《Terraform 101 从入门到实践》 Functions函数
《Terraform 101 从入门到实践》这本小册在南瓜慢说官方网站和GitHub两个地方同步更新,书中的示例代码也是放在GitHub上,方便大家参考查看。
Terraform的函数
Terraform为了让大家在表达式上可以更加灵活方便地进行计算,提供了大量的内置函数(Function)。目前并不支持自定义函数,只能使用Terraform自带的。使用函数的格式也很简单,直接写函数名+参数即可。如下面的函数为取最大值:
> max(34, 45, 232, 25)
232这里把函数单独列成一章不是因为它很难理解,而因为它很常用,值得把这些函数梳理一下,以便查询使用吧。
数值计算函数
绝对值abs:
> abs(5)
5
> abs(-3.1415926)
3.1415926
> abs(0)
0返回大于等于该数值的最小整数:
> ceil(3)
3
> ceil(3.1)
4
> ceil(2.9)
3小于等于该数值的最大整数:
> floor(6)
6
> floor(6.9)
6
> floor(5.34)
5对数函数:
> log(16, 2)
4
> log(9, 3)
2.0000000000000004指数函数:
> pow(6, 2)
36
> pow(6, 1)
6
> pow(6, 0)
1最大值、最小值:
> max(2, 98, 75, 4)
98
> min(2, 98, 75, 4)
2字符串转换成整数,第二个参数为进制:
> parseint("16", 10)
16
> parseint("16", 16)
22
> parseint("FF", 16)
255
> parseint("1010", 2)
10信号量函数:
> signum(6)
1
> signum(-6)
-1
> signum(0)
0字符串函数
删去换行,在从文件中读取文本时非常有用:
> chomp("www.pkslow.com")
"www.pkslow.com"
> chomp("www.pkslow.com\n")
"www.pkslow.com"
> chomp("www.pkslow.com\n\n")
"www.pkslow.com"
> chomp("www.pkslow.com\n\n\r")
"www.pkslow.com"
> chomp("www.pkslow.com\n\n\ra")
<<EOT
www.pkslow.coma
EOT格式化输出:
> format("Hi, %s!", "Larry")
"Hi, Larry!"> format("My name is %s, I'm %d", "Larry", 18)
"My name is Larry, I'm 18"> format("The reuslt is %.2f", 3)
"The reuslt is 3.00"> format("The reuslt is %.2f", 3.1415)
"The reuslt is 3.14"> format("The reuslt is %8.2f", 3.1415)
"The reuslt is 3.14"遍历格式化列表:
> formatlist("My name is %s, I'm %d %s.", ["Larry", "Jeremy", "Tailor"], [18, 28, 33], "in 2022")
tolist(["My name is Larry, I'm 18 in 2022.","My name is Jeremy, I'm 28 in 2022.","My name is Tailor, I'm 33 in 2022.",
])参数可以是List,还可以是单个变量。
字符串连接:
> join(".", ["www", "pkslow", "com"])
"www.pkslow.com"
> join(", ", ["Larry", "Pkslow", "JJ"])
"Larry, Pkslow, JJ"大小写字母转换:
> lower("Larry Nanhua DENG")
"larry nanhua deng"
> upper("Larry Nanhua DENG")
"LARRY NANHUA DENG"首字母大写:
> title("larry")
"Larry"替换:
> replace("www.larrydpk.com", "larrydpk", "pkslow")
"www.pkslow.com"
> replace("hello larry", "/la.*y/", "pkslow")
"hello pkslow"分割:
> split(".", "www.pklow.com")
tolist(["www","pklow","com",
])反转:
> strrev("pkslow")
"wolskp"截取:
> substr("Larry Deng", 0, 5)
"Larry"
> substr("Larry Deng", -4, -1)
"Deng"去除头尾某些特定字符,注意这里只要有对应字符就会删除:
> trim("?!what?!!!!!", "?!")
"what"
> trim("abaaaaabbLarry Dengaab", "ab")
"Larry Deng"去除头尾特定字符串,注意与上面的区别:
> trimsuffix("?!what?!!!!!", "!!!")
"?!what?!!"
> trimprefix("?!what?!!!!!", "?!")
"what?!!!!!"去除头尾的空格、换行等空串:
> trimspace(" Larry Deng \n\r")
"Larry Deng"正则匹配,下面的例子是匹配第一个和匹配所有:
> regex("[a-z\\.]+", "2021www.pkslow.com2022larry deng 31415926")
"www.pkslow.com"
> regexall("[a-z\\.]+", "2021www.pkslow.com2022larry deng 31415926")
tolist(["www.pkslow.com","larry","deng",
])更多正则匹配语法可参考:https://www.terraform.io/language/functions/regex
集合类函数
alltrue:判断列表是否全为真,空列表直接返回true。只能是bool类型或者对应的字符串。
> alltrue([true, "true"])
true
> alltrue([true, "true", false])
false
> alltrue([])
true
> alltrue([1])
╷
│ Error: Invalid function argument
│
│ on <console-input> line 1:
│ (source code not available)
│
│ Invalid value for "list" parameter: element 0: bool required.anytrue:判断列表是否有真,只要有一个为真就返回true。空列表为false。
> anytrue([true])
true
> anytrue([true, false])
true
> anytrue([false, false])
false
> anytrue([])
falsechunklist分片:根据分片数来对列表进行切分。
> chunklist(["www", "pkslow", "com", "Larry", "Deng"], 3)
tolist([tolist(["www","pkslow","com",]),tolist(["Larry","Deng",]),
])coalesce返回第一个非空元素:
> coalesce("", "a", "b")
"a"
> coalesce("", "", "b")
"b"coalescelist返回第一个非空列表:
> coalescelist([], ["pkslow"])
["pkslow",
]从字符串列表里把空的去掉:
> compact(["", "www", "", "pkslow", "com"])
tolist(["www","pkslow","com",
])concat连接多个列表:
> concat([1, 2, 3], [4, 5, 6])
[1,2,3,4,5,6,
]contains判断是否存在某个元素:
> contains(["www", "pkslow", "com"], "pkslow")
true
> contains(["www", "pkslow", "com"], "Larry")
falsedistinct去除重复元素:
> distinct([1, 2, 2, 1, 3, 8, 1, 10])
tolist([1,2,3,8,10,
])element获取列表的某个元素:
> element(["a", "b", "c"], 1)
"b"
> element(["a", "b", "c"], 2)
"c"
> element(["a", "b", "c"], 3)
"a"
> element(["a", "b", "c"], 4)
"b"flatten把内嵌的列表都展开成一个列表:
> flatten([1, 2, 3, [1], [[6]]])
[1,2,3,1,6,
]index获取列表中的元素的索引值:
> index(["www", "pkslow", "com"], "pkslow")
1keys获取map的所有key值:
> keys({name="Larry", age=18, webSite="www.pkslow.com"})
["age","name","webSite",
]values获取map的value值:
> values({name="Larry", age=18, webSite="www.pkslow.com"})
[18,"Larry","www.pkslow.com",
]length获取字符串、列表、Map等的长度:
> length([])
0
> length(["pkslow"])
1
> length(["pkslow", "com"])
2
> length({pkslow = "com"})
1
> length("pkslow")
6lookup(map, key, default)根据key值在map中找到对应的value值,如果没有则返回默认值:
> lookup({name = "Larry", age = 18}, "age", 1)
18
> lookup({name = "Larry", age = 18}, "myAge", 1)
1matchkeys(valueslist, keyslist, searchset)对key值进行匹配。匹配到key值后,返回对应的Value值。
> matchkeys(["a", "b", "c", "d"], [1, 2, 3, 4], [2, 4])
tolist(["b","d",
])merge合并Map,key相同的会被最后的覆盖:
> merge({name = "Larry", webSite = "pkslow.com"}, {age = 18})
{"age" = 18"name" = "Larry""webSite" = "pkslow.com"
}
> merge({name = "Larry", webSite = "pkslow.com"}, {age = 18}, {age = 13})
{"age" = 13"name" = "Larry""webSite" = "pkslow.com"
}one取集合的一个元素,如果为空则返回null;如果只有一个元素,则返回该元素;如果多个元素,则报错:
> one([])
null
> one(["pkslow"])
"pkslow"
> one(["pkslow", "com"])
╷
│ Error: Invalid function argument
│
│ on <console-input> line 1:
│ (source code not available)
│
│ Invalid value for "list" parameter: must be a list, set, or tuple value with either zero or one elements.
╵range生成顺序列表:
range(max)
range(start, limit)
range(start, limit, step)> range(3)
tolist([0,1,2,
])
> range(1, 6)
tolist([1,2,3,4,5,
])
> range(1, 6, 2)
tolist([1,3,5,
])reverse反转列表:
> reverse([1, 2, 3, 4])
[4,3,2,1,
]setintersection对set求交集:
> setintersection([1, 2, 3], [2, 3, 4], [2, 3, 6])
toset([2,3,
])setproduct列出所有组合可能:
> setproduct(["Larry", "Harry"], ["Deng", "Potter"])
tolist([["Larry","Deng",],["Larry","Potter",],["Harry","Deng",],["Harry","Potter",],
])setsubtract:set的减法
> setsubtract([1, 2, 3], [3, 4])
toset([1,2,
])# 求不同
> setunion(setsubtract(["a", "b", "c"], ["a", "c", "d"]), setsubtract(["a", "c", "d"], ["a", "b", "c"]))
["b","d",
]setunion:set的加法
> setunion([1, 2, 3], [3, 4])
toset([1,2,3,4,
])slice(list, startindex, endindex)截取列表部分,包括startindex,但不包括endindex:
> slice(["a", "b", "c", "d", "e"], 1, 4)
["b","c","d",
]sort对列表中的字符串进行排序,要注意如果输入的是数字,会先转化为字符串再排序:
> sort(["larry", "pkslow", "com", "deng"])
tolist(["com","deng","larry","pkslow",
])
> sort([3, 6, 1, 9, 12, 79, 22])
tolist(["1","12","22","3","6","79","9",
])sum求和:
> sum([3, 1.2, 9, 17.3, 2.2])
32.7transpose对Map的key和value进行换位:
> transpose({"a" = ["1", "2"], "b" = ["2", "3"]})
tomap({"1" = tolist(["a",])"2" = tolist(["a","b",])"3" = tolist(["b",])
})zipmap根据key和value的列表按一对一关系生成Map:
> zipmap(["age", "name"], [18, "Larry Deng"])
{"age" = 18"name" = "Larry Deng"
}加密解密
Base64:
> base64encode("pkslow")
"cGtzbG93"
> base64decode("cGtzbG93")
"pkslow"
> textencodebase64("pkslow", "UTF-8")
"cGtzbG93"
> textdecodebase64("cGtzbG93", "UTF-8")
"pkslow"csv文本解析:
> csvdecode("seq,name,age\n1,larry,18\n2,pkslow,3\n3,Jeremy,29")
tolist([{"age" = "18""name" = "larry""seq" = "1"},{"age" = "3""name" = "pkslow""seq" = "2"},{"age" = "29""name" = "Jeremy""seq" = "3"},
])Json解析:
> jsonencode({"name"="Larry", "age"=18})
"{\"age\":18,\"name\":\"Larry\"}"
> jsondecode("{\"age\":18,\"name\":\"Larry\"}")
{"age" = 18"name" = "Larry"
}URL:
> urlencode("Larry Deng/a/:/./@")
"Larry+Deng%2Fa%2F%3A%2F.%2F%40"YAML:
> yamlencode({"a":"b", "c":"d"})
"a": "b"
"c": "d"> yamlencode({"foo":[1, 2, 3], "bar": "baz"})
"bar": "baz"
"foo":
- 1
- 2
- 3> yamlencode({"foo":[1, {"a":"b","c":"d"}, 3], "bar": "baz"})
"bar": "baz"
"foo":
- 1
- "a": "b""c": "d"
- 3
> yamldecode("hello: world")
{"hello" = "world"
}> yamldecode("true")
true> yamldecode("{a: &foo [1, 2, 3], b: *foo}")
{"a" = [1,2,3,]"b" = [1,2,3,]
}文件处理:
获取绝对路径:
> abspath(path.root)
"/Users/larry"获取路径中的目录,或者是文件名:
> dirname("/home/larry/soft/terraform")
"/home/larry/soft"
> dirname("/home/larry/soft/terraform/")
"/home/larry/soft/terraform"
> basename("/home/larry/soft/terraform")
"terraform"
> basename("/home/larry/soft/terraform/")
"terraform"判断文件是否存在,并获取文件内容:
> fileexists("/Users/larry/.bash_profile")
true
> file("/Users/larry/.bash_profile")
> filebase64("/Users/larry/.bash_profile")根据模式匹配所有文件:
> fileset("/Users/larry", "*.bash*")
toset([".bash_history",".bash_profile",".bash_profile.backup",
])templatefile(path, vars)模板化文件:指定文件和变量,把变量值替换掉模板中的变量。
时间函数
获取当前时间,并格式化显示,格式请参考:https://www.terraform.io/language/functions/formatdate
> formatdate("YYYY-MM-DD hh:mm:ss / D MMMM YYYY", timestamp())
"2022-03-05 08:25:48 / 5 March 2022"
> formatdate("EEEE, DD-MMM-YY hh:mm:ss ZZZ", "2018-01-02T23:12:01Z")
"Tuesday, 02-Jan-18 23:12:01 UTC"时间加减:
> timeadd(timestamp(), "24h")
"2022-03-06T08:28:52Z"
> timeadd(timestamp(), "-24h10m")
"2022-03-04T08:19:08Z"支持的单位有:"ns", "us" (or "µs"), "ms", "s", "m", and "h".
其它
加密:
> md5("www.pkslow.com")
"97e164b60faf4d7875c2a8a5bc3f2245"UUID:
> uuid()
"049bf418-15d1-e034-28db-92945067dcf6"IP:
> cidrsubnet("172.16.0.0/12", 4, 2)
"172.18.0.0/16"更多请参考官网。
相关文章:

《Terraform 101 从入门到实践》 Functions函数
《Terraform 101 从入门到实践》这本小册在南瓜慢说官方网站和GitHub两个地方同步更新,书中的示例代码也是放在GitHub上,方便大家参考查看。 Terraform的函数 Terraform为了让大家在表达式上可以更加灵活方便地进行计算,提供了大量的内置函数…...

使用kubeadm快速部署一个K8s集群
wkubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。 这个工具能通过两条指令完成一个kubernetes集群的部署: # 创建一个 Master 节点 $ kubeadm init# 将一个 Node 节点加入到当前集群中 $ kubeadm join <Master节点的IP和端口 >1. 安装要求 …...

初探富文本之CRDT协同算法
初探富文本之CRDT协同算法 CRDT的英文全称是Conflict-free Replicated Data Type,最初是由协同文本编辑和移动计算而发展的,现在还被用作在线聊天系统、音频分发平台等等。当前CRDT算法在富文本编辑器领域的协同依旧是典型的场景,常用于作为…...
Dubbo和Zookeeper集成分布式系统快速入门
文件结构 代码部分 1、新建provider-server导入pom依赖 <dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo-spring-boot-starter</artifactId><version>2.7.3</version></dependency><dependency>&l…...
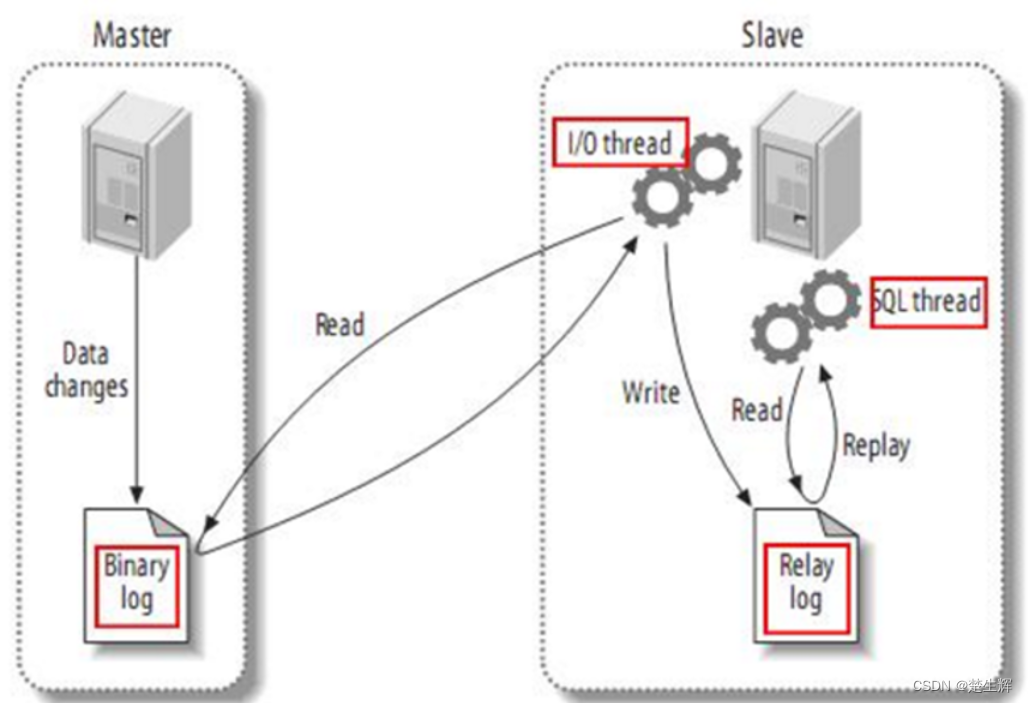
大数据工具Maxwell的使用
1.Maxwell简介 Maxwell 是由美国Zendesk公司开源,用Java编写的MySQL变更数据抓取软件。它会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变更数据以 JSON 格式发送给 Kafka、Kinesi等流数据处理平台。 官…...

freesurfer如何将组模板投影到个体空间——如投影 Schaefer2018 到个体空间
freesurfer如何将组模板投影到个体空间——如投影 Schaefer2018 到个体空间 freesurfer如何将组模板投影到个体空间? freesurfer如何将组模板投影到个体空间——如投影 Schaefer2018 到个体空间freesurfer的整理流程freesurfer的安装freesurfer对结构像分割流程及批处理代码fr…...
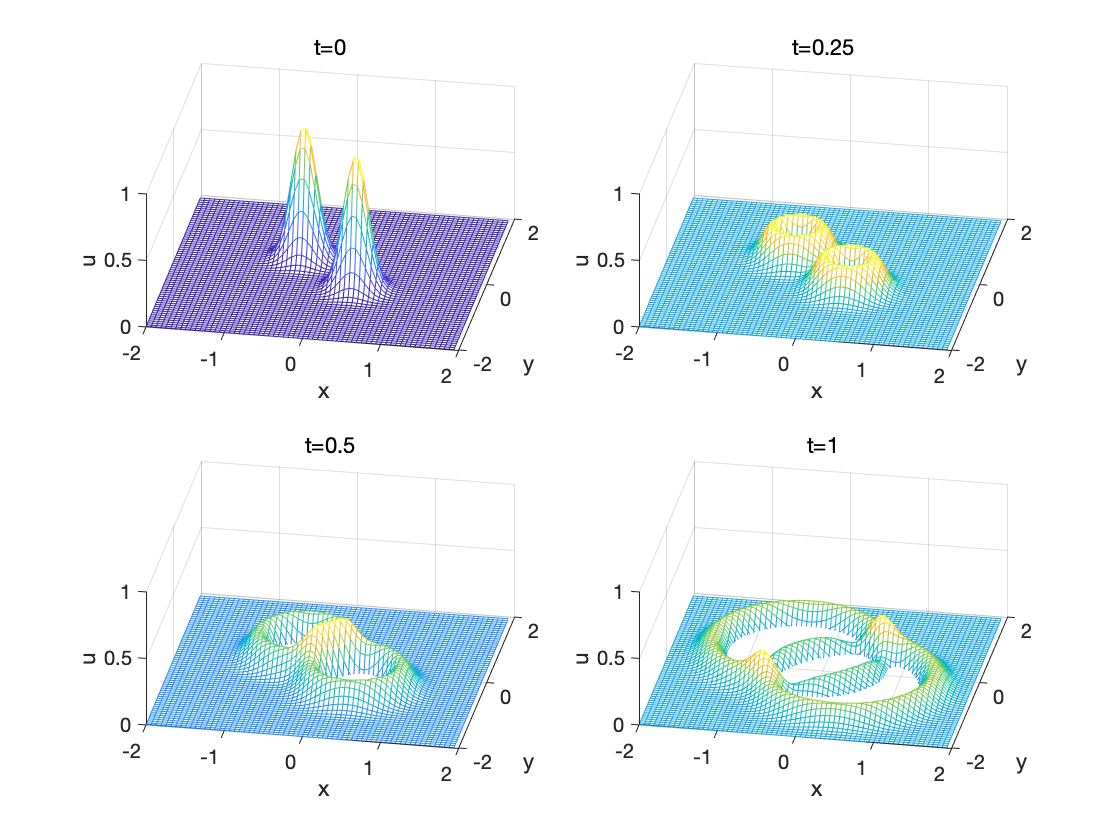
Matlab傅里叶谱方法求解二维波动方程
傅里叶谱方法求解基本偏微分方程—二维波动方程 二维波动方程 将一维波动方程中的一维无界弦自由振动方程推广到二维空间上, 就得到了描述无界 (−∞<x,y<∞)(-\infty<x, y<\infty)(−∞<x,y<∞) 弹性薄膜的波动方程: ∂2u∂t2a2(∂2∂x2∂2∂y2)u(1)\frac…...

【深度学习】卷积神经网络
1 卷积神经网络(CNN)可以做什么? 检测任务分类与检索超分辨率重构:将图像训练的更清晰医学任务等无人驾驶人脸识别 2 用GPU:图像处理单元 比CPU块一百倍以上 3 卷积神经网络与传统神经网络的区别 传统神经网络&…...
【C++】六个默认成员函数——取地址重载,const成员函数
🍅 初始化和清理 拷贝复制 目录 ☃️1.取地址重载 ☃️2.const取地址操作符重载 这两个运算符一般不需要重载,使用编译器生成的默认取地址的重载即可,只有特殊情况,才需要重载,比如想让别人获取到指定的内容…...
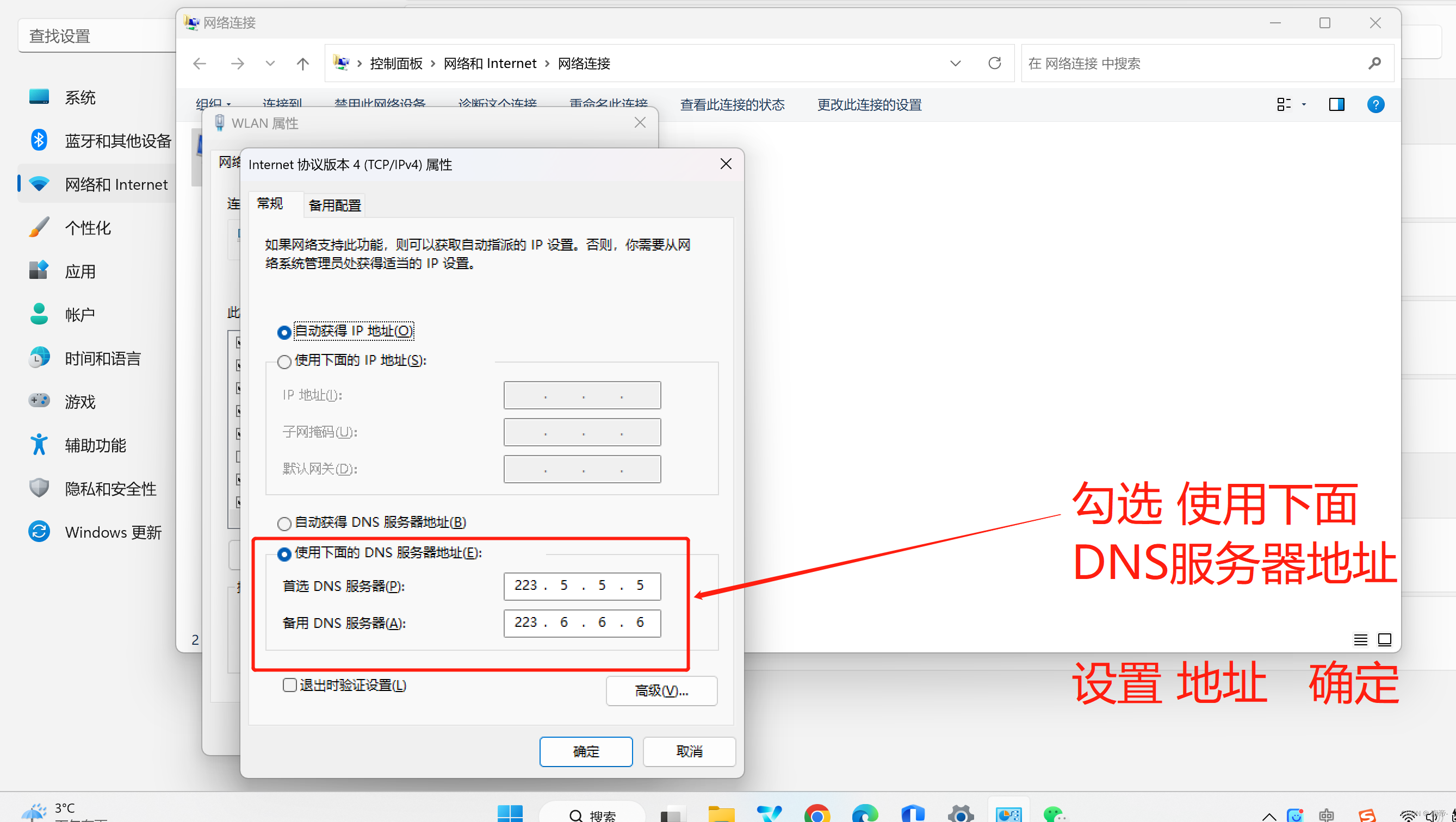
Win11浏览器无法上网,秒杀网上99.9%教程—亲测完胜
前言 例如:网上的教程 列如: 关闭代理服务器、QQ微信可以登录,但浏览器无法上网、Win11、Win10无法上网、重启网络、重启电脑、去掉代理服务器等等。 一系列教程,要多鸡肋就多鸡肋。 我是用我2020年在CSDN上发布的第一篇文章&…...
)
Vulkan Graphics pipeline Dynamic State(图形管线之动态状态)
Vulkan官方英文原文:请见 Vulkan 1.3.236 - A Specification 10.9 章节。对应的Vulkan技术规格说明书版本: Vulkan 1.3.2A dynamic pipeline state is a state that can be changed by a command buffer command during the execution of a command buff…...

CSP-《I‘m stuck!》-感悟
题目 做题过程 注:黄色高亮表示需要注意的地方,蓝色粗体表示代码思路 好久没有写过代码了,今天做这道编程题,简直是灾难现场。 上午编程完后发现样例没有通过,检查发现算法思路出现了问题:我计数了S不能到…...
)
[实践篇]13.19 Qnx进程管理slm学习笔记(二)
【QNX Hypervisor 2.2用户手册】目录(完结) 四,配置文件结构 4.1 根元素 一个配置文件的XML根元素是system,如下: <SLM:system>-- component and module descriptions -- </SLM:system> 4.2 组件 一个进程对于SLM来说就是一个组件。在配置文件中,你必须为一…...
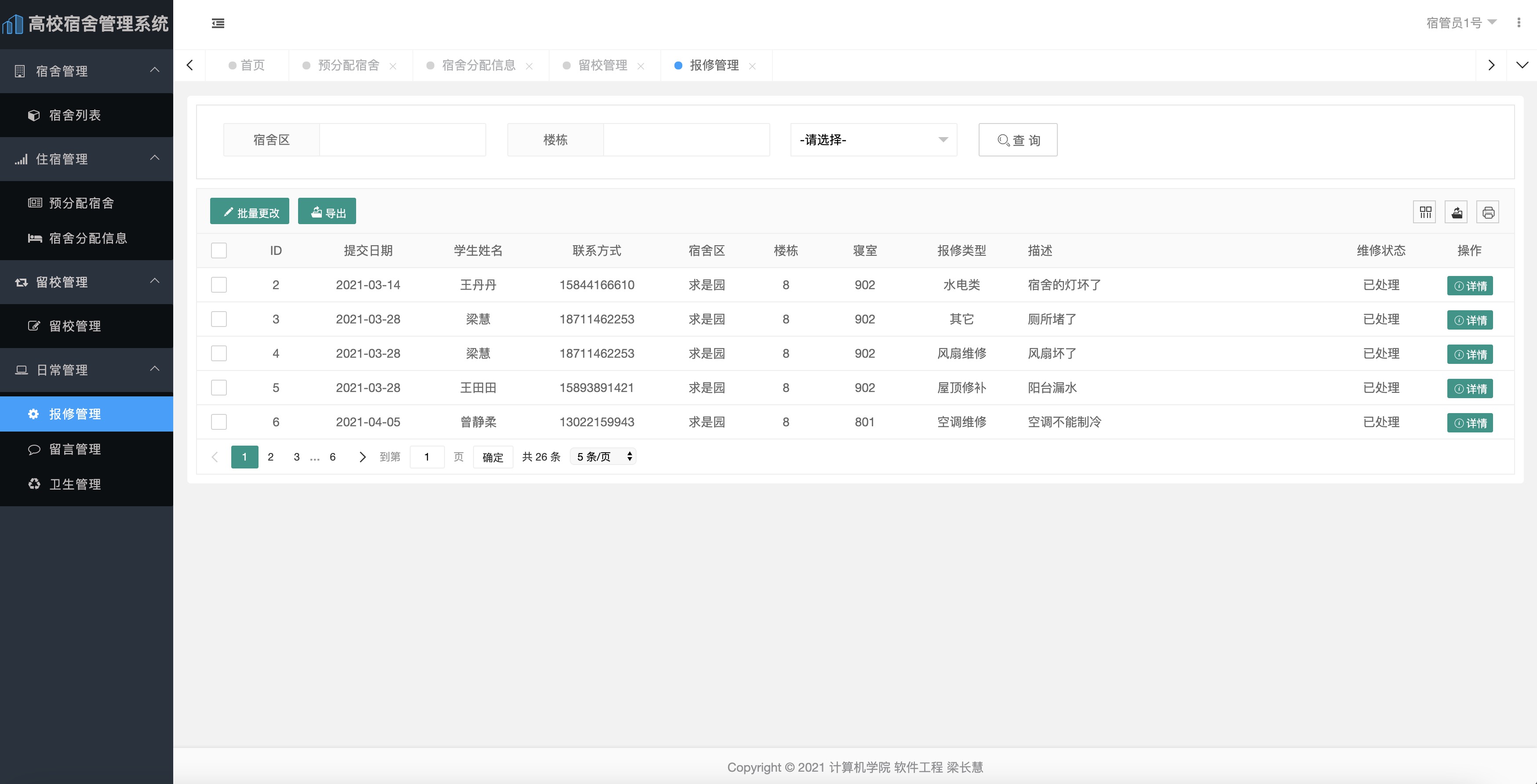
(免费分享)基于 SpringBoot 的高校宿舍管理系统带论文
项目描述 系统代码质量高,功能强大,带论文。 系统的功能主要有: (1)基本信息管理 基本信息分为学生信息和宿舍信息两部分,其功能是负责维护这些信息,对 它们进行增删查改等操作。 &#x…...

运筹系列78:cbc使用介绍
1. 上手 1.1 快速使用 首先是简单的调用测试,在mac上首先安装clp的库:brew install coin-or-tools/coinor/cbc,然后新建项目进行调用,各项配置如下,注意要添加的library和directory比较多: 1.2 命令行方…...

RocketMQ底层源码解析——事务消息的实现
1. 简介 RocketMQ自身实现了事务消息,可以通过这个机制来实现一些对数据一致性有强需求的场景,保证上下游数据的一致性。 以电商交易场景为例,用户支付订单这一核心操作的同时会涉及到下游物流发货、积分变更、购物车状态清空等多个子系统…...

学习802.11之MAC帧格式(一篇就够!)
802.11规范的关键在于MAC(媒介访问控制层),MAC位于各式物理层之上,控制数据传输。负责核心成帧操作以及与有线骨干网络之间的交互。 802.11 MAC采用载波监听多路访问(CSMA)机制来控制对传输媒介的访问&…...

使用阿里云IoT Studio建立物模型可视化界面
使用阿里云IoT Studio建立物模型可视化界面 上一篇文章介绍了如何使用ESP-01S上报数据到物模型:https://blog.csdn.net/weixin_46251230/article/details/128996719 这次使用阿里云IoT Studio建立物模型的Web页面 阿里云IoT Studio: https://studio.i…...

HBase 复习 ---- chapter07
HBase 复习 ---- chapter07部署 HBase(运维) 1:部署 HBase 实际是部署了三个技术(hadoop zookeeper hbase) hadoop hdfs mapreduce common hdfs namenode datanode secondaryNamenode yarn ResourceManager&a…...

跟我一起写Makefile--个人总结
此篇笔记是根据陈皓大佬《跟我一起写Makefile》学习所得 文章目录换行符clean变量make的自动推导另类风格的Makefile清空目标文件的规则cleanMakefile总述显示规则隐晦规则变量的定义注释引用其它的Makefile环境变量MAKEFILESmake的工作方式书写规则规则举例规则的语法在规则中…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...