AI大模型需要什么样的数据?
数据将是未来AI大模型竞争的关键要素
人工智能发展的突破得益于高质量数据的发展。例如,大型语言模型的最新进展依赖于更高质量、更丰富的训练数据集:与GPT-2相比,GPT-3对模型架构只进行了微小的修改,但花费精力收集更大的高质量数据集进行训练。ChatGPT与GPT-3的模型架构类似,并使用RLHF(来自人工反馈过程的强化学习)来生成用于微调的高质量标记数据。

人工智能领域以数据为中心的AI,即在模型相对固定的前提下,通过提升数据的质量和数量来提升整个模型的训练效果。提升数据集质量的方法主要有:添加数据标记、清洗和转换数据、数据缩减、增加数据多样性、持续监测和维护数据等。未来数据成本在大模型开发中的成本占比或将提升,主要包括数据采集,清洗,标注等成本。
图片以数据为中心的 AI:模型不变,通过改进数据集质量提升模型效果
AI大模型需要高质量、大规模、多样性的数据集
1)高质量:高质量数据集能够提高模型精度与可解释性,并且减少收敛到最优解的时间,即减少训练时长。
2)大规模:OpenAI 在《Scaling Laws for Neural Language Models》中提出 LLM 模型所遵循的“伸缩法则”(scaling law),即独立增加训练数据量、模型参数规模或者延长模型训练时间,预训练模型的效果会越来越好。
3)丰富性:数据丰富性能够提高模型泛化能力,过于单一的数据会非常容易让模型过于拟合训练数据。

数据集如何产生
建立数据集的流程主要分为 1)数据采集;2)数据清洗:由于采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题;3)数据标注:最重要的一个环节;4)模型训练:模型训练人员会利用标注好的数据训练出需要的算法模型;5)模型测试:审核员进行模型测试并将测试结果反馈给模型训练人员,而模型训练人员通过不断地调整参数,以便获得性能更好的算法模型;6)产品评估:产品评估人员使用并进行上线前的最后评估。
数据采集
采集的对象包括视频、图片、音频和文本等多种类型和多种格式的数据。数据采集目前常用的有三种方式,分别为:1)系统日志采集方法;2)网络数据采集方法;3)ETL。
图片
数据清洗
数据清洗是提高数据质量的有效方法。由于采集到的数据可能存在缺失值、噪声数据、重复数据等质量问题,故需要执行数据清洗任务,数据清洗作为数据预处理中至关重要的环节,清洗后数据的质量很大程度上决定了 AI 算法的有效性。
图片
数据标注
数据标注是流程中最重要的一个环节。管理员会根据不同的标注需求,将待标注的数据划分为不同的标注任务。每一个标注任务都有不同的规范和标注点要求,一个标注任务将会分配给多个标注员完成。
图片
图片
模型训练与测试
最终通过产品评估环节的数据才算是真正过关。产品评估人员需要反复验证模型的标注效果,并对模型是否满足上线目标进行评估。
图片
主要大语言模型数据集
参数量和数据量是判断大模型的重要参数。2018 年以来,大语言模型训练使用的数据集规模持续增长。2018 年的 GPT-1 数据集约 4.6GB,2020 年的 GPT-3 数据集达到了 753GB,而到了 2021 年的 Gopher,数据集规模已经达到了 10,550GB。总结来说,从 GPT-1 到LLaMA 的大语言模型数据集主要包含六类:维基百科、书籍、期刊、Reddit 链接、CommonCrawl 和其他数据集。
维基百科
维基百科是一个免费的多语言协作在线百科全书。维基百科致力于打造包含全世界所有语言的自由的百科全书,由超三十万名志愿者组成的社区编写和维护。截至2023年3月,维基百科拥有332种语言版本,总计60,814,920条目。其中,英文版维基百科中有超过664万篇文章,拥有超4,533万个用户。维基百科中的文本很有价值,因为它被严格引用,以说明性文字形式写成,并且跨越多种语言和领域。一般来说,重点研究实验室会首先选取它的纯英文过滤版作为数据集。

书籍
书籍主要用于训练模型的故事讲述能力和反应能力,包括小说和非小说两大类。数据集包括ProjectGutenberg和Smashwords(TorontoBookCorpus/BookCorpus)等。ProjectGutenberg是一个拥有7万多本免费电子书的图书馆,包括世界上最伟大的文学作品,尤其是美国版权已经过期的老作品。BookCorpus以作家未出版的免费书籍为基础,这些书籍来自于世界上最大的独立电子书分销商之一的Smashwords。
期刊
期刊可以从ArXiv和美国国家卫生研究院等官网获取。预印本和已发表期刊中的论文为数据集提供了坚实而严谨的基础,因为学术写作通常来说更有条理、理性和细致。ArXiv是一个免费的分发服务和开放获取的档案,包含物理、数学、计算机科学、定量生物学、定量金融学、统计学、电气工程和系统科学以及经济学等领域的2,235,447篇学术文章。美国国家卫生研究院是美国政府负责生物医学和公共卫生研究的主要机构,支持各种生物医学和行为研究领域的研究,从其官网的“研究&培训”板块能够获取最新的医学研究论文。
WebText(来自Reddit链接)
Reddit链接代表流行内容的风向标。Reddit是一个娱乐、社交及新闻网站,注册用户可以将文字或链接在网站上发布,使它成为了一个电子布告栏系统。WebText是一个大型数据集,它的数据是从社交媒体平台Reddit所有出站链接网络中爬取的,每个链接至少有三个赞,代表了流行内容的风向标,对输出优质链接和后续文本数据具有指导作用。
Commoncrawl/C4
Commoncrawl是2008年至今的一个网站抓取的大型数据集。CommonCrawl是一家非盈利组织,致力于为互联网研究人员、公司和个人免费提供互联网副本,用于研究和分析,它的数据包含原始网页、元数据和文本提取,文本包含40多种语言和不同领域。重点研究实验室一般会首先选取它的纯英文过滤版(C4)作为数据集。
其他数据集
ThePile数据集:一个825.18GB的英语文本数据集,用于训练大规模语言模型。ThePile由上文提到的ArXiv、WebText、Wikipedia等在内的22个不同的高质量数据集组成,包括已经建立的自然语言处理数据集和几个新引入的数据集。除了训练大型语言模型外,ThePile还可以作为语言模型跨领域知识和泛化能力的广泛覆盖基准。其他数据集包含了GitHub等代码数据集、StackExchange等对话论坛和视频字幕数据集等。
多模态数据集
模态是事物的一种表现形式,多模态通常包含两个或者两个以上的模态形式,包括文本、图像、视频、音频等。多模态大模型需要更深层次的网络和更大的数据集进行预训练。过去数年中,多模态大模性参数量及数据量持续提升。
语音+文本
SEMAINE数据集:创建了一个大型视听数据库,作为构建敏感人工侦听器(SAL)代理的迭代方法的一部分,该代理可以使人参与持续的、情绪化的对话。高质量的录音由五台高分辨率、高帧率摄像机和四个同步录制的麦克风提供。录音共有150个参与者,总共有959个与单个SAL角色的对话,每个对话大约持续5分钟。固体SAL录音被转录和广泛注释:每个剪辑6-8个评分者追踪5个情感维度和27个相关类别。
图像+文本
COCO数据集:MSCOCO的全称是MicrosoftCommonObjectsinContext,起源于微软于2014年出资标注的MicrosoftCOCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。图像包括91类目标,328,000张图像和2,500,000个label。ConceptualCaptions数据集:图像标题注释数据集,其中包含的图像比MS-COCO数据集多一个数量级,并代表了更广泛的图像和图像标题风格。通过从数十亿个网页中提取和过滤图像标题注释来实现这一点。
ImageNet数据集:建立在WordNet结构主干之上的大规模图像本体。ImageNet的目标是用平均5,001,000张干净的全分辨率图像填充WordNet的80,000个同义词集中的大多数。这将产生数千万个由WordNet语义层次结构组织的注释图像。ImageNet的当前状态有12个子树,5247个同义词集,总共320万张图像。
LAION-400M数据集:LAION-400M通过CommonCrawl提取出随机抓取2014-2021年的网页中的图片、文本内容。通过OpenAI的Clip计算,去除了原始数据集中文本和图片嵌入之间预先相似度低于0.3的内容和文本,提供了4亿个初筛后的图像文本对样本。
图片
LAION-5B数据集:包含58.5亿个CLIP过滤的图像-文本对的数据集,比LAION-400M大14倍,是世界第一大规模、多模态的文本图像数据集,共80T数据,
图片
LanguageTable数据集:Language-Table是一套人类收集的数据集,是开放词汇视觉运动学习的多任务连续控制基准。
IAPRTC-12数据集:IAPRTC-12基准的图像集合包括从世界各地拍摄的2万张静态自然图像,包括各种静态自然图像的横截面。这包括不同运动和动作的照片,人物、动物、城市、风景和当代生活的许多其他方面的照片。示例图像可以在第2节中找到。每张图片都配有最多三种不同语言(英语、德语和西班牙语)的文本标题。
视频+图像+文本
YFCC100数据集:YFCC100M是一个包含1亿媒体对象的数据集,其中大约9920万是照片,80万是视频,所有这些都带有创作共用许可。数据集中的每个媒体对象都由几块元数据表示,例如Flickr标识符、所有者名称、相机、标题、标签、地理位置、媒体源。从2004年Flickr成立到2014年初,这些照片和视频是如何被拍摄、描述和分享的,这个集合提供了一个全面的快照。
图像+语音+文本
CH-SIMS数据集:CH-SIMS是中文单模态和多模态情感分析数据集,包含2,281个精细化的野外视频片段,既有多模态注释,也有独立单模态注释。它允许研究人员研究模态之间的相互作用,或使用独立的单模态注释进行单模态情感分析。
视频+语音+文本
IEMOCAP数据集:南加州大学语音分析与解释实验室(SAIL)收集的一种新语料库,名为“上的二元会话,这些标记提供了他们在脚本和自发口语交流场景中面部表情和手部动作的详细信息。语料库包含大约12小时的数据。详细的动作捕捉信息、激发真实情绪的交互设置以及数据库的大小使这个语料库成为社区中现有数据库的有价值的补充,用于研究和建模多模态和富有表现力的人类交流。
相关文章:
AI大模型需要什么样的数据?
数据将是未来AI大模型竞争的关键要素 人工智能发展的突破得益于高质量数据的发展。例如,大型语言模型的最新进展依赖于更高质量、更丰富的训练数据集:与GPT-2相比,GPT-3对模型架构只进行了微小的修改,但花费精力收集更大的高质量…...

Java每日一练_模拟面试题1(死锁)
一、死锁的条件 死锁通常发生在两个或者更多的线程相互等待对方释放资源,从而导致它们都无法继续执行。死锁的条件通常被描述为四个必要条件,也就是互斥条件、不可剥夺条件、占有并等待条件和循环等待条件。 互斥条件:资源不能被共享&#x…...

第三方库认识- Mysql 数据库 API 认识
文章目录 一、msyql数据库API接口1.初始化mysql_init()——mysql_init2.链接数据库mysql_real_connect——mysql_real_connect3.设置当前客户端的字符集——mysql_set_character_set4.选择操作的数据库——mysql_select_db5.执行sql语句——mysql_query6.保存查询结果到本地——…...

Python兼职接单全攻略:掌握技能,拓宽收入渠道
引言 随着Python在数据处理、Web开发、自动化办公、爬虫技术等多个领域的广泛应用,越来越多的人开始利用Python技能进行兼职接单,以此拓宽收入渠道。本文将详细介绍Python兼职接单的注意事项、所需技能水平、常见单子类型、接单途径及平台,帮…...

一键编译并启动一个 ARM Linux qemu 虚拟机
需要事先自己编译 qemu-system-arm 可执行文件; 1,编译创建ARM 虚拟机 #!/usr/bin/bash sudo lssudo apt-get install gcc-arm-linux-gnueabi#wget https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.10.tar.gztar zxf linux-kernel-v5.10…...
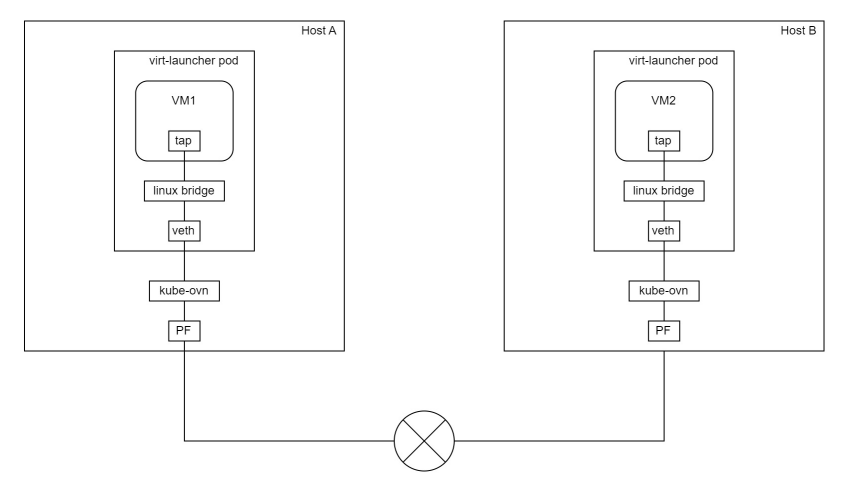
KubeVirt虚拟机存储及网络卸载加速解决方案
1. 方案背景 1.1. KubeVirt介绍 随着云计算和容器技术的飞速发展,Kubernetes已成为业界公认的容器编排标准,为用户提供了强大、灵活且可扩展的平台来部署和管理各类应用。然而,在企业的实际应用中,仍有许多传统应用或遗留系统难…...

JVM—对象已死?
参考资料:深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)周志明 在堆里面存放着 Java 世界中几乎所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象之中哪些还“存活”着,哪些已经“死去”。 1、如何判…...

【前端面试3+1】20 css三栏布局6种实现方式、多行文本溢出怎么实现、token过期了怎么处理、【二叉树的中序遍历】
一、css三栏布局6种实现方式 1.浮动布局(Floats) .container {overflow: auto; /* 清除浮动 */ }.left, .right {width: 20%; /* 左右栏宽度 */float: left; }.middle {width: 60%; /* 中间栏宽度 */margin: 0 20%; /* 左右栏宽度 */ } 2.Flexbox .conta…...
)
【C++】vector介绍以及模拟实现(超级详细<=>源码并存)
欢迎来到我的Blog,点击关注哦💕 【C】vector介绍以及模拟实现 前言vector介绍 vector常见操作构造函数iteratorcapacitymodify vector模拟实现存储结构默认构造函数构造函数拷贝构造函数赋值运算符重载析构函数 容量(capacity)si…...

【Redis 进阶】主从复制(重点理解流程和原理)
在分布式系统中为了解决单点问题(某个服务器程序只有一个节点(只搞一个物理服务器来部署这个服务器程序)。可用性不高:如果这个机器挂了意味着服务就中断了;性能 / 支持的并发量比较有限)。通常会把数据复制…...
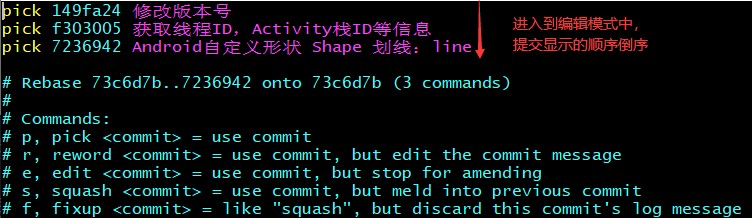
Git常用命
转自:https://blog.csdn.net/ahjxhy2010/article/details/80047553 1.查看某个文件或目录的修改历史 git log filename #查看fileName相关的commit记录 git log -p filenam # 显示每次提交的diff#只看某次提交中的某个文件变化,commit-id 文件名…...
强化学习时序差分算法之Q-learning算法——以悬崖漫步环境为例
0.简介 基于时序差分算法的强化学习算法除了Sarsa算法以外还有一种著名算法为Q-learning算法,为离线策略算法,与在线策略算法Sarsa算法相比,其时序差分更新方式变为 Q(St,At)←Q(St,At)α[Rt1γmaxaQ(St1,a)−Q(St,At)] 对于 Sarsa 来说&am…...

111推流111
推流推流...

刷题——数组中只出现一次的两个数字
数组中只出现一次的两个数字_牛客题霸_牛客网 描述 一个整型数组里除了两个数字只出现一次,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。 数据范围:数组长度 2≤n≤10002≤n≤1000,数组中每个数的大小 0<val≤100000…...

《剖析程序员面试“八股文”:助力、阻力还是噱头?》
#“八股文”在实际工作中是助力、阻力还是空谈? 作为现在各类大中小企业面试程序员时的必问内容,“八股文”似乎是很重要的存在。但“八股文”是否能在实际工作中发挥它“敲门砖”应有的作用呢?有IT人士不禁发出疑问:程序员面试考…...

Redis过期key的删除策略
在 Redis 中,设置了过期时间的键在过期时间到达后,并不会立即从内存中删除。如果不是,那过期后到底什么时候被删除呢? 下面对这三种删除策略进行具体分析。 立即删除: 立即删除能够保证内存数据的及时性和空间的有效…...

软件管理
设备挂载在目录下才可以读 挂载类似于将u盘插在电脑上 mount /dev/sr0 /opt/openeuler/ vim /etc/rc.d/rc.local #开机自运行脚本,将挂载命令写入脚本,并给这个脚本执行权限 chmod x /etc/rc.d/rc.local [rootlocalhost ~]# cd /etc/yum.repos.d/ […...

【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路
【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路 本文对可完成赛事“逻辑推理赛道:复杂推理能力评估”初赛的Baseline2部分关键代码进行详细解读,介绍Baseline2涉及的关键技术和初步上分思路。 Baseline2代码由Datawhal…...

软件测试——测试分类(超超超齐全版)
为什么要对软件测试进行分类 软件测试是软件⽣命周期中的⼀个重要环节,具有较⾼的复杂性,对于软件测试,可以从不同的⻆度加以分类,使开发者在软件开发过程中的不同层次、不同阶段对测试⼯作进⾏更好的执⾏和管理测试的分类⽅法。…...
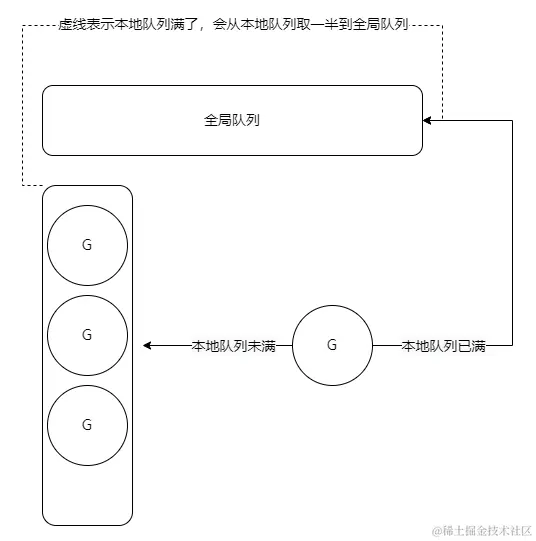
深入解析 Go 语言 GMP 模型:并发编程的核心机制
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:点击跳转到网站,对人工智能感兴趣的小伙伴可以点进去看看。 前言 本章是Go并发编程的起始篇章,在未来几篇文章中我们会…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...