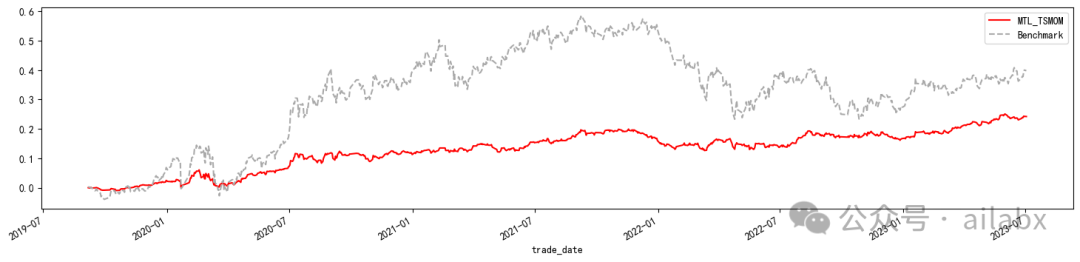
稳稳的年化10%,多任务时序动量策略——基于pytorch的深度学习策略(附python代码)
原创文章第608篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。
做因子挖掘这段时间,有一个观感。
传统的因子挖掘,尤其是手工构造因子,到遗传算法因子挖掘。——本身也是一种”拟合“,或者说试图”解释“过往的收益率,有一种符号表达的方式。
传统机器学习,我们也是试图这么做的,有不少工程上的tricks。
但在深度学习时代,最大的一点进步就是不需要特征工程,因为特征工程本身是对现实数据的简化。深度卷积神经网络读图片,它是读入像素级数据,然后自己建模。
之前星球有同学提问说——为什么不能直接端到端建模?
这其实是一个好问题。
图像识别就是端到端,AlphaGo就是端到端,深度强化学习端到端构建投资组合——从逻辑上更符合金融投资的场景——它甚至不需要label。
通过深度强化学习构建、筛选因子,然后再用深度学习来组合因子,这里确实会损失很多信息。
IC筛选出来的因子,在机器学习里组合效果并不一定好。
一个原因可能是ic是线性信息,而机器学习可以拟合高维非线性的信息。
所以,现在手工构建的因子,多数用于加权合成,而非机器学习;那么反过来,机器学习所需的特征,通过IC值来筛选还靠谱吗?
import warnings# from collections import defaultdict
from typing import Dict, List, Tupleimport pandas as pd
import torch
from torch.nn.utils import clip_grad_norm_# from torch.utils.data import DataLoader
from tqdm import tqdmfrom .data_processor import DataProcessor
from .general import corrcoef_loss, get_strategy_returns, share_loss
from .module import Multi_Task_Model # CustomDataset
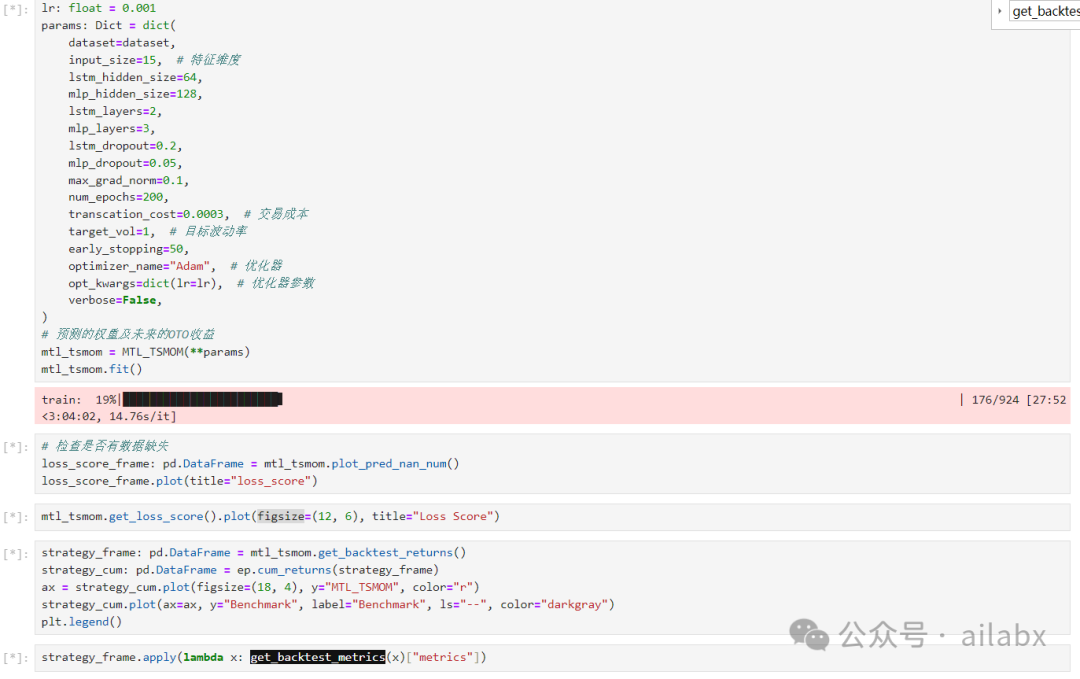
from .utils import all_nan, plot_pred_nan_numclass MTL_TSMOM:def __init__(self,dataset: DataProcessor,input_size: int,lstm_hidden_size: int,mlp_hidden_size: int,lstm_layers: int,mlp_layers: int,optimizer_name: str,transcation_cost: float,target_vol: float,lstm_dropout: float,mlp_dropout: float,max_grad_norm: float,# batch_size: int,num_epochs: int,opt_kwargs: Dict = None,early_stopping: int = 50,log_step: int = 100,verbose: bool = False,save_path: str = None,) -> None:self.epoch_loss = [] # 储存每一次的损失# self.all_loss = defaultdict(list) # 储存每一次的损失 1-train 2-validself.dataset = datasetself.transcation_cost = transcation_costself.target_vol = target_volself.max_grad_norm = max_grad_norm# self.batch_size = batch_sizeself.num_epochs = num_epochsself.early_stopping = early_stoppingself.log_step = log_stepself.verbose = verboseself.save_path = save_path# 初始化模型self.model = Multi_Task_Model(input_size,lstm_hidden_size,mlp_hidden_size,lstm_layers,mlp_layers,lstm_dropout,mlp_dropout,).cuda()if opt_kwargs is None:opt_kwargs = {}self.optimizer = getattr(torch.optim, optimizer_name)(self.model.parameters(), **opt_kwargs)def log(self, arg, verbose=True) -> None:if verbose:print(arg)def train_model(self, train_datase: List, gloabal_step: int = None) -> float:self.model.train()# train_dataset = CustomDataset(train_datase)# train_loader = DataLoader(# train_dataset, batch_size=self.batch_size, shuffle=False# )features, next_returns, forward_vol = train_datasetotal_loss = 0.0# loss = 0.0# for batch, (features, next_returns, forward_vol) in enumerate(train_loader):pred_sigma, weight = self.model(features)auxiliary_loss: float = corrcoef_loss(pred_sigma, forward_vol)main_loss: float = share_loss(weight, next_returns, self.target_vol, self.transcation_cost)total_loss = (auxiliary_loss + main_loss) * 0.5self.optimizer.zero_grad()total_loss.backward()# 为了防止梯度爆炸,我们对梯度进行裁剪if self.max_grad_norm is not None:clip_grad_norm_(self.model.parameters(), self.max_grad_norm)self.optimizer.step()# if gloabal_step is not None:# self.all_loss[gloabal_step].append(# (1, batch, auxiliary_loss, main_loss, total_loss)# )# loss += total_lossreturn total_loss # loss / len(train_loader)def validation_model(self, validation_dataset: List, gloabal_step: int = None) -> float:# valid_dataset = CustomDataset(validation_dataset)# valid_loader = DataLoader(# valid_dataset, batch_size=self.batch_size, shuffle=False# )total_loss = 0.0# loss = 0.0self.model.eval()features, next_returns, forward_vol = validation_datasetwith torch.no_grad():# for batch, (features, next_returns, forward_vol) in enumerate(valid_loader):pred_sigma, weight = self.model(features)auxiliary_loss = corrcoef_loss(pred_sigma, forward_vol)main_loss = share_loss(weight, next_returns, self.target_vol, self.transcation_cost)total_loss = (auxiliary_loss + main_loss) * 0.5# loss += total_loss# if gloabal_step is not None:# self.all_loss[gloabal_step].append(# (2, batch, auxiliary_loss, main_loss, total_loss)# )return total_loss # loss / len(valid_loader)def predict_data(self, test_part: List) -> Tuple[torch.Tensor, torch.Tensor]:features, next_returns, _ = test_partwith torch.no_grad():_, weight = self.model(features)return weight, next_returnsdef loop(self, train_part: List, valid_part: List, global_step: int = None) -> float:best_valid_loss: float = float("inf") # 用于记录最好的验证集损失epochs_without_improvement: int = 0 # 用于记录连续验证集损失没有改善的轮数for epoch in range(self.num_epochs):train_loss: float = self.train_model(train_part)valid_loss: float = self.validation_model(valid_part)if (self.log_step is not None) and (epoch % self.log_step == 0):self.log(f"Epoch {epoch or epoch+1}, Train Loss: {train_loss:.4f}, Valid Loss: {valid_loss:.4f}",self.verbose,)# 判断是否有性能提升,如果没有则计数器加 1# NOTE:这样是最小化适用的,如果是最大化,需要改成 valid_loss > best_valid_lossif valid_loss < best_valid_loss:best_valid_loss = valid_lossepochs_without_improvement: int = 0else:epochs_without_improvement += 1# 保存每一次的损失self.epoch_loss.append((global_step, train_loss, valid_loss))# 判断是否满足 early stopping 条件if (self.early_stopping is not None) and (epochs_without_improvement >= self.early_stopping):self.log(f"Early stopping at epoch {epoch + 1}...", self.verbose)breakreturn valid_lossdef fit(self):ls: List = [] # 储存每一次的权重和收益size: int = len(self.dataset.train_dataset)for i, (train_part, valid_part, test_part) in enumerate(tqdm(zip(self.dataset.train_dataset,self.dataset.valid_dataset,self.dataset.test_dataset,),total=size,desc="train",)):self.loop(train_part, valid_part, i)weight, next_returns = self.predict_data(test_part)ls.append((weight, next_returns))if all_nan(weight):warnings.warn(f"下标{i}次时:All nan in weight,已经跳过")# raise ValueError(f"下标{i}次时:All nan in weight")breakweights_tensor: torch.Tensor = torch.cat([t[0] for t in ls], dim=0)returns_tensor: torch.Tensor = torch.cat([t[1] for t in ls], dim=0)self.weight = weights_tensorself.next_returns = returns_tensorif self.save_path is not None:torch.save(self.model.state_dict(), self.save_path)# return weights_tensor, returns_tensordef get_backtest_returns(self) -> pd.DataFrame:try:self.weightexcept NameError as e:raise NameError("请先调用fit方法") from estrategy_frame: pd.DataFrame = get_strategy_returns(self.weight, self.next_returns, self.dataset.test_idx)return strategy_framedef get_loss_score(self) -> pd.DataFrame:if self.epoch_loss == []:raise ValueError("请先调用fit方法")return pd.DataFrame([(j.item(), k.item()) for _, j, k in self.epoch_loss],columns=["train", "valid"],)def plot_pred_nan_num(self):try:self.weightexcept NameError as e:raise NameError("请先调用fit方法") from ereturn plot_pred_nan_num(self.weight)
昨天在星球里发布的论文,以上是核心代码。

通过时序动量和波动率对投资组合目标波动率建模。
代码下载:
吾日三省吾身
01
财富自由小目标——七年赚到500万实现财富自由,这是我的计划,也适合大多数普通人——这是我三年前写的文章了,这个时间点的认知,基本已经成型。财富自由的三个层次,三条路径吧。
第二层次相信并持续践行中。
努力开展第三层次。——做生产者,创造有价值的东西,走财富自由快车道。
更新了一下小目标: 按进度5年的阶段小目标,如果你有勇气把目标提升至10倍,那么5年内就可以实现大目标。
2000个W——普通人基本可以退休且无后顾之忧了。
怎么做呢?投资、创业、技能和知识付费。。
我问kimi怎么做,它的回答:
普通人在5年内赚取2000万是一个具有挑战性的目标,但并非不可能。以下是一些可能的途径和策略,但请注意,这些方法都涉及不同程度的风险,并且成功并不是保证的。
02
“对宏观保持耐心,对微观保持效率”。
今天读到这句话挺受启发。
多数人对宏观缺乏耐心,无论是投资还是经营自己的人生。
其实就是“但行好事,莫问前程”,又同长期主义,延迟满足相关联。
好的事情发生,需要一点时间,有时候来得比你想象中要更久。我们可以努力的时间,只是一点一滴的当下。
“种一棵树最好的时间是十年前,其次是现在“。
03
吐槽两句——有一种讲量化的书,竟然只讲一堆理论、公式,数学推导。
然后竟然没有一行代码。
金融是一个偏实战的行业,它与物理、数学这种严格的科学不同。
好比马可维茨获得诺奖的MVO,并不能用于投资一样,因为参数敏感度太高,收益率无法预估且不稳定等因素。
理论当然重要,但金融的艺术性决定理论与实战会有出入。
所以,作为量化的书,不结合实战,连数据分析都不做,就光讲理论,洋洋洒洒这么厚的一本书,实在是。
之后我若是写书,一定会规避这种风格。要么不写,要么大家一定会拿到可以直接跑的代码。
AI量化实验室——2024量化投资的星辰大海
相关文章:
稳稳的年化10%,多任务时序动量策略——基于pytorch的深度学习策略(附python代码)
原创文章第608篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。 做因子挖掘这段时间,有一个观感。 传统的因子挖掘,尤其是手工构造因子,到遗传算法因子挖掘。——本身也是一种”拟合“,或者说试图”…...

C++分析AVL树
目录 AVL树介绍 AVL树平衡因子更新分析 AVL树插入时旋转与平衡因子更新 左单旋 右单旋 左右单旋 右左单旋 AVL旋转可行性 AVL树节点删除(待补充) AVL树分析 AVL树介绍 二叉搜索树在某些极端情况下可能会退化,为了解决这个问题&…...

aurora8b10b ip的使用(framing接口下的数据回环测试)
文章目录 一、Aurora8B/10B协议二、时钟、复位与状态指示1、时钟2、复位3、状态指示 三、数据发送、接受接口(1)AXI4-Stream位排序(2)Streaming接口(3)Framing接口(帧传输接口) 四、…...

如何通过OpenCV判断图片是否包含在视频内?
要判断图片是否包含在视频内,可以使用计算机视觉技术和图像处理方法。这通常涉及特征匹配或模板匹配。以下是一个基于OpenCV的解决方案,通过特征匹配的方法来实现这一目标。 步骤概述 读取视频和图片: 使用OpenCV读取视频文件和图片文件。 …...

大数据基础:Spark重要知识汇总
文章目录 Spark重要知识汇总 一、Spark 是什么 二、Spark 四大特点 三、Spark框架模块介绍 3.1、Spark Core的RDD详解 3.1.1、什么是RDD 3.1.2、RDD是怎么理解的 四、Spark 运行模式 4.1、Spark本地模式介绍 4.2、Spark集群模式 Standalone 4.3、Spark集群模式 Stan…...

Executable Code Actions Elicit Better LLM Agents
Executable Code Actions Elicit Better LLM Agents Github: https://github.com/xingyaoww/code-act 一、动机 大语言模型展现出很强的推理能力。但是现如今大模型作为Agent的时候,在执行Action时依然还是通过text-based(文本模态)后者JSO…...

循环结构(三)——do-while语句
目录 🍁引言 🍁一、语句格式 🚀格式1 🚀格式2 🍁二、语句执行过程 🍁三、实例 🚀【例1】 🚀【例2】 🚀【例3】 🍁总结 🍁备注 &am…...

pandas 或筛选
pandas 或筛选 在Pandas中,可以使用DataFrame.loc方法结合逻辑运算符来实现或筛选。这里提供一个简单的例子: import pandas as pd 创建示例DataFrame df pd.DataFrame({ ‘A’: [1, 2, 3, 4], ‘B’: [5, 6, 7, 8], ‘C’: [9, 10, 11, 12] }) 设定…...

工具(1)—截屏和贴图工具snipaste
演示和写代码文档的时候,总是需要用到截图。在之前的流程里面,一般是打开WX或者QQ,找到截图工具。但是尴尬的是,有时候,微信没登录,而你这个时候就在写文档。为了截个图,还需要启动微信…...
【从零开始一步步学习VSOA开发】快速体验SylixOS
快速体验SylixOS 安装完毕RealEvo-IDE 后,同时也安装了RealEvo-Simulator。RealEvo-Simulator 是一个虚拟运行环境,可以模拟各种体系结构并在其上运行 SylixOS。相比于物理板卡,在 RealEvo-Simulator 进行运行调测更加的方便快捷且成本低廉。…...

Ansible自动化:简化IT基础设施管理的艺术
目录 一.前言 二.Ansible简介 2.1什么是Ansible? 2.2Ansible的主要特点 2.3Ansible的应用场景 三.探索Ansible的高级功能 3.1 高级Playbook特性 3.2 Ansible Vault 3.3 动态Inventory 3.4Ansible Tower(AWX) 3.5模块开发 3.6 Ans…...

【Rust光年纪】探索Rust语言中的WebSocket库和框架:优劣一览
Rust语言中的实时通信利器:WebSocket库与框架全面解析 前言 随着Rust语言的不断发展,其在Web开发领域也变得越来越受欢迎。WebSocket作为实现实时通信的重要技术,在Rust的生态系统中也有多个库和框架提供了支持。本文将介绍几个主流的Rust …...

HTML 基础结构
目录 1. 文档声明 2. 根标签 3. 头部元素 4. 主题元素 5. 注释 6. 演示 1. 文档声明 <!DOCTYPE html>:声明文档类型,表示该文档是 html 文档, 2. 根标签 (1)所有的其他标签都要放在一对根标签中&#…...

多页合同怎么盖骑缝章_电子合同怎么盖骑缝章?
多页合同怎么盖骑缝章?电子合同怎么盖骑缝章? 对于纸质多页合同,盖骑缝章是一种常见的做法,用于确保合同的完整性,防止任何页面被替换或篡改。以下是盖骑缝章的基本步骤: 将所有合同页面平铺在桌面上。用…...

GD 32 IIC通信协议
前言: ... 通信方式 通信方式分为串行通信和并行通信。常见的串口就是串行通信的方式 常用的串行通信接口 常用的串行通信方式有USART,IIC,USB,CAN总线 同步与异步 同步通信:IIC是同步通信,有两个线一个是时钟信号线,一个数数据…...

Spring Task初学
介绍 Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑 为什么要在Java程序中使用Spring Task? 运行效果 cron表达式:一般日和周不会同时出现 入门案例 启动类添加注解EnableScheduling开始任务调度 创建MyTask类…...

决策树可解释性分析
决策树可解释性分析 决策树是一种广泛使用的机器学习算法,以其直观的结构和可解释性而闻名。在许多应用场景中,尤其是金融、医疗等领域,模型的可解释性至关重要。本文将从决策路径、节点信息、特征重要性等多个方面分析决策树的可解释性&…...

BUGKU-WEB never_give_up
解题思路 F12查看请求和响应,查找线索 相关工具 base64解码URL解码Burp Suit抓包 页面源码提示 <!--1p.html--> 2. 去访问这个文件,发现直接跳转到BUGKU首页,有猫腻那就下载看看这个文件内容吧 爬虫下载这个文件 import requests …...

hive自动安装脚本
使用该脚本注意事项 安装hive之前确定机子有网络。或者yum 更改为本地源,因为会使用epel仓库下载一个pv的软件使用该脚本前提是自行安装好mysql数据库准备好tomcat软件包,该脚本使用tomcat9.x版本测试过能正常执行安装成功,其他版本没有测试…...

unix 用户态 内核态
在UNIX操作系统中,"用户态"和"内核态"是两种不同的运行模式,它们定义了程序在执行时的权限级别: 用户态(User Mode): 用户态是程序运行的常规状态,大多数应用程序在执行时…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...