【机器学习】机器学习与医疗健康在疾病预测中的融合应用与性能优化新探索


文章目录
- 引言
- 第一章:机器学习在医疗健康中的应用
- 1.1 数据预处理
- 1.1.1 数据清洗
- 1.1.2 数据归一化
- 1.1.3 特征工程
- 1.2 模型选择
- 1.2.1 逻辑回归
- 1.2.2 决策树
- 1.2.3 随机森林
- 1.2.4 支持向量机
- 1.2.5 神经网络
- 1.3 模型训练
- 1.3.1 梯度下降
- 1.3.2 随机梯度下降
- 1.3.3 Adam优化器
- 1.4 模型评估与性能优化
- 1.4.1 模型评估指标
- 1.4.2 超参数调优
- 1.4.3 增加数据量
- 1.4.4 模型集成
- 第二章:疾病预测的具体案例分析
- 2.1 糖尿病预测
- 2.1.1 数据预处理
- 2.1.2 模型选择与训练
- 2.1.3 模型评估与优化
- 2.2 心脏病预测
- 2.2.1 数据预处理
- 2.2.2 模型选择与训练
- 2.2.3 模型评估与优化
- 2.3 肺癌预测
- 2.3.1 数据预处理
- 2.3.2 模型选择与训练
- 2.3.3 模型评估与优化
- 第三章:性能优化与前沿研究
- 3.1 性能优化
- 3.1.1 特征工程
- 3.1.2 超参数调优
- 3.1.3 模型集成
- 3.2 前沿研究
- 3.2.1 深度学习在医疗健康中的应用
- 3.2.2 联邦学习与隐私保护
- 3.2.3 强化学习在医疗决策中的应用
- 结语
引言
机器学习是一种通过数据训练模型,并利用模型对新数据进行预测和决策的技术。其基本思想是让计算机通过样本数据自动学习规律,而不是通过明确的编程指令。根据学习的类型,机器学习可以分为监督学习、无监督学习和强化学习。随着医疗健康领域数据的快速积累,机器学习在疾病预测、诊断和治疗中的应用越来越广泛,为提升医疗服务质量和效率提供了强有力的技术支持。
本文将详细介绍机器学习在医疗健康中的应用,包括数据预处理、模型选择、模型训练和性能优化。通过具体的案例分析,展示机器学习技术在疾病预测中的实际应用,并提供相应的代码示例。

第一章:机器学习在医疗健康中的应用
1.1 数据预处理
在医疗健康应用中,数据预处理是机器学习模型成功的关键步骤。医疗数据通常具有高维度、时间序列性和噪声,需要进行清洗、归一化和特征工程。
1.1.1 数据清洗
数据清洗包括处理缺失值、异常值和重复数据。缺失值可以通过删除、插值或填充等方法处理;异常值可以通过统计分析和域知识进行识别和处理;重复数据可以通过去重操作去除。
import pandas as pd
import numpy as np# 加载数据
data = pd.read_csv('medical_data.csv')# 处理缺失值
data.fillna(data.mean(), inplace=True)# 处理异常值
data = data[(np.abs(data - data.mean()) <= (3 * data.std()))]# 去除重复数据
data.drop_duplicates(inplace=True)
1.1.2 数据归一化
数据归一化可以消除不同特征之间的量纲差异,常见的方法包括标准化和最小最大缩放。
from sklearn.preprocessing import StandardScaler, MinMaxScaler# 标准化
scaler = StandardScaler()
data_standardized = scaler.fit_transform(data)# 最小最大缩放
scaler = MinMaxScaler()
data_normalized = scaler.fit_transform(data)
1.1.3 特征工程
特征工程包括特征选择、特征提取和特征构造。特征选择可以通过相关性分析和主成分分析(PCA)等方法进行;特征提取可以通过技术指标计算等方法进行;特征构造可以通过组合和变换现有特征生成新的特征。
from sklearn.decomposition import PCA# 特征选择
correlation_matrix = data.corr()
selected_features = correlation_matrix.index[abs(correlation_matrix["target"]) > 0.5]# 主成分分析
pca = PCA(n_components=5)
data_pca = pca.fit_transform(data[selected_features])
1.2 模型选择
在医疗健康中,常用的机器学习模型包括逻辑回归、决策树、随机森林、支持向量机(SVM)和神经网络等。不同模型适用于不同的任务和数据特征,需要根据具体应用场景进行选择。
1.2.1 逻辑回归
逻辑回归适用于二分类任务,如疾病预测和患者分类。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split# 数据分割
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.2.2 决策树
决策树适用于分类和回归任务,能够处理非线性数据,并具有良好的解释性。
from sklearn.tree import DecisionTreeClassifier# 训练决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.2.3 随机森林
随机森林通过集成多棵决策树,提高了模型的稳定性和预测精度,特别适用于复杂的医疗数据。
from sklearn.ensemble import RandomForestClassifier# 训练随机森林模型
model = RandomForestClassifier()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.2.4 支持向量机
支持向量机适用于分类任务,特别是在高维数据和小样本数据中表现优异。
from sklearn.svm import SVC# 训练支持向量机模型
model = SVC()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.2.5 神经网络
神经网络适用于复杂的预测和分类任务,能够捕捉数据中的非线性关系。常用的神经网络包括前馈神经网络、卷积神经网络(CNN)和递归神经网络(RNN)。
from keras.models import Sequential
from keras.layers import Dense# 构建神经网络模型
model = Sequential()
model.add(Dense(units=64, activation='relu', input_dim=X_train.shape[1]))
model.add(Dense(units=32, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
1.3 模型训练
模型训练是机器学习的核心步骤,通过优化算法最小化损失函数,调整模型参数,使模型在训练数据上表现良好。常见的优化算法包括梯度下降、随机梯度下降和Adam优化器等。
1.3.1 梯度下降
梯度下降通过计算损失函数对模型参数的导数,逐步调整参数,使损失函数最小化。
import numpy as np# 定义损失函数
def loss_function(y_true, y_pred):return np.mean((y_true - y_pred) ** 2)# 梯度下降优化
def gradient_descent(X, y, learning_rate=0.01, epochs=1000):m, n = X.shapetheta = np.zeros(n)for epoch in range(epochs):gradient = (1/m) * X.T.dot(X.dot(theta) - y)theta -= learning_rate * gradientreturn theta# 训练模型
theta = gradient_descent(X_train, y_train)
1.3.2 随机梯度下降
随机梯度下降在每次迭代中使用一个样本进行参数更新,具有较快的收敛速度和更好的泛化能力。
def stochastic_gradient_descent(X, y, learning_rate=0.01, epochs=1000):m, n = X.shapetheta = np.zeros(n)for epoch in range(epochs):for i in range(m):gradient = X[i].dot(theta) - y[i]theta -= learning_rate * gradient * X[i]return theta# 训练模型
theta = stochastic_gradient_descent(X_train, y_train)
1.3.3 Adam优化器
Adam优化器结合了动量和自适应学习率的优点,能够快速有效地优化模型参数。
from keras.optimizers import Adam# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
1.4 模型评估与性能优化
模型评估是衡量模型在测试数据上的表现,通过计算模型的准确率、召回率、F1-score等指标,评估模型的性能。性能优化包括调整超参数、增加数据量和模型集成等方法。
1.4.1 模型评估指标
常见的模型评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-score等。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-score: {f1}')
1.4.2 超参数调优
通过网格搜索(Grid Search
)和随机搜索(Random Search)等方法,对模型的超参数进行调优,找到最优的参数组合。
from sklearn.model_selection import GridSearchCV# 定义超参数网格
param_grid = {'max_depth': [3, 5, 7, 10],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 网格搜索
grid_search = GridSearchCV(estimator=DecisionTreeClassifier(), param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)# 输出最优参数
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = DecisionTreeClassifier(**best_params)
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.4.3 增加数据量
通过数据增强和采样技术,增加训练数据量,提高模型的泛化能力和预测性能。
from imblearn.over_sampling import SMOTE# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)# 训练模型
model.fit(X_resampled, y_resampled)# 预测与评估
y_pred = model.predict(X_test)
1.4.4 模型集成
通过模型集成的方法,将多个模型的预测结果进行组合,提高模型的稳定性和预测精度。常见的模型集成方法包括Bagging、Boosting和Stacking等。
from sklearn.ensemble import VotingClassifier# 构建模型集成
ensemble_model = VotingClassifier(estimators=[('lr', LogisticRegression()),('dt', DecisionTreeClassifier()),('rf', RandomForestClassifier())
], voting='soft')# 训练集成模型
ensemble_model.fit(X_train, y_train)# 预测与评估
y_pred = ensemble_model.predict(X_test)
第二章:疾病预测的具体案例分析
2.1 糖尿病预测
糖尿病是一种常见的慢性疾病,通过早期预测,可以有效预防和控制糖尿病的发展。以下是使用机器学习技术进行糖尿病预测的具体案例分析。
2.1.1 数据预处理
首先,对糖尿病数据集进行预处理,包括数据清洗、归一化和特征工程。
# 加载糖尿病数据集
data = pd.read_csv('diabetes.csv')# 数据清洗
data.fillna(data.mean(), inplace=True)
data = data[(np.abs(data - data.mean()) <= (3 * data.std()))]
data.drop_duplicates(inplace=True)# 数据归一化
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data)# 特征选择
correlation_matrix = data.corr()
selected_features = correlation_matrix.index[abs(correlation_matrix["Outcome"]) > 0.1]# 主成分分析
pca = PCA(n_components=5)
data_pca = pca.fit_transform(data[selected_features])# 数据分割
X = data_pca
y = data["Outcome"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2.1.2 模型选择与训练
选择合适的模型进行训练,这里以随机森林为例。
# 训练随机森林模型
model = RandomForestClassifier()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
2.1.3 模型评估与优化
评估模型的性能,并进行超参数调优和数据增强。
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-score: {f1}')# 超参数调优
param_grid = {'n_estimators': [50, 100, 150],'max_depth': [3, 5, 7, 10],'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(estimator=RandomForestClassifier(), param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = RandomForestClassifier(**best_params)
model.fit(X_train, y_train)# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
model.fit(X_resampled, y_resampled)# 预测与评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Optimized Accuracy: {accuracy}')
print(f'Optimized Precision: {precision}')
print(f'Optimized Recall: {recall}')
print(f'Optimized F1-score: {f1}')
2.2 心脏病预测
心脏病是威胁人类健康的主要疾病之一,通过机器学习技术,可以实现对心脏病的早期预测和风险评估。以下是心脏病预测的具体案例分析。
2.2.1 数据预处理
# 加载心脏病数据集
data = pd.read_csv('heart_disease.csv')# 数据清洗
data.fillna(data.mean(), inplace=True)
data = data[(np.abs(data - data.mean()) <= (3 * data.std()))]
data.drop_duplicates(inplace=True)# 数据归一化
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data)# 特征选择
correlation_matrix = data.corr()
selected_features = correlation_matrix.index[abs(correlation_matrix["target"]) > 0.1]# 主成分分析
pca = PCA(n_components=5)
data_pca = pca.fit_transform(data[selected_features])# 数据分割
X = data_pca
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2.2.2 模型选择与训练
选择合适的模型进行训练,这里以支持向量机为例。
# 训练支持向量机模型
model = SVC()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
2.2.3 模型评估与优化
评估模型的性能,并进行超参数调优和数据增强。
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-score: {f1}')# 超参数调优
param_grid = {'C': [0.1, 1, 10],'gamma': [0.001, 0.01, 0.1],'kernel': ['linear', 'rbf']
}
grid_search = GridSearchCV(estimator=SVC(), param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = SVC(**best_params)
model.fit(X_train, y_train)# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
model.fit(X_resampled, y_resampled)# 预测与评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Optimized Accuracy: {accuracy}')
print(f'Optimized Precision: {precision}')
print(f'Optimized Recall: {recall}')
print(f'Optimized F1-score: {f1}')
2.3 肺癌预测
肺癌是全球范围内发病率和死亡率较高的癌症之一,通过机器学习技术,可以实现对肺癌的早期预测和精准诊断。以下是肺癌预测的具体案例分析。
2.3.1 数据预处理
# 加载肺癌数据集
data = pd.read_csv('lung_cancer.csv')# 数据清洗
data.fillna(data.mean(), inplace=True)
data = data[(np.abs(data - data.mean()) <= (3 * data.std()))]
data.drop_duplicates(inplace=True)# 数据归一化
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data)# 特征选择
correlation_matrix = data.corr()
selected_features = correlation_matrix.index[abs(correlation_matrix["diagnosis"]) > 0.1]# 主成分分析
pca = PCA(n_components=5)
data_pca = pca.fit_transform(data[selected_features])# 数据分割
X = data_pca
y = data["diagnosis"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2.3.2 模型选择与训练
选择合适的模型进行训练,这里以神经网络为例。
# 构建神经网络模型
model = Sequential()
model.add(Dense(units=64, activation='relu', input_dim=X_train.shape[1]))
model.add(Dense(units=32, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
2.3.3 模型评估与优化
评估模型的性能,并进行超参数调优和数据增强。
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Accuracy: {accuracy}')# 超参数调优
from keras.optimizers import Adam
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])# 数据增强
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
model.fit(X_resampled, y_resampled, epochs=10, batch_size=32, validation_split=0.2)# 预测与评估
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Optimized Accuracy: {accuracy}')
第三章:性能优化与前沿研究
3.1 性能优化
3.1.1 特征工程
通过特征选择、特征提取和特征构造,优化模型的输入,提高模型的性能。
from sklearn.feature_selection import SelectKBest, f_classif# 特征选择
selector = SelectKBest(score_func=f_classif, k=10)
X_selected = selector.fit_transform(X, y)
3.1.2 超参数调优
通过网格搜索和随机搜索,找到模型的最优超参数组合。
from sklearn.model_selection import RandomizedSearchCV# 随机搜索
param_dist = {'n_estimators': [50, 100, 150],'max_depth': [3, 5, 7, 10],'min_samples_split': [2, 5, 10]
}
random_search = RandomizedSearchCV(estimator=RandomForestClassifier(), param_distributions=param_dist, n_iter=10, cv=5, scoring='accuracy')
random_search.fit(X_train, y_train)
best_params = random_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = RandomForestClassifier(**best_params)
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
3.1.3 模型集成
通过模型集成,提高模型的稳定性和预测精度。
from sklearn.ensemble import StackingClassifier# 构建模型集成
stacking_model = StackingClassifier(estimators=[('lr', LogisticRegression()),('dt', DecisionTreeClassifier()),('rf', RandomForestClassifier())
], final_estimator=LogisticRegression())# 训练集成模型
stacking_model.fit(X_train, y_train)# 预测与评估
y_pred = stacking_model.predict(X_test)
3.2 前沿研究
3.2.1 深度学习在医疗健康中的应用
深度学习在医疗健康中的应用包括医学图像分析、基因数据分析和个性化治疗等。
3.2.2 联邦学习与隐私保护
联邦学习通过在不交换数据的情况下进行联合建模,保护数据隐私,提高模型的安全性和公平性。
3.2.3 强化学习在医疗决策中的应用
强化学习通过与环境的交互,不断优化决策策略,在医疗决策和治疗方案优化中具有广泛的应用前景。
结语
机器学习作为医疗健康领域的重要技术,已经在多个应用场景中取得了显著的成果。通过对数据的深入挖掘和模型的不断优化,机器学习技术将在疾病预测、诊断和治疗中发挥更大的作用,推动医疗健康事业的发展。
相关文章:
【机器学习】机器学习与医疗健康在疾病预测中的融合应用与性能优化新探索
文章目录 引言第一章:机器学习在医疗健康中的应用1.1 数据预处理1.1.1 数据清洗1.1.2 数据归一化1.1.3 特征工程 1.2 模型选择1.2.1 逻辑回归1.2.2 决策树1.2.3 随机森林1.2.4 支持向量机1.2.5 神经网络 1.3 模型训练1.3.1 梯度下降1.3.2 随机梯度下降1.3.3 Adam优化…...

MySQL(8.0)数据库安装和初始化以及管理
1.MySQL下载安装和初始化 1.下载安装包 下载地址:https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.33-1.el7.x86_64.rpm-bundle.tar wget https://downloads.mysql.com/archives/get/p/23/file/mysql-8.0.33-1.el7.x86_64.rpm-bundle.tar 2.解压…...
C# Web控件与数据感应之 TreeView 类
目录 关于 TreeView 一些区别 准备数据源 范例运行环境 一些实用方法 获取数据进行呈现 根据ID设置节点 获取所有结点的索引 小结 关于 TreeView 数据感应也即数据捆绑,是一种动态的,Web控件与数据源之间的交互,本文将继续介绍与…...

java使用责任链模式进行优化代码
1.什么是责任链 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许多个对象有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。每个收到请求的对象要么处理该请求,要么将它传递给链中…...

【人工智能】边缘计算与 AI:实时智能的未来
💎 我的主页:2的n次方_ 💎1. 引言 随着物联网设备数量的爆炸性增长和对实时处理需求的增加,边缘计算与人工智能(Edge AI)成为一个热门话题。Edge AI 通过在本地设备上运行 AI 算法,减少对云计…...

Day12--Servlet实现前后端交互(案例:学生信息管理系统登录页面)
(在一个完整的项目架构中,servlet的角色和位置) Servlet、GenericServlet和HttpServlet三者之间的关系是Java Web开发中的一个重要概念,它们共同构成了基于Java的服务器端程序的基础。以下是具体分析: 1. Servlet接口…...

Android 安装应用-准备阶段
安装应用的准备阶段是在PackageManagerService类中的preparePackageLI(InstallArgs args, PackageInstalledInfo res),代码有些长,分段阅读。 分段一 分段一: GuardedBy("mInstallLock")private PrepareResult preparePackageLI(I…...

【JKI SMO】框架讲解(九)
本节内容将演示如何向SMO框架添加启动画面。 1.打开LabVIEW新建一个空白项目,并保存。 2.找到工具,打开SMO Editor。 3.新建一个SMO,选择SMO.UI.Splash。 4. 打开LabVIEW项目,可以看到项目里多了一个SystemSplash类。 打开Process…...
Linux通过Docker安装Microsoft Office+RDP远程控制
之前根据B站教程《在linux上安装微软office》:在linux上安装微软office_哔哩哔哩_bilibili 写过一篇使用KVM虚拟机安装Microsoft OfficeRDP远程控制的文章,根据B站的教程安装后,发现有远程控制延迟的问题,比如拖动Office窗口时会…...
利用Qt实现调用文字大模型的API,文心一言、通义千问、豆包、GPT、Gemini、Claude。
利用Qt实现调用文字大模型的API,文心一言、通义千问、豆包、GPT、Gemini、Claude。 下载地址: AI.xyz 1 Qt实现语言大模型API调用 视频——Qt实现语言大模型API调用 嘿,大家好!分享一个最近做的小项目 “AI.xyz” 基于Qt实现调用各家大模型…...

借助医疗保健专用的 LLM提高诊断支持与准确性
概述 最近的研究表明,大规模语言模型在医疗人工智能应用中非常有效。它们在诊断和临床支持系统中的有效性尤为明显,在这些系统中,它们已被证明能为各种医疗询问提供高度准确的答案(例如,医生在诊断过程中需要用到语言…...
)
微前端(qiankun)
微前端 特点:独立开发、独立部署,独立运行,增量升级 解决的问题:日常开发过程中,可能有很多老项目需要迭代,但是可能新的一些可能需要使用的依赖或者新的一些框架,老项目已经不满足,…...
)
速通c++(周二)
前言 Hello,大家好啊,我是文宇,不是文字,是文宇哦。 今天是速通c第二期。 运算符 c里的运算符种类有很多,因为这个教程是入门教程,所以只介绍其中我们会用到的几种。 算数运算 c中的算数运算有九个&a…...

拓扑未来物联网平台简介
拓扑未来物联网平台是基于Thingsboard二次开发的面向产业互联和智慧生活应用的物联网PaaS平台,支持适配各种网络环境和协议类型,可实现各种传感器和智能硬件的快速接入。有效降低物联网应用开发和部署成本,满足物联网领域设备连接、智能化改造…...
)
软件测试经理工作日常随记【7】-接口+UI自动化(多端集成测试)
软件测试经理工作日常随记【7】-UI自动化(多端集成测试) 自动化测试前篇在此 前言 今天开这篇的契机是,最近刚好是运维开发频繁更新证书的,每次更新都在0点,每次一更新都要走一次冒烟流程。为了不让我的美容觉被阉割…...
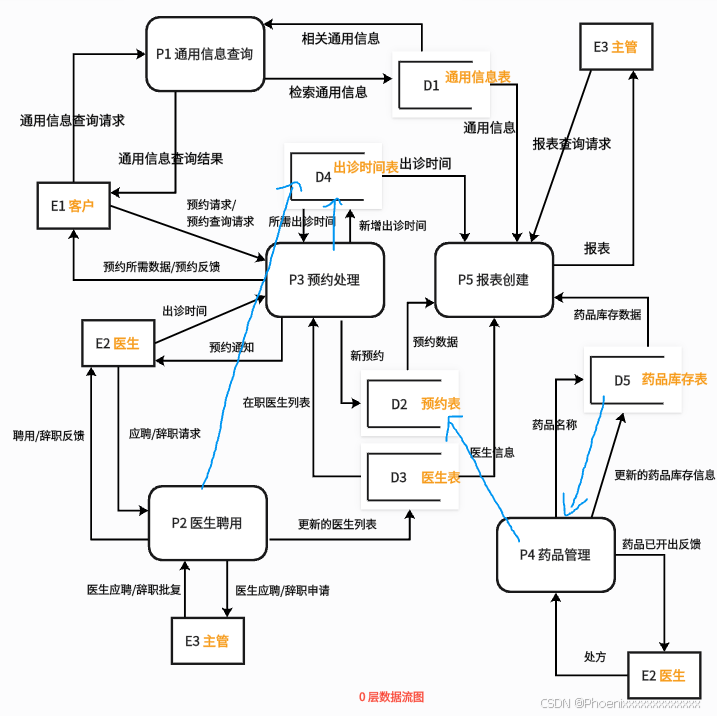
软考:软件设计师 — 9.数据流图
九. 数据流图 数据流图是下午场考试中第一个题目,分值 15 分。通常会考察实体名、存储名、加工名的补充,以及找到缺失的数据流并改正等。 1. 数据平衡原则 数据流的分析依赖于数据平衡原则。 父图与子图之间的平衡 父图与子图之间平衡是指任何一张 …...
收银系统源码-门店折扣活动应该怎么做
系统概况: 专门为零售行业的连锁店量身打造的收银系统,适用于常规超市、生鲜超市、水果店、便利店、零食专卖店、服装店、母婴用品、农贸市场等类型的门店使用。同时线上线下数据打通,线下收银的数据与小程序私域商城中的数据完全同步&#…...
Python数值计算(12)——线性插值
1. 概述 插值是根据已知的数据序列(可以理解为你坐标中一系列离散的点),找到其中的规律,然后根据找到的这个规律,来对其中尚未有数据记录的点进行数值估计的方法。最简单直观的一种插值方式是线性插值,它是…...

TypeScript(switch判断)
1.switch 语法用法 switch是对某个表达式的值做出判断。然后决定程序执行哪一段代码 case语句中指定的每个值必须具有与表达式兼容的类型 语法switch(表达式){ case 值1: 执行语句块1 break; case 值2: 执行语句块3 break; dfault: //如…...

血细胞自动检测与分类系统:深度学习与UI界面的结合
一、项目概述 项目背景 在医学实验室中,血细胞的检测和分类是诊断和研究的重要环节。传统方法依赖于人工显微镜检查,费时且容易出现误差。通过深度学习技术,特别是目标检测模型YOLO,可以实现自动化、快速且准确的血细胞检测和分…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...