Linux 中的同步机制
代码基于:Kernel 6.6
临界资源:指哪些在同一时刻只允许被一个线程访问的软件或硬件资源。这种资源的特点是,如果有线程正在使用,其他进程必须等待直到该线程释放资源。
临界区:指在每个线程中访问临界资源的那段代码。由于临界资源需要互斥访问,因此每个线程的临界区代码在执行时需要确保没有其他现成同事访问该资源。
1. 原子操作(atomic)
原子操作是指不能再进一步分割的操作,是指单个处理器执行期间,一组操作被视为不可分割的整理,要么全部完成,要么全部不执行。这些操作不会被其他线程或中断打断,因此保证数据的一致性和完整性。
原子操作特点:
- 封装性:操作内部的细节外部不可见,保证了操作的可见性和顺序一致性;
- 隔离性:在同一时间点内,只有单个线程能够执行原子操作,避免了竞态条件;
- 原子性:在并发环境中,整个操作表现为不可分割的单位;
include/linux/types.htypedef struct {int counter;
} atomic_t;#define ATOMIC_INIT(i) { (i) } //atomic_t 变量初始化#ifdef CONFIG_64BIT
typedef struct {s64 counter;
} atomic64_t;
#endifinclude/asm-generic/atomic.h#define arch_atomic_read(v) READ_ONCE((v)->counter)
#define arch_atomic_set(v, i) WRITE_ONCE(((v)->counter), (i))一般会使用atomic_read和atomic_set接口对atomic 变量进行读写,不同使用场景这两个函数的实现也不同,例如使能 CONFIG_ARCH_ATOMIC 会调用上面的 arch_atomic_read。
在 SMP 系统中,atomic_read接口调用的就是READ_ONCE(),atomic_set接口调用的就是WRITE_ONCE()函数。
2. 互斥锁(Mutex)
互斥锁是一种休眠锁,锁征用时可能存在进程的睡眠与唤醒,context 的切换带来的代价高,适用于加锁时间较长的场景。
互斥锁每次只允许一个进程进入临界区,有点类似二元信号量。也只能是互斥锁的 owner可以unlock。
与信号量相比,互斥锁的性能与扩展性都更好,因此在内核中总是会优先考虑互斥锁。
include/linux/mutex.hstruct mutex {atomic_long_t owner; //原子计数,用于指向锁持有者的 task_structraw_spinlock_t wait_lock; //自旋锁,用于 wait_list 链表的互斥
#ifdef CONFIG_MUTEX_SPIN_ON_OWNERstruct optimistic_spin_queue osq; //osq 锁
#endifstruct list_head wait_list; //链表,用于管理所有在该mutex 上睡眠的线程
#ifdef CONFIG_DEBUG_MUTEXESvoid *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
};kernel/locking/mutex.hstruct mutex_waiter {struct list_head list; //用以添加到wait_liststruct task_struct *task; //等待的线程struct ww_acquire_ctx *ww_ctx;
#ifdef CONFIG_DEBUG_MUTEXESvoid *magic;
#endif
};在使用mutex 时,有如下注意点:
- 一次只能有一个进程持有互斥锁;
- 只有锁的 owner能进行unlock 操作;
- 禁止多次解锁操作;
- 禁止递归加锁操作;
- mutex 数据结构只能通过API 进行初始化;
- mutex 数据结构禁止使用
memset或者copy来进行初始化; - 已经被持有的mutex锁,禁止被再次初始化;
- 持有mutex 锁的task 不能
exit; - 持有mutex 锁的内存区域不能被
free; - mutex 锁不允许在硬件、软件中断上下文,例如tasklets、timers 等;
2.1 mutext 初始化
include/linux/mutex.h#define mutex_init(mutex) \
do { \static struct lock_class_key __key; \\__mutex_init((mutex), #mutex, &__key); \
} while (0)kernel/locking/mutex.cvoid
__mutex_init(struct mutex *lock, const char *name, struct lock_class_key *key)
{atomic_long_set(&lock->owner, 0);raw_spin_lock_init(&lock->wait_lock);INIT_LIST_HEAD(&lock->wait_list);
#ifdef CONFIG_MUTEX_SPIN_ON_OWNERosq_lock_init(&lock->osq);
#endifdebug_mutex_init(lock, name, key);
}
EXPORT_SYMBOL(__mutex_init);调用初始化的时候,会将owner 重置,wai_lock、wait_list、osq 等都会被重置。这就是为什么强调被初始化的mutex 不能再初始化(schedule 的线程可能再也无法唤醒)。
2.2 mutex_lock()
include/linux/mutex.hextern void mutex_lock(struct mutex *lock);
该图是mutex_lock函数调用的大致流程图,从流程图中可以看出该函数大致分两步:
- 快速lock
- 慢速lock
__mutex_trylock_fast函数会调用 atomic_long_try_cmpxchg_acquire函数,true 代表锁成功。
atomic_long_try_cmpxchg_acquire函数中判断lock->owner==0表明锁未持有,将curr赋值给lock->owner标记curr 进程持有该锁,并返回true;若lock->owner !=0 表明锁被持有,则返回false 继续慢速 lock。
进入慢速路径最终调用的是__mutex_lock_common函数,该过程比较复杂,感兴趣可以查看源码。
2.3 mutex_unlock()
include/linux/mutex.hextern void mutex_unlock(struct mutex *lock);
释放锁的过程比较简单,核心调用__mutex_unlock_slowpath函数,当 wait_list 不为空时会取出第一个mutex_waiter,并调用wake_q_add将该waiter 的task 添加到唤醒队列,最终调用wake_up_q函数唤醒等在该锁上的线程。
参考:
https://zhuanlan.zhihu.com/p/633069533
https://www.cnblogs.com/LoyenWang/p/12826811.html
3. 信号量(semaphore)
信号量是Linux 系统常用的同步与互斥的机制。
信号量在创建时需要设置一个初始值,表示同时可以有几个任务访问该信号量保护的共享资源。当初始值为1,表示同时只能有一个任务可以访问信号量保护的共享资源,该信号量又称为二元信号量(bindary semaphore).
可以将信号量比喻成一个盒子,初始化时在盒子里放入N把钥匙,钥匙先到先得,当N把钥匙都被拿走完后,再来拿钥匙的人就需要等待了,只有等到有人将钥匙归还了,等待的人才能拿到钥匙。
inlucde/linux/semaphore.hstruct semaphore {raw_spinlock_t lock; //自旋锁,用于count值的互斥访问unsigned int count; //计数值,能同时允许访问的数量,也就是上文中的 N把钥匙struct list_head wait_list; //不能立即获取到信号量的访问者,都会加到等待队列中
};kernel/locking/semaphore.cstruct semaphore_waiter { //当 N 把钥匙被拿走,后来的进程需要等待struct list_head list; //用于添加到 wait_list中struct task_struct *task; //等待的线程bool up; //标记是否释放信号量
};3.1 信号量的初始化
inlucde/linux/semaphore.hstatic inline void sema_init(struct semaphore *sem, int val)
{static struct lock_class_key __key;*sem = (struct semaphore) __SEMAPHORE_INITIALIZER(*sem, val);lockdep_init_map(&sem->lock.dep_map, "semaphore->lock", &__key, 0);
}#define DEFINE_SEMAPHORE(_name, _n) \struct semaphore _name = __SEMAPHORE_INITIALIZER(_name, _n)信号量的初始化有两种方式,sema_init 接口需要在 CONFIG_DEBUG_LOCK_ALLOC 使能的情况下使用。
3.2 down/up
inlucde/linux/semaphore.hextern void down(struct semaphore *sem);
extern void up(struct semaphore *sem);kernel/locking/semaphore.cvoid __sched down(struct semaphore *sem)
{unsigned long flags;might_sleep();raw_spin_lock_irqsave(&sem->lock, flags);if (likely(sem->count > 0))sem->count--;else__down(sem);raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(down);void __sched up(struct semaphore *sem)
{unsigned long flags;raw_spin_lock_irqsave(&sem->lock, flags);if (likely(list_empty(&sem->wait_list)))sem->count++;else__up(sem);raw_spin_unlock_irqrestore(&sem->lock, flags);
}
EXPORT_SYMBOL(up);
down接口用于获取信号量,up用于释放信号量;- 调用
down时,如果sem->count > 0时,也就是盒子里边还有多余的锁,直接自减并返回了,当sem->count == 0时,表明盒子里边的锁被用完了,当前任务会加入信号量的等待列表中,设置进程的状态,并调用schedule_timeout来睡眠指定时间,实际上这个时间设置的无限等待,也就是只能等着被唤醒,当前任务才能继续运行; - 调用
up时,如果等待列表为空,表明没有多余的任务在等待信号量,直接将sem->count自加即可。如果等待列表非空,表明有任务正在等待信号量,那就需要对等待列表中的第一个任务(等待时间最长)进行唤醒操作,并从等待列表中将需要被唤醒的任务进行删除操作;
3.3 扩展的接口
extern int __must_check down_interruptible(struct semaphore *sem);
extern int __must_check down_killable(struct semaphore *sem);
extern int __must_check down_timeout(struct semaphore *sem, long jiffies);extern int __must_check down_trylock(struct semaphore *sem);3.3.1 down_trylock()
kernel/locking/semaphore.cint __sched down_trylock(struct semaphore *sem)
{unsigned long flags;int count;raw_spin_lock_irqsave(&sem->lock, flags);count = sem->count - 1;if (likely(count >= 0))sem->count = count;raw_spin_unlock_irqrestore(&sem->lock, flags);return (count < 0);
}
EXPORT_SYMBOL(down_trylock);down_trylock用于获取信号量且不用等待;- 返回0表示获取成功,返回1表示获取失败,返回值与
spin_trylock、mutext_trylock是相反的; - 与
mutex_trylock不同,down_trylock可以用在中断上下文,且 sem 能被任何task 或中断释放;
3.3.2 其他扩展
down_trylock 之外的其他扩展接口,最终调用的都是 ___down_common 接口,处理流程如上面的流程图。
3.4 信号量缺点
对比 Mutex 锁,Semaphore 与Mutex 在实现上有一个重大的区别:ownership.
Mutex 被持有后有一个明确的 owner,而Semaphore 并没有owner,当一个进程阻塞在某个信号量上时,它没法知道自己阻塞在哪个进程(线程)之上。
没有ownership会带来以下几个问题:
- 在保护临界区的时候,无法进行优先级反转的处理;
- 系统无法对其进行跟踪断言处理,比如死锁检测等;
- 信号量的调试变得更加麻烦;
因此,在Mutex 能满足要求的情况下,优先使用Mutex。
参考:
https://www.cnblogs.com/LoyenWang/p/12907230.html
4. 读写信号量(rwsem)
读写信号量的原理与读写锁类似,读写信号量归根到底是 “信号量”,读写锁归根到底是 “自旋锁”,而信号量与自旋锁的区别一个可以睡眠,一个只能自旋。
读写信号量原理:
- 允许多个读者同时进入临界区;
- 读者与写者不能同时进入临界区(读者与写者互斥);
- 写者与写者不能同时进入临界区(写者与写者互斥);
include/linux/rwsem.hstruct rw_semaphore {atomic_long_t count; //读写信号量的计数atomic_long_t owner; //当写者成功获取锁时,owner会指向锁的持有者
#ifdef CONFIG_RWSEM_SPIN_ON_OWNERstruct optimistic_spin_queue osq; //乐观自旋
#endifraw_spinlock_t wait_lock; //自旋锁,用于count值的互斥访问struct list_head wait_list; //不能立即获取到信号量的访问者,都会加到等待队列中...
};4.1 count
* On 64-bit architectures, the bit definitions of the count are:** Bit 0 - writer locked bit* Bit 1 - waiters present bit* Bit 2 - lock handoff bit* Bits 3-7 - reserved* Bits 8-62 - 55-bit reader count* Bit 63 - read fail bit** On 32-bit architectures, the bit definitions of the count are:** Bit 0 - writer locked bit* Bit 1 - waiters present bit* Bit 2 - lock handoff bit* Bits 3-7 - reserved* Bits 8-30 - 23-bit reader count* Bit 31 - read fail bit*/
#define RWSEM_WRITER_LOCKED (1UL << 0)
#define RWSEM_FLAG_WAITERS (1UL << 1)
#define RWSEM_FLAG_HANDOFF (1UL << 2)
#define RWSEM_FLAG_READFAIL (1UL << (BITS_PER_LONG - 1))#define RWSEM_READER_SHIFT 8
#define RWSEM_READER_BIAS (1UL << RWSEM_READER_SHIFT)
#define RWSEM_READER_MASK (~(RWSEM_READER_BIAS - 1))
#define RWSEM_WRITER_MASK RWSEM_WRITER_LOCKED
#define RWSEM_LOCK_MASK (RWSEM_WRITER_MASK|RWSEM_READER_MASK)
#define RWSEM_READ_FAILED_MASK (RWSEM_WRITER_MASK|RWSEM_FLAG_WAITERS|\RWSEM_FLAG_HANDOFF|RWSEM_FLAG_READFAIL)注意bit1:RWSEM_FLAG_WAITERS
当前持锁的如果是reader,来了一个writer,持锁失败进入等待队列,那么 RWSEM_FLAG_WAITERS 为1。此时又有一个reader 来持锁,在快速路径中根据这个判断,持锁也会失败,进入慢速路径,再根据一些条件进行判断是否可以持锁。所以,reader 已经持锁的情况下,其他的reader 也不是无条件可以马上持锁的。
另外,rwsem 在初始化的时候会将count 设为 RWSEM_UNLOCKED_VALUE:
include/linux/rwsem.h#define RWSEM_UNLOCKED_VALUE 0L4.2 owner
owner 有两个作用:
- 记录rwsem 被哪个task 持有。只有writer 持锁时,这个owner 才能正确表示持有者,而可能同时存在很多个reader,所以reader 持锁时,owner 不能正确表示持锁着,这也是锁传递不能对 reader 进行传递的原因;
- 因为task_struct 的地址是 L1_CACHE_BYTES 对齐的,所以其最低 2 位恒为0,这 2 位就可以用来描述一些状态信息。
来看下最低 2 位:
kernel/locking/rwsem.c#define RWSEM_READER_OWNED (1UL << 0)
#define RWSEM_NONSPINNABLE (1UL << 1)
#define RWSEM_OWNER_FLAGS_MASK (RWSEM_READER_OWNED | RWSEM_NONSPINNABLE)当一个writer 获得rwsem,会将task_struct 指针存入owner,在 unlock时 清除owner;
当一个reader 获得rwsem,也会将task_struct 指针存入owner,但需要将 RWSEM_READER_OWNED 标志位置1. 在unlock 的时候所有的字段将基本保持不变,所以,对于一个空闲的rwsem 或 已经有reader-owned 的rwsem,owner 的值或许包含上一次获得rwsem 的 reader 的信息;
4.3 osq(乐观自旋队列)
struct optimistic_spin_node {struct optimistic_spin_node *next, *prev;int locked; /* 1 if lock acquired */int cpu; /* encoded CPU # + 1 value */
};struct optimistic_spin_queue {/** Stores an encoded value of the CPU # of the tail node in the queue.* If the queue is empty, then it's set to OSQ_UNLOCKED_VAL.*/atomic_t tail;
};Optimistic spin queue 翻译过来为乐观自旋队列,即形成一组处于自旋状态的任务队列。
和等待队列不同,osq 中的任务都是当前正在执行的任务。osq 并没有将这些任务的 task struct 形成队列结构,而是把 per-cpu 的MSC lock 对象串联形成队列。如下图:

虽然都是自旋,但是自旋方式并不一样。Osq队列中的头部节点是持有osq锁的,只有该任务处于对rwsem的owner进行乐观自旋的状态(我们称之rwsem乐观自旋)。Osq队列中的其他节点都是自旋在自己的mcs lock上(我们称之mcs乐观自旋)。当头部的mcs lock释放掉后(结束rwsem乐观自旋),它会将mcs lock传递给下一个节点,从而让spinner队列上的任务一个个的按顺序进入rwsem的乐观自旋,从而避免了cache-line bouncing带来的性能开销。
cache-line bouncing的理解:为了以较低的成本大幅提升性能,现代CPU都有cache。cpu cache已经发展到了三级缓存结构。其中L1和L2cache为每一个核独有,L3则全部核共享。为了保证全部的核看到正确的内存数据,一个核在写入本身的L1 cache后,CPU会执行Cache一致性算法把对应的cacheline同步到其余核,这个过程并不很快。当多个cpu上频繁修改某个字段时,这个字段所在的cacheline被不停地同步到其它的核上,就像在核间弹来弹去,这个现象就叫作cache bouncing。
4.4 读写信号量初始化
4.4.1 静态初始化
include/linux/rwsem.h#define __RWSEM_INITIALIZER(name) \{ __RWSEM_COUNT_INIT(name), \.owner = ATOMIC_LONG_INIT(0), \__RWSEM_OPT_INIT(name) \.wait_lock = __RAW_SPIN_LOCK_UNLOCKED(name.wait_lock), \.wait_list = LIST_HEAD_INIT((name).wait_list), \__RWSEM_DEBUG_INIT(name) \__RWSEM_DEP_MAP_INIT(name) }#define DECLARE_RWSEM(name) \struct rw_semaphore name = __RWSEM_INITIALIZER(name)4.4.2 动态初始化
include/linux/rwsem.h#define init_rwsem(sem) \
do { \static struct lock_class_key __key; \\__init_rwsem((sem), #sem, &__key); \
} while (0)kernel/locking/rwsem.cvoid __init_rwsem(struct rw_semaphore *sem, const char *name,struct lock_class_key *key)
{atomic_long_set(&sem->count, RWSEM_UNLOCKED_VALUE); //初始化countraw_spin_lock_init(&sem->wait_lock); //初始化wait_lockINIT_LIST_HEAD(&sem->wait_list); //初始化wait_listatomic_long_set(&sem->owner, 0L); //初始化owner
#ifdef CONFIG_RWSEM_SPIN_ON_OWNERosq_lock_init(&sem->osq); //初始化osq
#endif
}
EXPORT_SYMBOL(__init_rwsem);
4.5 down_read()
4.6 up_read()
4.7 down_write()
4.7 up_write()
参考:https://zhuanlan.zhihu.com/p/553482378
5. 自旋锁(spinlock)
spinlock 是一种不可休眠锁,spinlock在持锁失败后,不会进行睡眠,而是自旋等待。
线程睡眠、唤醒时都需要进行调度,这部分线程上、下文的切换也是性能开销。而spinlock则在持锁失败后,不会进行睡眠,少了这一部分的开销。
spinlock不适合保护很大的临界区,因为在持锁后会关闭抢占或中断,如果持锁时间过长,持锁线程以及持锁未成功进行自旋线程所在cpu会出现调度不及时带来的性能问题。
另外,在软、硬中断上下文,是不允许睡眠的,所以 mutex不能在这里使用,需要使用spinlock。
5.1 自旋锁与UP、SMP 的关系
UP:Unified Processor
SMP:Symmetric Multi-Processors
根据自旋锁的逻辑,自旋锁的临界区是不能休眠的。在UP下,只有一个CPU,如果我们执行到了临界区,此时自旋锁是不可能处于加锁状态的。因为我们正在占用CPU,又没有其它的CPU,其它的临界区要么没有到来、要么已经执行过去了。所以我们是一定能获得自旋锁的,所以自旋锁对UP来说是没有意义的。但是为了在UP和SMP下代码的一致性,UP下也有自旋锁,但是自旋锁的定义就变成了空结构体,自旋锁的加锁操作就退化成了禁用抢占,自旋锁的解锁操作也就退化成了开启抢占。所以说自旋锁只适用于SMP,但是在UP下也提供了兼容操作。
5.2 自旋锁的发展
5.2.1 wild spinlock(原始自旋锁)
struct spinlock {int locked;
};void spin_lock(struct spinlock *lock)
{while (lock->locked);lock->locked = 1;
}void spin_unlock(struct spinlock *lock)
{lock->locked = 0;
}锁的持有者会将locked 置1,释放时会将locked 置0,其他不能获得 spinlock 的进程原地自旋。
wild spinlock 的实现非常简单,但这种简单的背后却掩盖着血雨腥风的竞争,一旦spinlock 被释放,哪个 CPU 的cache 先看到 locked 的值,就优先获得 spinlock,没有排队的机制,这样导致某 CPU 可能长期等锁,从而带来延迟不确定问题,甚至导致CPU 饿死。
为了改善获取lock 乱插队,ticket spinlock 出现了。
5.2.2 ticket spinlock(票号自旋锁)
struct spinlock {unsigned short owner;unsigned short next;
};ticket spinlock引入排队机制,以FIFO的顺序处理spinlock的申请,第一个CPU抢占spinlock时会先获取到spinlock,后面的CPU根据他们抢占的先后顺序来获取到spinlock,这就实现了获取spinlock的公平性。
每一个参与获取 spinlock 的CPU 的cache 都会缓存两个变量:current ticket和next ticket。每当有 CPU 要获取锁时,会向外发出一个 ticket,即 next ticket 加 1,当有 CPU 要释放锁时,current ticket 加1,每个 CPU 发现自己的ticket 和 current ticket 相等时就获得到锁。
所有试图获取spinlock的 CPU 都在不停的读取spinlock中两个变量的数值变化,当spinlock的值被更改时,这些CPU对应的cache line都会被invalidate,它们必须重新从内存读取新的spinlock的值到自己的cache line中。
而事实上,只有队列中最先排队的那个CPU的cache line被invalidate才是有意义的,对于其他的CPU来说,自己的cache line被invalidate完全是在浪费总线资源。
实际上wild spinlock也有这种浪费总线的问题。为了解决这种资源浪费问题,MCS spinlock出现了。
5.2.3 MCS spinlock(MCS自旋锁)
MCS 锁机制是由John Mellor Crummey和Michael Scott在论文中《algorithms for scalable synchronization on shared-memory multiprocessors》提出的,并以他俩的名字来命名;
struct mcs_spinlock
{struct mcs_spinlock *next;int locked;
};
lock 操作值需要将所有所属 CPU 的 mcs_spinlock 结构体串联成到链表尾部,然后自旋直到自己的 mcs_spinlock 的locked 成员被置1.
unlock 的操作只需要将解锁的 CPU 对应的 mcs_spinlock 结构体的next 的locked 成员置 1,交出锁的使用权,即通知链表中下一个 CPU 可以获取锁了。
5.2.4 qspinlock(队列自旋锁)
include/asm-generic/qspinlock_types.htypedef struct qspinlock {union {atomic_t val;#ifdef __LITTLE_ENDIANstruct {u8 locked;u8 pending;};struct {u16 locked_pending;u16 tail;};
#else...
#endif};
} arch_spinlock_t;- locked:一个字节,表示这个锁是否被持有;
- pending:一个字节,当锁 unlock 之后,持有这个位的 CPU 最先持锁;
- locked_pending:双字节,对应 locked、pending;
- tail:双字节,分两部分编码:
- 2 位:用来编码执行流(线程、软中断、硬中端、非屏蔽中断)
- 14位:用来编码CPU index
qspinlock 的数据结构大致分布如下:

正如qspinlock的作者所说:这个补丁可能不是锁竞争问题的终极解决方案。但重要的是,qspinlock在竞争不严重的场景表现出色,释放一个ticket 自旋锁需要执行一个“读-改-写”原子指令,而qspinlock的释放只需一个写操作。
5.3 自旋锁初始化
5.3.1 动态初始化
include/linux/spinlock.h# define spin_lock_init(_lock) \
do { \spinlock_check(_lock); \*(_lock) = __SPIN_LOCK_UNLOCKED(_lock); \
} while (0)include/linux/spinlock_types.h#define ___SPIN_LOCK_INITIALIZER(lockname) \{ \.raw_lock = __ARCH_SPIN_LOCK_UNLOCKED, \...#define __SPIN_LOCK_INITIALIZER(lockname) \{ { .rlock = ___SPIN_LOCK_INITIALIZER(lockname) } }5.3.2 静态初始化
include/linux/spinlock_types.h#define __SPIN_LOCK_UNLOCKED(lockname) \(spinlock_t) __SPIN_LOCK_INITIALIZER(lockname)#define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)5.3.3 实际初始化
include/asm-generic/qspinlock_types.h#define __ARCH_SPIN_LOCK_UNLOCKED { { .val = ATOMIC_INIT(0) } }无论是动态初始化,还是静态初始化,最终就是调用__ARCH_SPIN_LOCK_UNLOCKED将qspinlock 的成员都置 0.
5.4 spin_lock()
include/linux/spinlock.hstatic __always_inline void spin_lock(spinlock_t *lock)
{raw_spin_lock(&lock->rlock);
}#define raw_spin_lock(lock) _raw_spin_lock(lock)
include/asm-genric/qspinlock.h/*** spin_lock()的核心处理函数* 有两个宏需要关注:_Q_LOCKED_VAL(1<<0) 和 _Q_PENDING_VAL(1<<8)* */
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{int val = 0;if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL)))return;queued_spin_lock_slowpath(lock, val);
}这里可快速上锁和慢速上锁,当lock->val 为0 的时候,认为没有线程持有该锁,可以快速上锁,否则进入慢速。
慢速上锁这里暂不剖析,详细可以查看源码。
5.5 spin_unlock()
include/linux/spinlock.hstatic __always_inline void spin_unlock(spinlock_t *lock)
{raw_spin_unlock(&lock->rlock);
}
include/asm-genric/qspinlock.hstatic __always_inline void queued_spin_unlock(struct qspinlock *lock)
{smp_store_release(&lock->locked, 0);
}可以看到队列自旋锁的解锁确实很简单,只需把 locked 字节设为 0 就可以了。
参考:
https://zhuanlan.zhihu.com/p/506795930
https://zhuanlan.zhihu.com/p/551234849
https://zhuanlan.zhihu.com/p/648188138
6. 读写锁(queue read/write lock)
Linux 内核在 spinlock 基础上实现了 读/写 控制的锁rwlock_t,通过如下数据结构可以看出在 arch_spinlock_t 的基础上多加了一个原子变量cnts,也就是说读写锁的本质就是自旋锁。
读写锁的原理:
- 在没有写锁时,任意读锁都可以并发;
- 当有写锁时,读锁或写锁必须自旋等待;
- 当有读锁时,读锁可以并发(不阻塞),写锁自旋等待;
include/linux/rwlock_types.htypedef struct {arch_rwlock_t raw_lock;
#ifdef CONFIG_DEBUG_SPINLOCKunsigned int magic, owner_cpu;void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
} rwlock_t;include/asm-generic/qrwlock_types.htypedef struct qrwlock {union {atomic_t cnts;struct {
#ifdef __LITTLE_ENDIANu8 wlocked; /* Locked for write? */u8 __lstate[3];
#else...
#endif};};arch_spinlock_t wait_lock;
} arch_rwlock_t;读写锁中用一个原子变量cnts用以统计读写状态:
- 高 24 位用以读锁操作计数,读锁操作成功计数+1;
- 低 8 位用以记录写锁状态:有写意愿、写锁使用中、没有写操作;
6.1 读写锁初始化
include/linux/rwlock.h# define rwlock_init(lock) \do { *(lock) = __RW_LOCK_UNLOCKED(lock); } while (0)include/linux/rwlock_types.h#define __RW_LOCK_UNLOCKED(lockname) \(rwlock_t) { .raw_lock = __ARCH_RW_LOCK_UNLOCKED, \RW_DEP_MAP_INIT(lockname) }include/asm-generic/qrwlock_types.h#define __ARCH_RW_LOCK_UNLOCKED { \{ .cnts = ATOMIC_INIT(0), }, \.wait_lock = __ARCH_SPIN_LOCK_UNLOCKED, \
}初始化就是将cnts 置0,并初始化自旋锁。
6.2 read_lock()
include/linux/rwlock.h#define read_lock(lock) _raw_read_lock(lock)
include/asm-generic/qrwlock.hstatic inline void queued_read_lock(struct qrwlock *lock)
{int cnts;cnts = atomic_add_return_acquire(_QR_BIAS, &lock->cnts);if (likely(!(cnts & _QW_WMASK)))return;/* The slowpath will decrement the reader count, if necessary. */queued_read_lock_slowpath(lock);
}读锁上锁分快速上锁和慢速上锁,当没有写锁的时候,read_lock() 可以成功返回,而当有写锁时,则进入慢速,具体逻辑可以查看源码。
6.3 read_unlock()
include/linux/rwlock.h#define read_unlock(lock) _raw_read_unlock(lock)
include/asm-generic/qrwlock.hstatic inline void queued_read_unlock(struct qrwlock *lock)
{(void)atomic_sub_return_release(_QR_BIAS, &lock->cnts);
}可以看到读锁的解锁确实很简单,只需把对读标记变量 __lstate 进行 -1 操作。
6.4 write_lock()
include/linux/rwlock.h#define write_lock(lock) _raw_write_lock(lock)
include/am-generic/qrwlock.hstatic inline void queued_write_lock(struct qrwlock *lock)
{int cnts = 0;/* Optimize for the unfair lock case where the fair flag is 0. */if (likely(atomic_try_cmpxchg_acquire(&lock->cnts, &cnts, _QW_LOCKED)))return;queued_write_lock_slowpath(lock);
}写锁上锁时,会优先尝试确认lock->cnts 时候有值,如果没有则直接获取写锁,并成功返回。
如果已经有锁,则调用queued_write_lock_slowpath进入慢速上锁。
6.5 write_unlock()
include/linux/rwlock.h#define write_unlock(lock) _raw_write_unlock(lock)
include/asm-generic/qrwlock.hstatic inline void queued_write_unlock(struct qrwlock *lock)
{smp_store_release(&lock->wlocked, 0);
}可以看到,写锁解锁时很简单,只需把 wlocked 字节设为 0 就可以了。
6.6 读写锁缺点
read_lock 与 write_lock 具有相同的优先权:读者必须等所有的写完成,写者必须等待读操作完成。
当接二连三都是读者操作,写锁可能会一直等待,这样造成写者饿死的情况。
7. 顺序锁
从下面定义可知,顺序锁本质还是自旋锁,只不过需要携带 seqcount。
include/linux/seqlock.htypedef struct {seqcount_spinlock_t seqcount;spinlock_t lock;
} seqlock_t;typedef struct seqcount_spinlock {seqcount_t seqcount;
#if defined(CONFIG_LOCKDEP) || defined(CONFIG_PREEMPT_RT)spinlock_t *lock;
#endif
} seqcount_spinlock_t;typedef struct seqcount {unsigned sequence;
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
} seqcount_t;顺序锁提供了一种方式:读者不阻塞写,与读写锁相比,不会出现写者饿死的情况。
这种方式下,读者不会阻塞写者,读者在读数据的时候,写者可以写数据。顺序锁有序列号,写者把序列号加 1,如果读者检测到序列号有变化,发现写者修改了数据,将会重试,读者的开销可能比较高。
7.1 顺序锁初始化
7.1.1 动态初始化
include/linux/seqlock.h#define seqlock_init(sl) \do { \spin_lock_init(&(sl)->lock); \seqcount_spinlock_init(&(sl)->seqcount, &(sl)->lock); \} while (0)结构体中变量 lock 通过spin_lock_init进行自旋锁初始化,详细看第 5.3.1 节。
include/linux/seqlock.h#define seqcount_spinlock_init(s, lock) seqcount_LOCKNAME_init(s, lock, spinlock)#define seqcount_LOCKNAME_init(s, _lock, lockname) \do { \seqcount_##lockname##_t *____s = (s); \seqcount_init(&____s->seqcount); \__SEQ_LOCK(____s->lock = (_lock)); \} while (0)# define seqcount_init(s) __seqcount_init(s, NULL, NULL)static inline void __seqcount_init(seqcount_t *s, const char *name,struct lock_class_key *key)
{lockdep_init_map(&s->dep_map, name, key, 0);s->sequence = 0;
}seqcount_spinlock_init函数主要是将 sequence 置0.
7.1.2 静态初始化
include/linux/seqlock.h#define DEFINE_SEQLOCK(sl) \seqlock_t sl = __SEQLOCK_UNLOCKED(sl)#define __SEQLOCK_UNLOCKED(lockname) \{ \.seqcount = SEQCNT_SPINLOCK_ZERO(lockname, &(lockname).lock), \.lock = __SPIN_LOCK_UNLOCKED(lockname) \}这里的自旋锁初始化使用__SPIN_LOCK_UNLOCKED宏,详细可以查看第 5.3.2 节。
另外,SEQCNT_SPINLOCK_ZERO目的也是初始化 sequence 为0.
7.2 读锁的三种方式
读者因为上锁的方式不同可以分:
-
顺序读者
-
持锁读者
7.2.1 read_seqbegin / read_seqretry

这种方式无加锁访问,读者在读临界区之前先读取sequence,退出临界区操作后再次读sequence并进行比较,如果发现前后的sequence不相等,则说明有写者更新内容,需要重新操作临界区。
所以,这种方式可能会给读者带来开销。
7.2.2 read_seqlock_excl / read_sequnlock_excl

这种方式就是利用seqlock 中的spinlock,进行自旋。
扩展接口有:
read_seqlock_excl_bh / read_sequnlock_excl_bh //申请自旋锁,禁止当前处理器的软中断
read_seqlock_excl_irq / read_sequnlock_excl_irq //申请自旋锁,禁止当前处理器的硬中断
read_seqlock_excl_irqsave / read_sequnlock_excl_irqrestore //申请自旋锁,保存当前cpu的硬中断状态,并禁止当前cpu的硬中断7.2.3 read_seqbegin_or_lock

读者的另一种方式是read_seqbegin_or_lock,可以根据sequence是否为奇数来确定是否有写者操作。
通过下文写锁操作可知,当有写者申请seqlock 时会将sequence进行+1操作,这样读者根据sequence是否为奇数确认是否进行写操作。
扩展接口:
read_seqbegin_or_lock_irqsave / done_seqretry_irqrestore
//如果没有写者,那么读者成为顺序读者;
//如果写着正在写数据,读者成为持锁读者,申请自旋锁,保存当前处理器硬中断状态,并禁止当前处理器的硬中断7.3 write_seqlock / write_sequnlock
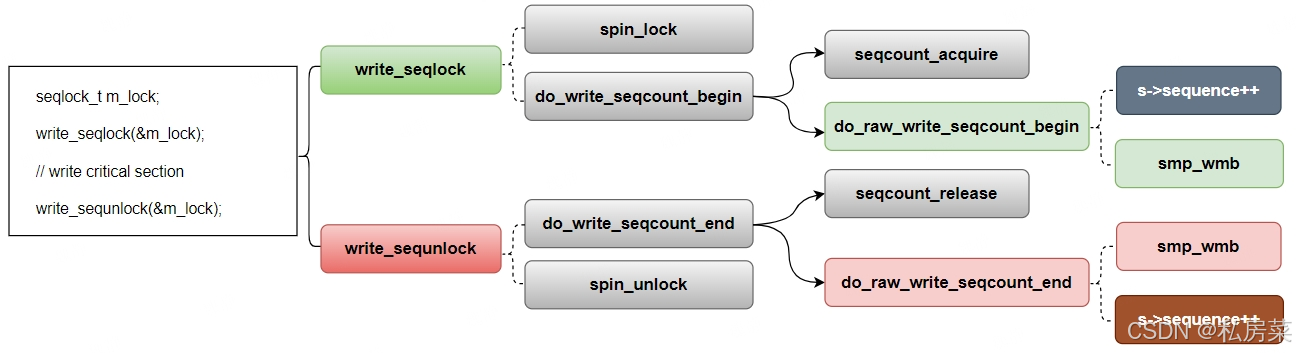
顺序锁的写锁只有一种方式,上锁时先是spin_lock,然后将sequence进行自增处理;解锁时先是spin_unlock,然后将sequence进行自增处理。
扩展接口:
write_seqlock_bh / write_sequnlock_bh //申请写锁,并禁止当前cpu的软中断
write_seqlock_irq / write_sequnlock_irq //申请写锁,并禁止当前cpu的硬中断
__write_seqlock_irqsave / write_sequnlock_irqrestore //申请写锁,保存当前cpu的硬中断状态,禁止当前cpu的硬中断流程中的 smp_rmb / smp_wmb两个函数是内存屏障操作,作用是告诉编译器内存中的值已经改变,之前对内存的缓存(缓存到寄存器) 都需要抛弃,屏障之后的内存操作需要重新从内存 load,而不能使用之前的寄存器缓存的值。
内存屏障就像是代码中一道不可逾越的屏障,屏障之前的 load/store 指令不能跑到屏障后边,同理,后边的也不能跑到前边。
7.4 顺序锁缺点
如果读者采用方式1,临界区中存在地址(指针) 操作,如果写者把地址修改了,那就可能造成访问错误。
8. RCU
相关文章:
Linux 中的同步机制
代码基于:Kernel 6.6 临界资源:指哪些在同一时刻只允许被一个线程访问的软件或硬件资源。这种资源的特点是,如果有线程正在使用,其他进程必须等待直到该线程释放资源。 临界区:指在每个线程中访问临界资源的那段代码。…...

Day17 枚举、typedef、位运算、堆空间的学习
目录 枚举 typedef 位运算 堆上的空间 枚举 一个一个列举出来,是指将变量的值一一列举出来,变量的值只限于列举出来的值的范围内。 作用: 1、为了提高代码的可读性 2、提高代码的安全性 枚举类型 基本语法: enum 枚举名 { …...

Python爬虫与数据分析:中国大学排名的深度挖掘
前言 👉 小编已经为大家准备好了完整的代码和完整的Python学习资料,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】 一、选题背景 高考作为中国学生生涯中最为重要的事,在高考之后,选择一所…...

微软开源库 Detours 详细介绍与使用实例分享
目录 1、Detours概述 2、Detours功能特性 3、Detours工作原理 4、Detours应用场景 5、Detours兼容性 6、Detours具体使用方法 7、Detours使用实例 - 使用Detours拦截系统库中的UnhandledExceptionFilter接口,实现对程序异常的拦截 C软件异常排查从入门到精通…...

js中的getElementById的使用方法
在JavaScript中,document.getElementById()是一种用于通过元素的id属性获取DOM元素的方法。它的作用是返回与指定id匹配的HTML元素。 使用document.getElementById()可以通过元素的id属性直接获取该元素的引用,然后可以使用该引用对元素进行各种操作。例…...

设计模式 - 桥接模式
💝💝💝首先,欢迎各位来到我的博客!本文深入理解设计模式原理、应用技巧、强调实战操作,提供代码示例和解决方案,适合有一定编程基础并希望提升设计能力的开发者,帮助读者快速掌握并灵活运用设计模式。 💝💝💝如有需要请大家订阅我的专栏【设计模式】哟!我会定…...

LeetCode530 二叉搜索树的最小绝对差
前言 题目: 530. 二叉搜索树的最小绝对差 文档: 代码随想录——二叉搜索树的最小绝对差 编程语言: C 解题状态: 成功解决! 思路 注意题目中的二叉搜索树,这个条件暗示每个节点的左子节点肯定小于该节点&am…...

【STM32 FreeRTOS】信号量与互斥锁
二值信号量 二值信号量的本质是一个队列长度为1的队列,该队列就只有空和满两种情况,这就是二值。 二值信号量通常用于互斥访问或任务同步,与互斥信号量比较类似,但是二值信号量有可能会导致优先级翻转的问题,所以二值…...
SP:eric 靶场复现【附代码】(权限提升)
靶机下载地址: https://www.vulnhub.com/entry/sp-eric,274/https://www.vulnhub.com/entry/sp-eric,274/ 1. 主机发现端口扫描目录扫描敏感信息获取 1.1. 主机发现 nmap -sn 192.168.7.0/24|grep -B 2 08:00:27:75:19:80 1.2. 端口扫描 nmap 192.168.7.104 -p…...
SpringBoot项目启动直接结束--已解决
点击启动类,项目启动了,但是却直接停止了。遇到这个问题如何解决呢? 想要项目一直启动是要部署在tomcat服务器上面了,说明现在项目没有运行在tomcat服务器上面。 解决方案: 添加springweb的starter依赖。 <dependency><…...

【笔记】从零开始做一个精灵龙女-画贴图阶段(下)
补充四点,第一,前期画体积用一号或十三号笔刷,压力60,硬度80,体积大一点 2号笔刷比较适合画过渡和软一点的东东 第二, 游戏里面角色原画海报都是发光很亮很透。但是在bp不能画那么亮,因为你进…...
React 学习——react项目中加入echarts图
实现的代码如下: import * as echarts from echarts import { useEffect, useRef } from react; const Home ()>{const chartRef useRef(null);useEffect(()>{// const chartDom document.getElementById(main);//使用id获取节点const chartDom chartRef…...

链表算法题一
旋转链表 旋转链表 首先考虑特殊情况 若给定链表为空表或者单个节点,则直接返回head,不需要旋转操作.题目给定条件范围: 0 < k < 2 ∗ 1 0 9 0 < k < 2 * 10^9 0<k<2∗109,但是受给定链表长度的限制,比如示例2中,k4与k1的效果等价. 那么可以得出kk%l…...
Unity(2022.3.38LTS) - 基础概念
目录 一. 场景 二. 游戏对象 三. 组件 四. 标签 五. 静态游戏对象 六. 保存 一. 场景 Unity 场景是游戏或应用开发中的一个重要概念。 Unity 场景的组成元素: 它通常包含了各种游戏对象,比如 3D 模型、灯光、摄像机、脚本组件、音频源等等。 作用…...

无人机之飞手必看篇
一、熟悉无人机设备 了解你的无人机:熟悉无人机的各个部分,包括遥控器、电池、螺旋桨和摄像头等。 预飞行检查:在每次飞行前进行预检查,确保所有部件正常工作,螺旋桨牢固,电池充满电。 二、选择适当的飞…...
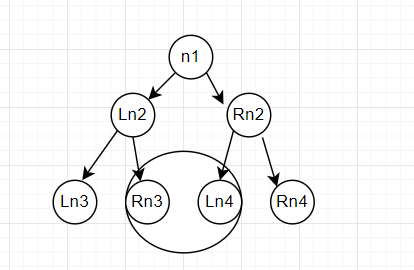
数据结构(11)——二叉搜索树
欢迎来到博主的专栏:数据结构 博主ID:代码小豪 文章目录 二叉搜索树二叉搜索树的声明与定义二叉搜索树的查找二叉搜索树的插入二叉搜索树的中序遍历二叉搜索树的删除 二叉搜索树 二叉搜索树也称二叉排序树,是具备以下特征的二叉树 (1&#x…...

如何使用和配置 AWS CLI 环境变量?
欢迎来到雲闪世界。环境变量在配置和保护应用程序方面起着至关重要的作用,在使用 AWS CLI(命令行界面)时,它们的使用尤其重要。在这篇博客文章中,我们将深入探讨环境变量的世界,探索它们的用途、它们在 AWS…...

七、流程控制
if语句 在go语言中if语句的写法是比较简单的,也是很常见的 func main() {a : trueif a {fmt.Println("a is true")} }if else 语句 func main() {a : trueif !a {fmt.Println("a is true")} else {fmt.Println("a is false")} }el…...

【通过python启动指定的文件】
通过python启动指定的文件 在 Python 中,可以使用os模块的startfile函数(在 Windows 系统中)或者subprocess模块来启动指定的文件。 以下是使用os模块在 Windows 系统中的示例: import osfile_path "C:\\path\\to\\your\…...

区块链开源的项目有哪些?
区块链领域有许多开源项目,它们覆盖了从基础设施到应用层的不同方面。以下是一些著名的区块链开源项目: 1. Bitcoin (比特币):第一个去中心化的加密货币,源代码在 GitHub 上开源。它实现了区块链技术的基本概念。 2. Ethereum (…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...