观存储历史,论数据未来
数据存储
这几天我反复观看了腾讯云社区的《中国数据库前世今生》纪录片,每次的感受都大相径庭。以下是我在这段时间里对纪录片的两个不同感想,希望感兴趣的小伙伴们也能去观看一番。
一个是关于国产数据库的发展趋势的探讨:https://blog.csdn.net/qq_40280043/article/details/141079384
另一个则是我个人与数据库相识、相知的经历:https://blog.csdn.net/qq_40280043/article/details/140957203

今天,受到这部纪录片的启发,我对数据存储产生了浓厚的兴趣,因此我在网上搜集了大量资料,准备探讨数据存储从古至今的发展历程,以及这一过程如何一步步支撑起现代数据库操作。通过对这一历程的深入探索,我将分享我对未来数据存储应具备的特性和趋势的看法。
本文所包含的数据和案例均来源于我个人的资料搜集和网络搜索,可能存在一些不准确之处。如果有任何不符之处,还请读者多多包涵并指正。
观历史
正如俗话所说的,“好记性不如烂笔头”,现代人们常依赖纸质记录来保存和维护数据。实际上,数据存储的需求自人类诞生之初便开始显现。让我们从数据存储的角度出发,深入探讨数据库的发展历程,以了解数据存储如何随时间演变和进步。
在我看来,数据库不仅仅是一种软件工具,而是一种用于系统化保存和管理大量数据的结构化形式。它的核心在于提供一种有效的方式来组织和存取数据,从而支持信息的存储和检索。
古代中国的记录方式
石器时代的记录方式
在石器时代,中国地区的记录方式相对原始,主要依赖口头传承和简单的物质标记。考古学家发现的一些岩画和陶器上的刻画符号,可能是最早的记录信息的方式之一。这些早期的记录形式为我们提供了宝贵的见解,揭示了古代人类如何尝试以最基本的方式保存和传递信息。

竹简与木简的使用
进入战国时期,竹简逐渐成为主要的书写材料。这种材料不仅轻便易得,而且便于保存,使得文字记录得以广泛传播。在这一时期,《左传》、《国语》等重要史书便是在竹简上记录下来的。此外,由于木简具有较高的耐久性,它们常被用于记录更为重要的文献,如法律文书和重要信件。因此,竹简和木简各自发挥了不同的作用,满足了时代对信息记录和保存的不同需求。

蔡伦造纸术的革新
公元105年,蔡伦对造纸工艺进行了重大改进,他利用树皮、麻头、破布和鱼网等原料,开发出一种新型纸张。这一创新不仅极大地降低了书写材料的成本,还显著提高了信息记录和传播的效率,使得书写和记录变得更加普及和便捷。
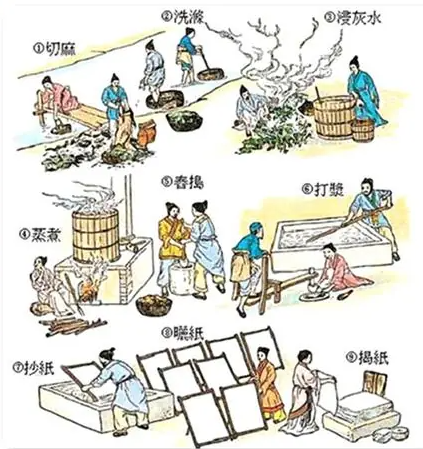
蔡伦的造纸术不仅在当时的社会中产生了重要影响,也对人类文明的传承和发展产生了深远的影响。这一技术的普及极大地推动了知识的传播和文化的积累,为世界各地的学术研究、文学创作和行政管理奠定了坚实的基础。
活字印刷术的发明
宋代的毕昇发明了活字印刷术,这一革命性的技术极大地改变了书籍复制的方式。之前,书籍的复制通常依赖于手工抄写,过程繁琐且耗时。而活字印刷术的出现,使得书籍的复制变得更加快捷和经济。利用可重复使用的活字,印刷工人能够迅速组装并打印出大量书籍,这不仅显著降低了制作成本,还提高了信息的传播效率。

尽管活字印刷术与现代数据库技术相隔了数百年,它们在本质上都致力于提高信息的存储、管理和检索效率。活字印刷术通过物理方式实现了信息的快速复制和广泛传播,极大地推动了知识的普及和文化的传承。而现代数据库技术则采用数字化手段,以更高效的方式存储和检索海量数据,满足了当代信息化社会对数据管理的复杂需求。这一技术演进不仅反映了信息处理方法的历史发展,也为现代信息存储技术的进步奠定了坚实的基础。
近现代中国及其技术发展
早期计算机和数据存储技术
20世纪中期,计算机技术的迅速发展催生了全球范围内的科技革新,中国也开始积极投入计算机及数据存储技术的研究与开发。1958年,中国成功研制出其第一台计算机——“1958型”,这不仅标志着中国计算机技术的起步,还代表了中国在计算机科学领域的重大突破。

在20世纪50年代,计算机的数据存储主要依赖磁带和磁盘技术。磁带是当时最早的计算机数据存储介质之一,尽管其存储密度较低,但由于成本低廉且复制方便,成为了计算机存储的主要选择。

随着技术的发展,磁盘存储技术的出现显著提高了数据存储的容量和访问速度,成为了更为先进的存储解决方案。中国在1960年代开始研究磁盘存储技术,逐步建立起了自己的磁盘生产线,为后续的技术发展奠定了坚实的基础。

与此同时,1956年IBM推出了首个硬盘——“IBM 305 RAMAC”,尽管其体积大约相当于两个冰箱,且存储容量仅为5MB,但这一开创性的产品标志着硬盘存储技术的诞生,为未来的数据存储技术发展奠定了基础。

早期计算机主要依赖磁带和磁盘作为数据存储介质,尽管这些技术在当时显得较为原始,但它们为中国后来的数据存储技术进步提供了重要的起点和经验。
关系数据库模型的采纳
1970年代,随着关系数据库模型的提出,中国的计算机科学家开始研究和应用这一模型。到了1980年代,SQL语言的标准化进一步推动了中国数据库技术的发展。

在1970年代和1980年代,硬盘的普及显著推动了数据库技术的实际应用和广泛普及。硬盘凭借其较大的存储容量和优越的随机访问能力,使得数据库系统能够处理更大规模的数据集,同时提高了数据访问的速度和效率。相比于磁带,硬盘在实时数据处理和复杂查询方面表现得更加出色,为数据库系统的进一步发展和应用奠定了坚实的基础。
换句话说,尽管硬盘技术在这些年中经历了许多进步和优化,现代使用的HDD硬盘在架构上与1973年的硬盘相差不大,其核心设计理念和基本工作原理依然保持一致。
关系数据库管理系统(RDBMS)的普及
到了1990年代,随着全球化的加速,国际知名的数据库系统如Oracle等开始在中国得到广泛应用,促进了中国数据库技术的快速发展。

到了1990年代,数据存储领域主要以**机械硬盘(HDD)**为主。这个时期,硬盘技术经历了显著的改进,容量不断增加,成本不断降低,使其成为主流的数据存储解决方案。
与此同时,尽管固态硬盘(SSD)在这一时期开始出现一些实验性产品,但由于技术尚未成熟和成本较高,它们尚未得到广泛应用。因此,机械硬盘在数据存储领域仍然占据主导地位。硬盘技术的持续进步不仅提升了存储容量和访问速度,还为数据库系统的广泛普及和性能提升提供了坚实的基础,推动了数据管理和应用的发展。
聊当下
21世纪的中国与云原生数据库技术
进入21世纪,尤其是2020年代,中国的数据存储技术经历了重大转型,重点转向了云原生数据库技术和云存储服务。在这一时期,尽管底层存储介质仍然包括传统的硬盘,尤其是固态硬盘(SSD),但云原生数据库技术和云存储服务的引入显著改变了数据存储和管理的方式。这些先进的技术使得硬盘的操作和管理变得更加透明、自动化和高效。
通过云原生架构,数据可以在分布式环境中进行高效处理和存储,而云存储服务则提供了灵活的存储选项、自动化的数据备份和恢复功能,以及即时的扩展能力。这种转型不仅提升了数据管理的灵活性和可靠性,还推动了数据存储技术在大规模应用场景中的进一步发展。
NoSQL数据库的探索
2000年代,面对大数据和非结构化数据的挑战,中国开始探索NoSQL数据库技术。这些数据库以其灵活的数据模型和可扩展性,满足了新兴应用场景的需求。

在2000年代,数据存储主要以**硬盘(HDD)和固态硬盘(SSD)**为主。虽然SSD开始逐渐普及,硬盘仍然在大容量存储方面占据主导地位。SSD的出现为处理速度和数据访问提供了显著的提升,但由于成本问题,HDD依然是大多数数据中心和存储解决方案的主要选择。
云计算与云数据库服务的发展
2010年代,随着云计算的兴起,中国的云服务提供商推出了多种云数据库服务,如腾讯云的TencentDB,这些服务为用户提供了更加灵活和高效的数据存储解决方案。
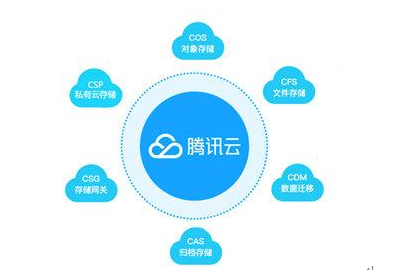
在2010年代,数据存储主要以固态硬盘(SSD)和云存储为主。SSD的普及提升了数据访问速度,而云存储服务则提供了灵活的扩展性和按需访问能力,支持了大数据和分布式计算的需求。
云原生数据库技术的创新
到了2020年代,云原生数据库技术在中国得到了快速发展。中国企业开始采用和开发如TDSQL等云原生数据库技术,以满足日益增长的数据存储和处理需求。

在2020年代,数据存储主要以云存储和云原生数据库为主。云原生数据库,如TDSQL等,提供了高度的弹性、可扩展性和容错能力,满足了大规模数据处理和存储的需求。同时,云存储服务的普及使得数据存储变得更加灵活和高效,支持各种应用场景和动态变化的负载需求。
论未来
我认为,未来的数据存储将继续呈现多样化的发展趋势,各种存储技术将根据具体需求(如存储密度、速度、成本、可靠性等)进行选择和优化。随着科技的不断进步,我们可以预见到多种可能的主流存储形式的出现。
例如,高密度存储技术可能会进一步提高数据存储的容量,而快速的固态硬盘(SSD)和新兴的存储级内存(SCM)则可能满足对速度的更高要求。同时,随着成本的降低和技术的成熟,云存储和分布式存储解决方案将变得更加普及,提供灵活性和高可用性。量子存储和DNA存储等前沿技术也有可能在未来成为新的主流形式。
欢迎大家积极讨论,分享你们对未来存储技术的见解和预测。
固态硬盘(SSD)
首先,让我们探讨一下已经存在的存储技术。相比传统的硬盘驱动器(HDD),固态硬盘(SSD)在读写速度和耐用性方面具有显著优势,预计它将继续扩大其市场份额。SSD采用闪存技术,运行时不会产生噪音和热量,而硬盘驱动器由于其机械结构,在工作过程中会产生噪音和热量,这不仅影响用户体验,也可能影响设备的稳定性和寿命。

此外,随着技术的不断进步和制造成本的降低,未来固态硬盘的价格有望进一步降低。尽管目前固态硬盘的价格通常高于传统硬盘,但若其成本进一步降低,固态硬盘将可能在价格上逐渐具备与HDD竞争的优势。虽然固态硬盘可能无法完全替代传统硬盘在某些特定应用中的角色,但它无疑将成为一种更为流行和广泛采用的存储介质。随着固态硬盘技术的成熟和普及,其在性能、耐用性和性价比方面的优势将会越来越明显。
磁带存储的复兴
磁带技术正在经历一场令人瞩目的复兴,凭借其高密度、高可靠性和经济成本,现代磁带技术在数据存储领域重新获得了重要地位。尤其是在长期数据归档和备份方面,现代磁带库能够支持达到PB级的数据存储容量,并且具有优异的数据完整性保护,即使在断电的情况下也能确保数据的安全。这使得磁带在备份和灾难恢复场景中表现得尤为出色。

尽管盒式磁带在大众视野中淡出已有约20年,但它依然在许多看不见的细分领域发挥着重要作用。例如,在互联网行业,由于磁带依靠电磁感应进行读写,并且在存储时无需通电,这使得它在网络离线状态下也能保持高度的安全性,特别适用于数据备份。像谷歌和微软Azure等大型云服务提供商,仍然广泛使用磁带进行数据备份。
2011年,谷歌曾经历过一次软件更新意外,导致Gmail中4万个账户的电子邮件被删除,但由于他们有使用磁带备份,这些重要数据得以成功恢复。国内的一些档案管理机构也同样依赖磁带备份。例如,郑州档案局在2017年进行了磁带数据恢复演练,以帮助工作人员熟悉如何在紧急情况下将备份数据从磁带恢复到磁盘中。
这些现象表明,磁带技术并未过时,而是以一种不易察觉的形式继续存在并发挥作用。虽然它不再是我们年轻时听音乐时使用的磁带,但其在数据存储和备份领域的实用性和可靠性依旧显著。你对磁带的未来怎么看呢?
DNA存储
DNA存储技术代表了一种新兴的信息存储方式,它利用人工合成的脱氧核糖核酸(DNA)作为存储介质。通过特定的算法,数字信息被编码成DNA序列,并合成到DNA分子中进行存储。这种技术具备多项显著优势:
首先,存储密度极高:1克DNA能够存储约2拍字节(PB)数据,这相当于大约300万张CD的存储容量,显示出其在数据存储上的巨大潜力。其次,DNA存储的数据保存时间可能长达数千年,远远超出目前任何存储技术的寿命,确保数据的长期保存。再者,DNA存储的物理稳定性极高,与电子介质不同,DNA不会因读取次数而衰退,这为长期数据存储提供了根本性解决方案。
此外,DNA存储技术具有低能耗和环保的优点,相比于传统存储技术,它能显著减少能源消耗和环境影响。最后,DNA的自我复制能力为数据的备份和复制提供了天然优势,进一步提升了数据存储的可靠性和可维护性。这些特点使得DNA存储技术成为一种极具前景的信息存储解决方案。

尽管DNA存储技术展现了极大的潜力,但目前面临一些挑战,这些挑战限制了其在大规模数据存储中的应用。其中,合成成本较高、合成速度慢以及读取过程中的延迟问题是主要的制约因素。这些问题使得DNA存储技术尚未广泛普及和应用。
例如,在2021年12月,东南大学的师生团队成功地将该校校训“止于至善”存入DNA序列,这一突破标志着DNA存储技术在实际应用中的重要进展。此外,2022年10月,天津大学的研究团队将10幅精选的敦煌壁画存入DNA中,并通过加速老化实验发现,这些信息在特定条件下可以保存非常长的时间。这些研究展示了DNA存储技术在文化遗产保存和长期数据存储中的巨大潜力,但要实现广泛应用仍需克服技术上的障碍。
量子存储
量子存储是量子信息科学中的一个重要领域,它涉及利用量子态来存储信息。与传统的数据存储技术相比,量子存储技术展现了独特的优势和潜力,尽管当前仍处于研究和发展的初期阶段。
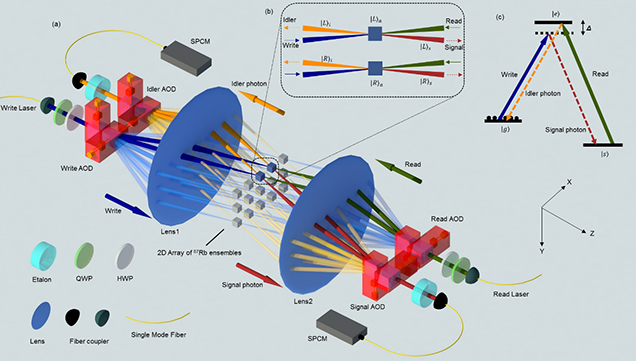
首先,数据表示方面,经典计算中数据以二进制形式存储,每个比特要么是0要么是1。而在量子计算中,量子比特(qubits)可以同时处于0和1的叠加状态。这种量子叠加现象为数据表示提供了全新的维度,使得数据存储具有更高的表达能力。
其次,量子存储技术的并行性显著增强。借助量子叠加和量子纠缠的原理,量子存储可以在单个操作中处理大量数据,从而提供前所未有的并行处理能力。这种能力使得量子存储能够在处理复杂计算和大规模数据时展现出强大的性能优势。
此外,量子存储的安全性也具有独特的优势。基于量子力学原理,如量子不可克隆定理,量子存储的数据理论上是安全的。这意味着,量子存储能够提供一种强有力的安全保障,有效防止数据被复制和窃取。
量子存储技术的发展被认为是量子信息科学中最令人激动的领域之一,具备了彻底改变我们处理和存储信息方式的潜力。其独特的能力不仅在于处理和存储数据的效率提升,还在于实现前所未有的安全性和计算能力。然而,要将这些潜力转化为现实应用,仍需在基础研究和技术开发上取得显著进展。随着量子物理学、材料科学以及信息技术等多个领域的深入交叉融合,量子存储技术有望从理论研究阶段逐步过渡到实际应用中,成为未来信息处理和存储领域的重要突破点。
总结
在探索未来的数据存储技术时,我们不禁感慨于人类智慧的无限可能。从古代的竹简、木简,到蔡伦的造纸术,再到现代的机械硬盘、固态硬盘,直至云存储和前沿的DNA存储与量子存储,技术的演进总是令人惊叹。历史告诉我们,在时间面前,所有不可逾越的技术壁垒都是纸老虎。
对于程序员而言,尽管底层存储介质的更迭可能对我们的操作方式影响甚微,但我们必须顺势而为,紧跟技术发展的步伐。数据存储的形式可能变化不大,但其背后的介质交互却经历了翻天覆地的变革。例如,硬盘的更替对我们来说可能是无感知的,但这背后是技术不断突破和创新的结果。
从竹简到云数据库,每一次技术的飞跃都不仅仅是存储介质的更新,更是数据处理能力和效率的大幅提升。活字印刷术的发明,让我们见证了信息复制和传播的革命;而现代数据库技术的兴起,尤其是云原生数据库技术的发展,更是让我们的数据管理变得更加自动化、高效和灵活。
然而,技术的每一次进步都不是一蹴而就的,它需要我们不断地探索、尝试和完善。正如我们在探索国产数据库的道路上所经历的那样,每一个阶段的突破都是对前人智慧的继承和发展。
面向未来,我们有理由相信,随着量子计算、DNA存储等前沿技术的逐步成熟,数据存储将迎来更加辉煌的时代。这些技术不仅将极大地提升数据存储的容量、速度和安全性,更将推动整个社会信息化水平的飞速发展。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位掘金优秀作者、腾讯云内容共创官、阿里云专家博主、华为云云享专家。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
相关文章:
观存储历史,论数据未来
数据存储 这几天我反复观看了腾讯云社区的《中国数据库前世今生》纪录片,每次的感受都大相径庭。以下是我在这段时间里对纪录片的两个不同感想,希望感兴趣的小伙伴们也能去观看一番。 一个是关于国产数据库的发展趋势的探讨:https://blog.c…...

linux:对目录的操作
一、对目录操作 1,打开目标目录 2.读取目录,, 3.关闭目录 目录 当文件看,只不过操作函数和操作文件函数不一样。 *1.opendir DIR *opendir(const char *name); 功能:打开一个目录获得一个目录流指针 参数:name:目录名 返回值…...

详解Redis 高可用的方式 Redis Cluster
Redis 高可用方式 Redis 提供了多种高可用性方案,主要包括以下几种方式: 主从复制(Replication) 主从复制是最基本的高可用性方案,通过将数据从一个主节点复制到多个从节点来实现数据的冗余和读写分离。主节点负责所…...
=0)
$clog2(1)=0
项目场景: 写ip 时, 使用参数化的方式实现2w1r 时,出现计算读返回index 时,减下溢! 问题描述 verilog中会使用parameter 参数化,例如使用dpth 和$clog2(dpth)addr 。 常见的写法没有什么问题。 module …...

开发学习日记1
用这个系列博客记录下学习开发的一些小收获 git的使用: 说来惭愧,学到了大二,git的使用还是一团糟,记录一下如何使用git进行团队合作开发 当要加入其他人的项目时首先你要创建自己的分支(克隆一下其他分支ÿ…...

孙宇晨领航波场TRON:引领数字资产迈向崭新纪元
在风起云涌的数字资产领域,孙宇晨这个名字始终与创新、突破和引领紧密相连。作为波场TRON的创始人,他不仅是一位远见卓识的领导者,更是推动数字资产迈向新纪元的坚实力量。 自波场TRON诞生以来,孙宇晨便以其敏锐的洞察力…...
)
python运维(twenty-four day)
一、python基础 1、环境python2、python3 [rootpython ~]# yum list installed | grep python #检查是否有python包 [rootpython ~]# yum list installed | grep epel #检查是否有epel包 [rootpython ~]# yum -y install epel-release [rootpython ~]# yum -y instal…...

Eureka原理实践
1. 简介 1.1. 概述 Eureka是Netflix开源的一个服务注册与发现框架,它在微服务架构中扮演着至关重要的角色。 Eureka由两个核心组件组成: Eureka Server(服务注册中心):负责存储、管理和提供服务实例信息,如服务名、IP地址、端口号等。Eureka Server通常采用集群部署以保…...

Ant-Design-Vue快速上手指南+排坑
1. 简介 1.1. 概述 Ant-Design-Vue是由阿里巴巴开源的一个基于Vue.js框架的企业级UI设计语言。它旨在帮助开发者构建设计优雅、体验流畅的企业级应用。Ant-Design-Vue提供了一系列高质量的Vue组件,包括表单、表格、布局、导航、图标等,可以帮助开发者快速搭建应用程序界面。…...

mysql5.7安装
1.创建一个software文件 2.先下载mysql的repo源 wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm 3安装源包 rpm -ivh mysql-community-release-el7-5.noarch.rpm 可能会报错 改成命令 rpm -ivh mysql-community-release-el7-5.noarch.rpm --nodeps…...

UE开发中的设计模式(三) —— 对象池模式
在FPS游戏中,射击会生成子弹,在命中敌人后子弹会被销毁,那么会导致子弹对象频繁地创建和销毁,会造成运行效率降低且会产生内存碎片问题,而对象池模式可以很好地解决这个问题。 文章目录 问题提出概述问题解决总结 问题…...

Mocha测试框架:JavaScript自动化测试的瑞士军刀
在JavaScript开发中,自动化测试是确保代码质量和可靠性的关键环节。Mocha是一个广泛使用的JavaScript测试框架,它支持多种断言库,允许开发者编写简洁、灵活的测试用例。Mocha特别适用于Node.js环境,但也可以在浏览器中运行。本文将…...

flask实现Streaming内容传输
当传输大量内存,以至于超出内存大小,一般http服务器会报500错误,这时可以使用Streaming流的方式来传输内容,类似ChatGPT和视频流那样的输出方式,flask里要用到生成器和直接响应。 from flask import stream_with_cont…...

seata的使用(SpringBoot项目整合seata)
文章目录 1、解压 seata-server-1.7.1.zip2、启动 双击 seata-server.bat3、启动 seata 控制台用户界面4、所有分布式事务相关数据库要有undo-log5、项目引入seata依赖6、项目添加seata配置7、代码实现: 1、解压 seata-server-1.7.1.zip 2、启动 双击 seata-server.…...

docker容器和宿主机网络不通
防火墙未开启,检查网络配置无异常 解决: [rootlocalhost ~]# vim /etc/sysctl.confnet.bridge.beidge-nf-call-iptables 1 net.bridge.beidge-nf-call-ip6tables 1[rootlocalhost ~]# sysctl -p [rootlocalhost ~]# systemctl restart docker 如果网…...

编程学习之旅:高效记录与整理笔记的艺术
引言:知识的海洋与导航的灯塔 在编程的浩瀚星空中,每一位学习者都像是勇敢的航海家,驾驶着知识的帆船,在无尽的信息海洋中探索未知的领域。然而,这片海洋既充满了机遇,也潜藏着挑战。信息的过载、知识的碎…...

dev c++中,在C++11模式下编译带M_PI宏的文件报错的解决办法
一、问题描述 当使用C11的模式,编译引用了math库中的M_PI的源文件时,报M_PI未声明的错误。 二、问题原因 因为M_PI是GNU扩展的宏,它不属于C11的标准,而-stdc11,表示以C11的标准进行编译,因此会产生以上问…...

【ubutnu24.04】k8s部署2:摸索修复问题
1.30.0 一直init失败有人说版本兼容问题重新安装了最新的1.31.0 版本kubeadm init 仍旧失败。安装依赖项 sudo apt-get install -y apt-transport-https ca-certificates curl gpgroot@PerfSvr:/home/zhangbin/perfwork/k8sadmin# sudo apt-get install -y apt-transport-https…...
”)
处理JSON数据时遇到的解析错误:“Unexpected character (`“`)”
问题背景 在开发过程中,经常会遇到需要解析JSON数据的情况。然而,在某些情况下,可能会遇到类似“Unexpected character (")”这样的错误。本文将详细介绍该错误的原因、如何诊断以及解决方法。 错误示例 以下是一个典型的错误信息示例…...
)
RDKit|分子输入输出格式解析(如 SMILES、Mol、SDF)
2.3 分子输入输出格式解析(如 SMILES、Mol、SDF) 在化学信息学中,分子的表示方式有很多种,常见的包括 SMILES、Mol 文件、SDF 文件等。RDKit 支持对这些格式的分子数据进行解析和处理,这使得它在化学和药物设计领域得到了广泛应用。本节将介绍如何在 RDKit 中解析和操作这…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...
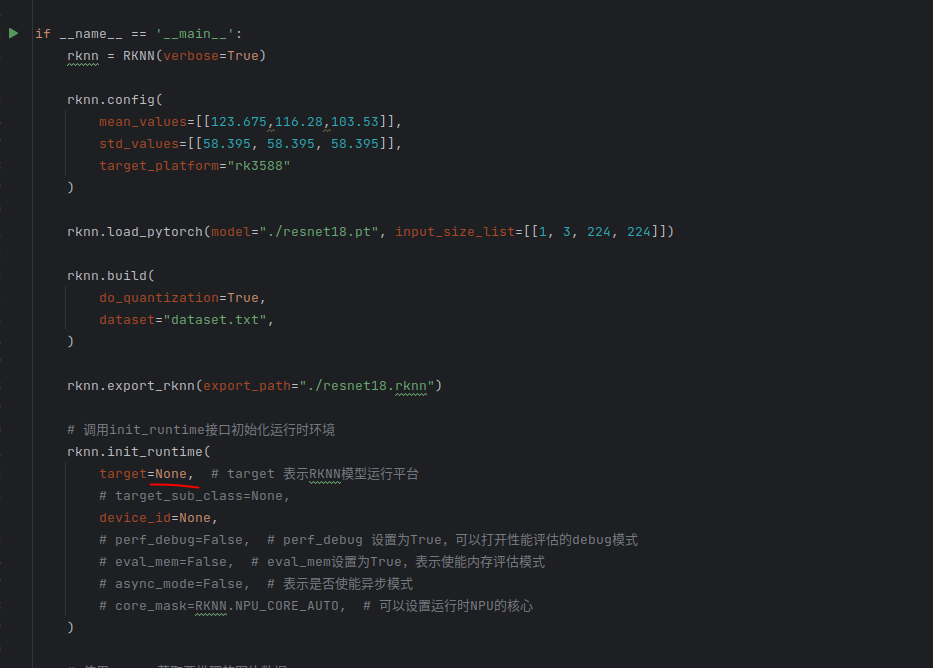
rknn toolkit2搭建和推理
安装Miniconda Miniconda - Anaconda Miniconda 选择一个 新的 版本 ,不用和RKNN的python版本保持一致 使用 ./xxx.sh进行安装 下面配置一下载源 # 清华大学源(最常用) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn…...
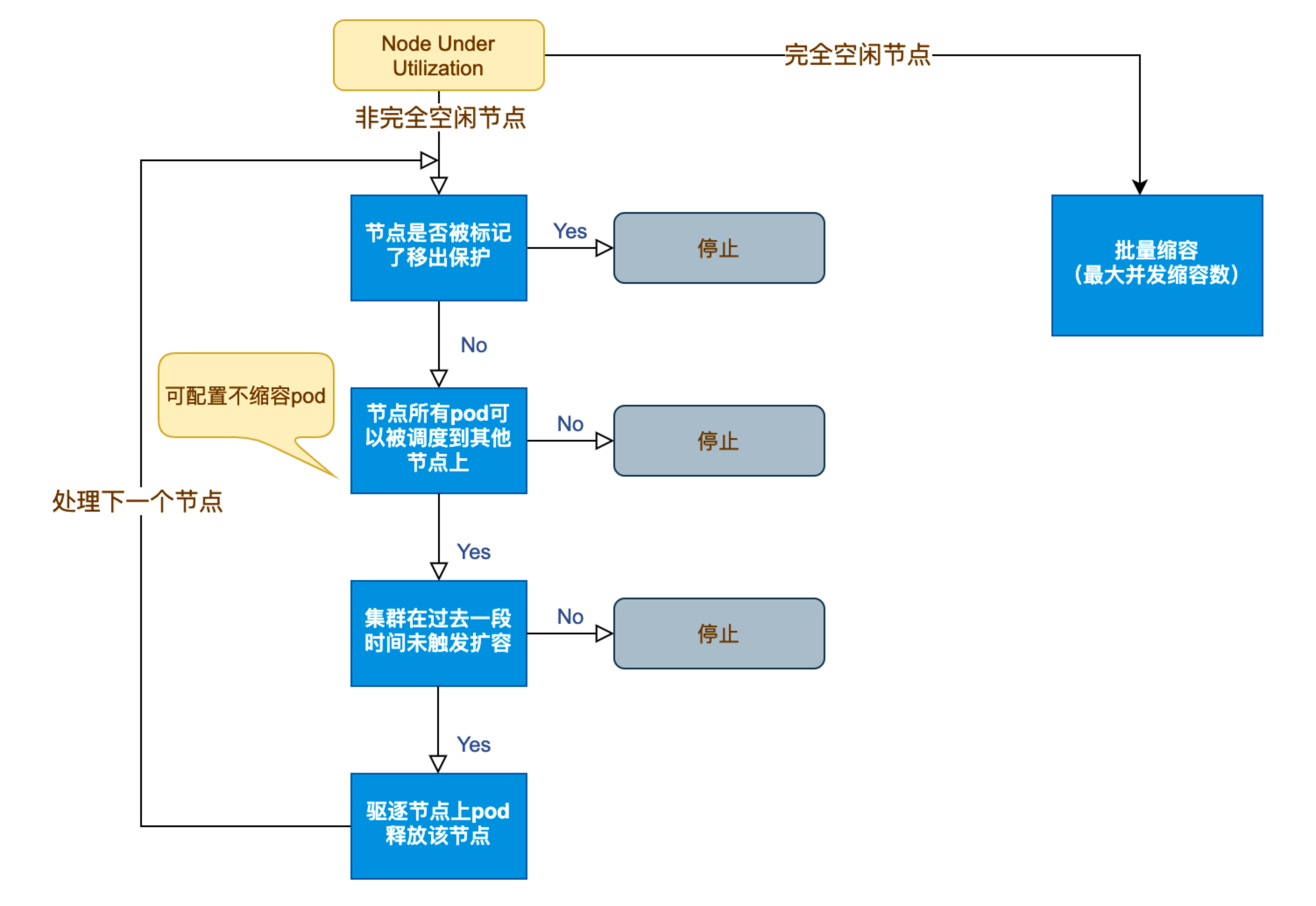
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

Python爬虫实战:研究Restkit库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的有价值数据。如何高效地采集这些数据并将其应用于实际业务中,成为了许多企业和开发者关注的焦点。网络爬虫技术作为一种自动化的数据采集工具,可以帮助我们从网页中提取所需的信息。而 RESTful API …...