pytorch 1 张量
张量
文章目录
- 张量
- `torch.Tensor` 的 主要属性
- `torch.Tensor` 的 其他常用属性和方法
- 叶子张量(Leaf Tensors)
- 定义
- 叶子张量的约定
- 深入理解
- 示例代码
- 总结
- 中间计算结果与 `detach()` 方法
- 定义
- 中间计算结果不是叶子节点
- 使用 `detach()` 方法使中间结果成为叶子张量
- 示例代码
- 实际应用
- 总结
- 关于 `requires_grad` 的说明
- 例子
- 直接创建张量的操作
- 解释与应用
- 梯度 requires_grad
- 关于张量是否计算梯度
- 是否开启梯度计算
- reshape/view
- 张量连续的概念
- 参考
tensor是一个类,我们先来认识它有哪些属性,再去观察它有哪些方法函数可使用。
Tensor主要有以下八个主要属性,data,dtype,shape,device,grad,grad_fn,is_leaf,requires_grad。
torch.Tensor 的 主要属性
-
data:- 包含张量的原始数据,不包含梯度信息。
- 如果你不关心梯度,只关心张量的数据本身,可以通过
tensor.data访问。
-
dtype:- 张量的数据类型,如
torch.float32、torch.int64等。 - 可以通过
tensor.dtype查看或指定张量的数据类型。
- 张量的数据类型,如
-
shape:- 张量的形状(也称为尺寸),表示每个维度的大小。
- 可以通过
tensor.shape或tensor.size()获取。
-
device:- 表示张量所在的设备,如
cpu或cuda:0(第一个GPU)。 - 可以通过
tensor.device获取张量所在的设备。
- 表示张量所在的设备,如
-
requires_grad:- 如果
True,表示张量需要计算梯度,在反向传播时会记录操作以便计算梯度。 - 可以通过
tensor.requires_grad设置或检查。
- 如果
-
grad:- 存储与张量关联的梯度信息,在反向传播之后会填充该值。
- 可以通过
tensor.grad访问,通常用于更新模型参数。
-
grad_fn:- 记录创建张量的
Function(函数),是创建该张量的操作的历史。 - 对于叶子节点张量(
is_leaf=True),grad_fn为None,因为它们不是通过某个操作计算得到的。
- 记录创建张量的
-
is_leaf:- 如果张量是计算图中的叶子节点,则
is_leaf=True。 - 通常,叶子节点是由用户创建的,且
requires_grad=True,没有使用运算符对它们进行进一步的计算。
- 如果张量是计算图中的叶子节点,则
torch.Tensor 的 其他常用属性和方法
-
ndim:- 返回张量的维度数(即张量的秩)。
-
T:- 返回张量的转置(对于2D张量来说,相当于矩阵转置)。
-
numel():- 返回张量中元素的总数。
-
stride():- 返回张量在每个维度上的步长。
-
storage():- 返回底层存储对象。
-
contiguous():- 返回一个内存连续的相同张量。如果张量在内存中不是连续的,这个方法会返回一个连续的副本。
-
to(device):- 将张量移动到指定设备(如 CPU 或 GPU)。
-
detach():- 创建一个与当前计算图分离的新张量,不会参与梯度计算。
-
clone():- 创建张量的深拷贝。
-
item():- 对于单元素张量,返回其 Python 标量值。
-
numpy():- 将张量转换为 NumPy 数组(仅在张量位于 CPU 上时可用)。
-
size():- 返回张量的形状(等同于
shape)。
- 返回张量的形状(等同于
-
view()或reshape():- 改变张量的形状,
view()要求张量的内存是连续的,而reshape()则不需要。
- 改变张量的形状,
-
squeeze()和unsqueeze():squeeze()移除张量中所有大小为1的维度。unsqueeze()在指定位置插入一个大小为1的新维度。
-
cpu()和cuda():cpu()将张量移动到 CPU。cuda()将张量移动到 GPU。
-
backward():- 计算梯度,通常在损失张量上调用。
-
retain_grad():- 对非叶节点也保留梯度(默认情况下,只有叶节点的梯度被保留)。
-
register_hook():- 注册一个反向传播的钩子函数,在计算梯度时调用,可以用于调试或修改梯度。
以下是关于 PyTorch 中 叶子张量 和 中间计算结果 的整理总结。
叶子张量(Leaf Tensors)
定义
在 PyTorch 的自动求导机制中,叶子张量 是计算图中的最基础的节点(或源节点),它们通常由用户直接创建,并且不会通过任何操作进一步派生出新的张量。
- 叶子张量: 是计算图中不依赖其他张量的张量。通常是通过直接创建张量的操作(例如
torch.tensor()、torch.randn()等)生成的。叶子张量通常代表模型的输入数据或参数。
叶子张量的约定
“All Tensors that have requires_grad which is False will be leaf Tensors by convention.”
这句话的意思是:
按照惯例,所有 requires_grad=False 的张量都被视为叶子张量。
深入理解
-
叶子张量(Leaf Tensors):
- 在 PyTorch 的计算图中,叶子张量是那些不是由其他张量通过操作创建的张量。
- 它们通常是直接创建的或者是模型的参数。
-
requires_grad:- 这个属性表示是否需要为该张量计算梯度。
- 当
requires_grad=True时,PyTorch 会跟踪对该张量的所有操作,以便后续进行自动微分。
-
约定(Convention):
- 这是 PyTorch 的一个设计决定,不是技术上的必然结果,但它简化了计算图的管理和梯度计算。
示例代码
import torch# 创建 requires_grad=False 的张量(叶子节点)
x = torch.randn(3)
print("x is leaf:", x.is_leaf) # True
print("x requires grad:", x.requires_grad) # False# 创建 requires_grad=True 的张量(也是叶子节点)
y = torch.randn(3, requires_grad=True)
print("y is leaf:", y.is_leaf) # True
print("y requires grad:", y.requires_grad) # True# 进行操作,创建非叶子节点
z = x + y
print("z is leaf:", z.is_leaf) # False
print("z requires grad:", z.requires_grad) # True# 使用 detach() 创建新的叶子节点
w = z.detach()
print("w is leaf:", w.is_leaf) # True
print("w requires grad:", w.requires_grad) # False
总结
- 叶子张量: 通常是由用户直接创建的,不依赖其他张量。默认情况下,
requires_grad=False的张量会被视为叶子张量。 - 非叶子张量: 是通过其他张量的操作生成的,
requires_grad=True的张量,如果不是直接创建的张量,而是通过计算生成的,则不是叶子张量。
中间计算结果与 detach() 方法
定义
中间计算结果 是通过对叶子张量进行操作生成的张量。它们通常不是叶子张量,除非使用 detach() 方法将它们从计算图中分离出来。
中间计算结果不是叶子节点
当我们对叶子张量进行操作时,生成的中间计算结果会被记录在计算图中。这些结果通常是非叶子张量,因为它们依赖于前面的操作和张量。
使用 detach() 方法使中间结果成为叶子张量
如果你希望将一个中间计算结果从计算图中分离出来,使其成为叶子张量,可以使用 detach() 方法。detach() 方法返回一个新的张量,与原始张量共享数据,但不会记录在计算图中,因此不会参与梯度计算。
示例代码
import torch# 创建叶子张量
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)# 对叶子张量进行操作,生成非叶子张量
y = x + 2# 使用 detach() 使 y_detach 成为叶子张量
y_detach = y.detach()print("y is leaf:", y.is_leaf) # False
print("y_detach is leaf:", y_detach.is_leaf) # True# 检查 y_detach 是否记录计算历史
print("y requires grad:", y.requires_grad) # True
print("y_detach requires grad:", y_detach.requires_grad) # False
实际应用
使用 detach() 有多个应用场景:
- 冻结模型的一部分:在训练时冻结某些层的参数,防止这些参数的梯度被计算和更新。
- 防止梯度传播:在反向传播中,有时希望切断某些部分的梯度传播,可以使用
detach()。 - 生成中间结果用于其他目的:例如在某些自定义损失函数或正则化过程中,需要从计算图中提取中间结果。
总结
- 中间计算结果通常不是叶子节点:因为它们依赖于前面的操作和张量。
detach()方法:可以将中间结果从计算图中分离出来,使其成为叶子张量,并且不再计算梯度。
关于 requires_grad 的说明
- 如果一个张量的
requires_grad=False,意味着我们不需要对其计算梯度。在大多数情况下,这样的张量是叶子张量。 - 反之,如果一个张量的
requires_grad=True,并且是通过其他张量的操作生成的(比如a = b + c,其中b.requires_grad=True),那么a不是叶子张量,因为它是通过操作生成的,依赖于b和c。
例子
import torch# 直接创建的张量,requires_grad=False,因此是叶子张量
x = torch.tensor([1.0, 2.0, 3.0])
print("x is leaf:", x.is_leaf) # True# 直接创建的张量,requires_grad=True,因此是叶子张量
y = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
print("y is leaf:", y.is_leaf) # True# 通过操作创建的张量,requires_grad=True,因此不是叶子张量
z = y + 2
print("z is leaf:", z.is_leaf) # False# 使用 detach 创建的张量,requires_grad=False,是叶子张量
z_detach = z.detach()
print("z_detach is leaf:", z_detach.is_leaf) # True
直接创建张量的操作
当然!下面是一个表格,列出了常见的用于直接创建张量的 PyTorch 函数和方法。每个方法都会创建一个新的张量,默认情况下,这些张量的 requires_grad=False,并且它们是计算图中的叶子节点。
| 函数/方法 | 描述 | 示例 |
|---|---|---|
torch.tensor() | 从数据创建张量,可以指定数据类型。 | x = torch.tensor([1, 2, 3]) |
torch.arange() | 创建一个包含从开始值到结束值(不包含结束值)的等差序列的张量。 | x = torch.arange(0, 10, 2) |
torch.linspace() | 创建一个包含在指定区间内均匀分布数值的张量。 | x = torch.linspace(0, 1, steps=5) |
torch.zeros() | 创建一个所有元素都为0的张量。 | x = torch.zeros(3, 3) |
torch.ones() | 创建一个所有元素都为1的张量。 | x = torch.ones(3, 3) |
torch.full() | 创建一个所有元素都为指定值的张量。 | x = torch.full((2, 2), 7) |
torch.eye() | 创建一个单位矩阵(对角线为1,其他位置为0)。 | x = torch.eye(3) |
torch.empty() | 创建一个未初始化的张量,元素值为未定义。 | x = torch.empty(2, 3) |
torch.rand() | 创建一个包含在 [0, 1) 之间均匀分布的随机数的张量。 | x = torch.rand(3, 3) |
torch.randn() | 创建一个包含从标准正态分布(均值为0,方差为1)中抽取的随机数的张量。 | x = torch.randn(3, 3) |
torch.randint() | 创建一个包含在 [low, high) 范围内均匀分布的整数的张量。 | x = torch.randint(0, 10, (3, 3)) |
torch.randperm() | 创建一个包含从0到n-1的随机排列的整数的张量。 | x = torch.randperm(10) |
torch.normal() | 创建一个包含从指定均值和标准差的正态分布中抽取的随机数的张量。 | x = torch.normal(mean=0, std=1, size=(3, 3)) |
torch.from_numpy() | 从一个 NumPy 数组创建张量,张量和数组共享内存。 | x = torch.from_numpy(np.array([1, 2, 3])) |
torch.clone() | 创建一个与原张量内容相同但在内存中独立的副本。 | x = torch.tensor([1, 2, 3]).clone() |
torch.randint_like() | 根据给定张量的形状,创建一个包含在 [low, high) 范围内的均匀分布整数的张量。 | x = torch.randint_like(torch.ones(3, 3), 0, 10) |
torch.zeros_like() | 根据给定张量的形状,创建一个所有元素为0的新张量。 | x = torch.zeros_like(torch.ones(3, 3)) |
torch.ones_like() | 根据给定张量的形状,创建一个所有元素为1的新张量。 | x = torch.ones_like(torch.ones(3, 3)) |
torch.full_like() | 根据给定张量的形状,创建一个所有元素为指定值的新张量。 | x = torch.full_like(torch.ones(3, 3), 7) |
torch.empty_like() | 根据给定张量的形状,创建一个未初始化的新张量。 | x = torch.empty_like(torch.ones(3, 3)) |
解释与应用
-
直接创建张量: 这些方法创建的张量通常作为计算图中的叶子节点,因为它们是由用户直接定义的。除非显式指定
requires_grad=True,否则它们不会参与梯度计算。 -
典型用例:
torch.zeros()和torch.ones()常用于初始化模型参数。torch.randn()和torch.rand()常用于生成随机初始化的张量,用于神经网络的权重初始化等。torch.eye()常用于生成单位矩阵,用于线性代数计算。torch.from_numpy()常用于将现有的 NumPy 数据转换为 PyTorch 张量。
梯度 requires_grad
关于张量是否计算梯度
这是一个很好的问题!PyTorch 中 requires_grad 的默认值取决于张量的创建方式和上下文。让我们详细探讨一下:
-
基本规则:
- 对于大多数通过 PyTorch 操作创建的新张量,默认
requires_grad=False。 - 对于通过涉及至少一个
requires_grad=True的张量的操作创建的新张量,默认requires_grad=True。
- 对于大多数通过 PyTorch 操作创建的新张量,默认
-
常见情况:
a) 使用 PyTorch 函数直接创建的张量:
x = torch.ones(5) # 默认 requires_grad=False y = torch.randn(3) # 默认 requires_grad=Falseb) 从 NumPy 数组创建的张量:
import numpy as np a = np.array([1, 2, 3]) x = torch.from_numpy(a) # 默认 requires_grad=Falsec) 通过操作已有张量创建的新张量:
x = torch.ones(5) y = x + 2 # 如果 x.requires_grad=False,则 y.requires_grad=Falsed) 模型参数:
import torch.nn as nn model = nn.Linear(10, 5) # model.weight 和 model.bias 默认 requires_grad=True -
特殊情况:
a) 使用
torch.tensor()创建张量时:x = torch.tensor([1, 2, 3]) # 默认 requires_grad=False y = torch.tensor([1, 2, 3], requires_grad=True) # 显式设置为 Trueb) 在
torch.no_grad()上下文中:with torch.no_grad():x = torch.ones(5) # 即使显式设置,也会是 Falsey = torch.ones(5, requires_grad=True) # 仍然是 True,但梯度不会被跟踪
让我们通过一个例子来演示这些规则:
import torch
import torch.nn as nn# 基本张量创建
x = torch.ones(5)
print("1. torch.ones():", x.requires_grad)# 使用 torch.tensor()
y = torch.tensor([1, 2, 3])
print("2. torch.tensor():", y.requires_grad)# 操作现有张量
z = x + y
print("3. 操作现有张量:", z.requires_grad)# 至少一个输入 requires_grad=True
x.requires_grad_(True)
w = x + y
print("4. 至少一个输入 requires_grad=True:", w.requires_grad)# 模型参数
model = nn.Linear(5, 3)
print("5. 模型参数 (weight):", model.weight.requires_grad)
print(" 模型参数 (bias):", model.bias.requires_grad)# torch.no_grad() 上下文
with torch.no_grad():a = torch.ones(5)b = torch.ones(5, requires_grad=True)print("6. torch.no_grad() 中创建:", a.requires_grad)print(" torch.no_grad() 中显式设置 True:", b.requires_grad)# 检查 torch.no_grad() 对梯度跟踪的影响
c = x * 2
with torch.no_grad():d = x * 2
print("7. 正常操作:", c.requires_grad)
print(" torch.no_grad() 中的操作:", d.requires_grad)这个示例展示了不同情况下 requires_grad 的默认行为。运行这段代码,你会看到:
- 基本张量创建默认为
False。 - 使用
torch.tensor()创建的张量默认为False。 - 操作不需要梯度的张量得到的新张量默认为
False。 - 如果操作中至少有一个输入需要梯度,结果张量默认为
True。 - 模型参数默认为
True。 - 在
torch.no_grad()上下文中,新创建的张量仍遵循默认规则,但不会跟踪计算图。 torch.no_grad()会暂时阻止梯度跟踪,即使操作涉及requires_grad=True的张量。
理解这些默认行为很重要,因为它们影响:
- 计算图的构建
- 内存使用
- 反向传播过程
在实际应用中:
- 对于模型参数,通常保持默认的
requires_grad=True。 - 对于输入数据,通常保持默认的
requires_grad=False。 - 在需要冻结某些参数或部分模型时,可以手动设置
requires_grad=False。 - 使用
torch.no_grad()来临时禁用梯度计算,通常用于推理或评估阶段。
是否开启梯度计算
要查看一个 PyTorch 张量是否开启了梯度计算,有几种方法。我来为您详细介绍这些方法,并提供一些实用的例子。
import torch# 创建几个不同的张量用于演示
x = torch.randn(3, requires_grad=True)
y = torch.zeros(3)
z = x * 2print("1. 使用 .requires_grad 属性:")
print("x.requires_grad:", x.requires_grad)
print("y.requires_grad:", y.requires_grad)
print("z.requires_grad:", z.requires_grad)print("\n2. 使用 .is_leaf 属性:")
print("x.is_leaf:", x.is_leaf)
print("y.is_leaf:", y.is_leaf)
print("z.is_leaf:", z.is_leaf)print("\n3. 检查 .grad_fn 属性:")
print("x.grad_fn:", x.grad_fn)
print("y.grad_fn:", y.grad_fn)
print("z.grad_fn:", z.grad_fn)print("\n4. 使用 torch.is_grad_enabled() 函数:")
print("全局梯度计算状态:", torch.is_grad_enabled())print("\n5. 在 torch.no_grad() 上下文中:")
with torch.no_grad():w = x * 2print("w.requires_grad:", w.requires_grad)print("torch.is_grad_enabled():", torch.is_grad_enabled())print("\n6. 使用 .detach() 方法:")
v = x.detach()
print("v.requires_grad:", v.requires_grad)print("\n7. 检查 .grad 属性:")
print("x.grad:", x.grad) # 在反向传播之前为 None
x.sum().backward()
print("反向传播后 x.grad:", x.grad)让我解释一下这些方法:
-
使用
.requires_grad属性:- 这是最直接的方法。
- 如果为
True,表示张量需要梯度计算。
-
使用
.is_leaf属性:- 叶子节点通常是需要梯度的张量。
- 但注意,并非所有
requires_grad=True的张量都是叶子节点。
-
检查
.grad_fn属性:- 如果张量有
grad_fn,说明它是由某个操作创建的,并且可能参与梯度计算。 - 叶子节点(如直接创建的张量)的
grad_fn为None。
- 如果张量有
-
使用
torch.is_grad_enabled()函数:- 这会检查全局的梯度计算状态。
- 在
torch.no_grad()上下文中,这会返回False。
-
在
torch.no_grad()上下文中:- 这个上下文管理器临时禁用梯度计算。
- 在此上下文中创建的张量默认
requires_grad=False。
-
使用
.detach()方法:- 这会创建一个与原张量共享数据但不需要梯度的新张量。
-
检查
.grad属性:- 只有需要梯度的叶子节点在反向传播后才会有
.grad属性。 - 在反向传播之前,即使
requires_grad=True,.grad也是None。
- 只有需要梯度的叶子节点在反向传播后才会有
重要说明:
requires_grad=True不意味着张量当前正在跟踪梯度,只是表示它有能力跟踪梯度。- 在
torch.no_grad()上下文中,即使requires_grad=True的张量也不会跟踪梯度。 - 非叶子节点(由操作创建的张量)通常不存储梯度,除非使用
retain_grad()。
在实际应用中:
- 对于模型参数,通常会看到
requires_grad=True。 - 对于输入数据,通常
requires_grad=False。 - 在模型评估或推理阶段,经常使用
torch.no_grad()来提高效率。
reshape/view
PyTorch 中的 reshape 和 view 方法。这两个方法都用于改变张量的形状,但它们在某些情况下有细微的区别。我们来详细解释一下:
x.view()
view 方法返回一个新的张量,其数据与原张量共享内存,但具有不同的形状。
特点:
- 更快,因为它不会复制数据。
- 要求张量是连续的(contiguous)。
- 如果张量不是连续的,会抛出错误。
x.reshape()
reshape 方法也返回一个新形状的张量,但它更灵活。
特点:
- 可以处理非连续的张量。
- 如果可能,它会返回一个视图(view)。
- 如果不可能返回视图,它会返回一个副本。
让我们通过一些例子来说明:
import torch# 创建一个简单的张量
x = torch.tensor([[1, 2, 3],[4, 5, 6]])
print("原始张量 x:")
print(x)
print("x 的形状:", x.shape)# 使用 view
y = x.view(3, 2)
print("\n使用 view 后的张量 y:")
print(y)
print("y 的形状:", y.shape)# 使用 reshape
z = x.reshape(3, 2)
print("\n使用 reshape 后的张量 z:")
print(z)
print("z 的形状:", z.shape)# 创建一个非连续的张量
a = torch.tensor([[1, 2, 3],[4, 5, 6]]).t() # 转置使其非连续
print("\n非连续张量 a:")
print(a)
print("a 是否连续:", a.is_contiguous())# 尝试使用 view(这会引发错误)
try:b = a.view(3, 2)
except RuntimeError as e:print("\n使用 view 时的错误:")print(e)# 使用 reshape(这会成功)
c = a.reshape(3, 2)
print("\n使用 reshape 后的张量 c:")
print(c)
print("c 的形状:", c.shape)这个例子展示了 view 和 reshape 的主要区别:
- 对于连续的张量,
view和reshape的行为是相同的。 - 对于非连续的张量,
view会失败,而reshape会成功(通过创建一个新的张量副本)。
在实践中:
- 如果你确定张量是连续的,使用
view可能会稍微快一些。 - 如果你不确定张量是否连续,或者你希望代码更加健壮,使用
reshape是更安全的选择。
总的来说,reshape 更加通用和安全,而 view 在特定情况下可能会有轻微的性能优势。在大多数情况下,使用 reshape 是个不错的选择,因为它能够处理更多的情况,并且性能差异通常是微不足道的。
张量连续的概念
很好的问题!让我们深入探讨一下张量的连续性概念。
张量的连续性(contiguity)是指张量在内存中的存储方式。这个概念对于理解某些 PyTorch 操作的行为和性能很重要。
-
连续的张量(Contiguous Tensor):
- 在内存中以一个连续的块存储。
- 元素的存储顺序与它们的访问顺序一致。
- 可以直接用
view()改变形状而不需要复制数据。
-
非连续的张量(Non-contiguous Tensor):
- 在内存中的存储可能是分散的或者顺序与访问顺序不一致。
- 通常是某些操作(如转置、切片等)的结果。
- 使用
view()会引发错误,需要先调用contiguous()或使用reshape()。
让我们通过一些例子来说明这个概念:
import torch# 创建一个连续的张量
x = torch.tensor([[1, 2, 3],[4, 5, 6]])
print("原始张量 x:")
print(x)
print("x 是否连续:", x.is_contiguous())# 创建一个非连续的张量(通过转置)
y = x.t()
print("\n转置后的张量 y:")
print(y)
print("y 是否连续:", y.is_contiguous())# 尝试对非连续张量使用 view
try:z = y.view(6)
except RuntimeError as e:print("\n对非连续张量使用 view 的错误:")print(e)# 使用 contiguous() 使张量变为连续
y_cont = y.contiguous()
print("\n使用 contiguous() 后的张量 y_cont:")
print(y_cont)
print("y_cont 是否连续:", y_cont.is_contiguous())# 现在可以使用 view 了
z = y_cont.view(6)
print("\n对连续张量使用 view 的结果 z:")
print(z)# 使用 reshape 可以直接处理非连续张量
w = y.reshape(6)
print("\n对非连续张量使用 reshape 的结果 w:")
print(w)解释:
-
原始张量
x是连续的。 -
转置操作
x.t()创建了一个非连续的张量y。这是因为转置改变了元素的访问顺序,但没有改变它们在内存中的实际存储顺序。 -
当我们尝试对非连续张量
y使用view()时,PyTorch 抛出了一个错误。这是因为view()需要张量是连续的。 -
我们可以使用
contiguous()方法创建一个新的连续张量y_cont。这个操作会在内存中重新排列元素。 -
对连续的
y_cont使用view()是可以的。 -
reshape()方法可以直接处理非连续的张量,它会在内部自动调用contiguous()如果需要的话。
实际应用中的影响:
-
性能:连续的张量通常可以更快地进行某些操作,因为数据在内存中是连续的。
-
内存使用:
contiguous()操作可能会创建一个新的张量副本,这会增加内存使用。 -
某些操作的要求:一些 PyTorch 操作(如
view())要求张量是连续的。 -
CUDA 操作:在 GPU 上,使用连续的张量通常会有更好的性能。
参考
- https://pytorch.org/docs/stable/tensors.html
- https://tingsongyu.github.io/PyTorch-Tutorial-2nd/chapter-2/2.3-datastruct-tensor.html
- https://pytorch.org/tutorials/beginner/introyt/autogradyt_tutorial.html
- https://pytorch.org/docs/stable/notes/autograd.html
相关文章:

pytorch 1 张量
张量 文章目录 张量torch.Tensor 的 主要属性torch.Tensor 的 其他常用属性和方法叶子张量(Leaf Tensors)定义叶子张量的约定深入理解示例代码总结 中间计算结果与 detach() 方法定义中间计算结果不是叶子节点使用 detach() 方法使中间结果成为叶子张量示…...

音视频开发继续学习
RGA模块 RGA模块定义 RGA模块是RV1126用于2D图像的裁剪、缩放、旋转、镜像、图片叠加等格式转换的模块。比方说:要把一个原分辨率1920 * 1080的视频压缩成1280 * 720的视频,此时就要用到RGA模块了。 RGA模块结构体定义 RGA区域属性结构体 imgType&am…...

【Datawhale X 魔搭 】AI夏令营第四期大模型方向,Task1:智能编程助手(持续更新)
在一个数据驱动的世界里,人工智能的未来应由每一个愿意学习和探索的人共同塑造和掌握。希望这里是你实现AI梦想的起点。 大模型小白入门:https://linklearner.com/activity/14/11/25 大模型开发工程师能力测试:https://linklearner.com/activ…...
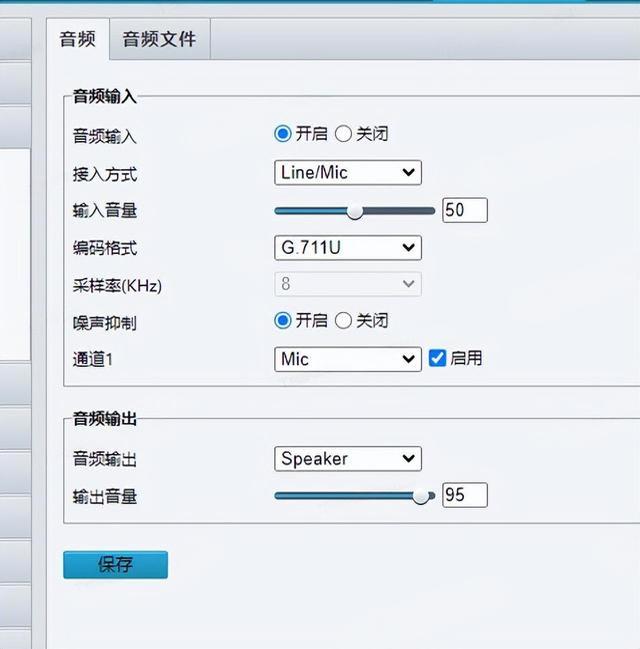
如何判断监控设备是否支持语音对讲
目录 一、大华摄像机 二、海康摄像机 三、宇视摄像机 一、大华摄像机 注意:大华摄像机支持跨网语音对讲,即设备和服务器可以不在同一网络内,大华设备的语音通道填写:34020000001370000001 配置接入示例: 音频输入…...
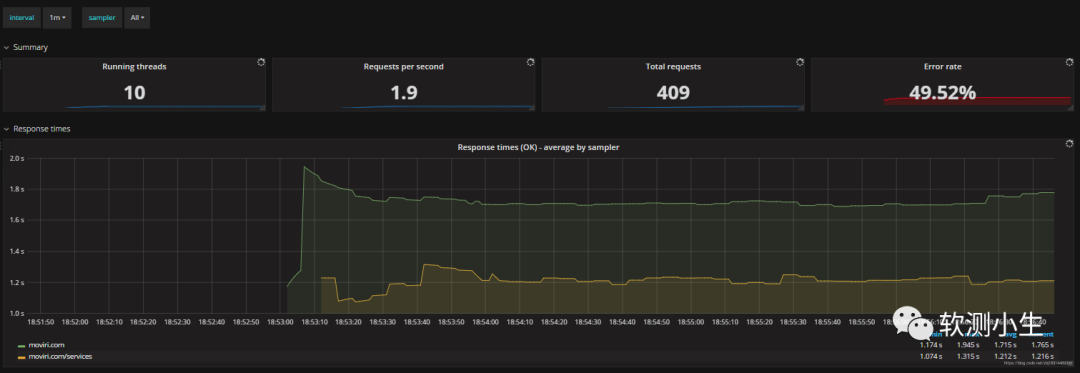
Grafana+Influxdb(Prometheus)+Apache Jmeter搭建可视化性能测试监控平台
此性能测试监控平台,架构可以是: GrafanaInfluxdbJmeterGrafanaPrometheusJmeter Influxdb和Prometheus在这里都是时序性数据库 在测试环境中,压测数据对存储和持久化的要求不高,所以这里的组件可以都通过docker-compose.yml文件…...

【笔记】MSPM0G3507移植RT-Thread——MSPM0G3507与RT_Thread(二)
一.创建新工程 找到"driverlib\empty"空白工程,CTRLC然后CTRLV复制副本 重命名为G3507_RTT 打开KEIL工程 双击empty.syscfg,然后打开SYSCONFIG 我的不知道为啥没有48pin选项,如果你也一样,可以跟着我做,如果…...

计算机毕业设计 美发管理系统 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

soapui调用接口参数传递嵌套xml,多层CDATA表达形式验证
1.环境信息 开发工具:idea 接口测试工具:soapui 编程语言:java 项目环境:jdk1.8 webservice:jdk自带的jws 处理xml:jdk自带的jaxb 2.涉及代码 package org.example.webdemo;import javax.jws.WebMethod; i…...

GB/T35561-2017d,GB/T38565-2020,ocr解析文本
因系统需要只找到pdf版本,解析一版记录 GB/T35561-2017d 10000 , 自然灾害 10100 , 水旱灾害 10101 , 洪水 10102 , 内涝 10103 , 水库重大险情 10104 , 堤防重大险情 10105 , 凌汛 10106 , 山洪 10107 , 农业干旱 10108 , 城镇缺水 10109 , 生态干旱 10110 , 农村…...

IDEA使用LiveTemplate快速生成方法注释
本文目标:开发人员,在了解利用Live Template动态获取方法输入输出参数、创建日期时间方法的条件下,进行自动生成方法注释,达到自动添加方法注释的程度; 文章目录 1 场景2 要点2.1 新增LiveTemplate模版2.2 模版内容填写…...

慢SQL优化
1、避免使用select * select * 不会走覆盖索引,会出现大量的回表操作,从而导致查询sql的性能很低。 --反例 select * from user where id 1;--正例 select name,age from user where id 1;2、union all 代替 union union:去重后的数据…...

MES生产执行系统源码,支持 SaaS 多租户,技术架构:springboot + vue-element-plus-admin
MES的定义与功能 MES是制造业中一种重要的管理信息系统,用于协调和监控整个生产过程。它通过收集、分析和处理各种生产数据,实现对生产流程的实时跟踪和监控,并为决策者提供准确的数据支持。MES涵盖了工厂运营、计划排程、质量管理、设备维护…...

【Linux】分析hung_panic生成的vmcore
简介 1、遇到一个问题: 上述日志是oom_kill,下述日志是hung_panic 2、分别解释两层含义,全部日志如下: [75834.243209] kodo invoked oom-killer: gfp_mask0x600040(GFP_NOFS), order0, oom_score_adj968 [75834.245657] CPU: 0…...

unity 画线写字
效果 1.界面设置 2.涉及两个脚本UIDraw.cs和UIDrawLine.cs UIDraw.cs using System; using System.Collections.Generic; using UnityEngine; using UnityEngine.EventSystems; using UnityEngine.UI;public class UIDraw : MonoBehaviour, IPointerEnterHandler, IPointerEx…...

GitHub的详细介绍
GitHub是一个面向开源及私有软件项目的托管平台,它建立在Git这个分布式版本控制系统之上,为开发者提供了在云端存储、管理和共享代码的便捷方式。以下是对GitHub的详细介绍: ### 一、GitHub的基本功能 1. **代码托管**:GitHub允…...

【鸿蒙学习】HarmonyOS应用开发者基础 - 构建更加丰富的页面之Tabs(三)
学完时间:2024年8月14日 一、前言叨叨 学习HarmonyOS的第六课,人数又成功的降了500名左右,到了3575人了。 本文接上一文章【鸿蒙学习】HarmonyOS应用开发者基础 - 构建更加丰富的页面(一),继续记录构建更…...

Detectron2 安装指南
文章目录 前言Detectron2官方文档官方指南 安装 Detectron2虚拟环境安装 PyTorch安装 Detectron2 总结 前言 Detectron2 是 Meta AI 的一个机器视觉相关的库,建立在 Detectron 和 maskrcnn-benchmark 基础之上,可以进行目标检测、语义分割、全景分割&am…...

亚马逊 Linux mysql5.7 安装纪录
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz cp /home/admin/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz /usr/local/mysql #解压压缩包 tar -zxvf mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz 重命名mysql-…...

ZLMediaKit编译webrtc
ZLMediaKit官方文档写的挺详细的,但是也不算特别详细。 按照上面的文档,执行到cmake的时候,会提示“srtp 未找到, WebRTC 相关功能打开失败”,但是cmke还是可以继续啊。此时看文档说webrtc比较复杂,默认是不编译的&am…...

KEEPALIVED高可用集群最详解
目录 一、高可用集群 1.1 集群的类型 1.2 实现高可用 1.3 VRRP:Virtual Router Redundancy Protocol 1.3.1 VRRP相关术语 1.5.2 VRRP 相关技术 二、部署KEEPALIVED 2.1 keepalived 简介 2.2 Keepalived 架构 2.3 Keepalived 环境准备 2.3.1 实验环境 2…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...

DeepSeek越强,Kimi越慌?
被DeepSeek吊打的Kimi,还有多少人在用? 去年,月之暗面创始人杨植麟别提有多风光了。90后清华学霸,国产大模型六小虎之一,手握十几亿美金的融资。旗下的AI助手Kimi烧钱如流水,单月光是投流就花费2个亿。 疯…...
Linux基础开发工具——vim工具
文章目录 vim工具什么是vimvim的多模式和使用vim的基础模式vim的三种基础模式三种模式的初步了解 常用模式的详细讲解插入模式命令模式模式转化光标的移动文本的编辑 底行模式替换模式视图模式总结 使用vim的小技巧vim的配置(了解) vim工具 本文章仍然是继续讲解Linux系统下的…...