数据结构之《二叉树》(中)
在数据结构之《二叉树》(上)中学习了树的相关概念,还了解的树中的二叉树的顺序结构和链式结构,在本篇中我们将重点学习二叉树中的堆的相关概念与性质,同时试着实现堆中的相关方法,一起加油吧!

1.实现顺序结构二叉树
在实现顺序结构的二叉树中通常把堆使用顺序结构的数组来存储,因此我们先要了解堆的概念与结构
1.1 堆的概念与结构
如果有一个关键码的集合 K = {k0 , k1 , k2 , ...,kn−1 } ,把它的所有元素按完全二叉树的顺序存储方式式存储,在⼀个⼀维数组中,并满足: Ki <= K2∗i+1 ( Ki >= K2∗i+1 且 Ki <= K2∗i+2 ),i = 0、1、2... ,则称为小堆(或大堆)。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
以上的堆的概念简单来说就是堆是完全二叉树,在大堆中根结点为最大的元素,在此之后的每个孩子结点都要小于或者等于它的父结点;在小堆中根结点为最小的元素,在此之后的每个孩子结点都要大于或者等于的父结点
因此通过堆的概念的了解需要知道堆有以下的性质:
• 堆中某个结点的值总是不大于或不小于其父结点的值
• 堆总是一棵完全二叉树
例如以下图示就是大堆,并且将其结点的数据存储到数组当中
以下图示就是小堆,并且将其结点的数据存储到数组当中


1.2二叉树的性质
在了解的堆的相关概念和结构后,之后我们要来实现堆,因此在此之前还要再了解二叉树的相关性质
💡 二叉树性质
• 对于具有 n 个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从0 开始编号,则对于序号为 i 的结点有:
1. 若 i>0 ,i 位置结点的双亲序号:; i=0 , i 为根结点编号,无双亲结点
2. 若 2i+1<n ,左孩⼦序号:, 2i+1>=n 否则无左孩子
3. 若 2i+2<n ,右孩⼦序号:, 2i+2>=n 否则无右孩子
对以上的性质来通过一个示例来加深理解
以下就是根据二叉树的性质来求出各节点的孩子结点以及父结点的图示


1.3堆的实现
在了解了堆相关的性质与结构后接下来就可以来试着实现堆
在实现堆的程序中还是将代码分为三个文件

1.堆结构的定义
//堆结构的定义
typedef int HDataType;
typedef struct Heap
{HDataType* arr;int size;//有效数据个数int capacity;//空间大小
}Heap;在定义堆的结构中,使用一个结构体来定义堆的结构,里面的成员变量和顺序表中相同,arr为数组首元素的指针,size为数组中有效元素的个数,capacity为数组空间的大小
2.堆的初始化
在堆的初始化函数的实现中先要在Heap.h内完成初始化函数的声明
//初始化堆
void HeapInit(Heap* php);将该函数命名为HeapInit,函数的参数为结构体指针
在完成了函数的声明后就是在Heap.c内完成函数的定义
//初始化堆
void HeapInit(Heap* php)
{assert(php);php->arr = NULL;php->size = php->capacity = 0;
}3.堆的插入
在堆的插入函数的实现中先要在Heap.h内完成插入函数的声明
//堆的插入
void HeapPush(Heap* php,HDataType x);将该函数命名为HeapPush,函数参数有两个,第一个为结构体指针,第二个为要插入的数据
在完成了函数的声明后就是在Heap.c内完成函数的定义
在堆的插入当中我们要实现的是在堆的末尾插入数据,也就是在数组的size-1位置插入新的数据,并且在插入之后由于堆的特性还要将堆中各元素的位置进行调整,使得其变为一个小堆或者大堆
因此在插入函数中我们先要实现向上调整的函数
3.1 向上调整法
要实现堆中的向上调整结点的函数首先要来分析在调整过程中需要实现哪些步骤,我们来看下面这个堆的示例
在这个小堆中我们先在堆的末尾插入数据为10的结点,在这之后要将该二叉树重新调整为小堆需要哪些操作呢?
首先就是要将新插入的结点10与它的父结点做对比,如果比父结点大就和父结点交换之后再和父结点的父结点比较重复以上操作直到最后父结点为0时就停止;在此过程中如果比父结点小就不进行交换
所以以上的二叉树要调整为小堆就要经过以下的步骤


在完全向上调整实例的分析后接下来就可以来实现向上调整的代码
先再Heap.h内对向上调整函数进行声明,通过以上的分析就可以推测出函数的参数有两个,一个为数组的首元素指针,另一个为数组的有效元素个数
//向上调整法 void AdjustUp(HDataType* arr, int child);
在以下的代码当中parent就来表示父结点的数组下标,child就来表示孩子节点的下标,因此在知道孩子结点的下标时要求父结点的下标就可以用到前面提到的二叉树的性质,父结点的下标等于其孩子结点下标减一再除以二
//向上调整法
void AdjustUp(HDataType* arr, int child)
{int parent = (child - 1) / 2;//求父结点下标while (child>0){//小堆时下面的if判断部分就用<//大堆时下面的if判断部分就用>if (arr[child] < arr[parent])//若父结点大于孩子结点就交换{Swap(&arr[child], & arr[parent]);child = parent;parent= (child - 1) / 2;}else{break;//若不符合以上if的条件就退出循环}}
}例如以上的示例中在以下代码中parent和child的变化就如以下图所示

在以上函数中的Swap是来实现两个数的交换,以下是函数的定义
void Swap(HDataType* p1, HDataType* p2) {HDataType* tmp = *p1;*p1 = *p2;*p2 = tmp; }
3.2 插入函数代码实现
在完成了向上调整的代码后接下来就可以来完成堆插入函数的实现
在插入函数中由于php为结构体指针,因此php不能为空,所以要将php进行assert断言
并且在插入之前也要判断数组空间是否满了,满了就要对空间进行调整,在此的调整代码和顺序表中相同
之后再将数据尾插到数组当中,再进行向上调整,最后切记要将size+1
//堆的插入
void HeapPush(Heap* php, HDataType x)
{assert(php);if (php->size == php->capacity)//对数组空间进行调整{int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;Heap* tmp = (Heap*)realloc(php->arr,sizeof(HDataType) * newcapacity);if (tmp == NULL){perror("malloc file");exit(1);}php->arr = tmp;php->capacity = newcapacity;}php->arr[php->size] = x;//进行尾插AdjustUp(php->arr, php->size);//进行向上调整php->size++;
}4.堆的删除
在堆的删除函数的实现中先要在Heap.h内完成删除函数的声明
//堆的删除
void HeapPop(Heap* php);将该函数命名为HeapPop,函数的参数是结构体指针
在完成了函数的声明后就是在Heap.c内完成函数的定义
在堆的删除中是将跟结点给删除,在删除过程中是将根结点和最后一个结点交换,之后将数组的有效个数减一这样就将原来的根结点给删除了,之后再进行各结点的调整使其重新变为一个堆
因此在插入函数中我们先要实现向下调整的函数
4.1向下调整法
要实现堆中的向下调整结点的函数首先要来分析在调整过程中需要实现哪些步骤,我们来看下面这个堆的示例
在这个小堆中我们如果已经跟结点删除,在这之后要将该二叉树重新调整为小堆需要哪些操作呢?

首先就是要将新的的跟结点70与它的两个孩子结点中小的做对比,如果比该孩子结点大就和该孩子结点交换之后再和该孩子结点的两的孩子结点中小的比较重复以上操作直到最后开始的跟结点为叶子节点时就停止;如果在这过程中比孩子结点中小的那个还小就不进行交换
所以以上的二叉树要调整为小堆就要经过以下的步骤

在完全向下调整实例的分析后接下来就可以来实现向下调整的代码
先再Heap.h内对向上调整函数进行声明,通过以上的分析就可以推测出函数的参数有三个,一个为数组的首元素指针,另一个为数组的有效元素个数 ,最后一个是要向下调整的元素的数组下标
//向下调整法 void AdjustDown(HDataType* arr, int n, int parent);
之后就是在Heap.c内完成函数的定义
在以下的代码当中parent就来表示父结点的数组下标,child就来表示孩子节点的下标,因此在知道父结点的下标时要求孩子结点的下标就可以用到前面提到的二叉树的性质,孩子结点的下标等于其父结点下标乘二再加一或二
while循环中当孩子节点下标大于数组有效个数也就是父节点为叶子节点时就退出循环,因此进入while条件为child<n
//向下调整法
void AdjustDown(HDataType* arr, int n, int parent)
{int child = 2 * parent + 1;//孩子节点的下标while (child<n){//如果为小堆 以下的if判断部分就用>//如果为大堆 以下的if判断部分就用<if (child+1<n && arr[child] > arr[child + 1]){child++;//若为小堆就找孩子节点中小的,大堆就找孩子节点中大的}if (arr[parent] > arr[child])//若孩子节点小于父节点就交换{Swap(&arr[parent], &arr[child]);parent = child;child= 2 * parent + 1;}else{break;//若不符合以上if的条件就退出循环}}
}例如以上的示例中在以下代码中parent和child的变化就如以下图所示

4.2删除函数代码实现
在插入函数中由于php为结构体指针,因此php不能为空,所以要将php进行assert断言
在删除函数中因为要删除的是堆的根结点,所以先将堆的根结点和堆的最后一个节点进行交换,之后再将size-1,这样就可以让数组当中的有效个数减一,使得原来的根结点被删除,之后再将该二叉树使用向下调整重新调整为堆
//堆的删除
void HeapPop(Heap* php)
{assert(php && php->size);php->arr[0] = php->arr[php->size - 1];--php->size;AdjustDown(php->arr, php->size, 0);
}5.取堆顶的元素
在堆的取堆顶的元素函数的实现中先要在Heap.h内完成取堆顶的元素函数的声明
//取堆顶的元素
HDataType HeapTop(Heap* php);将该函数命名为HeapTop,函数的参数是结构体指针,函数的返回值是堆跟结点内的数据
在完成了函数的声明后就是在Heap.c内完成函数的定义
//取堆顶的元素
HDataType HeapTop(Heap* php)
{assert(php);return php->arr[0];
}
6.堆的数据个数
在求堆的数据个数函数的实现中先要在Heap.h内完成堆的数据个数函数的声明
//堆的数据个数
int HeapSize(Heap* php);将该函数命名为HeapSize,函数的参数是结构体指针,函数的返回值是堆的结点结点个数
在完成了函数的声明后就是在Heap.c内完成函数的定义
因为堆是用数组来实现的,所以堆中的结点个数就为数组的有效元素个数
//堆的数据个数
int HeapSize(Heap* php)
{assert(php);return php->size;
}7.堆的判空
在判断堆是否为空函数的实现中先要在Heap.h内完成判断堆是否为空函数的声明
//堆的判空
bool HeapEmpty(Heap* php);将该函数命名为HeapEmpty,函数的参数是结构体指针,函数的返回类型是布尔类型
在完成了函数的声明后就是在Heap.c内完成函数的定义
在该函数中当当堆为空时就返回true,不为空时返回false
//堆的判空
bool HeapEmpty(Heap* php)
{assert(php);return php->size == 0;
}8.堆的销毁
在堆的销毁函数的实现中先要在Heap.h内完成堆的销毁函数的声明
//销毁堆
void HeapDestory(Heap* php);将该函数命名为HeapDestory,函数的参数是结构体指针
在完成了函数的声明后就是在Heap.c内完成函数的定义
//销毁堆
void HeapDestory(Heap* php)
{assert(php);if (php->arr){free(php->arr);}php->arr = NULL;php->size = php->capacity = 0;
}9.堆实现完整代码
Heap.h
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>//堆结构的定义
typedef int HDataType;
typedef struct Heap
{HDataType* arr;int size;//有效数据个数int capacity;//空间大小
}Heap;//初始化堆
void HeapInit(Heap* php);
//销毁堆
void HeapDestory(Heap* php);
//堆的插入
void HeapPush(Heap* php,HDataType x);
//堆的删除
void HeapPop(Heap* php);
//取堆顶的元素
HDataType HeapTop(Heap* php);
//堆的数据个数
int HeapSize(Heap* php);
//堆的判空
bool HeapEmpty(Heap* php);
//向上调整法
void AdjustUp(HDataType* arr, int child);
//向下调整法
void AdjustDown(HDataType* arr, int n, int parent);Heap.c
#include"Heap.h"void Swap(HDataType* p1, HDataType* p2)
{HDataType* tmp = *p1;*p1 = *p2;*p2 = tmp;
}//向上调整法
void AdjustUp(HDataType* arr, int child)
{int parent = (child - 1) / 2;while (child>0){//小堆 <//大堆 >if (arr[child] < arr[parent]){Swap(&arr[child], & arr[parent]);child = parent;parent= (child - 1) / 2;}else{break;}}}//向下调整法
void AdjustDown(HDataType* arr, int n, int parent)
{int child = 2 * parent + 1;while (child<n){//小堆 >//大堆 <if (child+1<n && arr[child] > arr[child + 1]){child++;}if (arr[parent] > arr[child]){Swap(&arr[parent], &arr[child]);parent = child;child= 2 * parent + 1;}else{break;}}
}//初始化堆
void HeapInit(Heap* php)
{assert(php);php->arr = NULL;php->size = php->capacity = 0;
}//销毁堆
void HeapDestory(Heap* php)
{assert(php);if (php->arr){free(php->arr);}php->arr = NULL;php->size = php->capacity = 0;
}//堆的插入
void HeapPush(Heap* php, HDataType x)
{assert(php);if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;Heap* tmp = (Heap*)realloc(php->arr,sizeof(HDataType) * newcapacity);if (tmp == NULL){perror("malloc file");exit(1);}php->arr = tmp;php->capacity = newcapacity;}php->arr[php->size] = x;AdjustUp(php->arr, php->size);php->size++;
}//堆的删除
void HeapPop(Heap* php)
{assert(php && php->size);php->arr[0] = php->arr[php->size - 1];--php->size;AdjustDown(php->arr, php->size, 0);
}//取堆顶的元素
HDataType HeapTop(Heap* php)
{assert(php);return php->arr[0];
}//堆的数据个数
int HeapSize(Heap* php)
{assert(php);return php->size;
}//堆的判空
bool HeapEmpty(Heap* php)
{assert(php);return php->size == 0;
}2.堆的应用
1.堆排序
在之前的C语言的学习当中我们实现了冒泡排序,但在算法的复杂度中得出了冒泡排序的时间复杂度为O(n^2),因此其实冒泡排序的效率是不高的。接下来我们就要来学习一种使用堆来实现排序的算法。
在此之前通过学习堆的相关概念知道了在小堆中的根结点是堆中最小的,那么在小堆中只要一直取堆的根结点就可以得到升序的数据,以下就是使用这种方法来实现的堆排序
void HeapSort(int* a, int n)
{Heap hp;for(int i = 0; i < n; i++){HeapPush(&hp,a[i]);}int i = 0;while (!HeapEmpty(&hp)){a[i++] = HeapTop(&hp);HeapPop(&hp);}HeapDestroy(&hp);
}但是在以上的这种算法中需要将数组中的数据先要先存储在堆当中才能在之后得到堆顶的数据,因此以上这种方法的空间复杂度就为O(n),那么有什么方法能在不申请新的空间下来实现堆排序呢?接下来就来看以下的这种基于原来数组建堆的方法
//堆排序算法
void HeapSort(int* arr, int n)
{for (int i = 0; i < n; i++){AdjustUp(arr, i);}int end = n - 1;while (end > 0){Swap(&arr[end], &arr[0]);AdjustDown(arr, end, 0);end--;}for (int i = 0; i < n; i++){printf("%d ", arr[i]);}
}在以上这种堆排序中先用向上调整法来将数组通过循环的将数组数组调整为堆,根据之前向上调整的代码在此的建的是小堆。之后的while循环中实现的是将小堆中的跟结点和尾结点进行交换这时数组中最小的元素就排在了数组的末尾之后再进行向下排序就可重新变为小堆,一直重复以上的操作就可以将数组的元素从小到大依次移动到数组末尾,最终原数组就变为升序的了。
那么以上除了使用向上调整建堆外,其实使用向下调整法也可以建堆,以下是使用向下调整法建堆的代码
//堆排序算法
void HeapSort(int* arr, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, n, i);}int end = n - 1;while (end > 0){Swap(&arr[end], &arr[0]);AdjustDown(arr, end, 0);end--;}for (int i = 0; i < n; i++){printf("%d ", arr[i]);}
}这两种那一这种效率更好呢,这就需要来分析向上建堆和向下建堆的时间复杂度
先来看向上调整法
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个结点不影响最终结果)
以下是各层的结点在向上调整过程中各层结点在调整过程中最坏的情况下移动的层数


需要移动结点总的移动步数为:每层结点个数 * 向上调整次数(第⼀层调整次数为0)
由此可得:
💡 向上调整算法建堆时间复杂度为: O(n ∗ log2 n)
接下来看向下调整法
以下是各层的结点在向下调整过程中各层结点在调整过程中最坏的情况下移动的层数

则需要移动结点总的移动步数为:每层结点个数 * 向下调整次数

💡 向下调整算法建堆时间复杂度为: O(n)
通过以上的分析后可以得出在堆排序中使用向下调整法建堆更好
堆排序第二个循环中的向下调整与建堆中的向上调整算法时间复杂度计算一致。因此堆排序的时间复杂度为 O(n + n ∗ log n) ,即 O(n log n)
2.TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下⼦全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
(1)用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
(2)用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者大的元素

以下这段代码可以实现将大量的整型数据输入到data.txt的文件当中
void CreateNDate()
{// 造数据int n = 100000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (int i = 0; i < n; ++i){int x = (rand() + i) % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}接下来就来实现解决TOP-K问题的代码,以下是实现的是得出数据结合中前K个最大的元素
void topk()
{int k=0;printf("k:");scanf("%d", &k);//读取文件中的前k个数据FILE* pf = fopen("data.txt", "r");if (pf == NULL){perror("fopen fail");exit(1);}int* pa = (int*)malloc(k * sizeof(int));if (pa == NULL){perror("malloc fail");exit(2);}for (int i = 0; i < k; i++){fscanf(pf, "%d", &pa[i]);}//使用前k个数据建堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(pa, k, i);}int tmp=0;//循环将k个数据之后的数据堆中最小的元素比较,若比这个元素大就交换while (fscanf(pf, "%d", &tmp) != EOF){if (tmp > pa[0]){pa[0] = tmp;AdjustDown(pa, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", pa[i]);}fclose(pf);pf = NULL;}
以上就是二叉树(中)的全部内容了,接下来在二叉树(下)将继续学习二叉树的知识,在下一篇中我们将重点学习链式结构的二叉树的相关知识,未完待续……
相关文章:
数据结构之《二叉树》(中)
在数据结构之《二叉树》(上)中学习了树的相关概念,还了解的树中的二叉树的顺序结构和链式结构,在本篇中我们将重点学习二叉树中的堆的相关概念与性质,同时试着实现堆中的相关方法,一起加油吧! 1.实现顺序结构二叉树 在…...
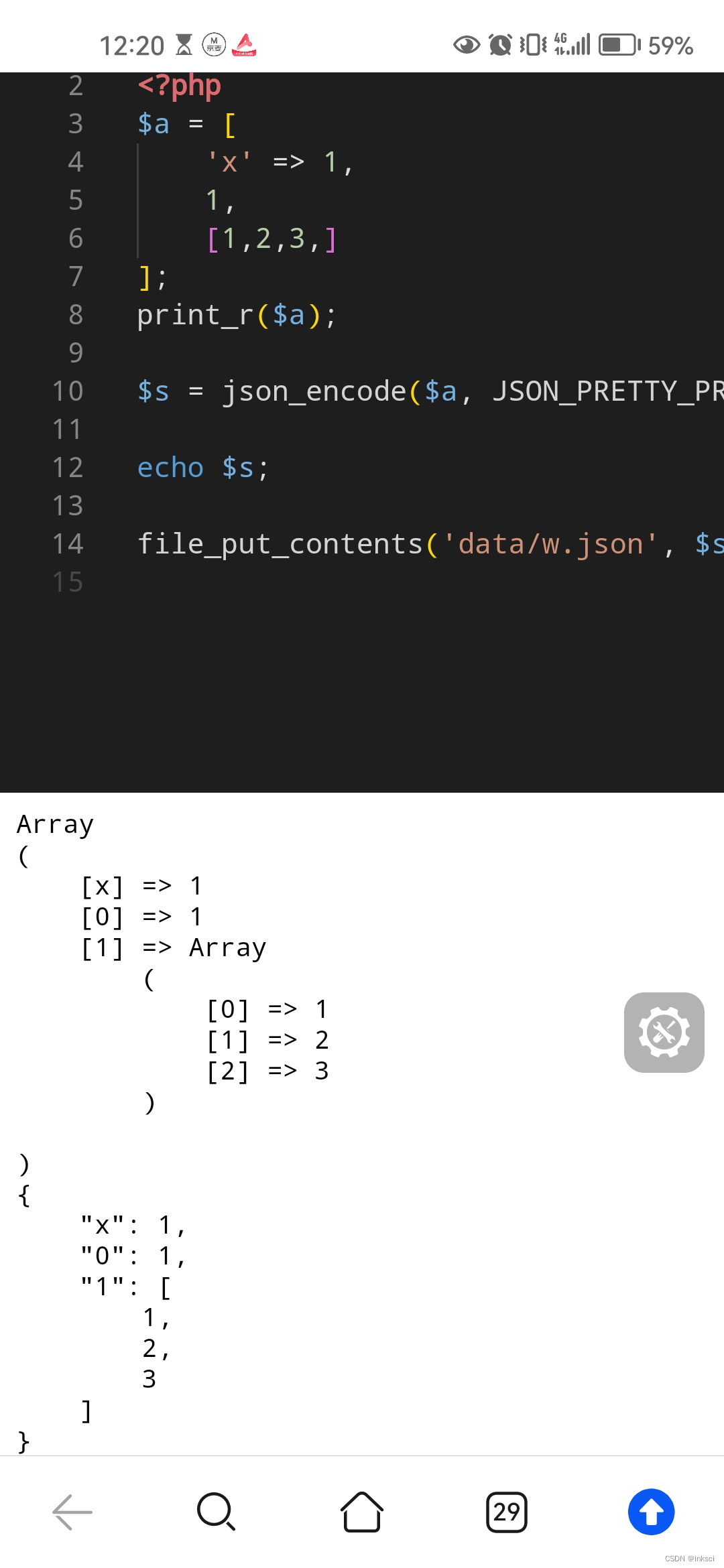
php json_encode 参数 JSON_PRETTY_PRINT
https://andi.cn/page/621642.html...

【UE 网络】Gameplay框架在DS架构中的扮演的角色
目录 0 引言1 核心内容1.1 Gameplay各部分创建的流程1.2 Gameplay框架在DS和客户端的存在情况1.3 数据是独立存在于DS和客户端的 2 Gameplay框架各自负责的功能2.1 GameMode2.2 GameState2.3 PlayerController2.4 PlayerState2.5 Pawn2.6 AIController2.7 Actor2.8 HUD2.9 UI &…...

【云原生】StatefulSet控制器详解
StatefulSet 文章目录 StatefulSet一、介绍与特点1.1、介绍1.2、特点1.3、组成部分1.4、为什么需要无头服务1.5、为什么需要volumeClaimTemplate 二、教程2.1、创建StatefulSet2.2、查看部署资源 三、StatefulSet中的Pod3.1、检查Pod的顺序索引3.2、使用稳定的网络身份标识3.3、…...

使用 Python 制作一个属于自己的 AI 搜索引擎
1. 使用到技术 OpenAI KEYSerper KEYBing Search 2. 原理解析 使用Google和Bing的搜搜结果交由OpenAI处理并给出回答。 3. 代码实现 import requests from lxml import etree import os from openai import OpenAI# 从环境变量中加载 API 密钥 os.environ["OPENAI_AP…...

rust读取csv文件,匹配搜索字符
1.代码 use std::fs::File; use std::io::{BufRead, BufReader}; use regex::{Regex};fn main() {let f File::open("F:\\0-X-RUST\\1-systematic\\ch2-fileRead\\data\\test.csv").unwrap();let mut reader BufReader::new(f);let re Regex::new("45asd&qu…...

隐藏采购订单类型
文章目录 1 Introduction2 code 1 Introduction The passage is that how to hiden purchase type . 2 code DATA: ls_shlp_selopt TYPE ddshselopt. IF ( sy-tcode ME21N OR sy-tcode ME22N OR sy-tcode ME23N or sy-tcode ME51N OR sy-tcode ME52N OR sy-tcode ME5…...

ESP32人脸识别开发- 基础介绍(一)
一、ESP32人脸识别的方案介绍 目前ESP32和ESP32S3都是支持的,官方推的开发板有两种,一种 ESP-EYE ,没有LCD 另一种是ESP32S3-EYE,有带LCD屏 二、ESP32人脸识别选用ESP32的优势 ESP32S3带AI 加速功能,在人脸识别的速度是比ESP32快了不少 | S…...

编程学习指南:语言选择、资源推荐与高效学习策略
目录 一、编程语言选择 1. Java:广泛应用的基石 2. C/C:深入底层的钥匙 3. Python:AI与大数据的宠儿 4. Web前端技术:构建交互界面的艺术 二、学习资源推荐 1. 国内外在线课程平台 2. 官方文档与教程 3. 书籍与电子书 4…...

AWS开发人工智能:如何基于云进行开发人工智能AI
随着人工智能技术的飞速发展,企业对高效、易用的AI服务需求日益增长。Amazon Bedrock是AWS推出的一项创新服务,旨在为企业提供一个简单、安全的平台,以访问和集成先进的基础模型。本文中九河云将详细介绍Amazon Bedrock的功能特点以及其收费方…...

CentOS 8 的 YUM 源替换为国内的镜像源
CentOS 8 的 YUM 源替换为国内的镜像源 1.修改 DNS 为 114.114.114.1141.编辑 /etc/resolv.conf 文件:2.在文件中添加或修改如下内容:3.保存并退出编辑器。 2.修改 YUM 源为国内镜像1.备份原有的 YUM 源配置:2.下载新的 YUM 源配置3.清理缓存…...

网络安全入门教程(非常详细)从零基础入门到精通_网路安全 教程
前言 1.入行网络安全这是一条坚持的道路,三分钟的热情可以放弃往下看了。2.多练多想,不要离开了教程什么都不会了,最好看完教程自己独立完成技术方面的开发。3.有时多百度,我们往往都遇不到好心的大神,谁会无聊天天给…...

浅学爬虫-爬虫维护与优化
在实际项目中,爬虫的稳定性和效率至关重要。通过错误处理与重试机制、定时任务以及性能优化,可以确保爬虫的高效稳定运行。下面我们详细介绍这些方面的技巧和方法。 错误处理与重试机制 在爬虫运行过程中,网络不稳定、目标网站变化等因素可…...

STM32G070系列芯片擦除、写入Flash错误解决
在用G070KBT6芯片调用HAL_FLASHEx_Erase(&EraseInitStruct, &PageError)时,调试发现该函数返回HAL_ERROR,最后定位到FLASH_WaitForLastOperation(FLASH_TIMEOUT_VALUE)函数出现错误,pFlash.ErrorCode为0xA0,即FLASH错误标…...

08.02_111期_Linux_NAT技术
NAT(network address translation)技术说明 IP报文在转发的时候需要考虑 源IP地址 和 目的IP地址, IP报文每到达一个节点,就会更改一次IP地址和目的IP地址,其中节点是指主机、服务器、路由器 那么这个更改是如何进行的呢? 除了…...

【2024蓝桥杯/C++/B组/小球反弹】
题目 分析 Sx 2 * k1 * x; Sy 2 * k2 * y; (其中k1, k2为整数) Vx * t Sx; Vy * t Sy; k1 / k2 (15 * y) / (17 * x); 目标1:根据k1与k2的关系,找出一组最小整数组(k1, k2)ÿ…...

PHP中如何实现函数的可变参数列表
在PHP中,实现函数的可变参数列表主要有两种方式:使用func_get_args()函数和使用可变数量的参数(通过...操作符,自PHP 5.6.0起引入)。 1. 使用func_get_args()函数 func_get_args()函数用于获取传递给函数的参数列表&…...

串---链串实现
链串详解 本文档将详细介绍链串的基本概念、实现原理及其在 C 语言中的具体应用。通过本指南,读者将了解如何使用链串进行各种字符串操作。 1. 什么是链串? 链串是一种用于存储字符串的数据结构,它使用一组动态分配的节点来保存字符串中的…...

科技赋能生活——便携气象站
传统气象站往往庞大而复杂,需要专业人员维护,它小巧玲珑,设计精致,可以轻松放入背包或口袋,随身携带,不占空间。无论是城市白领穿梭于高楼大厦间,还是户外爱好者深入山林湖海,都能随…...

Golang——GC原理
1.垃圾回收的目的 将未被引用到的对象销毁,回收其所占的内存空间。 2.根对象是什么 全局变量:在编译器就能确定的存在于程序整个生命周期的变量。 执行栈:每个goroutine都包含自己的执行栈,这些执行栈上包含栈上的变量及指向分配…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...