【MySQL】索引——索引的引入、认识磁盘、磁盘的组成、扇区、磁盘访问、磁盘和MySQL交互、索引的概念
文章目录
- MySQL
- 1. 索引的引入
- 2. 认识磁盘
- 2.1 磁盘的组成
- 2.2 扇区
- 2.3 磁盘访问
- 3. 磁盘和MySQL交互
- 4. 索引的概念
- 4.1 索引测试
- 4.2 Page
- 4.3 单页和多页情况
MySQL

1. 索引的引入
海量表在进行普通查询的时候,效率会非常的慢,但是索引可以解决这个问题。
--构建一个8000000条记录的数据
--构建的海量表数据需要有差异性,所以使用存储过程来创建
-- 产生随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
--产生随机数字
delimiter $$
create function rand_num()
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
--创建存储过程,向雇员表添加海量数据
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
-- 执行存储过程,添加8000000条记录
call insert_emp(100001, 8000000);
查询员工编号为998877的员工
select * from EMP where empno=998877;
本机一个人来操作就要耗时接近5秒,所有如果放在公网中,假如同时有1000个人并发查询,那很可能就死机。
解决方法,创建索引
alter table EMP add index(empno);
换一个员工编号,测试看看查询时间
select * from EMP where empno=123456;
2. 认识磁盘
磁盘(disk)是指利用磁记录技术存储数据的存储器。
磁盘是计算机主要的存储介质,可以存储大量的二进制数据,并且断电后也能保持数据不丢失。早期计算机使用的磁盘是软磁盘(Floppy Disk,简称软盘),如今常用的磁盘是硬磁盘(Hard disk,简称硬盘)。

2.1 磁盘的组成
盘片:
盘片:是存储数据的主要介质,通常由铝、玻璃或陶瓷等材料制成,表面涂有磁性物质,数据就记录在这些磁性涂层上。
例如,一个磁盘可能有多个盘片,像多层蛋糕一样叠放。

磁道:
磁道是磁盘表面上的一组同心圆。数据在磁盘上的存储就是分布在这些磁道上的。可以把磁道想象成一个环形的跑道,数据就如同运动员在跑道上的位置。每个磁道被划分成多个扇区,扇区是数据读写的基本单位。磁道的密度会影响磁盘的存储容量和数据传输速度。
例如,磁盘外圈的磁道周长较长,能存储更多数据,而内圈磁道周长较短,存储的数据相对较少。在磁盘工作时,磁头会沿着磁道移动来读取或写入数据。

2.2 扇区
扇区:
扇区是磁盘存储的基本单位它的大小一般是固定的,常见为 512 字节。比如要存数据到磁盘,就会按扇区来存放。扇区有编号,从 0 开始。
相邻扇区组成磁道,多个磁道构成盘面。就算数据不满一个扇区,也会占一整个扇区的空间。扇区能让磁盘存储更高效、管理数据更方便。
数据库文件,本质其实就是保存在磁盘的盘片当中。也就是上面的一个个小格子中,就是我们经常所说的扇区。当然,数据库文件很大,也很多,一定需要占据多个扇区。
定位扇区:
通常存储着磁盘的重要信息,比如分区表,这能告诉系统磁盘如何划分区域来存储不同的数据。还可能存有引导记录,帮助计算机启动时找到操作系统的位置并加载。定位扇区就像是磁盘的“地图指南”和“启动钥匙”。
例如,当计算机开机时,会首先读取定位扇区的信息,来知道如何找到并启动系统

定位扇区:通常是指在磁盘操作中,为了特定目的而专门标识或指定的扇区。它可能具有特殊的用途或被系统用于特定的功能,例如存储磁盘的关键信息,如分区表、引导记录等。
普通扇区:则是磁盘上用于一般数据存储和读写的扇区。
我们现在已经能够在硬件层面定位,任何一个基本数据块了(扇区)。那么在系统软件上,就直接按照扇区(512字节,部分4096字节),进行IO交互吗?不是
如果操作系统直接使用硬件提供的数据大小进行交互,那么系统的IO代码,就和硬件强相关,换言之,如果硬件发生变化,系统必须跟着变化
从目前来看,单次IO512字节,还是太小了。IO单位小,意味着读取同样的数据内容,需要进行多次磁盘访问,会带来效率的降低。
之前文件系统,就是在磁盘的基本结构下建立的,文件系统读取基本单位,就不是扇区,而是数据块。所以,系统读取磁盘,是以块为单位的,基本单位是 4KB 。
2.3 磁盘访问
磁盘随机访问(Random Access)与连续访问(Sequential Access)
随机访问:本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
连续访问:如果当次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
因此尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。
磁盘是通过机械运动进行寻址的,随机访问不需要过多的定位,故效率比较高。
3. 磁盘和MySQL交互
而 MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,所以,为了提高基本的IO效率, MySQL 进行IO的基本单位是 16KB。
也就是说,磁盘这个硬件设备的基本单位是 512 字节,而 MySQL InnoDB引擎 使用 16KB 进行IO交互。MySQL 和磁盘进行数据交互的基本单位是 16KB 。 这个基本数据单元,在 MySQL 这里叫做page。
mysql> SHOW GLOBAL STATUS LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 | -- 16*1024=16384
+------------------+-------+
1 row in set (0.01 sec)
总结:
MySQL 中的数据文件,是以page为单位保存在磁盘当中的。
MySQL 的 CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数据。
而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。
所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。
为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进行IO交互。
为何更高的效率,一定要尽可能的减少系统和磁盘IO的次数。
4. 索引的概念
MySQL 索引是一种用于提高数据库查询和操作性能的数据结构。
它就像是一本书的目录,通过索引,MySQL 能够更快地定位和获取所需的数据,而不必遍历整个数据表。
所以索引能够显著提高数据库的查询速度,可能让速度提升数百甚至数千倍,只需执行正确的 create index 操作,无需对内存、程序或 SQL 语句进行大的改动。
同时也强调了索引并非毫无代价。虽然能加快查询,但会降低插入、更新和删除操作的速度,因为这些写操作会产生大量的 I/O 开销。这意味着在使用索引时需要权衡查询性能和写操作性能之间的平衡。
关于常见索引的分类:
主键索引(primary key):用于唯一标识表中的每一行记录,确保其值的唯一性和非空性。例如,在学生表中,学号可以作为主键索引。
唯一索引(unique):确保某一列的值不重复,但允许为 NULL。比如,在用户表中,身份证号可以设置为唯一索引。
普通索引(index):用于加快数据的查询速度,但不保证列值的唯一性。比如,在商品表中,商品名称可以创建普通索引。
全文索引(fulltext):主要用于解决中文文本的索引问题,能够高效地在大量文本数据中进行搜索。例如,在文章表中,文章内容可以创建全文索引来快速搜索特定的关键词或短语。
4.1 索引测试
建立测试表:
mysql> create table if not exists user (-> id int primary key,-> age int not null,-> name varchar(16) not null-> );
Query OK, 0 rows affected (0.01 sec)

插入多条记录:
mysql> insert into user (id, age, name) values(3, 18, '杨过');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(4, 16, '小龙女');
Query OK, 1 row affected (0.00 sec)mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(5, 36, '郭靖');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
Query OK, 1 row affected (0.00 sec)

查看插入结果:
mysql> select * from user;

我们会发现排序竟然默认是有序的。
4.2 Page
单个Page:
MySQL 中要管理很多数据表文件,而要管理好这些文件,就需要 先描述,在组织 ,我们目前可以简单理解成一个个独立文件是有一个或者多个Page构成的。
不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表。
因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看出,数据是有序且彼此关联的。

多个Page:
在上面页模式中,只有一个功能,就是在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,我们也可以看到,现在的页模式内部,实际上是采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
如果有1千万条数据,一定需要多个Page来保存1千万条数据,多个Page彼此使用双链表链接起来,而且每个Page内部的数据也是基于链表的。那么,查找特定一条记录,也一定是线性查找。这效率也太低了。

4.3 单页和多页情况
单页情况:
针对上面的单页Page,我们能否也引入目录呢?当然可以。
那么当前,在一个Page内部,我们引入了目录。比如,我们要查找id=4记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录2[3],直接进行定位新的起始位置,提高了效率。现在我们可以再次正式回答上面的问题了,为何通过键值 MySQL 会自动排序?可以很方便引入目录。

多页情况:
MySQL 中每一页的大小只有 16KB ,单个Page大小固定,所以随着数据量不断增大, 16KB 不可能存下所有的数据,那么必定会有多个页来存储数据。
在单表数据不断被插入的情况下, MySQL 会在容量不足的时候,自动开辟新的Page来保存新的数据,然后通过指针的方式,将所有的Page组织起来。
其实目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址。

… …
相关文章:
【MySQL】索引——索引的引入、认识磁盘、磁盘的组成、扇区、磁盘访问、磁盘和MySQL交互、索引的概念
文章目录 MySQL1. 索引的引入2. 认识磁盘2.1 磁盘的组成2.2 扇区2.3 磁盘访问 3. 磁盘和MySQL交互4. 索引的概念4.1 索引测试4.2 Page4.3 单页和多页情况 MySQL 1. 索引的引入 海量表在进行普通查询的时候,效率会非常的慢,但是索引可以解决这个问题。 -…...

python部署flask项目
python部署flask项目 1. 准备服务器2. 设置服务器环境3. 创建虚拟环境并安装项目依赖4. 配置Gunicorn5. 配置Nginx6. 设置Supervisor(可选)7. 测试部署 将Flask项目部署到服务器的流程大致如下: 1. 准备服务器 首先,需要准备一台…...

数据建模标准-基于事实建模
前情提要 数据模型定义 DAMA数据治理体系中将数据模型定义为一种文档形式,数据模型是用来将数据需求从业务传递到IT,以及在IT内部从分析师、建模师和架构师到数据库设计人员和开发人员的主要媒介; 作用 记录数据需求和建模过程中产生的数据定义&…...
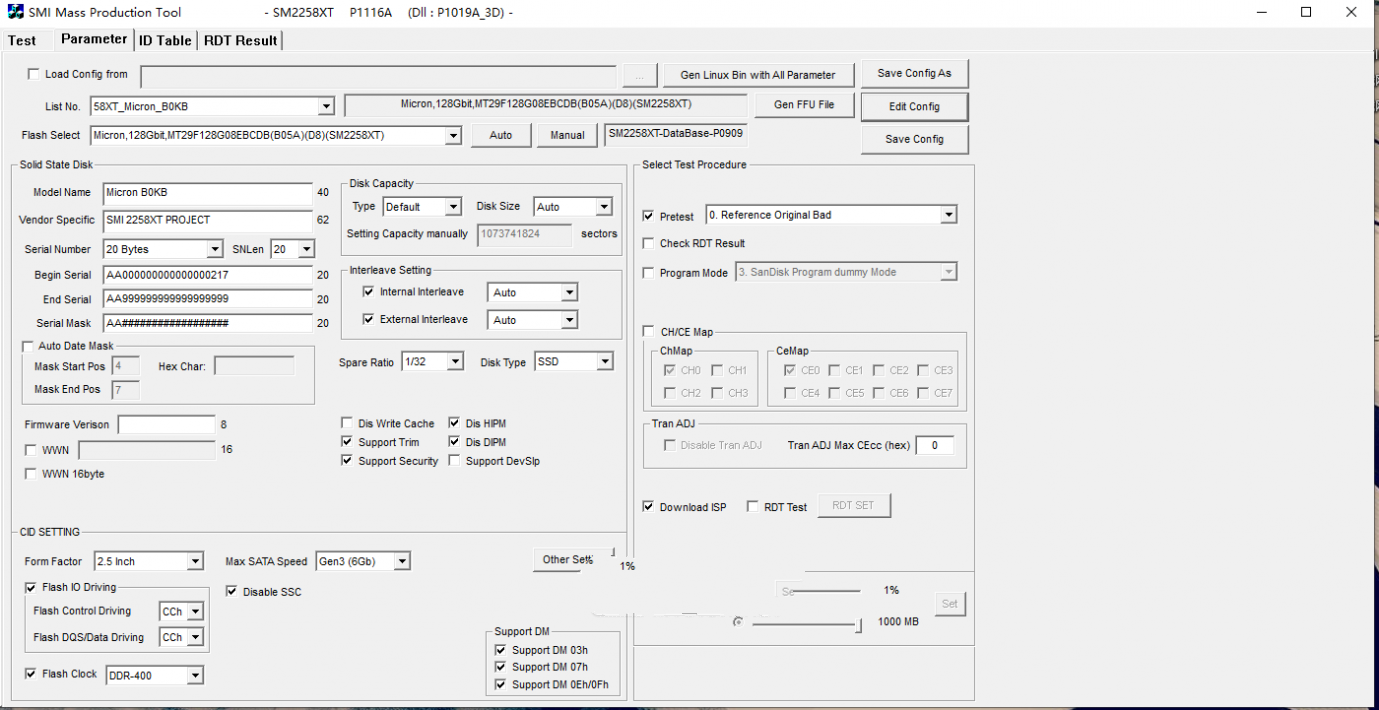
量产部落SM2258XT开卡软件,SM2258XT主控128G SSD固态卡死修复
故障现象:连接此固态硬盘后电脑就会卡死,拔掉重新连接概率性显示盘符,显示了之后也不能正常操作,一点击打开,电脑就立马卡死。 解决过程:下载了很多款量产工具,都不能开卡成功,点击…...
《零散知识点 · 自定义 HandleMapping》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数…...

谈谈我对微服务的理解2.0
文章目录 一、引出问题二、微服务2-1、微服务的技术2-2、微服务的目的 三、微服务的拆分四、不连表查询五、微服务的好处六、微服务的坏处七、应付当下 这篇文章原本叫《如何做到不连表查询》,因为我对这个事一直耿耿于怀。在上家公司我经常被连表折磨(连…...

ECCV 2024前沿科技速递:GLARE-基于生成潜在特征的码本检索点亮低光世界,低光环境也能拍出明亮大片!
在计算机视觉与图像处理领域,低光照条件下的图像增强一直是一个极具挑战性的难题。暗淡的光线不仅限制了图像的细节表现,还常常引入噪声和失真,极大地影响了图像的质量和可用性。然而,随着ECCV 2024(欧洲计算机视觉会议…...

前端低代码必备:FrontendBlocks 4.0版本重磅发布,助力Uniapp-X原生APP开发
项目介绍 本软件是一款强大的所见即所得前端页面设计器,是低代码开发领域的基础设施,生成的代码不依赖于任何框架,实测可以将前端布局工作的耗时减少80%以上,最关键的是,它实现了人人都可以写前端页面的梦想。 不用写…...

如何将PyCharm 中使用 PDM 管理的 Django 项目迁移到 VS Code 并确保一切正常工作?
嗨,我是兰若姐姐,相信很多小伙伴都遇到过这种情况,使用pycharm用习惯了,想换个编辑器,比如换成vscode,今天就告诉大家,如果轻松切换到vscode 步骤 1:在 VS Code 中打开项目 打开 V…...

认识Android Handler
“Android Handler” 通常指的是 Android 开发中的 Handler 类,它是 Android SDK 的一部分,用于管理消息队列和线程之间的通信。它在 Android 开发中非常有用,特别是在计划消息和可运行对象(Runnables)在未来某个时间点…...

如何在 Ubuntu VPS 上安装 Cassandra 并运行单节点集群
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 介绍 Cassandra,或者说 Apache Cassandra,是一个高度可扩展的开源数据库系统,在多节点设置上能够实…...

Golang | Leetcode Golang题解之第316题去除重复字母
题目: 题解: func removeDuplicateLetters(s string) string {left : [26]int{}for _, ch : range s {left[ch-a]}stack : []byte{}inStack : [26]bool{}for i : range s {ch : s[i]if !inStack[ch-a] {for len(stack) > 0 && ch < stack…...

pxe的实验
首先搭好实验环境、 如果没有安装好图形,则需要用yum groups list找到有“GUI”的然后用yum groups " " 把含有GUI的复制到双引号里安装 然后再执行init 5 打开图形 Kickstart 如果dnf用不了改成yum 然后在用yum install httpd -y 安装好http的软件 之后…...

复杂智能软件系统开发
软件开发技术总是伴随着计算技术的时代问题向前发展,随着智能计算时代的到来,软件界需要回应智能软件开发的问题。 大型机时代,软件开发的主要问题是软件开发的效率和质量问题,用机器指令或汇编语言编写软件,效率低、质量差。随着高级程序设计语言的出现及其自动编译技术…...
kickstart自动安装脚本
当安装Linux操作系统时,安装过程会需要回答很多关于设定的问题 这些问题必须手动选择,否则无法进行安装。当只安装1台Linux系统,手动选择设定工作量比较轻松,当安装多台Linux,这些设定需要重复多次,这些重复…...

linux运维一天一个shell命令之grep详解
一、概念 grep 是 Linux 和 Unix 系统中一个非常常用的命令行工具,用于搜索文本文件中的特定模式。它支持正则表达式,并能在文件中快速查找匹配的行 二、正则表达式 1.概念 正则表达式(Regular Expressions,简称 regex 或 reg…...

COMSOL金属氢化物-放氢过程
在此记录下放氢过程的软件设置思路 1、采用的是"达西定律""层流" 物理场,其中"层流"物理场选择了”弱可压缩流动“,这里主要是选择”可压缩流动“的话,算出来的瞬时流量值跟实测差距太大了。 2、设置"达西…...
软件性能测试)
(四)软件性能测试
1. 性能测试包含的方法有哪些(至少列举5种)? 正确回答通过率:69.0%[ 详情 ] 推荐指数: ★★★★★ 试题难度: 中级 性能测试大致分为以下六类 1、验收性能测试: 通过模拟生产运行的业务压力量…...

萱仔大模型学习记录5-langchain实战
前面我的bertlora微调已经跑出了不错的结果,我也学会了如何在bert上使用Lora进行微调,我后续会补充一个医疗意图识别的项目于这个系列,现在这个医疗意图识别代码还暂时不准备公开。我就继续按照我的计划学习一番LangChain。 LangChain是一个用…...

安装使用netron
1.安装netron pip install netron2.使用以下命令,然后打开浏览器查看。 netron netron --host 0.0.0.0 --port 6780 netron "model_path" --host 0.0.0.0 --port 67803.在jupyterlab中使用 github有人推荐的方法,jupyterlab部署在本地的可以用…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...
软件工程 期末复习
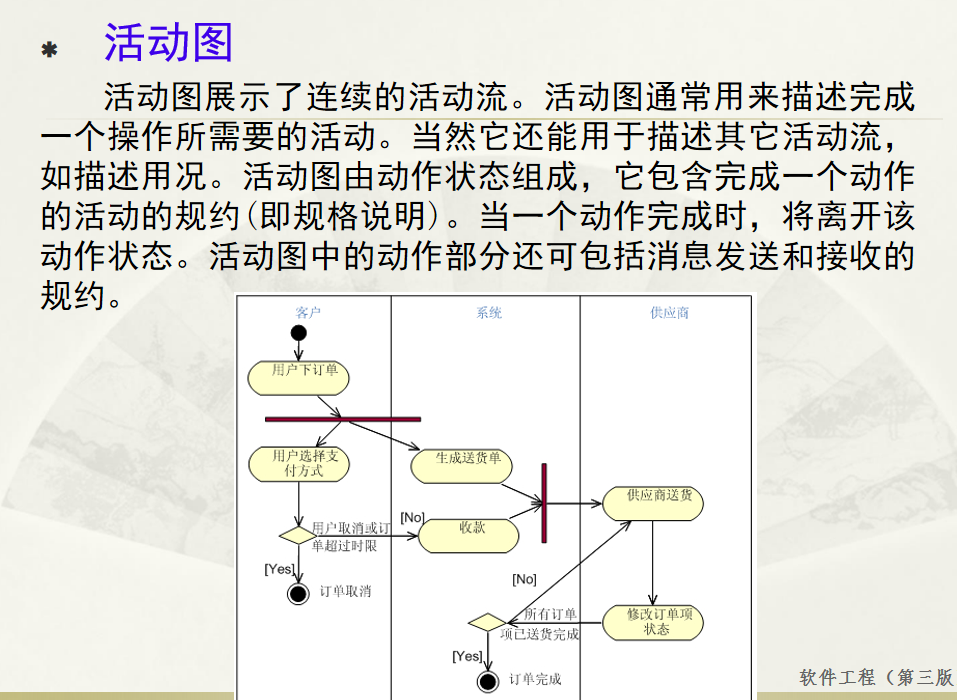
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...