4章7节:用R做数据重塑,数据去重和数据的匹配
在数据科学的分析流程中,数据重塑是一项非常重要的操作。数据的重塑通常指将数据从一种形式转换为另一种形式,以满足后续分析的需求。R语言提供了丰富的工具和函数来帮助用户高效地进行数据重塑操作。本文中,我们将深入探讨数据重塑的概念及其重要性,并详细介绍几个关键操作,包括数据去重、数据的匹配以及行列命名。
一、数据重塑
数据重塑(Data Reshaping)是指通过对数据框(Data Frame)或其他类型的数据结构进行操作,改变其形式或结构的过程。数据重塑的目标是使数据更加符合特定分析的需求,从而简化分析过程,提高分析的准确性和效率。
提高数据分析的灵活性:通过重塑数据,分析人员可以将数据转换为适合各种分析模型的形式。例如,将宽格式数据转换为长格式数据,或反之亦然,以便于时间序列分析、回归分析等。
数据清理与准备:数据重塑是数据清理过程中不可或缺的一部分。通过重塑,用户可以去除冗余信息、修正错误数据、匹配数据集之间的关系等。
优化计算性能:在某些情况下,特定形式的数据可能更易于处理,能够提高计算效率,特别是在处理大数据集时。
简化可视化过程:很多可视化工具和方法对数据的格式有特定的要求,通过重塑数据,可以更轻松地将数据转换为适合可视化的格式。
二、数据重塑之数据去重
数据去重(Data deduplication)是指识别并删除数据文件集合中的重复数据,仅保留唯一的数据单元,从而消除冗余数据。因为重复数据的存在不但浪费存储资源,而且可能导致数据分析结果出现偏差,所以在数据清洗过程中,去重是不可忽视的一项工作。
数据去重通常有完全去重和不完全去重两种。
完全去重是指在数据集中识别并删除那些所有字段值完全相同的重复记录。比如,在一个客户数据库中,如果两个记录的所有字段(如姓名、地址、电话等)完全相同,则其中一个记录将被删除,保留唯一的一份记录。完全去重的主要目的是消除完全重复的数据,确保每一条记录都是唯一的。
不完全去重涉及到在数据清洗过程中处理那些部分重复的数据记录。与完全去重不同,不完全去重的标准是根据数据的业务逻辑和具体需求来确定的。比如,在一个客户数据库中,两个记录可能在部分字段上相同(如姓名相同但地址不同),这种情况下,我们需要根据实际业务需求来决定是否保留这些记录,以及如何处理这些部分重复的记录。
在医学数据处理中,由于数据的复杂性和多样性,去除重复数据显得尤为重要。为了演示去重操作,
我们先创建一个就医患者的数据集。这里我们将数据集中每一行表示一个患者的就诊记录,包括患者 ID、姓名、年龄、诊断、住址和就诊日期等信息。我们将探讨完全去重和不完全去重的应用场景,并演示如何使用 duplicated() 函数实现不完全去重。
# 创建扩展的示例患者数据集
patients_data <- data.frame(PatientID = c(1, 2, 3, 1, 4, 5, 6, 3, 7, 8, 9, 3, 10, 11),Name = c("张三", "李四", "王五", "张三", "赵六", "孙七", "周八", "王五", "吴九", "王五", "李四", "王五", "李四", "赵六"),Age = c(30, 45, 28, 30, 60, 50, 34, 28, 41, 28, 45, 29, 45, 60),Diagnosis = c("感冒", "高血压", "糖尿病", "感冒", "冠心病", "关节炎", "胃炎", "糖尿病", "肺炎", "胃炎", "高血压", "糖尿病", "感冒", "冠心病"),Address = c("北京", "上海", "广州", "北京", "天津", "深圳", "南京", "广州", "杭州", "南京", "上海", "上海", "北京", "天津"),VisitDate = as.Date(c('2024-01-01', '2024-01-02', '2024-01-03', '2024-01-01', '2024-01-04', '2024-01-05', '2024-01-06', '2024-01-03', '2024-01-07', '2024-01-06', '2024-01-02', '2024-01-03', '2024-01-01', '2024-01-04'))
)# 显示扩展后的原始患者数据集
print("扩展后的原始患者数据集:")
print(patients_data)数据可见:
PatientID Name Age Diagnosis Address VisitDate
1 1 张三 30 感冒 北京 2024-01-01
2 2 李四 45 高血压 上海 2024-01-02
3 3 王五 28 糖尿病 广州 2024-01-03
4 1 张三 30 感冒 北京 2024-01-01
5 4 赵六 60 冠心病 天津 2024-01-04
6 5 孙七 50 关节炎 深圳 2024-01-05
7 6 周八 34 胃炎 南京 2024-01-06
8 3 王五 28 糖尿病 广州 2024-01-03
9 7 吴九 41 肺炎 杭州 2024-01-07
10 8 王五 28 胃炎 南京 2024-01-06
11 9 李四 45 高血压 上海 2024-01-02
12 3 王五 29 糖尿病 上海 2024-01-03
13 10 李四 45 感冒 北京 2024-01-01
14 11 赵六 60 冠心病 天津 2024-01-041、完全去重
在上面数据集中,如果一条患者记录的所有字段(如 PatientID、Name、Age、Diagnosis、Address 和 VisitDate)都与另一条记录相同,则认为它是完全重复的,需要删除。我们可以使用R中的unique()函数删除完全重复的行,只保留一个记录:
# 使用 unique() 函数进行完全去重
unique_patients <- unique(patients_data)# 显示完全去重后的患者数据集
print("完全去重后的患者数据集:")
print(unique_patients)
去重后的数据集为:
PatientID Name Age Diagnosis Address VisitDate
1 1 张三 30 感冒 北京 2024-01-01
2 2 李四 45 高血压 上海 2024-01-02
3 3 王五 28 糖尿病 广州 2024-01-03
5 4 赵六 60 冠心病 天津 2024-01-04
6 5 孙七 50 关节炎 深圳 2024-01-05
7 6 周八 34 胃炎 南京 2024-01-06
9 7 吴九 41 肺炎 杭州 2024-01-07
10 8 王五 28 胃炎 南京 2024-01-06
11 9 李四 45 高血压 上海 2024-01-02
12 3 王五 29 糖尿病 上海 2024-01-03
13 10 李四 45 感冒 北京 2024-01-01
14 11 赵六 60 冠心病 天津 2024-01-04可以看到,去重后数据集中的重复记录已被成功移除。
2、不完全去重
除了使用unique()函数进行完全去重外,在实际的数据清洗工作中,还可能遇到需要基于部分字段进行去重的需求。R中的duplicated()函数可以帮助我们识别部分字段的重复记录,然后根据这些重复记录进行去重操作。
接上面的例子,我们可以根据实际业务逻辑来决定如何处理这些有部分重复的记录。所以,我们将基于 VisitDate 和 Address 进行去重,保留记录中患者的首次出现。
# 基于 VisitDate 和 Address 进行去重,保留首次记录
non_dup_patients <- patients_data[!duplicated(patients_data[, c("VisitDate", "Address")]), ]
上面这行代码的目的是对患者数据集进行不完全去重,具体来说:提取
VisitDate和Address列: 选择这两个列作为去重的基础,意思是我们希望找到在同一天、同一地点就诊的重复记录。检测重复: 使用duplicated()函数检测VisitDate和Address组合中的重复记录。保留首次记录: 通过!duplicated()的逻辑反转操作,仅保留每组VisitDate和Address组合中的第一条记录,其余重复记录将被去掉。创建去重后的数据框: 最终,去重后的数据框被赋值给non_dup_patients,该数据框中只包含每个VisitDate和Address组合的首次出现的记录,其他重复项已被删除。
运行上述代码,我们可以识别出哪些行是基于Patient和Age字段的重复记录,并将这些重复记录删除,得到最终的数据集。
# 显示按 VisitDate 和 Address 去重后的患者数据集(保留首次记录)
print("按 VisitDate 和 Address 去重后的患者数据集(保留首次记录):")
print(non_dup_patients)结果可见:
PatientID Name Age Diagnosis Address VisitDate
1 1 张三 30 感冒 北京 2024-01-01
2 2 李四 45 高血压 上海 2024-01-02
3 3 王五 28 糖尿病 广州 2024-01-03
5 4 赵六 60 冠心病 天津 2024-01-04
6 5 孙七 50 关节炎 深圳 2024-01-05
7 6 周八 34 胃炎 南京 2024-01-06
9 7 吴九 41 肺炎 杭州 2024-01-07
12 3 王五 29 糖尿病 上海 2024-01-032、数据的匹配
数据匹配(Data Matching)是指基于某个或某些相同的变量(字段),将两个数据框合并在一起。数据匹配操作在数据预处理和整合中非常常见,尤其在处理来自不同数据源的医学数据时更是如此。常见的匹配操作包括左连接(left join)、右连接(right join)、内连接(inner join)、全连接(full join)、半连接(semi join)和反连接(anti join)。我们将以构建两个示例数据框为基础,逐步演示这些操作的实现和实际应用场景。
构建两个示例数据框
首先,我们构建两个示例数据框df.1和df.2,用于演示不同类型的数据匹配与合并操作。
# 创建两个数据框
df.1 <- data.frame(x = c('a','b','c','d','e','f','a'), y = c(1, 2, 3, 4, 5, 6, 7))
df.2 <- data.frame(x = c('a','b','m','n'), z = c('A','B','M',"N"))# 查看数据框内容
print(df.1)
print(df.2)
df.1的数据如下:
x y
1 a 1
2 b 2
3 c 3
4 d 4
5 e 5
6 f 6
7 a 7df.2的数据如下:
x z
1 a A
2 b B
3 m M
4 n N左连接(Left Join)
左连接返回左表df.1的所有记录,并且会匹配右表df.2中相同x值的记录。如果在右表中没有匹配的记录,结果中对应的列值为NA。
library(dplyr)# 执行左连接
result_left_join <- left_join(df.1, df.2, by = 'x')
print(result_left_join)
结果可见:
x y z
1 a 1 A
2 b 2 B
3 c 3 <NA>
4 d 4 <NA>
5 e 5 <NA>
6 f 6 <NA>
7 a 7 A左连接在数据整合过程中非常有用,尤其当你需要保持主要数据框的所有记录,而仅在某些列上增加补充信息时。
右连接(Right Join)
右连接与左连接相反,它返回右表df.2的所有记录,并匹配左表df.1中的记录。如果左表中没有匹配的记录,结果中对应的列值为NA。
# 执行右连接
result_right_join <- right_join(df.1, df.2, by = 'x')
print(result_right_join)
结果可见:
x y z
1 a 1 A
2 b 2 B
3 a 7 A
4 m NA M
5 n NA N右连接主要用于保留右表的所有记录,并在需要时填充来自左表的相关数据。
内连接(Inner Join)
内连接返回两个数据框中匹配的部分,也就是变量x的交集部分。仅保留在两个数据框中都存在的记录。
# 执行内连接
result_inner_join <- inner_join(df.1, df.2, by = 'x')
print(result_inner_join)
结果可见:
x y z
1 a 1 A
2 b 2 B
3 a 7 A内连接最适合在你只关心同时存在于两个数据集中的记录时使用。
全连接(Full Join)
全连接将两个数据框的所有记录返回。如果某个数据框中没有匹配的记录,结果中对应的列值为NA。
# 执行全连接
result_full_join <- full_join(df.1, df.2, by = 'x')
print(result_full_join)
结果可见:
x y z
1 a 1 A
2 b 2 B
3 c 3 <NA>
4 d 4 <NA>
5 e 5 <NA>
6 f 6 <NA>
7 a 7 A
8 m NA M
9 n NA N全连接在需要结合所有可能的记录时非常有用,特别是在数据整合和对比分析中。
半连接(Semi Join)
半连接用于从左表(df.1)中提取在右表(df.2)中有匹配项的记录。换句话说,半连接会返回左表中所有能够在右表中找到匹配值的行,但它只保留左表中的列,而不会添加右表中的列。
# 执行半连接
result_semi_join <- semi_join(df.1, df.2, by = 'x')
print(result_semi_join)
结果可见:
x y
1 a 1
2 b 2
3 a 7在这个例子中,df.1中的x列有值a和b,它们在df.2中也存在。因此,半连接返回了df.1中x为a和b的所有记录。
反连接(Anti Join)
反连接用于从左表(df.1)中排除在右表(df.2)中有匹配项的记录。简单来说,反连接会返回左表中所有在右表中找不到匹配值的行。
# 执行反连接
result_anti_join <- anti_join(df.1, df.2, by = 'x')
print(result_anti_join)
结果可见:
x y
1 c 3
2 d 4
3 e 5
4 f 6
半连接和反连接在数据处理的特定场景中非常有用,前者用于提取符合条件的记录,而后者用于排除不符合条件的记录。它们可以帮助我们有效地筛选和清理数据,从而提高数据分析的精度和效率。
更新:2024/08/11

相关文章:
4章7节:用R做数据重塑,数据去重和数据的匹配
在数据科学的分析流程中,数据重塑是一项非常重要的操作。数据的重塑通常指将数据从一种形式转换为另一种形式,以满足后续分析的需求。R语言提供了丰富的工具和函数来帮助用户高效地进行数据重塑操作。本文中,我们将深入探讨数据重塑的概念及其…...

大数据面试SQL(七):累加刚好超过各省GDP40%的地市名称
文章目录 累加刚好超过各省GDP40%的地市名称 一、题目 二、分析 三、SQL实战 四、样例数据参考 累加刚好超过各省GDP40%的地市名称 一、题目 现有各省地级市的gdp数据,求从高到低累加刚好超过各省GDP40%的地市名称,临界地市也需要。 例如: 浙江省…...

建议收藏!这4款设计师常用的素材管理软件,助你工作效率翻倍!
嘿,设计师们!你是否还在为那一堆堆散乱的素材头疼?每次灵感来袭,却要花费大量时间在层层文件夹中苦苦搜寻?别急,今天我就来给大家推荐4款超给力的素材管理软件,它们不仅能帮你轻松整理素材库&am…...

用于NLP领域的排序模型最佳实践
在自然语言处理(NLP)领域,用于排序任务的模型通常是指那些能够对文本进行排序、比较或评估其相关性的模型。这些模型可以应用于诸如文档排序、句子排序、问答系统中的答案排序等多种场景。在当前的研究和发展中,基于深度学习的方法…...

域名未备案的支付平台遭遇大攻击怎么办
域名未备案的支付平台遭遇大攻击怎么办?在当今数字化时代,支付平台的安全与稳定性是保障业务连续性和用户信任的关键。然而,对于因域名未备案而面临法律风险的支付平台来说,其安全挑战更为严峻。当这类平台遭遇大规模的网络攻击&a…...

【NI-DAQmx入门】LabVIEW数据采集基础应用程序框架
对于可管理规模的 LabVIEW 程序,分析现有程序或设计新程序的方法通常是从整体到具体,即从高级到低级的分析和设计。从一开始就直接深入细节可能会效率较低。 在设计阶段,开发人员首先将程序垂直划分为几个层级。从最顶层开始,他们…...
海山数据库(He3DB)源码详解:CommitTransaction函数源码详解
文章目录 海山数据库(He3DB)源码详解:CommitTransaction函数1. 执行条件2. 执行过程2.1 获取当前节点状态:2.2 检查当前状态:2.3 预提交处理:2.4 提交处理:2.5 释放资源:2.6 提交事务: 作者介绍…...

【网络】传输层TCP协议的报头和传输机制
目录 引言 报头和有效载荷 确认应答机制 捎带应答机制 超时重传机制 排序和去重 连接管理机制 个人主页:东洛的克莱斯韦克-CSDN博客 引言 TCP是传输层协议,全称传输控制协议。TCP报头中有丰富的字段以及协议本身会制定完善的策略来保证网络传输的…...

【活动报名】打造编程学习“知识宝库”:高效笔记记录与整理指南
如何高效记录并整理编程学习笔记? 在编程学习的旅程中,拥有一套高效的笔记记录和整理方法至关重要。以下将从三个方向为您详细介绍如何打造属于自己的编程学习“知识宝库”。 方向一:笔记工具选择 选择合适的笔记工具是高效记录编程学习笔记…...

使用Arduino IDE生成带有bootloader的烧录文件
使用Arduino IDE生成bin(烧录)文件 1、在“项目”中,选择“导出已编译的二进制文件” 2、在工程目录中,会出现“build”文件夹 3、在build文件夹中,有hex文件,以及包含bootloader的bin和hex文件 bin和h…...
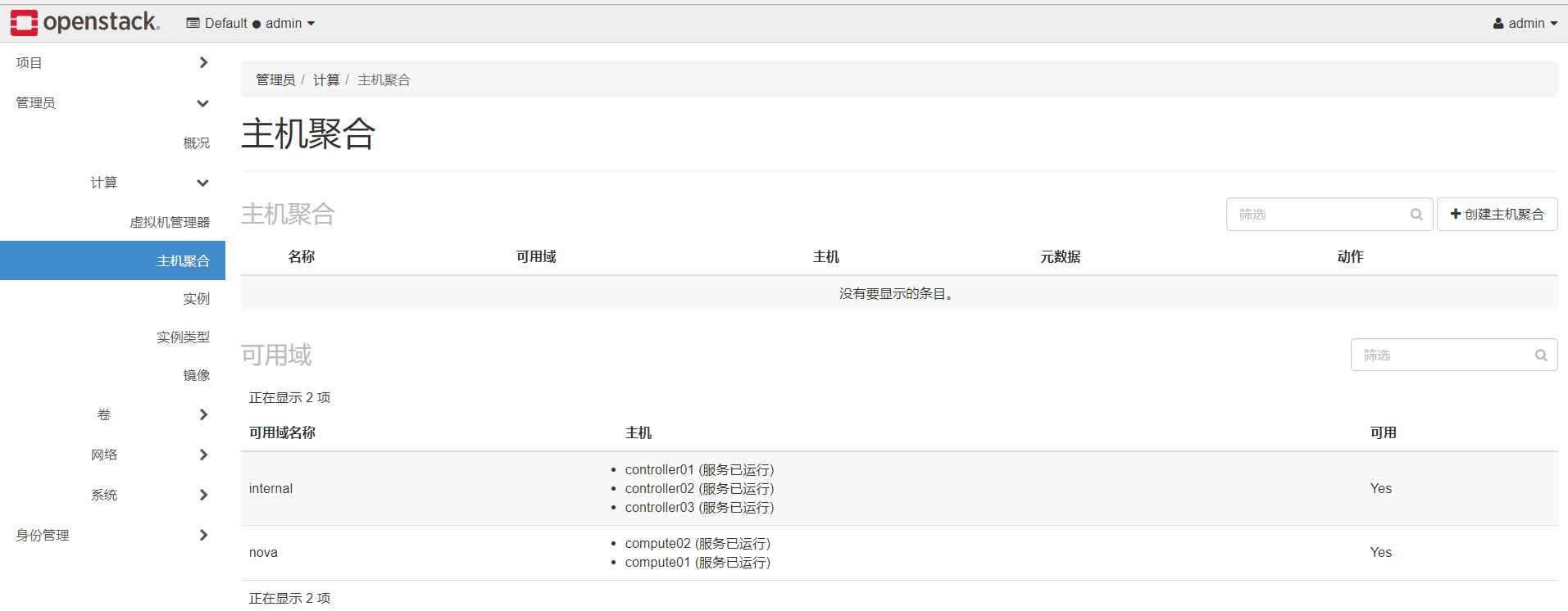
搭建高可用OpenStack(Queen版)集群(九)之部署nova计算节点
一、搭建高可用OpenStack(Queen版)集群之部署计算节点 一、部署nova 1、安装nova-compute 在全部计算节点安装nova-compute服务 yum install python-openstackclient openstack-utils openstack-selinux -y yum install openstack-nova-compute -y 若yu…...

C# 字符串扩展方法
功能 1.判断一个字符串是否为null或者空字符串 2.判断一个字符串是否为null或者空白字符 3.判断一个字符串是否为数字 4.判断一个字符串是否为邮件 5.判断一个字符串是否为字母加数字 6.判断一个字符串是否为手机号码 7.判断一个字符串是否为电话号码 8.判断一个字符串是否为网…...

JookDB和MobaXterm下载安装使用
文章目录 1.使用背景2.MobaXterm的下载安装使用3.JooKDB的下载安装使用 1.使用背景 由于xshell和xftp等工具都是收费的,即使有破解版但是有的公司里不让用盗版的软件。可以使用MobaXterm来替代。 同理可使用JooKDB来代替收费的navicat 来连接数据库。 2.MobaXterm…...
)
Docker安装Nacos(详细教程)
Docker安装Nacos的步骤相对直接,但需要注意一些细节以确保安装成功。以下是一个详细的安装步骤指南: 1. 安装Docker 首先,确保你的系统中已经安装了Docker。如果尚未安装,你可以通过访问Docker的官方网站或使用包管理器…...

Pandas:提供了快速、灵活和表达式丰富的数据结构。
引言 Pandas是Python中最为广泛使用的数据分析和操作库之一,特别适用于处理结构化数据。该库的名称源自“Panel Data”的缩写,意为面板数据或多维数据。Pandas基于NumPy构建,继承了其高效的数组计算能力,并在此基础上进一步扩展&…...

强!小目标检测全新突破!检测速度快10倍,GPU使用减少73.4%
强!小目标检测全新突破,提出Mamba-in-Mamba结构,通过内外两层Mamba模块,同时提取全局和局部特征,实现了检测速度快10倍,GPU使用减少73.4%的显著效果! 【小目标检测】是近年来在深度…...

重修设计模式-创建型-原型模式
重修设计模式-创建型-原型模式 原型模式就是利用已有对象(原型)通过拷贝方式来创建对象的模式,达到节省对象创建时间的目的。适用于对象创建成本较大,且同一类的不同对象之间差别不大的场景。 比如一个对象中的数据需要经过复杂…...

S71200 - 编程 - 笔记
1 DEMO 1.1气阀控制 1.2 红绿灯 基于PLC红绿灯控制_哔哩哔哩_bilibili 2 介绍变量DB,M,I,Q的使用 在PLC编程中,通常会使用多种类型的变量来实现逻辑控制、数据存储和输入输出操作。以下是常见的PLC变量类型及其用途ÿ…...

【项目】畅聊天地博客测试报告
项目简介:本项目采用 SSM框架结合 Websocket 技术构建。用户通过简单的注册和登录即可进入聊天室,与其他在线用户实时交流。系统支持文字消息的快速发送和接收、消息实时推送,确保交流的及时性和流畅性。SSM 框架为项目提供了稳定的架构和高效…...

【Next】全局样式和局部样式
不同于 nuxt ,next 的样式绝大部分都需要手动导入。 全局样式 使用 sass 先安装 npm i sass -D 。 我们可以定义一个 styles 文件,存放全局样式。 variables.scss $fs30: 30px;mixin border() {border: 1px solid red; }main.scss use ./variables …...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...