缓存一致性问题
1. 引言
1.1 数据库与缓存的工程实践
在软件工程领域,数据库(Database)和缓存(Cache)是两种常见的数据存储解决方案,它们在系统架构中扮演着至关重要的角色。数据库是数据持久化的后端存储,它提供了数据的长期存储、复杂查询和事务性支持。而缓存则是一种位于数据库和应用程序之间的临时存储,它通过存储频繁访问的数据来减少对数据库的直接访问次数,从而提高系统的性能。
数据库的特点:
-
持久性:数据长期存储,即使系统崩溃也能恢复数据。
-
稳定性:成熟的事务支持,确保数据的一致性和完整性。
-
容量:通常具有较大的存储容量。
缓存的特点:
-
速度:读写速度快,能够快速响应数据请求。
-
容量:相对数据库来说,存储容量较小。
-
成本:访问延迟低,成本相对较高。
在高并发的环境下,合理利用缓存可以显著提升数据访问速度,减轻数据库的负担。
1.2 缓存一致性问题的提出
尽管缓存可以提高性能,但它也带来了新的挑战——缓存一致性问题。当数据库中的数据更新后,如何确保缓存中的数据也同步更新,避免用户读取到过时的数据,是缓存一致性问题的核心。
缓存一致性可以分为三个层次:
-
强一致性:缓存和数据库中的数据始终保持一致。
-
最终一致性:缓存和数据库中的数据在一定时间内可能不一致,但最终会达到一致状态。
-
弱一致性:不保证缓存和数据库中的数据一致性,数据的更新可能会延迟。
在实际应用中,强一致性虽然理想,但实现成本较高,而最终一致性和弱一致性虽然实现成本较低,但可能会影响用户体验。
结语
在本节中,我们探讨了数据库和缓存在工程实践中的应用,以及缓存一致性问题的重要性。理解这些基本概念对于后续深入分析缓存一致性问题和解决方案至关重要。在接下来的章节中,我们将详细分析缓存一致性问题,并探讨不同的解决方案。
-
理论分析
2.1 缓存一致性问题
缓存一致性问题是指在分布式系统中,缓存数据与数据库数据之间的同步问题。当数据库中的数据被更新或删除后,如何保证缓存中的数据也相应地更新或删除,以避免用户读取到过时的数据。
问题背景:
-
在一个高并发的系统中,数据库的压力非常大,使用缓存可以显著减轻这种压力。
-
缓存通常存储热点数据,即那些被频繁访问的数据。
-
缓存和数据库是两个独立的存储系统,它们之间的数据同步需要额外的机制来保证。
问题难点:
-
并发控制:在多线程或多进程环境中,如何保证数据操作的原子性和一致性。
-
数据同步延迟:缓存和数据库之间的数据同步可能会有延迟,这可能导致数据不一致。
-
系统复杂性:引入缓存一致性机制会增加系统的复杂性,可能会影响性能。
2.2 读写流程串讲
读写流程是缓存一致性问题中的核心概念。下面详细分析读写流程中的各个步骤:
写流程
-
写入数据库:当数据更新请求到达时,首先将数据写入数据库。
-
清除缓存:在数据写入数据库后,需要清除缓存中对应的数据项,以避免读操作读取到旧数据。
读流程
-
查询缓存:当数据读取请求到达时,首先查询缓存是否有该数据。
-
缓存未命中:如果缓存中没有数据(Cache Miss),则查询数据库。
-
更新缓存:从数据库中读取数据后,将其写入缓存,以便下次可以直接从缓存中读取。
流程图:

2.3 缓存双删策略
缓存双删策略是一种解决缓存一致性问题的策略。在写流程中,不是只清除一次缓存,而是进行两次清除操作:
-
第一次清除:在数据写入数据库之前,先清除缓存中的数据。
-
写入数据库:执行数据的写入操作。
-
第二次清除:在数据写入数据库之后,再次清除缓存中的数据。
这种策略可以减少在写操作和第一次清除缓存之间的时间窗口,降低读操作读取到旧数据的风险。
流程图:

2.4 缓存延时双删策略
缓存延时双删策略是对双删策略的改进,它在第二次清除缓存之前增加了一个延时:
-
第一次清除:在数据写入数据库之前,先清除缓存中的数据。
-
写入数据库:执行数据的写入操作。
-
延时:在写入数据库后,等待一段预设的时间。
-
第二次清除:延时结束后,再次清除缓存中的数据。
这种策略可以进一步减少读操作在写操作和第一次清除缓存之间的时间窗口内读取到旧数据的风险。
流程图:

2.5 写缓存禁用机制
写缓存禁用机制是一种更为激进的策略,它在写操作期间暂时禁用缓存的写入:
-
禁用写入:在数据写入数据库之前,禁用缓存的写入功能。
-
写入数据库:执行数据的写入操作。
-
等待确认:等待数据库操作确认完成。
-
启用写入:数据库操作完成后,重新启用缓存的写入功能。
这种策略可以确保在写操作期间,缓存不会被更新,从而避免了缓存和数据库之间的数据不一致问题。
流程图:

结语
在本节中,我们深入分析了缓存一致性问题,并探讨了几种常见的解决方案,包括缓存双删策略、缓存延时双删策略和写缓存禁用机制。这些策略各有优势和适用场景,选择合适的策略需要根据具体的业务需求和系统特点来决定。在实际应用中,可能需要结合多种策略来达到最佳的缓存一致性效果。在下一节中,我们将通过技术实战来进一步展示这些策略的具体实现。
-
技术实战
在本节中,我们将深入探讨一致性缓存服务的实现,包括架构设计、缓存模块、数据库模块以及服务层的具体实现。我们将通过代码示例和图表来详细展示如何构建一个高效的缓存系统。
3.1 架构设计
首先,我们需要设计一个清晰的架构,以支持缓存和数据库之间的一致性操作。架构的核心组件包括:
-
一致性缓存服务(Service):作为系统的核心,负责协调缓存和数据库的操作,确保数据的一致性。
-
缓存模块(Cache):负责缓存数据的存储和检索,以及与缓存相关的一致性操作。
-
数据库模块(DB):负责数据库的交互,包括数据的持久化和查询。
架构图:

3.2 缓存模块实现
缓存模块是实现数据快速访问的关键。以下是缓存模块需要实现的核心功能:
-
Get:从缓存中获取数据,如果数据不存在(Cache Miss),返回特定的错误。
-
Del:从缓存中删除指定的数据。
-
Disable:禁用特定数据的缓存写入机制,通常用于写操作期间。
-
Enable:延时启用特定数据的缓存写入机制,确保数据的一致性。
-
PutWhenEnable:当缓存写入机制启用时,将数据写入缓存。
缓存模块的伪代码示例:
type Cache interface {Get(key string) (string, error)Del(key string) errorDisable(key string, expireSeconds int64) errorEnable(key string, delaySeconds int64) errorPutWhenEnable(key, value string, expireSeconds int64) error
}3.3 数据库模块实现
数据库模块负责与数据库的交互,以下是数据库模块需要实现的核心功能:
-
Put:将数据写入或更新到数据库。
-
Get:从数据库中读取数据,如果数据不存在,返回特定的错误。
数据库模块的伪代码示例:
type DB interface {Put(ctx context.Context, obj interface{}) errorGet(ctx context.Context, objPtr interface{}) error
}3.4 一致性缓存服务Service实现
服务层是缓存模块和数据库模块的协调者,它实现了数据的读写操作,并确保了缓存和数据库之间的一致性。以下是服务层的核心实现逻辑:
-
写操作:先在数据库中写入数据,然后根据策略禁用或延时禁用缓存写入机制。
-
读操作:先尝试从缓存中读取数据,如果缓存未命中,则从数据库中读取并更新到缓存。
服务层的伪代码示例:
type Service struct {cache Cachedb DBopts *options
}
func (s *Service) Write(ctx context.Context, key string, value string) error {// 写入数据库err := s.db.Put(ctx, value)if err != nil {return err}// 根据策略禁用或延时禁用缓存写入if s.opts.DisableCacheWrite {return s.cache.Disable(key, s.opts.DisableCacheWriteDuration)} else {return s.cache.Enable(key, s.opts.CacheWriteDelayDuration)}
}
func (s *Service) Read(ctx context.Context, key string, objPtr interface{}) error {value, err := s.cache.Get(key)if err == nil {// 缓存命中,直接返回数据return nil} else if err != s.cache.ErrorCacheMiss {// 缓存错误,返回错误return err}// 缓存未命中,从数据库中读取err = s.db.Get(ctx, objPtr)if err != nil {return err}// 更新到缓存return s.cache.PutWhenEnable(key, value, s.opts.CacheExpiration)
}结语
在本节中,我们详细介绍了一致性缓存服务的架构设计和核心组件的实现。通过分离缓存模块和数据库模块,我们能够清晰地管理数据的读写操作,并确保缓存和数据库之间的一致性。在下一节中,我们将通过具体的代码示例和案例分析,进一步展示这些概念在实际开发中的应用。
-
缓存一致性问题的深入分析与策略
在本节中,我们将深入分析缓存一致性问题,并探讨不同的解决策略。我们将详细讨论每种策略的工作原理、优缺点,并通过图表和代码示例来展示如何在实际系统中应用这些策略。
4.1 缓存一致性问题的根源
缓存一致性问题主要源于缓存和数据库之间的数据同步问题。当数据库中的数据更新时,如果缓存中的数据没有同步更新,就可能导致用户读取到过时的数据。这种情况在高并发系统中尤为常见,因为多个请求可能同时修改和读取同一数据项。
4.2 缓存一致性策略
4.2.1 缓存失效策略(Cache Invalidation)
工作原理:当数据库中的数据更新或删除时,立即或在很短的时间内使缓存中对应的数据项失效。
优点:
-
简单直接,易于实现。
-
可以保证数据的强一致性。
缺点:
-
可能会因为频繁的失效操作导致缓存的利用率降低。
-
在高并发情况下,可能会引起缓存雪崩现象。
4.2.2 缓存双删策略(Double Cache Eviction)
工作原理:在更新数据库前先删除缓存中的数据,待数据库更新完成后再次删除缓存中的数据。
优点:
-
减少了缓存中保留过时数据的时间窗口。
缺点:
-
两次删除操作之间仍然存在时间窗口,可能无法完全避免数据不一致。
4.2.3 缓存延时双删策略(Delayed Double Cache Eviction)
工作原理:在数据库更新后,不是立即进行第二次删除缓存操作,而是等待一段预设的时间。
优点:
-
进一步减少了数据不一致的风险。
缺点:
-
增加了实现的复杂性。
-
需要合理设置延时时间,以平衡性能和一致性。
4.2.4 写缓存禁用机制(Write-Through Cache Disable)
工作原理:在数据写入数据库的过程中,暂时禁用缓存的写入操作。
优点:
-
确保了写操作期间缓存不会被更新,从而避免了数据不一致。
缺点:
-
写操作期间缓存的写入性能受到影响。
4.2.5 缓存穿透和雪崩解决方案
缓存穿透:指查询不存在的数据,导致请求直接打到数据库上。
解决方案:
-
使用布隆过滤器来快速判断数据是否存在。
-
缓存空结果或使用特殊标记。
缓存雪崩:指大量缓存数据在同一时间过期,导致大量请求直接打到数据库上。
解决方案:
-
为缓存数据设置随机过期时间。
-
使用分布式锁或其他同步机制来控制缓存重建。
4.3 策略选择与应用
选择缓存一致性策略时,需要考虑以下因素:
-
业务需求:是否需要强一致性或最终一致性。
-
系统负载:高并发情况下的系统表现。
-
实现复杂性:策略的实现难度和对现有系统的影响。
4.4 实例分析
我们将通过一个具体的示例来展示如何在实际系统中应用上述策略。假设我们有一个电子商务平台,需要处理商品信息的缓存和数据库同步。
示例场景:
-
商品信息更新操作。
-
商品信息读取操作。
代码示例:
// 商品信息更新操作
func UpdateProduct(ctx context.Context, service *Service, key string, product *Product) error {// 禁用缓存写入err := service.cache.Disable(key, service.opts.WriteDisableDuration)if err != nil {return err}// 更新数据库err = service.db.Put(ctx, product)if err != nil {return err}// 延时启用缓存写入return service.cache.Enable(key, service.opts.WriteEnableDelay)
}
// 商品信息读取操作
func GetProduct(ctx context.Context, service *Service, key string) (*Product, error) {product, err := service.cache.Get(key)if err == nil {return product, nil}// 缓存未命中,从数据库中读取product = &Product{}err = service.db.Get(ctx, product)if err != nil {return nil, err}// 更新到缓存return product, service.cache.PutWhenEnable(key, product, service.opts.CacheExpiration)
}结语
在本节中,我们深入分析了缓存一致性问题,并探讨了多种解决策略。我们讨论了每种策略的工作原理、优缺点,并提供了如何在实际系统中应用这些策略的示例。缓存一致性是一个复杂的问题,需要根据具体的业务需求和系统特点来选择合适的策略。在下一节中,我们将通过一个开源项目来进一步展示这些策略的具体实现和应用效果。
相关文章:
缓存一致性问题
1. 引言 1.1 数据库与缓存的工程实践 在软件工程领域,数据库(Database)和缓存(Cache)是两种常见的数据存储解决方案,它们在系统架构中扮演着至关重要的角色。数据库是数据持久化的后端存储,它…...

【MYSQL】MYSQL逻辑架构
mysql逻辑架构分为3层 mysql逻辑架构分为3层 1). 连接层:主要完成一些类似连接处理,授权认证及相关的安全方案。 2). 服务层:在 MySQL据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断,SQL接口&…...

【Python】数据类型之字符串
本篇文章将继续讲解字符串其他功能: 1、求字符串长度 功能:len(str) ,该功能是求字符串str的长度。 代码演示: 2、通过索引获取字符串的字符。 功能:str[a] str为字符串,a为整型。该功能是获取字符…...

c++编写java模式的线程类
在 C11 中,我们可以使用 <thread> 标准库来创建和管理线程。然而,C 不像 Java 那样提供一个内置的 Thread 类,而是提供了一个更底层的 API。下面是一个模拟 Java 中 Thread 类功能的 C11 实现。 我们将创建一个名为 SimpleThread 的类…...

vcpkg install libtorch[cuda] -allow-unsupported-compiler
在vcpkg中不懂如何使用 nvcc 的 -allow-unsupported-compiler, 所以直接注释了CUDA中对版本的检查代码. C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\include\crt\host_config.h 奇了怪了,我是用的是vs2022,但是还是被检查为不支持的编译器!!! 可以试一下改这…...

Flink的DateStream API中的ProcessWindowFunction和AllWindowFunction两种用于窗口处理的函数接口的区别
目录 ProcessWindowFunction AllWindowFunction 具体区别 ProcessWindowFunction 示例 AllWindowFunction 示例 获取时间不同,一个数据产生的时间一个是数据处理的时间 ProcessWindowFunction AllWindowFunction 具体示例 ProcessWindowFunction 示例 Al…...

MATLAB中dmperm函数用法
目录 语法 说明 dmperm函数的功能是完成Dulmage-Mendelsohn 分解。 语法 p dmperm(A) [p,q,r,s,cc,rr] dmperm(A) 说明 如果列 j 与行 i 匹配,p dmperm(A) 得到的结果为向量 p,这样 p(j) i,如果列 j 与其不匹配,得到的结…...

苹果折叠屏设备:创新设计与技术突破
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 苹果折叠屏设备:创新设计与技术突破 在科技迅速发展的今天,苹果公司以其一贯的创新精神和对产品质量的严格把控&#x…...

C#加班统计次数
C#加班统计次数 运行环境:vs2022 .net 8.0 社区版 1、用C#语言;2、有界面上传Excel文件; 3、对Excel列(部门、人员姓名、人员编号、考勤时间 )处理:(1)按人员编号、考勤日期分组且保留原来字段&…...

【资治通鉴】“ 将欲取之、必先予之 “ 策略 ① ( 魏桓子 割让土地 | 资治通鉴原文分析 | 道德经、周书、吕氏春秋、六韬 中的相似策略 )
文章目录 一、" 将欲取之、必先予之 " 策略1、魏桓子 割让土地2、资治通鉴原文分析 二、" 将欲取之、必先予之 " 类似的原理1、将欲败之,必姑辅之;将欲取之,必姑与之 - 周书2、将欲歙之,必固张之,…...

Spring5 的日志学习
我们在使用 Spring5 的过程中会出现这样的现像,就是 Spring5 内部代码打印的日志和我们自己的业务代码打印日志使用的不是统一日志实现,尤其是在项目启动的时候,Spring5 的内部日志使用的是 log4j2,但是业务代码打印使用的可能是 …...

python爬虫实践
两个python程序的小实验(附带源码) 题目1 爬取http://www.gaosan.com/gaokao/196075.html 中国大学排名,并输出。提示:使用requests库获取页面的基本操作获取该页面,运用BeautifulSoup解析该页面绑定对象soup&#x…...

【前端面试】七、算法-数组展平
目录 1.判断数组 2.二维数组展平 3.多维数组展平 1.判断数组 // 判断数组console.log([].constructor Array);console.log( Array.isArray([]));console.log( [] instanceof Array);console.log(Object.prototype.toString.call([]) [object Array]); 2.二维数组展平 const…...

Laravel php框架与Yii php 框架的优缺点
Laravel和Yii都是流行的PHP框架,它们各自具有独特的优点和缺点。以下是对这两个框架优缺点的详细分析: Laravel PHP框架的优缺点 优点 1、设计思想先进:Laravel的设计思想非常先进,非常适合应用各种开发模式,如TDD&…...

使用 addRouteMiddleware 动态添加中间
title: 使用 addRouteMiddleware 动态添加中间 date: 2024/8/4 updated: 2024/8/4 author: cmdragon excerpt: 摘要:文章介绍了Nuxt3中addRouteMiddleware的使用方法,该功能允许开发者动态添加路由中间件,以实现诸如权限检查、动态重定向及…...

Zookeeper未授权访问漏洞
Zookeeper未授权访问漏洞 Zookeeper是分布式协同管理工具,常用来管理系统配置信息,提供分布式协同服务。Zookeeper的默认开放端口是 2181。Zookeeper安装部署之后默认情况下不需要任何身份验证,造成攻击者可以远程利用Zookeeper,…...

【JavaEE】定时器
目录 前言 什么是定时器 如何使用java中的定时器 实现计时器 实现MyTimeTask类 Time类中存储任务的数据结构 实现Timer中的schedule方法 实现MyTimer中的构造方法 处理构造方法中出现的线程安全问题 完整代码 考虑在限时等待wait中能否用sleep替换 能否用PriorityBlo…...

2024带你轻松玩转Parallels Desktop19虚拟机!让你在Mac电脑上运行Windows系统
大家好,今天我要给大家安利一款神奇的软件——Parallels Desktop 19虚拟机。这款软件不仅可以让你在Mac电脑上运行Windows系统,还能轻松切换两个操作系统之间的文件和应用程序,让你的工作效率翻倍! 让我来介绍一下Parallels Desk…...
以及非递归实现二分查找)
【算法】递归实现二分查找(优化)以及非递归实现二分查找
递归实现二分查找 思路分析 1.首先确定该数组中间的下标 mid (left right) / 2; 2.然后让需要查找的数 findVal 和 arr[mid] 比较 findVal > arr[mid],说明要查找的数在 arr[mid] 右边,需要向右递归findVal < arr[mid],说明要查…...

CDN 是什么?
CDN是一种分布式网络服务,通过将内容存储在分布式的服务器上,使用户可以从距离较近的服务器获取所需的内容,从而加速互联网上的内容传输。 就近访问:CDN 在全球范围内部署了多个服务器节点,用户的请求会被路由到距离最…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

从实验室到产业:IndexTTS 在六大核心场景的落地实践
一、内容创作:重构数字内容生产范式 在短视频创作领域,IndexTTS 的语音克隆技术彻底改变了配音流程。B 站 UP 主通过 5 秒参考音频即可克隆出郭老师音色,生成的 “各位吴彦祖们大家好” 语音相似度达 97%,单条视频播放量突破百万…...
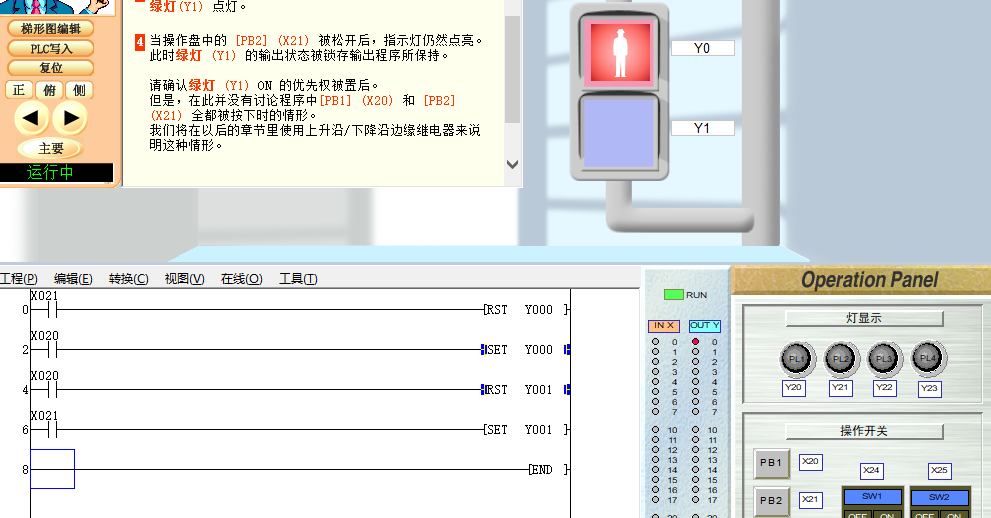
PLC入门【4】基本指令2(SET RST)
04 基本指令2 PLC编程第四课基本指令(2) 1、运用上接课所学的基本指令完成个简单的实例编程。 2、学习SET--置位指令 3、RST--复位指令 打开软件(FX-TRN-BEG-C),从 文件 - 主画面,“B: 让我们学习基本的”- “B-3.控制优先程序”。 点击“梯形图编辑”…...
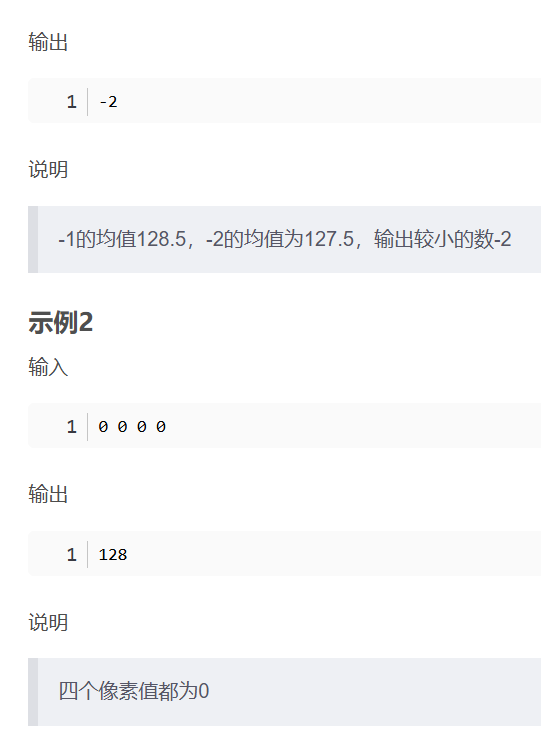
华为OD机考- 简单的自动曝光/平均像素
import java.util.Arrays; import java.util.Scanner;public class DemoTest4 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint[] arr Array…...