Pytorch 混合精度训练 (Automatically Mixed Precision, AMP)
Contents
- 混合精度训练 (Mixed Precision Training)
- 单精度浮点数 (FP32) 和半精度浮点数 (FP16)
- 为什么要用 FP16
- 为什么只用 FP16 会有问题
- 解决方案
- 损失缩放 (Loss Scaling)
- FP32 权重备份
- 黑名单
- Tensor Core
- NVIDIA apex 库代码解读
- opt-level (o1, o2, o3, o4)
- apex 的 o1 实现
- apex 的 o2 实现
- 在 PyTorch 中使用混合精度训练
- Automatic Mixed Precision (AMP)
- Typical Mixed Precision Training
- Saving/Resuming
- Working with Unscaled Gradients (Gradient Clipping)
- Working with Scaled Gradients
- Gradient accumulation
- Gradient penalty
- Working with Multiple GPUs
- 其他注意事项
- References
PyTorch 1.6 之前,大家都是用 NVIDIA 的 apex 库来实现 AMP 训练。1.6 版本之后,PyTorch 出厂自带 AMP,仅需几行代码,就能让显存占用减半,训练速度加倍
混合精度训练 (Mixed Precision Training)
单精度浮点数 (FP32) 和半精度浮点数 (FP16)
- PyTorch 默认使用单精度浮点数 (FP32) 来进行网络模型的计算和权重存储,表示范围为 [−3e38,−1e−38]∪[1e−38,3e38]\left[-3 e^{38},-1 e^{-38}\right] \cup\left[1 e^{-38}, 3 e^{38}\right][−3e38,−1e−38]∪[1e−38,3e38]. 而半精度浮点数 (FP16) 表示范围只有 [−6.5e4,−5.9e−8]∪[5.9e−8,6.5e4]\left[-6.5 e^{4},-5.9 e^{-8}\right] \cup\left[5.9 e^{-8}, 6.5 e^{4}\right][−6.5e4,−5.9e−8]∪[5.9e−8,6.5e4],可以看到 FP32 能够表示的范围要比 FP16 大的多得多
 其中
其中sign位表示正负,exponent位表示指数,fraction 位表示分数 - 此外浮点数还存在舍入误差,当两个数字相差太大时,相加是无效的。例如 2−3+2−142^{-3}+2^{-14}2−3+2−14 在 FP32 中就不会有问题,但在 FP16 中,由于 FP16 表示的固定间隔为 2−132^{-13}2−13,因此 2−142^{-14}2−14 加了跟没加一样
# FP32
>>> torch.tensor(2**-3) + torch.tensor(2**-14)
tensor(0.1251)# FP16
>>> torch.tensor(2**-3).half() + torch.tensor(2**-14).half()
tensor(0.1250, dtype=torch.float16)

对于 float16:
- 如果 Exponent 位全部为 0:
- 如果 fraction 位全部为 0,则表示数字 0
- 如果 fraction 位不为 0,则表示一个非常小的数字 (subnormal numbers),其计算方式为 (−1)signbit×2−14×(0+fraction1024)(-1)^{signbit}\times2^{-14}\times(0+\frac{fraction}{1024})(−1)signbit×2−14×(0+1024fraction)
- 如果 Exponent 位全部为 1:
- 如果 fraction 位全部为 0,则表示 ±inf±inf±inf
- 如果 fraction 位不为0,则表示 NAN
- Exponent 位的其他情况:(−1)signbit×(exponent×2−15)×(1+fraction1024)(-1)^{signbit}\times(exponent\times2^{-15})\times(1+\frac{fraction}{1024})(−1)signbit×(exponent×2−15)×(1+1024fraction)

为什么要用 FP16
- 如果我们在训练过程中将 FP32 替代为 FP16,有以下两个好处:(1) 减少显存占用: FP16 的显存占用只有 FP32 的一半,这使得我们可以用更大的 batch size;(2) 加速训练: 使用 FP16,模型的训练速度几乎可以提升 1 倍
为什么只用 FP16 会有问题
如果我们简单地把模型权重和输入从 FP32 转化成 FP16,虽然速度可以翻倍,但是模型的精度会被严重影响。原因如下:
- 上/下溢出: FP16 的表示范围不大,超过 6.5e46.5 e^{4}6.5e4 的数字会上溢出变成 inf,小于
5.9e−85.9 e^{-8}5.9e−8 的数字会下溢出变成 0。下溢出更加常见,因为在网络训练的后期,模型的梯度往往很小,甚至会小于 FP16 的下限,此时梯度值就会变成 0,模型参数无法更新。下图为 SSD 网络在训练过程中的梯度统计,有 67% 的值下溢出变成 0

- 舍入误差: 就算梯度不会上/下溢出,如果梯度值和模型的参数值相差太远,也会发生舍入误差的问题。假设模型参数 w=2−3w=2^{-3}w=2−3,学习率 η=2−2\eta=2^{-2}η=2−2,梯度 g=2−12g=2^{-12}g=2−12,则 w′=w+η×g=2−3+2−2×2−12=2−3w'=w+\eta\times g=2^{-3}+2^{-2}\times 2^{-12}=2^{-3}w′=w+η×g=2−3+2−2×2−12=2−3
解决方案
损失缩放 (Loss Scaling)
- 为了解决下溢出的问题,论文中对计算出来的 loss 值进行缩放 (scale),由于链式法则的存在,对 loss 的缩放会作用在每个梯度上。缩放后的梯度,就会平移到 FP16 的有效范围内。这样就可以用 FP16 存储梯度而又不会溢出了。此外,在进行更新之前,需要先将缩放后的梯度转化为 FP32,再将梯度反缩放 (unscale) 回去以便进行参数的梯度下降 (注意这里一定要先转成 FP32,不然 unscale 的时候还是会下溢出)
- 缩放因子 (loss_scale) 一般都是框架自动确定的,只要没有发生 inf 或者 nan,loss_scale 越大越好。因为随着训练的进行,网络的梯度会越来越小,更大的 loss_scale 可以更加充分地利用 FP16 的表示范围
FP32 权重备份
- 为了实现 FP16 的训练,我们需要把模型权重和输入数据都转成 FP16,反向传播的时候就会得到 FP16 的梯度。如果此时直接进行更新,因为梯度 ×\times× 学习率的值往往较小,和模型权重的差距会很大,可能会出现舍入误差的问题
- 解决思路是: 将模型权重、激活值、梯度等数据用 FP16 来存储,同时维护一份 FP32 的模型权重副本用于更新。在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。因为整个更新过程是在 FP32 的环境中进行的,所以不会出现舍入误差
黑名单
- 对于那些在 FP16 环境中运行不稳定的模块,我们会将其添加到黑名单中,强制它在 FP32 的精度下运行。比如需要计算 batch 均值的 BN 层就应该在 FP32 下运行,否则会发生舍入误差。还有一些函数对于算法精度要求很高,比如 torch.acos(),也应该在 FP32 下运行
- 如何保证黑名单模块在 FP32 环境中运行: 以 BN 层为例,将其权重转为 FP32,并且将输入从 FP16 转成 FP32,这样就可以保证整个模块是在 FP32 下运行的
Tensor Core
- Tensor Core 可以让 FP16 做矩阵相乘,然后把结果累加到 FP32 的矩阵中。这样既可以享受 FP16 高速的矩阵乘法,又可以利用 FP32 来消除舍入误差

NVIDIA apex 库代码解读
opt-level (o1, o2, o3, o4)
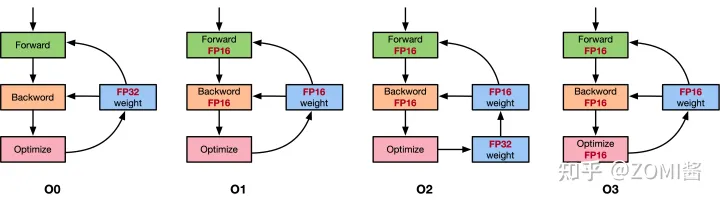
- 首先介绍下 apex 提供的几种 opt-level: o1, o2, o3, o4
- o0 是纯 FP32,用来当精度的基准。o3 是纯 FP16,用来当速度的基准
- 重点讲 o1 和 o2 。我们之前讲的 AMP 策略其实就是 o2: 除了 BN 层的权重和输入使用 FP32,模型的其余权重和输入都会转化为 FP16。此外还会创建一个 FP32 的权重副本来执行更新操作
- 和 o2 不同, o1 不再需要 FP32 权重备份,因为 o1 的模型一直都是 FP32。 可能有些读者会好奇,既然模型参数是 FP32,那怎么在训练过程中使用 FP16 呢?答案是 o1 建立了一个 PyTorch 函数的黑白名单,对于白名单上的函数,强制要求其用 FP16,即会将函数的参数先转化为 FP16,再执行函数本身。黑名单则强制要求 FP32。以
nn.Linear为例, 这个模块有两个权重参数 weight 和 bias,输入为 input,前向传播就是调用了torch.nn.functional.linear(input, weight, bias)。 o1 模式会将 input、weight、bias 先转化为 FP16 格式 input_fp16、weight_fp16、bias_fp16,再调用函数torch.nn.functional.linear(input_fp16, weight_fp16, bias_fp16)。这样一来就实现了模型参数是 FP32,但是仍然可以使用 FP16 来加速训练。o1 还有一个细节: 虽然白名单上的 PyTorch 函数是以 FP16 运行的,但是产生的梯度是 FP32,所以不需要手动将其转成 FP32 再 unscale,直接 unscale 即可。通常来说 o1 比 o2 更稳,一般先选择 o1,再尝试 o2 看是否掉点,如果不掉点就用 o2
apex 的 o1 实现
- (1) 根据黑白名单对 PyTorch 内置的函数进行包装。白名单函数强制 FP16,黑名单函数强制 FP32。其余函数则根据参数类型自动判断,如果参数都是 FP16,则以 FP16 运行,如果有一个参数为 FP32,则以 FP32 运行
- (2) 将 loss_scale 初始化为一个很大的值
- (3) 对于每次迭代
- (a). 前向传播: 模型权重是 FP32,按照黑白名单自动选择算子精度
- (b). 将 loss 乘以 loss_scale
- (ccc). 反向传播: 因为模型权重是 FP32,所以即使函数以 FP16 运行,也会得到 FP32 的梯度
- (d). 将梯度 unscale,即除以 loss_scale
- (e). 如果检测到 inf 或 nan.
- i. loss_scale /= 2
- ii. 跳过此次更新
- (f).
optimizer.step(),执行此次更新 - (g). 如果连续 2000 次迭代都没有出现 inf 或 nan,则 loss_scale *= 2
apex 的 o2 实现
- (1) 将除了 BN 层以外的模型权重转化为 FP16,并且包装了 forward 函数,将其参数也转化为 FP16
- (2) 维护一个 FP32 的模型权重副本用于更新
- (3) 将 loss_scale 初始化为一个很大的值
- (4) 对于每次迭代
- (a). 前向传播: 除了 BN 层是 FP32,模型其它部分都是 FP16
- (b). 将 loss 乘以 loss_scale
- (ccc). 反向传播,得到 FP16 的梯度
- (d). 将 FP16 梯度转化为 FP32,并 unscale
- (e). 如果检测到 inf 或 nan
- i. loss_scale /= 2
- ii. 跳过此次更新
- (f). optimizer.step(),执行此次更新
- (g). 如果连续 2000 次迭代都没有出现 inf 或 nan,则 loss_scale *= 2
在 PyTorch 中使用混合精度训练
Automatic Mixed Precision (AMP)
from torch.cuda.amp import autocast, GradScaler
- 通常 AMP 需要同时使用 autocast 和 GradScaler,其中 autocast 的实例对象是作为上下文管理器 (context manger) 或装饰器 (decorator) 来允许用户代码的某些区域在混合精度下运行,自动为 CUDA 算子选择(单/半)精度来提升性能并保持精度 (See the Autocast Op Reference for details on what precision autocast chooses for each op, and under what circumstances.),并且 autocast 区域是可以嵌套的,这可以强制让 FP16 下可能溢出的模型部分以 FP32 运行;而 GradScaler 则是用来进行 loss scale
- autocast 应该只封装网络的前向传播 (forward pass(es)),以及损失计算 (loss computation(s))。反向传播不推荐在 autocast 区域内执行,反向传播的操作会自动以对应的前向传播的操作的数据类型运行
Typical Mixed Precision Training
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)# Creates a GradScaler once at the beginning of training.
scaler = GradScaler(enabled=True)for epoch in epochs:for input, target in data:optimizer.zero_grad()# Runs the forward pass with autocasting.with autocast(enabled=True, dtype=torch.float16):output = model(input)loss = loss_fn(output, target)# Scales loss. Calls backward() on scaled loss to create scaled gradients.scaler.scale(loss).backward()# scaler.step() first unscales the gradients of the optimizer's assigned params.# If these gradients do not contain infs or NaNs, optimizer.step() is then called,# otherwise, optimizer.step() is skipped.scaler.step(optimizer)# Updates the loss scale value for next iteration.scaler.update()
Saving/Resuming
checkpoint = {"model": net.state_dict(),"optimizer": opt.state_dict(),"scaler": scaler.state_dict()}
net.load_state_dict(checkpoint["model"])
opt.load_state_dict(checkpoint["optimizer"])
scaler.load_state_dict(checkpoint["scaler"])
Working with Unscaled Gradients (Gradient Clipping)
- 经过
scaler.scale(loss).backward()得到的梯度是 scaled gradient,如果想要在scaler.step(optimizer)前进行梯度裁剪等操作,就必须先用scaler.unscale_(optimizer)得到 unscaled gradient
scaler = GradScaler()for epoch in epochs:for input, target in data:optimizer.zero_grad()with autocast(dtype=torch.float16):output = model(input)loss = loss_fn(output, target)scaler.scale(loss).backward()# Unscales the gradients of optimizer's assigned params in-placescaler.unscale_(optimizer)# Since the gradients of optimizer's assigned params are unscaled, clips as usual:torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)# optimizer's gradients are already unscaled, so scaler.step does not unscale them,# although it still skips optimizer.step() if the gradients contain infs or NaNs.scaler.step(optimizer)# Updates the scale for next iteration.scaler.update()
Working with Scaled Gradients
Gradient accumulation
- Gradient accumulation 基于 effective batch of size
batch_per_iter*iters_to_accumulate(*num_procsif distributed) 进行梯度累加,因此属于同一个 effective batch 的多个迭代 batch 内,scale factor 应该保持不变 (scale updates should occur at effective-batch granularity),并且累加的梯度应该是 Scaled Gradients。因为如果在梯度累加结束前的某一个迭代中 unscale gradient (或改变 scale factor),那么下一个迭代的梯度回传就会把 scaled grads 加到 unscaled grads (或乘上了不同 scale factor 的 scaled grads) 上,这会使得在最后进行梯度更新时,我们无法恢复出 accumulated unscaled grads. 如果想要 unscaled grads,应该在梯度累加结束后调用scaler.unscale_(optimizer)
scaler = GradScaler()for epoch in epochs:for i, (input, target) in enumerate(data):with autocast(dtype=torch.float16):output = model(input)loss = loss_fn(output, target)loss = loss / iters_to_accumulate# Accumulates scaled gradients.scaler.scale(loss).backward()if (i + 1) % iters_to_accumulate == 0:# may unscale_ here if desired (e.g., to allow clipping unscaled gradients)scaler.step(optimizer)scaler.update()optimizer.zero_grad()
Gradient penalty
- https://pytorch.org/docs/stable/notes/amp_examples.html#gradient-penalty
Working with Multiple GPUs
- 目前的版本中 (v1.13),不管是 DP (one GPU per thread) (多线程) 还是 DDP (one GPU per process) (多进程),上述代码都无需改动。只有当使用 DDP (multiple GPUs per process) 时,才需要给 model 的 forwad 方法添加 autocast 装饰器或上下文管理器
- 当然,如果使用老版本的 pytorch,是否需要改动代码请参考官方文档
其他注意事项
- 常数的范围:为了保证计算不溢出,首先要保证人为设定的常数不溢出,如各种 epsilon,INF (改成
-float('inf')就可以啦)
References
- paper: Micikevicius, Paulius, et al. “Mixed precision training.” (ICLR, 2018).
- AUTOMATIC MIXED PRECISION PACKAGE - TORCH.AMP
- CUDA AUTOMATIC MIXED PRECISION EXAMPLES
- Automatic Mixed Precision Recipe
- 由浅入深的混合精度训练教程
- 【PyTorch】唯快不破:基于 Apex 的混合精度加速
- 浅谈混合精度训练
- 【Trick2】torch.cuda.amp自动混合精度训练 —— 节省显存并加快推理速度
- 自动混合精度训练 (AMP) – PyTorch
相关文章:
Pytorch 混合精度训练 (Automatically Mixed Precision, AMP)
Contents混合精度训练 (Mixed Precision Training)单精度浮点数 (FP32) 和半精度浮点数 (FP16)为什么要用 FP16为什么只用 FP16 会有问题解决方案损失缩放 (Loss Scaling)FP32 权重备份黑名单Tensor CoreNVIDIA apex 库代码解读opt-level (o1, o2, o3, o4)apex 的 o1 实现apex …...

使用太极taichi写一个只有一个三角形的有限元
公式来源 https://blog.csdn.net/weixin_43940314/article/details/128935230 GAME103 https://games-cn.org/games103-slides/ 初始化我们的三角形 全局的坐标范围为0-1 我们的三角形如图所示 ti.kernel def init():X[0] [0.5, 0.5]X[1] [0.5, 0.6]X[2] [0.6, 0.5]x[0…...
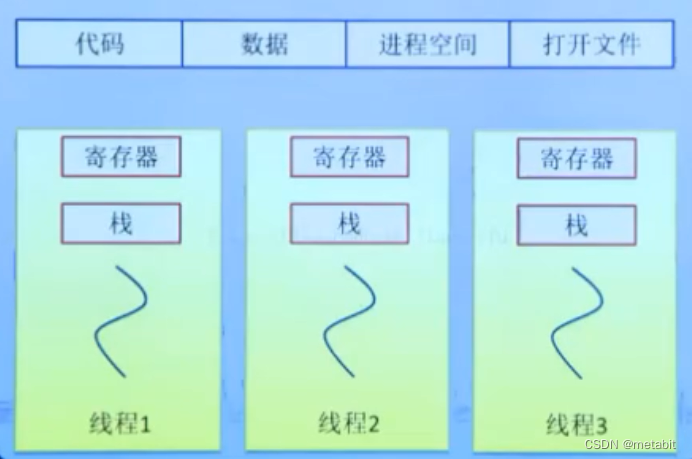
进程,线程
进程是操作系统分配资源的基本单位,线程是CPU调度的基本单位。 PCB:进程控制块,操作系统描述程序的运行状态,通过结构体task,struct{…},统称为PCB(process control block)。是进程管理和控制的…...

第03章_基本的SELECT语句
第03章_基本的SELECT语句 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 1. SQL概述 1.1 SQL背景知识 1946 年,世界上第一台电脑诞生,如今,借由这台电脑发展…...

干货 | 简单了解运算放大器...
运算放大器发明至今已有数十年的历史,从最早的真空管演变为如今的集成电路,它在不同的电子产品中一直发挥着举足轻重的作用。而现如今信息家电、手机、PDA、网络等新兴应用的兴起更是将运算放大器推向了一个新的高度。01 运算放大器简述运算放大器&#…...
C++定位new用法及注意事项
使用定位new创建对象,显式调用析构函数是必须的,这是析构函数必须被显式调用的少数情形之一!, 另有一点!!!析构函数的调用必须与对象的构造顺序相反!切记!!&a…...

【Android笔记75】Android之翻页标签栏PagerTabStrip组件介绍及其使用
这篇文章,主要介绍Android之翻页标签栏PagerTabStrip组件及其使用。 目录 一、PagerTabStrip翻页标签栏 1.1、PagerTabStrip介绍 1.2、PagerTabStrip的使用 (1)创建布局文件...

【Kafka】【二】消息队列的流派
消息队列的流派 ⽬前消息队列的中间件选型有很多种: rabbitMQ:内部的可玩性(功能性)是⾮常强的rocketMQ: 阿⾥内部⼀个⼤神,根据kafka的内部执⾏原理,⼿写的⼀个消息队列中间 件。性能是与Kaf…...

现代 cmake (cmake 3.x) 操作大全
cmake 是一个跨平台编译工具,它面向各种平台提供适配的编译系统配置文件,进而调用这些编译系统完成编译工作。cmake 进入3.x 版本,指令大量更新,一些老的指令开始被新的指令集替代,并加入了一些更加高效的指令/参数。本…...
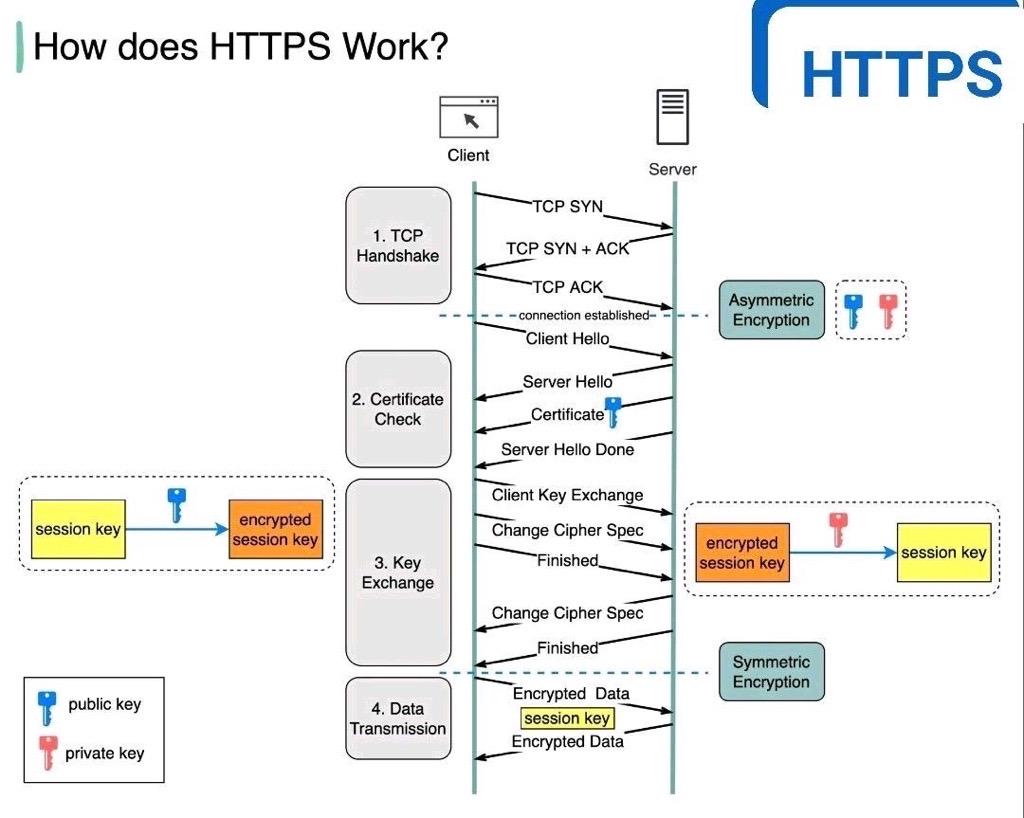
how https works?https工作原理
简单一句话: https http TLShttps 工作原理:HTTPS (Hypertext Transfer Protocol Secure)是一种带有安全性的通信协议,用于在互联网上传输信息。它通过使用加密来保护数据的隐私和完整性。下面是 HTTPS 的工作原理:初始化安全会…...

Docker的资源控制管理
目录 一、CPU控制 1、设置CPU使用率上限 2、设置CPU资源占用比(设置多个容器时才有效) 3、设置容器绑定指定的CPU 二、对内存使用进行限制 1、创建指定物理内存的容器 2、创建指定物理内存和swap的容器 3、 对磁盘IO配额控制(blkio&a…...

MMSeg无法使用单类自定义数据集训练
文章首发及后续更新:https://mwhls.top/4423.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 摘要:将三通道图像转为一通道图像,…...

Redis使用方式
一、Redis基础部分: 1、redis介绍与安装比mysql快10倍以上 *****************redis适用场合**************** 1.取最新N个数据的操作 2.排行榜应用,取TOP N 操作 3.需要精确设定过期时间的应用 4.计数器应用 5.Uniq操作,获取某段时间所有数据排重值 6.实时系统,反垃圾系统7.P…...
 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播)
无主之地3重型武器节奏评分榜(9.25) 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播
无主之地3重型武器节奏评分榜(9.25) 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播者 发射巨大能量球,能量球会额外生成追踪附近敌人的伴生弹 全属性 SSS SSS SSS - T0 伊甸6号-…...

什么是编程什么是算法
1.绪论 编程应在一个开发环境中完成源程序的编译和运行。首先,发现高级语言开发环境,TC,Windows系统的C++,R语言更适合数学专业的学生。然后学习掌握编程的方法,在学校学习,有时间的人可以在网上学习,或者购买教材自学。最后,编写源程序,并且在开发环境中实践。 例如…...

【c++】函数
文章目录函数的定义函数的调用值传递常见样式函数的声明函数的分文件编写函数的作用: 将一段经常使用的代码封装起来,减少重复代码。 一个较大的程序,一般分为若干个程序块,每个模板实现特定的功能。 函数的定义 返回值类型 函数…...

[golang gin框架] 1.Gin环境搭建,程序的热加载,路由GET,POST,PUT,DELETE
一.Gin 介绍Gin 是一个 Go (Golang) 编写的轻量级 http web 框架,运行速度非常快,如果你是性能和高效的追求者,推荐你使用 Gin 框架.Gin 最擅长的就是 Api 接口的高并发,如果项目的规模不大,业务相对简单,这…...
【开源】祁启云网络验证系统V1.11
简介 祁启云免费验证系统 一个使用golang语言、Web框架beego、前端Naive-Ui-Admin开发的免费网络验证系统 版本 当前版本1.11 更新方法 请直接将本目录中的verification.exe/verification直接覆盖到你服务器部署的目录,更新前,请先关闭正在运行的验…...

震源机制(Focal Mechanisms)之沙滩球(Bench Ball)
沙滩球包含如下信息: a - 判断断层类型,可根据球的颜色快速判断 b - 判断断层的走向(strike),倾角(dip) c - 确定滑移角/滑动角(rake) 走向 ,倾角,滑移角 如不了解断层的定义,可以先阅读:震…...

C++入门:多态
多态按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。C 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。1、纯虚函数声明如下: virtual void funtion1()0; 纯…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...

《Offer来了:Java面试核心知识点精讲》大纲
文章目录 一、《Offer来了:Java面试核心知识点精讲》的典型大纲框架Java基础并发编程JVM原理数据库与缓存分布式架构系统设计二、《Offer来了:Java面试核心知识点精讲(原理篇)》技术文章大纲核心主题:Java基础原理与面试高频考点Java虚拟机(JVM)原理Java并发编程原理Jav…...