【Spark计算引擎----第三篇(RDD)---《深入理解 RDD:依赖、Spark 流程、Shuffle 与缓存》】
前言:
💞💞大家好,我是书生♡,本阶段和大家一起分享和探索大数据技术Spark—RDD,本篇文章主要讲述了:RDD的依赖、Spark 流程、Shuffle 与缓存等等。欢迎大家一起探索讨论!!!
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
- 1. RDD缓存和checkpoint
- 1.1 缓存机制
- 1. 2 CheckPoint 机制
- 2. RDD依赖
- 2.1 窄依赖(Narrow Dependency)
- 2.2 宽依赖(Wide Dependency)
- 2.3 管理依赖
- 2.4 日志查看依赖关系和计算流程
- 2.5 划分stage
- 3.Spark的运行流程(内核调度)
- 4.spark的shuffle过程
- 4.1 shuffle介绍
- 4.2 Shuffle 的过程
- Shuffle 的影响
- 4.3 SparkShuffle配置
1. RDD缓存和checkpoint
在 Apache Spark 中,缓存(也称为持久化)和 checkpoint 是两种用于优化性能和容错的重要机制。这两种机制可以帮助减少重复计算,提高应用程序的效率。
RDD的缓存和checkpoint机制也是spark计算速度快的原因之一

1.1 缓存机制
定义:
缓存是一种将 RDD 的计算结果存储在内存或磁盘上的机制。通过缓存,Spark 可以避免重新计算已经处理过的数据,从而显著提高应用程序的性能。
- 缓存是将RDD存储到内存上或者是本地磁盘上(Linux)
- 缓存是临时持久化操作

用途:
- 提高性能:对于需要多次访问的数据集,缓存可以避免重复计算,显著加快执行速度。
- 内存管理:可以根据可用内存和数据的重要性选择合适的存储级别。
- 保证RDD容错性:应用程序运行过程中, 可能因为一些原因导致rdd计算失败需要重新计算
应用场景:
- 计算时间长的rdd
- 计算成本昂贵的RDD
- 重复多次使用的RDD
注意点
- 应用程序结束后会自动清空缓存RDD
- 缓存不会切断RDD之间的依赖关系(缓存的rdd有可能丢失, 丢失后还可以通过依赖关系计算得到)
- 缓存的RDD需要通过aciton算子触发缓存任务, 触发缓存任务后的RDD才是从缓存中获取的,触发缓存任务之前, 调用的rdd还是通过依赖关系计算得到的
- 缓存级别:缓存的RDD存储在哪里 默认存储在内存中, 也可以设置存储在内存和本地磁盘
persist只是定义了一个缓存任务,并不是执行- 使用
unpersist:释放缓存
API
- cache():默认将 RDD 存储在内存中,如果内存不足则溢出到磁盘。
- persist(storageLevel):允许指定不同的存储级别,如 MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY 等。
- is_cached :查看缓存状态,进行了缓存返回TRUE,反之返回False
- unpersist:释放缓存
缓存的级别:
缓存RDD默认存储在内存中
from pyspark.storagelevel import StorageLevel
- StorageLevel.DISK_ONLY # 将数据缓存到磁盘上
- StorageLevel.DISK_ONLY_2 #将数据缓存到磁盘上 保存两份
- StorageLevel.DISK_ONLY_3 # 将数据缓存到磁盘上 保存三份
- StorageLevel.MEMORY_ONLY # 将数据缓存到内存 默认
- StorageLevel.MEMORY_ONLY_2 #将数据缓存到内存 保存两份
- StorageLevel.MEMORY_AND_DISK # 将数据缓存到内存和磁盘 优先将数据缓存到内存上,内存不足可以缓存到磁盘
- StorageLevel.MEMORY_AND_DISK_2 # 将数据缓存到内存和磁盘
- StorageLevel.OFF_HEAP # 基本不使用 缓存在系统管理的内存上 jvm(内存)在系统上运行,系统内存
- StorageLevel.MEMORY_AND_DISK_ESER # 将数据缓存到内存和磁盘 序列化操作,按照二进制存储,节省空间
案例:
这个案例中我们对 rdd_cnt 这个RDD对象进行了缓存操作
rdd_cnt.persist(storageLevel=StorageLevel.MEMORY_ONLY)
# 创建SparkContext对象
sc = SparkContext()# 从HDFS读取文本文件
rdd_file = sc.textFile("/data/stu.csv")
# 读取文件后,对文件进行分割,得到每个学生的信息
rdd_stu = rdd_file.map(lambda x: x.split(","))
rdd_map = rdd_stu.map(lambda x: (x[0], int(x[1])))# 查看是否对rdd进行缓存操作, 返回True或False
print(rdd_map.is_cached)
# 统计不同年龄段的人数 0-30 为青年,30-60为中年,大于60为老年
rdd_age= rdd_map.map(lambda x: ('青年',1) if x[1]<30 else ('中年',1) if x[1]<=60 and x[1]>=30 else ('老年',1) )
rdd_cnt= rdd_age.reduceByKey(lambda x,y: x+y)# 对rdd_reducebykey进行缓存操作, 只是定义了一个缓存任务
# 如果实现对rdd进行缓存, 需要调用action算子触发缓存任务
# 触发缓存任务之前, 调用的当前rdd还是通过依赖关系计算得到的
rdd_cnt.persist(storageLevel=StorageLevel.MEMORY_ONLY)
# 查看是否对rdd进行缓存操作, 返回True或False
print(rdd_cnt.is_cached)# 手动释放
rdd_cnt.unpersist()
print(rdd_cnt.is_cached)print(rdd_cnt.collect())

内存限制:确保有足够的内存来缓存数据,否则可能会导致 OutOfMemoryError。
1. 2 CheckPoint 机制
定义
Checkpoint 是一种容错机制,用于将 RDD 的数据持久化到可靠的存储系统(如 HDFS、S3 等)。与缓存不同,Checkpoint 不仅用于提高性能,还可以在节点故障时恢复数据。
- checkpoint将RDD存储到HDFS(分块多副本)中
- checkpoint的RDD是不会随程序运行结果而被清空
- checkpoint会永久存储RDD, RDD之间的依赖关系会被删除
- checkpoint是永久持久化操作
用途
- 提高计算效率
- 容错:当 Spark 应用程序遇到故障时,可以从 Checkpoint 恢复数据,避免重新计算整个数据流。
- 减少依赖:通过 Checkpoint,可以减少计算依赖的深度,从而降低故障时需要重新计算的数据量。
注意
- 永久存储在HDFS上
- 程序运行结束不会被删除
- 会切断rdd之间的依赖关系
- 需要通过action算子触发checkpoint任务
API
- setCheckpointDir(path=):将 RDD 的数据持久化到指定的目录。
- rdd.checkpoint() :对RDD进行checkpoint操作
使用
checkpoint:将rdd存储在HDFS中使用:
- ①设置checkpoint目录路径 sc.setCheckpointDir()
- ②rdd.checkpoint()
案例:
"""
checkpoint:将rdd存储在HDFS中
使用:①设置checkpoint目录路径 sc.setCheckpointDir() ②rdd.checkpoint()
注意点:①永久存储在HDFS上 ②程序运行结束不会被删除 ③会切断rdd之间的依赖关系 ④需要通过action算子触发checkpoint任务
"""
# 统计不同词出现的次数 -> 分组聚合操作
from pyspark import SparkContext
# 导入缓存级别类
from pyspark import StorageLevel# 创建sc对象
sc = SparkContext()
# 设置checkpoint目录
sc.setCheckpointDir('/checkpoint')
# 读取hdfs文件数据,转换成rdd对象
rdd_words = sc.textFile('/data/words.txt')
rdd_flatmap = rdd_words.flatMap(lambda x: x.split(','))
rdd_map = rdd_flatmap.map(lambda x: (x, 1))
print(rdd_map.is_checkpointed)
rdd_reducebykey = rdd_map.reduceByKey(lambda x, y: x + y)
# 对rdd_reducebykey进行checkpoint操作, 只是定义了一个checkpoint任务
# 如果实现对rdd进行checkpoint, 需要调用action算子触发checkpoint任务
# 触发checkpoint任务之前, 调用的rdd还是通过依赖关系计算得到的
rdd_reducebykey.checkpoint()
# 查看是否对rdd进行checkpoint操作, 返回True或False
print(rdd_reducebykey.is_checkpointed)
# 根据词出现的次数进行降序操作
# rdd_reducebykey是通过依赖关系计算得到的, 不是从checkpoint中获取的
rdd_sortby = rdd_reducebykey.sortBy(lambda x: x[1], ascending=False)
print(rdd_sortby.collect())
# rdd_reducebykey是从checkpoint中获取的
rdd_sortby2 = rdd_reducebykey.sortBy(lambda x: x[1], ascending=True)
print(rdd_sortby2.collect())

注意事项
存储空间:确保 Checkpoint 目录有足够的存储空间。
性能开销:频繁地执行 Checkpoint 会增加额外的 I/O 开销。
2. RDD依赖
在 Apache Spark 中,弹性分布式数据集(Resilient Distributed Dataset, RDD)之间的依赖关系是 Spark 计算模型的核心部分。依赖关系决定了数据的处理顺序和粒度,同时也影响着 Spark 作业的执行效率和容错性。
-
定义:
- RDD 之间的依赖关系指的是一个 RDD 如何依赖于另一个 RDD 的数据。(相邻RDD之间存在的因果关系, 可以称为依赖关系)----》新RDD一定是由旧RDD计算得到, RDD1->RDD2->RDD3
- 这种依赖关系决定了数据流的方向和数据处理的顺序。
- RDD特性之一
- 依赖关系可以保证RDD计算的容错性, 如果rdd因为某些原因计算失败, 可以根据依赖关系重新计算
-
类型:
- 窄依赖(Narrow Dependency):每个父 RDD 分区最多被一个子 RDD 分区使用。
- 宽依赖(Wide Dependency):一个子 RDD 分区可能依赖于多个父 RDD 分区。
-
影响:
- 窄依赖:允许 Spark 在流水线中并行执行任务。
- 宽依赖:导致数据重分布,增加了计算成本。

2.1 窄依赖(Narrow Dependency)
-
定义:
- 窄依赖指的是父 RDD 的每个分区最多被一个子 RDD 分区使用。(一对一或者多对一关系)
- 窄依赖通常出现在
map、filter、union等操作中。
-
触发窄依赖关系的算子
- map()
- flatMap()
- filter()
- mapValues()
- mapPartitions()
-
特点:
- 窄依赖操作可以并行执行,因为它们不需要重新分布数据。
- 通常不会触发 shuffle 操作。


- 示例:
- 使用
map操作将每个元素乘以 2:rdd = sc.parallelize([1, 2, 3, 4, 5]) doubled_rdd = rdd.map(lambda x: x * 2)
- 使用
2.2 宽依赖(Wide Dependency)
-
定义:
- 宽依赖指的是一个子 RDD 分区可能依赖于多个父 RDD 分区。
- 宽依赖通常出现在
groupByKey、reduceByKey、join等操作中。
-
触发宽依赖关系的算子
- groupBy()
- groupByKey()
- reduceByKey()
- sortBy()
- sortByKey()
- distinct()
-
特点:
- 宽依赖操作需要触发 shuffle 操作,即数据需要在节点间进行重分布。
- 通常会导致较高的计算成本。
-
示例:
- 使用
reduceByKey对数据进行聚合:rdd = sc.parallelize([(1, 2), (1, 3), (2, 4)]) result = rdd.reduceByKey(lambda x, y: x + y)
- 使用
影响
-
计算效率:
- 窄依赖通常比宽依赖更高效,因为它们不需要 shuffle 数据。
- 宽依赖可能会导致更多的磁盘 I/O 和网络传输,从而降低性能。
-
容错性:
- RDD 的容错性是通过 lineage 信息来实现的。
- 当数据丢失时,Spark 可以根据依赖关系重新计算丢失的数据。
-
执行计划:
- Spark 的 DAGScheduler 会根据依赖关系构建执行计划。
- 宽依赖会导致新的 stage 的形成,而窄依赖则可以在同一个 stage 内执行。


示例
假设我们有一个简单的 RDD rdd1,并执行了一系列的操作来创建新的 RDD。
rdd1 = sc.parallelize([1, 2, 3, 4, 5])# 窄依赖
rdd2 = rdd1.map(lambda x: x * 2)# 宽依赖
rdd3 = rdd2.groupByKey()# 窄依赖
rdd4 = rdd3.flatMap(lambda x: x)# 宽依赖
rdd5 = rdd4.reduceByKey(lambda x, y: x + y)
在这个例子中,rdd2 和 rdd4 之间的依赖关系是窄依赖,而 rdd3 和 rdd5 之间的依赖关系是宽依赖。宽依赖操作(如 groupByKey 和 reduceByKey)会导致数据重分布,而窄依赖操作(如 map 和 flatMap)则不需要重分布数据。
2.3 管理依赖
通过DAG有向无环图图计算算法管理RDD之间的依赖关系

- DAG称为有向无环图(有方向没有闭环), 是图计算中的一种算法
- DAG有向无环图作用
- 管理RDD之间的依赖关系, 保证RDD按照依赖关系进行有序地计算
- 根据RDD之间的依赖关系对计算任务划分成多个计算步骤, 每个步骤称为stage阶段
- 触发宽依赖关系的算子会产生新的stage阶段
- 窄依赖关系的算子计算步骤是在同一个stage阶段进行

2.4 日志查看依赖关系和计算流程
- app spark应用程序
- appID 就是这个程序的ID
- APP Name 就是这个spark程序的名字(别名)

- job -> 计算任务(一个app中是可能有多个job), 执行action算子时才会产生job

- stage -> 计算步骤/阶段, DAG根据宽依赖关系划分成多个stage

- task -> task线程任务, 真正执行的计算任务,有多少个分区就有多个task线程任务
- stage -> 计算步骤/阶段, DAG根据宽依赖关系划分成多个stage

2.5 划分stage
怎么划分stage:DAG根据宽依赖关系划分成多个stage
为甚要划分成多个stage呢?
- spark的task任务是以线程方式实现多任务计算, 线程多任务会有一个资源抢夺问题, 导致计算不准确
- spark中同一个stage中的多个task任务是并行计算的, 下一个stage中的多个task任务要想并行计算, 需要等上一个stage计算步骤完成后才能并行计算
- 为什么要等待上一个stage计算完成?
- 宽依赖是会进行shuffle过程, 数据需要重新洗牌, 等待过程就是洗牌过程
- 如何划分stage?
- 查看rdd之间是否存在宽依赖关系
- 触发宽依赖关系的算子
- 通过日志查看DAG有向无环图‘
注意:在一个stage中,会有多个线程也就是多个task任务是并行计算,那么就会有资源竞争,有的任务执行快,有的任务执行慢,当执行快的任务执行完的时候,慢的任务刚刚执行了,一旦这个时候通过宽依赖进行计算就会出现数据缺失的的问题,因此划分成多个stage,让执行快的任务等慢的任务执行完之后一起一起执行宽依赖的算子计算,这样子数据就不会缺失了。

3.Spark的运行流程(内核调度)
Spark框架中封装了三个Scheduler类完成整个spark的计算过程
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
- DAGScheduler
- 根据rdd间的依赖关系,将提交的job划分成多个stage。
- 对每个stage中的task进行描述(task编号,task执行的rdd算子)
- TaskScheduler
- 获取DAGScheduler提交的task
- 调用SchedulerBackend获取executor的资源信息
- 给task分配资源,维护task和executor对应关系
- 管理task任务队列
- 将task给到SchedulerBackend,然后由SchedulerBackend分发对应的executor执行
- SchedulerBackend
- 向RM申请资源
- 获取executor信息
- 分发task任务

- 执行spark应用程序, 创建driver进程, driver进程调用三个scheduler类创建三个scheduler对象
- schedulerbackend向资源调度工具主服务申请计算资源, 创建executor进程
- 执行了action算子触发计算任务, DAGscheduler根据宽依赖关系划分stage, 同时分析stage中的task描述, 将taskSet提交给Taskscheduler
- Taskscheduler将计算资源分配给task, 同时维护task和executor之间关系, 管理task执行顺序, 将分配计算资源的task交给schedulerbackend
- schedulerbackend将task线程任务给到executor进程执行
4.spark的shuffle过程
4.1 shuffle介绍
在 Apache Spark 中,Shuffle 是一个关键的概念,它涉及到数据的重新分布,通常发生在宽依赖操作中,例如 groupByKey, reduceByKey, join 等。
mapreduce的shuffle作用: 将map计算后的数据传递给reduce使用
mapreduce的shuffle过程: 分区,排序,合并(规约)
-
Shuffle 的定义
Shuffle 是指在 Spark 中对数据进行重新分布的过程,通常涉及到将数据从一个节点移动到另一个节点。这个过程发生在宽依赖操作中,因为这些操作需要将具有相同 key 的数据聚集在一起,而这些数据可能最初分布在不同的节点上。 -
Shuffle 的原因
Shuffle 发生的主要原因是需要将数据重新分布到不同的分区中,以便进行聚合或连接等操作。例如,在groupByKey操作中,具有相同 key 的所有元素需要被聚集在一起以进行聚合计算。 -
作用:不同阶段的数据传递
-
无论是spark shuffle还是mapreduce shuffle,本质都是传递数据 -
spark的shuffle分成两个阶段
- map阶段: shuffle write, 将上一个stage的数据保存到磁盘文件中
- reduce阶段: shuffle read, 将磁盘文件中的数据保存到下一个stage中

spark的shuffle方法类:
是spark封装好的处理shuffle的方法
- hashshuffle
- spark1.2版本之前使用, 在spark2.0版本删除
- hash(key)%分区数=结果值…余数, 余数相同的数据放到一起
- 未优化的hashshuffle -> 有多少个buffer有多少个磁盘小文件
- 优化后的hashshuffle -> 有多少个分区有多少个磁盘小文件


- sortshuffle
- spark2.0/3.0版本使用的都是sortshuffle
- 普通模式 -> 使用排序方式将数据划分
- 将分区数据存储在5M大小的memory中, 从memory取1w条数据进行排序
- bypass模式
- 类似于优化后的hashshuffle
- hash(key)%分区数=结果值…余数, 余数相同的数据放到一起


无论是hash还是排序都是将相同key值放在一起处理
- [(‘a’,1),(‘b’,2),(‘a’,1)]
- hash(key)%分区数,相同的key数据余数是相同的,会放一起,交给同一个分区进行处理
- 按照key排序,相同key的数据也会放在一起 ,然后交给同一分区处理
4.2 Shuffle 的过程
Shuffle 的过程可以分为以下几个主要阶段:
-
Map 阶段:
- Map 阶段通常涉及对输入数据进行转换,例如应用
map或flatMap等操作。 - 在宽依赖操作中,数据会被标记为需要参与 shuffle。
- Map 阶段还会进行一些优化,例如将部分结果写入本地磁盘。
- Map 阶段通常涉及对输入数据进行转换,例如应用
-
Shuffle write:
- Map 阶段产生的数据会被写入本地磁盘上的 shuffle 文件。
- 每个 map 任务都会产生一个或多个 shuffle 文件,这些文件按 key 进行分区。
- Shuffle 文件通常会被压缩以节省存储空间和传输时间。
-
Shuffle read:
- 在 shuffle 读阶段,reduce 任务会从所有 map 任务产生的 shuffle 文件中读取数据。
- 读取数据时,reduce 任务会根据 key 去定位相应的 shuffle 文件,并从中读取数据。
- 数据可能需要在网络上传输,这取决于数据的存储位置。
-
Reduce 阶段:
- Reduce 阶段处理从 shuffle 文件中读取的数据。
- 对于每个 key,reduce 任务会执行相应的聚合或连接操作。
- 最终结果会被输出到内存或磁盘上。
Shuffle 的影响
Shuffle 过程可能会显著影响 Spark 应用程序的性能,因为它涉及到大量的磁盘 I/O 和网络传输。为了减少 shuffle 的影响,可以采取以下措施:
- 减少 shuffle 的数量:尽量使用窄依赖操作来减少 shuffle 的需求。
- 调整并行度:通过设置
spark.sql.shuffle.partitions来调整 shuffle 的并行度。 - 优化数据分布:确保数据在节点之间均匀分布,以减少数据倾斜。
- 启用压缩:通过启用 shuffle 文件的压缩来减少传输的数据量。
- 使用高效的序列化方式:例如使用 Kryo 序列化器来提高序列化和反序列化的效率。
示例
假设我们有一个简单的 RDD,我们想要使用 reduceByKey 来计算每个 key 的总和。
from pyspark import SparkContextsc = SparkContext("local", "Shuffle Example")# 创建一个 RDD
rdd = sc.parallelize([(1, 2), (1, 3), (2, 4)])# 使用 reduceByKey 进行聚合
result = rdd.reduceByKey(lambda x, y: x + y)print("Result:", result.collect())
在这个例子中,reduceByKey 操作会导致 shuffle,因为需要将具有相同 key 的元素聚集在一起。
4.3 SparkShuffle配置
spark.shuffle.file.buffer
参数说明:
该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小(默认是32K)。将数据写到磁盘文件之前会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。 2倍 3倍
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升
spark.reducer.maxSizeInFlight
参数说明:
该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。(默认48M)
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetriesandspark.shuffle.io.retryWai
spark.shuffle.io.maxRetries :
shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)
spark.shuffle.io.retryWait:
该参数代表了每次重试拉取数据的等待间隔。(默认为5s)
调优建议:一般的调优都是将重试次数调高,不调整时间间隔。
spark.shuffle.memoryFraction=10
参数说明:
该参数代表了Executor 1G内存中,分配给shuffle read task进行聚合操作内存比例。
spark.shuffle.manager
参数说明:该参数用于设置shufflemanager的类型(默认为sort)
Hash:spark1.x版本的默认值,HashShuffleManager
Sort:spark2.x版本的默认值,普通机制。当shuffle read task 的数量小于等于200采用bypass机制
spark.shuffle.sort.bypassMergeThreshold=200- 根据task数量决定sortshuffle的模式
- task数量小于等于200 就采用bypass task大于200就采用普通模式
参数说明:
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些
- 交互式开发中使用
pyspark --master yarn --name shuffle_demo --conf 'spark.shuffle.sort.bypassMergeThreshold=300'
通过--conf = ''来配置参数
- 脚本中配置参数
- 创建conf对象, 实现spark参数设置
- 对象名=类名()
- 调用set()返回对象本身
conf = (SparkConf().set('spark.shuffle.sort.bypassMergeThreshold', '300').set('spark.shuffle.io.maxRetries', '5'))
- 创建sc对象
- 传递conf对象
- sc = SparkContext(master=‘yarn’, appName=‘shuffle_demo’, conf=conf)
from pyspark import SparkContext
from pyspark import SparkConf# 创建conf对象, 实现spark参数设置
# 对象名=类名()
# 调用set()返回对象本身
conf = (SparkConf().set('spark.shuffle.sort.bypassMergeThreshold', '300').set('spark.shuffle.io.maxRetries', '5'))# 创建sc对象
# 传递conf对象
sc = SparkContext(master='yarn', appName='shuffle_demo', conf=conf)
# 读取hdfs文件数据,转换成rdd对象
rdd_words = sc.textFile('/data/words.txt')
print(rdd_words.take(num=3))
rdd_flatmap = rdd_words.flatMap(lambda x: x.split(','))
print(rdd_flatmap.collect())
rdd_map = rdd_flatmap.map(lambda x: (x, 1))
print(rdd_map.collect())
rdd_reducebykey = rdd_map.reduceByKey(lambda x, y: x + y)
print(rdd_reducebykey.collect())
# 根据词出现的次数进行降序操作
rdd_sortby = rdd_reducebykey.sortBy(lambda x: x[1], ascending=False)
print(rdd_sortby.collect())
查看历史服务,发现配置生效

相关文章:
【Spark计算引擎----第三篇(RDD)---《深入理解 RDD:依赖、Spark 流程、Shuffle 与缓存》】
前言: 💞💞大家好,我是书生♡,本阶段和大家一起分享和探索大数据技术Spark—RDD,本篇文章主要讲述了:RDD的依赖、Spark 流程、Shuffle 与缓存等等。欢迎大家一起探索讨论!࿰…...

四、日志收集loki+ promtail+grafana
一、简介 Loki是受Prometheus启发由Grafana Labs团队开源的水平可扩展,高度可用的多租户日志聚合系统。 开发语言: Google Go。它的设计具有很高的成本效益,并且易于操作。使用标签来作为索引,而不是对全文进行检索,也就是说&…...

xdma的linux驱动编译给arm使用(中断检测-测试程序)
1、驱动链接 XDMA驱动源码官网下载地址为:https://github.com/Xilinx/dma_ip_drivers 下载最新版本的XDMA驱动源码,即master版本,否则其驱动用不了(xdma ip核版本为4.1)。 2、驱动 此部分来源于博客:xd…...

探索之路——初识 Vue Router:构建单页面应用的完整指南
目录 1. Vue Router 简介 2. 安装与配置 Vue Router 安装步骤 配置路由 3. 在 Vue 应用中使用路由 4. 进阶使用 路由守卫 懒加载 高级路由技术 嵌套路由 动态路由匹配 编程式的路由导航 路由懒加载 路由元信息 在现代前端开发中,单页面应用(SPA)因其出…...

传输层_计算机网络
文章目录 运输层UDPTCPTCP连接管理TCP三次握手TCP四次挥手 可靠机制流量控制拥塞控制 QUIC 运输层 网络层提供了主机之间的逻辑通信 运输层为运行在不同主机上的进程之间提供了逻辑通信 UDP(用户数据报协议)提供一种不可靠、无连接的服务,数据报 TCP(传输控制协议)…...
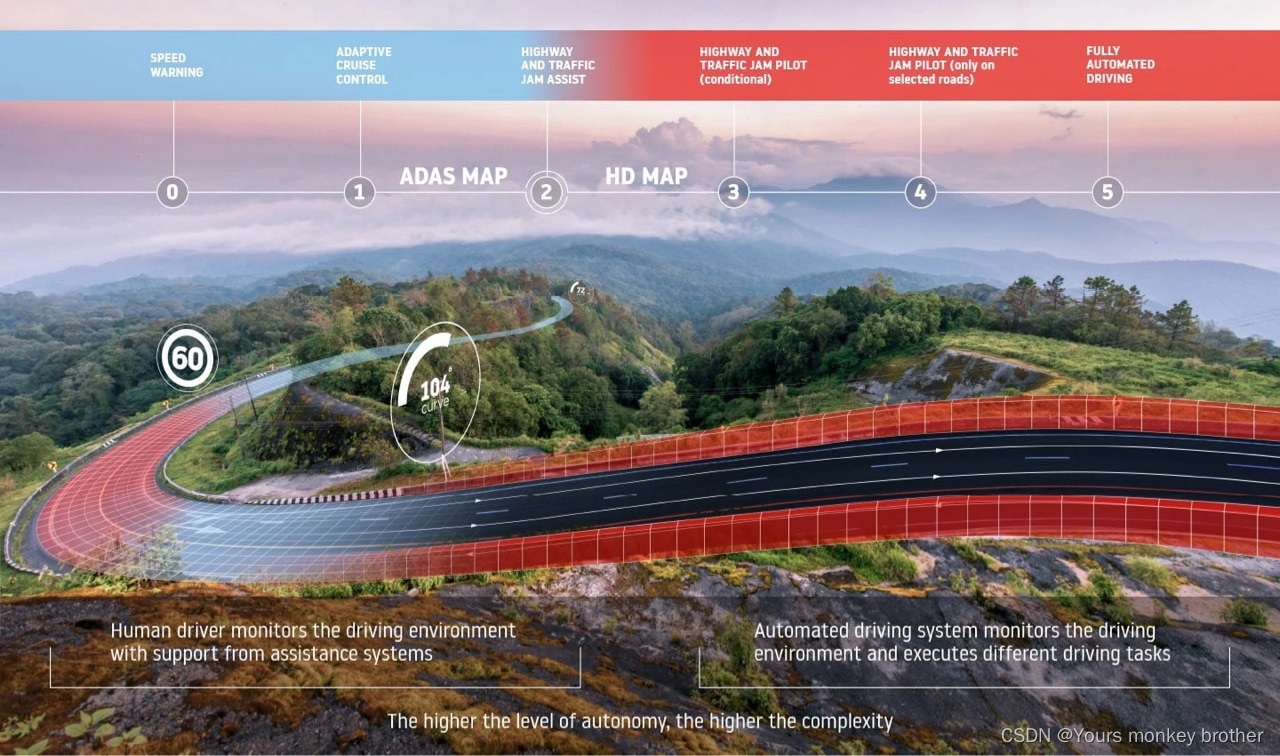
自动驾驶的六个级别是什么?
自动驾驶汽车和先进的驾驶辅助系统(ADAS)预计将帮助拯救全球数百万人的生命,消除拥堵,减少排放,并使我们能够在人而不是汽车周围重建城市。 自动驾驶的世界并不只由一个维度组成。从没有任何自动化到完整的自主体验&a…...

深度学习复盘与论文复现F
文章目录 1、Environment construction1.1 macos conda1.2 macos PyTorch1.3 iTerm settings1.4 install jupyter 2、beam search2.1 greedy search2.2 exhaustive search2.3 beam search 3、Attention score3.1 Masking softmax operation3.2 Additive attention3.3 Zoom dot …...

如何学习自动化测试工具!
要学习和掌握自动化测试工具的使用方法,可以按照以下步骤进行: 一、明确学习目标 首先,需要明确你想要学习哪种自动化测试工具。自动化测试工具种类繁多,包括但不限于Selenium、Appium、JMeter、Postman、Robot Framework等&…...

短信接口被恶意盗刷
短信接口被恶意盗刷是指攻击者通过各种手段,大量发送短信请求,导致短信资源被浪费,服务提供商可能面临经济损失,正常用户的服务也可能受到影响。以下是一些可能导致短信接口被恶意盗刷的原因和相应的解决方案: 原因&a…...

实验4-2-1 求e的近似值
//实验4-2-1 求e的近似值 /* 自然常数 e 可以用级数 11/1!1/2!⋯1/n!⋯ 来近似计算。 本题要求对给定的非负整数 n,求该级数的前 n1 项和。 输入格式:输入第一行中给出非负整数 n(≤1000)。 输出格式:在一行中输出部分和的值,保留…...

内网穿透--LCX+portmap转发实验
实验背景 通过公司带有防火墙功能的路由器接入互联网,然后由于私网IP的缘故,公网 无法直接访问内部web服务器主机,通过内网其它主机做代理,穿透访问内网web 服务器主机 实验设备 1. 路由器、交换机各一台 2. 外网 kali 一台&…...

缓存一致性问题
1. 引言 1.1 数据库与缓存的工程实践 在软件工程领域,数据库(Database)和缓存(Cache)是两种常见的数据存储解决方案,它们在系统架构中扮演着至关重要的角色。数据库是数据持久化的后端存储,它…...

【MYSQL】MYSQL逻辑架构
mysql逻辑架构分为3层 mysql逻辑架构分为3层 1). 连接层:主要完成一些类似连接处理,授权认证及相关的安全方案。 2). 服务层:在 MySQL据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断,SQL接口&…...

【Python】数据类型之字符串
本篇文章将继续讲解字符串其他功能: 1、求字符串长度 功能:len(str) ,该功能是求字符串str的长度。 代码演示: 2、通过索引获取字符串的字符。 功能:str[a] str为字符串,a为整型。该功能是获取字符…...

c++编写java模式的线程类
在 C11 中,我们可以使用 <thread> 标准库来创建和管理线程。然而,C 不像 Java 那样提供一个内置的 Thread 类,而是提供了一个更底层的 API。下面是一个模拟 Java 中 Thread 类功能的 C11 实现。 我们将创建一个名为 SimpleThread 的类…...

vcpkg install libtorch[cuda] -allow-unsupported-compiler
在vcpkg中不懂如何使用 nvcc 的 -allow-unsupported-compiler, 所以直接注释了CUDA中对版本的检查代码. C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include\crt\host_config.h 奇了怪了,我是用的是vs2022,但是还是被检查为不支持的编译器!!! 可以试一下改这…...

Flink的DateStream API中的ProcessWindowFunction和AllWindowFunction两种用于窗口处理的函数接口的区别
目录 ProcessWindowFunction AllWindowFunction 具体区别 ProcessWindowFunction 示例 AllWindowFunction 示例 获取时间不同,一个数据产生的时间一个是数据处理的时间 ProcessWindowFunction AllWindowFunction 具体示例 ProcessWindowFunction 示例 Al…...

MATLAB中dmperm函数用法
目录 语法 说明 dmperm函数的功能是完成Dulmage-Mendelsohn 分解。 语法 p dmperm(A) [p,q,r,s,cc,rr] dmperm(A) 说明 如果列 j 与行 i 匹配,p dmperm(A) 得到的结果为向量 p,这样 p(j) i,如果列 j 与其不匹配,得到的结…...

苹果折叠屏设备:创新设计与技术突破
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 苹果折叠屏设备:创新设计与技术突破 在科技迅速发展的今天,苹果公司以其一贯的创新精神和对产品质量的严格把控&#x…...

C#加班统计次数
C#加班统计次数 运行环境:vs2022 .net 8.0 社区版 1、用C#语言;2、有界面上传Excel文件; 3、对Excel列(部门、人员姓名、人员编号、考勤时间 )处理:(1)按人员编号、考勤日期分组且保留原来字段&…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...
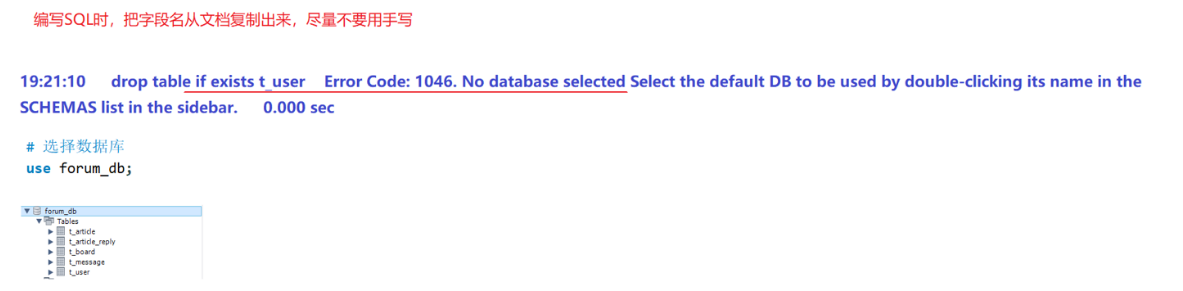
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...
Centos 7 服务器部署多网站
一、准备工作 安装 Apache bash sudo yum install httpd -y sudo systemctl start httpd sudo systemctl enable httpd创建网站目录 假设部署 2 个网站,目录结构如下: bash sudo mkdir -p /var/www/site1/html sudo mkdir -p /var/www/site2/html添加测试…...