PyTorch--卷积神经网络(CNN)模型实现手写数字识别
文章目录
- 前言
- 完整代码
- 代码解析
- 1. 导入必要的库
- 2. 设备配置
- 3. 超参数设置
- 4. 加载MNIST数据集
- 5. 创建数据加载器
- 6. 定义卷积神经网络模型
- 7. 实例化模型并移动到设备
- 8. 定义损失函数和优化器
- 9. 训练模型
- 10. 测试模型
- 11. 保存模型
- 常用函数解析
- 小改进
- 数据集部分可视化
- 训练过程可视化
前言
今天要介绍的这段代码是一个使用PyTorch框架实现的卷积神经网络(CNN)模型,用于对MNIST数据集进行分类的示例。MNIST数据集是手写数字识别领域的一个标准数据集,包含0到9的灰度图像。
代码的主要组成部分如下:
-
导入必要的库:导入PyTorch、PyTorch神经网络模块、torchvision(用于处理图像数据集)和transforms(用于图像预处理)。
-
设备配置:设置模型运行的设备,优先使用GPU(如果可用),否则使用CPU。
-
超参数设置:定义了训练迭代的轮数(
num_epochs)、类别数(num_classes)、批次大小(batch_size)和学习率(learning_rate)。 -
加载MNIST数据集:使用
torchvision.datasets.MNIST加载MNIST训练集和测试集,并应用transforms.ToTensor将图像转换为张量。 -
创建数据加载器:使用
torch.utils.data.DataLoader创建训练和测试数据的加载器,以便在训练和测试过程中批量加载数据。 -
定义卷积神经网络模型:定义了一个名为
ConvNet的类,继承自nn.Module。模型包含两个卷积层(每层后接批量归一化和ReLU激活函数),以及一个全连接层。 -
实例化模型并移动到设备:创建
ConvNet模型的实例,并将其移动到之前设置的设备上。 -
定义损失函数和优化器:使用
nn.CrossEntropyLoss作为损失函数,torch.optim.Adam作为优化器。 -
训练模型:进行多个epoch的训练,每个epoch中对数据集进行遍历,执行前向传播、损失计算、反向传播和参数更新。
-
测试模型:在测试阶段,将模型设置为评估模式,并禁用梯度计算以提高效率,然后计算模型在测试集上的准确率。
-
保存模型:使用
torch.save保存训练后的模型参数到文件,以便将来可以重新加载和使用模型。
完整代码
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms# Device configuration
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# Hyper parameters
num_epochs = 5
num_classes = 10
batch_size = 100
learning_rate = 0.001# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='../../data/',train=True, transform=transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root='../../data/',train=False, transform=transforms.ToTensor())# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size, shuffle=False)# Convolutional neural network (two convolutional layers)
class ConvNet(nn.Module):def __init__(self, num_classes=10):super(ConvNet, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.layer2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.fc = nn.Linear(7*7*32, num_classes)def forward(self, x):out = self.layer1(x)out = self.layer2(out)out = out.reshape(out.size(0), -1)out = self.fc(out)return outmodel = ConvNet(num_classes).to(device)# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)# Forward passoutputs = model(images)loss = criterion(outputs, labels)# Backward and optimizeoptimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item()))# Test the model
model.eval() # eval mode (batchnorm uses moving mean/variance instead of mini-batch mean/variance)
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Test Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')
代码解析
1. 导入必要的库
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
- 导入PyTorch及其神经网络(nn)、计算机视觉(vision)模块和变换(transforms)模块。
2. 设备配置
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
- 使用
torch.device设置模型运行的设备,优先使用GPU(如果可用)。
3. 超参数设置
num_epochs = 5
num_classes = 10
batch_size = 100
learning_rate = 0.001
- 定义训练迭代的轮数(
num_epochs),输出类别的数量(num_classes),每个批次的样本数(batch_size),以及优化算法的学习率(learning_rate)。
4. 加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='../../data/',train=True, transform=transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root='../../data/',train=False, transform=transforms.ToTensor())
- 使用
torchvision.datasets.MNIST加载MNIST数据集,包括训练集和测试集。transforms.ToTensor将图像数据转换为张量。
5. 创建数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size, shuffle=False)
- 使用
torch.utils.data.DataLoader创建数据加载器,用于批量加载数据,并在训练时打乱数据顺序。
6. 定义卷积神经网络模型
class ConvNet(nn.Module):def __init__(self, num_classes=10):super(ConvNet, self).__init__()# 定义模型层passdef forward(self, x):# 定义前向传播过程pass
- 定义一个名为
ConvNet的类,继承自nn.Module。在__init__中初始化模型的层,在forward中定义前向传播逻辑。
7. 实例化模型并移动到设备
model = ConvNet(num_classes).to(device)
- 创建
ConvNet模型的实例,并使用.to(device)将其移动到之前设置的设备上。
8. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- 定义
nn.CrossEntropyLoss作为损失函数,使用torch.optim.Adam作为优化器。
9. 训练模型
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):# 训练过程pass
- 遍历所有epoch和batch,执行训练过程,包括数据预处理、前向传播、损失计算、反向传播和参数更新。
10. 测试模型
model.eval() # eval mode
with torch.no_grad():# 测试过程pass
- 将模型设置为评估模式,禁用梯度计算,并执行测试过程,计算模型的准确率。
11. 保存模型
torch.save(model.state_dict(), 'model.ckpt')
- 使用
torch.save保存模型的状态字典到文件,以便之后可以重新加载和使用模型。
常用函数解析
-
torch.device(device_str)- 格式:
torch.device(device_str) - 参数:
device_str—— 指定设备类型和编号(如’cuda:0’)或’cpu’。 - 意义:确定模型和张量运行的设备。
- 用法示例:
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') model.to(device)
- 格式:
-
torchvision.datasets.MNIST(...)- 格式:
torchvision.datasets.MNIST(root, train, transform, download) - 参数:指定数据集路径、是否为训练集、预处理变换、是否下载数据集。
- 意义:加载MNIST数据集。
- 用法示例:
train_dataset = torchvision.datasets.MNIST(root='../../data/', train=True, transform=transforms.ToTensor(), download=True)
- 格式:
-
torch.utils.data.DataLoader(...)- 格式:
torch.utils.data.DataLoader(dataset, batch_size, shuffle) - 参数:数据集对象、批次大小、是否打乱数据。
- 意义:创建数据加载器。
- 用法示例:
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
- 格式:
-
nn.Module- 格式:作为基类,不直接实例化。
- 意义:所有神经网络模块的基类。
- 用法示例:
class ConvNet(nn.Module):def __init__(self, num_classes=10):super(ConvNet, self).__init__()# ...
-
nn.Sequential- 格式:
nn.Sequential(*modules) - 参数:一个模块序列。
- 意义:按顺序应用多个模块。
- 用法示例:
self.layer1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2) )
- 格式:
-
nn.Conv2d(...)- 格式:
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) - 参数:输入通道数、输出通道数、卷积核大小、步长、填充。
- 意义:创建二维卷积层。
- 用法示例:
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2)
- 格式:
-
nn.BatchNorm2d(...)- 格式:
nn.BatchNorm2d(num_features) - 参数:特征数量。
- 意义:创建二维批量归一化层。
- 用法示例:
nn.BatchNorm2d(16)
- 格式:
-
nn.ReLU()- 格式:
nn.ReLU() - 意义:创建ReLU激活层。
- 用法示例:
nn.ReLU()
- 格式:
-
nn.MaxPool2d(...)- 格式:
nn.MaxPool2d(kernel_size, stride) - 参数:池化核大小、步长。
- 意义:创建最大池化层。
- 用法示例:
nn.MaxPool2d(kernel_size=2, stride=2)
- 格式:
-
nn.Linear(...)- 格式:
nn.Linear(in_features, out_features) - 参数:输入特征数、输出特征数。
- 意义:创建全连接层。
- 用法示例:
self.fc = nn.Linear(7*7*32, num_classes)
- 格式:
-
nn.CrossEntropyLoss()- 格式:
nn.CrossEntropyLoss() - 意义:创建交叉熵损失层。
- 用法示例:
criterion = nn.CrossEntropyLoss()
- 格式:
-
torch.optim.Adam(...)- 格式:
torch.optim.Adam(params, lr) - 参数:模型参数、学习率。
- 意义:创建Adam优化器。
- 用法示例:
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- 格式:
-
.to(device)- 格式:
.to(device) - 参数:设备对象。
- 意义:将模型或张量移动到指定设备。
- 用法示例:
images = images.to(device) labels = labels.to(device)
- 格式:
-
.reshape(-1, num_features)- 格式:
reshape(new_shape) - 参数:新形状。
- 意义:重塑张量形状。
- 用法示例:
out = out.reshape(out.size(0), -1)
- 格式:
-
torch.max(outputs.data, 1)- 格式:
torch.max(input, dim) - 参数:输入张量、计算最大值的维度。
- 意义:获取张量在指定维度上的最大值和索引。
- 用法示例:
_, predicted = torch.max(outputs.data, 1)
- 格式:
-
torch.no_grad()- 格式:
torch.no_grad() - 意义:上下文管理器,用于推理或测试阶段禁用梯度计算。
- 用法示例:
with torch.no_grad():# 测试模型的代码
- 格式:
-
.sum().item()- 格式:
.sum(dim).item() - 参数:求和的维度。
- 意义:计算张量在指定维度的和,并转换为Python数值。
- 用法示例:
correct += (predicted == labels).sum().item()
- 格式:
-
model.eval()- 格式:
model.eval() - 意义:将模型设置为评估模式。
- 用法示例:
model.eval()
- 格式:
-
torch.save(...)- 格式:
torch.save(obj, f) - 参数:要保存的对象、文件路径。
- 意义:保存对象到文件。
- 用法示例:
torch.save(model.state_dict(), 'model.ckpt')
- 格式:
小改进
在运行代码的时候发现可视化十分简陋,于是进行了第一波可视化小改进:读取部分数据集。
数据集部分可视化
def show_images(images):plt.figure(figsize=(10,10))for i, img in enumerate(images):plt.subplot(5, 5, i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(img.squeeze().numpy(), cmap='gray')plt.show()# Visualize a few images
dataiter = iter(train_loader)
images, _ = next(dataiter)
show_images(images[:25]) # Visualize 25 images另外,请注意,由于MNIST数据集中的图像是灰度图,它们的形状是(batch_size, channels, height, width),即(100, 1, 28, 28)。在使用show_images函数之前,我们需要将图像重塑为(batch_size, height, width),即(100, 28, 28)。以下是show_images函数的修正:
def show_images(images):plt.figure(figsize=(10,10))for i, img in enumerate(images):plt.subplot(5, 5, i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(img.squeeze().numpy(), cmap='gray') # 使用 squeeze() 来去除单维度plt.show()
确保在使用show_images函数时传递正确形状的图像。如果图像是从DataLoader中获取的,你可能需要使用unsqueeze(0)来添加一个批次维度,然后再调用squeeze()来去除单维度。例如:
images = images.unsqueeze(0) # 添加一个批次维度
show_images(images[:25]) # 可视化前25张图像
这样就可以正确地显示图像了。

然后呢,继续执行代码,我们发现训练过程的可视化也是少得可怜,于是我们再加多一点可视化内容。
训练过程可视化
要对训练过程进行更多的可视化,咱们可以记录每个epoch的损失值,并使用Matplotlib绘制损失随epoch变化的图表。以下是如何修改代码来实现这一点:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt# ...(之前的代码保持不变,包括设备配置、数据加载、模型定义等)# 训练模型
def train(model, device, train_loader, optimizer, epoch, num_epochs):model.train() # Set the model to training modetotal_step = len(train_loader)losses = []for i, (images, labels) in enumerate(train_loader):images, labels = images.to(device), labels.to(device)# Forward passoutputs = model(images)loss = criterion(outputs, labels)# Backward and optimizeoptimizer.zero_grad()loss.backward()optimizer.step()# Collect loss for plottinglosses.append(loss.item())if (i+1) % 100 == 0:print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))return losses# 绘制损失曲线的函数
def plot_losses(epochs, losses):plt.figure(figsize=(10, 5))for i, loss_per_epoch in enumerate(losses):plt.plot(loss_per_epoch, label=f'Epoch {i+1}')plt.title('Loss over epochs')plt.xlabel('Steps')plt.ylabel('Loss')plt.legend()plt.show()# 训练过程
losses_over_epochs = []
for epoch in range(num_epochs):losses = train(model, device, train_loader, optimizer, epoch, num_epochs)losses_over_epochs.append(losses)print(f'Epoch {epoch+1}/{num_epochs} - Average Loss: {sum(losses)/len(losses):.4f}')# 绘制所有epoch的损失曲线
plot_losses(num_epochs, losses_over_epochs)# ...(测试模型和保存模型的代码保持不变)
在这个修改后的代码中,我们添加了两个新的函数:
train:这个函数用于训练模型,并记录每个step的损失。它返回一个包含所有step损失的列表。plot_losses:这个函数接受epoch列表和损失列表作为参数,并绘制出损失随训练step变化的曲线。
在主训练循环中,我们对每个epoch调用train函数,并收集所有epoch的损失,然后使用plot_losses函数绘制损失曲线。
请注意,这里绘制的是每个step的损失,而不是每个epoch的损失均值。如果想要绘制每个epoch的平均损失,可以修改train函数来计算每个epoch的平均损失,并只记录这个值。
咱直接把最终代码贴上:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt# Device configuration
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# Hyper parameters
num_epochs = 10
num_classes = 10
batch_size = 100
learning_rate = 0.001# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='../../data/',train=True, transform=transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root='../../data/',train=False, transform=transforms.ToTensor())# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size, shuffle=False)# Convolutional neural network (two convolutional layers)
class ConvNet(nn.Module):def __init__(self, num_classes=10):super(ConvNet, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.layer2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.fc = nn.Linear(7*7*32, num_classes)def forward(self, x):out = self.layer1(x)out = self.layer2(out)out = out.view(out.size(0), -1) # Flatten the outputout = self.fc(out)return outmodel = ConvNet(num_classes).to(device)# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# Function to visualize images
def show_images(images):plt.figure(figsize=(10,10))for i, img in enumerate(images):plt.subplot(5, 5, i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(img.squeeze().numpy(), cmap='gray')plt.show()# Function to train the model
def train(model, device, train_loader, optimizer, epoch, num_epochs):model.train() # Set the model to training modetotal_step = len(train_loader)losses = []for i, (images, labels) in enumerate(train_loader):images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()losses.append(loss.item())if (i+1) % 100 == 0:print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))return losses# Function to test the model
def test(model, device, test_loader):model.eval() # Set the model to evaluation modecorrect = 0total = 0with torch.no_grad():for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()return 100 * correct / total# Function to plot training progress
def plot_progress(epochs, train_losses, test_accuracies):plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)for i in range(epochs):plt.plot(train_losses[i], label=f'Epoch {i+1}')plt.title('Training Loss')plt.xlabel('Batch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(test_accuracies, label='Accuracy')plt.title('Test Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.legend()plt.show()# Visualize a few images
dataiter = iter(train_loader)
images, _ = next(dataiter)
show_images(images[:25]) # Visualize 25 images# Initialize lists to monitor loss and accuracy
train_losses = []
test_accuracies = []# Train the model
for epoch in range(num_epochs):print(f'Epoch {epoch+1}/{num_epochs}')train_loss = train(model, device, train_loader, optimizer, epoch, num_epochs)train_losses.append(train_loss)test_accuracy = test(model, device, test_loader)test_accuracies.append(test_accuracy)print(f'Epoch {epoch+1}/{num_epochs} - Average Loss: {sum(train_loss)/len(train_loss):.4f}, Accuracy: {test_accuracy:.2f}%')# Plot training progress
plot_progress(num_epochs, train_losses, test_accuracies)# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')
经过修改后的训练过程如下图所示:


还有很多很多小改进的方向,就留给各位自己尝试啦。
相关文章:
PyTorch--卷积神经网络(CNN)模型实现手写数字识别
文章目录 前言完整代码代码解析1. 导入必要的库2. 设备配置3. 超参数设置4. 加载MNIST数据集5. 创建数据加载器6. 定义卷积神经网络模型7. 实例化模型并移动到设备8. 定义损失函数和优化器9. 训练模型10. 测试模型11. 保存模型 常用函数解析小改进数据集部分可视化训练过程可视…...

前端程序员回忆工作第1年的记录总结(一)
更多详情:爱米的前端小笔记(csdn~xitujuejin~zhiHu~Baidu~小红shu)同步更新,等你来看!都是利用下班时间整理的,整理不易,大家多多👍💛➕🤔哦!你们…...

SQL Server端口设置完整详细步骤
大家好,我是程序员小羊! 前言: 前面是对SQLserver服务器一些介绍,不想了解的可直接点击目录跳入正题,谢谢!!! SQL Server 是由微软公司开发的关系数据库管理系统 (RDBMS)。它主要…...

【2024】k8s集群 图文详细 部署安装使用(两万字)
目录💻 一、前言二、下载依赖配置环境1、配置系统环境1.1、配置桥接网络1.1.1、parallels desktop配置1.1.2、VMware配置 1.2、配置root用户登陆 2、环境配置安装下载2.1、安装ipset和ipvsadm2.2、关闭SWAP分区 3、配置Containerd容器3.1、下载安装Containerd3.2、创…...

CSS 伪类和伪元素
也是选择器的一种,被称为伪类和伪元素。这一类选择器的数量众多,通常用于很明确的目的。 伪类 什么是伪类 伪类是选择器的一种,它用于选择处于特定状态的元素。 比如当它们是这一类型的第一个元素时(:first-child)&…...

某动一面——算法题
function restoreIpAddresses(s) {const result = [];function backtrack(start, path) {// 如果剩余的字符数不符合IP地址的要求,则剪枝if (s.length - start > (4 - path.length) * 3) return;if (s.length - start < (4 - path.length)) return;// 当找到了四段IP地址…...

kubernetes中共享内存和内存区别
计算机科学中的内存与共享内存 在计算机科学中,“内存”和“共享内存”是两个不同的概念,但它们之间有着密切的关系。为了更好地理解这两个概念及其相互关系,我们可以分别解释一下: 内存 (Memory) 内存通常指的是计算机系统的主…...

JavaWeb04-MyBatis与Spring结合
目录 前言 一、MyBatis入门(MyBatis官网) 1.1 创建mybatis项目(使用spring项目整合式方法) 1.2 JDBC 1.3 数据库连接池 1.4 实用工具:Lombok 二、MyBatis基础操作 2.1 准备工作 2.2 导入项目并实现操作 2.3 具…...
Mybatis-springBoot
MyBatis 是一个流行的 Java 持久层框架,它简化了与关系型数据库的交互。通过将 SQL 语句与 Java 代码进行映射,MyBatis 提供了一种方便、灵活的方式来执行数据库操作。它支持动态SQL、缓存机制和插件扩展,使得开发人员能够更高效地编写和管理…...

【中国数据库前世今生】数据存储管理的起源与现代数据库发展启蒙
记录开启本篇的目的: 作为1名练习时长2年半的DBA,工作大部分时间都在和数据库打交道,包括Oracle,Mysql,Postgresql,Opengauss等国内外数据库。但是对数据库的发展史却知之甚少。 正好腾讯云开发者社区正在热播:【纪录片】中国数据库前世今生,借此机会了解…...

拉卡拉上半年营收29.82亿元 外卡、数字化服务提升业绩增长空间
8月9日晚,拉卡拉(300773.SZ)发布2024年半年业绩报告。在国内经济延续恢复向好态势、国内消费市场规模持续增长的背景下,拉卡拉积极推进“推广数字支付、共享数字科技、兑现数据价值”的经营战略,上半年公司实现营业收入29.82亿元,…...

数学建模——启发式算法(蚁群算法)
算法原理 蚁群算法来自于蚂蚁寻找食物过程中发现路径的行为。蚂蚁并没有视觉却可以寻找到食物,这得益于蚂蚁分泌的信息素,蚂蚁之间相互独立,彼此之间通过信息素进行交流, 从而实现群体行为。 蚁群算法的基本原理就是蚂蚁觅食的过程…...
详解)
【Pytorch实用教程】在做模型融合时非常关键的代码:nn.Identity()详解
文章目录 nn.Identity()基础介绍主要用途示例代码以ResNet为例介绍 self.resnet.fc = nn.Identity() 的作用1. **背景:ResNet 模型结构**2. **代码 `self.resnet.fc = nn.Identity()` 的作用**3. **为什么使用 `nn.Identity()`**4. **示例代码**nn.Identity()基础介绍 nn.Ide…...

【开源力荐】一款基于web的可视化视频剪辑工具
嗨, 大家好, 我是徐小夕. 之前一直在社区分享零代码&低代码的技术实践,也陆陆续续设计并开发了多款可视化搭建产品,比如: H5-Dooring(页面可视化搭建平台)V6.Dooring(可视化大屏搭建平台)橙…...

鸿萌数据恢复服务: 如何修复 SQL Server 数据库错误 829?
天津鸿萌科贸发展有限公司从事数据安全服务二十余年,致力于为各领域客户提供专业的数据恢复、数据备份、网络及终端数据安全等解决方案与服务。 同时,鸿萌是众多国际主流数据恢复软件(Stellar、UFS、R-Studio、ReclaiMe Pro 等)的授权代理商,…...

OpenCV图像处理——按最小外接矩形剪切图像
引言 在图像处理过程中,提取感兴趣区域(ROI)并在其上进行处理后,往往需要将处理后的结果映射回原图像。这一步通常涉及以下几个步骤: 找到最小外接矩形:使用 cv::boundingRect 或 cv::minAreaRect 提取感兴…...

《熬夜整理》保姆级系列教程-玩转Wireshark抓包神器教程(4)-再识Wireshark
1.简介 按照以前的讲解和分享路数,宏哥今天就应该从外观上来讲解WireShark的界面功能了。 2.软件界面 由上到下依次是标题栏、主菜单栏、主菜单工具栏、显示过滤文本框、打开区、最近捕获并保存的文件、捕获区、捕获过滤文本框、本机所有网络接口、学习区及用户指…...

调用yolov3模型进行目标检测
要调用已经训练好的YOLOv3模型对图片进行检测,需要完成以下几个步骤: 加载预训练模型:从预训练的权重文件中加载模型。准备输入图片:将图片转换为模型所需的格式。进行推理:使用模型对图片进行推理,得到检…...

linux文件——重定向原理——dup、重定向与execl、VFS
前言:本篇讲解linux下的重定向相关内容。 在本篇中, 博主将会带着友友们一边实验, 一边探索底层原理。 通过本篇的学习, 友友们将会了解到重定向是如何实现的, 重定向的本质是什么, 重定向和进程替换之间的…...
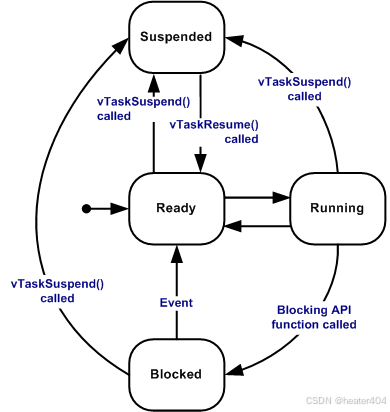
【STM32 FreeRTOS】任务
使用 RTOS 的实时应用程序可以被构建为一组独立的任务。每个任务在自己的上下文中执行,不依赖于系统内的其他任务或 RTOS 调度器本身。在任何时间点,应用程序中只能执行一个任务,实时 RTOS 调度器负责决定所要执行的任务。因此, R…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
算法打卡第18天
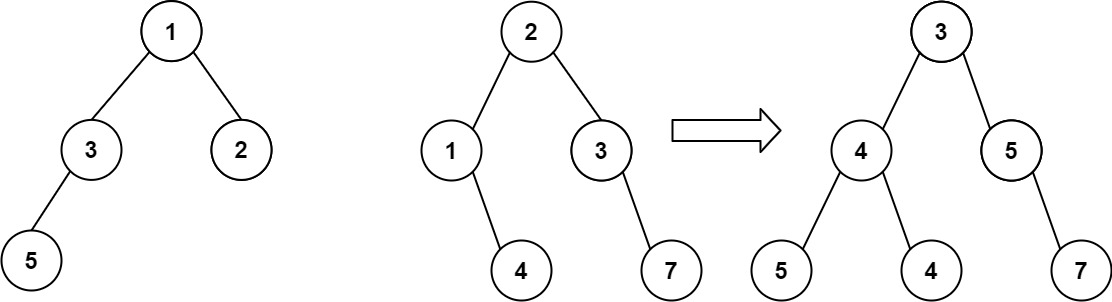
从中序与后序遍历序列构造二叉树 (力扣106题) 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7…...

GAN模式奔溃的探讨论文综述(一)
简介 简介:今天带来一篇关于GAN的,对于模式奔溃的一个探讨的一个问题,帮助大家更好的解决训练中遇到的一个难题。 论文题目:An in-depth review and analysis of mode collapse in GAN 期刊:Machine Learning 链接:...