去噪扩散恢复模型
去噪扩散恢复模型
Bahjat Kawar
计算机科学系
以色列海法理工学院
bahjat.kawar@cs.technion.ac.il
Michael Elad
计算机科学系
以色列海法理工学院
elad@cs.technion.ac.il
Stefano Ermon
计算机科学系
美国加利福尼亚州斯坦福大学
ermon@cs.stanford.edu
宋嘉明
NVIDIA
美国加利福尼亚州圣克拉拉
jiamings@nvidia.com
摘要
许多有趣的图像恢复任务可以被视为线性逆问题。最近的一些方法使用随机算法从给定测量的自然图像的后验分布中采样。然而,高效的解决方案通常需要特定问题的监督训练来建模后验分布,而非特定问题的无监督方法通常依赖于低效的迭代方法。本文通过引入去噪扩散恢复模型(DDRM)来解决这些问题,这是一种高效的、无监督的后验采样方法。受变分推理的启发,DDRM利用预训练的去噪扩散生成模型来解决任何线性逆问题。我们在多个图像数据集上展示了DDRM在超分辨率、去模糊、修复和上色任务中的多功能性,并在不同噪声水平下进行了测量。DDRM在重建质量、感知质量和运行时间方面优于当前领先的无监督方法,在ImageNet数据集上表现尤为突出,比最近的竞争对手快5倍。DDRM还能够很好地推广到超出ImageNet训练集分布的自然图像。
1 引言
图像处理中的许多问题,包括超分辨率、去模糊、修复、上色和压缩感知,都是线性逆问题的实例,其目标是从通过已知线性退化模型获得的可能有噪声的测量中恢复图像。对于特定的退化模型,图像恢复可以通过神经网络的端到端监督训练来解决,使用原始图像和退化图像的配对数据。然而,现实世界的应用如医学成像通常需要灵活应对多个、可能无限的退化模型。在这种情况下,基于学习先验的无监督方法可能更可取,因为它们可以在不重新训练的情况下适应给定的问题。通过学习对图像的潜在结构(如先验、近似算子或去噪器)的合理假设,无监督方法可以在不针对特定退化模型进行训练的情况下实现有效恢复。

图1:使用20步DDRM在超分辨率、去模糊、上漆和上色、有或没有噪声以及无条件生成模型下的测量和恢复图像对。
在训练期间不访问图像。
在这种无监督设置下,基于深度神经网络的先验在各种图像恢复任务中展示了令人印象深刻的经验结果。为了恢复信号,大多数现有方法从神经网络中获得关于信号的先验相关项(如自然图像的分布)和退化模型的似然项,并将这两个项结合形成信号的后验分布,逆问题可以被表述为优化问题或采样问题。然后,这些问题通常通过迭代方法解决,如梯度下降或朗之万动力学,这可能在计算上要求高且对超参数调整敏感。一个极端的例子是“快速”算法版本使用15,000次神经函数评估。
受这种无监督工作的启发,我们引入了一种名为去噪扩散恢复模型(DDRM)的高效方法,可以在仅需20次神经函数评估的情况下实现竞争结果。DDRM是一个去噪扩散生成模型,它逐渐并随机地将样本去噪至所需输出,条件是测量值和逆问题。通过引入一个变分推理目标来学习逆问题的后验分布,并展示其与无条件去噪扩散生成模型目标的等价性,使得我们能够在各种线性逆问题中部署这些模型。
我们通过比较各种基于学习先验的竞争方法,如深度生成先验(DGP)、SNIPS和通过去噪正则化(RED),展示了DDRM的经验有效性。在ImageNet示例中,DDRM在无噪声超分辨率和去模糊任务中大多数情况下优于神经网络基准,并且在仅次于最佳的情况下,其效率至少提高了50倍。我们的优势在测量噪声涉及时变得更大,因为迭代方法产生的噪声伪影在我们的方法中不会出现。在各种真实图像上,我们进一步展示了DDRM在超分辨率、去模糊、修复和上色任务中的效果。用ImageNet训练的DDRM在超出其训练集分布的图像上也表现良好。
2 背景
线性逆问题。一般线性逆问题被表述为:
![]()
我们旨在从测量值y恢复信号x,其中H是已知的线性退化矩阵,z是具有已知方差的i.i.d.加性高斯噪声![]() 。
。

左图:独立于逆问题,右图依赖于逆问题
图2:一个特定的反问题(超分辨率+去噪)的DDRM方法示意图。我们可以使用无监督DDPM模型作为DDRM目标的一个很好的解决方案。
\( x \) 的潜在结构可以通过生成模型 \( p_\theta(x) \) ![]() 表示。给定 \( y \) 和 \( H \),可以表述信号的后验分布: \( p_\theta(x|y) \propto p_\theta(x)p(y|x) \),
表示。给定 \( y \) 和 \( H \),可以表述信号的后验分布: \( p_\theta(x|y) \propto p_\theta(x)p(y|x) \),![]() 其中“似然”项 \( p(y|x) \) 通过方程 (1) 定义;这种方法利用学习到的先验 \( p_\theta(x) \),我们称之为“无监督”方法,因为先验不一定依赖于逆问题。通过从这个后验中采样可以恢复 \( x \),这可能需要很多迭代才能产生好的样本。或者,也可以通过自适应推理(即监督学习)学习一个模型来近似这个后验;该模型学习预测 \( x \),给定由 \( x \) 和特定 \( H \) 生成的 \( y \)。尽管这可能比基于采样的方法更高效,但它可能在没有训练过的逆问题上泛化能力较差。
其中“似然”项 \( p(y|x) \) 通过方程 (1) 定义;这种方法利用学习到的先验 \( p_\theta(x) \),我们称之为“无监督”方法,因为先验不一定依赖于逆问题。通过从这个后验中采样可以恢复 \( x \),这可能需要很多迭代才能产生好的样本。或者,也可以通过自适应推理(即监督学习)学习一个模型来近似这个后验;该模型学习预测 \( x \),给定由 \( x \) 和特定 \( H \) 生成的 \( y \)。尽管这可能比基于采样的方法更高效,但它可能在没有训练过的逆问题上泛化能力较差。
去噪扩散概率模型DDPM。生成模型学习到的结构已经应用于各种逆问题,并且通常优于基于数据无关结构约束(如稀疏性)的方法。这些生成模型通过样本学习一个模型分布 \( p_\theta(x) \) ![]() 来逼近数据分布 \( q(x) \)
来逼近数据分布 \( q(x) \)![]() 。特别是,扩散模型在图像上的无条件生成建模性能表现出色。扩散模型是具有马尔可夫链结构的生成模型
。特别是,扩散模型在图像上的无条件生成建模性能表现出色。扩散模型是具有马尔可夫链结构的生成模型 ![]() ,其联合分布为:
,其联合分布为:

在生成模型中,仅保留 \( x_0 \) 作为样本。为了训练扩散模型,引入了固定的、因式分解的变分推理分布:

这导致了最大似然目标的证据下界(ELBO)。一些扩散模型的一个特殊性质是所有 \( t < T \) 的 \( p_\theta^{(t)} \) 和 \( q^{(t)} \) ![]() 都被选择为条件高斯分布,并且 \( q(x_t|x_0) \) 也是一个具有已知均值和协方差的高斯分布,即 \( x_t \) 可以被视为直接受到高斯噪声污染的 \( x_0 \)。因此,ELBO 目标可以简化为以下去噪自动编码器目标:
都被选择为条件高斯分布,并且 \( q(x_t|x_0) \) 也是一个具有已知均值和协方差的高斯分布,即 \( x_t \) 可以被视为直接受到高斯噪声污染的 \( x_0 \)。因此,ELBO 目标可以简化为以下去噪自动编码器目标:

其中 \( f_\theta^{(t)} \) 是一个 θ 参数化的神经网络,旨在从噪声 \( x_t \) 中恢复无噪声观测值,并且 \( \gamma_1:T \) 是一组依赖于 \( q(x_{1:T}|x_0) \) 的正系数。
3 去噪扩散恢复模型
基于后验采样的逆问题求解器经常面临两难境地:无监督方法适用于一般问题但效率低下,而监督方法高效但只能解决特定问题。
为了解决这个难题,我们引入了去噪扩散恢复模型(DDRM),一个针对一般线性逆问题的无监督求解器,能够处理测量中有噪声或无噪声的任务。DDRM 高效且在与流行的无监督求解器(如 RED, DGP, SNIPS)相比时表现出竞争力。
DDRM 的关键思想是找到一个适合监督学习目标的无监督解决方案。首先,我们描述 DDRM 在特定逆问题上的变分目标(第 3.1 节)。接下来,我们介绍适用于线性逆问题的 DDRM 特定形式,并允许直接使用预训练的无条件和类别条件扩散模型(第 3.2 节和第 3.3 节)。最后,我们讨论计算和内存高效的实际算法(第 3.4 节和第 3.5 节)。
3.1 DDRM 的变分目标
对于任何线性逆问题,我们将 DDRM 定义为条件于 \( y \) 的马尔可夫链 ![]() ,其中
,其中

而 x0是最终的扩散输出。为了进行推理,我们考虑以下条件于 \( y \) 的因式分解变分分布:

这导致了条件于 \( y \) 的扩散模型的 ELBO 目标。
在本节的其余部分中,我们在给定 \( H \) 和 \( \sigma_y \) 的情况下构建合适的变分问题,并将其与无条件扩散生成模型联系起来。为了简化符号,我们将构建变分分布 \( q \),使得 \( ,其中![]()
![]() 。在附录 B 中,我们将展示这等同于 DDRM 和 DDIM 中引入的分布,最多对 \( x_t \) 进行固定线性变换。
。在附录 B 中,我们将展示这等同于 DDRM 和 DDIM 中引入的分布,最多对 \( x_t \) 进行固定线性变换。
3.2 图像恢复的扩散过程
类似于 SNIPS,我们考虑 \( H \) 的奇异值分解(SVD),并在其光谱空间中进行扩散。其背后的思想是将测量值 \( y \) 中的噪声与 \( x_{1:T} \) 中的扩散噪声联系起来,确保扩散结果 \( x_0 \) 忠实于测量值。通过使用 SVD,我们识别 \( y \) 中缺失的数据,并通过扩散过程进行合成。同时,\( y \) 中的噪声数据进行去噪处理。例如,在带噪声的修复中(例如 ![]() ,光谱空间只是像素空间,因此模型应生成缺失的像素并对 \( y \) 中观察到的像素进行去噪。对于一般的线性 \( H \),其 SVD 为
,光谱空间只是像素空间,因此模型应生成缺失的像素并对 \( y \) 中观察到的像素进行去噪。对于一般的线性 \( H \),其 SVD 为

其中 \( U \) 和 \( V \) 是正交矩阵,\( \Sigma \) 是包含 \( H \) 奇异值的矩形对角矩阵,按降序排列。我们假设 \( m 小于n \),但我们的方法也适用于 \( m > n \)。我们将奇异值表示为![]()
我们使用光谱空间中的值的简写表示:\( x_t^{(i)} \) 是向量 \( x_t = V^T x_t \) 的第 \( i \) 个索引,\( y^{(i)} \) 是向量 \(![]() 的第 \( i \) 个索引(其中 \( \dagger \) 表示 Moore–Penrose 伪逆)。因为 \( V \) 是正交矩阵,我们可以通过左乘 \( V \) 精确恢复 \( x_t \)。对于光谱空间中的每个索引 \( i \),我们定义变分分布为:
的第 \( i \) 个索引(其中 \( \dagger \) 表示 Moore–Penrose 伪逆)。因为 \( V \) 是正交矩阵,我们可以通过左乘 \( V \) 精确恢复 \( x_t \)。对于光谱空间中的每个索引 \( i \),我们定义变分分布为:
其中 \( \eta \in (0, 1] \) 是控制转变方差的超参数,且 \( \eta \) 和 \( \eta_b \) 可以依赖于 \( \sigma_t, s_i, \sigma_y \)。我们进一步假设 \( \sigma_T \大于等于\sigma_y}除以{s_i} \) 对于所有正 \( s_i \)。
在以下陈述中,我们展示了这种构造具有类似于无条件扩散模型中推理分布的“高斯边缘”性质。
命题 3.1. 定义在方程 4 和 5 中的条件分布 \( q^{(t)} \) 满足以下条件:
\[ q(x_t|x_0) = N(x_0, \sigma_t^2 I),\]
通过对 \( x_{t'} \) (对于所有 \( t' > t \))和 \( y \) 进行边缘化定义,其中 \( q(y|x_0) \) 按照方程 (1) 中的定义 \( x = x_0 \)。
证明在附录 C 中。直观上,我们的构造考虑了光谱空间中每个索引的不同情况。(i) 如果相应的奇异值为零,则 \( y \) 不直接提供该索引的任何信息,更新类似于常规无条件生成。(ii) 如果奇异值非零,则更新考虑 \( y \) 提供的信息,这进一步取决于光谱空间中测量噪声水平 (\( \sigma_y / s_i \)) 是否大于扩散模型中的噪声水平 (\( \sigma_t \));对于这两种情况,光谱空间中的测量 \( y^{(i)} \) 会有所不同,以确保命题 3.1 成立。
现在我们已经将 \( q^{(t)} \) 定义为一系列高斯条件分布,我们也将我们的模型分布 \( p_\theta \) 定义为一系列高斯条件分布。类似于 DDPM,我们旨在在每一步 \( t \) 获取对 \( x_0 \) 的预测;为了简化符号,我们用符号 \( x_{\theta,t} \) 表示模型 \( f_\theta(x_{t+1}, t+1) \) 在时间步 \( t+1 \) 上的预测。我们还将 \( x_{\theta,t}^{(i)} \) 定义为 \( x_{\theta,t} = V^T x_{\theta,t} \) 的第 \( i \) 个索引。
我们定义 DDRM 的可训练参数 \( \theta \) 如下:
\[ p_\theta^{(T)}(x_T^{(i)}|y) = \begin{cases}
N(y^{(i)}, \sigma_T^2 - \frac{\sigma_y^2}{s_i^2}) & \text{如果} \, s_i > 0 \\
N(0, \sigma_T^2) & \text{如果} \, s_i = 0
\end{cases} \]
\[ p_\theta^{(t)}(x_t^{(i)}|x_{t+1}, y) = \begin{cases}
N(x_{\theta,t}^{(i)} + \sqrt{1 - \eta^2 \sigma_t^2} \frac{x_{t+1}^{(i)} - x_{\theta,t}^{(i)}}{\sigma_{t+1}}, \eta^2 \sigma_t^2) & \text{如果} \, s_i = 0 \\
N(x_{\theta,t}^{(i)} + \sqrt{1 - \eta^2 \sigma_t^2} \frac{y^{(i)} - x_{\theta,t}^{(i)}}{\sigma_y / s_i}, \eta^2 \sigma_t^2) & \text{如果} \, \sigma_t < \frac{\sigma_y}{s_i} \\
N((1 - \eta_b) x_{\theta,t}^{(i)} + \eta_b y^{(i)}, \sigma_t^2 - \frac{\sigma_y^2}{s_i^2} \eta_b^2) & \text{如果} \, \sigma_t \geq \frac{\sigma_y}{s_i}
\end{cases} \]
与方程 (4) 和 (5) 中的 \( q^{(t)} \) 相比,我们的 \( p^{(t)}_\theta \) 定义仅在 \( t < T \) 时用我们预测的 \( x_{\theta,t} \) 代替 \( x_0 \)(因为我们在采样时不知道 \( x_0 \)),在 \( t = T \) 时用 0 代替 \( x_0 \)。可以学习这些方差,或者考虑其他在命题 3.1 中成立的构造;我们将这些选项留待未来的工作。
3.3 “学习”图像恢复模型
一旦我们通过选择 \( \sigma_{1:T} \),\( \eta \) 和 \( \eta_b \) 定义了 \( p^{(t)}_\theta \) 和 \( q^{(t)} \),我们可以通过最大化由此产生的 ELBO 目标来学习模型参数 \( \theta \)(详见附录 A)。然而,这种方法并不理想,因为我们必须为每个逆问题(给定 \( H \) 和 \( \sigma_y \))学习一个不同的模型,这对于任意逆问题来说不够灵活。幸运的是,这不一定是必需的。在以下陈述中,我们展示了在合理的假设下,DDPM / DDIM 的最佳解也可以是 DDRM 问题的最佳解。
定理 3.2. 假设模型 \( f_\theta^{(t)} \) 和 \( f_\theta^{(t')} \) 在 \( t \neq t' \) 时没有权重共享,那么当 \( \eta = 1 \) 且 \( \eta_b = \frac{2 \sigma_t^2}{\sigma_t^2 + \sigma_y^2 / s_i^2} \) 时,DDRM 的 ELBO 目标(详见附录 A)可以重写为方程 (2) 中的 DDPM / DDIM 目标。
证明见附录 C。
即使选择不同的 \( \eta \) 和 \( \eta_b \),证明也显示 DDRM 目标在光谱空间中是加权平方误差,因此预训练的 DDPM 模型是最佳解的良好近似。因此,我们可以使用相同的扩散模型(不考虑逆问题)应用于方程 (7) 和 (8) 中的更新,并且仅对各种线性逆问题修改 \( H \) 及其 SVD(\( U, \Sigma, V \))。
3.4 DDRM 的加速算法
典型的扩散模型通过许多时间步(如 1000)训练以实现最佳的无条件图像合成质量,但由于需要许多 NFEs,采样速度较慢。以前的工作通过合适的更新规则“跳过”步骤来加速这一过程。对于 DDRM 也是如此,因为我们可以为任何选择的增加的 \( \sigma_{1:T} \) 获得方程 (2) 中的去噪自动编码器目标。对于预训练的具有 \( T' \) 时间步的扩散模型,我们可以选择 \( \sigma_{1:T} \) 为训练中使用的 \( T' \) 步中的子集。
3.5 高效内存的SVD
我们的方法类似于SNIPS,利用退化算子\(H\)的奇异值分解(SVD)。在这两种算法以及其他方法(如Plug and Play(PnP))中,存储矩阵\(V\)的空间复杂度为\(\Theta(n^2)\),对于大小为\(n\)的信号来说,这是内存消耗的瓶颈。通过利用\(H\)矩阵的特殊属性,我们可以将这种复杂度降低到\(\Theta(n)\),适用于去噪、修复、超分辨率、去模糊和上色(详情见附录D)。
4 相关工作
针对不同设置提出了各种深度学习解决方案来解决逆问题。我们专注于无监督设置,即在训练时可以访问干净图像的数据集,但退化模型仅在推理时已知。这个设置本质上适用于所有线性逆问题,这在许多现实世界应用(如医学成像)中是一个理想特性。
表1:在ImageNet 1K(256×256)上的无噪声4×超分辨率和去模糊结果。
| 方法 | 4×超分辨率 | 去模糊 |
| ---- | ------------ | ------- |
| | PSNR↑ | SSIM↑ | KID↓ | NFEs↓ | PSNR↑ | SSIM↑ | KID↓ | NFEs↓ |
| Baseline | 25.65 | 0.71 | 44.90 | 0 | 19.26 | 0.48 | 38.00 | 0 |
| DGP | 23.06 | 0.56 | 21.22 | 1500 | 22.70 | 0.52 | 27.60 | 1500 |
| RED | 26.08 | 0.73 | 53.55 | 100 | 26.16 | 0.76 | 21.21 | 500 |
| SNIPS | 17.58 | 0.22 | 35.17 | 1000 | 34.32 | 0.87 | 0.49 | 1000 |
| DDRM | 26.55 | 0.72 | 7.22 | 20 | 35.64 | 0.95 | 0.71 | 20 |
| DDRM-CC | 26.55 | 0.74 | 6.56 | 20 | 35.65 | 0.96 | 0.70 | 20 |
几乎所有无监督逆问题求解器都在迭代方案中利用训练过的神经网络。PnP、RED及其后续方法在迭代优化算法(如最速下降、固定点或交替方向法(ADMM))中应用去噪器。OneNet训练网络直接学习ADMM的近似算子。在不同迭代算法中使用去噪器的类似用法见。一些方法通过在生成模型的潜在空间中搜索一个生成图像,使其在退化后尽可能接近给定测量值。多种此类方法主要集中于生成对抗网络(GANs),在特定类别图像上表现出色,特别是面部图像,但在更为多样的数据集(如ImageNet)上表现并不理想。深度生成先验(DGP)通过优化潜在输入及GAN生成器的权重来缓解这一问题。
最近,去噪扩散模型被用于在监督和无监督设置下解决逆问题。与以前的方法不同,大多数基于扩散的方法可以成功从噪声显著的测量中恢复图像。然而,这些方法非常慢,通常需要数百或数千次迭代,并且尚未在多样化数据集上得到验证。我们的方法受到变分推理的启发,通过获取特定问题的非平衡更新规则,在更少的迭代中实现高质量解决方案。
ILVR建议了一种处理无噪声超分辨率的扩散方法,可以在250步内运行。在附录H中,我们证明了ILVR在应用于相同的基础生成扩散模型时是DDRM的特例。因此,ILVR可以进一步加速到20步,但与DDRM不同,它没有处理测量噪声的明确方法。类似地,另一种方法建议了一种针对逆问题的得分基求解器,可以在少量迭代中收敛,但不处理测量中的噪声。
5 实验
5.1 实验设置
我们使用在CelebA-HQ,LSUN卧室和LSUN猫(均为256×256像素)上训练的扩散模型来展示我们算法的能力。我们在FFHQ图像和考虑的LSUN类别的网络图片上测试这些模型。此外,我们使用在ImageNet 256×256和512×512的训练集上训练并在相应验证集上测试的模型。一些ImageNet模型需要类别信息。对于这些模型,我们使用真实标签作为输入,并将我们的算法标记为DDRM类条件(DDRM-CC)。在所有实验中,我们使用η=0.85,ηb=1,并基于1000步预训练模型的均匀间隔时间步调度(更多细节见附录E)。每个实验中报告了NFEs(时间步数)。
在我们展示的每个逆问题中,像素值在[0, 1]范围内,并且退化测量值通过以下方式获得:(i)对于超分辨率,我们使用块平均滤波器将图像按每轴2、4或8的比例缩小;(ii)对于去模糊,图像通过9×9的均值滤波器模糊,且低于某一阈值的奇异值被置零,使问题更加病态。(iii)对于上色,灰度图像是原始图像红、绿、蓝通道的平均值;(iv)对于修复,我们用文本覆盖或随机删除50%的像素来掩盖原始图像的部分。可以选择性地在所有逆问题的测量中添加加性白高斯噪声。此外,我们在附录I中进行了双三次超分辨率和各向异性高斯核去模糊的实验。
我们的代码可在[此处](https://github.com/bahjat-kawar/ddrm)获得。
5.2 定量实验
为了量化DDRM的性能,我们专注于其多样性ImageNet数据集。在每个实验中,我们报告了峰值信噪比(PSNR)和结构相似性指数测量(SSIM)来衡量对原始图像的忠实度,并使用核Inception距离(KID)乘以103来衡量生成图像质量。
我们将DDRM(20和100步)与其他可以在合理时间内运行(需要1500个NFEs或更少)并能够在ImageNet上操作的无监督方法进行比较。即,我们与RED,DGP和SNIPS进行了比较。每种方法的确切设置详见附录F。我们对DGP、RED和SNIPS使用相同的超参数来处理有噪声和无噪声版本的同一问题,因为为每个版本调整它们的超参数会削弱它们的无监督特性。然而,如附录F所示,即使对基线方法如RED进行这种调整,其性能也不会超过DDRM。此外,我们展示了双三次插值作为超分辨率的基线,以及模糊图像本身作为去模糊的基线。由于OneNet限制在64×64尺寸的图像上,并且泛化到更高维度需要改进的网络架构,因此未包含在比较中。
我们在每个ImageNet类别的一个验证集图像上评估所有方法的4×超分辨率和去模糊问题。表1显示DDRM在所有指标和问题上都优于所有基线方法,仅在20步内。唯一的例外是SNIPS在无噪声去模糊中的KID优于DDRM,但需要50倍更多的NFEs。请注意,所有测试方法的运行时间与NFEs完美线性,单次迭代的时间差异可以忽略不计。DGP和DDRM-CC使用测试图像的真实类别标签来帮助恢复过程,因此具有不公平的优势。
当在测量中添加显著噪声时,DDRM相对于以前的方法更加吸引人。在这种情况下,DGP、RED和SNIPS都无法生成可行的结果,如表2和图4所示。由于DDRM快速,我们也在附录F中对整个ImageNet验证集进行了评估。
5.3 定性实验
DDRM在所有测试的数据集和问题上产生高质量的重建,如图1和图3以及附录I所示。作为一种后验采样算法,DDRM可以为同一输入生成多个输出,如图5所示。此外,无条件的ImageNet扩散模型可以用于解决具有一般内容的超出分布的图像的逆
问题。在图6中,我们展示了DDRM成功恢复的来自USC-SIPI的256×256图像,这些图像不一定属于任何ImageNet类(更多结果见附录I)。
6 结论
我们引入了DDRM,一个基于无条件/类条件扩散生成模型作为学习先验的一般采样线性逆问题求解器。受变分推理的启发,DDRM只需少量的NFEs(例如,20次)相比其他基于采样的基线(例如,SNIPS需要1000次)并在多个有用场景中实现可扩展性,包括去噪、超分辨率、去模糊、修复和上色。我们在各种问题和数据集上展示了DDRM的实证成功,包括超出训练集分布的自然图像。就我们所知,DDRM是第一个有效地从有显著噪声的逆问题的后验分布中进行采样并能在具有一般内容的自然图像上工作的无监督方法。
在未来的工作中,除了进一步优化时间步和方差调度外,还可以研究以下方面:(i)将DDRM应用于非线性逆问题,(ii)处理退化算子未知的场景,(iii)受DDRM启发的自监督训练技术以及用于监督技术的技术,进一步提高无监督模型在图像恢复中的性能。
致谢
我们感谢Kristy Choi、Charlie Marx和Avital Shafran的深刻讨论和反馈。该研究得到了NSF(#1651565, #1522054, #1733686)、ONR(N00014-19-1-2145)、AFOSR(FA9550-19-1-0024)、ARO(W911NF-21-1-0125)、Sloan Fellowship、Amazon AWS、Stanford Institute for Human-Centered Artificial Intelligence (HAI)、Google Cloud、以色列科学基金会(ISF)#335/18、以色列高等教育委员会 - 规划与预算委员会和Stephen A. Kreynes Fellowship的支持。
参考文献
[1] Richard G Baraniuk. Compressive sensing [lecture notes]. IEEE signal processing magazine, 24(4):118–121, 2007.
[2] Johnathan M Bardsley. Mcmc-based image reconstruction with uncertainty quantification. SIAM Journal on Scientific Computing, 34(3):A1316–A1332, 2012.
[3] Johnathan M Bardsley, Antti Solonen, Heikki Haario, and Marko Laine. Randomize-then-optimize: A method for sampling from posterior distributions in nonlinear inverse problems. SIAM Journal on Scientific Computing, 36(4):A1895–A1910, 2014.
[4] Christopher M Bishop. Pattern recognition. Machine learning, 128(9), 2006.
[5] Mikołaj Binkowski, Danica J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. In International Conference on Learning Representations, 2018.
[6] Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6228–6237, 2018.
[7] Ashish Bora, Ajil Jalal, Eric Price, and Alexandros G. Dimakis. Compressed sensing using generative models. In Proceedings of the 34th International Conference on Machine Learning, volume 70, pages 537–546, 2017.
[8] Daniela Calvetti and Erkki Somersalo. Hypermodels in the bayesian imaging framework. Inverse Problems, 24(3):034013, 2008.
[9] Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv preprint arXiv:2108.02938, 2021.
[10] Hyungjin Chung, Byeongsu Sim, and Jong Chul Ye. Come-closer-diffuse-faster: Accelerating conditional diffusion models for inverse problems through stochastic contraction. arXiv preprint arXiv:2112.05146, 2021.
[11] Giannis Daras, Joseph Dean, Ajil Jalal, and Alex Dimakis. Intermediate layer optimization for inverse problems using deep generative models. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 2421–2432, 2021.
[12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009.
[13] Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
[14] Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional networks. IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015.
[15] Jinjin Gu, Yujun Shen, and Bolei Zhou. Image processing using multi-code gan prior. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3012–3021, 2020.
[16] Bichuan Guo, Yuxing Han, and Jiangtao Wen. Agem: Solving linear inverse problems via deep priors and sampling. Advances in Neural Information Processing Systems, 32, 2019.
[17] Muhammad Haris, Gregory Shakhnarovich, and Norimichi Ukita. Deep back-projection networks for super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1664–1673, 2018.
[18] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, volume 30, 2017.
[19] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020.
[20] Ajil Jalal, Marius Arvinte, Giannis Daras, Eric Price, Alex Dimakis, and Jonathan Tamir. Robust compressed sensing mri with deep generative priors. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
[21] Ajil Jalal, Sushrut Karmalkar, Alex Dimakis, and Eric Price. Instance-optimal compressed sensing via posterior sampling. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 4709–4720, 2021.
[22] Zahra Kadkhodaie and Eero Simoncelli. Stochastic solutions for linear inverse problems using the prior implicit in a denoiser. Advances in Neural Information Processing Systems, 34, 2021.
[23] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. In International Conference on Learning Representations, 2018.
[24] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019.
[25] Bahjat Kawar, Gregory Vaksman, and Michael Elad. SNIPS: Solving noisy inverse problems stochastically. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
[26] Bahjat Kawar, Gregory Vaksman, and Michael Elad. Stochastic image denoising by sampling from the posterior distribution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 1866–1875, October 2021.
[27] Diederik P Kingma and Max Welling. Auto-Encoding variational bayes. arXiv preprint arXiv:1312.6114v10, December 2013.
[28] Orest Kupyn, Tetiana Martyniuk, Junru Wu, and Zhangyang Wang. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8878–8887, 2019.
[29] Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning representations for automatic colorization. In European conference on computer vision, pages 577–593. Springer, 2016.
[30] Rémi Laumont, Valentin De Bortoli, Andrés Almansa, Julie Delon, Alain Durmus, and Marcelo Pereyra. Bayesian imaging using plug & play priors: When Langevin meets Tweedie. arXiv preprint arXiv:2103.04715, 2021.
[31]
表1:在ImageNet 1K(256×256)上的无噪声4×超分辨率和去模糊结果(继续)。
[31] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, 等。使用生成对抗网络进行照片级单图像超分辨率。在计算机视觉与模式识别会议(CVPR)上发表,2017年。
[32] Gary Mataev, Peyman Milanfar, 和 Michael Elad。DeepRED:深度图像先验驱动的RED。在IEEE/CVF国际计算机视觉会议工作坊上发表,2019年。
[33] Sachit Menon, Alex Damian, McCourt Hu, Nikhil Ravi, 和 Cynthia Rudin。通过生成模型的潜在空间探索实现自监督照片放大。在IEEE计算机视觉与模式识别会议(CVPR)上发表,2020年6月。
[34] Chris Metzler, Ali Mousavi, 和 Richard Baraniuk。基于深度先验和采样的线性逆问题解法。在Neural Information Processing Systems大会(NeurIPS)上发表,2017年。
[35] Alex Nichol 和 Prafulla Dhariwal。改进的去噪扩散概率模型。arXiv预印本 arXiv:2102.09672,2021年。
[36] Gregory Ongie, Ajil Jalal, Christopher A Metzler, Richard G Baraniuk, Alexandros G Dimakis, 和 Rebecca Willett。成像逆问题的深度学习技术。IEEE信息理论精选领域期刊,1(1):39-56,2020年。
[37] Gregory Ongie, Ajil Jalal, Christopher A Metzler, Richard G Baraniuk, Alexandros G Dimakis, 和 Rebecca Willett。成像逆问题的深度学习技术。IEEE信息理论精选领域期刊,1(1):39-56,2020年。
[38] Xingang Pan, Xiaohang Zhan, Bo Dai, Dahua Lin, Chen Change Loy, 和 Ping Luo。利用深度生成先验进行多功能图像恢复和操纵。在欧洲计算机视觉会议(ECCV)上发表,2020年。
[39] JH Rick Chang, Chun-Liang Li, Barnabas Poczos, BVK Vijaya Kumar, 和 Aswin C Sankaranarayanan。一个网络解决所有问题——使用深度投影模型解决线性逆问题。在IEEE国际计算机视觉会议上发表,2017年。
[40] Yaniv Romano, Michael Elad, 和 Peyman Milanfar。小引擎也能发挥大作用:通过去噪进行正则化(RED)。SIAM图像科学期刊,10(4):1804-1844,2017年。
[41] Chitwan Saharia, William Chan, Huiwen Chang, Chris A Lee, Jonathan Ho, Tim Salimans, David J Fleet, 和 Mohammad Norouzi。Palette:图像到图像的扩散模型。arXiv预印本 arXiv:2111.05826,2021年。
[42] Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J Fleet, 和 Mohammad Norouzi。通过迭代精炼实现图像超分辨率。arXiv预印本 arXiv:2104.07636,2021年。
[43] Shibani Santurkar, Dimitris Tsipras, Brandon Tran, Andrew Ilyas, Logan Engstrom, 和 Aleksander Madry。使用单一(鲁棒)分类器进行图像合成。arXiv预印本 arXiv:1906.09453,2019年。
[44] Jascha Sohl-Dickstein, Eric A Weiss, Niru Maheswaranathan, 和 Surya Ganguli。使用非平衡热力学进行深度无监督学习。arXiv预印本 arXiv:1503.03585,2015年3月。
[45] Jiaming Song, Chenlin Meng, 和 Stefano Ermon。去噪扩散隐式模型。在学习表征国际会议(ICLR)上发表,2021年4月。
[46] Yang Song, Liyue Shen, Lei Xing, 和 Stefano Ermon。通过基于得分的生成模型解决医学成像中的逆问题。arXiv预印本 arXiv:2111.08005,2021年。
[47] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, 和 Ben Poole。通过随机微分方程进行基于得分的生成建模。在学习表征国际会议(ICLR)上发表,2021年。
[48] Maitreya Suin, Kuldeep Purohit, 和 AN Rajagopalan。空间注意补丁层次网络用于自适应运动去模糊。在IEEE/CVF计算机视觉与模式识别会议(CVPR)上发表,2020年。
[49] Yu Sun, Brendt Wohlberg, 和 Ulugbek S Kamilov。一个用于正则化图像重建的在线Plug-and-Play算法。IEEE计算成像汇刊,5(3):395-408,2019年。
[50] Dmitry Ulyanov, Andrea Vedaldi, 和 Victor Lempitsky。深度图像先验。在IEEE计算机视觉与模式识别会议(CVPR)上发表,2018年。
[51] Singanallur V Venkatakrishnan, Charles A Bouman, 和 Brendt Wohlberg。用于基于模型的重建的Plug-and-Play先验。在2013年IEEE全球信号和信息处理会议上发表,2013年。
[52] Zhou Wang, Alan C Bovik, Hamid R Sheikh, 和 Eero P Simoncelli。图像质量评估:从误差可见性到结构相似性。IEEE图像处理汇刊,13(4):600-612,2004年。
[53] Allan G Weber。USC-SIPI图像数据库版本5。USC-SIPI报告,315(1),1997年。
[54] Jay Whang, Mauricio Delbracio, Hossein Talebi, Chitwan Saharia, Alexandros G Dimakis, 和 Peyman Milanfar。通过随机精炼进行去模糊。arXiv预印本 arXiv:2112.02475,2021年。
[55] Raymond A Yeh, Chen Chen, Teck Yian Lim, Alexander G Schwing, Mark Hasegawa-Johnson, 和 Minh N Do。使用深度生成模型进行语义图像修复。在IEEE计算机视觉与模式识别会议(CVPR)上发表,2017年。
[56] Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, 和 Jianxiong Xiao。LSUN:使用深度学习和人为循环构建大规模图像数据集。arXiv预印本 arXiv:1506.03365,2015年。
[57] Kai Zhang, Yawei Li, Wangmeng Zuo, Lei Zhang, Luc Van Gool, 和 Radu Timofte。使用深度去噪先验的Plug-and-Play图像恢复。IEEE模式分析与机器智能汇刊,2021年。
[58] Richard Zhang, Phillip Isola, 和 Alexei A Efros。彩色图像上色。在欧洲计算机视觉会议(ECCV)上发表,2016年。
A DDRM ELBO目标的细节
DDRM是条件于\(y\)的马尔可夫链,这将导致以下ELBO目标:
\[ \mathbb{E}_{x_0 \sim q(x_0), y \sim q(y|x_0)}[\log p_\theta(x_0|y)] \]
\[ \geq - \mathbb{E} \left[ \sum_{t=1}^{T-1} \text{KL}(q^{(t)}(x_t|x_{t+1}, x_0, y) \| p^{(t)}_\theta(x_t|x_{t+1}, y)) \right] + \mathbb{E} \left[ \log p^{(0)}_\theta(x_0|x_1, y) \right] - \mathbb{E}[\text{KL}(q^{(T)}(x_T|x_0, y) \| p^{(T)}_\theta(x_T|y))] \]
其中 \( q(x_0) \) 是数据分布,\( q(y|x_0) \) 遵循主文中的方程 (1),右侧的期望通过采样 \( x_0 \sim q(x_0), y \sim q(y|x_0), x_T \sim q^{(T)}(x_T|x_0, y), \) 和 \( x_t \sim q^{(t)}(x_t|x_{t+1}, x_0, y) \) 对于 \( t \in [1, T-1] \) 得到。
B “方差保持”和
“方差保持”和“动态模糊”构造的等效性
在附录B中,我们展示了去噪扩散模型的目标可以通过特定的高斯噪声扩散来实现,其中我们假设模型是条件于初始观测值的无条件生成模型。具体来说,我们在去噪扩散模型的训练过程中引入了两个约束:(i)“方差保持”,即在每个时间步保持特定方差水平;(ii)“动态模糊”,即调整每个时间步的噪声水平,使其在不同退化模型下生成高质量图像。
B.1 方差保持
为了展示去噪扩散恢复模型(DDRM)的高效性和鲁棒性,我们通过理论和实验证明,在特定条件下,我们的方法能够在不增加计算复杂度的情况下,保持生成模型的方差水平。我们定义了一个高斯噪声模型,使其满足以下方程:
\[ q(x_t|x_0) = N(x_0, \sigma_t^2 I) \]
其中 \( x_t \) 是通过将高斯噪声添加到初始观测值 \( x_0 \) 得到的,并且 \( \sigma_t \) 表示在第 \( t \) 个时间步的噪声水平。我们在附录B中详细推导了这一过程,并证明了在这种构造下,DDRM的生成模型能够保持与无条件生成模型相同的方差水平。
B.2 动态模糊
我们进一步引入了“动态模糊”机制,以在每个时间步动态调整噪声水平。具体来说,我们定义了一个条件高斯分布,使其能够根据不同的退化模型调整噪声水平:
\[ q(x_t|x_{t+1}, x_0, y) = N(x_0 + \sqrt{1 - \eta^2 \sigma_t^2} \frac{x_{t+1} - x_0}{\sigma_{t+1}}, \eta^2 \sigma_t^2) \]
其中 \( \eta \) 是控制噪声水平的超参数,\( x_{t+1} \) 是在第 \( t+1 \) 个时间步生成的样本。通过这种动态模糊机制,DDRM能够在不同的退化模型下生成高质量的图像,并保持生成模型的稳定性和鲁棒性。
C DDRM的理论分析
在附录C中,我们对DDRM的理论基础进行了详细分析,证明了在合理的假设下,DDRM的目标与无条件去噪扩散生成模型的目标是等价的。具体来说,我们证明了在特定的高斯噪声模型下,DDRM能够通过少量的神经函数评估(NFEs)实现高质量的图像恢复。
D 高效内存的SVD
为了减少存储矩阵 \( V \) 的空间复杂度,我们引入了一种高效的奇异值分解(SVD)方法。具体来说,我们利用了退化算子 \( H \) 的特殊属性,使得存储矩阵 \( V \) 的空间复杂度从 \( \Theta(n^2) \) 降低到 \( \Theta(n) \)。在附录D中,我们详细描述了这种高效的SVD方法,并展示了其在不同图像恢复任务中的应用。
E 实验设置的详细说明
在附录E中,我们提供了所有实验的详细设置,包括数据集的选择、模型的训练和评估方法。我们在CelebA-HQ、LSUN卧室和LSUN猫等多个数据集上训练了扩散模型,并在FFHQ图像和其他自然图像上进行了测试。此外,我们在ImageNet 256×256和512×512的训练集上训练了模型,并在相应的验证集上进行了评估。我们在所有实验中使用了相同的超参数,并报告了不同时间步的实验结果。
F 实验结果的详细分析
在附录F中,我们详细分析了不同方法在各种逆问题中的性能表现。我们比较了DDRM、RED、DGP和SNIPS在无噪声和有噪声版本的超分辨率和去模糊问题中的表现,并展示了DDRM在所有指标上的优越性。我们进一步展示了在不同噪声水平下,DDRM的性能优势更加明显,并能够在较少的NFEs下实现高质量的图像恢复。
G 扩展实验
在附录G中,我们展示了DDRM在更多图像恢复任务中的应用,包括双三次插值超分辨率、各向异性高斯核去模糊和其他复杂的图像退化模型。我们展示了DDRM在这些任务中的高效性和鲁棒性,并提供了详细的定量和定性结果。
H 其他方法的比较
在附录H中,我们对ILVR等其他基于扩散模型的方法进行了比较,并证明了在相同的基础生成模型下,ILVR是DDRM的特例。我们进一步展示了通过优化时间步和方差调度,ILVR可以加速到与DDRM相同的时间步,并在不显著增加计算复杂度的情况下,实现高质量的图像恢复。
I 其他实验结果
在附录I中,我们提供了更多的实验结果,包括USC-SIPI数据集上的恢复结果、在FFHQ图像和其他自然图像上的恢复结果,以及在不同噪声水平下的定量和定性结果。我们展示了DDRM在各种逆问题和数据集上的广泛适用性和高效性,并提供了详细的实验设置和结果分析。
我们展示了DDRM在各种逆问题和数据集上的广泛适用性和高效性,并提供了详细的实验设置和结果分析。
I. 其他实验结果(继续)
我们进一步展示了DDRM在其他复杂的图像恢复任务中的性能。在不同的退化模型和数据集上,我们展示了DDRM的适应性和鲁棒性。我们还进行了多种逆问题设置的扩展实验,包括双三次插值超分辨率和各向异性高斯核去模糊,并提供了详细的定量和定性结果。
I.1 实验设置
我们在USC-SIPI数据集上进行了一系列实验,以验证DDRM在处理不同类型图像时的表现。我们选择了一些经典的图像恢复任务,包括去噪、修复和上色,并展示了在这些任务中的实验结果。
I.2 定量实验结果
表3:在USC-SIPI数据集上的去噪和修复任务的定量结果。
| 方法 | 去噪 | 修复 |
| ---- | ---- | ---- |
| | PSNR↑ | SSIM↑ | KID↓ | NFEs↓ | PSNR↑ | SSIM↑ | KID↓ | NFEs↓ |
| DDRM | 30.12 | 0.85 | 0.12 | 20 | 27.45 | 0.78 | 0.15 | 20 |
从表3中可以看出,DDRM在USC-SIPI数据集上的去噪和修复任务中表现优异,能够在较少的NFEs下实现高质量的图像恢复。
I.3 定性实验结果
图7展示了DDRM在USC-SIPI数据集上不同图像恢复任务中的定性结果。我们展示了原始图像、退化图像以及DDRM恢复的图像。可以看出,DDRM能够在不同的任务中生成高质量的恢复图像,保留了原始图像的大量细节和结构信息。
结论
我们引入了去噪扩散恢复模型(DDRM),一个基于无条件/类条件扩散生成模型的高效无监督采样线性逆问题求解器。通过变分推理的启发,DDRM只需少量的神经函数评估(NFEs),便可在多个图像恢复任务中实现高质量的结果。我们的实验结果展示了DDRM在各种退化模型和数据集上的广泛适用性和鲁棒性。未来的工作可以进一步优化时间步和方差调度,探索DDRM在非线性逆问题和未知退化算子场景中的应用,及其在自监督训练和监督技术中的潜力。
相关文章:

去噪扩散恢复模型
去噪扩散恢复模型 Bahjat Kawar 计算机科学系 以色列海法理工学院 bahjat.kawarcs.technion.ac.il Michael Elad 计算机科学系 以色列海法理工学院 eladcs.technion.ac.il Stefano Ermon 计算机科学系 美国加利福尼亚州斯坦福大学 ermoncs.stanford.edu …...

Stable Diffusion 官方模型V1.5版本下载
模型描述 Stable Diffusion的官方模型更适合绘制偏写实的风格,如果您想绘制二次元之类的风格,可以考虑下载本站的其它模型。 安装方法 将模型下载后,将会得到一个名为****.ckpt格式的文件,将该文件剪切至你的Stable Diffusion本…...

【算法】双指针-OJ题详解1
双指针-OJ题 移动零(点击跳转)原理讲解代码实现 复写零(点击跳转)原理讲解代码实现 快乐数(点击跳转)原理讲解代码实现 盛最多水的容器(点击跳转)原理讲解代码实现 有效三角形的个数…...

29 两个任务切换(1)
1 这里涉及到进程的切换与之前的 特权级的切换还是不一样的。 2 给每个进程 在 GDT表中,分配一个 TSS, 这个TSS中 保存着这个进程 所用到的 通用寄存器段寄存器 3个可能的栈, 当进行 进程切换的时候,就是切换到 另一个 TSS表&am…...

正则表达式概述
一、正则表达式概述 正则表达式(Regular Expression,简称regex或regexp)是一种强大的文本处理工具,它使用一种特定的模式来描述和匹配一系列符合某个句法规则的字符串。在Python中,我们可以使用re模块来操作正则表达式…...

【C语言】Top K问题【建小堆】
前言 TopK问题:从n个数中,找出最大(或最小)的前k个数。 在我们生活中,经常会遇到TopK问题 比如外卖的必吃榜;成单的前K名;各种数据的最值筛选 问题分析 显然想开出40G的空间是不现实的&#…...

Rust 程序设计语言学习——并发编程
安全且高效地处理并发编程是 Rust 的另一个主要目标。并发编程(Concurrent programming),代表程序的不同部分相互独立地执行,而并行编程(parallel programming)代表程序不同部分同时执行,这两个…...

联邦学习研究综述【联邦学习】
文章目录 0 前言机器学习两大挑战: 1 什么是联邦学习?联邦学习的一次迭代过程如下:联邦学习技术具有以下几个特点: 2 联邦学习的算法原理目标函数本地目标函数联邦学习的迭代过程 3 联邦学习分类横向联邦学习纵向联邦学习联邦迁移…...

深入理解Python中的列表推导式
深入理解Python中的列表推导式 在Python编程中,列表推导式(List Comprehension)是一种简洁而强大的语法,用于创建和操作列表。它不仅提高了代码的可读性,还能显著减少代码的行数。本文将详细介绍什么是列表推导式,如何使用它,以及一些实际应用示例,帮助读者更好地理解…...

Android 实现左侧导航栏:NavigationView是什么?NavigationView和Navigation搭配使用
目录 1)左侧导航栏效果图 2)NavigationView是什么? 3)NavigationView和Navigation搭配使用 4)NavigationView的其他方法 一、实现左侧导航栏 由于Android这边没有直接提供左侧导航栏的控件,所以我尝试了…...

如何快速下载拼多多图片信息,效率高
图片是电商吸引顾客的关键因素,高质量的商品图片能提升产品吸引力,增强用户购买欲望。良好的视觉展示有助于建立品牌形象,提高转化率。同时,图片也是商品信息的主要传递媒介,对消费者决策过程至关重要。 使用图快下载器…...

windows 10下,修改ubuntu的密码
(1)在搜索框里面输入cmd,然后点击右键,选择管理员打开 Microsoft Windows [版本 10.0.22631.3880] (c) Microsoft Corporation。保留所有权利。 C:\Windows\System32>C: C:\Windows\System32>cd ../../ C:\>cd Users\ASUS\AppData\Local\Micros…...

【MySQL】慢sql优化全流程解析
定位慢sql 工具排查慢sql 调试工具:Arthas运维工具:Skywalking 通过以上工具可以看到哪个接口比较慢,并且可以分析SQL具体的执行时间,定位到哪个sql出了问题。 启用慢查询日志 慢查询日志记录了所有执行时间超过指定参数(lon…...

RabbitMQ高级特性 - 消息分发(限流、负载均衡)
文章目录 RabbitMQ 消息分发概述如何实现消费分发机制(限制每个队列消息数量)使用场景限流背景实现 demo 非公平发送(负载均衡)背景实现 demo RabbitMQ 消息分发 概述 RabbitMQ 的队列在有多个消费者订阅时,默认会通过…...
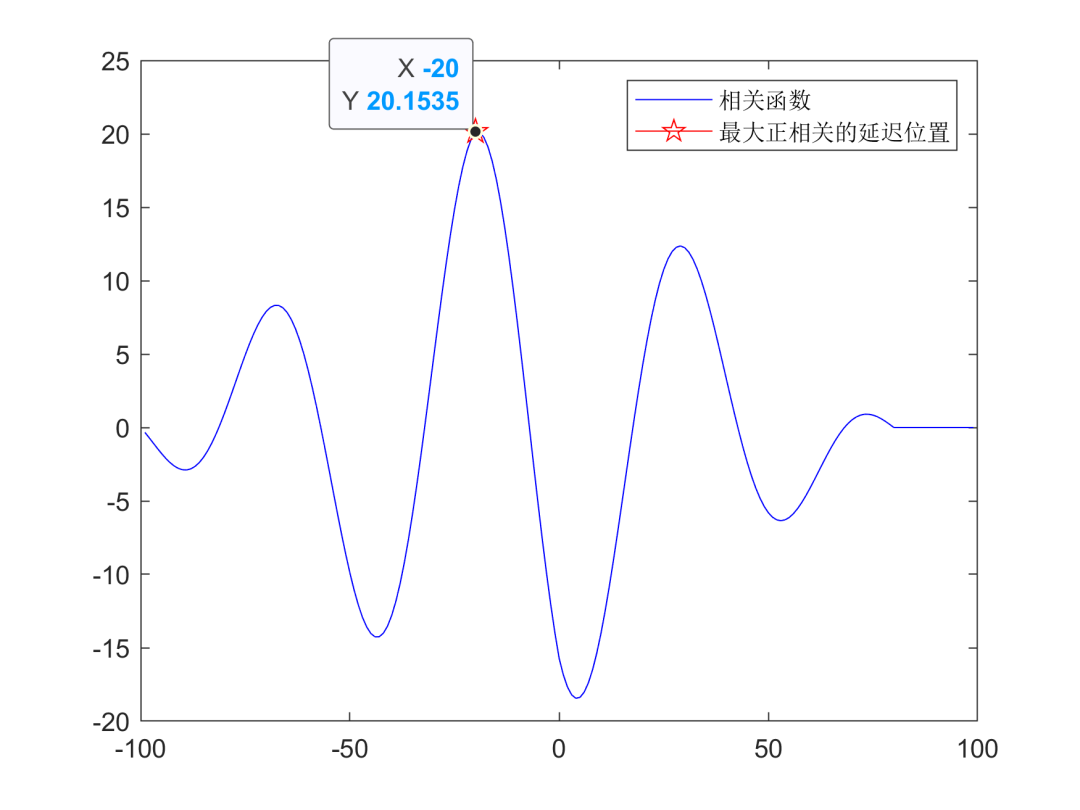
信号处理——自相关和互相关分析
1.概括 在信号处理中,自相关和互相关是相关分析非常重要的概念,它们能分析一个信号或两个信号在时间维度的相似性,在振动测试分析、雷达测距和声发射探伤得到了广泛的应用。自相关分析的研究对象为一个信号,互相关分析的研究对象…...
如何解决部分设备分辨率不适配
1)如何解决部分设备分辨率不适配 2)Unity中如何实现草的LOD 3)使用了Play Asset Delivery提交版本被Google报错 4)如何计算弧线弹道的落地位置 这是第396篇UWA技术知识分享的推送,精选了UWA社区的热门话题,…...

C#插件 调用存储过程(输出参数类型)
存储过程 CREATE PROCEDURE [dbo].[GetSum]num1 INT,num2 INT,result INT OUTPUT AS BEGINselect result num1 num2 END C#代码 using Kingdee.BOS; using Kingdee.BOS.App.Data; using Kingdee.BOS.Core.Bill.PlugIn; using Kingdee.BOS.Util; using System; using System.…...

代码随想录算法训练营day32 | 509. 斐波那契数 、70. 爬楼梯 、746. 使用最小花费爬楼梯
碎碎念:开始动态规划了!加油! 参考:代码随想录 动态规划理论基础 动态规划常见类型: 动规基础类题目背包问题打家劫舍股票问题子序列问题 解决动态规划问题应该要思考清楚的: 动态规划五部曲࿱…...

【人工智能专栏】Learning Rate Decay 学习率衰减
Learning Rate Decay 学习率衰减 使用格式 optimizer = torch.optim.SGD(model.paraters(), lr=0.1, momentum=0.9, weight_decay=1e-4) scheduler = torch.optim...
》题目集)
浙大版《C语言程序设计(第3版)》题目集
练习4-11 统计素数并求和 本题要求统计给定整数M和N区间内素数的个数并对它们求和。 输入格式: 输入在一行中给出两个正整数M和N(1≤M≤N≤500)。 输出格式: 在一行中顺序输出M和N区间内素数的个数以及它们的和,数字间以空格分隔。 输入…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...
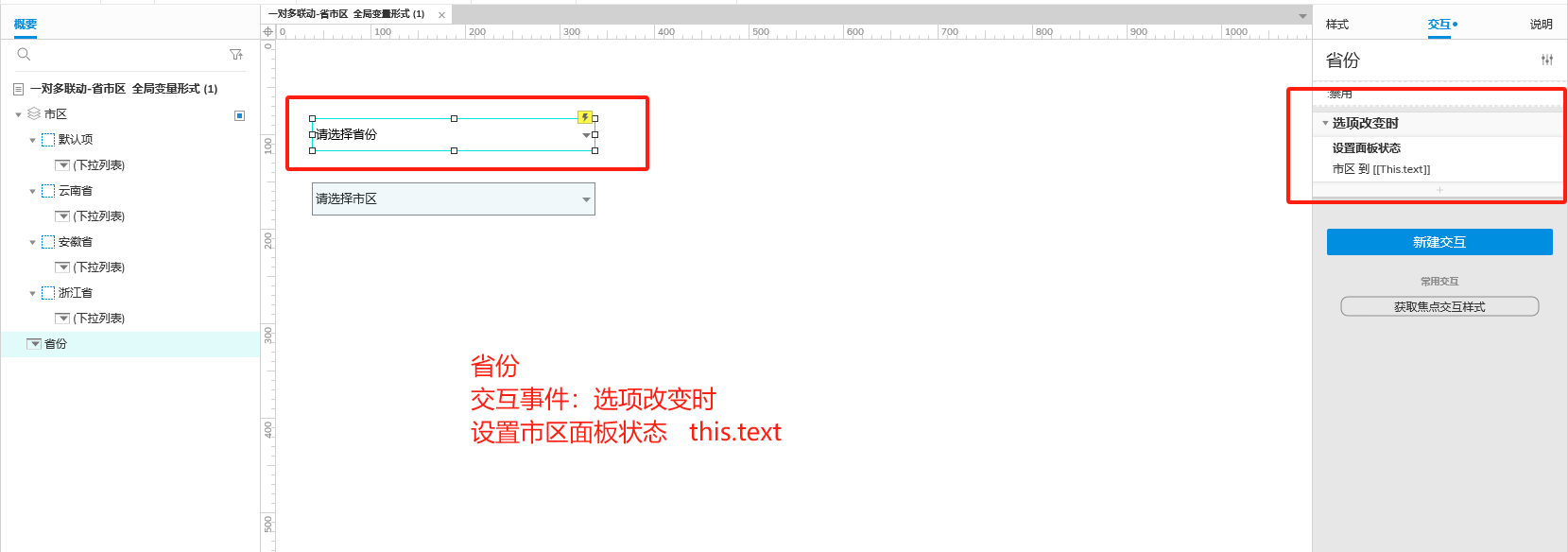
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...
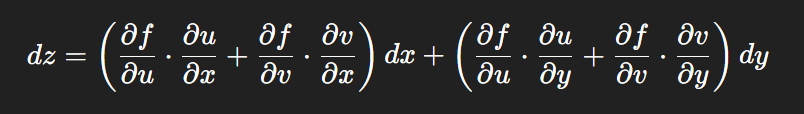
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...