SolverLearner:提升大模型在高度归纳推理的复杂任务性能,使其能够在较少的人为干预下自主学习和适应
SolverLearner:提升大模型在高度归纳推理的复杂任务性能,使其能够在较少的人为干预下自主学习和适应
- 提出背景
- 归纳推理(Inductive Reasoning)
- 演绎推理(Deductive Reasoning)
- 反事实推理(Counterfactual Reasoning)
- 区别
- 效果
- 归纳推理在医学中的应用
- 演绎推理在医学中的应用
- 反事实推理在医学中的应用
- SolverLearner的工作原理
- 如何使用SolverLearner
- 具体用法
- 场景描述
- 步骤 1: 数据准备
- 步骤 2: 实现SolverLearner
- Python实现示例
论文:https://arxiv.org/html/2408.00114v1
提出背景
推理主要分为演绎推理和归纳推理两种形式。
尽管已有众多研究探讨大模型的推理能力,但这些研究往往没有明确区分这两种推理类型,造成了一定的混淆。
这就引出了一个关键问题:在 LLM 的推理过程中,演绎推理和归纳推理哪个更具挑战性?
虽然大家普遍关注了 LLM 在执行演绎推理任务时的表现,但它们在归纳推理方面的能力尚未得到充分研究。
为此,我们提出了一个名为 SolverLearner 的新框架,通过这个框架,LLM 可以仅凭现有例子学习输入与输出之间的关系。
通过专注于研究归纳推理,我们能够更清晰地了解 LLM 在这一领域的表现。
结果显示,LLM 通过 SolverLearner 在归纳推理上取得了接近完美的表现。
然而,令人意外的是,尽管 LLM 在归纳推理方面表现出色,它们在处理一些需要反思考的演绎推理任务时表现却相对较弱。
近年来,随着像 GPT-3 和 ChatGPT 这样的大模型的发展,自然语言处理领域取得了显著的进步。
这些模型在多种任务上展现出了印象深刻的推理能力,但在某些领域仍存在挑战。
例如,一项最新研究显示,尽管这些模型在常规任务如十进制算术上表现优异,但在处理偏离常规的“反事实”推理任务时,如九进制算术,准确性会明显下降。
目前还不清楚这些模型是否真正具备基本推理能力,还是仅仅依赖于近似检索。
基于这个现象,我们的研究旨在深入探讨大型语言模型的推理能力。
推理分为演绎推理和归纳推理两种类型。
演绎推理从一般假设出发,推导出具体结论;归纳推理则是从观察到的实例中归纳出一般性原则。
尽管对这些模型的推理能力已有广泛研究,但很少有研究清楚地区分这两种推理类型。
比如,在算术推理任务中,模型主要是应用数学概念来解题,这更多体现了演绎推理。
然而,当模型通过几个例子进行学习时,其表现的提升往往被归功于归纳推理。
这种推理方式的混合提出了一个关键问题:在大型语言模型的推理中,演绎推理和归纳推理哪个的局限性更大?
为了回答这个问题,区分这两种推理方式至关重要。
当前的研究方法往往依赖于不同的数据集,直接比较存在挑战。
为了解决这一点,我们设计了一系列比较实验,这些实验在不同的上下文中使用一致的任务,分别强调演绎和归纳推理。
例如,在算术任务中,模型的演绎推理能力取决于其如何应用明确给出的输入输出映射函数来解决问题。
而归纳推理的能力则是模型如何基于几个示例推断出这些映射关系。
根据这种设定,我们采用了四种方法来详细研究模型的推理能力,从演绎推理到归纳推理逐步过渡。
最新的研究发现,虽然模型在使用输入输出示例进行归纳推理时面临困难,但这些困难可能与演绎推理能力不足有关,而不仅仅是归纳推理本身。
为了更好地区分这两种推理,我们提出了一个名为 SolverLearner 的新模型,专注于归纳推理。
该模型通过一个两步过程,首先学习输入输出映射函数,然后再应用这些函数进行推理,确保避开基于模型本身的演绎推理。
我们对几种大型语言模型在多个任务上的表现进行了评估,结果显示这些模型通过 SolverLearner 展现了出色的归纳推理能力,多数情况下几乎达到完美表现。
然而,尽管在归纳推理上表现强劲,这些模型在演绎推理,尤其是在“反事实”推理方面的能力相对较弱。
这一发现虽然出乎意料,但与之前的研究结果是一致的。
在没有任何先验例子的情况下,模型执行任务的能力很大程度上依赖于其在预训练阶段的训练频率。
归纳推理(Inductive Reasoning)
归纳推理是从具体的观察中推导出一般性结论的过程。
这种推理方式不尝试证明结论的绝对真实性,而是提供了使结论可能为真的支持性证据。
归纳推理的特点是从个别案例或实例出发,总结出普遍规律或原则。
例如,如果一个人观察到几次日出都是从东方开始的,他可能会归纳出“太阳总是从东方升起”的结论。
演绎推理(Deductive Reasoning)
演绎推理是从一般到个别的推理过程,它从一个或多个前提出发,通过逻辑推理得出结论。
这种推理方式如果前提正确且推理合逻辑,其结论则必定正确。
例如,所有哺乳动物都有心脏(前提一),所有狗都是哺乳动物(前提二),因此所有狗都有心脏(结论)。
反事实推理(Counterfactual Reasoning)
反事实推理涉及对“如果情况不同会怎样”这类问题的思考。
它基于对现实世界事件的假设性改变,探讨这些改变可能带来的后果。
反事实推理通常用于分析因果关系、做出决策和解决问题。
例如,一个人可能会思考:“如果我当时没有选择这份工作,我的生活会怎样不同?”这种推理帮助人们评估不同选择的潜在结果。
这三种推理方式在日常生活和科学研究中都非常重要,它们各自有独特的应用领域和限制。
在人工智能和机器学习中,有效地整合和应用这些推理方式对于提高模型的决策能力和适应性至关重要。
区别
对大模型而言,演绎推理和归纳推理哪个更有挑战性?
这两种推理的主要区别在于我们是否向模型明确展示了输入到输出的映射关系。
简单来说,这些映射可以视为一个函数 f_w: X → Y,其中输入 x 转换成输出 y。
我们根据是否提供直接的映射关系来区分演绎和归纳推理:
- 演绎推理:我们直接向模型提供输入输出的映射关系(即 f_w)。
- 归纳推理:我们给模型展示一些例子(即 x, y 对),但刻意不提供输入输出的映射关系。
比如在算术任务中,基数系统就是输入输出的映射函数。
效果

SolverLearner 性能 1.
├── 性能评估【结果概览】
在本研究中,我们利用SolverLearner框架对LLMs在各种推理任务上的表现进行了测试。
结果显示,LLMs在处理标准演绎推理任务时表现出一定的局限性,但在归纳推理任务中显示出较强的能力,特别是当使用SolverLearner框架时,模型能够有效学习并应用新的知识。
└── 演绎与归纳结果【比较分析】
通过对演绎和归纳推理任务的比较分析,我们发现LLMs在归纳推理上的表现通常优于演绎推理。
这一结果暗示了在设计和训练LLMs时,增强模型的归纳推理能力可能是提升其整体性能的关键。
└── LLMs在复杂任务中的能力【洞察】
我们的研究讨论了LLMs在处理一些复杂推理任务时表现出的挑战和局限。
尽管LLMs能够处理大量数据并从中提取信息,但它们在需要深层次逻辑推理和处理较少见数据模式的任务上仍面临困难。
这一发现提示我们,在未来的模型训练中需要更多地考虑如何提高模型的适应性和推理深度。
归纳推理在医学中的应用
归纳推理在医学问诊中非常关键,它帮助医生从有限的患者信息中推断可能的疾病或病因。例如:
- 病例相似性分析:LLMs可以通过分析大量类似病例来识别症状的模式,从而帮助医生理解一个新患者的病情可能属于哪种已知的病症范畴。
- 疾病预测:通过归纳过去患者的数据,LLMs能够预测某些症状可能导致的疾病,即使这种联系在医学文献中不是非常明显。
演绎推理在医学中的应用
演绎推理用于从已知的医学知识出发,应用具体的医学原则和规则来解决个别病例。例如:
- 诊断逻辑推理:基于具体的症状和测试结果,LLMs能够应用医学知识库中的规则来逐步推导并确认疾病的类型。
- 治疗规划:根据确诊的疾病,演绎出最合适的治疗方案,包括药物、手术或其他治疗方法。
反事实推理在医学中的应用
反事实推理在医学决策中提供了考虑不同诊断和治疗路径的可能后果的能力。例如:
- 治疗方案比较:探索如果采取不同的治疗方法,患者健康结果可能如何变化。
- 风险评估:评估如果忽略某些症状或测试结果,可能会错过的诊断或治疗机会。
SolverLearner框架旨在通过专注于从上下文示例中学习,而不依赖于明确的演绎推理过程,来增强大型语言模型(LLMs)的归纳推理能力。
SolverLearner的工作原理
-
函数提议阶段:
- 目的:此阶段旨在假设一个将输入数据点映射到各自输出值的函数。这个函数不是由用户提供的,而是需要LLM从给定的示例中推断出来。
- 过程:LLM使用提供的上下文示例来学习或提出一个解释输入如何与输出相关的函数。
-
函数执行阶段:
- 目的:一旦提出了函数,就需要测试它以确保对训练集之外的其他数据点也能正确工作。
- 过程:使用外部工具(如代码解释器)执行提议的函数,以保持归纳推理过程的纯净性。这种设置确保模型不依赖于可能拥有的任何内置演绎推理能力。
如何使用SolverLearner
要有效使用SolverLearner,通常需要遵循以下步骤:
- 设置您的数据:准备您的数据集,明确定义输入及其相应的输出示例。这些示例不应明确包括将输入映射到输出的函数或公式。
- 实施SolverLearner:在您的LLM环境中整合SolverLearner框架。这涉及调整模型以分别处理函数提议和执行的两个阶段。
- 训练模型:允许LLM与提供的示例互动,以学习和提议潜在的映射函数。这种训练专注于归纳推理。
- 测试函数:使用外部解释器应用LLM提议的函数到新的示例上,并验证其准确性。这一测试阶段应与学习阶段明确区分,以避免演绎推理的污染。
- 评估性能:评估LLM从有限示例中泛化的能力,以及它开发将输入映射到输出的函数的准确性。
通过专注于归纳推理并将其与通常嵌入在LLMs中的演绎推理过程分离,SolverLearner旨在增强这些模型的纯归纳推理能力。
这种方法在需要从有限数据中理解潜在模式或原则的场景中特别有用,如在解决新问题或从实验数据中学习新的科学原理等情况。
表3:空间推理任务的提示语。
Zero-shot
您位于一个房间的中央,可以假设房间的宽度和高度都是500单位。房间的布局如下:
‘名称’:‘卧室’,‘宽度’:500,‘高度’:500,‘方向’:‘北’:[0, 1],‘南’:[0, -1],‘东’:[1, 0],‘西’:[-1, 0],‘物体’:[‘名称’:‘椅子’,‘方向’:‘东’,‘名称’:‘衣柜’,‘方向’:‘北’,‘名称’:‘书桌’,‘方向’:‘南’]
请根据物体的描述位置,使用常规的2D坐标系统提供物体的坐标,格式如下:
[‘名称’:‘椅子’,‘x’:‘?’,‘y’:‘?’,‘名称’:‘衣柜’,‘x’:‘?’,‘y’:‘?’,‘名称’:‘书桌’,‘x’:‘?’,‘y’:‘?’]
Few-shot IO w/ MF(带映射功能的少样本输入输出)
您是一位专业的程序员,位于一个房间的中央,可以假设房间的宽度和高度都是500单位。房间的布局如下:
‘名称’:‘洗衣房’,‘宽度’:500,‘高度’:500,‘方向’:‘北’:[0, 1],‘南’:[0, -1],‘东’:[1, 0],‘西’:[-1, 0],‘物体’:[‘名称’:‘烘干机’,‘方向’:‘东’,‘名称’:‘水槽’,‘方向’:‘西’,‘名称’:‘洗衣机’,‘方向’:‘南’]
请根据物体的描述位置,使用常规的2D坐标系统提供物体的坐标,如下示例所示:
[‘名称’:‘烘干机’,‘x’:500,‘y’:250,‘名称’:‘水槽’,‘x’:0,‘y’:250,‘名称’:‘洗衣机’,‘x’:250,‘y’:0]
根据以上示例,请给出以下房间中物体的坐标,使用相同的格式:
‘名称’:‘卧室’,‘宽度’:500,‘高度’:500,‘物体’:[‘名称’:‘椅子’,‘方向’:‘东’,‘名称’:‘衣柜’,‘方向’:‘北’,‘名称’:‘书桌’,‘方向’:‘南’]
Few-shot IO w/o MF(无映射功能的少样本输入输出)
您位于一个房间的中央,可以假设房间的宽度和高度都是500单位。房间的布局如下:
‘名称’:‘洗衣房’,‘宽度’:500,‘高度’:500,‘物体’:[‘名称’:‘烘干机’,‘方向’:‘东’,‘名称’:‘水槽’,‘方向’:‘西’,‘名称’:‘洗衣机’,‘方向’:‘南’]
请根据物体的描述位置,使用常规的2D坐标系统提供物体的坐标,如下示例所示:
[‘名称’:‘烘干机’,‘x’:500,‘y’:250,‘名称’:‘水槽’,‘x’:0,‘y’:250,‘名称’:‘洗衣机’,‘x’:250,‘y’:0]
根据以上示例,请给出以下房间中物体的坐标,使用相同的格式:
‘名称’:‘卧室’,‘宽度’:500,‘高度’:500,‘物体’:[‘名称’:‘椅子’,‘方向’:‘东’,‘名称’:‘衣柜’,‘方向’:‘北’,‘名称’:‘书桌’,‘方向’:‘南’]
SolverLearner
您是一位专业程序员,位于一个房间的中央,可以假设房间的宽度和高度都是500单位。房间的布局如下:‘名称’:‘洗衣房’,‘宽度’:500,‘高度’:500,‘物体’:[‘名称’:‘烘干机’,‘方向’:‘东’,‘名称’:‘水槽’,‘方向’:‘西’,‘名称’:‘洗衣机’,‘方向’:‘南’]
请根据物体的描述位置,使用常规的2D坐标系统提供物体的坐标,如下示例所示:
[‘名称’:‘烘干机’,‘x’:500,‘y’:250,‘名称’:‘水槽’,‘x’:0,‘y’:250,‘名称’:‘洗衣机’,‘x’:250,‘y’:0]
请总结这种布局模式并实现一个 solver() 函数来实现目标。
def solver():# 逐步编写Python程序# 输入是房间的布局# 输出是物体的坐标
定义 solver() 函数后,请将该函数放置在 “START_CODE” 和 “END_CODE” 之间。
具体用法
当然可以。让我们使用一个简单的文本分类任务作为示例,展示如何应用SolverLearner框架来训练一个模型,使其能够通过归纳学习来识别文本情感(正面或负面)。这个任务不涉及数学运算,而是关注于文本处理和模式识别。
场景描述
假设我们有一组文本数据,每条数据都标记为正面或负面情感。我们希望模型能从提供的例子中学习如何区分文本的情感倾向。
步骤 1: 数据准备
- 数据:准备一组标记了情感的文本数据。例如:
- “I love this product!” (Positive)
- “This is the worst experience ever.” (Negative)
步骤 2: 实现SolverLearner
SolverLearner框架的实现需要设计一个训练过程,让模型从提供的示例中学习如何识别文本的情感。
- 学习阶段:模型使用少量的标记数据来学习文本的情感分类。
- 执行阶段:验证模型是否能准确地将学到的规则应用于新的、未见过的文本。
Python实现示例
这里,我们将使用一个非常简化的Python代码示例,展示如何实现这一过程:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNBdef solver(train_data, train_labels):# 文本向量化vectorizer = CountVectorizer()X_train = vectorizer.fit_transform(train_data)# 训练朴素贝叶斯分类器classifier = MultinomialNB()classifier.fit(X_train, train_labels)# 返回训练好的模型和向量化工具,以便后续处理新文本return classifier, vectorizer# 训练数据
train_data = ["I love this product!", "This is the worst experience ever."]
train_labels = ["Positive", "Negative"]# 学习阶段
classifier, vectorizer = solver(train_data, train_labels)# 测试阶段
def test_new_text(text):X_test = vectorizer.transform([text])prediction = classifier.predict(X_test)return prediction[0]# 测试新文本
print(test_new_text("I hate this!")) # 预期输出: 'Negative'
print(test_new_text("Fantastic, good job!")) # 预期输出: 'Positive'
在这个例子中,我们使用了朴素贝叶斯分类器来学习如何根据训练数据中的示例区分文本的情感。
学习阶段涉及模型的训练和向量化工具的设置,而执行阶段则是使用这些工具和模型来预测新文本的情感。
这个例子简单地展示了SolverLearner框架在文本分类任务中的应用,帮助模型通过有限的例子来学习并推广知识。
在实际应用中,你可以扩展这个框架,使用更复杂的模型和更大的数据集来处理更多样化的文本分类任务。
SolverLearner 可以被视为一种通过机器学习模型进行推理和学习的方法论,特别适用于需要模型进行高级推理和归纳学习的复杂问题。
相关文章:
SolverLearner:提升大模型在高度归纳推理的复杂任务性能,使其能够在较少的人为干预下自主学习和适应
SolverLearner:提升大模型在高度归纳推理的复杂任务性能,使其能够在较少的人为干预下自主学习和适应 提出背景归纳推理(Inductive Reasoning)演绎推理(Deductive Reasoning)反事实推理(Counterf…...

PHP智能问诊导诊平台-计算机毕业设计源码75056
摘 要 智能问诊导诊平台作为一种智能化医疗服务工具,利用PHP语言开发,旨在为用户提供便捷的在线问诊和导诊服务。该平台集成了智能算法和医疗数据,实现了智能化的病情诊断和治疗建议,帮助用户更快速地获取医疗信息和建议。用户可…...

数据结构初阶(c语言)-排序算法
数据结构初阶我们需要了解掌握的几种排序算法(除了直接选择排序,这个原因我们后面介绍的时候会解释)如下: 其中的堆排序与冒泡排序我们在之前的文章中已经详细介绍过并对堆排序进行了一定的复杂度分析,所以这里我们不再过多介绍。 一&#x…...

网络云相册实现--nodejs后端+vue3前端
目录 主页面 功能简介 系统简介 api 数据库表结构 代码目录 运行命令 主要代码 server apis.js encry.js mysql.js upload.js client3 index.js 完整代码 主页面 功能简介 多用户系统,用户可以在系统中注册、登录及管理自己的账号、相册及照片。 每…...

【JS】Object.defineProperty与Proxy
一、Object.defineProperty 这里只是简单描述,具体请看另一篇文章:Object.defineProperty。 Object.defineProperty 是 JavaScript 中用于定义或修改对象属性的功能强大的方法。它可以精确地控制属性的行为,如是否可枚举、可配置、可写等。…...

《计算机网络》(第8版)第8章 互联网上的音频/视频服务 复习笔记
第 8 章 互联网上的音频/视频服务 一、概述 1 多媒体信息的特点 多媒体信息(包括声音和图像信息)最主要的两个特点如下: (1)多媒体信息的信息量往往很大; (2)在传输多媒体数据时&a…...

linux进程控制——进程替换——exec函数接口
前言: 本节内容进入linux进程控制板块的最后一个知识点——进程替换。 通过本板块的学习, 我们了解了进程的基本控制方法——进程创建, 进程退出, 进程终止, 进程替换。 进程控制章节和上一节进程概念板块都是在谈进程…...
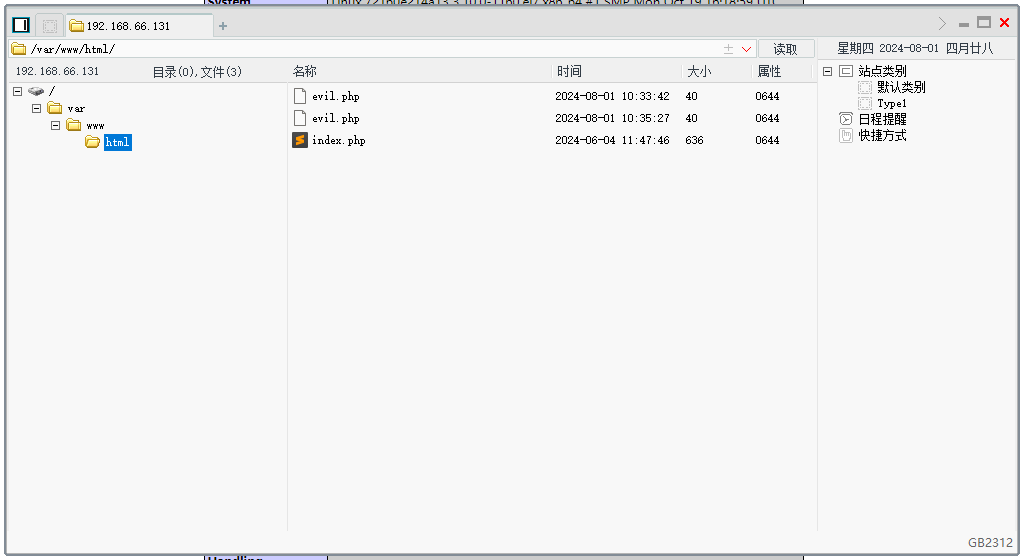
Apache解析漏洞~CVE-2017-15715漏洞分析
Apache解析漏洞 漏洞原理 # Apache HTTPD 支持一个文件拥有多个后缀,并为不同后缀执行不同的指令。比如如下配置文件: AddType text/html .html AddLanguage zh-CN .cn# 其给 .html 后缀增加了 media-type ,值为 text/html ;给 …...

Xilinx管脚验证流程及常见问题
1 流程 1.1 新建I/O Planning Project I/O Planning Project中可以不需要RTL的top层.v代码,仅图形化界面即可配置管脚约束XDC文件的生成: Create I/O Ports: 导出XDC文件和自动生成的top_interface.v文件: 1.2 新建test Project …...

格雷厄姆的《聪明的投资者》被誉为“投资圣经”
本杰明格雷厄姆的《聪明的投资者》(The Intelligent Investor: A Book of Practical Counsel)是投资领域的一部经典之作,被誉为“投资圣经”。以下是对该书的详细解析: 一、书籍基本信息 书名:《聪明的投资者》&…...

TypeScript声明文件
TypeScript声明文件 在JavaScript的生态系统中,随着项目的复杂度和规模不断增加,开发者对于类型安全和代码质量的追求也日益增长。TypeScript,作为JavaScript的一个超集,通过添加静态类型检查和ES6等新特性支持,极大地…...

.NET_WPF_使用Livecharts数据绑定图表
相关概念 LiveCharts 是一个开源的图表库,适用于多种 .NET 平台,包括 WPF、UWP、WinForms 等。LiveCharts 通过数据绑定与 MVVM 模式兼容,使得视图模型可以直接控制图表的显示,无需直接操作 UI 元素。这使得代码更加模块化&#x…...

一句JS代码,实现随机颜色的生成
今天我们只用 一句JS代码,实现随机颜色的生成,首先看一下效果: 每次刷新浏览器背景颜色都不一样 实现此效果的JS函数 : let randomColor () > ...: 定义一个箭头函数randomColor,用于生成一个随机颜色。 Math.ra…...

校园抢课助手【7】-抢课接口限流
在上一节中,该接口已经接受过风控的处理,过滤掉了机器人脚本请求,剩下都是人为的下单请求。为了防止用户短时间内高频率点击抢课链接,海量请求造成服务器过载,这里使用接口限流算法。 先介绍下几种常用的接口限流策略…...

char类型和int类型
一、char类型 在Java中,char(字符)类型用于表示单个字符,它是基本数据类型之一。以下是关于Java中char类型的一些重要信息: 表示方式: char类型用于存储Unicode字符,占用16位(即2个字…...

C++参悟:stl中的比较最大最小操作
stl中的比较最大最小操作 一、概述二、最小值1. min2. min_element 三、最大值1. max2. max_element 四、混合1. minmax2. minmax_element 一、概述 记录这里C11中常用的最小值和最大值的比较函数,最好的参考资料其实就是 https://zh.cppreference.com 最重要的查…...

JAVA读取netCdf文件并绘制热力图
读取netCdf的依赖 <dependency><groupId>ucar</groupId><artifactId>netcdfAll</artifactId><version>5.5.3</version><scope>system</scope><exclusions><exclusion><groupId>org.slf4j</groupId…...

数据结构——八大排序
一.排序的概念和其应用 1.1排序的概念 排序:排列或排序是将一组数据按照一定的规则或顺序重新组织的过程,数据既可以被组织成递增顺序(升序),或者递减顺序(降序)。稳定性:假定在待…...
流程与UI界面(终章))
【Unity】RPG2D龙城纷争(十九)流程与UI界面(终章)
更新日期:2024年8月1日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介一、游戏流程1.初始化流程2.开始流程3.关卡流程4.关卡结束流程5.启用所有流程二、UI界面逻辑1.开始界面2.存档界面3.关卡界面DataRegion 数据显示逻辑区域RoundRegion 回合逻辑区域RoleMenu…...

C#类和结构体的区别
1、类class是引用类型,多个引用类型变量的值会互相影响。存储在堆(heap)上 2、结构体struct是值类型,多个值类型变量的值不会互相影响。存储在栈(stack)上 类结构关键字classstruct类型引用类型值类型存储…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案
TV Bro电视浏览器:为智能电视打造的最佳遥控器上网解决方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 还在为智能电视上网操作不便而烦恼吗?…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...