阿里云智能大数据演进
本文根据7月24日飞天发布时刻产品发布会、7月5日DataFunCon2024·北京站:大数据·大模型.双核时代实录整理而成,演讲信息如下:
演讲人:徐晟 阿里云研究员/计算平台产品负责人
主要内容:
-
Overview - 阿里云大数据 + AI 产品线介绍
-
Trending - 大数据和 AI 趋势分析
-
Solution - 阿里云智能大数据产品解决方案
-
Future - 未来展望
一、Overview - 阿里云 + AI 产品线介绍
首先简单介绍一下阿里云的大数据和AI产品。阿里云在全球布局30个region,基本已覆盖国际各主要地区,包括89个可用区, 超过3200个CDN节点,为客户提供高效稳定的基础云化的计算和存储服务。

阿里云拥有非常多的大数据和AI系列产品,大数据产品主要包括两条线:
-
一是自研产品线,自阿里云成立之初便自主研发,涵盖大数据处理、机器学习、数据仓库等多个领域,如MaxCompute、DataWorks、Hologres、PAI等。
-
二是开源产品线,阿里云积极参与开源社区,贡献并维护了一系列开源项目,如Apache Flink、Apache Spark、StarRocks等,为全球开发者提供了丰富的工具和资源。
2023年,阿里云大数据与AI平台实现了3位数增长,成为国内领先的技术驱动力。据统计,国内超过半数的大模型预训练工作在阿里云平台上完成,彰显了其在AI领域的强大实力。在大数据平台性能测试中,阿里云在TPC-DS、TPC-H、TPC-BB等多个榜单上均有出色表现,证明了其在决策型数据分析领域的卓越能力。市场份额方面,阿里云在2022年占据了约49亿市场份额中的20亿,稳居国内领先地位。同时,阿里云在云数仓、AI基础架构和AI开发服务等领域的国际测评中也取得了显著成绩。尽管在国内市场保持领先地位,但阿里云也清醒地认识到,在国际竞争中仍需努力追赶。

阿里云大数据平台的核心优势包括:
-
首先,阿里云凭借强大的基础设施,构建了业界领先的弹性伸缩能力。无论是在业务高峰期还是低谷期,阿里云都能迅速调整资源按需弹性和分时弹性等,多种弹性配置灵活资源供给确保客户应用的平稳运行。这一能力的实现,得益于阿里云对云计算底层技术的深入研究和创新。
-
在技术优化方面,阿里云持续投入,通过算法优化、架构改进等手段,显著提升了服务的性价比。客户在享受高性能计算和存储服务的同时,也获得了成本效益的双重优势。
-
稳定性是阿里云的另一大优势。在数据密集型和高并发场景下,阿里云的服务依然保持了极高的稳定性和可靠性,这背后是阿里云对系统架构的精心设计和对故障恢复机制的不断完善。
-
随着AI技术的兴起,阿里云积极探索大数据与AI的深度融合,推出了一系列创新解决方案。从智能数据分析到AI模型训练,阿里云为客户提供了一站式服务,推出AI for Science、Data for AI等助力企业快速实现AI赋能。
-
此外,阿里云在安全管控和企业服务方面也做了大量工作。从数据加密、访问控制到合规性审计,阿里云构建了全方位的安全防护体系,让客户在享受云计算便利的同时,无需担心数据安全问题。
阿里云的这些努力,不仅提升了自身的竞争力,也为客户带来了实实在在的价值。在数字化转型的浪潮中,阿里云正成为企业信赖的合作伙伴,共同探索未来无限可能。
二、Trending - 大数据和 AI 趋势分析
接下来分享一下大数据和AI的发展趋势,以及阿里云大数据产品是如何顺应这种趋势而演进的。
1. 从数据湖到大数据AI一体

数据湖作为一种数据存储架构,允许以原始格式存储海量数据,无需预定义数据模型,为数据分析提供了极大的灵活性。在系统规模较小、数据处理需求相对简单时,数据湖能够很好地满足需求。其灵活的数据摄入和存储能力,使得企业能够快速响应业务变化,进行探索性数据分析。
但是,随着数据量的激增和业务复杂度的提升,数据湖的非结构化存储和缺乏数据治理开始暴露出问题。所以,特定规模前,数据湖灵活性占优,之后,数仓成长性占优。在数据湖时代,我们无法做到数据湖和数据仓库的成本和灵活性的平衡,各自都有非常大的问题。但是在湖仓一体时代,随着数据读取效率的变高,这个曲线的规律将会被打破,我们可以通过技术的优化与迭代逐渐去取得性能与成本的平衡。后续我们将介绍从数据湖到湖仓一体到大数据AI融合一体的演进。

数据湖的概念自提出以来,旨在创建一个统一的数据存储空间,以原始格式存储各类数据,供不同计算引擎访问和处理。然而,随着技术的发展,数据湖的局限性逐渐显现,尤其是在数据格式、数据治理和跨引擎共享方面,这促使了从数据湖到湖仓一体(Lakehouse),再到大数据AI一体架构的演进。
最初,数据湖设想中包含结构化、半结构化数据的统一存储,但缺乏统一的数据格式标准,导致计算引擎访问数据时效率低下。引擎往往需要自行解析数据,这不仅限制了数据的共享,还可能造成数据孤岛,即数据虽然存储在公共存储上,但实际上只对特定引擎可用。
为了解决这些问题,Lakehouse架构应运而生。Lakehouse在数据湖的基础上,引入了统一的表格式标准,如Delta、Hudi、Iceberg等,以及统一的SDK,使得数据在湖上能够被多个引擎以标准方式访问,从而实现了真正的湖仓一体。阿里云的Paimon、File Cache和Table Cache等技术,进一步优化了湖仓性能,使其接近本地数仓的水平。
随着大数据与AI的深度融合,对数据的统一管理提出了更高要求。大数据AI一体架构不仅关注结构化和半结构化数据,还需考虑AI引擎特有的数据格式,如特征向量等。这要求构建统一的元数据管理,以实现跨引擎的数据访问和处理。元数据管理成为连接不同数据源、引擎的关键,确保了数据的统一视图和高效利用。
然而,从数据湖到大数据AI一体的演进并非没有挑战。公共存储相比私有存储,在性能优化上存在天然劣势,因为私有存储可以针对特定引擎进行深度优化。但随着网络、存储I/O等技术的不断进步,这一差距有望缩小,甚至消失。正如神经网络的发展历程所示,技术进步最终克服了算力限制,推动了AI的广泛应用。
综上所述,大数据与AI的融合是一个持续演进的过程,从数据湖到大数据AI一体架构,不仅解决了数据格式、数据治理和跨引擎共享的挑战,还推动了数据管理技术的创新。尽管在性能优化上仍面临难题,但随着技术的不断进步,这些问题将逐渐得到解决,为大数据与AI的深度融合铺平道路。
2. 阿里云自研大数据产品
(1)MaxCompute

首先,MaxCompute,作为阿里云的旗舰级大数据处理平台,自诞生之日起便与阿里云的崛起紧密相连。MaxCompute的架构设计体现了阿里云在数据存储、计算、调度与服务层面的深厚积累。其核心层包括私有存储与公共存储,通过开放的存储API和SDK,实现了数据的灵活访问与管理。之上,弹性计算和调度层确保了资源的高效利用,能够根据业务需求动态调整计算能力。更进一步,MaxCompute集成了增量计算、元数据管理和开放API等高级功能,为用户提供了一站式的开发与服务体验。这些都属于标配的能力。

在功能与性能上,MaxCompute展现出了企业级安全、大规模数据处理和高可用性等关键优势。由于其早期服务于阿里巴巴集团内部高并发的淘宝、天猫等场景,MaxCompute在安全体系、数据规模处理和故障恢复机制上做了大量优化,确保了数据的完整性和系统的稳定性。此外,MaxCompute与算法的深度融合,使其在机器学习、数据挖掘等领域展现出了强大的应用潜力。
近年来,MaxCompute的重点演进方向之一是湖仓一体的开放架构。同时,Severless的服务弹性进一步增强,能够根据用户需求动态调整资源,确保了在不同业务场景下的高效运行。阿里云的MaxCompute平台,凭借其先进的架构设计和优化技术,为众多企业用户带来了显著的性能提升和成本优化。通过将原有的开源Hadoop体系迁移至MaxCompute,企业不仅能够享受到更稳定、更高效的数据处理能力,还能在成本控制上实现突破。
所以,今天我们在讲所有大数据和AI的尝试时候,一定会看三个指标,第一是稳定性,具有一票否决权;第二是性价比;第三则是性能,如果性能很低,即使性价比很高也是不符合我们的需要的。MaxCompute过往在离线计算领域表现卓越,更在近年来积极拥抱AI,推动大数据与AI的深度融合,形成了独特的数据处理与分析生态。

为了满足AI开发中对交互式编程环境的需求,MaxCompute引入了Notebook开发环境,将大数据处理与AI开发无缝对接。这一创新不仅为开发者提供了熟悉的Python编程环境,也使得大数据工程师能够更便捷地进行数据探索和模型构建,促进了大数据与AI的协同工作。MaxFrame计算框架的推出,是MaxCompute在大数据与AI融合上的又一进展。
MaxFrame允许用户在MaxCompute平台上直接运行分布式Python计算任务,充分利用已购买的MaxCompute计算资源。这一设计不仅避免了系统切换的繁琐,还有效降低了用户成本,实现了大数据与AI计算的资源共享和优化。MaxCompute内部还集成了深度学习和统计学习算法,为用户提供了一站式的算法调用服务。这意味着,用户无需在外部寻找开发算法,就能在MaxCompute平台上进行复杂的数据分析和模型训练,大大简化了工作流程,提高了效率。
在MaxCompute上实现了一个小的大数据和AI的闭环,后面讲到的产品大都具有类似功能。综上所述,MaxCompute通过引入Notebook环境、MaxFrame计算框架和内置算法库,构建了一个完整的大数据与AI融合生态。这一生态不仅体现了MaxCompute在技术融合上的前瞻性,也为用户提供了更加灵活、高效和经济的数据处理解决方案。阿里云的产品线之所以强大,正是因为在每个产品中都融入了大数据与AI结合、湖仓一体以及统一元数据管理等先进理念。MaxCompute的成功案例,正是这一理念的最佳实践。
(2)DataWorks

DataWorks,可以看作是MaxCompute的伴生体。DataWorks从原来最早的基于MaxCompute单引擎闭环,到后面的多引擎支持,今天的DataWorks已经完全不一样了。首先,底层的引擎也好、存储也好都可以用通过DataWorks直接进行访问。中间数据集成、数据治理、数据开发等整套体系已非常完备。现在又加入了当前流行的Copilot、自然语言转SQL、自然语言分析,通过DataWorks不但可以访问到所有的引擎,还可以在开发态享受大模型的红利。
(3)Hologres

Hologres提供统一、实时、弹性、易用的一站式实时数仓引擎,一份数据支持OLAP查询、即席分析、在线服务、向量计算多个场景, 可同时替换 OLAP 引擎(Greenplum/Presto/Impala/ClickHouse等)或 KV 数据库(HBase/Redis等),在TPC-H 30,000GB标准测试结果中Hologres获得世界第一,领先第二名23%。支持10亿+/秒的高吞吐实时写入与更新,PB级数据可实现秒级分析。阿里云自研的三驾马车,MaxCompute、Hologres再加上DataWorks这三个产品基本上覆盖了当前90%的重要场景。剩下的一块是流计算,会用到Flink。
(4)典型案例
下面分享几个案例。

首先是电商的案例。阿里巴巴作为全球领先的电商企业,在电商领域的深厚积累为阿里云产品组合提供了丰富的应用场景。在电商场景中,阿里云的产品组合展现出了强大的数据处理与分析能力。以人工智能平台PAI(平台AI)、Search(搜索服务)、Hologres(交互式查询)以及实时计算Flink技术为核心,构建了从原始数据(ODS)到数据仓库(DWD)再到数据服务(ADS)的整层数仓建模。这些在阿里云整套的产品组合里面都有实际的成功案例。不仅支撑了阿里巴巴内部电商业务的高效运营,也为外部企业提供了成熟的电商解决方案。阿里云在电商领域的实践,尤其注重数据安全与容灾能力的建设。考虑到金融客户等对数据安全有着极高要求的场景,阿里云在产品设计之初就将安全性与容灾机制作为核心考量,确保在任何情况下都能保障数据的完整性和系统的稳定性。

另一个案例是某数字媒体案例。所有数字化相关的迁移、计算、治理,再加上AI,都可以通过我们的产品组合来解决。上图中清晰展示了从数据采集、处理到分析、应用的全链条解决方案。这一架构不仅涵盖了数据的生命周期管理,还融入了AI技术,如智能推荐、内容分析等,为数字媒体的个性化服务和内容创新提供技术支撑。
3. 阿里云开源大数据产品
下面介绍阿里云开源大数据产品。

前面介绍的自研产品重点关注性能、稳定性和能力,而开源产品则更多焦点于如何与湖存储生态无缝融合,以及如何通过开放的生态体系,提供更广泛的兼容性和灵活性。阿里云的开源产品不仅关注性能和稳定性,更强调与湖存储的紧密集成,兼容多种表格式,以及高效的元数据管理,体现了开源先天的开放性和生态兼容性。JindoFS作为阿里云开源产品中的一个亮点,它巧妙地封装了OSS接口,同时支持HDFS文件系统,实现了OSS接口与HDFS的互通。这一设计保持了与上一代数仓方案的兼容性,确保了数据的平滑迁移和使用,起到了前后承启的作用。它也支持file cache等,在此基础上,它也支持前面介绍的主流的湖格式,再加上今年顶级的Apache开源项目Paimon。这些最后统一会被DLF的湖元仓来统一来管理。DLF元数据管理服务在阿里云的湖存储生态中扮演着关键角色。它统一管理了所有湖存储格式的元数据,提供了统一的数据访问和管理接口,使得用户在处理不同格式的数据时,能够享受到一致的体验。DLF的出现,极大地简化了湖存储生态中的元数据管理,提升了数据处理的效率和灵活性。在此基础之上,是我们整个的开源体系。包括EMR、Spark、Flink体系,现在还新加了Milvus的向量检索,在阿里云的开源体系中,ECS(Elastic Compute Service)和EMR(Elastic MapReduce)模式一度是用户搭建自定义大数据处理框架的首选。用户可以租用ECS服务器,并在其上部署EMR框架,构建定制化的数据处理环境。这种模式的流行,背后反映的是用户对于系统控制和定制能力的需求。用户希望能够随时调试和修复问题,拥有对底层系统的完全掌控。然而,随着技术的不断进步和云计算服务的成熟,行业趋势逐渐从分散走向统一,Serverless(无服务器)模式成为新的发展方向。Serverless模式之所以成为主流,关键在于它能够真正解决用户在运维、成本控制和系统管理方面的痛点。在Serverless模式下,用户无需关心底层资源的购买、续费和运维,只需专注于业务逻辑的实现。系统安全、可运维性等技术细节由云服务提供商统一管理,用户只需按需使用和付费,大大简化了操作流程,降低了运维成本。阿里云顺应这一趋势,将Serverless模式作为EMR和Spark产品线的重点发展方向。通过Serverless化,阿里云致力于为用户提供更加灵活、高效、低成本的数据处理服务,让用户能够更专注于业务创新,而无需过多关注底层技术细节。与此同时,阿里云的开源体系也保持着高度的开放性和灵活性。无论是裸金属、ECS、弹性容器还是其他形式的计算资源,阿里云都能够提供支持,满足不同用户在不同场景下的需求。与自研体系相比,开源体系在提供高度定制化能力的同时,也更加注重与行业标准的兼容和用户需求的灵活性,让用户在享受云服务便利的同时,能够根据自身业务特点选择最合适的部署方式。
(1)Serverless Spark

开源系主推Serverless Spark。在Serverless Spark的场景中,Celeborn作为Apache顶级项目,引入了Remote机制,这一创新在数据处理架构上带来了革命性的变化。当有很多计算节点在分布的时候,传统的Spark作业在执行shuffle操作时,依赖于计算节点的本地存储,这不仅限制了shuffle数据的规模,还可能引发存储资源的不均衡分配,导致计算节点因存储空间不足而出现瓶颈。特别是在大规模分布式计算环境中,这一问题尤为突出,增加了系统运维的复杂性和成本。
Celeborn通过将shuffle操作从计算节点的本地存储转移到远程shuffle服务,实现了存储与计算的分离,今天我们有一个shuffle的池子就好了,这是一个非常重要的突破。第二个问题,在大数据处理领域Native Engine(原生引擎)的概念日益受到关注,其核心优势在于能够直接在底层存储系统上运行,无需通过中间层或框架进行数据访问,从而显著提升数据处理的性能和效率。今年我们计划在云栖大会上发布Flink Native Engine,期待大家的关注。
(2)Serverless StarRocks

另外要介绍的就是Serverless StarRocks。Serverless StarRocks作为阿里云的高性能分析引擎,自诞生之初即以湖原生设计为核心,这意味着它在设计上就充分考虑了与湖存储生态的深度融合。Serverless StarRocks不仅能够无缝对接湖存储的各种格式,如Hive、Iceberg、Hudi等,还针对湖存储进行了专门的优化,以提升数据处理性能和分析效率。通过Serverless化,StarRocks实现了资源的弹性伸缩,能够在不增加运维负担的前提下,自动调整计算资源,以应对不同规模的数据处理需求。
(3)Paimon

接下来介绍的是Paimon。当前,Iceberg常常被大家当作批处理的标准湖表格式来用,那为什么还要做Paimon?Paimon是阿里云为解决实时数据处理和流计算场景而设计的湖存储格式。与业界常用的如Delta,Iceberg、Hudi等格式相比,Paimon在实时性能方面具有显著优势。最初,Paimon是为了与Flink等实时计算框架紧密集成而开发的,因此在流处理场景下表现出色。随着Paimon的不断发展,它已经能够同时支持批处理和流处理,成为了一种全面的湖存储格式。我们希望Paimon未来也能够成为一个主力的格式,目前引擎也都在做对接。
(4)实时计算Flink版

Flink作为阿里云在实时计算领域的核心产品,即将迎来一系列创新性的发布,包括针对特定场景优化的native算子和native Flink版本。这些技术革新旨在提升Flink在实时数据处理、流计算等场景下的性能和灵活性,满足企业对实时数据处理日益增长的需求。阿里云将在九月份的云栖大会上,详细分享这些创新成果。欢迎大家来听这方面的专场介绍。
4. 阿里云搜索产品

阿里云的搜索产品主要包括两个部分。第一部分是Elasticsearch。ES在阿里云上做了非常多的适配,它可以将日志等很多轻量的场景很方便地用起来。同时,我们自己还有一个叫做OpenSearch的产品,源自阿里巴巴主搜框架,即淘宝搜索背后的强大技术支撑。主搜框架的开源版本Heavenask,展现了阿里云在搜索技术领域的开放与共享。
那么,对于搜索这个方向,我们最大的区别是什么?今天任何一个做大搜的平台,包括以前的bing、百度或淘宝,虽然它不处理这种数据的结构化的问题,因为商家把结构化表直接入进去了,但其背后有着一个非常庞杂的体系。阿里云的优势在于构建了一个能够支持成百上千算法工程师协同工作的平台。这一平台的构建,对于大型搜索平台的运维和算法迭代至关重要,它使得搜索引擎能够不断优化,提升搜索结果的相关性和用户体验。
把平台与Elasticsearch这样更多的搜索引擎做整合,是未来的一个方向。随着大模型技术的发展, RAG技术成为提升搜索准确性和相关性的重要手段。RAG技术通过结合检索结果和大模型,能够提供更加准确和一致的搜索结果。RAG做检索增强跟大模型相关,然而大模型是没有办法保证准确性的,可能对同一问题给出的答案都是不一样的,所以我们希望将其不确定性转为确定性,希望通过改变input来实现。也就是先搜一遍,把搜索的结果再提交给大模型来回答,这时准确率就会更高。但是要实现这件事是很难的,一定要在整个搜索的向量部分做得非常好才可能有所提升。
当然,从理论上来讲,如果能够接受无限制的token,那也就不需要RAG了,但从成本上来讲是不现实的。所以,我们一直强调三点:一是稳定性,二是性价比,三是性能。我们的LLM智能问答版已经上线,大家有兴趣可以看一下,一分钟怎么构建一个RAG系统。
5. 阿里云人工智能平台PAI
接下来介绍AI场景。

上图左侧展示的是一个PAI-DSW的gallery。PAI-DSW即notebook的编程模式,gallery指的是做好的模板。对于已经收录的模型训练场景,直接点一下模板就可以直接使用了。今天对于AI用户来说,其实就包括两个场景,第一个场景是大家来用,来开发;第二个场景就是购买、管理和使用。

如上图所示,今天的AI工程的infrastructure跟以前有很大区别,以前很多的学习可能一个机器有八个卡,可能用一个卡甚至半个卡就够了。但现在不一样了,几十几百个B的一个模型需要多少卡?所以这个时候问题就出来了,当集群变更大、任务变得更多以后,尤其更要命的是,卡不一定是一样的。这个时候就需要一个非常复杂的工程体系,能够把任务合理地分配到不同的资源上;其次,如果卡出问题,比如八个卡中可能有一个出问题,另外七个还work,正常的监测手段也是看不到的,这些就需要我们在工程上做非常多的适配工作,能够做损失的恢复,也就是把任务调到其它卡上去跑;第三个问题,因为要调到其它卡上去跑,需要在中间save这些状态,这个过程又会影响整体的performance,这里也需要保证间隔足够短,在不影响整体performance的同时保证这个任务能够快速的被schedule。这就是我们的PAI在训练上面做的一些能力。
(1)PAI-DSW

上图中介绍的是交互式开发notebook,在此不展开讲解。
(2)PAI-EAS

接着是推理服务。在大模型的推理服务中,profile和decode这两个过程的要求是不一样的,前者是计算密集型,后者则是访问存储密集型。要做好优化,当模型很大需要很多并行的时候,同样也需要一个很强的工程框架,PAI也提供了这方面的能力。
(3)PAI-DLC

另外一块是模型训练服务PAI-DLC,它与PAI-DSW,交互式开发notebook,和模型推理服务PAI-EAS并列构成人工智能平台PAI的三驾马车,完整解决了AI infrastructure的问题。目前,百川智能、零一万物、vivo、复旦大学、巨人网络等大批企业和机构都在阿里云上训练大模型,并通过阿里云对外提供服务。
三、Solution - 阿里云智能大数据产品解决方案
前面介绍的每个产品都形成了一些自己的小闭环,但是其实我们更希望提供更加统一的解决方案,在今年九月份的云栖大会上将推出一个新的解决方案。

如图,Meta管理、存储管理上面是跨引擎的复用,最上面是开发平台,可以跨引擎调度。我们希望通过这种一体化的方式,不仅仅在产品内部做大数据和AI和湖的这种生态的闭环,也在整体的解决方案上面做闭环。

这里想大家展示了之前提到的阿里云大数据AI产品组合的整体大数据AI融合的产品整体架构。
四、Future - 未来展望

最后是对未来的一些展望。历史上,我们走过很多的阶段,搜索、大数据、AI依次成为业界焦点。然而今天是有史以来第一次,大数据、搜索和AI同台演出。所以今天这个时代跟原来是不一样的,对系统的要求,对产品要求,对知识结构的要求,以及对整个方向的要求都是不一样的。所以,阿里云希望能做出更多更好的产品,来助力业务的创新与发展。如果大家对于上面的阿里云与AI产品感兴趣,也可以在官网体验我们产品的免费试用与各类入门教程,谢谢大家。
以上就是本次分享的内容,谢谢大家。
相关文章:
阿里云智能大数据演进
本文根据7月24日飞天发布时刻产品发布会、7月5日DataFunCon2024北京站:大数据大模型.双核时代实录整理而成,演讲信息如下: 演讲人:徐晟 阿里云研究员/计算平台产品负责人 主要内容: Overview - 阿里云大数据 AI 产品…...

Java面试题———Spring篇①
目录 一,谈谈你对SpringIOC的理解 二,Spring中有哪些依赖注入方式 三,你用过哪些Spring注解 四,SpringBean的作用域有几种 五,Spring中的bean线程安全吗 六,谈谈你对SpringAOP的理解 七,…...

4章10节:用R做数据重塑,变体函数应用详解和可视化的数据预处理介绍
数据重塑(Data Reshaping)是将数据从一种结构转换为另一种结构的过程,是清理、分析和可视化数据的重要步骤。R语言作为数据科学的强大工具,提供了许多包来帮助我们进行数据重塑,其中最常用的就是dplyr包。dplyr包以其简洁的语法和高效的操作速度著称,它不仅可以帮助我们进…...

Socks5代理IP在跨境电商和网络爬虫领域的实战应用
在现代互联网环境中,Socks5代理IP因其强大的灵活性和隐私保护功能,成为了跨境电商和网络爬虫领域的重要工具。本文将探讨Socks5代理IP的基本原理,并详细介绍其在跨境电商和网络爬虫中的实际应用。 1. Socks5代理IP简介 Socks5代理IP是一种网…...

农业上的目标跟踪论文汇总
文章目录 2022Multi-object tracking using Deep SORT and modified CenterNet in cotton seedling counting (Computers and Electronics in Agriculture)A novel apple fruit detection and counting methodology based on deep learning and trunk tracking in modern orcha…...

gpxt 小程序:轨迹合并与管理的高效工具
引言 在户外探险和运动追踪领域,GPXT小程序以其独特的轨迹管理和合并功能脱颖而出,成为徒步、骑行等运动爱好者不可或缺的工具。本文将详细介绍GPXT小程序的核心功能及其对户外活动爱好者的实用性。 核心功能概览 轨迹合并 GPXT小程序允许用户将多个…...

elasticsearch集成springboot详细使用
1.es下载&配置 配置JVM 配置跨域 配置https和密码 2.es启动 .\elasticsearch.bat 或 后台启动: nohup ./bin/elasticsearch& 浏览器访问:https://localhost:9200 输入账户:elastic / 123456 3.重置es密码 .\elasticsearch-r…...

html+css网页制作 化妆品电商4个页面
htmlcss网页制作 化妆品电商4个页面 网页作品代码简单,可使用任意HTML编辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作)。 获取源码 1ÿ…...

微调LLama 3.1——七月论文审稿GPT第5.5版:拿早期paper-review数据集微调LLama 3.1
前言 对于llama3,我们之前已经做了针对llama3 早7数据微调后的测评 去pk llama2的早7数据微调后,推理测试集中的早期paper:出来7方面review去pk gpt4推理测试集中的早期paper:7方面reviewground truth是早期paper的7方面人工rev…...

rust 编译时报错:type annotations needed for Box
如下图所示: 解决方法: 升级time的版本: cargo update -p time...
应用方案 | 低功耗接地故障控制器D4145
一、概述 D4145 是一个接地故障断路器。它能够检测到不良的接地条件,譬如装置接触到水时,它会在有害或致命的电击发生之前将电路断开。 D4145能检测并保护从火线到地线,从零线到地线的故障.这种简单而传统的电路设计能够确保其应用自如和长时间的可靠性。…...

第一次彩色pcb打样记录
感受和总结 看到彩色电路板和绿油板放在一起,感触还是挺大的。而且彩色板还直接给沉金,感觉焊上器件不要外壳都很好看了。后面一定记录一下这个板子实现的功能。 板子功能暂时分配 五个触摸盘,为了通过触摸控制不同功能,例如&a…...

通过 MediatR 实现了请求的分发和处理器的解耦
1. 前端请求发起 假设前端通过 HTTP GET 请求访问 GetTemplateSettings 端点,URL 中包含了 SubjectUuid 和 SubjectType 作为查询参数。 2. 进入 Controller 方法 请求到达后,会进入 MinBcController 类中的 GetTemplateSettings 方法,该方…...

Naive UI+vue一些组件的注意事项
NSpace(间距 Space) 默认给出space内的组件加一个div间隔,只能批量修改space内的元素样式,不能单独修改自组件样式,一般用于横向布局,若垂直布局若需要flex布局,慎用space组件NDataTable(数据表格 Data Table) :flex-h…...

sgetrf M N is 103040 时报错,这是个bug么 lapack and Openblas the same,修复备忘
号外: $ clang-format -style"{BasedOnStyle: llvm, IndentWidth: 4}" -i hello.cpp $ clang-format -style"{BasedOnStyle: llvm, IndentWidth: 4}" -i hello.cpp IndentWidth:4不错,默认2太下了 1,现象 MN103040时&…...

[后端代码审计] PHP 数组知识汇总
文章目录 前言1. 数组基础1.1 数组概念1.2 索引数组1.3 关联数组1.4 多维数组 2. 数组函数2.1 count()2.2 array_merge()2.3 array_keys()2.4 array_values()2.5 in_array() 3. 数组遍历3.1 for循环遍历3.2 foreach遍历3.3 遍历索引数组3.4 遍历关联数组 4. 数组排序4.1 sort()…...

单点Redis中面临哪些问题
我的后端学习大纲 我的Redis学习大纲 1.面试:请说下在单点Redis中面临哪些问题: 1.1.单点Redis的问题: 1.数据丢失问题:Redis是内存存储,服务重启可能会丢失数据 2.并发能力问题:单节点Redis并发能力虽然…...

数学建模--蒙特卡洛算法之电子管更换刀片寿命问题
目录 1.电子管问题重述 2.电子管问题分析 3.电子管问题求解 4.刀片问题重述 5.刀片问题分析 6.刀片问题求解 1.电子管问题重述 某设备上安装有4只型号规格完全相同的电子管,已知电子管寿命服从100~200h之间的均匀分布. 只要有一个电子管…...

如何解码Linux下事件响应工具evtest的时间戳
evtest介绍 这里放一下原文链接evtest工具介绍及安装 在开发input子系统驱动时,常常会使用evtest工具进行测试。evtest是打印evdev内核事件的工具,它直接从内核设备读取并打印设备描述的带有值和符号名的事件,可以用来调试鼠标、键盘、触摸…...

基于STM32开发的智能门禁系统
目录 引言环境准备工作 硬件准备软件安装与配置系统设计 系统架构硬件连接代码实现 初始化代码控制代码应用场景 小区门禁管理企业办公门禁系统常见问题及解决方案 常见问题解决方案结论 1. 引言 智能门禁系统通过整合多种身份识别技术,如密码输入、RFID刷卡、指…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...
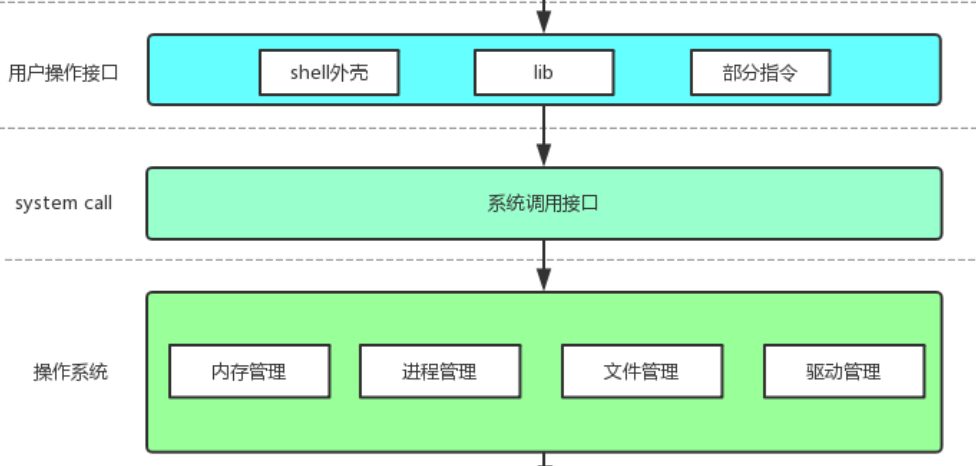
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

32位寻址与64位寻址
32位寻址与64位寻址 32位寻址是什么? 32位寻址是指计算机的CPU、内存或总线系统使用32位二进制数来标识和访问内存中的存储单元(地址),其核心含义与能力如下: 1. 核心定义 地址位宽:CPU或内存控制器用32位…...

Appium下载安装配置保姆教程(图文详解)
目录 一、Appium软件介绍 1.特点 2.工作原理 3.应用场景 二、环境准备 安装 Node.js 安装 Appium 安装 JDK 安装 Android SDK 安装Python及依赖包 三、安装教程 1.Node.js安装 1.1.下载Node 1.2.安装程序 1.3.配置npm仓储和缓存 1.4. 配置环境 1.5.测试Node.j…...