重启人生计划-积蓄星火
🥳🥳🥳 茫茫人海千千万万,感谢这一刻你看到了我的文章,感谢观赏,大家好呀,我是最爱吃鱼罐头,大家可以叫鱼罐头呦~🥳🥳🥳
如果你觉得这个【重启人生计划】对你也有一定的帮助,加入本专栏,开启新的训练计划,漫长成长路,千锤百炼,终飞升巅峰!无水文,不废话,唯有日以继日,终踏顶峰! ✨✨欢迎订阅本专栏✨✨
❤️❤️❤️ 最后,希望我的这篇文章能对你的有所帮助! 愿自己还有你在未来的日子,保持学习,保持进步,保持热爱,奔赴山海! ❤️❤️❤️
🔥【重启人生计划】第零章序·大梦初醒🔥
🔥【重启人生计划】第壹章序·明确目标🔥
🔥【重启人生计划】第贰章序·勇敢者先行🔥
🔥【重启人生计划】第叁章序·拒绝内耗🔥


序言
大家好,我是最爱吃鱼罐头,距离离职已经过去一个月了,目前进度为3,打算重新找工作倒计时27天,当然这其中也会去投递面试。
人生哪里是旷野,人生是山谷,是迷雾重重的森林,是湍急的被裹挟向前的河流,是迷茫和疲倦交织的前路。
今日回顾
昨天不是很焦虑吗,一直在看招聘信息吗,昨晚就在想,先不去理招聘的信息,在面试的过程,假设在这样的一个场景下,比如说我自己作为面试官的时候,我看着眼前自己的这份简历时,对镜子前面的帅哥提问的时候,你会考虑问那些问题呢。
在出去面试的时候,甚至在投递简历的时候,首先你必须对你的简历负责,你必须非常了解你的简历给你带来优势和弱项,你才有可能在面试过程中掌握更多的主动;有时候,自己可能身在局中,而不知问题所在的时候,那就去面试吧,由面试官来真实的提问你,由面试官发现你的弱项,你再去完善提升自己,这是我设想的,对自己发问,修改简历,完善简历,并且能够更从容的应对简历中所面临的问题。
挑战之旅第三天,今天早上大概回顾了下jvm的内容,后面就刷day4的算法题,难度适中,是需要理解链表的数据结构,下午就开始刷了MySQL的面试题,昨天暂时没时间刷视频,想着明天休息一下背诵的进度,来刷一下视频,但进度一直在这,明天再看看吧。
算法回顾
设计链表 📍
设计链表📍

说这道题之前,并且后续做的相关题目都是在这基础上去完成的,所以先说下链表的数据结构:
链表,全名链式存储结构,也是线性表的一种,但是与顺序表不同,不同表现在于:
- 在存储结构中,顺序表是用一组地址连续的存储单元依次存储线性表中的数据元素,而链表它是一种物理存储单元上非连续、非顺序的存储结构;
- 在存储数据中,顺序表只需要存数据元素信息就可以了。而在链表中,除了要存数据元素信息外,还要存储它的后继元素的存储地址;
- 在逻辑顺序中,顺序表是通过数据元素物理存储的相邻关系来反映数据元素之间逻辑上的相邻关系,而在链表中是通过链表的存储后续元素的存储地址来实现的逻辑上的顺序。
在链表中,通常我们把存储数据元素信息所在的域称为数据域,把存储直接后继位置所在的域称为指针域,而将这两部分信息合并称为结点(Node)。
- 数据域:主要用来存放的是数据元素,它可以是基本数据类型,也可以是引用数据类型;
- 指针域:在Java中,是没有指针的概念,但是你能理解指针概念也行,如果理解不了,我们可以称之为引用域或者NEXT指针。引用域可以理解为存储下一个结点的引用地址;NEXT指针可以理解为当前结点指向的下一个结点是谁,是什么。最后一个结点的NEXT指针通常指向null,就是一个空,如果一个结点的next是空的,就说明这个结点是最后一个结点。
链表的基本结构就是通过一系列结点组合成,而结点又是可以在内存中动态生成,一个个结点通过NEXT指针来串联起来,形成一个链表。
基础概念知识:
- 结点:链表中的基本单元,包含数据和一个指向下一个结点的指针(在单向链表中)。例如,一个结点可以包含一个整数和一个指针,指向下一个结点。
- 头结点(Head):链表的起始结点。通过它可以访问链表中的所有其他结点。
- 尾结点(Tail):链表的最后一个结点,它的指针为空(在单向链表中),表示链表的结束。
- 单向链表:每个结点只包含一个指向下一个结点的指针。遍历链表时只能从头到尾前进,无法回退。
- 双向链表:每个结点包含两个指针,一个指向下一个结点,一个指向前一个结点。可以从头到尾遍历,也可以从尾到头遍历。
- 循环链表:链表的最后一个结点指向头结点,形成一个循环结构。可以是单向的,也可以是双向的。
讲个不恰当的例子,当让我回忆回忆得了:
不知道大家还是否记得那个是要成为海贼王的辣个男人,路飞现在已经觉醒了第五档,“太阳神尼卡”形态,只能说主角光环闪闪发光呀,反正我路飞就是挂多,凯多再怎么打,能打得过主角吗,可见后面的剧情路飞已经快要接近他的梦想了,成为"海贼王",那就是完结的时候了吧。

我们今天主要讲的是链表,那大家知道草帽海贼团中的人有谁呢,那这个草帽海贼团的人员关系跟我们今天要学习的链表有什么关系呢?

我们应该知道草帽海贼团人员总有一个入团顺序,入团顺序分别为 路飞 --> 索隆 --> 乌索普 --> 山治 --> 娜美 --> 乔巴 --> 罗宾 --> 弗兰奇 --> 布鲁克 --> 甚平。他们之间本无任何联系可言,只因最终都加入草帽海贼团中,他们已经有关系牵绊,这就像链表一样,他们通过路飞这个头结点来连接每一个结点形成一个草帽海贼团的链表,我们可以看下下面画的链表图(头像来自网络)。

只要掌握了单链表的话,后续的一些题目都可以正常理解了,下面这道题也是让你设计出一个链表,可以设计单链表或者双链表。下面是使用单链表实现方式。
代码实现:
package com.ygt.day4;/*** 707. 设计链表* https://leetcode.cn/problems/design-linked-list/description/* 你可以选择使用单链表或者双链表,设计并实现自己的链表。* 单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。* 如果是双向链表,则还需要属性 prev 以指示链表中的上一个节点。假设链表中的所有节点下标从 0 开始。* 实现 MyLinkedList 类:* MyLinkedList() 初始化 MyLinkedList 对象。* int get(int index) 获取链表中下标为 index 的节点的值。如果下标无效,则返回 -1 。* void addAtHead(int val) 将一个值为 val 的节点插入到链表中第一个元素之前。在插入完成后,新节点会成为链表的第一个节点。* void addAtTail(int val) 将一个值为 val 的节点追加到链表中作为链表的最后一个元素。* void addAtIndex(int index, int val) 将一个值为 val 的节点插入到链表中下标为 index 的节点之前。如果 index 等于链表的长度,那么该节点会被追加到链表的末尾。如果 index 比长度更大,该节点将 不会插入 到链表中。* void deleteAtIndex(int index) 如果下标有效,则删除链表中下标为 index 的节点。* 输入* ["MyLinkedList", "addAtHead", "addAtTail", "addAtIndex", "get", "deleteAtIndex", "get"]* [[], [1], [3], [1, 2], [1], [1], [1]]* 输出* [null, null, null, null, 2, null, 3]* 解释* MyLinkedList myLinkedList = new MyLinkedList();* myLinkedList.addAtHead(1);* myLinkedList.addAtTail(3);* myLinkedList.addAtIndex(1, 2); // 链表变为 1->2->3* myLinkedList.get(1); // 返回 2* myLinkedList.deleteAtIndex(1); // 现在,链表变为 1->3* myLinkedList.get(1); // 返回 3* @author ygt* @since 2024/8/14*/
public class MyLinkedList {/*单链表:一个单链表中可能会存在多个结点,其每个结点由两部分构成:- `val`域:数据域,用来存储元素数据;- `next`域:存放结点的直接后继的地址(位置)的指针域,用于指向下一结点;- 当链表后续无数据时,一般来说都是最后一个节点指针域指向null代表单链表的结束。这里就简单构造下单链表下面的方法也是常见的链表的使用方法*/// 既然要有结点,那么先创建一个内部结点类class Node{// - `val`域:数据域,用来存储元素数据;int val;// - `next`域:存放结点的直接后继的地址(位置)的指针域,用于指向下一结点;Node next;// 构造方法public Node(int val) {this.val = val;}public Node(int val, Node next) {this.val = val;this.next = next;}}// 在链表中,需要一些必要的属性信息// 头结点Node head;// 链表大小int size;// 下面开始编写方法public MyLinkedList() {// 初始化类size = 0;// 初始化时可以有虚拟头结点和普通头结点的方法。// 虚拟头结点是额外增加一个没有值的结点在链表头部,但是链表大小不加一,在一些算法题目很实用。// 普通头结点,也就是在原来链表上进行操作,区别在于,创建第一个结点时,普通头结点就是第一个结点,// 而虚拟头结点就是原本第一个结点,而创建第一个结点是虚拟头结点的下一个结点。// 下面使用虚拟头结点方法head = new Node(-1);}// 这是获取方法,根据索引取出链表的位置。public int get(int index) {// 需要注意如果包含了虚拟头结点// 临界值判断if(index < 0 || index >= size) {return -1;}// 查询链表指定位置的元素 是需要遍历链表即遍历每个元素// 从索引0处开始遍历,从虚拟头结点的下一个结点的元素开始遍历 。// 如 虚拟头结点 --> 0 --> 1 --> 2 现在要查找index为1的位置,即 1的结点的元素。// 1. 从虚拟头结点的下一个结点开始 即真正索引为0处。Node curNode = head.next; // 即当前为0// 2. 开始遍历链表,直到找到index的位置。 现在需要查找到index为1的位置for (int i = 0; i < index; i++) {// 每次循环,都需要将当前的结点指向下一个结点,直到找到index位置。curNode = curNode.next; // 即循环一次就可以找到 1结点的位置了。}// 最终获得到curNode.val就是我们想要获取到的元素。return curNode.val;}// 头插法public void addAtHead(int val) {// 例如: 虚拟 --> 1,头插一个0的数据, 所以为 虚拟 --> 0 --> 1// 新建一个结点接收当前数据, 并指向虚拟结点的下一个结点位置。// 即 0 --> 1 temp 结点指向 1结点。Node temp = new Node(val, head.next);// 然后虚拟结点需要指向当前的temp结点。后续的结点无需操作。head.next = temp;// 可以简写一步为:// head.next = new Node(val, head.next);// 链表的长度 + 1size++;}// 尾插法public void addAtTail(int val) {addAtIndex(size, val);}// 任意位置插入public void addAtIndex(int index, int val) {// 检验位置的合法性: 如果指定的索引位置不符合要求,抛出异常// 切记,index是可以取到size和0的位置,即在链表的尾部添加一个元素或者头部添加一个元素if (index < 0 || index > size) {return ;}// 如果是索引是0,我们可以直接使用头插法if (index == 0) {addAtHead(val);return;}// 如果索引是0之后的数据,需要确定的结点是待插入位置的结点位置// 如: 原结点为:虚拟结点 --> 0 --> 2 三个结点(0, 1, 2),现在需要插入位置为1处,所以需要找到1前面的一个数即0的位置// 而我们有个虚拟结点,所以需要循环的次数就是index次即 for(int i = 0; i < index; i ++) 找到0处的结点,// 然后0.next = 当前带插入的数据temp, 当前待插入的数据temp.next = 2的结点// 最终结点为:虚拟结点 --> 0 --> 1 --> 2// 1. 确定带插入新元素结点之前的那个结点是谁。// 创建一个Node结点prev,初始化的时候指向虚拟头结点head。虚拟节点在开始的时候指向的是0这个索引位置的元素它之前的那个节点。Node prev = head;// 循环确定处真正需要待插入位置的结点之前的那个结点是谁。for (int i = 0; i < index; i++) {// 从0开始遍历,将prev的下一个节点prev.next指向prev,即prev向后移动,直到找到待插入节点的前一个节点的位置。prev = prev.next;}// 2. 确定好位置后,就跟之前的插入头结点的方式一样,// 新建一个结点接收当前数据, 并指向当前确定的prev结点的下一个结点位置。// temp 结点指向 2结点。即 1 --> 2Node temp = new Node(val, prev.next);// 然后当前确定的prev结点需要指向当前的temp结点。 即 0 --> 1prev.next = temp;// 可以简写一步为:// prev.next = new Node(val, prev.next);// 最后,链表的长度需要 + 1size++;}public void deleteAtIndex(int index) {// 需要先校验需要删除的位置是否存在。if (index < 0 || index >= size) {return;}// 删除的逻辑,其实和我们的插入元素的逻辑一般,// 如: 原结点为:虚拟结点 --> 0 --> 1 --> 2 四个结点(0, 1, 2, 3),现在需要删除位置为1处,所以需要找到1前面的一个数即0的位置// 而我们有个虚拟结点,所以需要循环的次数就是index次即 for(int i = 0; i < index; i ++) 找到0处的结点,// 然后0.next = 2, 将0结点的next域指向2的结点就行了,1这个结点就没有人去指向,就被删除了// 最终结点为:虚拟结点 --> 0 --> 2// 1. 确定带删除元素结点之前的那个结点是谁。// 创建一个Node结点prev,初始化的时候指向虚拟头结点head。虚拟节点在开始的时候指向的是0这个索引位置的元素它之前的那个节点。Node pre = head;// 循环遍历,找到待删除元素结点的前一个节点位置for (int i = 0; i <= index - 1; i++) {pre = pre.next;}// 2. 确定好位置后,可以得到待删除元素的结点Node delNode = pre.next; // 得到1结点。// 将待删除元素结点的前一个结点的next指向待删除元素结点的next结点位置上。即0 --> 2 0结点去指向2结点pre.next = delNode.next;// 最后,链表的长度需要 - 1size--;}public static void main(String[] args) {MyLinkedList myLinkedList = new MyLinkedList();myLinkedList.addAtHead(4);System.out.println(myLinkedList.get(1));myLinkedList.addAtHead(1);myLinkedList.addAtHead(5);myLinkedList.deleteAtIndex(3);myLinkedList.addAtHead(7);System.out.println(myLinkedList.get(3));System.out.println(myLinkedList.get(3));System.out.println(myLinkedList.get(3));myLinkedList.addAtHead(1);myLinkedList.deleteAtIndex(4);}
}
删除链表中的节点
删除链表中的节点 📍
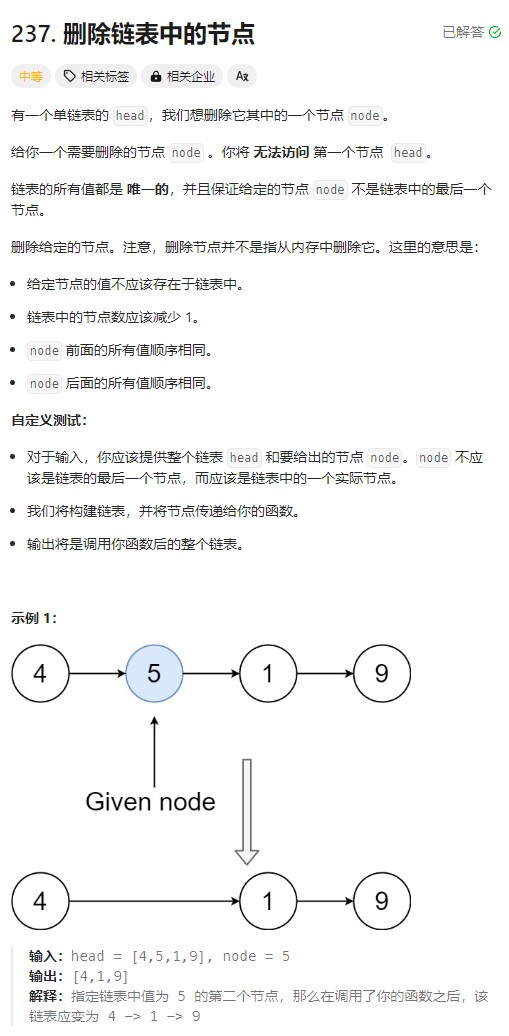
这道题,有点抽象,因为平时操作链表的话,都是头结点去操作,无论查找、删除什么的,都是从头结点出发,而这道题呢,无法获取到head,也就是无法获取到前一个结点,并且题目保证给定的节点 node 不是链表中的最后一个节点。,那么这道题思路是这样的:将自己包装成下一个结点就可以很简单写出来了,当前结点的值替换为下一个结点的值。
代码实现:
package com.ygt.day4;/*** 237. 删除链表中的节点* https://leetcode.cn/problems/delete-node-in-a-linked-list/description/* 有一个单链表的 head,我们想删除它其中的一个节点 node。* 给你一个需要删除的节点 node 。你将 无法访问 第一个节点 head。* 链表的所有值都是 唯一的,并且保证给定的节点 node 不是链表中的最后一个节点。* 删除给定的节点。注意,删除节点并不是指从内存中删除它。这里的意思是:* 给定节点的值不应该存在于链表中。* 链表中的节点数应该减少 1。* node 前面的所有值顺序相同。* node 后面的所有值顺序相同。* 自定义测试:* 对于输入,你应该提供整个链表 head 和要给出的节点 node。node 不应该是链表的最后一个节点,而应该是链表中的一个实际节点。* 我们将构建链表,并将节点传递给你的函数。* 输出将是调用你函数后的整个链表。* 输入:head = [4,5,1,9], node = 5* 输出:[4,1,9]* 解释:指定链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9** @author ygt* @since 2024/8/14*/
public class DeleteNode {public static void main(String[] args) {ListNode node4 = new ListNode(9);ListNode node3 = new ListNode(1, node4);ListNode node2 = new ListNode(5, node3);ListNode node = new ListNode(4, node2);ListNode.print(node);new DeleteNode().deleteNode(node3);System.out.println();ListNode.print(node);}public void deleteNode(ListNode node) {// 因为无法获取到head,也就是无法获取到前一个结点,并且题目保证给定的节点 node 不是链表中的最后一个节点。// 那么这道题思路是这样的:将自己包装成下一个结点 就可以很简单写出来了// 当前结点的值替换为下一个结点的值node.val = node.next.val;// 然后当前结点next指针直接指向后一个结点node.next = node.next.next;// 搞定!!}
}
反转链表
反转链表 📍
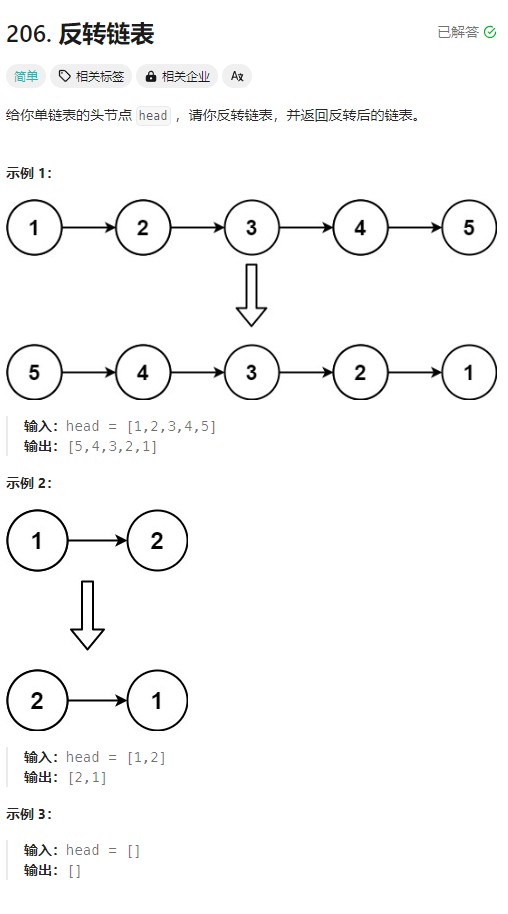
对于这道题的讲解呢,有两种方法:
- 遍历反转单链表;
- 递归反转单链表。
这里就只实现遍历反转单链表方式,后续如果学习到了递归或者现在就会,就可以直接实现递归方式。
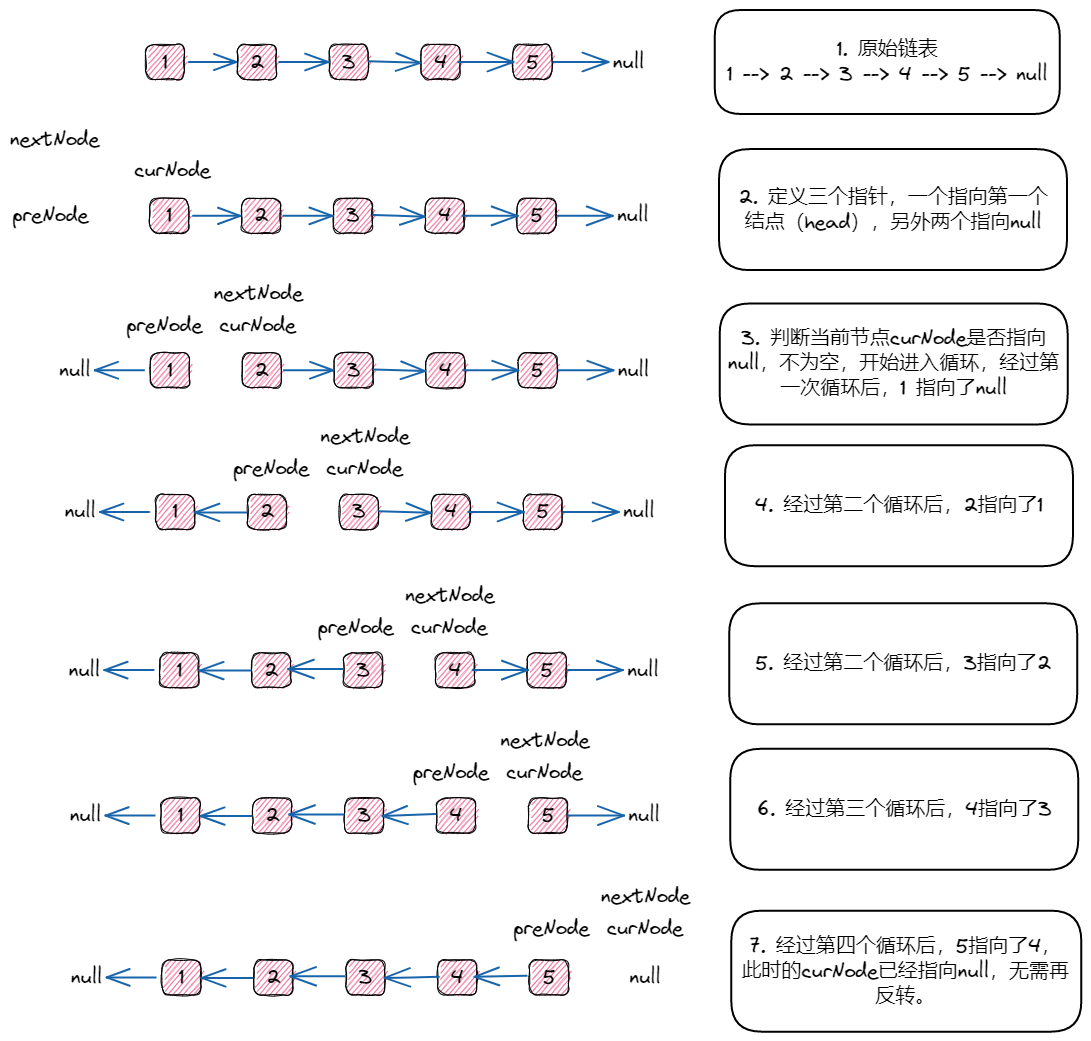
主要步骤:
- 创建两个指针,curNode指针保存当前的head节点数据,preNode节点指针指向null;
- 并循环判断当前节点是否为null;
- 如果为空,就反转结束,退出循环;
- 如果不为空,就进行循环获取当前的节点的下一个节点,并将当前节点的next指针指向下一个节点;
- 最终完成链表的反转。
看一下图解:
动图:

如果自己代码要运行的话,得先有个结点类:
package com.ygt.day4;public class ListNode {int val;public ListNode next;ListNode() {}public ListNode(int val) {this.val = val;}public ListNode(int val, ListNode next) {this.val = val;this.next = next;}// 打印public static void print(ListNode node) {ListNode cur = node;if (cur != null) {System.out.print(cur.val + " --> ");ListNode next = cur.next;print(next);}else {System.out.print("null");}}
}
代码实现:
package com.ygt.day4;/*** 206. 反转链表* https://leetcode.cn/problems/reverse-linked-list/description/* 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。* 输入:head = [1,2,3,4,5]* 输出:[5,4,3,2,1]* @author ygt* @since 2024/8/14*/
public class ReverseList {public static void main(String[] args) {ListNode node5 = new ListNode(5);ListNode node4 = new ListNode(4, node5);ListNode node3 = new ListNode(3, node4);ListNode node2 = new ListNode(2, node3);ListNode node = new ListNode(1, node2);// 打印查看当前效果ListNode.print(node);ListNode listNode = new ReverseList().reverseList(node);System.out.println();// 打印查看当前效果ListNode.print(listNode);}// 遍历反转单链表public ListNode reverseList(ListNode head) {/*这道题的主要思路,实现关键也是双指针的应用:1. 创建两个指针,curNode指针保存当前的head节点数据,preNode节点指针指向null;2. 并循环判断当前节点是否为null;3. 如果为空,就反转结束,退出循环;4. 如果不为空,就进行循环获取当前的节点的下一个节点,并将当前节点的next指针指向下一个节点;5. 最终完成链表的反转。*/// 通过双指针迭代法, preNode指针执行null,curNode执行head节点,在判断curNode还未为null时,一直迭代遍历,// 不断指针往前移动,并在移动过程中,curNode的next指针指向preNode代表反转。// 前结点为nullListNode preNode = null;// 当前的结点ListNode curNode = head;// 增加一个保存下一个结点的结点指针ListNode nextNode = null;// 判断当前结点是否为null,只要还没指向null,一直遍历,当前结点指针往前移while(curNode != null) {// 获取当前结点的next,避免反转后找不到,并在最后赋值为curNode,实现结点指针一直往前移动nextNode = curNode.next;// 将当前的结点的next指针指向preNode,相当于反转curNode.next = preNode;// 重置双指针操作。// 赋值前结点为当前节点preNode = curNode;// 最后赋值当前的节点为next结点curNode = nextNode;}// 最后返回前一个结点,即原链表的最后一个结点,即5return preNode;}
}
删除排序链表中的重复元素
删除排序链表中的重复元素📍
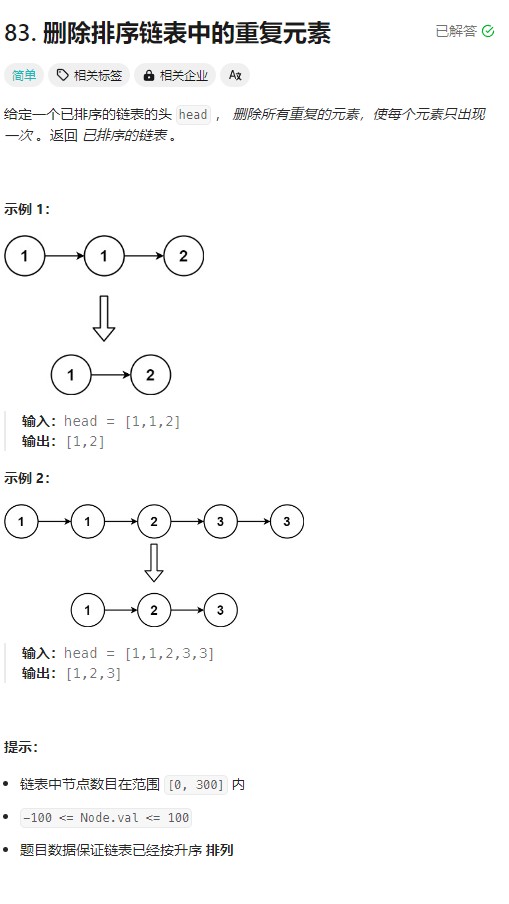
这道题的解题思路:
1. 使用指针 curNode指向当前head结点;2. 通过判断 curNode的next是否不为空;3. 不为空,就需要判断 curNode 和 curNode.next 两者的值是否相同,相同就得移除,不同就后移即可。
代码实现:
package com.ygt.day4;/*** 83. 删除排序链表中的重复元素* https://leetcode.cn/problems/remove-duplicates-from-sorted-list/description/* 给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。* 输入:head = [1,1,2,3,3]* 输出:[1,2,3]* @author ygt* @since 2024/8/14*/
public class DeleteDuplicates {public static void main(String[] args) {ListNode node5 = new ListNode(3);ListNode node4 = new ListNode(3, node5);ListNode node3 = new ListNode(2, node4);ListNode node2 = new ListNode(1, node3);ListNode node = new ListNode(1, node2);// 打印查看当前效果ListNode.print(node);ListNode listNode = new DeleteDuplicates().deleteDuplicates(node);System.out.println();// 打印查看当前效果ListNode.print(listNode);}public ListNode deleteDuplicates(ListNode head) {if(head == null || head.next == null) {return head;}/*注意,这道题链表有序的,完全可以使用一次遍历就删除重复元素,主要思路:1. 使用指针 curNode指向当前head结点;2. 通过判断 curNode的next是否不为空;3. 不为空,就需要判断 curNode 和 curNode.next 两者的值是否相同,相同就得移除;不同就后移即可。*/ListNode curNode = head;while (curNode.next != null) {if (curNode.val == curNode.next.val) {curNode.next = curNode.next.next;} else {curNode = curNode.next;}}return head;}
}
小结算法
今天的算法还是相对比较简单,很好刷,认真思考下,就可以完成的,但是前提得要有链表的基础。

明日内容
基础面试题
下面的题目的答案是基于自己的理解和思考去编写出来的,也希望大家如果看到了,可以根据自己的理解去转换为自己的答案。
当然很多思考也有参考别人的成分,但是自己能讲述出来就是最棒的。
这里有一篇阿里的mysql面试题

暂时还没时间刷,决定明天抽一天时间来刷视频吧,毕竟后续的内容还是有点难度,必须得理解理解,像mvcc这个也是面试mysql的难点之一。
12. 事务的四大特性和隔离级别
事务:
是数据库从一种一致性状态到另一种一致性的状态,即事务的操作,要么都执行,要么都不执行。比如事务是将一组业务操作中的多条SQL语句当做一个整体,那么这个多条语句要么都成功执行,要么都执行失败。而这数据库引擎中,InnoDB是支持事务,而MyIASM就不支持啦。
- 原子性(atomicity): 事务是最小的执行单位,要么全成功,要么全失败。
- 一致性(consistency): 事务开始和结束后,数据库的完整性不会被破坏。
- 隔离性(isolation): 事务的执行是相互隔离的,不同事务之间互不影响,四种隔离级别为RU(读未提交)、RC(读已提交)、RR(可重复读)、SERIALIZABLE (串行化)。
- 持久性(durability): 事务提交后,对数据的修改是永久性的,即使系统故障也不会丢失。
而这ACID主要是由什么保证呢?
- A原子性是由undo log 日志保证的,它记录了需要回滚的日志信息,事务回滚撤销时就会执行已经成功的SQL语句
- C一致性是由其他三大特性保证,并且程序代码要保证业务的一致性
- I隔离性是由MVCC保证
- D持久性是由内存+redo log保证,mysql修改数据的同时在内存和redo log日志中记录这次操作,如果数据库宕机的话,就可以从redo log中恢复。
隔离级别:
-
read-uncommitted读取未提交:最低的隔离级别,读取尚未的提交的数据,也被为脏读,它可能会发生就是脏读现象和不可重复读和幻读现象。
-
read-committed读已提交:可以读取并发事务中已经提交的数据,可以有效的阻止脏读,但是每次读取的值发生了改变,所以不可重复读和幻读仍有可能发生。
-
repeatable-read可重复读:mysql的默认隔离级别,对同一字段的读取多次结果是一致的,可以阻止脏读和不可重复读,但是幻读仍会发生。那幻读就是本来我读取的只有一行的数据,此时再次读取可能多了一行,此时就是幻读了。
-
serializable可串行化:最高的隔离级别,可以有效的解决脏读、不可重复读、幻读现象。但是效率会比较低。
13. redo 和 undo是什么
redo log:重做日志 ,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。
主要作用:InnoDB引擎的事务采用了WAL技术(Write-Ahead Logging ),这种技术的思想就是先写日志,再写磁盘,只有日志写入成功,才算事务提交成功,这里的日志就是redo log。当发生宕机且数据未刷到磁盘的时候,可以通过redo log来恢复,保证持久性。
undo log:回滚日志 ,回滚行记录到某个特定版本,用来保证事务的原子性、一致性。
主要作用:主要用于事务的回滚(undo log 记录的是每个修改操作的逆操作)和一致性非锁定读(undo log回滚行记录到某种特定的版本—MVCC,即多版本并发控制)。
14. redo log详解以及如何刷盘
redo log由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
redo log的整体流程:
- 先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝
- 生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值
- 当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加写的方式
- 定期将内存中修改的数据刷新到磁盘中
redo log的刷盘策略:
redo log的写入并不是直接写入磁盘的,而是先写入到文件系统缓存中,最后根据刷盘策略写入到磁盘的redo log file中。
InnoDB给出 innodb_flush_log_at_trx_commit 参数,该参数控制 commit提交事务时,如何将 redo log buffer 中的日志刷新到 redo log file 中。它支持三种策略:
设置为0:每次事务提交时不进行刷盘操作,由后台线程masterThread每隔1s写入文件系统缓存中并刷到磁盘中;设置为1:每次事务提交时都进行写入文件系统缓存中并刷到磁盘中(默认);设置为2:每次事务提交时都只把 redo log buffer 内容写入文件系统缓存中,不进行同步。由os自己决定什么时候同步到磁盘文件。
15.Innodb是如何实现事务的
Innodb通过Buffer Pool,LogBuffer,Redo Log,Undo Log来实现事务,以一个update语句为例:
- Innodb在收到一个update语句后,会先根据条件找到数据所在的页,并将该页缓存在Buffer Pool中;
- 执行update语句,修改Buffer Pool中的数据,也就是内存中的数据;
- 针对update语句生成一个RedoLog对象,并存入LogBuffer中;
- 针对update语句生成undolog日志,用于事务回滚;
- 如果事务提交,那么则把RedoLog对象进行持久化,后续还有其他机制将Buffer Pool中所修改的数据页持久化到磁盘中;
- 如果事务回滚,则利用undolog日志进行回滚。
16. MVCC
所谓的MVCC,是一种数据库的并发控制机制,它的目标是在保证数据一致性和隔离性的同时,提供更好的并发性能。主要就是生成一个ReadView,通过ReadView找到符合条件的记录版本(历史版本由undo日志构建)。查询语句只能读到在生成ReadView之前已提交事务所做的更改,在生成ReadView之前未提交的事务或者之后才开启的事务所做的更改是看不到的。而写操作生成新的版本并更新到数据行中,读记录的历史版本和改动记录的最新版本本身并不冲突,也就是采用MVCC时,读-写操作并不冲突。
MVCC主要就是依赖于记录行中的隐藏字段以及undo log版本链和readView,
- trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
- roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到
undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。 - undo log版本链:每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个
roll_pointer属性,连接形成一个链表; - readView:快照读的读视图,当事务启动时,会生成数据库系统当前的一个快照,InnoDB为每个事务构造了一个数组,用来记录并维护系统当前活跃事务的ID。主要包括:
-
creator_trx_id,创建这个 Read View 的事务 ID。 -
m_ids,表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。 -
min_trx_id,活跃的事务中最小的事务 ID。 -
max_trx_id,表示生成ReadView时系统中应该分配给下一个事务的id值。max_trx_id是系统最大的事务id值,这里要注意是系统中的事务id,需要区别于正在活跃的事务ID。
-
具体的流程:
-
首先获取事务自己的版本号,也就是事务 ID;
-
生成 ReadView;
-
查询得到的数据,然后与 ReadView 中的事务版本号进行比较;
-
如果不符合 ReadView 规则,就需要从 Undo Log 中获取历史快照;
-
最后返回符合规则的数据。
17. MySQL 中有哪几种锁?
在MySQL中,常见的锁包括以下几种:
- 共享锁(Shared Lock):也称为读锁(Read Lock),用于允许多个事务同时读取同一资源,但禁止并发写入操作。其他事务可以获取共享锁,但无法获取排他锁。
- 排他锁(Exclusive Lock):也称为写锁(Write Lock),用于独占地锁定资源,阻止其他事务的读写操作。其他事务无法获取共享锁或排他锁,直到持有排他锁的事务释放锁。
- 表级锁(Table-level Locking):在事务操作中对整个表进行加锁。当一个事务对表进行写入操作时,其他事务无法对该表进行任何读写操作。表级锁通常是针对特定的DDL操作或备份操作。
- 行级锁(Row-level Locking):也称为记录锁(Record Locking),在事务操作中对数据行进行加锁。行级锁可以控制并发读写操作,不同事务之间可以并发地访问不同行的数据。MySQL的InnoDB存储引擎默认使用行级锁。
- 页锁:在
页的粒度上进行锁定,页锁的开销介于表锁和行锁之间,会出现死锁。锁定粒度介于表锁和行锁之间,并发度一般。 - 意向锁 (intention lock):它允许行级锁与表级锁共存,而意向锁就是其中的一种
表锁。 - 记录锁(Record Lock):用于行级锁的一种形式,锁定数据库中的一个记录(行)以保证事务的隔离性和完整性。
- 间隙锁(Gap Lock):用于行级锁的一种形式,锁定两个记录之间的间隙。它可以防止其他事务在该间隙中插入新记录,从而保证数据的一致性。
- 临键锁(Next-Key Locks): 临键锁是记录锁和间隙锁的结合,锁定的是一个范围,并且包括记录本身。
需要注意的是,MySQL的不同存储引擎对锁的支持和实现方式可能有所不同。例如,MyISAM存储引擎使用表级锁来控制并发访问,而InnoDB存储引擎则支持更细粒度的行级锁,提供更好的并发性能和数据一致性。
算法
在有链表的基础上进行链表的算法题,可以事半功倍。

需要有链表以及双指针的基础。
- 反转链表 II 📍
- 删除排序链表中的重复元素 II 📍
- 删除链表的倒数第 N 个结点 📍
- 移除链表元素 📍
🌸 完结
最后,相关算法的代码也上传到gitee或者github上了。
乘风破浪会有时 直挂云帆济沧海
希望从明天开始,一起加油努力吧,成就更好的自己。
🥂 虽然这篇文章完结了,但是我还在,永不完结。我会努力保持写文章。来日方长,何惧车遥马慢!✨✨✨
💟 感谢各位看到这里!愿你韶华不负,青春无悔!让我们一起加油吧! 🌼🌼🌼
💖 学到这里,今天的世界打烊了,晚安!🌙🌙🌙
相关文章:

重启人生计划-积蓄星火
🥳🥳🥳 茫茫人海千千万万,感谢这一刻你看到了我的文章,感谢观赏,大家好呀,我是最爱吃鱼罐头,大家可以叫鱼罐头呦~🥳🥳🥳 如果你觉得这个【重启人生…...

2024.08.11 校招 实习 内推 面经
地/球🌍 : neituijunsir 交* 流*裙 ,内推/实习/校招汇总表格 1、自动驾驶一周资讯 - 比亚迪将采购华为智驾系统,用于方程豹新款越野车;英特尔发布第一代车载独立显卡;黑芝麻智能上市首日破发大跌 自动…...
)
LCA(Lowest Common Ancestor)
LCA(Lowest Common Ancestor) 定义 在树上取两点 x,yx,y,他们的 LCA 为距离他们最近的公共祖先。 本章主要讲的是倍增求 LCA。 暴力求取 从 xx 开始向上移动到根结点,并标记沿途结点。从 yy 开始向上移动到根结点,…...

张钹院士:大模型时代的企业AI发展趋势
在当今技术迅速发展的时代,生成式人工智能与大模型正成为推动产业变革的重要力量。随着AI技术的不断成熟与普及,它的应用已从个人领域扩展至企业层面,广泛覆盖各行各业。 那么,新技术究竟会给产业带来哪些积极地影响?…...

php连接sphinx的长连接事宜以及sphinx的排除查询以及关于sphinx里使用SetSelect进行复杂的条件过滤或复杂查询
一、php连接sphinx的长连接事宜以及sphinx的排除查询 在使用php连接sphinx时,默认的sphinx连接非长连接,于是在想php连接sphinx能否进行一些优化 publish:January 9, 2018 -Tuesday: 方法:public bool SphinxClient::open ( void ) — 建立到…...

抓包分析排查利器TCPdump
tcpdump命令介绍与常规用法。 基础命令介绍 # 固定语法 -i 指定网卡名称 -nn 显示IP地址 -w 指定输出的文件名称 tcpdump -i eth0 -nn -w test.cap-nn 不把主机的网络地址与协议转换成名字 -w 把数据包数据写入指定的文件 and 连接参数 host 指明主机 port 指明端口 src 源IP…...

八种排序算法的复杂度(C语言)
归并排序(递归与非递归实现,C语言)-CSDN博客 快速排序(三种方法,非递归快排,C语言)-CSDN博客 堆排序(C语言)-CSDN博客 选择排序(C语言)以及选择排序优化-CSDN博客 冒泡排序(C语言)-CSDN博客 直接插入排序(C语言)-CSDN博客 希尔排序( 缩小增量排序 )(C语言)-CSDN博客 计数…...

docker compose部署rabbitmq集群,并使用haproxy负载均衡
一、创建rabbitmq的data目录 mkdir data mkdir data/rabbit1 mkdir data/rabbit2 mkdir data/rabbit3 二、创建.erlang.cookie文件(集群cookie用) echo "secretcookie" > .erlang.cookie 三、创建haproxy.cfg配置文件 global log stdout fo…...

git强制推送代码教程
git强制推送代码教程 首先说明情况,我的代码remote了两个git库,现在想要推送到其中一个,但是版本不对,被拒绝,因此下面将进行强制推送 首先检查远程库都有哪些 git remote -v2. 检查当前的分支 git branch当前分支前…...
)
windows C++-高级并发和异步(三)
深入了解 winrt::resume_foreground(下) 调用 winrt::resume_foreground 时会始终先排队,然后展开堆栈。 也可选择设置恢复优先级。 winrt::fire_and_forget RunAsync(DispatcherQueue queue) {...co_await winrt::resume_foreground(queue, DispatcherQueuePrior…...
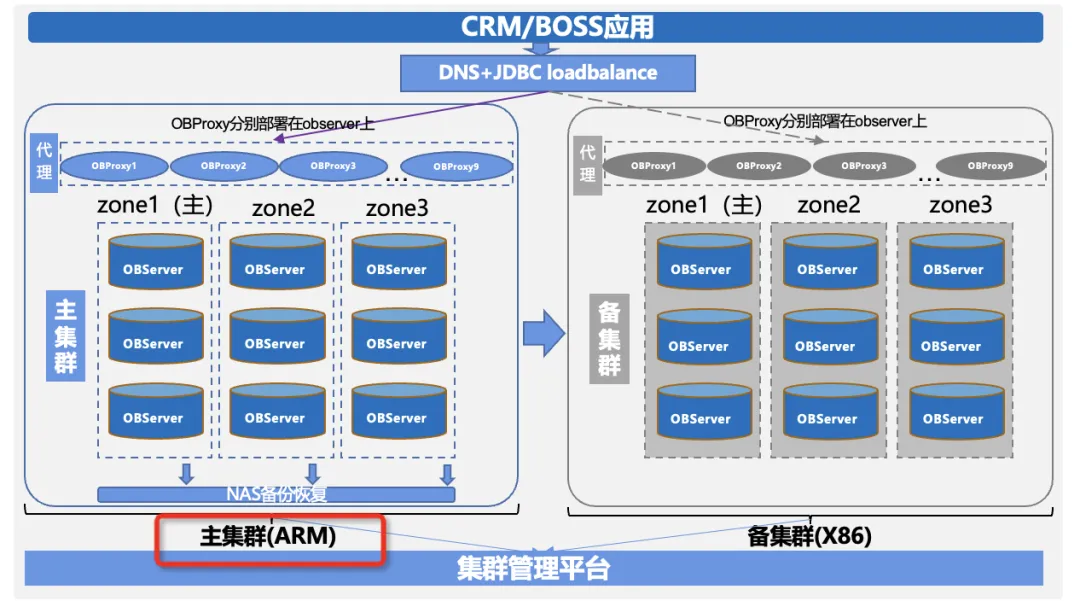
河北移动:核心系统数据库成功完成整体迁移 ,实现全栈国产|OceanBase案例
本文作者:移动通信集团河北有限公司架构规划专家,房瑞 项目背景: 中国移动通信集团河北有限公司一直在积极响应国家及集团的号召,以磐舟&磐基云原生为底座,结合国产浏览器、中间件、数据库、操作系统和服务器等&a…...

ZKRollup
目录 ZKRollup 基本概念 运作原理 特点与优势 应用场景 典型项目 ZKRollup ZKRollup,全称为Zero-Knowledge Rollup,是一种基于零知识证明的二层扩容方案(Layer 2)。它旨在通过提高交易处理效率和降低交易成本来扩展区块链网络的能力,尤其是在以太坊等区块链平台上得…...

letcode 分类练习 树的遍历
letcode 分类练习 树的遍历 树的构建递归遍历前序遍历中序遍历后序遍历 迭代遍历前序遍历中序遍历后序遍历 层序遍历层序遍历可以解决的问题107. 二叉树的层序遍历 II199. 二叉树的右视图637. 二叉树的层平均值429. N 叉树的层序遍历515.在每个树行中找最大值116.填充每个节点的…...

redisssion分布式锁
分布式锁的问题 基于setnx的分布式锁实现起来并不复杂,不过却存在一些问题。 锁误删问题 第一个问题就是锁误删问题,目前释放锁的操作是基于DEL,但是在极端情况下会出现问题。 例如,有线程1获取锁成功,并且执行完任…...

嘎嘎嘎拿到去年想要的包
一年多了 继续,把项目收尾吧 好好学前端,外企!react!从0开始,紧迫!加油!...
前奏编曲:如何编写二段式前奏
选好音源 Pianoteq 6 STAGE比较明亮些,适合做前奏的音源 确定和弦进行 比如4536251,每个小节2和弦,每个小节的和弦弹一下 优化和弦进行衔接和织体 二段式不用对和弦进行就近解决的处理,因为前奏前后要形成对比。 前半部分往…...

征服云端:Kubernetes如何让微服务与云原生技术如虎添翼
引言 在这个数字化转型的时代,微服务架构已经成为构建现代应用程序的首选方式。它不仅提高了开发效率,还增强了系统的可扩展性和灵活性。而随着云计算技术的迅猛发展,云原生的概念逐渐深入人心,它代表了一种全新的软件开发方法论…...

开源AI智能名片系统与高级机器学习技术的融合应用:重塑商务交流的未来
摘要:在数字化浪潮的推动下,人工智能(AI)技术,尤其是机器学习领域的快速发展,正深刻改变着各行各业的面貌。开源AI智能名片系统作为这一变革的先锋,通过集成并优化多种高级机器学习技术…...

Java中synchronized的偏向锁是如何减少锁开销的
偏向锁(Biased Locking)是一种优化 Java synchronized 锁的机制,旨在减少在无竞争情况下的锁开销。它通过将锁偏向于单个线程来优化锁的性能。以下是偏向锁减少锁开销的具体方式和原理: 偏向锁的工作原理 锁的初始状态: 当一个对…...

react18 + ts 使用video.js 直播.m3u8格式的视频流
一、安装依赖 我使用的video.js版本是8.17.3,从 Video.js 7.x 开始,HLS 支持被内置到了 Video.js 中所以不需要安装其他依赖 npm i video.js 二、创建VideoPlayer组件 import React, { useEffect, useRef } from react import videojs from video.js …...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...