Python3 第八十一课 -- urllib
目录
一. 前言
二. urllib.request
三. urllib.error
四. urllib.parse
五. urllib.robotparser
一. 前言
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
本文主要介绍 Python3 的 urllib。
urllib 包 包含以下几个模块:
- urllib.request - 打开和读取 URL。
- urllib.error - 包含 urllib.request 抛出的异常。
- urllib.parse - 解析 URL。
- urllib.robotparser - 解析 robots.txt 文件。

二. urllib.request
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- timeout:设置访问超时时间。
- cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
- cadefault:已经被弃用。
- context:ssl.SSLContext类型,用来指定 SSL 设置。
实例如下:
from urllib.request import urlopenmyURL = urlopen("https://www.baidu.com/")
print(myURL.read())以上代码使用 urlopen 打开一个 URL,然后使用 read() 函数获取网页的 HTML 实体代码。
read() 是读取整个网页内容,我们可以指定读取的长度:
from urllib.request import urlopenmyURL = urlopen("https://www.baidu.com/")
print(myURL.read(300))除了 read() 函数外,还包含以下两个读取网页内容的函数:
-
readline() - 读取文件的一行内容
from urllib.request import urlopenmyURL = urlopen("https://www.baidu.com/") print(myURL.readline()) #读取一行内容 -
readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
from urllib.request import urlopenmyURL = urlopen("https://www.baidu.com/") lines = myURL.readlines() for line in lines:print(line)
我们在对网页进行抓取时,经常需要判断网页是否可以正常访问,这里我们就可以使用 getcode() 函数获取网页状态码,返回 200 说明网页正常,返回 404 说明网页不存在:
import urllib.requestmyURL1 = urllib.request.urlopen("https://www.baidu.com/")
print(myURL1.getcode()) # 200try:myURL2 = urllib.request.urlopen("https://www.baidu.com/no.html")
except urllib.error.HTTPError as e:if e.code == 404:print(404) # 404如果要将抓取的网页保存到本地,可以使用 Python3 File write() 方法 函数:
from urllib.request import urlopenmyURL = urlopen("https://www.baidu.com/")
f = open("baidu_urllib_test.html", "wb")
content = myURL.read() # 读取网页内容
f.write(content)
f.close()执行以上代码,在本地就会生成一个 baidu_urllib_test.html 文件,里面包含了 https://www.baidu.com/ 网页的内容。
URL 的编码与解码可以使用 urllib.request.quote() 与 urllib.request.unquote() 方法:
import urllib.requestencode_url = urllib.request.quote("https://www.baidu.com/") # 编码
print(encode_url)unencode_url = urllib.request.unquote(encode_url) # 解码
print(unencode_url)输出结果为:
https%3A//www.baidu.com/
https://www.baidu.com/模拟头部信息
我们抓取网页一般需要对 headers(网页头信息)进行模拟,这时候需要使用到 urllib.request.Request 类:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- headers:HTTP 请求的头部信息,字典格式。
- origin_req_host:请求的主机地址,IP 或域名。
- unverifiable:很少用这个参数,用于设置网页是否需要验证,默认是 False。
- method:请求方法, 如 GET、POST、DELETE、PUT等。
import urllib.request
import urllib.parseurl = 'https://www.baidu.com/?s=' # 百度搜索页面
keyword = 'Python 教程'
key_code = urllib.request.quote(keyword) # 对请求进行编码
url_all = url+key_code
header = {'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
request = urllib.request.Request(url_all,headers=header)
reponse = urllib.request.urlopen(request).read()fh = open("./urllib_test_baidu_search.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()执行以上 Python 代码,会在当前目录生成 urllib_test_baidu_search.html 文件,打开 urllib_test_baidu_search.html 文件(可以使用浏览器打开)。
表单 POST 传递数据,我们先创建一个表单,代码如下,我这里使用了 PHP 代码来获取表单的数据:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>百度一下( baidu.com) urllib POST 测试</title>
</head>
<body>
<form action="" method="post" name="myForm">Name: <input type="text" name="name"><br>Tag: <input type="text" name="tag"><br><input type="submit" value="提交">
</form>
<hr>
<?php
// 使用 PHP 来获取表单提交的数据,你可以换成其他的
if(isset($_POST['name']) && $_POST['tag'] ) {echo $_POST["name"] . ', ' . $_POST['tag'];
}
?>
</body>
</html>import urllib.request
import urllib.parseurl = 'https://www.baidu.com/try/py3/py3_urllib_test.php' # 提交到表单页面
data = {'name':'baidu', 'tag' : '百度一下'} # 提交数据
header = {'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #头部信息
data = urllib.parse.urlencode(data).encode('utf8') # 对参数进行编码,解码使用 urllib.parse.urldecode
request=urllib.request.Request(url, data, header) # 请求处理
reponse=urllib.request.urlopen(request).read() # 读取结果fh = open("./urllib_test_post_baidu.html","wb") # 将文件写入到当前目录中
fh.write(reponse)
fh.close()执行以上代码,会提交表单数据到 py3_urllib_test.php 文件,输出结果写入到 urllib_test_post_baidu.html 文件。
打开 urllib_test_post_baidu.html 文件(可以使用浏览器打开)。
三. urllib.error
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
对不存在的网页抓取并处理异常:
import urllib.request
import urllib.errormyURL1 = urllib.request.urlopen("https://www.baidu.com/")
print(myURL1.getcode()) # 200try:myURL2 = urllib.request.urlopen("https://www.baidu.com/no.html")
except urllib.error.HTTPError as e:if e.code == 404:print(404) # 404四. urllib.parse
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring 为 字符串的 url 地址,scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
from urllib.parse import urlparseo = urlparse("https://www.baidu.com/?s=python+%E6%95%99%E7%A8%8B")
print(o)以上实例输出结果为:
ParseResult(scheme='https', netloc='www.baidu.com', path='/', params='', query='s=python+%E6%95%99%E7%A8%8B', fragment='')从结果可以看出,内容是一个元组,包含 6 个字符串:协议,位置,路径,参数,查询,判断。
我们可以直接读取协议内容:
from urllib.parse import urlparseo = urlparse("https://www.baidu.com/?s=python+%E6%95%99%E7%A8%8B")
print(o.scheme)以上实例输出结果为:
https完整内容如下:
| 属性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
|
| 0 | URL协议 | scheme 参数 |
|
| 1 | 网络位置部分 | 空字符串 |
|
| 2 | 分层路径 | 空字符串 |
|
| 3 | 最后路径元素的参数 | 空字符串 |
|
| 4 | 查询组件 | 空字符串 |
|
| 5 | 片段识别 | 空字符串 |
|
| 用户名 |
| |
|
| 密码 |
| |
|
| 主机名(小写) |
| |
|
| 端口号为整数(如果存在) |
|
五. urllib.robotparser
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
urllib.robotparser 提供了 RobotFileParser 类,语法如下:
class urllib.robotparser.RobotFileParser(url='')这个类提供了一些可以读取、解析 robots.txt 文件的方法:
-
set_url(url) - 设置 robots.txt 文件的 URL。
-
read() - 读取 robots.txt URL 并将其输入解析器。
-
parse(lines) - 解析行参数。
-
can_fetch(useragent, url) - 如果允许 useragent 按照被解析 robots.txt 文件中的规则来获取 url 则返回 True。
-
mtime() -返回最近一次获取 robots.txt 文件的时间。 这适用于需要定期检查 robots.txt 文件更新情况的长时间运行的网页爬虫。
-
modified() - 将最近一次获取 robots.txt 文件的时间设置为当前时间。
-
crawl_delay(useragent) -为指定的 useragent 从 robots.txt 返回 Crawl-delay 形参。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
request_rate(useragent) -以 named tuple RequestRate(requests, seconds) 的形式从 robots.txt 返回 Request-rate 形参的内容。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
site_maps() - 以 list() 的形式从 robots.txt 返回 Sitemap 形参的内容。 如果此形参不存在或者此形参的 robots.txt 条目存在语法错误,则返回 None。
>>> import urllib.robotparser
>>> rp = urllib.robotparser.RobotFileParser()
>>> rp.set_url("http://www.musi-cal.com/robots.txt")
>>> rp.read()
>>> rrate = rp.request_rate("*")
>>> rrate.requests
3
>>> rrate.seconds
20
>>> rp.crawl_delay("*")
6
>>> rp.can_fetch("*", "http://www.musi-cal.com/cgi-bin/search?city=San+Francisco")
False
>>> rp.can_fetch("*", "http://www.musi-cal.com/")
True相关文章:
Python3 第八十一课 -- urllib
目录 一. 前言 二. urllib.request 三. urllib.error 四. urllib.parse 五. urllib.robotparser 一. 前言 Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。 本文主要介绍 Python3 的 urllib。 urllib 包 包含以下几个模块: url…...

Vue 3+Vite+Eectron从入门到实战系列之(五)一后台管理登录页
前面已经讲了不少基础知识,这篇开始,我们进行实操,做个后台管理系统,打包成多端的,可安装的桌面app!!其中,登录,退出的提示信息用系统的提示,不使用elemengplus的弹窗提示!ÿ…...

Docker 网络代理配置及防火墙设置指南
Docker 网络代理配置及防火墙设置指南 背景 在某些环境中,服务器无法直接访问外网,需要通过网络代理进行连接。虽然我们通常会在 /etc/environment 或 /etc/profile 等系统配置文件中直接配置代理,但 Docker 命令无法使用这些配置。例如&am…...

基于PostGIS(Postgres)+Node.js实现的xyz瓦片地图服务器
背景介绍 前两天研究GeoServer发布存储在PostGIS中栅格数据,最终目的是想在PostGIS中存储金字塔瓦片,用GeoServer发布,但是最后经过研究不改GeoServer源码的情况下,好像只支持将大图tif存在PostGIS数据库中进行发布,金…...

浙大数据结构慕课课后题(06-图3 六度空间)
题目要求: 输入格式: 输入第1行给出两个正整数,分别表示社交网络图的结点数N(1<N≤103,表示人数)、边数M(≤33N,表示社交关系数)。随后的M行对应M条边,每行给出一对正…...

Windows File Recovery卡在99%怎么解决?实用指南!
为什么会出现“Windows File Recovery卡在99%”的问题? Windows File Recovery(Windows文件恢复)是微软设计的命令行应用程序。它可以帮助用户从健康/损坏/格式化的存储设备中恢复已删除/丢失的文件。 通过输入相关命令,设置源/…...

数据结构之数组
写在前面 看下数组。 1:巴拉巴拉 数组是一种线性数据结构,使用连续的内存空间来存储数据,存储的数据要求有相同的数据类型,并且每个元素占用的内存空间相同。获取元素速度非常快,为O(1)常量时间复杂度,所…...

springboot集成sensitive-word实现敏感词过滤
文章目录 敏感词过滤方案一:正则表达式方案二:基于DFA算法的敏感词过滤工具框架-sensitive-wordspringboot集成sensitive-word步骤一:引入pom步骤二:自定义配置步骤三:自定义敏感词白名单步骤四:核心方法测…...

C++ 之动手写 Reactor 服务器模型(一):网络编程基础复习总结
基础 IP 地址可以在网络环境中唯一标识一台主机。 端口号可以在主机中唯一标识一个进程。 所以在网络环境中唯一标识一个进程可以使用 IP 地址与端口号 Port 。 字节序 TCP/IP协议规定,网络数据流应采用大端字节序。 大端:低地址存高位,…...

qt 在vs2022 报错记录
1,qt.network.ssl: QSslSocket::connectToHostEncrypted: TLS initialization failed 需要把SSL 相关的库加入进去,如ssleay32.dll,libeay32.dll。 2,在一个文件中已定义,编译器在链接时,在多处报 已在.*…...

【人工智能】TensorFlow和机器学习概述
一、TensorFlow概述 TensorFlow是由Google Brain团队开发的开源机器学习库,用于各种复杂的数学计算,特别是在深度学习领域。以下是对TensorFlow的详细概述: 1. 核心概念 张量(Tensor):TensorFlow中的基本…...

SQLALchemy 的介绍
SQLALchemy 的介绍 基本概述主要特点使用场景安装与配置安装 SQLAlchemy配置 SQLAlchemy示例:使用 SQLite 数据库连接到其他数据库 结论 总结 SQLAlchemy是Python编程语言下的一款开源软件,它提供了SQL工具包及对象关系映射(ORM)工…...
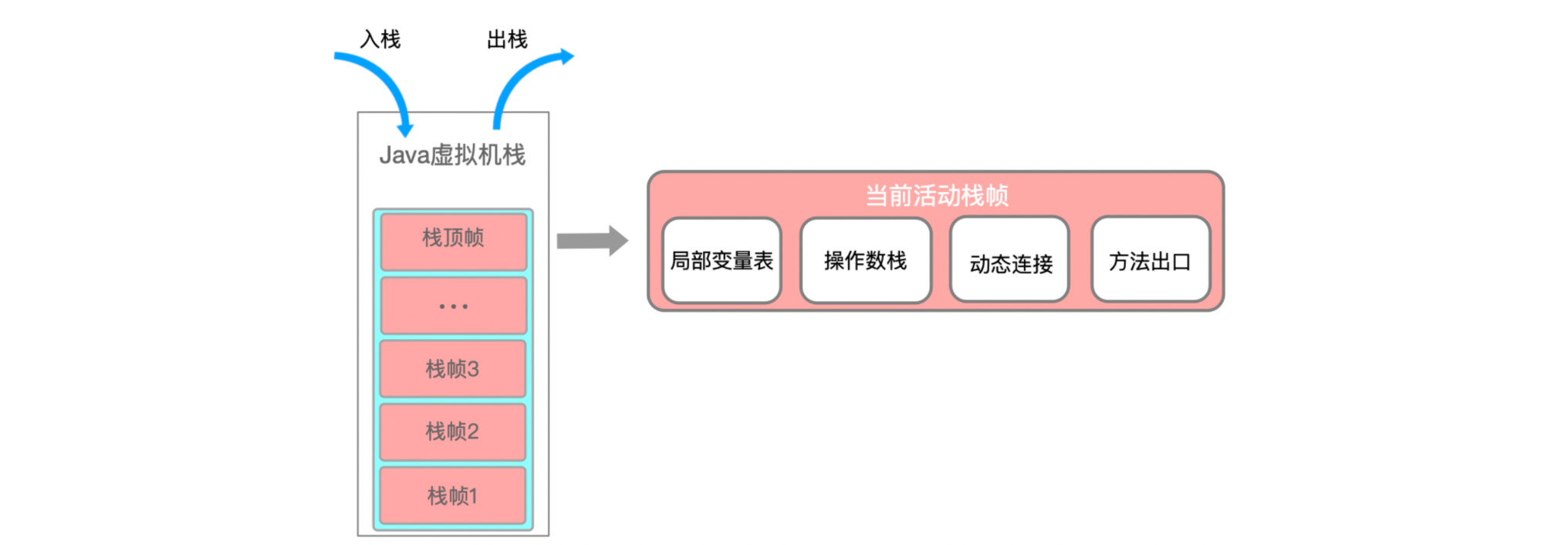
Java虚拟机:运行时内存结构
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 035 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

微信小程序子组件调用父组件的方法
来源:通义千文2.5 步骤 1: 定义父组件中的方法 首先,在父组件中定义一个方法(如 handleClick),并准备一个用于接收子组件传来的数据的方法。 父组件(Parent.wxml) html<!-- parent.wxml …...

【数据结构】TreeMap和TreeSet
目录 前言TreeMap实现的接口内部类常用方法 TreeSet实现的接口常用方法 前言 Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 一般把搜索的数据称为关键字(Key), 和关键字对应的称为…...

前端react集成OIDC
文章目录 OpenID Connect (OIDC)3种 授权模式 【服务端】express 集成OIDC【前端】react 集成OIDCoidc-client-js库 原生集成react-oidc-context 库非组件获取user信息 OAuth 2.0 协议主要用于资源授权。 OpenID Connect (OIDC) https://openid.net/specs/openid-connect-core…...

JavaWeb—XML_Tomcat10_HTTP
一、XML XML是EXtensible MarkupLanguage的缩写,翻译过来就是可扩展标记语言。所以很明显,XML和HTML一样都是标记语言,也就是说它们的基本语法都是标签。 可扩展:三个字表面上的意思是XML允许自定义格式。但这不代表你可以随便写; 在XML基…...

中介者模式在Java中的实现:设计模式精解
中介者模式在Java中的实现:设计模式精解 中介者模式(Mediator Pattern)是一种行为型设计模式,用于定义一个中介者对象,以封装一系列对象之间的交互,从而使对象之间的交互不再直接发生,减少了系…...

PyQt编程快速上手
Python GUI安装 GUI就是图形用户界面的意思,在Python中使用PyQt可以快速搭建自己的应用,使得自己的程序看上去更加高大上,学会GUI编程可以使得自己的软件有可视化的结果。 如果你想用Python快速制作界面,可以安装PyQt:…...

Docker Swarm管理
Docker Swarm管理 前置知识点 Docker Swarm 是 Docker 公司 2014年出品的基于 Docker 的集群管理调度工具,能够将多台主机构建成一个Docker集群,并结合Overlay网络实现容器调度的互访 用户可以只通过 Swarm API 来管理多个主机上的 Docker Swarm 群集包…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...