Python酷库之旅-第三方库Pandas(081)
目录
一、用法精讲
336、pandas.Series.str.rpartition方法
336-1、语法
336-2、参数
336-3、功能
336-4、返回值
336-5、说明
336-6、用法
336-6-1、数据准备
336-6-2、代码示例
336-6-3、结果输出
337、pandas.Series.str.slice方法
337-1、语法
337-2、参数
337-3、功能
337-4、返回值
337-5、说明
337-6、用法
337-6-1、数据准备
337-6-2、代码示例
337-6-3、结果输出
338、pandas.Series.str.slice_replace方法
338-1、语法
338-2、参数
338-3、功能
338-4、返回值
338-5、说明
338-6、用法
338-6-1、数据准备
338-6-2、代码示例
338-6-3、结果输出
339、pandas.Series.str.split方法
339-1、语法
339-2、参数
339-3、功能
339-4、返回值
339-5、说明
339-6、用法
339-6-1、数据准备
339-6-2、代码示例
339-6-3、结果输出
340、pandas.Series.str.rsplit方法
340-1、语法
340-2、参数
340-3、功能
340-4、返回值
340-5、说明
340-6、用法
340-6-1、数据准备
340-6-2、代码示例
340-6-3、结果输出



一、用法精讲
336、pandas.Series.str.rpartition方法
336-1、语法
# 336、pandas.Series.str.rpartition方法
pandas.Series.str.rpartition(sep=' ', expand=True)
Split the string at the last occurrence of sep.This method splits the string at the last occurrence of sep, and returns 3 elements containing the part before the separator, the separator itself, and the part after the separator. If the separator is not found, return 3 elements containing two empty strings, followed by the string itself.Parameters:
sep
str, default whitespace
String to split on.expand
bool, default True
If True, return DataFrame/MultiIndex expanding dimensionality. If False, return Series/Index.Returns:
DataFrame/MultiIndex or Series/Index of objects.336-2、参数
336-2-1、sep(可选,默认值为' '):字符串,用作分隔符的字符串,你可以设置为任何字符串,作为切割的依据。
336-2-2、expand(可选,默认值为True):布尔值,如果为True,返回一个DataFrame,其中每一列分别对应分隔符前、分隔符和分隔符后的部分;如果为False,返回一个Series,其中每个元素是一个包含三部分的元组。
336-3、功能
从右侧开始查找指定的分隔符,将字符串分为三部分。对于每个字符串,它会查找最后一次出现的分隔符,将字符串分割成以下三部分:
- 分隔符前的部分
- 分隔符本身
- 分隔符后的部分
336-4、返回值
如果expand=True,返回一个DataFrame,包含三列,分别是分隔符前的部分、分隔符、分隔符后的部分;如果expand=False,返回一个Series,每个元素是一个包含上述三部分的元组。
336-5、说明
使用场景:
336-5-1、数据清洗与处理:在数据清洗过程中,常常需要从字符串中提取特定信息,比如从文件路径中提取文件名或文件扩展名,可以使用rpartition方法找到最后一个斜杠,并将路径分割成目录和文件。
336-5-2、文本分析:在进行文本分析时,可能需要从句子中提取特定的词或字符串段,例如,获取最后一个单词和其之前的部分,这在处理评论、反馈等用户生成内容时尤其有用。
336-5-3、分割复合数据:在某些情况下,字符串可能包含用特定字符分隔的复合数据(如“键:值”对),使用rpartition可以方便地将其分成键和值。
336-6、用法
336-6-1、数据准备
无336-6-2、代码示例
# 336、pandas.Series.str.rpartition方法
# 336-1、数据清洗(提取文件名)
import pandas as pd
# 示例数据
file_paths = pd.Series(['/home/user/documents/report.pdf','/var/www/html/index.html','/tmp/example.txt'
])
# 使用rpartition提取文件名
file_names = file_paths.str.rpartition('/')[2]
print("提取的文件名:")
print(file_names, end='\n\n')# 336-2、文本分析(提取最后一个单词)
import pandas as pd
# 示例数据
sentences = pd.Series(['The quick brown fox',' jumps over the lazy dog','Hello world'
])
# 提取最后一个单词
last_words = sentences.str.rpartition(' ')[2]
print("提取的最后一个单词:")
print(last_words, end='\n\n')# 336-3、分割复合数据(提取键和值)
import pandas as pd
# 示例数据
key_value_pairs = pd.Series(['name:Alice','age:30','city:New York'
])
# 提取键和值
keys = key_value_pairs.str.rpartition(':')[0]
values = key_value_pairs.str.rpartition(':')[2]
print("提取的键:")
print(keys)
print("提取的值:")
print(values)336-6-3、结果输出
# 336、pandas.Series.str.rpartition方法
# 336-1、数据清洗(提取文件名)
# 提取的文件名:
# 0 report.pdf
# 1 index.html
# 2 example.txt
# Name: 2, dtype: object# 336-2、文本分析(提取最后一个单词)
# 提取的最后一个单词:
# 0 fox
# 1 dog
# 2 world
# Name: 2, dtype: object# 336-3、分割复合数据(提取键和值)
# 提取的键:
# 0 name
# 1 age
# 2 city
# Name: 0, dtype: object
# 提取的值:
# 0 Alice
# 1 30
# 2 New York
# Name: 2, dtype: object337、pandas.Series.str.slice方法
337-1、语法
# 337、pandas.Series.str.slice方法
pandas.Series.str.slice(start=None, stop=None, step=None)
Slice substrings from each element in the Series or Index.Parameters:
start
int, optional
Start position for slice operation.stop
int, optional
Stop position for slice operation.step
int, optional
Step size for slice operation.Returns:
Series or Index of object
Series or Index from sliced substring from original string object.337-2、参数
337-2-1、start(可选,默认值为None):整数或None,指定要开始切片的位置索引,索引从0开始,如果未指定或为None,则默认从字符串的起始位置开始。
337-2-2、stop(可选,默认值为None):整数或None,指定切片结束的位置索引,切片不包括该位置的字符,如果未指定或为None,则默认切到字符串的末尾。
337-2-3、step(可选,默认值为None):整数或None,指定步长,默认为None,即步长为1;步长为负数时,可以进行反向切片。
337-3、功能
用于从Series中的每个字符串中根据指定的索引范围提取子字符串,它允许你通过指定起始位置、结束位置和步长来精确控制提取的部分。
337-4、返回值
返回Series或Index,具体取决于输入数据的类型:
- 返回值是一个与原Series长度相同的新Series,其中包含根据指定的start、stop和step提取的子字符串。
- 如果某个字符串的长度小于start,该位置返回一个空字符串。
337-5、说明
无
337-6、用法
337-6-1、数据准备
无337-6-2、代码示例
# 337、pandas.Series.str.slice方法
import pandas as pd
# 示例数据
s = pd.Series(['apple', 'banana', 'cherry', 'date'])
# 从索引1开始切片到索引4(不包括4)
result_slice = s.str.slice(start=1, stop=4)
# 仅指定步长为2,默认从头到尾
result_step = s.str.slice(step=2)
# 反向切片,步长为-1
result_reverse = s.str.slice(start=4, stop=0, step=-1)
print("从索引1到4切片:")
print(result_slice)
print("\n每隔一个字符切片:")
print(result_step)
print("\n反向切片:")
print(result_reverse)337-6-3、结果输出
# 337、pandas.Series.str.slice方法
# 从索引1到4切片:
# 0 ppl
# 1 ana
# 2 her
# 3 ate
# dtype: object
#
# 每隔一个字符切片:
# 0 ape
# 1 bnn
# 2 cer
# 3 dt
# dtype: object
#
# 反向切片:
# 0 elpp
# 1 nana
# 2 rreh
# 3 eta
# dtype: object338、pandas.Series.str.slice_replace方法
338-1、语法
# 338、pandas.Series.str.slice_replace方法
pandas.Series.str.slice_replace(start=None, stop=None, repl=None)
Replace a positional slice of a string with another value.Parameters:
start
int, optional
Left index position to use for the slice. If not specified (None), the slice is unbounded on the left, i.e. slice from the start of the string.stop
int, optional
Right index position to use for the slice. If not specified (None), the slice is unbounded on the right, i.e. slice until the end of the string.repl
str, optional
String for replacement. If not specified (None), the sliced region is replaced with an empty string.Returns:
Series or Index
Same type as the original object.338-2、参数
338-2-1、start(可选,默认值为None):整数或None,指定开始切片的索引位置,索引从0开始,如果不指定(即为None),默认从字符串的开头开始切片。
338-2-2、stop(可选,默认值为None):整数或None,指定结束切片的索引位置(不包括该位置),如果不指定(即为None),默认一直切到字符串的末尾。
338-2-3、repl(可选,默认值为None):字符串或None,指定要替换切片部分的字符串,repl将取代原字符串从start到stop位置的内容。
338-3、功能
用于对字符串序列的某一部分进行替换操作,你可以指定从哪个位置开始(start),到哪个位置结束(stop),然后用指定的字符串(repl)来替换这部分内容,该方法不会改变原序列,而是返回一个新的序列,其中包含替换后的字符串。
338-4、返回值
返回一个pandas.Series对象,包含处理后的字符串序列,原序列中的每一个字符串都会根据指定的start、stop和repl参数进行相应的替换操作。
338-5、说明
无
338-6、用法
338-6-1、数据准备
无338-6-2、代码示例
# 338、pandas.Series.str.slice_replace方法
import pandas as pd
# 示例数据
data = pd.Series(['abcdefg', 'hijklmn', 'opqrstu'])
# 使用str.slice_replace()方法
result = data.str.slice_replace(start=2, stop=5, repl='XYZ')
print(result)338-6-3、结果输出
# 338、pandas.Series.str.slice_replace方法
# 0 abXYZfg
# 1 hiXYZmn
# 2 opXYZtu
# dtype: object339、pandas.Series.str.split方法
339-1、语法
# 339、pandas.Series.str.split方法
pandas.Series.str.split(pat=None, *, n=-1, expand=False, regex=None)
Split strings around given separator/delimiter.Splits the string in the Series/Index from the beginning, at the specified delimiter string.Parameters:
patstr or compiled regex, optional
String or regular expression to split on. If not specified, split on whitespace.nint, default -1 (all)
Limit number of splits in output. None, 0 and -1 will be interpreted as return all splits.expandbool, default False
Expand the split strings into separate columns.If True, return DataFrame/MultiIndex expanding dimensionality.If False, return Series/Index, containing lists of strings.regexbool, default None
Determines if the passed-in pattern is a regular expression:If True, assumes the passed-in pattern is a regular expressionIf False, treats the pattern as a literal string.If None and pat length is 1, treats pat as a literal string.If None and pat length is not 1, treats pat as a regular expression.Cannot be set to False if pat is a compiled regexNew in version 1.4.0.Returns:
Series, Index, DataFrame or MultiIndex
Type matches caller unless expand=True (see Notes).Raises:
ValueError
if regex is False and pat is a compiled regex.339-2、参数
339-2-1、pat(可选,默认值为None):字符串或None,指定用于分割字符串的分隔符,如果不指定(即为None),默认按照空白字符(包括空格、制表符等)进行分割;如果指定了regex=True,则pat被解释为正则表达式。
339-2-2、n(可选,默认值为-1):整数或None,指定最多分割的次数,如果为-1(默认值),则不限制分割次数,即分割所有出现的分隔符。
339-2-3、expand(可选,默认值为False):布尔值,是否将分割结果展开为一个DataFrame,若为True,返回一个DataFrame,每个拆分的部分作为一列;若为False(默认值),返回一个Series,其中每个元素是一个列表,包含分割后的字符串部分。
339-2-4、regex(可选,默认值为None):布尔值或None,是否将pat解释为正则表达式,如果为None(默认值),则会根据pat是否为正则表达式自动判断;如果为True,则强制将pat解释为正则表达式。
339-3、功能
用于将字符串按照指定的分隔符拆分为多个部分,你可以控制分割的次数以及是否将结果展开为多列。
339-4、返回值
如果expand=False(默认值),返回一个pandas.Series对象,其中每个元素是一个列表,包含分割后的字符串部分;如果expand=True,返回一个pandas.DataFrame对象,其中每列对应分割后的字符串部分。
339-5、说明
无
339-6、用法
339-6-1、数据准备
无339-6-2、代码示例
# 339、pandas.Series.str.split方法
import pandas as pd
# 示例数据
data = pd.Series(['a,b,c', 'd,e,f', 'g,h,i'])
# 不展开结果,只分割一次
result1 = data.str.split(",", n=1, expand=False)
# 展开结果为多列
result2 = data.str.split(",", expand=True)
print("Result with expand=False:")
print(result1)
print("\nResult with expand=True:")
print(result2)339-6-3、结果输出
# 339、pandas.Series.str.split方法
# Result with expand=False:
# 0 [a, b,c]
# 1 [d, e,f]
# 2 [g, h,i]
# dtype: object
#
# Result with expand=True:
# 0 1 2
# 0 a b c
# 1 d e f
# 2 g h i340、pandas.Series.str.rsplit方法
340-1、语法
# 340、pandas.Series.str.rsplit方法
pandas.Series.str.rsplit(pat=None, *, n=-1, expand=False)
Split strings around given separator/delimiter.Splits the string in the Series/Index from the end, at the specified delimiter string.Parameters:
pat
str, optional
String to split on. If not specified, split on whitespace.n
int, default -1 (all)
Limit number of splits in output. None, 0 and -1 will be interpreted as return all splits.expand
bool, default False
Expand the split strings into separate columns.If True, return DataFrame/MultiIndex expanding dimensionality.If False, return Series/Index, containing lists of strings.Returns:
Series, Index, DataFrame or MultiIndex
Type matches caller unless expand=True (see Notes).340-2、参数
340-2-1、pat(可选,默认值为None):字符串或None,指定用于分割字符串的分隔符,如果不指定(即为None),默认按照空白字符(包括空格、制表符等)进行分割;如果指定了regex=True,则pat被解释为正则表达式。
340-2-2、n(可选,默认值为-1):整数或None,指定最多分割的次数,从右侧开始,如果为-1(默认值),则不限制分割次数,即分割所有出现的分隔符。
340-2-3、expand(可选,默认值为False):布尔值,是否将分割结果展开为一个DataFrame,若为True,返回一个DataFrame,每个拆分的部分作为一列;若为False(默认值),返回一个Series,其中每个元素是一个列表,包含分割后的字符串部分。
340-3、功能
用于将字符串从右侧开始按照指定的分隔符拆分为多个部分,你可以控制分割的次数以及是否将结果展开为多列,与split()方法不同的是,rsplit()从右向左进行分割,这在处理末尾部分的固定格式或逆序字符串时特别有用。
340-4、返回值
如果expand=False(默认值),返回一个pandas.Series对象,其中每个元素是一个列表,包含从右侧开始分割后的字符串部分;如果expand=True,返回一个pandas.DataFrame对象,其中每列对应从右侧分割后的字符串部分。
340-5、说明
无
340-6、用法
340-6-1、数据准备
无340-6-2、代码示例
# 340、pandas.Series.str.rsplit方法
import pandas as pd
# 示例数据
data = pd.Series(['a,b,c', 'd,e,f', 'g,h,i'])
# 不展开结果,只从右侧分割一次
result1 = data.str.rsplit(",", n=1, expand=False)
# 从右侧展开结果为多列
result2 = data.str.rsplit(",", expand=True)
print("Result with expand=False:")
print(result1)
print("\nResult with expand=True:")
print(result2)340-6-3、结果输出
# 340、pandas.Series.str.rsplit方法
# Result with expand=False:
# 0 [a,b, c]
# 1 [d,e, f]
# 2 [g,h, i]
# dtype: object
#
# Result with expand=True:
# 0 1 2
# 0 a b c
# 1 d e f
# 2 g h i相关文章:
Python酷库之旅-第三方库Pandas(081)
目录 一、用法精讲 336、pandas.Series.str.rpartition方法 336-1、语法 336-2、参数 336-3、功能 336-4、返回值 336-5、说明 336-6、用法 336-6-1、数据准备 336-6-2、代码示例 336-6-3、结果输出 337、pandas.Series.str.slice方法 337-1、语法 337-2、参数 …...

C语言基础⑩——构造类型(结构体)
一、数据类型分类 1、基本类型 整数型 短整型:short(2个字节);整型(默认):int(4个字节);长整型:long(8个字节)…...

宝兰德荣获openEuler项目群青铜捐赠人称号,共筑开源生态繁荣新篇章
近日,开放原子开源基金会正式公布了新增捐赠人名单,宝兰德凭借在开源领域的卓越贡献与深厚实力,被授予openEuler项目群青铜捐赠人称号。 开放原子开源基金会是致力于推动全球开源事业发展的非营利机构,于2020年6月在北京成立。开放…...

【Python单元测试】学习笔记3
文章目录 08.PyTest框架什么是PyTestPyTest的优点PyTest的测试环境PyTest常用参数跳过测试 09.PyTest fixture基础PyTest fixture定义和使用引用多个Fixture 10. conftest.pyconftest.py的用途 11. 参数化测试用例为什么需要参数化测试用例使用parameterizer插件实现使用pytest…...

OpenSSL源码编译及Debug
** 1. 环境 Linux 5.19.0-14-generic 22.04.1-Ubuntu 2. 所需工具 gcc version 11.3.0 (Ubuntu 11.3.0-1ubuntu1~22.04) cmake version 3.22.1 3. 步骤 3.1 获取openssl源码 方法可以git clone获得源码,或者直接去GitHub上下载压缩包,GitHub网址…...

go之goburrow/modbus 学习
goburrow/modbus 是一个用Go语言实现的Modbus协议库,提供了Modbus主机(Master)和从机(Slave)的实现,支持两种主要的Modbus传输模式:Modbus TCP和Modbus RTU。 功能介绍 1. 支持的传输模式 Mod…...

开放词汇目标检测(Open-Vocabulary Object Detection, OVOD)算法是什么?
开放词汇目标检测(Open-Vocabulary Object Detection, OVOD)算法是什么? 随着计算机视觉技术的快速发展,目标检测(Object Detection)已经在各种应用场景中得到了广泛的应用。然而,传统的目标检…...

【教程】Ubuntu给pycharm添加侧边栏快捷方式
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 以下教程不仅限于pycharm,其他软件也是一样操作 1、进入到pycharm的目录,先通过命令行打开pycharm: ./bin/pycharm…...

三个月外贸小白好迷茫,该何去何从?
最近看到一个共性的问题,也许对于大多数外贸新人来说,都有过这样的困扰和无力感,也许对于每一个没有强大背景的外贸小伙伴来说,可能都是这样一路成长起来的。 大家好,我是一名普通二本英专生,八月中旬入职…...
)
MySQL数据库——基本查询(Create)
CRUD:Create(创建)Retrieve(读取)Update(更新)Delete(删除) 1.Create ①单行数据全列插入 insert [into] table_name [(colume[,colume]……)] values (value_list) […...

spring-security-1-快速入门
1 功能 身份认证(authentication)授权(authorization)防御常见攻击 身份认证:常见账号密码登录,短信登录 授权:什么样的角色,能看见什么菜单,能访问哪些接口。 2 pom <dependency><groupId>org.springf…...

5 大场景上手通义灵码企业知识库 RAG
大家好,我是通义灵码,你的智能编程助手!最近我又升级啦,智能问答功能全面升级至 Qwen2,新版本在各个方面的性能和准确性都得到了显著提升。此外,行间代码补全效果也全面优化,多种编程语言生成性…...

免费远程控制电脑的软件有哪些?
什么是远程控制? 远程控制是一种通过网络从一台设备操作另一台设备的技术。连接后,用户可以直接远程操作那台电脑进行各种操作。随着科技的不断进步和用户需求的增加,远程控制市场日益蓬勃。远程控制不仅应用于远程办公和远程教学࿰…...

Linux软件包yum
目录 Linux软件包管理器 yum关于rzsz注意事项查看软件包如何安装软件卸载命令 Linux开发工具Linux编辑器-vim使用1. vim的基本概念2. vim的基本操作3. vim正常模式命令集4. vim末行模式命令集5. vim操作总结 小彩蛋 Linux软件包管理器 yum 软件包 在Linux下安装软件ÿ…...

网页的切换与嵌套
网页的切换与嵌套 网页的切换 在浏览器窗口中如果点击超链接标签会在当前的浏览器窗口中显示新的数据,但有些超链接标签点击后却会在一个新的窗口显示数据,这种情况下就无法对新的开的窗口页面进行操作了。 基于这种情况,我们就需要使用dri…...
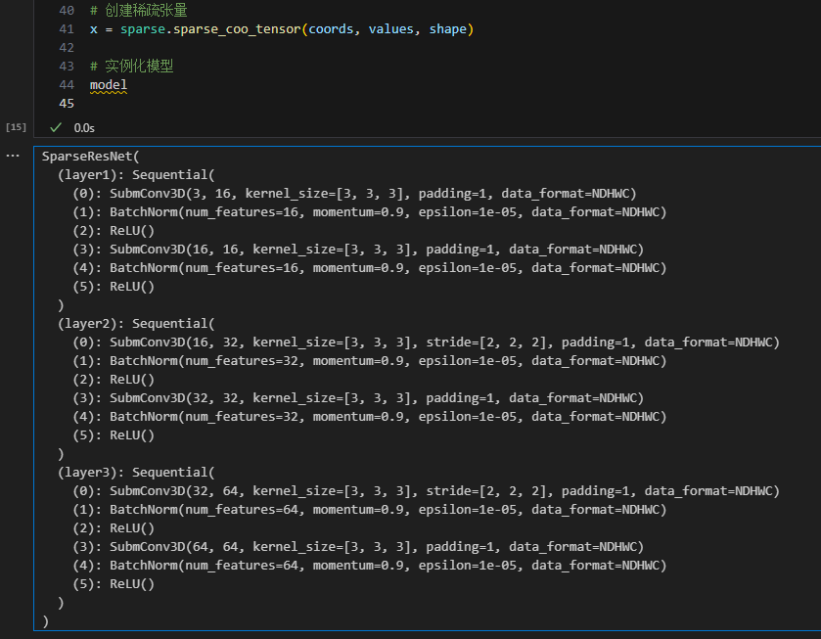
基于飞桨框架的稀疏计算使用指南
本文作者-是 Yu 欸,华科在读博士生,定期记录并分享所学知识,博客关注者5w。本文将详细介绍如何在 PaddlePaddle 中利用稀疏计算应用稀疏 ResNet,涵盖稀疏数据格式的础知识、如何创建和操作稀疏张量,以及如何开发和训练…...

启明云端WT32C3-S6物联网模块,乐鑫ESP32-C3芯片技术应用
随着物联网技术的飞速发展,智能设备在我们生活中的应用越来越广泛。从智能电网到远程医疗,从楼宇自动化到智能家居,这些技术正在改变我们的生活方式。 在这样的背景下,启明云端推出的WT32C3-S6 WiFi模块以其低功耗、高性价比的特…...

超越流水线,企业研发规范落地新思路
作者:子丑 内容大纲: 1、研发规范≠流程约束 2、自动化工具→研发规范载体 3、研发规范在工具上的落地示例 4、研发规范的选型方法与常见实践 研发规范≠流程约束 这个故事特别适合研发规范的场景,我们要避免成为把猫绑在柱子上的信众…...

财务会计与管理会计(四)
文章目录 月度数据统计分析OFFSET函数在图表分析中的应用 多种费用组合分析图SUMPRODUCT函数 省公司全年数据分析模板INDIRECT、OFFSET函数 多公司分季度数据筛选VLOOKUP、IFERROR函数的应用 淘宝后台数据分析OFFSET函数在跨表取数中的应用 燃气消耗台账数据统计分析图SUMPRODU…...
回归分析系列1-多元线性回归
03 多元线性回归 3.1 简介 多元线性回归是简单线性回归的扩展,允许我们同时研究多个自变量对因变量的影响。多元回归模型可以表示为: 其中,x1,x2,…,xp是 p 个自变量,β0 是截距,β1,β2,…,βp是对应的回归系数&…...

【Qt串口实战】硬件升级后readyRead信号丢失的排查与修复
1. 问题现象:硬件升级后readyRead信号神秘消失 那天早上刚到公司,硬件组的同事兴冲冲地跑过来告诉我:"老王,我们给设备升级了最新固件,性能提升30%!"我心想这是好事啊,结果打开调试软…...

InstructPix2Pix:5分钟掌握AI图像编辑的终极指南
InstructPix2Pix:5分钟掌握AI图像编辑的终极指南 【免费下载链接】instruct-pix2pix 项目地址: https://gitcode.com/gh_mirrors/in/instruct-pix2pix 你是否曾经幻想过,只需一句话就能让图片中的对象变成你想要的样子?比如把普通的大…...

ARM Cortex-M调试陷阱:Flash断点残留如何导致Hard Fault
1. 项目概述:一次由断点引发的“血案”与深度剖析最近在支持一个基于NXP KW36(Cortex-M0内核)的BLE项目时,我遇到了一个极其隐蔽且令人抓狂的问题。同一批次的板子,烧录完全相同的固件,绝大多数运行正常&am…...

OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 [特殊字符]
OpenUPM安全最佳实践:保护你的Unity包注册表完全指南 🔒 【免费下载链接】openupm OpenUPM - Open Source Unity Package Registry (UPM) 项目地址: https://gitcode.com/gh_mirrors/op/openupm OpenUPM作为开源Unity包管理器(UPM&…...

林调报告生成慢?文献综述耗时长?NotebookLM林业科研加速器已上线,72小时实测效率提升3.8倍
更多请点击: https://kaifayun.com 第一章:NotebookLM林业科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为深度阅读与知识整合设计。在林业科学研究中,它可高效处理林学文献、野外调查报告、遥感数据说明书、…...

Rust嵌入式开发实战:开源机械爪控制库openclaw-rs架构解析与应用
1. 项目概述:当Rust遇上开源机械爪最近在逛GitHub的时候,偶然发现了一个挺有意思的项目——neul-labs/openclaw-rs。光看名字,你大概能猜到它是个用Rust语言写的、跟机械爪(Claw)相关的开源项目。没错,这正…...

NVIDIA开发环境自动化构建:从CUDA、cuDNN版本对齐到可复现环境管理
1. 项目概述:一个面向开发者的NVIDIA环境构建工具最近在折腾一些AI相关的本地实验,发现配置一个稳定、高效的NVIDIA开发环境,尤其是CUDA、cuDNN这些核心组件的版本对齐,真是一件让人头疼的事情。相信很多做机器学习、深度学习或者…...

从鱼眼到广角:相机畸变公式的实战拆解与参数调优
1. 相机畸变:从鱼眼到广角的视觉魔法 第一次用鱼眼镜头拍照片时,我被画面边缘夸张的弯曲效果震撼到了——直线变成了弧线,方形门框变成了圆润的拱门。这种"变形魔法"其实就是相机畸变最直观的体现。作为算法工程师,我花…...

黑苹果配置不再难:Hackintool一站式解决方案让你15分钟搞定驱动问题
黑苹果配置不再难:Hackintool一站式解决方案让你15分钟搞定驱动问题 【免费下载链接】Hackintool The Swiss army knife of vanilla Hackintoshing 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintool 还在为黑苹果的显卡驱动、音频输出和USB识别问题而…...

【Nanobot】README09_LEVEL4 添加新聊天渠道
【Nanobot】README09_LEVEL4 添加新聊天渠道 源码地址:https://github.com/HKUDS/nanobot 🎯 目标 指导如何为 nanobot 添加新的聊天渠道(如 Signal、Matrix、Line 等)。 📋 添加新 Channel 的步骤 步骤 1࿱…...