助项目。
-
整体而言,这篇论文提出了一个创新的多模态学习框架,通过跨模态对齐和扩散重建来提高图像分类模型的性能和鲁棒性。
相关文章:
每日学术速递8.2
1.A Scalable Quantum Non-local Neural Network for Image Classification 标题: 用于图像分类的可扩展量子非局部神经网络 作者: Sparsh Gupta, Debanjan Konar, Vaneet Aggarwal 文章链接:https://arxiv.org/abs/2407.18906 摘要&#x…...

SAP-PLM创建物料主数据接口
FUNCTION zplm_d_0001_mm01. *"---------------------------------------------------------------------- *"*"本地接口: *" EXPORTING *" VALUE(EX_TOTAL) TYPE CHAR4 *" VALUE(EX_SUCCESSFUL) TYPE CHAR4 *" …...

超声波眼镜清洗机哪个品牌好?四款高性能超声波清洗机测评剖析
对于追求高生活质量的用户来说,眼镜的清洁绝对不能马虎。如果不定期清洁眼镜,时间久了,镜片的缝隙中会积累大量的灰尘和细菌,眼镜靠近眼部,对眼部健康有很大影响。在这种情况下,超声波清洗机显得尤为重要。…...
卸载Windows软件的正确姿势,你做对了吗?
前言 今天有小伙伴突然问我:她把软件都卸载了,但是怎么软件都还在运行? 这个问题估计很多小伙伴都是遇到过的,对于电脑小白来说,卸载Windows软件真的真的真的是一件很难的事情。所以,今天咱们就来讲讲&am…...
WEB前端14-Element UI(学生查询表案例/模糊查询/分页查询)
Vue2-Element UI 1.可重用组件的开发 可重用组件 我们一般将可重复使用的组件放在components目录之下,以便父组件的灵活调用 <!--可重用组件一般与css密切相关,使用可重用组件的目的是,将相似的组件放在一起,方便使用-->…...

使用swiftui自定义圆形进度条实现loading
实现的代码如下: // // LoadingView.swift // SwiftBook // // Created by Song on 2024/8/2. //import SwiftUIstruct LoadingView: View {State var process 0.5var body: some View {VStack(spacing: 20) {ZStack {Circle().stroke(.gray.opacity(0.3), lin…...

C# 设计模式之抽象工厂模式
总目录 前言 工厂方法模式是为了克服简单工厂模式的缺点而设计出来的,简单工厂模式的工厂类随着产品类的增加需要增加额外的代码,而工厂方法模式每个具体工厂类只完成单个实例的创建,所以它具有很好的可扩展性。但是在现实生活中,…...

Javascript前端面试基础(八)
window.onload和$(document).ready区别 window.onload()方法是必须等到页面内包括图片的所有元素加载完毕后才能执行$(document).ready()是DOM结构绘制完毕后就执行,不必等到加载完毕 window.onload 触发时机:window.onload 事件会在整个页面…...

R 语言学习教程,从入门到精通,R的安装与环境的配置(2)
1、R的安装与环境的配置 R语言是一款完全免费且开源的软件,它的开源许可证是GNU通用公共许可证(GPL),这意味着任何人都可以自由地使用、复制、修改和发布R语言的源代码,甚至可以将其用于商业用途。 和python等其他语言…...

Python批量下载音乐功能
Python批量下载音乐功能 Python批量下载音乐,调用API接口,同时下载歌曲和歌词 先安排一下要用的模块,导入进来。 import re import json import requests目录结构 下载音乐 Awking_Class.pymusic.txt 文件文件写的是音乐名字,使用换行分割 new_music 注意这个 ne…...
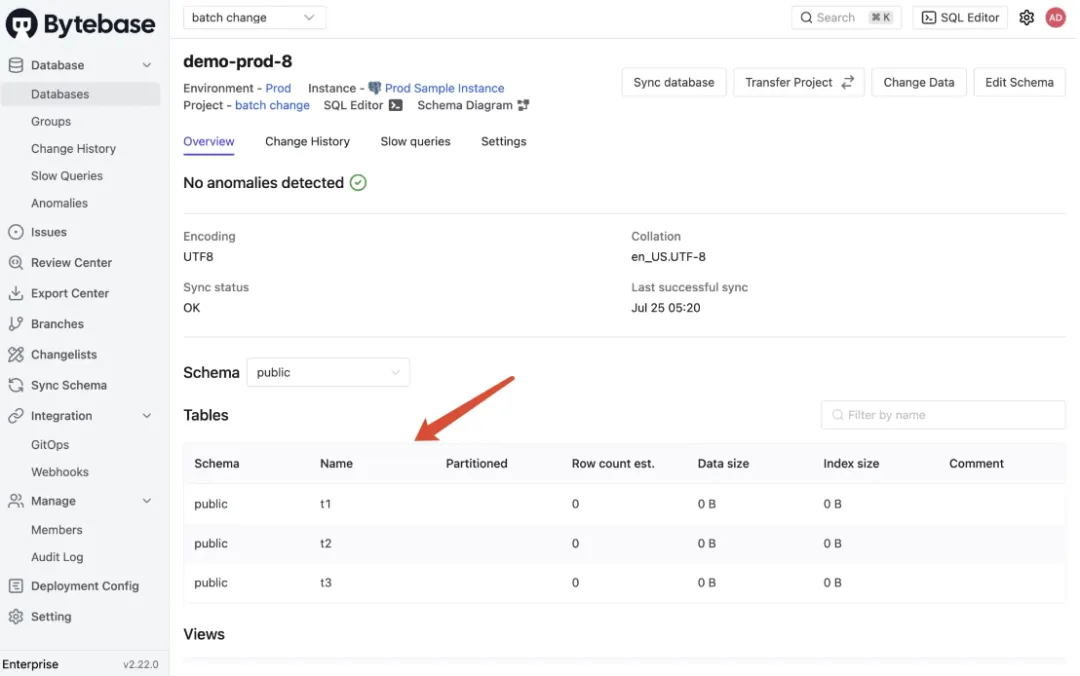
用 Bytebase 实现批量、多环境、多租户数据库的丝滑变更
Bytebase 提供了多种功能来简化批量变更管理,适用于多环境或多租户情况。本教程将指导您如何使用 部署配置 和 数据库组 在不同场景下进行数据库批量变更。 默认流水线 vs 部署配置 图片数据库 vs 数据库组 1. 准备 请确保已安装 Docker,如果本地没有重…...

java之方法引用 —— ::
目录 一、简介 二、引用静态方法 1.格式 2.示例 编辑 3.条件解析 三、引用成员方法 1.格式 2.示例 四、引用构造方法 1.格式 2.示例 五、类名引用成员方法 1.格式 2.略微不同的方法引用规则 3.示例 六、引用数组的构造方法 1.格式 2.示例 一、简介 方…...
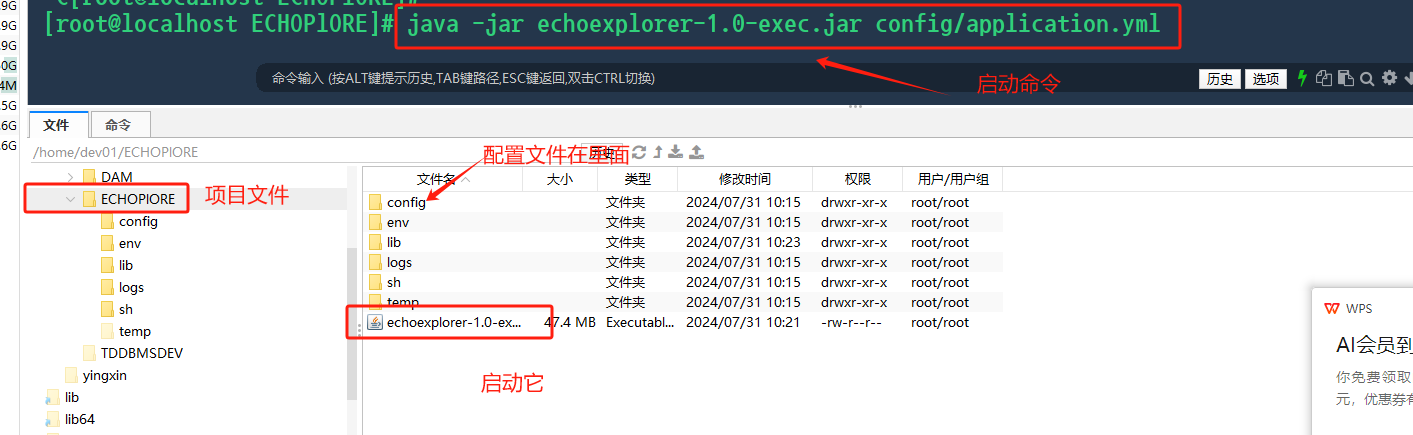
「测试线排查的一些经验-上篇」 后端工程师
文章目录 端口占用脚本失灵线上部署项目结构模版配置文件生效 一般产品研发过程所使用的环境可分为: 研发环境-dev测试环境-test生产环境-prod 软件开发中,完整测试环境包括:UT、IT、ST、UAT UT Unit Test 单元测试 IT System Integration …...

AOSP12_BatteryStats统计电池数据信息
前言 BatteryStats模块主要用于设备在电池供电是系统对各个模块电量使用的统计,Android提供的Battery Historain工具就是对此模块统计的数据进行解析和展示。 一 BatteryStats模块类图 模块主要类图如下:见根目录的模块类图 BatteryStats:抽象类,本模块的核心类,主要定…...

【Android Studio】UI 布局
文章目录 view布局LinearLayout view 在Android开发中,View是一个非常重要的概念,它是所有用户界面组件的基类。View类及其子类构成了Android应用中的用户界面。每个View都占用屏幕上的一个矩形区域,并可以响应用户输入(如触摸、按…...

虚拟机Windows server忘记密码解决方法
原理 utilman.exe是Windows辅助工具管理器程序,虽然它本身不是一个关键的系统进程,但通过修改这个文件,用户可以访问一些有用的UI设置。在某些情况下,比如忘记密码需要重置时,通过修改utilman.exe文件为c…...
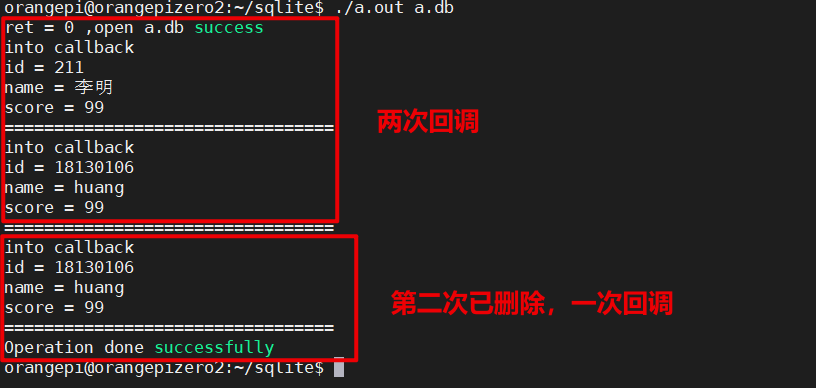
【香橙派系列教程】(六)嵌入式SQLite数据库
【六】嵌入式SQLite数据库 文章目录 【六】嵌入式SQLite数据库1.简介2.SQLite数据库安装3.SQLite命令用法1.创建数据库2.创建和查看表格3.插入查看数据(记录)4.删除更改数据(记录) 4.SQLite编程操作1.打开/创建数据库的C接口2.创建…...

深入探讨PHP8的新特性与性能优化
本文由 ChatMoney团队出品 随着互联网技术的飞速发展,PHP作为后端开发领域的热门语言也在不断演进。近期,PHP8的发布引起了广泛关注。本文将为您详细介绍PHP8的新特性以及性能优化,并通过具体示例帮助您更好地理解和应用这些新特性。 一、PH…...
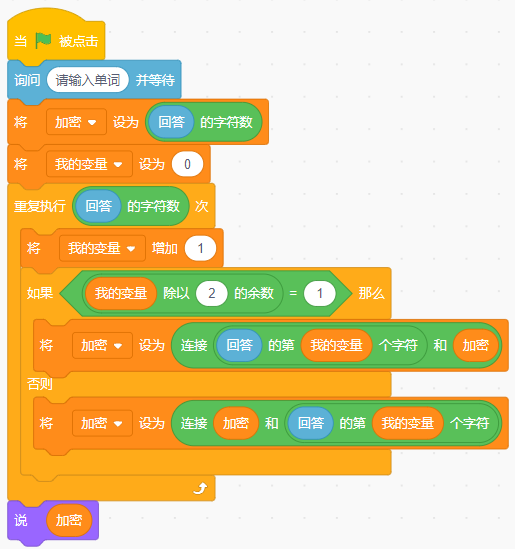
2024年06月 Scratch 图形化(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
Scratch图形化等级考试(1~4级)全部真题・点这里 一、单选题(共10题,共30分) 第1题 运行下列程序,输入单词“PLAY”,最后角色说?( ) A:LY4AP B:AP4LY C:YA4PL D:PL4AY 答案:B 根据程序分析可知,首先获取单词字符数,然后奇数位的字母放在字符数左侧,偶数位…...

书生大模型全链路开源体系
书生大模型全链路开源体系 数据 预训练 微调 评测 部署 应用...

抖音批量下载工具:高效解决方案与实战指南
抖音批量下载工具:高效解决方案与实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量…...

DeepSeek-Coder-V2-Lite-Instruct社区案例集:开发者如何用AI改变编程方式
DeepSeek-Coder-V2-Lite-Instruct社区案例集:开发者如何用AI改变编程方式 【免费下载链接】DeepSeek-Coder-V2-Lite-Instruct 开源代码智能利器——DeepSeek-Coder-V2,性能比肩GPT4-Turbo,全面支持338种编程语言,128K超长上下文&a…...
)
Java虚拟线程调试黄金组合:jstack -l + jcmd VM.native_memory + JMC Thread Group视图(生产环境零侵入诊断法)
第一章:Java虚拟线程调试黄金组合:jstack -l jcmd VM.native_memory JMC Thread Group视图(生产环境零侵入诊断法)虚拟线程(Virtual Threads)作为 Project Loom 的核心特性,在高并发场景下显著…...

公司SEO推广有哪些常见的误区需要避免
公司SEO推广有哪些常见的误区需要避免 在数字化营销的时代,公司SEO推广已经成为提升网站流量和品牌知名度的重要手段。在实际操作中,许多企业在SEO推广过程中常常犯下一些常见的误区,这些误区不仅影响了SEO的效果,还可能导致资源…...

《算法竞赛从入门到国奖》算法基础:动态规划-最长子序列
💡Yupureki:个人主页 ✨个人专栏:《C》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》 《个人在线OJ平台》 🌸Yupureki🌸的简介: 目录 1. 最长上升子序列 算法原理 代码示例 2. 合唱队形 算法原理 代码示例 3. 最长公共…...

OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块
OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块 1. 为什么需要专用技能模块? 上周我在整理技术文档时遇到一个典型场景:需要将十几份混杂着截图和文字说明的会议纪要,自动转换成结构化的Markdown文件。当…...

寒冬降临:当资本撤出AI测试赛道
2026年初,全球资本市场对AI技术的狂热投资骤然降温。随着VC基金转向更保守的资产配置,依赖融资的AI测试工具开发商面临生存危机:初创公司批量裁员,开源项目停止维护,企业采购的智能测试平台因无法续约沦为“断线木偶”…...

StreamlabsArduinoAlerts:嵌入式设备接入Twitch直播事件
1. StreamlabsArduinoAlerts 库深度解析:嵌入式设备接入 Twitch 直播事件的完整实现方案 StreamlabsArduinoAlerts 是一个专为资源受限嵌入式平台设计的轻量级 C 库,其核心目标是让 Arduino、ESP8266、ESP32、Particle 及基于 ATmega/STM32 的 MCU 能够直…...

使用Image - To - image条件生成对抗网络评估乳腺癌新辅助化疗反应的动态对比增强MRI血管渗透性映射
论文总结1、提出了一种基于条件生成对抗网络(cGAN)的新方法,用于将动态对比增强磁共振成像(DCE MRI)快速转换为药代动力学(PK)血管通透性参数图(Ktrans),以早…...

新手入门:在快马平台动手实现你的第一个ui-ux-pro-max设计页面
作为一个刚接触前端设计的新手,最近在InsCode(快马)平台尝试做了一个UI-UX-Pro-Max级别的登录注册页面,整个过程意外地顺利。这里记录下我的实践过程,希望能帮到同样想入门的朋友。 从零搭建页面框架 先用HTML搭建基础结构,包含表…...